






Collection&List
集合类的概述
-
集合类的特点:提供一种存储空间可变的存储模型,存储的数据容量可以随时发生改变。主要就是可以存取数据,并且是容量是可以增长的。
-
集合类的体系图
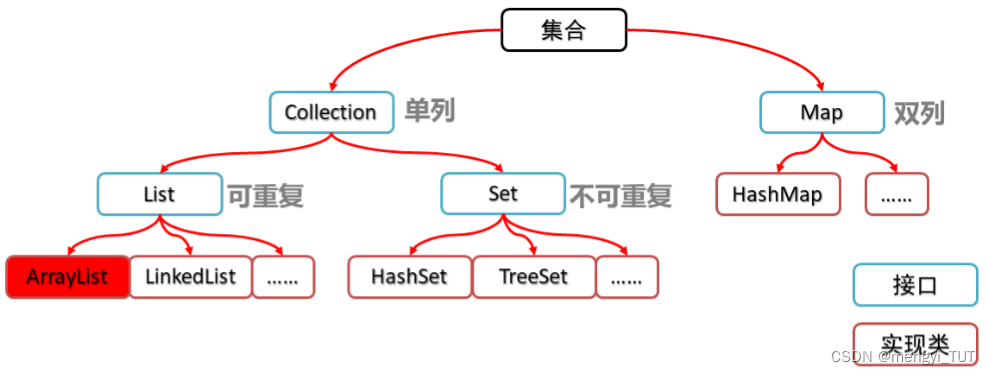
注意:
- 上面的“集合”不是接口也不是实现类,表示Collection和Map及他们的子类,都是属于集合类别的。
- 单列是指,数据存储没有模型是只有值,没有键的;双列表示这个Map的这个集合的模型是两列的,一列是键一列是值,具体可以看下面的这个图,你可以懂我意思的吧。
- 蓝色框框的是表示接口,红色框框表示的是具体的实现类。我们要学这个ArrayList和LinkedList,我们可以先学接口的方法,我们知道接口中的方法的使用和功能,这样我们就知道这个ArrayList和LinkedList的那些实现接口里的那个方法的使用和功能了,这样可以节省我们时间。就是接口提供了一个实现类都需要有的方法,且功能和使用都是确定的,但是子类可以用不同的数据结构来实现他,所以我们学接口的方法的使用就可以节省学他子类的对应的方法的使用了。当然要是想了解源码的话,还是得具体研究具体类的源码的。具体类实现接口的数据结构不同,所以他们做某个操作,比如插入,查找的效率就不同,所以我们需要看这个容器被使用的场景选择对应的容器。
- 我们现在要学的具体类是ArrayList、LinkedList、HashSet、TreeSet、HashMap,其他的比如那个List下面的……我们可以对照ArrayList和LinkedList学习使用。
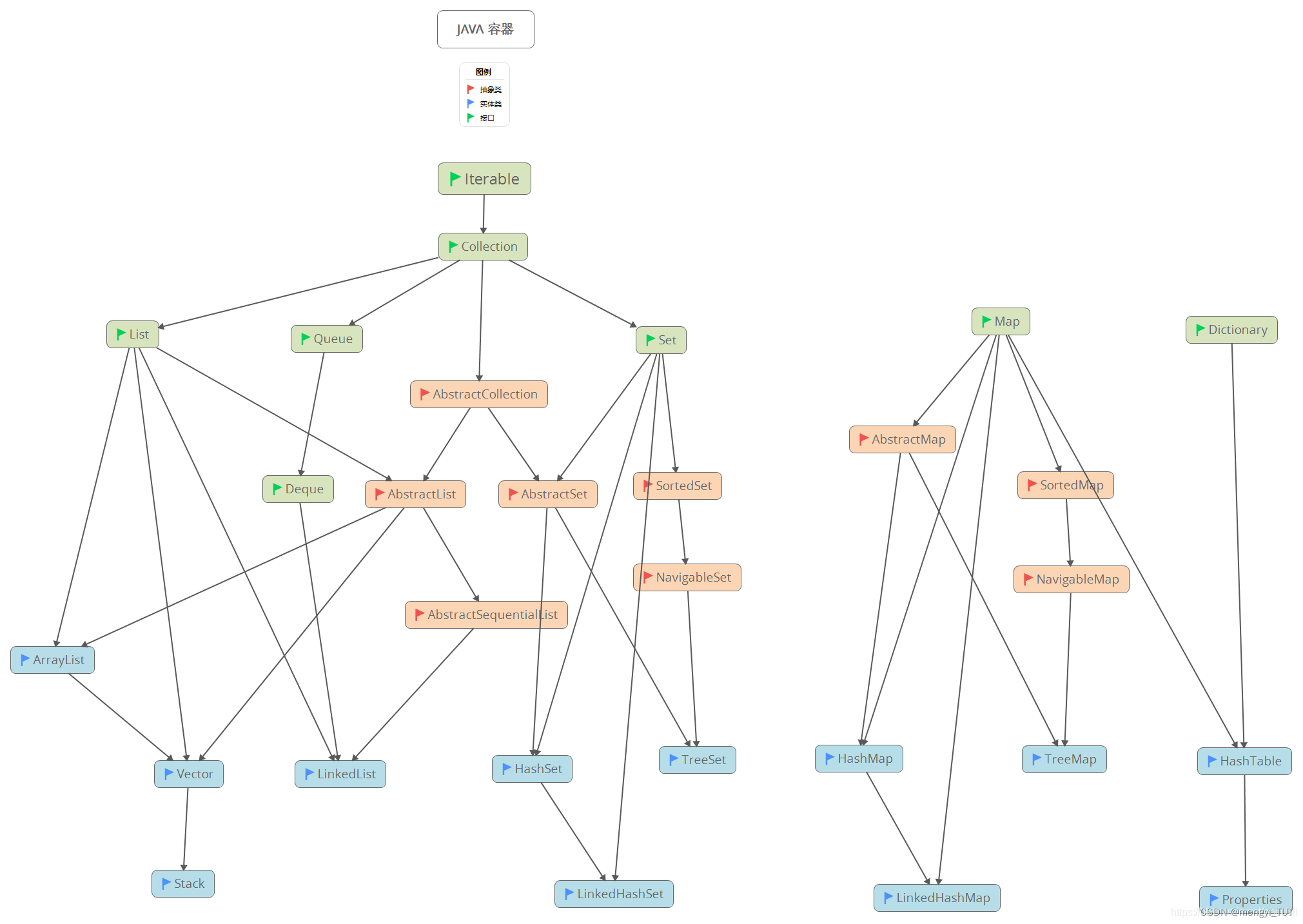
- 上面的这个集合体系图是简化版的。实际上的集合体系图他们的继承关系比这个复杂。
下面是集合体系比较完整的结构图:(集合也叫容器)
Collection
Collection的概述
- 是单列集合的顶层接口。
- 他没有直接的实现类。
Collection集合基本使用
因为Collection没有直接实现类,所以只能用他子接口的具体实现类来创建对象,用多态的形式创建对象
public class CollectionDemo01 {
public static void main(String[] args) {
//创建Collection集合的对象
Collection<String> c = new ArrayList<String>();
//添加元素:boolean add(E e)
c.add("hello");
c.add("world");
c.add("java");
//输出集合对象
System.out.println(c);//这里打印的是:[hello, world, java],然后解释一下,为什么这个接口里面没有toString方法,但是为什么这里还是会打印这个toString的内容呢?因为这个println方法是把这个对象吃进去,然后造型为Object的,然后在println内部是把这个c对象当作是Object类的对象,所以可以执行toString方法。然后执行看右边的原则,具体执行时是去执行ArrayList的toString方法,因为ArrayList的toString方法是被重写的,所以输出这个[hello, world, java]
}
}
Collection集合的常用方法
| 方法名 | 说明 |
|---|---|
| boolean add(E e) | 添加元素,返回添加是否成功,且这个add方法返回永远都是true,所以我们用他的返回值做不了什么 |
| boolean remove(Object o) | 从集合中移除指定的元素,要是那个集合里没有这个元素,就返回false,不移除什么东西 |
| void clear() | 清空集合中的元素,并且那个集合的size()方法返回的集合长度也变为0了 |
| boolean contains(Object o) | 判断集合中是否存在指定的元素,要是有返回true,没有返回false。 |
| boolean isEmpty() | 判断集合是否为空,也可以理解为判断集合的size()返回是不是0 |
| int size() | 集合的长度,也就是集合中元素的个数 |
package com.liudashuai;
import java.util.ArrayList;
import java.util.Collection;
public class Demo {
public static void main(String[] args) {
Collection<String> c = new ArrayList<String>();
//添加元素:boolean add(E e)
c.add("hello");
c.add("world");
c.add("java");
//输出集合对象
System.out.println(c.contains("world"));//结果是true
/* ArrayList中那个contains方法长这样
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
*/
/* 先调用这个indexOf方法,然后要是o!=null的话,就用o.equals(集合的每一个元素)
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
*/
}
}
即这里的contains(Object o)方法:判断是否包含那个元素,要是这个o不是null的话,是用这个o.equals(集合中的每一个元素),要是equals判断出来这个两个东西相同,这个contains(Object o)方法就返回true,不然就返回false。
