









用过Stable Diffusion生成图片的小伙伴可能会发现,很多时候我们一眼就能看出图片就是AI生成的。 那有什么办法可以让生成的图片更加写实呢?
今天,我给大家安利一个皮肤质感调节神器。
话不多说,我们先来看看效果:
生成效果

(图片由AI生成,请谨慎甄别)
左图是处理前,右图是处理后,写实效果提升了不少,细节也提升了不少,那么具体是怎么做到,请接着往下看。
所需模型
一、【*Stable Diffusion 模型*】majicMIX realistic麦橘写实
该模型来自作者“麦橘MAJIC”提供,根据模型名字可知,这是一个写实风格的模型。
下载后,存放在:\models\Stable-diffusion 文件夹中。
二、【Lora 模型】林鹤-皮肤质感调整器-差异炼丹功能性lora模型
该模型来自作者“林鹤_AIGC”提供,根据作者描述,该lora 模型有以下效果:
- 拒绝ai塑胶感,拒绝强曝光。
- 增加皮肤肌理,质感增强,同时柔化光源!
下载后,存放在:\models\Lora 文件夹中。
上述两个步骤完成后,需要重启SD,确保模型生效。
步骤说明
一 、文生图
首先,输入一下关键词:
a girl,realistic
接着来到参数部分,采样方法选择 DPM++ SDE Karras ,迭代步数改为 30 ,高度改为 768,总批次数改为 3,这样可以一次跑三张图出来。
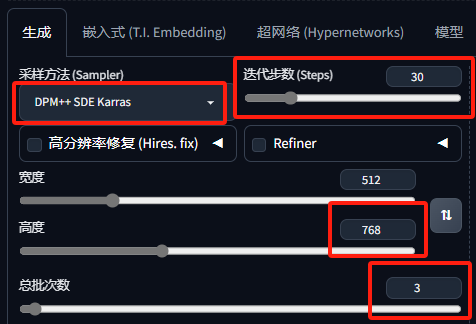
接着我们开启 Adetailer 面部修复,点击 启动After Detailer,模型选择 face_yolov8n.pt。最后点击生成,这里可以看出已经生成三张出来了。

(图片由AI生成,请谨慎甄别)
二 、加上皮肤质感
接着我们在同样的数据上加上皮肤质感,首先先选择Lora模型,并且把权重调低一点,改为0.8。
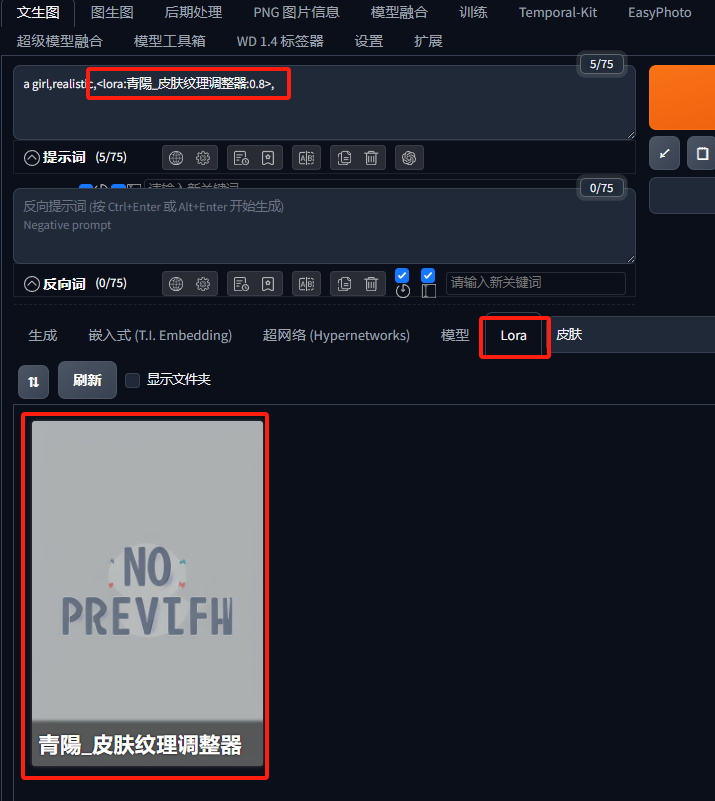
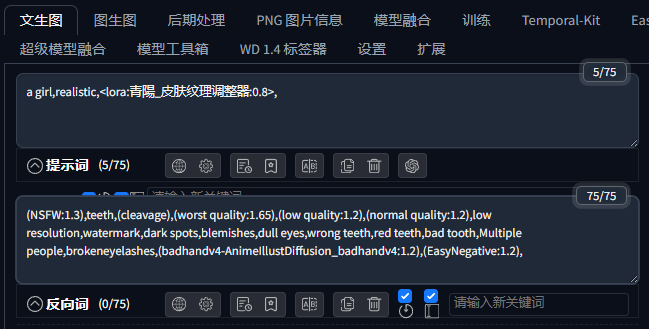
根据模型作者的推荐,填入以下负面词:
(NSFW:1.3),teeth,(cleavage),(worst quality:1.65),(low quality:1.2),(normal quality:1.2),low resolution,watermark,dark spots,blemishes,dull eyes,wrong teeth,red teeth,bad tooth,Multiple people,brokeneyelashes,(badhandv4-AnimeIllustDiffusion_badhandv4:1.2),(EasyNegative:1.2),
来到参数部分,我们先固定一下随机数种子,点击绿色按钮即可。

