






IPAdapter 是用于图像到图像调节的非常强大的模型。主题甚至参考图像的风格都可以很容易地转移,可以将其视为一张图像的 lora。
安装
使用 Comfyuimanager 或者使用命令行
进入 custom_nodes 目录
git clone https://github.com/cubiq/ComfyUI_IPAdapter_plus.git
这份完整版的comfyui资料包已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

重启 comfyui
Ipadaper 基本原理
IP-Adapter 提供了一种独特的方法来控制图像和视频的生成。它的工作方式与 ControlNet 不同 - 它不是试图直接引导图像,而是通过**将提供的图像转换为嵌入(embedds)(本质上是一个提示)**并使用它来指导图像的生成。它生成的嵌入在英语中是无法理解的,它可以以文本提示 struggle 的方式详细说明(即,很难描述衬衫上衣领的确切类型或部分张开的嘴的形状)。由于它无需动手,因此可以在保持连贯性的同时进行更重的风格传输。
它依赖于剪辑视觉(clip_vision )模型 - 该模型查看源图像并开始编码 - 这些是其他计算机视觉任务中使用的成熟模型。然后 IPAdapter 模型使用此信息并创建令牌(即提示(prompts))并应用它们。重要的是要知道 Clip Vision 仅使用 512x512 像素 - 因此,如果太小,精细细节仍然会丢失。
简单来说就是使用 clip_vision 模型 将图片转成一种特定的 prompt 结合我们输入的 prompt 共同作用生成
相关模型
clip_vision模型
存放地址 ``
/ComfyUI/models/clip_vision
- CLIP-ViT-H-14-laion2B-s32B-b79K.safetensor
- CLIP-ViT-bigG-14-laion2B-39B-b160k.safetensors
- clip-vit-large-patch14-336.bin, 仅适用于 Kolors 模型
Ipadapter 模型
存放地址 ``
/ComfyUI/models/ipadapter
- ip-adapter_sd15.safetensors,基础模型,平均强度
- ip-adapter_sd15_light_v11.bin,强度较弱
- ip-adapter-plus_sd15.safetensors,Plus 模型,非常强大,也最常用
- ip-adapter-plus-face_sd15.safetensors、人脸模型、肖像
- ip-adapter-full-face_sd15.safetensors,更强的面部模型,不一定更好
- ip-adapter_sd15_vit-G.safetensors,基本模型,需要 bigG clip 视觉编码器,即
CLIP-ViT-bigG-14-laion2B-39B-b160k.safetensors - ip-adapter_sdxl_vit-h.safetensors,SDXL 模型
- ip-adapter-plus_sdxl_vit-h.safetensors,SDXL plus 模型
- ip-adapter-plus-face_sdxl_vit-h.safetensors,SDXL 人脸模型
- ip-adapter_sdxl.safetensors,vit-G SDXL 模型,需要 bigG clip 视觉编码器, 即
CLIP-ViT-bigG-14-laion2B-39B-b160k.safetensors - ip-adapter_sd15_light.safetensors,v1.0 Light 影响模型,已废弃的
面部模型
- ip-adapter-faceid_sd15.bin 基本 FaceID 模型
- ip-adapter-faceid-plusv2_sd15.bin、FaceID 和 v2
- ip-adapter-faceid-portrait-v11_sd15.bin、肖像的文本提示样式迁移
- ip-adapter-faceid_sdxl.bin、SDXL 基础 FaceID
- ip-adapter-faceid-plusv2_sdxl.bin,SDXL plus v2
- ip-adapter-faceid-portrait_sdxl.bin、SDXL 文本提示样式迁移
- ip-adapter-faceid-portrait_sdxl_unnorm.bin,非常强的风格传输仅限 SDXL
- ip-adapter-faceid-plus_sd15.bin,FaceID plus v1,已弃用的
- ip-adapter-faceid-portrait_sd15.bin,portrait 模型的 v1,已弃用的
面部模型结合使用的 lora
存放地址 ``
/ComfyUI/models/loras
- ip-adapter-faceid_sd15_lora.safetensors
- ip-adapter-faceid-plusv2_sd15_lora.safetensors
- ip-adapter-faceid_sdxl_lora.safetensors, SDXL FaceID LoRA