package com.liudashuai;
import java.util.ArrayList;
import java.util.Collection;
public class Demo {
public static void main(String[] args) {
Collection<String> c = new ArrayList<String>();
//添加元素:boolean add(E e)
c.add("hello");
c.add("world");
c.add(null);
c.add("java");
//输出集合对象
System.out.println(c.contains(null));//true
}
}
上面这样的结果也是true。看源码的分析就懂了。
集合的遍历
先介绍一下迭代器
- 迭代器,集合的专用遍历方式。(这里的集合不包括Map,因为Map里面没有iterator()方法,但是Collection有iterator方法,所以Collection和他下面的类可以用迭代器方式遍历。且因为Collection实现了Iterable接口,所以Collection和他下面的类可以使用for-each,只有实现了Iterable接口的类的对象可以使用for-each,才可以作放在or-each的for括号中的冒号前面。因为Map即没有iterator()方法也没有实现Iterable接口所以Map即不能使用迭代器,也不能用for-each。注意:这里Map不能使用迭代器是因为没有iterator()方法不是因为没有实现Iterable接口,因为iterator()方法是返回一个迭代器,是生成迭代器的方法,而Map里面没有生成迭代器的方法,所以不能用迭代器,所以HashMap和TreeMap也不能直接用迭代器和for-each)
- Iterator iterator():Collection中有一个iterator()方法,这个方法的作用是返回此集合中元素的迭代器(返回一个Iterator接口的实现类的对象)Collection中没有Iterator的实体类,但是他的子类比如ArrayList里面有一个Iterator的实现类,但是是private的,所以他的那个Iterator实现类只能在ArrayList内部new。
- 迭代器是通过集合的iterator()方法得到的,所以我们说它是依赖于集合而存在的。一般只有在集合里面你可能会用到这个Iterator迭代器,其他地方你看不到这个迭代器Iterator的使用。
这个迭代器Iterator接口,里面的方法不多,主要用到的是hasNext方法和next方法。这个Iterator的实现类里面有一个变量来记住集合的下标,hasNext是判断这个变量是不是 == 集合的size(),要是等于就返回false。然后next方法是用一个 i 来记住这个变量,然后这个变量+1;然后返回集合中以 i 为下标的值,这样next就读到了集合中的元素。且在下一次用next方法可以读集合里面的下一个元素。值得注意的是:next会先判断这个Iterator中记住下标的这个变量的值是不是有没有小于集合的size,要是标记变量的值大于等于集合的size值的话,将会抛出NoSuchElementException异常,所以我们经常用hasNext配合next来使用,如下例:
下面讲一下用Iterator遍历的步骤:
public class IteratorDemo {
public static void main(String[] args) {
//创建集合对象
Collection<String> c = new ArrayList<>();
//添加元素
c.add("hello");
c.add("world");
c.add("java");
c.add("javaee");
//Iterator<E> iterator():返回此集合中元素的迭代器,通过集合的iterator()方法得到
Iterator<String> it = c.iterator();
//用while循环改进元素的判断和获取
while (it.hasNext()) {
String s = it.next();
System.out.println(s);
}
}
}
注意这个Iterator接口其实是这么写的,public interface Iterator {……}所以他是可以带泛型的。还有就是因为每次next会把迭代器里那个指向下标的变量+1,所以hasNext判断这个变量是不是 == 集合的size,可以作为判断结束条件。因为最后一个元素被next返回后,那个指向下标的变量又+1了,所以他就 == 集合的size了,所以可以判断集合有没有读取结束。
下面我们看一下上面这个代码的iterator方法的源码:
因为上面那个代码的是用多态的,所以执行这个iterator()方法的时候是执行ArrayList类的那个iterator()方法,ArrayList的iterator方法长下面这样,这里new了一个Itr类。我们继续看看Itr这个类长什么样
public Iterator<E> iterator() {
return new Itr();
}
Itr这个类长下面这样,这个Itr是ArrayList内的一个内部类且是private的,所以只能像上面的iterator()这样,用ArrayList内部封装的那些又有new Itr()的方法去返回一个Itr对象。
private class Itr implements Iterator<E> {
int cursor; // index of next element to return
int lastRet = -1; // index of last element returned; -1 if no such
