










一、AI 绘画工具的选择与运用
1. 工作场景下 AI 绘画工具的选择
目前文生图的主流 AI 绘画平台主要有三种:Midjourney、Stable Diffusion、DALL·E。如果要在实际工作场景中应用,我更推荐 Stable Diffusion。
温馨提示:下方多图预警 1. 注册、创建服务器 ① 打开Midjourney官网,右下角选择"J

通过对比,Stable Diffusion 在数据安全性(可本地部署)、可扩展性(成熟插件多)、风格丰富度(众多模型可供下载,也可以训练自有风格模型)、费用版权(开源免费、可商用)等方面更适合我们的工作场景。

那么如何在实际工作中应用 Stable Diffusion 进行 AI 绘画?
要在实际工作中应用 AI 绘画,需要解决两个关键问题,分别是:图像的精准控制和图像的风格控制。

2. 图像精准控制
图像精准控制推荐使用 Stable Diffusion 的 ControlNet 插件。在 ControlNet 出现之前,AI 绘画更像开盲盒,在图像生成前,你永远都不知道它会是一张怎样的图。ControlNet 的出现,真正意义上让 AI 绘画上升到生产力级别。简单来说 ControlNet 它可以精准控制 AI 图像的生成。

ControlNet 主要有 8 个应用模型:OpenPose、Canny、HED、Scribble、Mlsd、Seg、Normal Map、Depth。以下做简要介绍:
OpenPose 姿势识别
通过姿势识别,达到精准控制人体动作。除了生成单人的姿势,它还可以生成多人的姿势,此外还有手部骨骼模型,解决手部绘图不精准问题。以下图为例:左侧为参考图像,经 OpenPose 精准识别后,得出中间的骨骼姿势,再用文生图功能,描述主体内容、场景细节和画风后,就能得到一张同样姿势,但风格完全不同的图。

Canny 边缘检测
Canny 模型可以根据边缘检测,从原始图片中提取线稿,再根据提示词,来生成同样构图的画面,也可以用来给线稿上色。

HED 边缘检测
跟 Canny 类似,但自由发挥程度更高。HED 边界保留了输入图像中的细节,绘制的人物明暗对比明显,轮廓感更强,适合在保持原来构图的基础上对画面风格进行改变时使用。

Scribble 黑白稿提取
涂鸦成图,比 HED 和 Canny 的自由发挥程度更高,也可以用于对手绘线稿进行着色处理。

Mlsd 直线检测
通过分析图片的线条结构和几何形状来构建出建筑外框,适合建筑设计的使用。

Seg 区块标注
通过对原图内容进行语义分割,可以区分画面色块,适用于大场景的画风更改。

Normal Map 法线贴图
适用于三维立体图,通过提取用户输入图片中的 3D 物体的法线向量,以法线为参考绘制出一副新图,此图与原图的光影效果完全相同。

Depth 深度检测
通过提取原始图片中的深度信息,可以生成具有同样深度结构的图。还可以通过 3D 建模软件直接搭建出一个简单的场景,再用 Depth 模型渲染出图。

ControlNet 还有项关键技术是可以开启多个 ControlNet 的组合使用,对图像进行多条件控制。例如:你想对一张图像的背景和人物姿态分别进行控制,那我们可以配置 2 个 ControlNet,第 1 个 ControlNet 使用 Depth 模型对背景进行结构提取并重新风格化,第 2 个 ControlNet 使用 OpenPose 模型对人物进行姿态控制。此外在保持 Seed 种子数相同的情况下,固定出画面结构和风格,然后定义人物不同姿态,渲染后进行多帧图像拼接,就能生成一段动画。
以上通过 ControlNet 的 8 个主要模型,我们解决了图像结构的控制问题。接下来就是对图像风格进行控制。
3. 图像风格控制
Stable Diffusion 实现图像风格化的途径主要有以下几种:Artist 艺术家风格、Checkpoint 预训练大模型、LoRA 微调模型、Textual Inversion 文本反转模型。

Artist 艺术家风格
主要通过画作种类 Tag(如:oil painting、ink painting、comic、illustration),画家/画风 Tag(如:Hayao Miyazaki、Cyberpunk)等控制图像风格。网上也有比较多的这类风格介绍,如:
- https://promptomania.com
- https://www.urania.ai/top-sd-artists
但需要注意的是,使用艺术家未经允许的风格进行商用,会存在侵权问题。