- ip-adapter-faceid-plusv2_sdxl_lora.safetensors, SDXL plus v2 LoRA
- ip-adapter-faceid-plus_sd15_lora.safetensors,已弃用的 FaceID plus v1 模型的 LoRA
使用案例拆解
风格参考
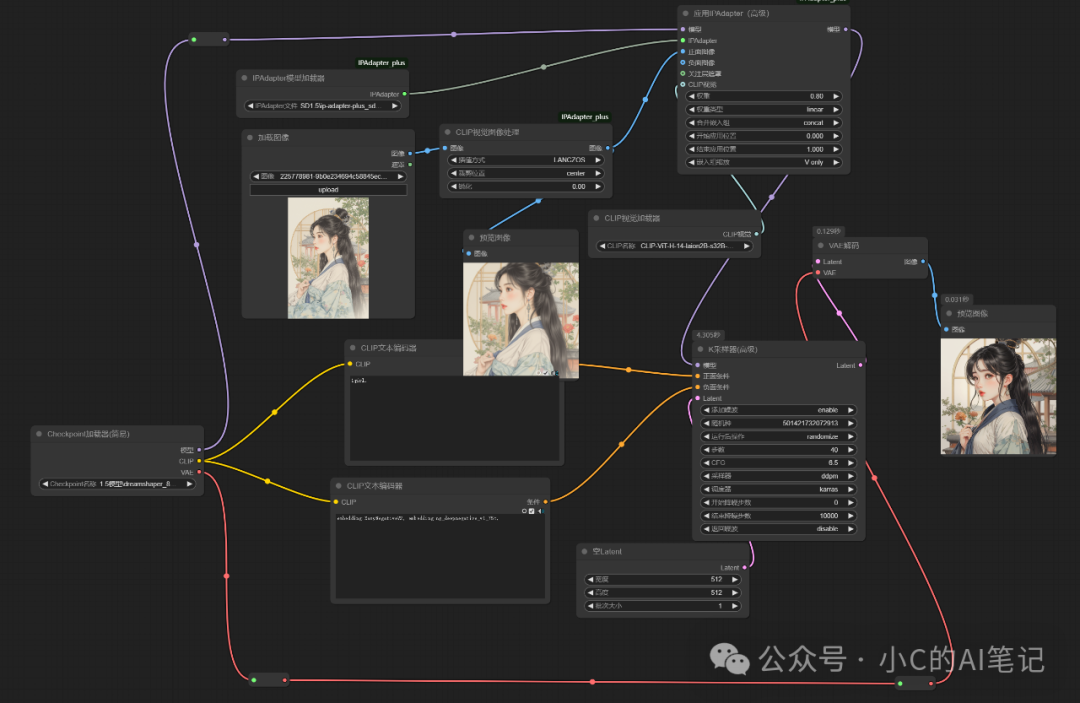
在 model 的路径上加入 Ipadapter 应用;即下图部分 ``
Ipadapter model + clip_version + image => ipadapter
应用进行Ipadapter 应用
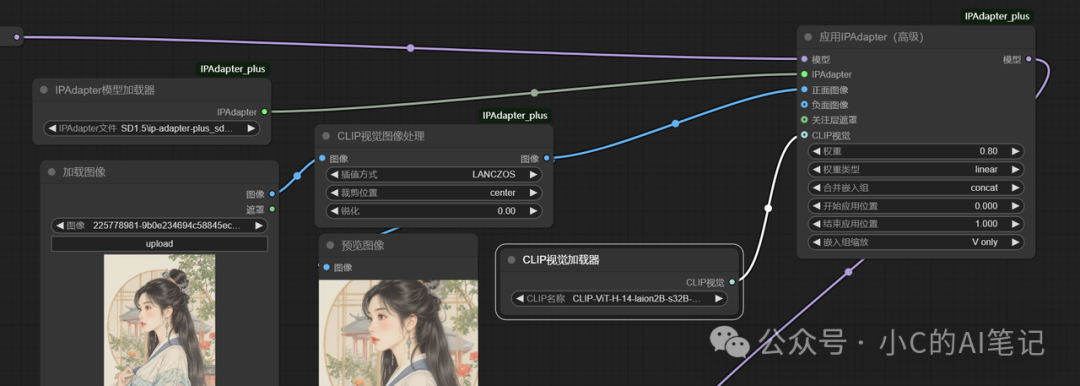
主要节点
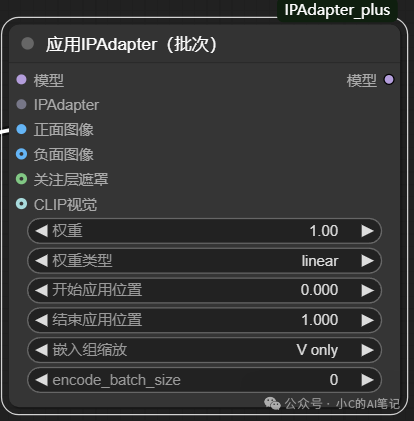
应用IPAdapter(高级)
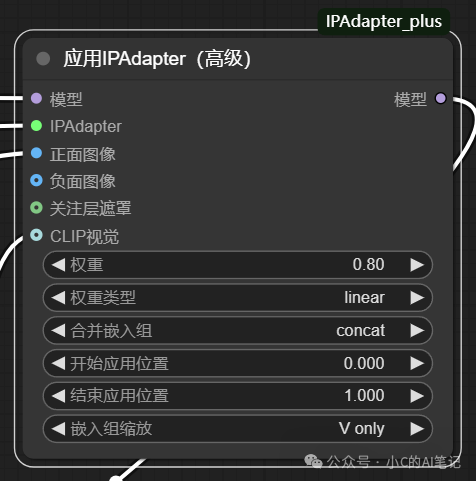
参数 :
-
model : 正常工作流加载的模型;即未使用ipadapter时加载的模型
-
ipadapter : 使用的 ipadapter 模型加载
-
正面图像:需要参考的图像
-
负面图像:需要参考的负面图像;可用于噪声注入,一般为噪点图,通常会带来更好的结果
-
关注层遮罩:即IPA作用的遮罩区域,如果不传就是作用整个图像生成
-
clip 视觉:加载使用的视觉模型
-
权重:ipadapter 的强度,0-1 取值,数值越高,ipa权重越强,参考图片的强度越大
-
权重类型:
-
- liner: 线性强度,从图像生成流程的初始到结束阶段,始终以恒定强度施加参考图的影响;需保持参考图风格或构图稳定性的任务(如产品设计模板化输出)
- ease in (渐强): 在生成初期以较低强度介入,随着生成进度逐步增强参考图的影响 ; 避免初始阶段参考图特征过于突兀,适合需要自然过渡的场景(如背景融合)
- ease out (渐弱): 生成初期以高强度介入,后期逐步减弱参考图影响; 适用于希望保留参考图核心元素但需增加创意变化的场景(如艺术风格化)
- Ease In-Out(渐强-渐弱): 生成初期和末期以较低强度介入,中期达到影响峰值; 平衡生成过程首尾阶段的自由度与中期精准控制,适合复杂构图生成。
- Weak Input (弱化输入阶段) : 降低生成流程早期对参考图的依赖,避免初始特征过度固化; 需保留参考图色彩但重构构图的广告海报设计。
- Weak Output(弱化输出阶段): 减弱生成末期参考图的影响,提升最终细节的原创性; 角色设计需保留基础特征但增加服饰/背景创新
- Weak Middle (弱化中间):在生成中期最小化参考图影响,强调首尾阶段控制
- Strong Middle(强化中间):在生成中期最大化参考图影响,聚焦核心元素强化
- Style Transfer(风格迁移):将参考图的艺术风格迁移至生成图像;
- Composition(构图迁移):重点迁移参考图的元素布局与空间关系,弱化具体细节
- strong Style Transfer(强风格迁移):Style Transfer的加强版
- Style and Composition (风格和构图):风格和构图融合迁移
- Style Transfer Precise(精准风格迁移):在风格迁移基础上增强细节还原度,适用于高精度商业设计;对原始图像的内容要求不高,主要参考其风格
- Composition Precise (精确构图迁移):对风格迁移要求不高,主要参考构图
以下是在使用 PLUS模型的情况下 各个权重类型对应的图片生成,大家可以自己参考下
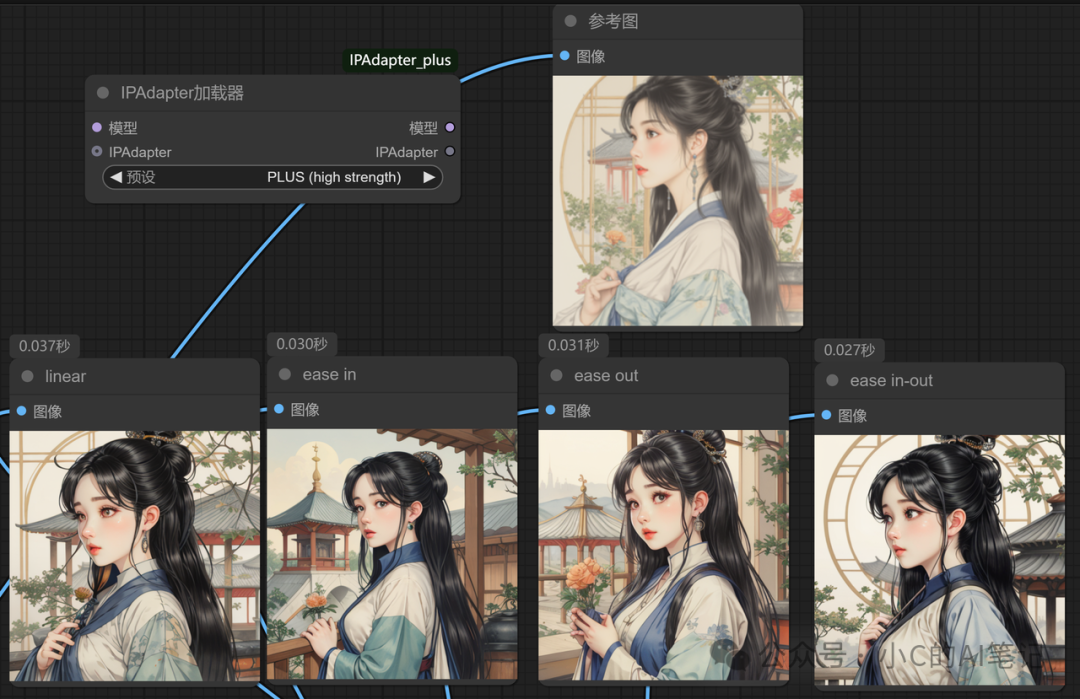
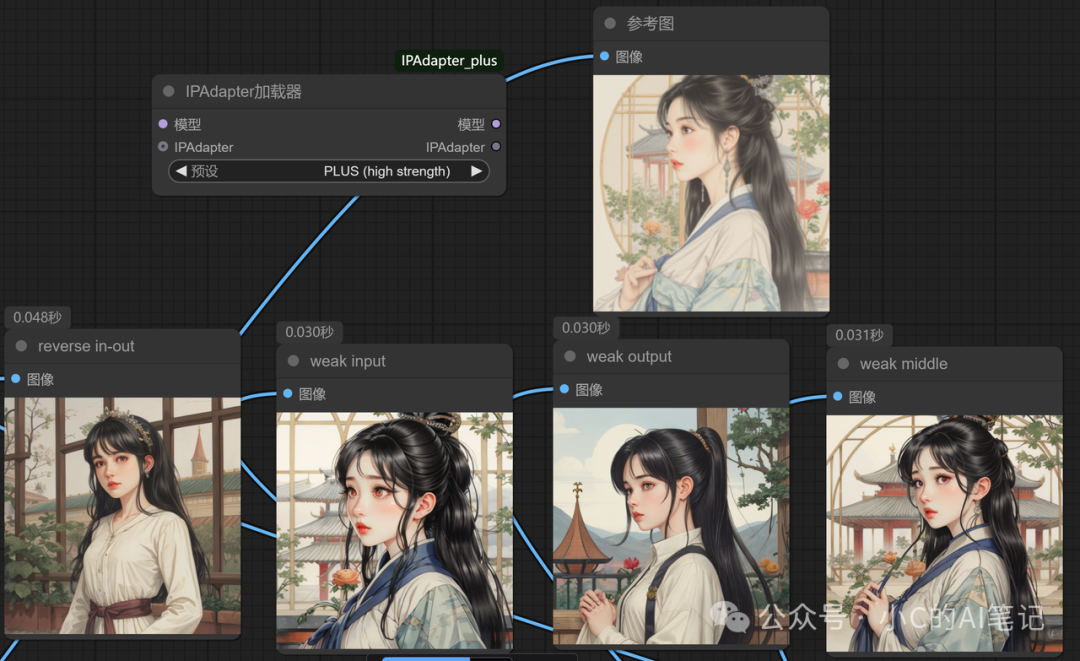
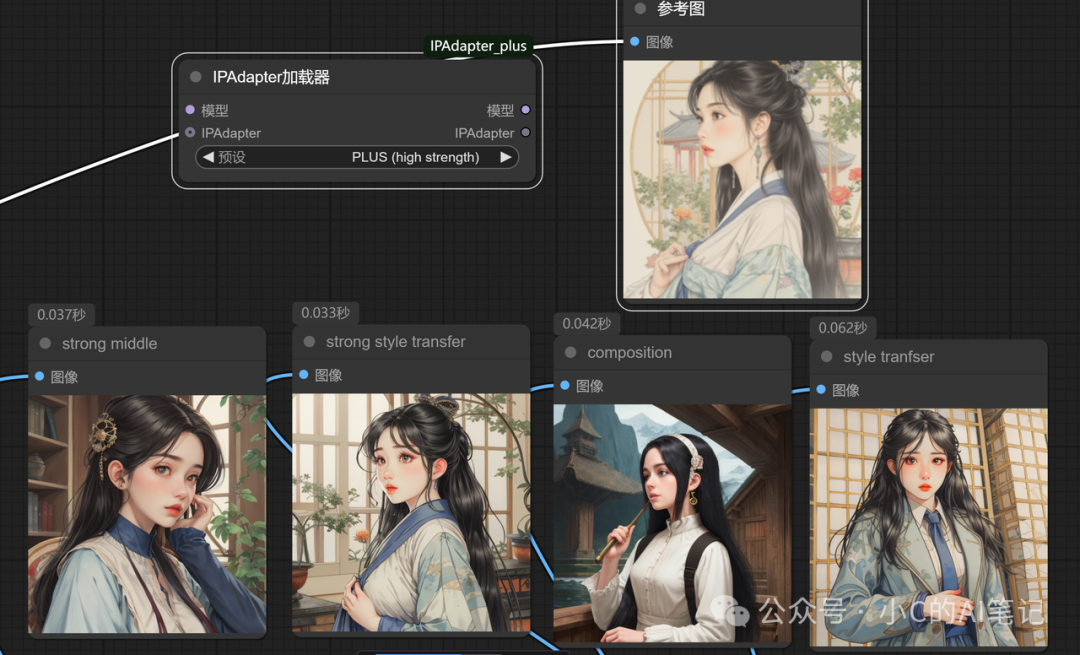
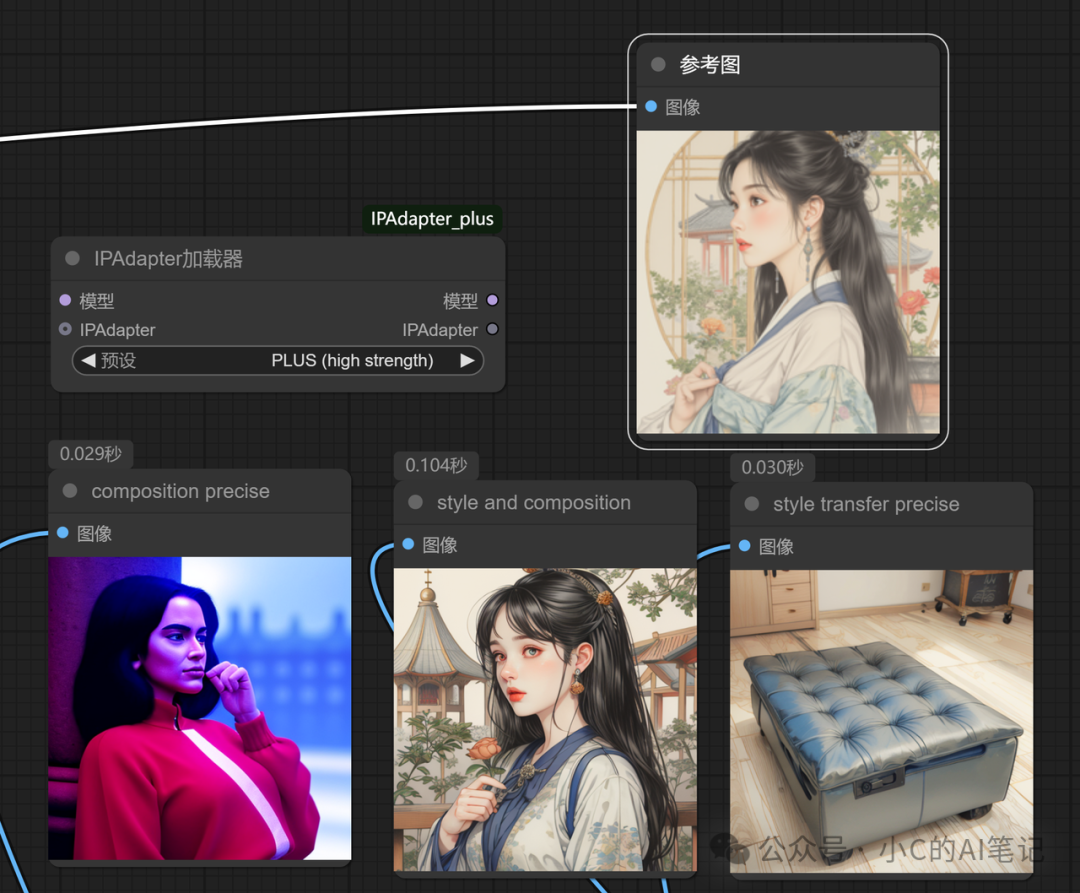
**
**
CLIP视觉图像处理
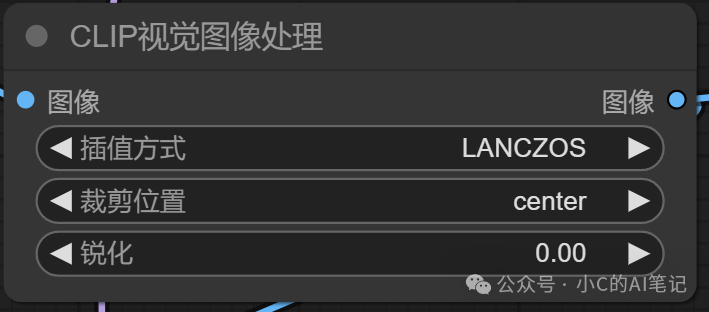
**
**
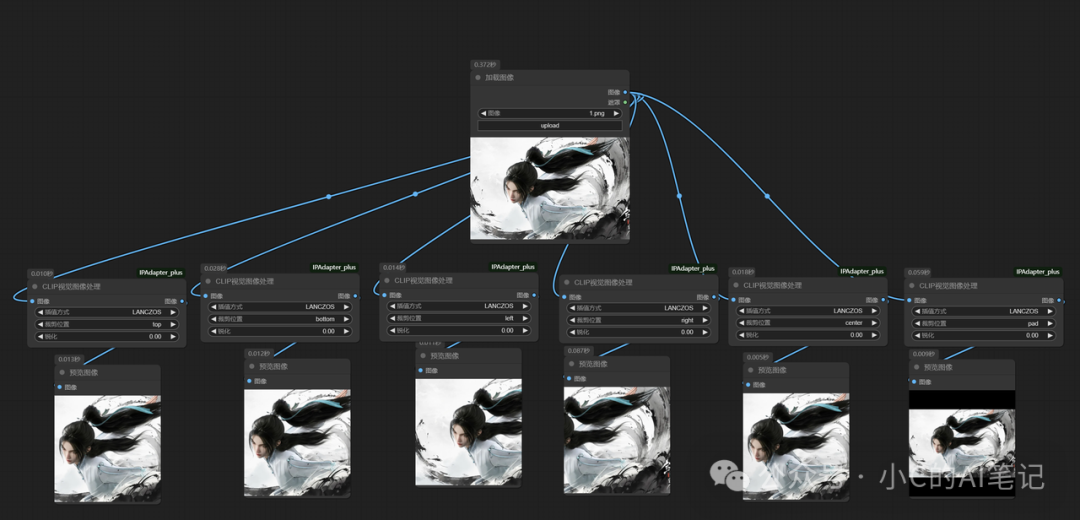
该节点主要的作用为预处理输入的图片;因为Ipadapter 需要输入的图片为正方形的,使用该节点可以对图片进行裁剪处理,同时如果图片效果不太好比如场景比较复杂或者人物占据的位置很小,也可以使用该节点进行处理,使人物的占比更大,ipa更好进行识别;
裁剪位置:
top:裁剪参考图上面部分内容(一般用于竖图)
bottom:裁剪参考图下面部分内容(一般用于竖图)
left:裁剪参考图左边部分内容(一般用于横图)
right:裁剪参考图右边部分内容(一般用于横图,如上图示例)
center:从图片中心位置裁剪周围多余部分
pad:不裁剪,直接通过黑色补齐图像变成正方形,可以参考到整张图像的全部信息
效果如下
**
**
加载 ipadapter 模型
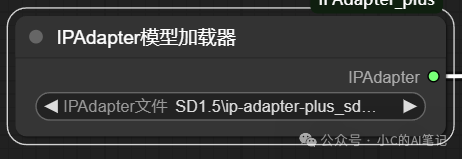
通常风格参考一般使用如下模型,其余的带 face的都和人物面部使用有关
Clip_version 加载
一般使用第一个
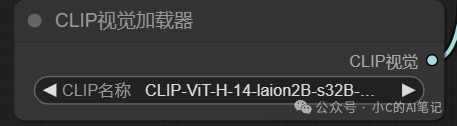
第二个一般配合 vit-G的ipadapter模型使用