int expectedModCount = modCount;
Itr() {}
public boolean hasNext() {
return cursor != size;
}
@SuppressWarnings("unchecked")
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
public void remove() {……}//这里先不了解所以用……
@Override
@SuppressWarnings("unchecked")
public void forEachRemaining(Consumer<? super E> consumer) {……}//这里先不了解所以用……
final void checkForComodification() {……}//这里先不了解所以用……
}
总之:Iterator的hasNext方法就是判断集合中以Iteraor的位置变量为下标的地方有没有元素(位置下标一开始值是0),next方法就是读取现在在位置的元素,然后把位置变量+1
List集合
List集合的概述和特点
- List集合概述
- 有序集合(也称为序列、列表),用户可以精确控制列表中每个元素的插入位置。用户可以通过整数索引访问元素。
- List是一个接口,他继承自Collection,所以Collection中有的功能List也有。比如那个iterator()、add(E e)、remove(Object o)、clear()、contains(Object o)、isEmpty()、size()。但是这个List也添加了自己特有的抽象方法,比如add(int index,E element)、remove(int index)、set(int index,E element)、get(int index)方法。注意这个List特有的add方法是add(int index,E element)这方法Collection是没有的,而这个add(E e)是Collection和他子类共有的,所以List也有。
- 与Set集合不同,列表通常允许重复的元素
- List集合特点
- 有索引(Set集合没有索引)
- 可以存储重复元素
- 元素存取有序(即,你存的顺序是怎样的,取出来的顺序就是怎样的,比如你存到ArrayList中先存55再存一个12,然后你遍历取出的顺序就是先取55再取12)
List集合的特有方法
| 方法名 | 描述 |
|---|---|
| void add(int index,E element) | 在此集合中的指定位置插入指定的元素 |
| E remove(int index) | 删除指定索引处的元素,返回被删除的元素,集合长度-1, |
| E set(int index,E element) | 修改指定索引处的元素,返回被修改的元素 |
| E get(int index) | 返回指定索引处的元素 |
注意:
add(int index , E element)方法中,新插入的元素放在集合的这个index下标处,集合原来这个index下标处的元素和后面的元素都向后移动,且集合的长度+1。且要是原来的集合长度是10,你在11位置插入没问题,要是在12位置插入数据会抛出IndexOutOfBoundsException异常。
remove(int index)方法中,要是你删除的元素的下标>集合的size-1,那么会抛出IndexOutOfBoundsException异常。
set(int index,E element)方法中,要是你的index>集合的size-1,一样会抛出IndexOutOfBoundsException异常
get(int index)方法中,要是你index>集合的size-1,也一样会抛出IndexOutOfBoundsException异常
有没有发现上面List比Collection多出来的特有方法都是有下标的方法。
List集合的遍历
List集合可以用迭代器来遍历,因为他继承了Collection嘛,所以Collection中说好要有的功能List一定是会有的。
除此之外,因为List是有索引的,所以可以利用索引来遍历。
下面演示一下List遍历集合的两种方式(其实还有用列表迭代器遍历的方式、for-each的方式)
-
案例需求
创建一个存储学生对象的集合,存储3个学生对象,使用程序实现在控制台遍历该集合
-
代码实现
-
学生类
public class Student { private String name; private int age; public Student() { } public Student(String name, int age) { this.name = name; this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } } -
测试类
public class ListDemo { public static void main(String[] args) { //创建List集合对象 List<Student> list = new ArrayList<Student>(); //创建学生对象 Student s1 = new Student("林青霞", 30); Student s2 = new Student("张曼玉", 35); Student s3 = new Student("王祖贤", 33); //把学生添加到集合 list.add(s1); list.add(s2); list.add(s3); //迭代器方式 Iterator<Student> it = list.iterator(); while (it.hasNext()) { Student s = it.next(); System.out.println(s.getName() + "," + s.getAge()); } System.out.println("--------"); //for循环方式 for(int i=0; i<list.size(); i++) { Student s = list.get(i); System.out.println(s.getName() + "," + s.getAge()); } } }