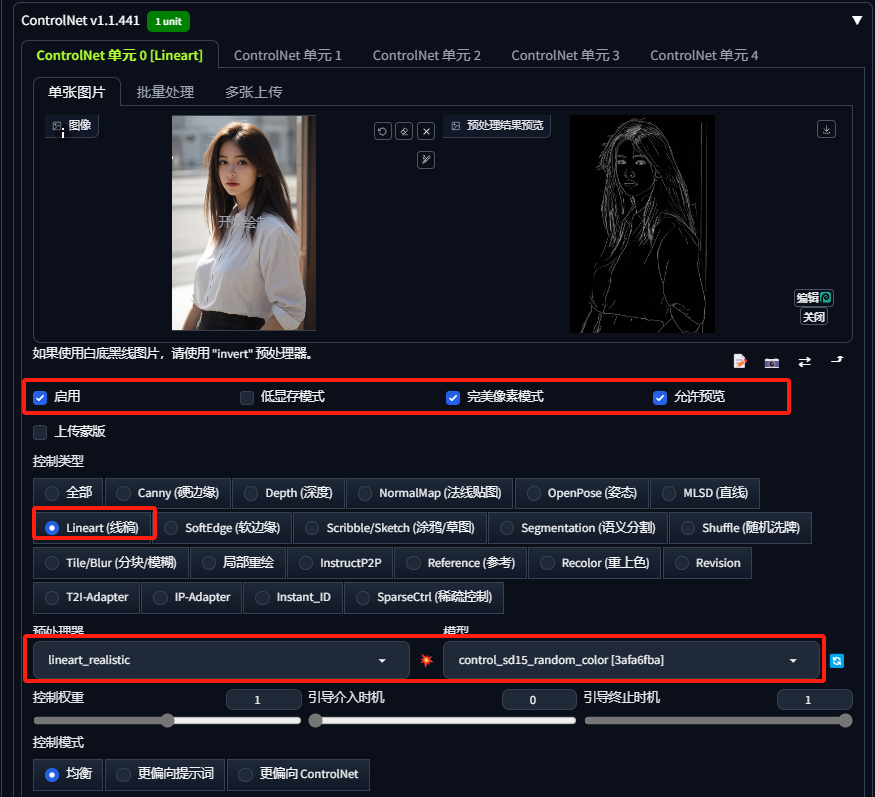
接下来找到 ControNet ,上传一张我们刚选中的一张图片,勾选完美像素模式、允许预览,控制类型选择Lineart(线稿),预处理器选择lineart_realistic。做这一步的目的是为了等一下生成出来的图和我们这张图有高度的相似度。
最后点击生成,下方就是生成出来的三张图片了。

(图片由AI生成,请谨慎甄别)
三、效果对比
从对比图可以看出,无论在皮肤的肌理还是在光感上,都自然柔和了很多。脸部的立体感有了很大的增强。效果嘎嘎好~

(图片由AI生成,请谨慎甄别)
总结
总体来说,有了这款皮肤质感的Lora模型,生成出来的图片确实要花费更长的时间去鉴别是否来自AI生成。整体也简单易用。
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
需要的可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

1.stable diffusion安装包 (全套教程文末领取哈)
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】















 1136
1136

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