其他方式 :
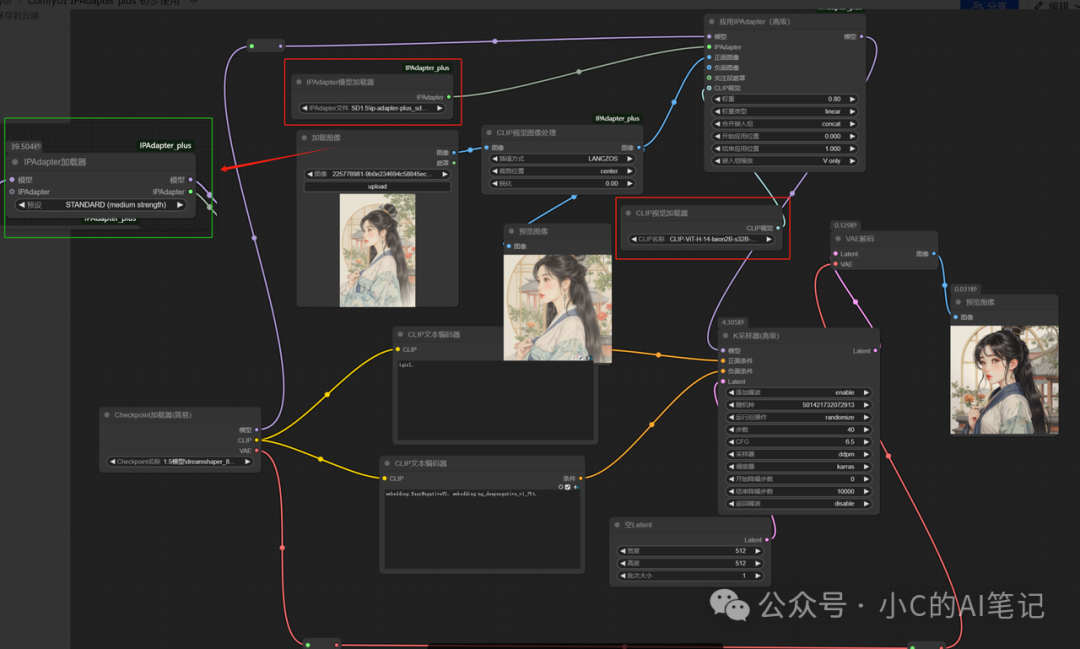
**
**
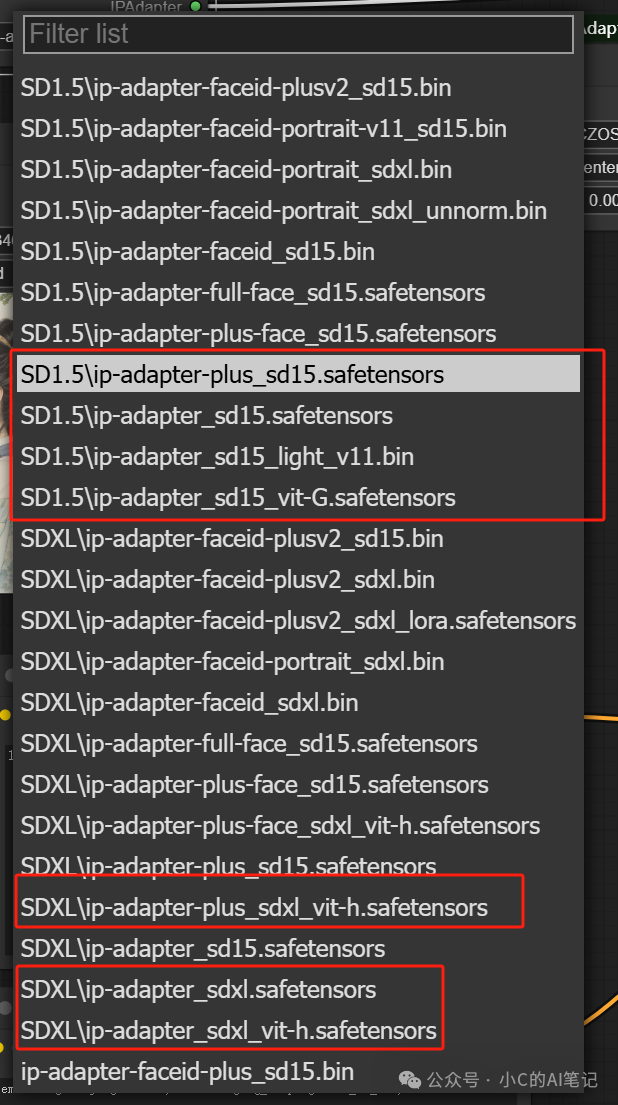
其中红色框框的两个分别加载可以使用绿色框框的统一加载代替
其组合方式为:
| Ipadapter加载器 | Ipadapter模型加载器 | clip视觉加载器 |
|---|---|---|
| PLUS (high strength) | ip-adapter-plus_sd15.safetensors | CLIP-ViT-H-14-laion2B-s32B-b79K.safetensors |
| LIGHT SD1.5 only (low strength) | ip-adapter_sd15_light_v11.bin | CLIP-ViT-H-14-laion2B-s32B-b79K.safetensors |
| STANDARD (medium strength) | ip-adapter_sd15.safetensors | CLIP-ViT-H-14-laion2B-s32B-b79K.safetensors |
| VIT-G(medium strength) | ip-adapter_sd15_vit-G.safetensors | CLIP-ViT-bigG-14-laion2B-39B-b160k.safetensors |
| PLUS FACE (portraits) | ip-adapter-plus-face_sd15.safetensors | CLIP-ViT-H-14-laion2B-s32B-b79K.safetensors |