-
并发修改异常
迭代器遍历的过程中,通过集合对象修改了集合中的元素,造成了迭代器获取元素中判断预期修改值和实际修改值不一致,则会出现:ConcurrentModificationException。这句话的解释看下面源码分析。
ConcurrentModificationException:叫作并发修改异常。当不允许这样修改时,你可以抛出这个异常。
比如这个例子就会抛出并发修改异常:
package com.liudashuai;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class Demo {
public static void main(String[] args) {
//创建集合对象
List<String> list = new ArrayList<String>();
//添加元素
list.add("hello");
list.add("world");
list.add("java");
//遍历集合,得到每一个元素,看有没有"world"这个元素,如果有,我就添加一个"javaee"元素,请写代码实现
Iterator<String> it = list.iterator();
while (it.hasNext()) {
String s = it.next();
if(s.equals("world")) {
list.add("javaee");
}
}
System.out.println(list);
}
}
抛出的异常如下:
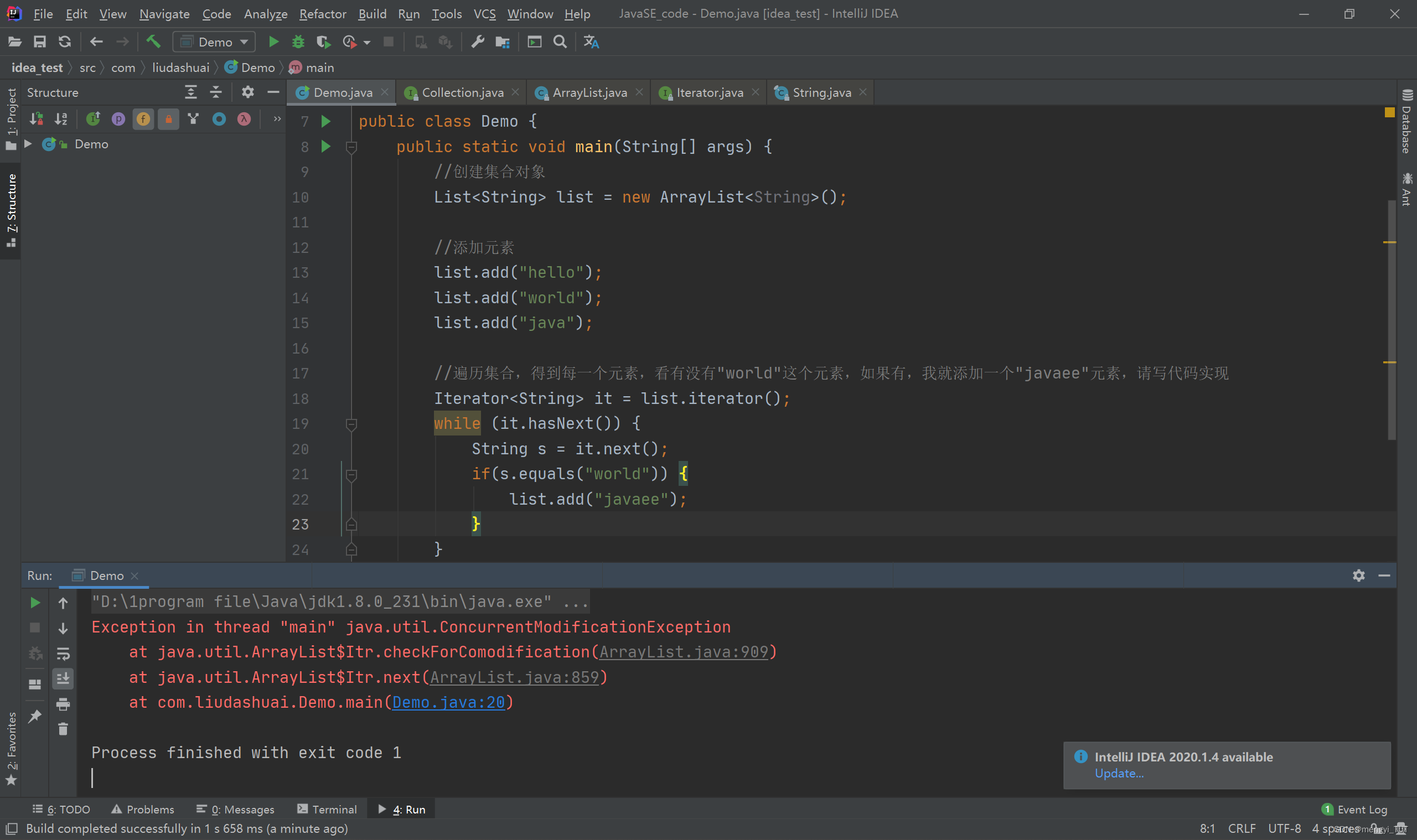
然后我们现在来分析这个异常,看异常信息可以知道,这个异常是mian方法中调用java.util.ArrayList I t r 对象的 n e x t 方法抛出的异常,然后又是这个 n e x t 方法调用 j a v a . u t i l . A r r a y L i s t Itr对象的next方法抛出的异常,然后又是这个next方法调用java.util.ArrayList Itr对象的next方法抛出的异常,然后又是这个next方法调用java.util.ArrayListItr这个对象的checkForComodification方法抛出的异常。所以异常的源头是java.util.ArrayList$Itr这个对象的checkForComodification方法抛出的。我们进去看看源码。
我们先看ArrayList类的源码(这里为了便于阅读省略了一些代码)
public abstract class AbstractList<E>{
protected int modCount = 0;//这个变量会记录实际修改集合的次数,所以每次add他都会+1.remove他也会+1。
}
public class ArrayList<E> extends AbstractList<E> implements List<E>
{
public boolean add(E e) {
ensureCapacityInternal(size + 1);//这个方法执行会使modCOunt++,所以这个add方法执行后这个modCount+1了,而这个ArrayList类里面是没有这个modCount的,因为他继承了AbstractList,所以他就继承了这个modCount.mod记录了目前集合修改的次数
elementData[size++] = e;
return true;
}
public Iterator<E> iterator() {
return new Itr();
}
private class Itr implements Iterator<E> {
int expectedModCount = modCount;//这个expectedModCount表示预期修改次数,一开始你new了这个Itr时,就把当时的modCount修改次数给了expectedModCount,让expectedModCount记住new这个Itr对象时ArrayList集合的修改次数。
Itr() {}
public E next() {
checkForComodification();//调用next的时候,会先调用这个checkForComodification方法。
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
final void checkForComodification() {//这个方法的作用是判断你new时存在expectedModCount里的集合修改次数和目前实际集合的修改次数modCount对比,要是不一样了,就会抛出并发修改异常
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
}
所以:你用iterator()方法创建了一个对象的时候,因为这个方法里面new 了一个Itr对象,所以当时记住了修改次数,然后你每次next的时候都是会比较一下集合目前被就改的次数和那个new Itr时的修改次数一不一样,然后上面的例子里的代码,因为在next方法调用前用了add方法,修改了原来的ArrayList集合,所以修改次数+1,然后你调用下一次next的时候,先检测实际修改次数和预期修改次数是否相同,就会发现不同,然后抛出并发修改异常。这就是抛出上面例子里抛出并发修改异常的原因。