Checkpoint 预训练大模型
Checkpoint 是根据特定风格训练的大模型,模型风格强大,但体积也较大,一般 5-7GB。模型训练难度大,需要极高的显卡算力。目前网上已经有非常多的不同风格的成熟大模型可供下载使用。如:https://huggingface.co/models?pipeline_tag=text-to-image

LoRA 微调模型
LoRA 模型是通过截取大模型的某一特定部分生成的小模型,虽然不如大模型的能力完整,但短小精悍。因为训练方向明确,所以在生成特定内容的情况下,效果会更好。LoRA 模型也常用于训练自有风格模型,具有训练速度快,模型大小适中,配置要求低(8G 显存)的特点,能用少量图片训练出风格效果。常用 LoRA 模型下载地址:
- https://stableres.info
- https//civitai.com(友情提醒:不要在办公场所打开,不然会很尴尬)

Textual Inversion 文本反转模型
Textual Inversion 文本反转模型也是微调模型的一种,它是针对一个风格或一个主题训练的风格模型,一般用于提高人物还原度或优化画风,用这种方式生成的模型非常小,一般几十 KB,在生成画作时使用对应 Tag 在 prompt 中进行调用。

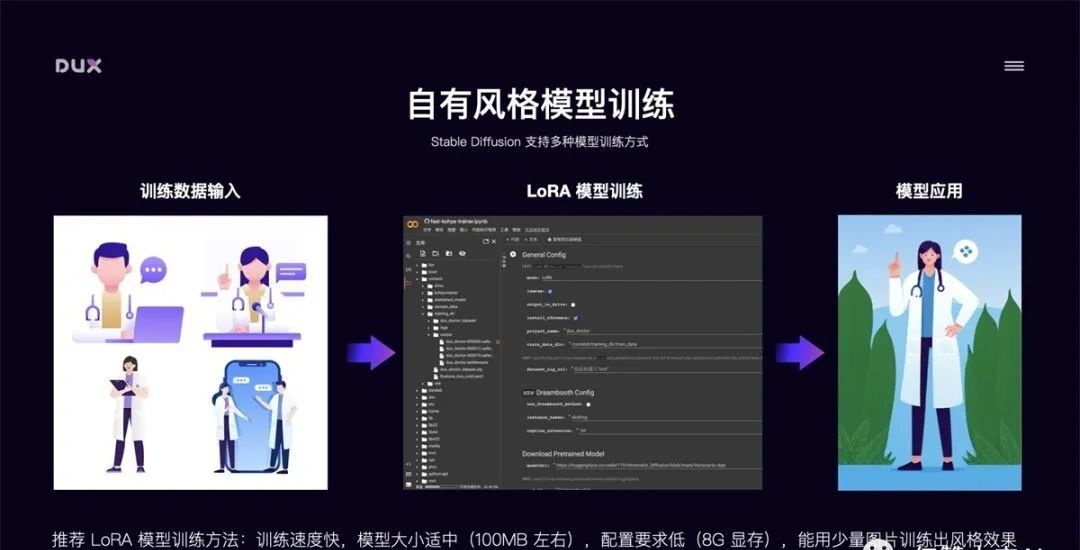
自有风格模型训练
Stable Diffusion 的强大之处还在于能够自定义训练风格模型,如果现有风格无法满足要求,我们还可以自己训练特定风格模型。Stable Diffusion 支持训练大模型和微调模型。我比较推荐的是用 LoRA 模型训练方法,该方法训练速度快,模型大小适中(100MB 左右),配置要求低(8G 显存),能用极少量图片训练出风格效果。例如:下图中我用了 10 张工作中的素材图,大概花了 20 分钟时间训练出该风格的 LoRA 模型,然后使用该模型就可以生成风格类似的图片。如果将训练样本量增大,那么训练出来的风格样式会更加精确。
了解了 Stable Diffusion 能干什么后,再来介绍下如何部署安装使用它。
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
👉[[CSDN大礼包:《StableDiffusion安装包&AI绘画入门学习资料》免费分享]](安全链接,放心点击)
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
零基础AI绘画学习资源介绍
👉stable diffusion新手0基础入门PDF👈
(全套教程文末领取哈)

👉AI绘画必备工具👈

👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉大厂AIGC实战案例👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉12000+AI关键词大合集👈

这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
















 912
912











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