| FULL FACE SD1.5 only (portraits stronger) | ip-adapter-full-face_sd15.safetensors | CLIP-ViT-H-14-laion2B-s32B-b79K.safetensors |
**
**
Ipadapter加载器效果测试
*脸部模型效果*
**
**
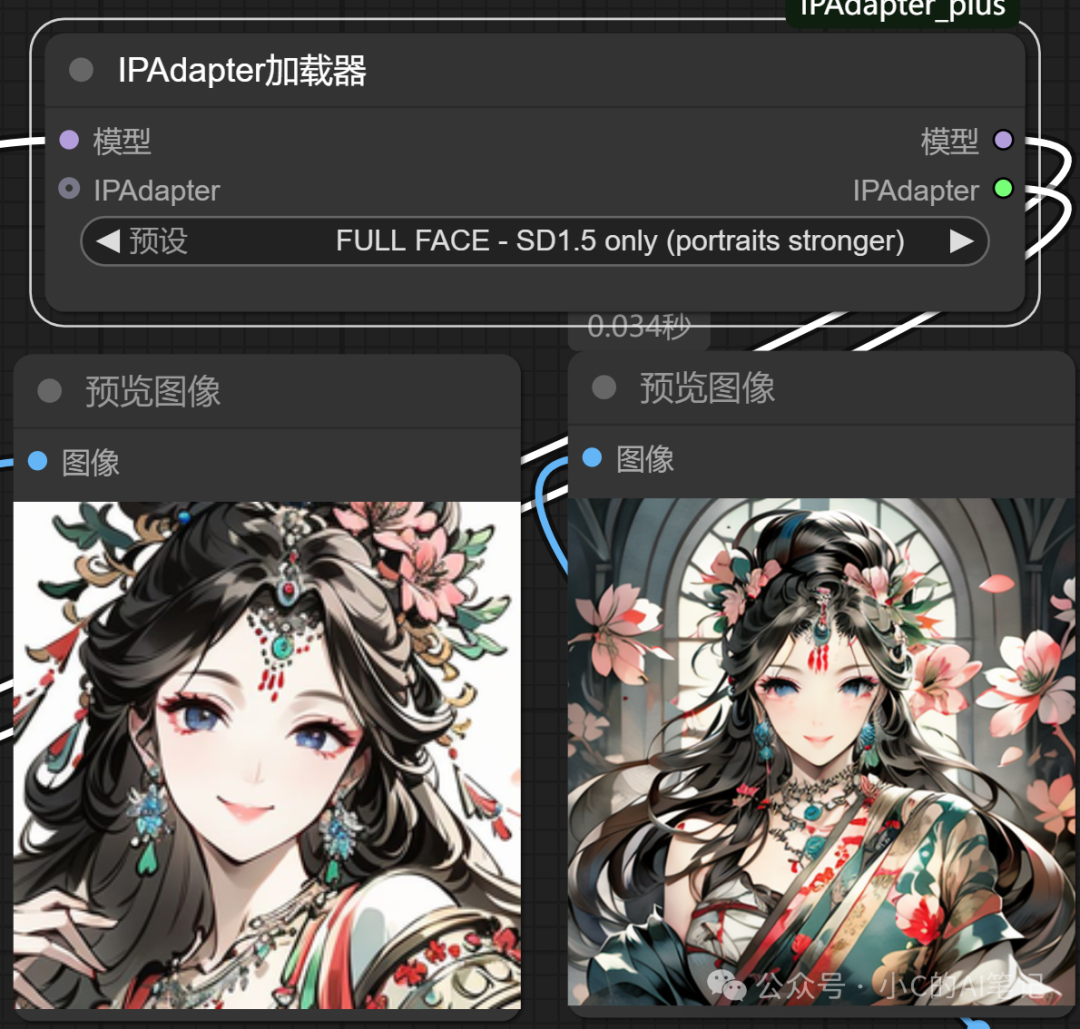
FULL FACE SD1.5 only (portraits stronger)
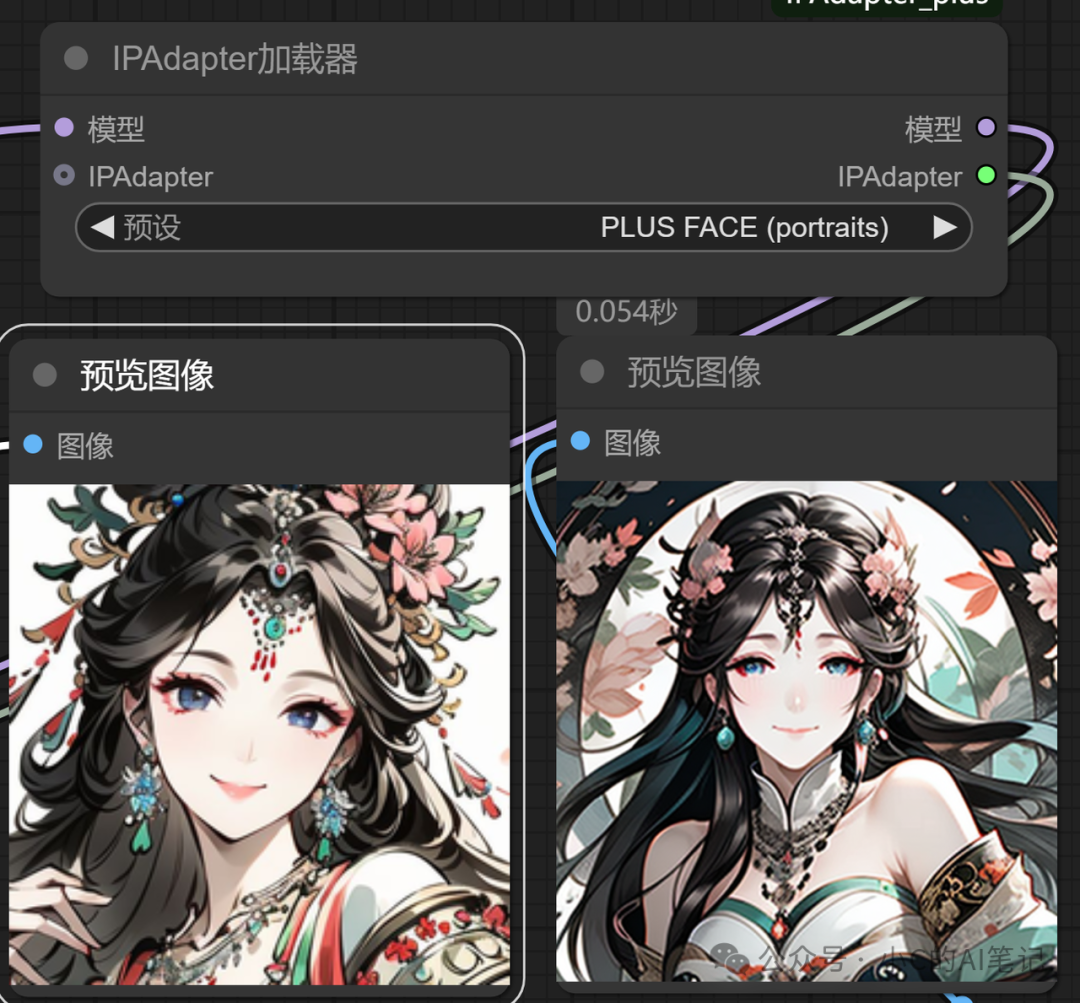
PLUS FACE (portraits)
其他模型效果
PLUS (high strength)
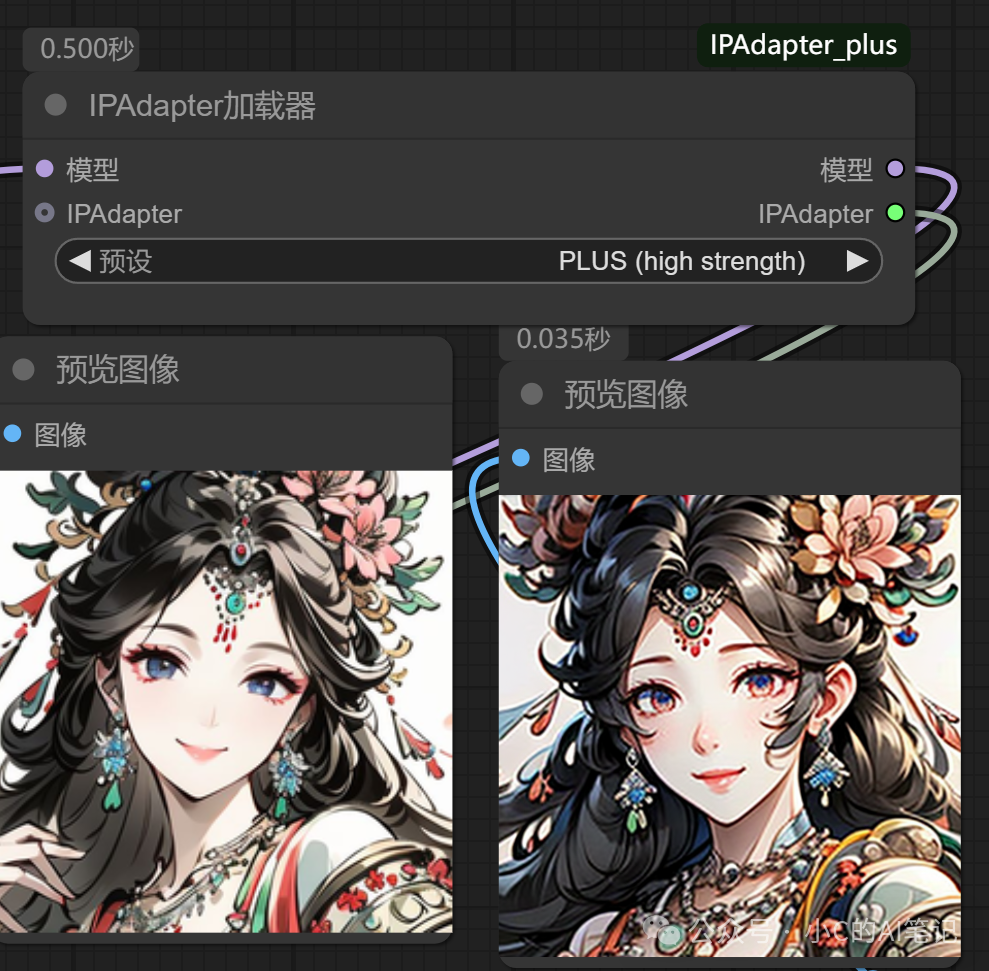
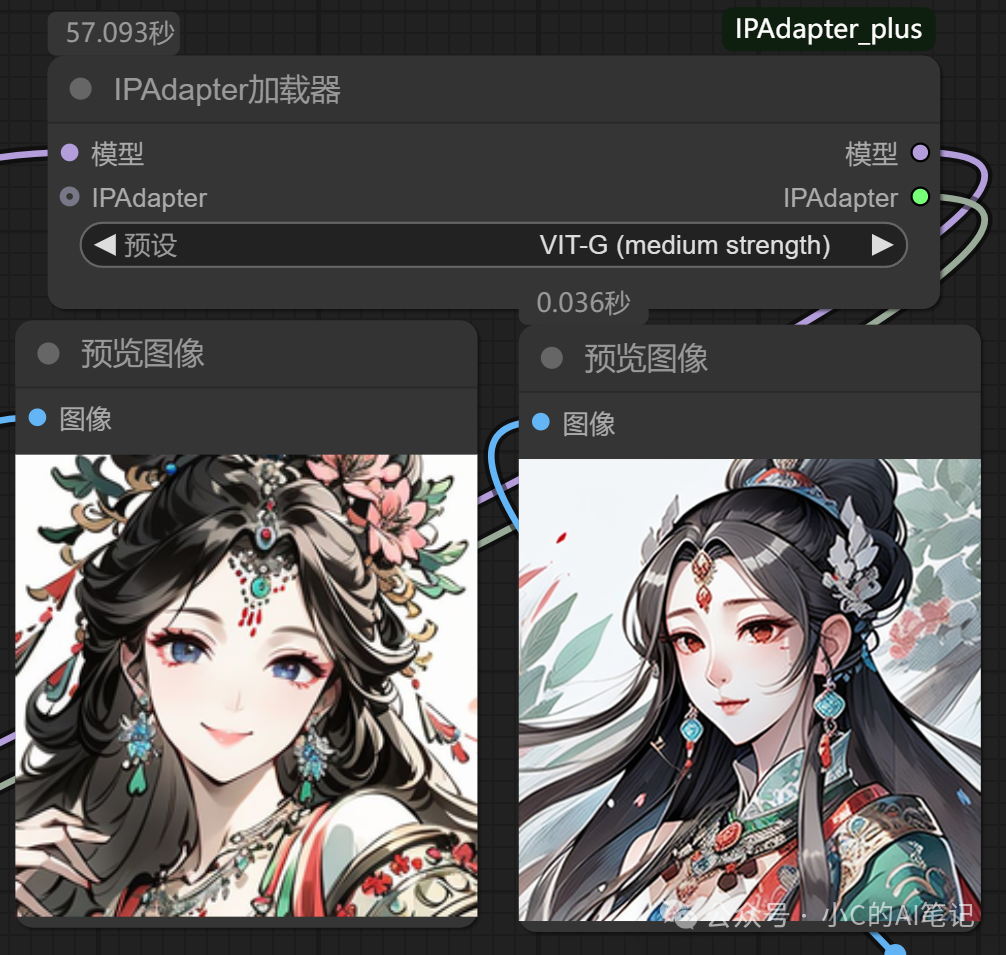
VIT-G(medium strength)
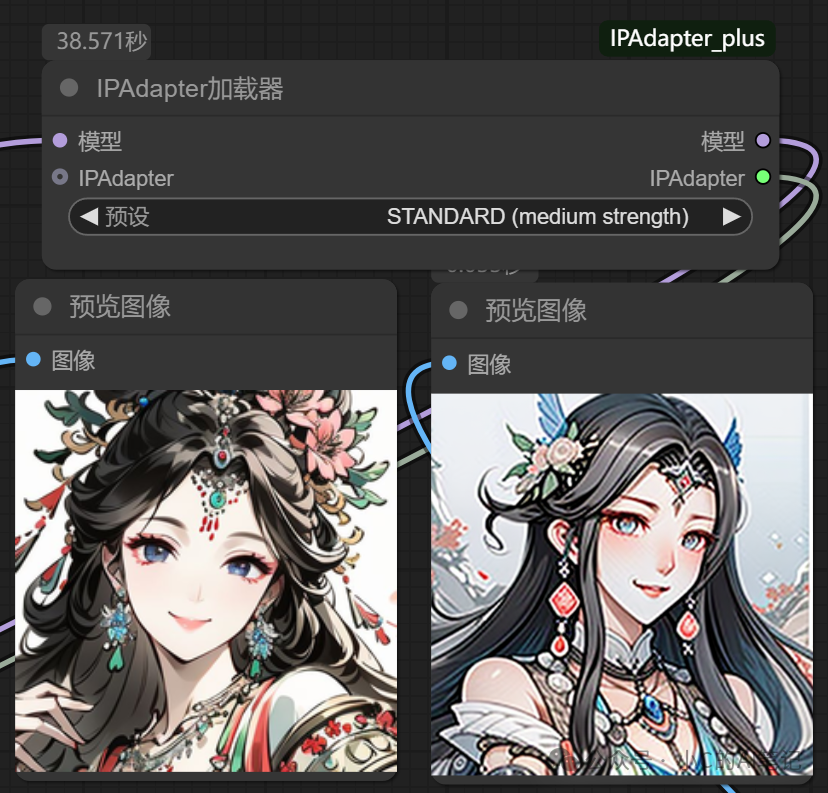
STANDARD (medium strength)
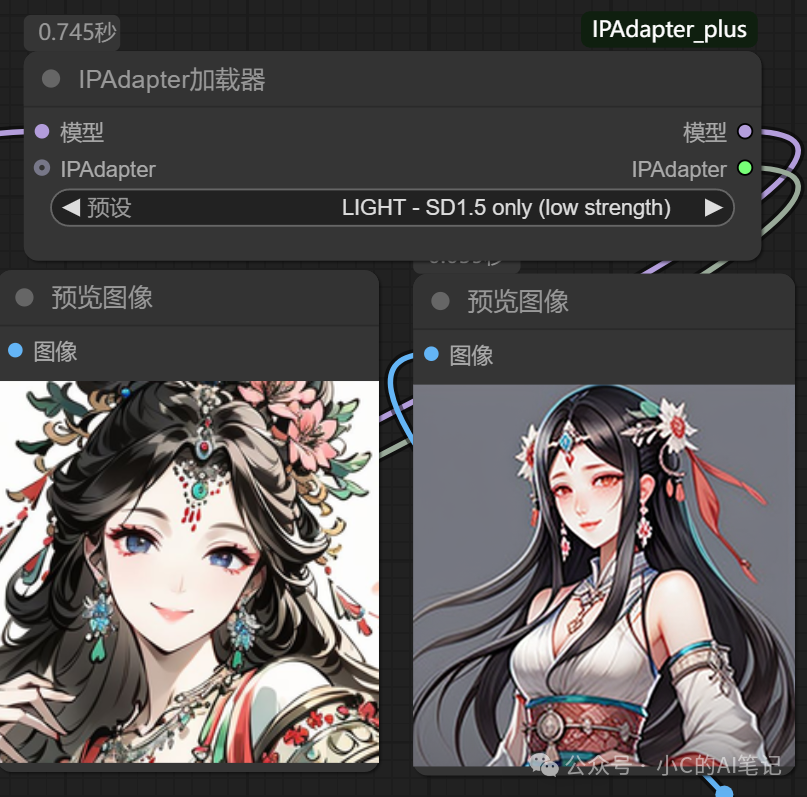
LIGHT SD1.5 only (low strength)
多风格融合
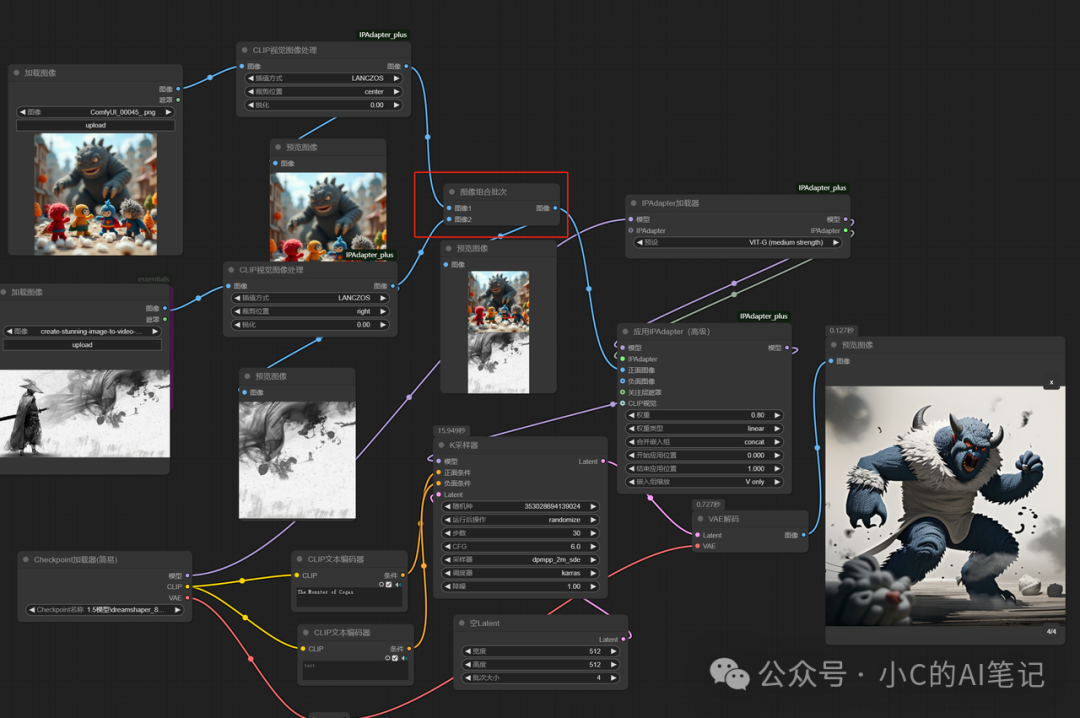
输入两张图片,一张水墨风格,一张针织童话风格,进行图片批次融合 输出图像如下:

区域风格控制
方式一:使用蒙版控制区域图片生成
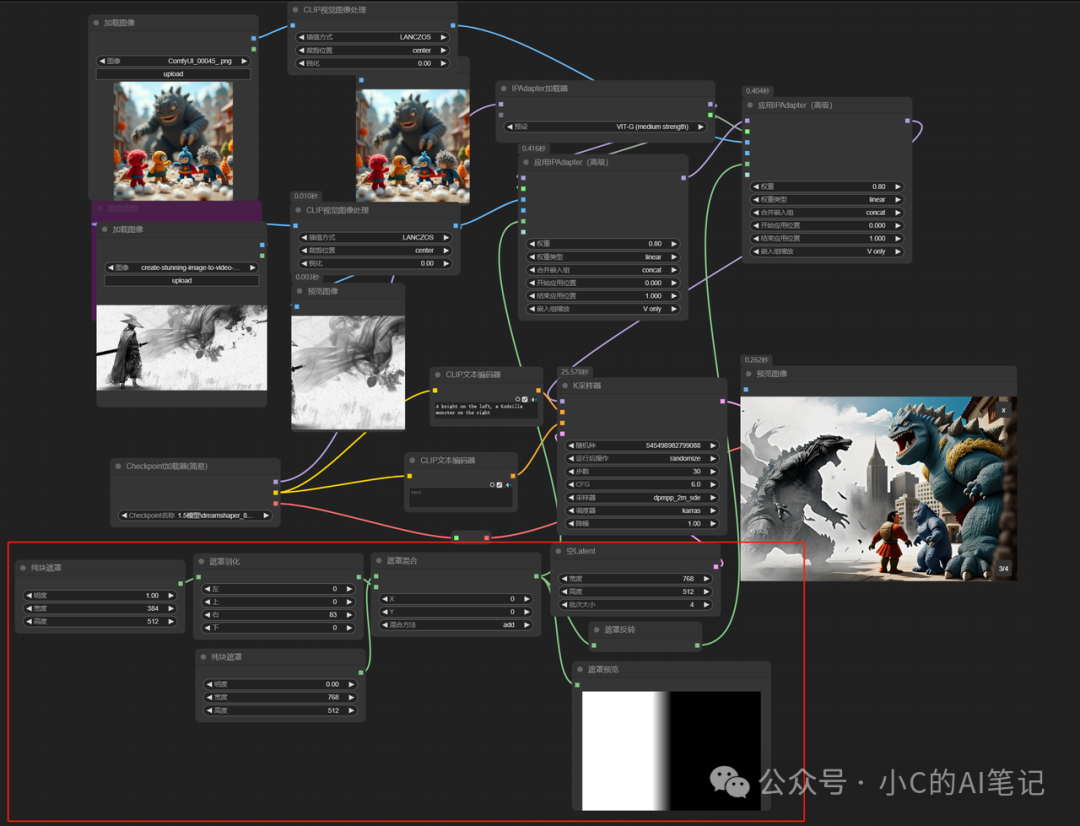
上面的提示词是 “左边一个中国古代武士,右边一个哥斯拉怪兽”;
使用蒙版控制ipadater生效区域实现
这种方式可以控制对应区域的ipa风格,但是没法控制各个区域的提示词;
所以导致生成的区域没有严格遵守提示词要求;
要想提示词也控制可以使用下面这种方式