ListIterator列表迭代器
-
概述
- List特有的迭代器,Collection没有的哦。在List里面有一个listIterator()的抽象方法,用于返回一个ListIterator的对象,所以List和他子类都一定可以用这个ListIterator。列表迭代器一般是只在List子类中用。
- ListIterator继承了Iterator,所以Iterator中有的hasNext和next方法他都有,且用法和功能是一样的。且这个ListIterator有他特有方法,比如,previous()、hasPrevious()、add(E e)。这三个方法在Iterator中都是没有的。
- 这个ListIterator迭代器和Iterator迭代器的区别是:ListIterator可以向任意方向遍历迭代器(看下面例子就知道了),还有就是Iterator是不能在迭代期间修改集合的,不然会抛出并发修改异常,但是ListIterator是允许在迭代期间修改集合的。
-
ListIterator的常用方法
返回值 方法 描述 void add(E e) 将指定的元素插入列表(可选操作)。 boolean hasNext() 与Iterator的hasNext用法和功能一样 boolean hasPrevious() 如果此列表迭代器在相反方向遍历列表时具有更多元素,则返回 true。E next() 与Iterator的next用法和功能一样 E previous() 返回列表中的上一个元素,并向后移动光标位置。 例子
package com.liudashuai; import java.util.ArrayList; import java.util.List; import java.util.ListIterator; public class Demo { public static void main(String[] args) { //创建集合对象 List<String> list = new ArrayList<String>(); //添加元素 list.add("hello"); list.add("world"); list.add("java"); //遍历集合,得到每一个元素,看有没有"world"这个元素,如果有,我就添加一个"javaee"元素,请写代码实现 ListIterator<String> lit = list.listIterator(); while (lit.hasNext()) { String s=lit.next();//hasNext、next的方法与Iterator的hasNext、next用法和功能是一样的 System.out.println(s); } System.out.println("---------"); while (lit.hasPrevious()) { String s=lit.previous(); System.out.println(s); } } } 结果: hello world java --------- java world hello分析:
这个ArrayList中的那个iterator方法长这样(省略了一部分源码),这里没有重新next方法和hasNext方法,所以是直接继承Itr的。
public interface List<E>{ Iterator<E> iterator(); ListIterator<E> listIterator(); } public class ArrayList<E> extends AbstractList<E> implements List<E>{ private class Itr implements Iterator<E> { int cursor; //表示当前迭代的位置,记录当前迭代到集合的哪个下标位置,是从0开始的 public boolean hasNext() { return cursor != size;//hasNext是判断迭代位置有没有达到集合下标上限 } public E next() {//next是读的是以调用next时的那个curse为下标的集合数据。且next还给curse+1了。 checkForComodification(); int i = cursor; if (i >= size) throw new NoSuchElementException(); Object[] elementData = ArrayList.this.elementData;//这里用ArrayList.this.elementData是指ArrayList的那一个elementData成员变量,这里面存的是集合的数据,这里的这个语句是把这个数据复制到Itr里next方法里的这个elementData变量里 if (i >= elementData.length) throw new ConcurrentModificationException(); cursor = i + 1;//把迭代位置+1 return (E) elementData[lastRet = i];//next是读那个curse+1前的集合位置的数据 } } public ListIterator<E> listIterator() { return new ListItr(0); } private class ListItr extends Itr implements ListIterator<E> { //在ListItr类里面没有curse这个变量,这个curse是在Itr中的,所以Itr和ListItr是共享这个变量的,所以会出现上面例子中的,你先向后迭代,然后再向前迭代输出了hello world java 然后输出java world hello,先向后跌带把那个curse向后移动了,然后再后面读一个数据把curse向前移动一个,所以出现了上面那个结果。 ListItr(int index) { super(); cursor = index; } public boolean hasPrevious() { return cursor != 0;//hasPrevious是判断迭代位置是不是到达集合下标的下限 } public E previous() {//这个方法是读传入时的curse然后-1的位置的值,且经过这个方法后这个curse会-1,然后再解释一下上面那个例子的原因,因为next先读值,然后+1,结束while (lit.hasNext()) {……}的时候,这个curse是集合下标上限+1,然后这个previous是先把curse-1然后再读的,所以读到了集合下标下限位置。 checkForComodification(); int i = cursor - 1;//你调用这个previous方法,就会用一个i记住记住curse-1,然后看看有没有小于0,要是小于0就会抛出NoSuchElementException异常。比如你现在的curse记住的当前下标是0,已经到下限了,然后你i就是-1,为了避免下标越界,他抛出一个NoSuchElementException异常 if (i < 0) throw new NoSuchElementException(); Object[] elementData = ArrayList.this.elementData;//拿到集合数据把他保存在局部变量elementData中 if (i >= elementData.length) throw new ConcurrentModificationException(); cursor = i;//相当于把curse-1 return (E) elementData[lastRet = i]; } public void add(E e) { checkForComodification(); try { int i = cursor; ArrayList.this.add(i, e); cursor = i + 1; lastRet = -1; expectedModCount = modCount;//这里就是ListIterator的对象调用add方法不会抛出并发修改异常的原因,因为在用ListIterator的add方法时是会把modCount赋值给expectedModCount变量的,所以你后面用next的时候判断时就不会发现预期修改值expectedModCount和实际修改值modCount不同了,这样运行next就不会抛出并发修改异常。比如下面的例子。但是你用ArrayList的add方法是没有expectedModCount = modCount;的,所以用ArrayList的add再用next方法就会抛出异常。 } catch (IndexOutOfBoundsException ex) { throw new ConcurrentModificationException(); } } } }ListIterator的add方法可以避免被next方法检测出并发修改异常。例子如下:
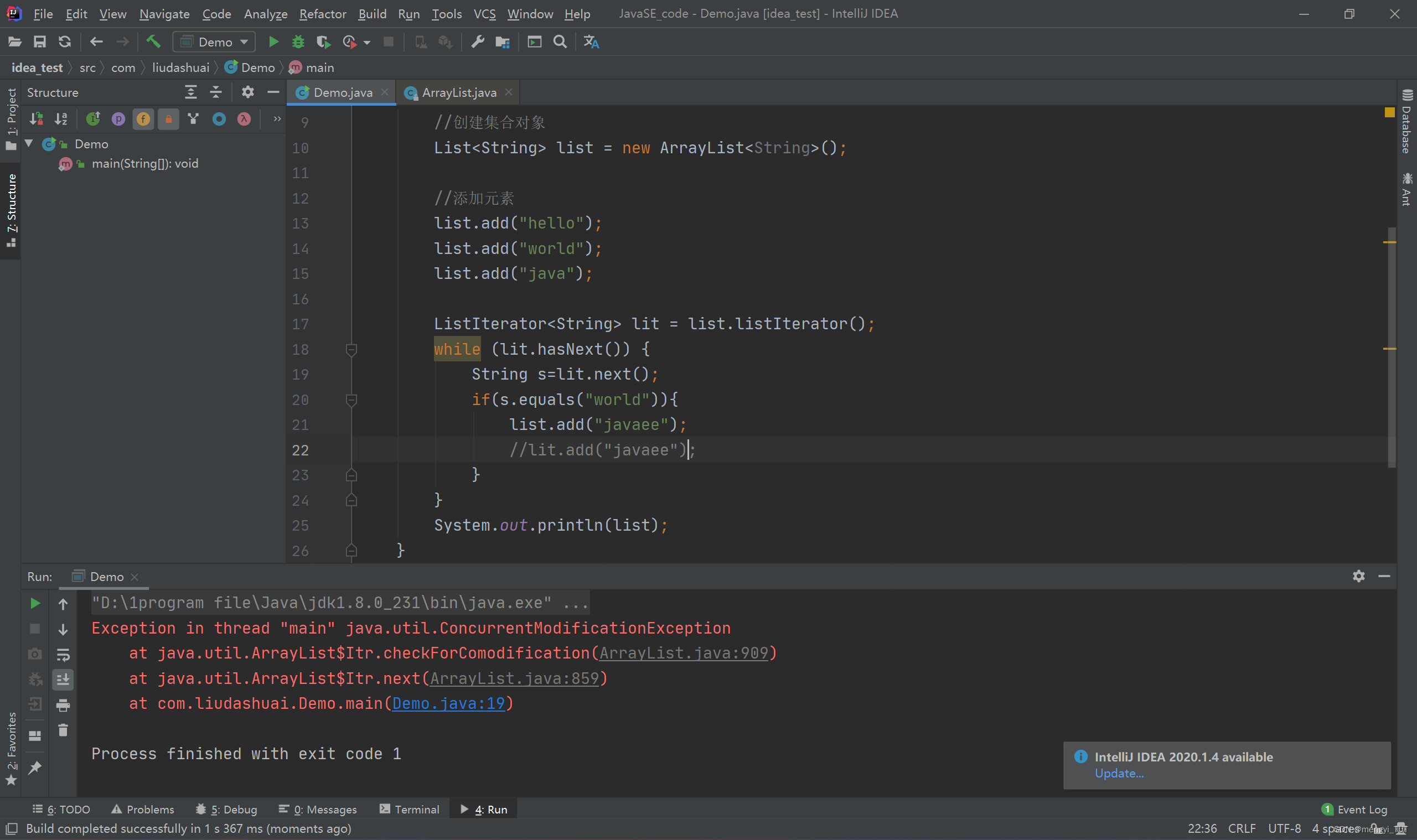
package com.liudashuai; import java.util.ArrayList; import java.util.List; import java.util.ListIterator; public class Demo { public static void main(String[] args) { //创建集合对象 List<String> list = new ArrayList<String>(); //添加元素 list.add("hello"); list.add("world"); list.add("java"); ListIterator<String> lit = list.listIterator(); while (lit.hasNext()) { String s=lit.next(); if(s.equals("world")){ //list.add("javaee"); lit.add("javaee"); } } System.out.println(list); } } //没有抛出异常,输出如下:(但是要注意添加的位置,是在world之后,即在ArrayList的以调用add方法时的那个迭代cursor值为下标的位置插入值。插入过程是:调用ArrayList的那个add(cursor,add传入的参数的值)方法插入的。 [hello, world, javaee, java]但是你要是用 list.add(“javaee”); 方法而不是用这个 lit.add(“javaee”); 就会抛出ConcurrentModificationException异常。
如图:
增强for循环
作用:简化数组和Collection及其子类的遍历。
实现了Iterable接口的类都可以是for-each(增强for循环)的目标。即可以使用for-each来简化遍历。这个Iterable接口就为了for-each而存在的。通过API文档我们知道,这个Iterable接口主要包含了Iterator iterator();抽象方法。所以实现这个接口的类里面一定会有迭代器。
for-each的底层是用迭代器来实现的,相当于底层用了Iterator的next()和hasNext()方法