方式二:IPAdapter区域条件

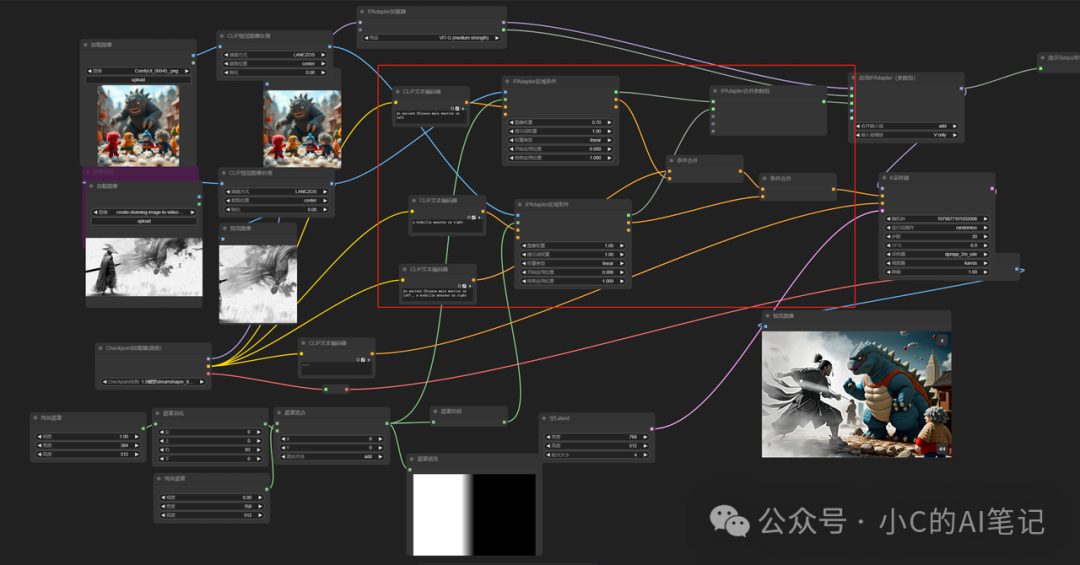
提示词:
总体提示词 : An ancient Chinese male warrior on left , a Godzilla monster on right 提示词1:a Godzilla monster on right 提示词2:An ancient Chinese male warrior on left
生成结果如下

**
**
批次节点使用
我们在上面进行多风格融合的适合使用了多张图像输入,IPA的操作是将两张图的风格进行了融合,如果我们需要分别参考输入图片进行批次风格转绘应该怎么做呢,那就是使用 **应用IPAdapter(批次)**节点
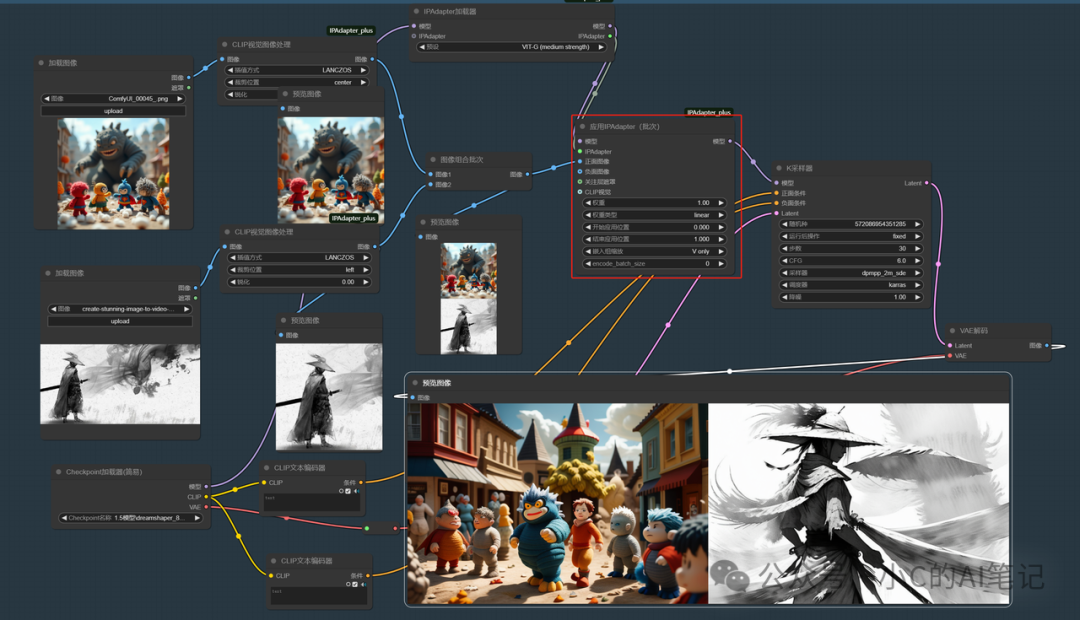
这样我们就得到了输入图片对应风格的多张照片了