-
定义格式
for(元素数据类型 变量名 : 数组/Collection或其子类对象的对象名) { 循环体; } -
示例代码
public class ForDemo { public static void main(String[] args) { int[] arr = {1,2,3,4,5}; for(int i : arr) { System.out.println(i); } System.out.println("--------"); String[] strArray = {"hello","world","java"}; for(String s : strArray) { System.out.println(s); } System.out.println("--------"); List<String> list = new ArrayList<String>(); list.add("hello"); list.add("world"); list.add("java"); for(String s : list) { System.out.println(s); } System.out.println("--------"); //因为内部原理是一个Iterator迭代器 /* for(String s : list) { if(s.equals("world")) { list.add("javaee"); //ConcurrentModificationException } } 相当于 Iterator<String> it=list.iterator(); while(it.hasNext()){ String s=it.next(); if(s.equals("world")) { list.add("javaee"); //ConcurrentModificationException } } */ } }
List的三种常用遍历
-
案例需求
创建一个存储学生对象的集合,存储3个学生对象,使用程序实现在控制台遍历该集合(List集合的遍历方式这么多种,但是下面三种是常用的)
-
代码实现
-
学生类
public class Student { private String name; private int age; public Student() { } public Student(String name, int age) { this.name = name; this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } } -
测试类
public class ListDemo { public static void main(String[] args) { //创建List集合对象 List<Student> list = new ArrayList<Student>(); //创建学生对象 Student s1 = new Student("林青霞", 30); Student s2 = new Student("张曼玉", 35); Student s3 = new Student("王祖贤", 33); //把学生添加到集合 list.add(s1); list.add(s2); list.add(s3); //迭代器:集合特有的遍历方式 Iterator<Student> it = list.iterator(); while (it.hasNext()) { Student s = it.next(); System.out.println(s.getName()+","+s.getAge()); } System.out.println("--------"); //普通for:带有索引的遍历方式 for(int i=0; i<list.size(); i++) { Student s = list.get(i); System.out.println(s.getName()+","+s.getAge()); } System.out.println("--------"); //增强for:最方便的遍历方式 for(Student s : list) { System.out.println(s.getName()+","+s.getAge()); } } }
-
数据结构
什么是数据结构:数据结构是指计算机存储和组织数据的方式。是那些相互之间存在一种或多种特定关系的数据元素的集合体。
你写代码的时候选择合适的数据结构来存放你数据,可以更加快捷的迅速地提高你代码的运行效率,这就是我们要学数据结构的原因,这里只是简单地提一下,为下面要讲的内容作铺垫。
数据结构之栈和队列
-
栈结构
先进后出
-
队列结构
先进先出
数据结构之数组和链表
-
数组结构
查询快、增删慢
-
队列结构
查询慢、增删快
List集合的常用子类
List集合的常用子类我们现在只学ArrayList和LinkedList。这个两个类是具体实现类。
ArrayList
-
特点
因为这个ArrayList的底层是数组实现的,所以它的特点是:查询快,增删慢。以后我们选择数据存储容器要看数据是否要求查询快,要是更注重查询速率就用ArrayList。
-
List几种遍历方式ArrayList都可以用,因为它是List的实现类嘛。
-
ArrayList的方法就不用讲了,前面已经讲过很多次了。
LinkedList
-
特点
因为这个LinkedList的底层是链表实现的,所以它的特点是:查询慢,增删快。以后我们选择数据存储容器要看数据是否要求增删快,要是更注重增删速率的话就用LinkedList。
-
List几种遍历方式LinkedList都可以用,因为它是List的实现类嘛。