IPAdapter编码 + IPAdapter合并嵌入组
这里是 Ipadapter encoder + 嵌入组 embedds 的使用;
Ipadapter encoder 是根据 CLIP视觉加载器 将输入的图片进行识别并编码成 embedds 输入模型当作生图的条件
下图使用了两个 IPAdapter编码 所以使用到了 embedds 合并节点将两个 embedds 进行组合
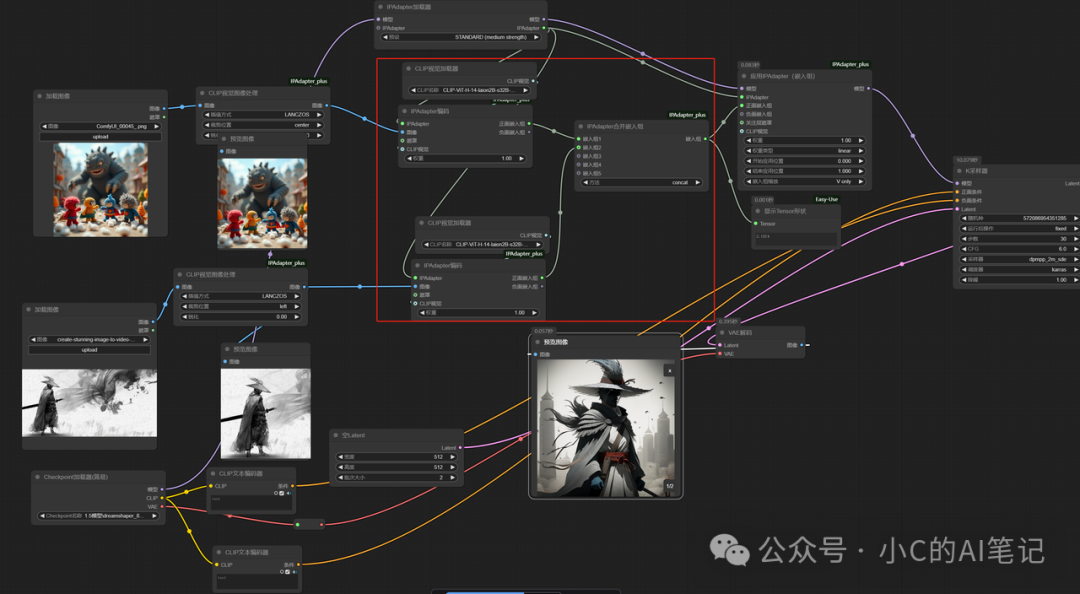
生成的图片则是基于两组embedds融合处理生成的,包含了两组图片的特征

因为使用 CLIP视觉加载器 需要加载模型进行图像识别,如果你觉得本次组合图片效果很好,可以重复使用,我们可以将其保存成embedds,下次使用时直接加载embedds,就不需要再去识别图片,可以节省我们的显存使用
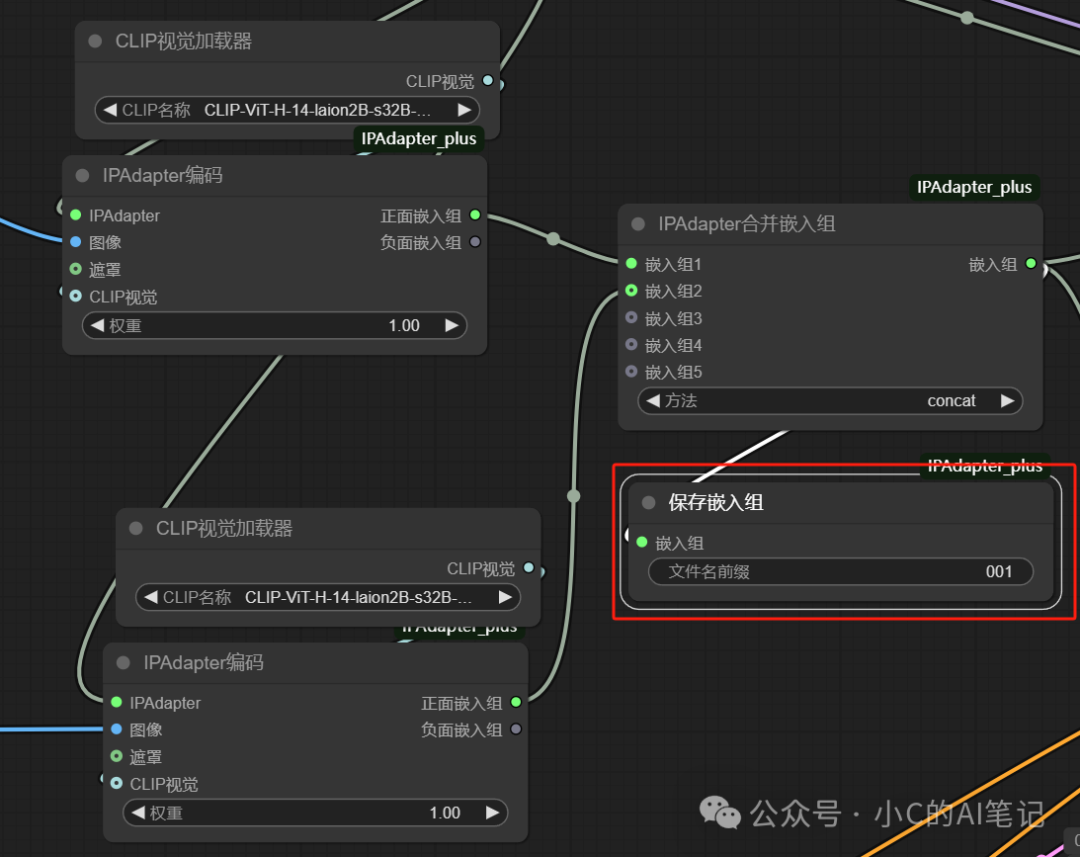
可以在目录
\ComfyUI\output
找到我们保存的embedds,以**.ipadpt** 结尾

我们将其复制到
\ComfyUI\input
目录
读取embedds
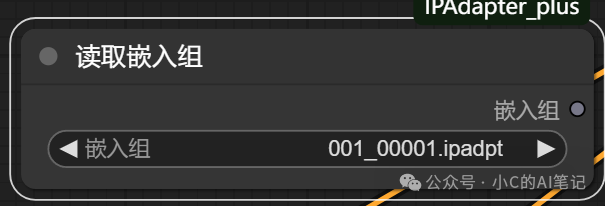
节点加载,如果我无法找到需要刷新页面即可
可以看到生成的结果是一样的
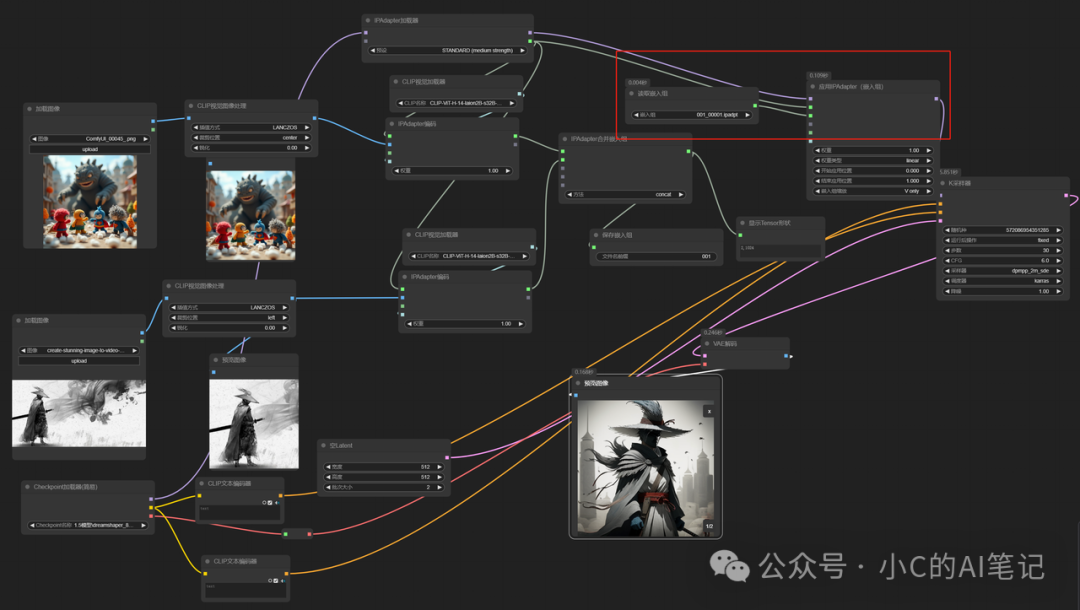
视频生成风格控制
在使用animatediff生成视频时,使用Ipadapter可以控制视频生成的稳定性和风格;当然生成视频的质量和原图的相似度和模型是有关系的;
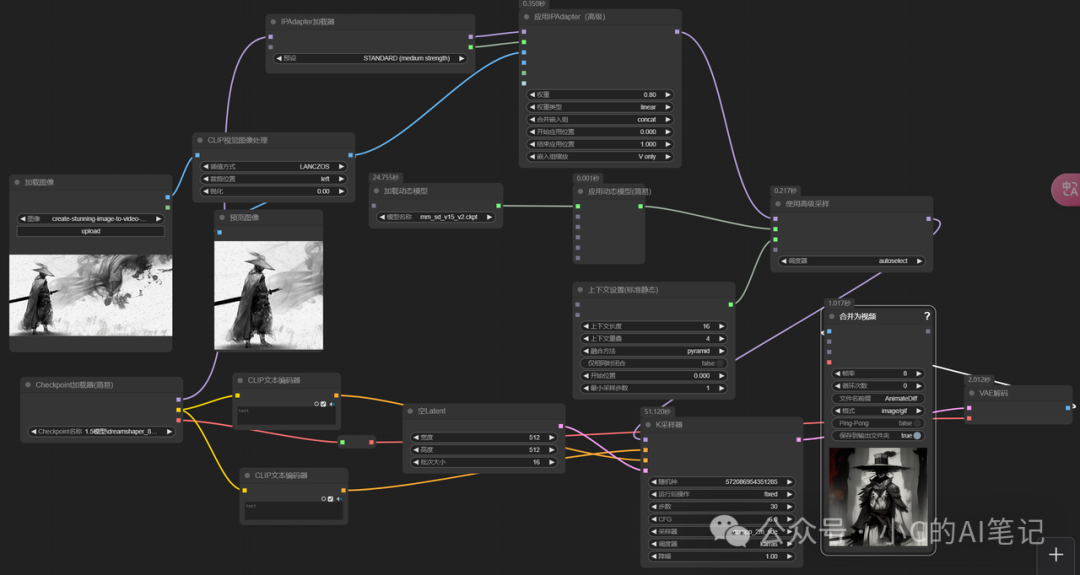
生成的视频: 按顺序分别为参考图,和生成的视频