例子:(ArrayList写了很多次了,ArrayList就不展示遍历了,展示一下LinkedList的遍历。虽然基本是一样的)
package com.liudashuai; import java.util.Iterator; import java.util.LinkedList; import java.util.ListIterator; public class Demo { public static void main(String[] args) { LinkedList<String> list = new LinkedList<String>(); list.add("hello"); list.add("world"); list.add("java"); //方式1 for (String s:list) { System.out.println(s); } //方式2 for (int i = 0; i < list.size(); i++) { String s=list.get(i); System.out.println(s); } //方式3 Iterator<String> it = list.iterator(); while (it.hasNext()) { String s = it.next(); System.out.println(s); } //方式4 ListIterator<String> lit=list.listIterator(); while (lit.hasNext()) { String s = lit.next(); System.out.println(s); } } } -
LinkedList的特有方法。(指比起List的新添加的特有方法)
方法名 说明 public void addFirst(E e) 在该列表开头插入指定的元素,其他向后移动 public void addLast(E e) 将指定的元素追加到此列表的末尾 public E getFirst() 返回此列表中的第一个元素 public E getLast() 返回此列表中的最后一个元素 public E removeFirst() 从此列表中删除并返回第一个元素 public E removeLast() 从此列表中删除并返回最后一个元素 使用示例:
package com.liudashuai; import java.util.LinkedList; public class Demo { public static void main(String[] args) { LinkedList<String> list = new LinkedList<String>(); list.add("hello"); list.add("world"); list.add("java"); list.addFirst("A"); list.addLast("E"); System.out.println(list); } } 结果:[A, hello, world, java, E]package com.liudashuai; import java.util.LinkedList; public class Demo { public static void main(String[] args) { LinkedList<String> list = new LinkedList<String>(); list.add("hello"); list.add("world"); list.add("java"); System.out.println(list.getFirst()); System.out.println(list.getLast()); } } 结果: hello javapackage com.liudashuai; import java.util.LinkedList; public class Demo { public static void main(String[] args) { LinkedList<String> list = new LinkedList<String>(); list.add("hello"); list.add("world"); list.add("java"); System.out.println(list.removeFirst()); System.out.println(list.removeLast()); System.out.println(list); } } 结果: hello java [world]
面试题常考
- ArrayList,LinkedList,Vector三者的相同点与不同点?(“Vector”可百度)【面试题】
- 相同点:ArrayList、LinkedList、Vevtor都实现了List接口,并且他们存储的数据都是可以重复的
- 不同点:
- ArrayList底层用的是Object[]数组存储的,查找的效率高,增删的效率低,查找的时间复杂度是O(I),增删元素的时间复杂度是O(n),但是ArrayList是线程不安全的。
- LinkedList底层用的是双向链表存储的,增删的效率比较高,查找的效率比较低。它也是线程不安全的。LinkedList的增删的时间复杂度是O(I),查找的时间复杂度是O(n)。
- Vector底层是用Object[]数组来存储数据的,因为它的很多方法都加了synchronized关键字,所以效率比较低,但是是线程安全的。














 1658
1658











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