Ipadapter + Controlnet
使用 Controlnet 进行形状控制,Ipadapter 进行风格转绘, 下面的例子是使用 canny 进行构图固定+Ipadapter进行风格转移
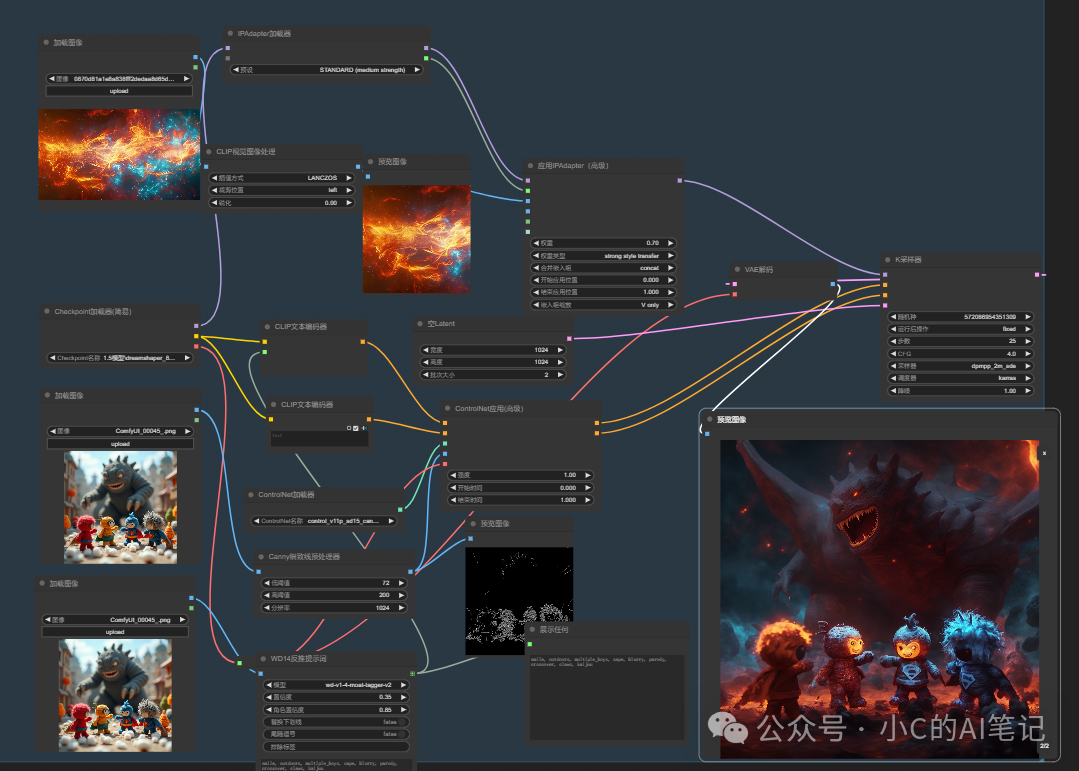
从上到下分别为 Ipadapter参考图,controlnet 控制图,生成的结果图
示例一:



示例二:



ipadapter-风格合成SDXL
这个是基于SDXL模型的选项,如果使用统一加载器即 Ipadapter 加载器,会自动帮我们加载 SDXL 相关的模型,否则的话需要我们自己修改
工作流
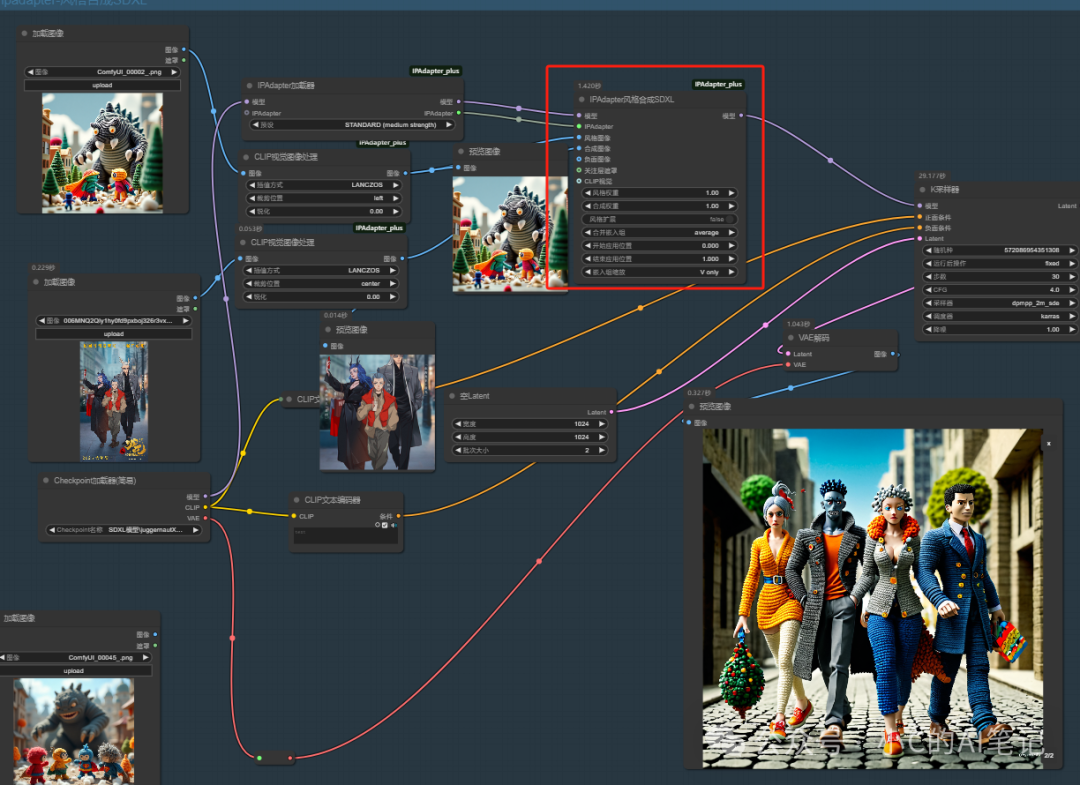
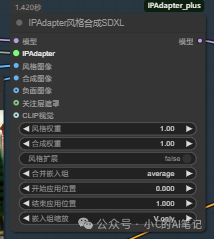
这个节点的作用相当于是一张图像控制风格,一张图像控制图像的大致构图
从上到下分别为风格图像,构图图像,结果图



负面图像
在负面图像加入噪波;我们知道,负面图像的作用是我们不想要的图片信息;如果我们在负面图像加入噪波信息,就意味着我们不想要噪波,那么我们生成的图的质量会更加好
加入噪波图
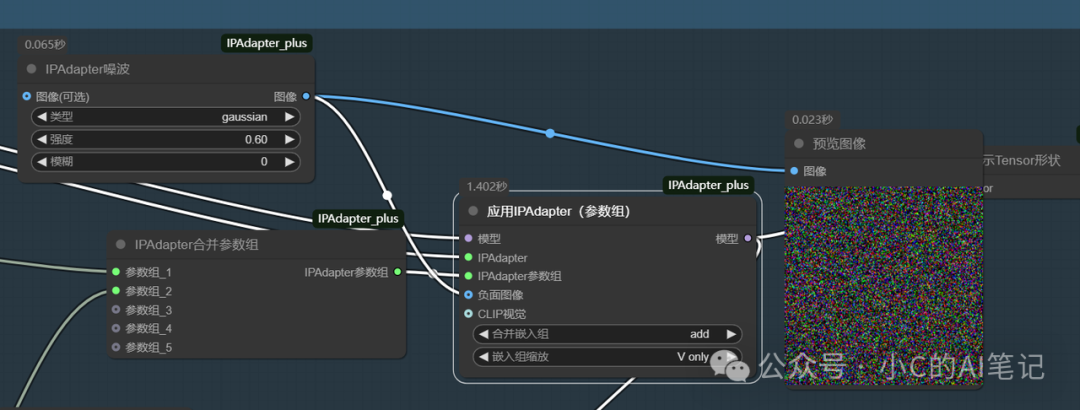
生成的图;我们可以看到明显比上面生成的图质量要好,要更加清晰、(对应IPAdapter区域条件工作流)

【AI绘画视频合集】
这份完整版的comfyui资料我已经打包好,点击下方卡片即可免费领取!
【AI绘画视频合集】
这份完整版的stable diffusion资料我已经打包好,点击下方卡片即可免费领取!
这份完整版的comfyui资料包已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









