







目录
前言 URL(在评论区)URL(在评论区)URL(在评论区)
目的 URL(在评论区)URL(在评论区)URL(在评论区)
思路 URL(在评论区)URL(在评论区)URL(在评论区)
前言
上一节我们讲到了Python正则法抓取某电影网Top250信息,
这一节再进行一个简单的正则法抓取例子:抓取某网站的迅雷种子资源!
目的
获取某网站中2022必看片榜单中所有电影的片名与对应迅雷种子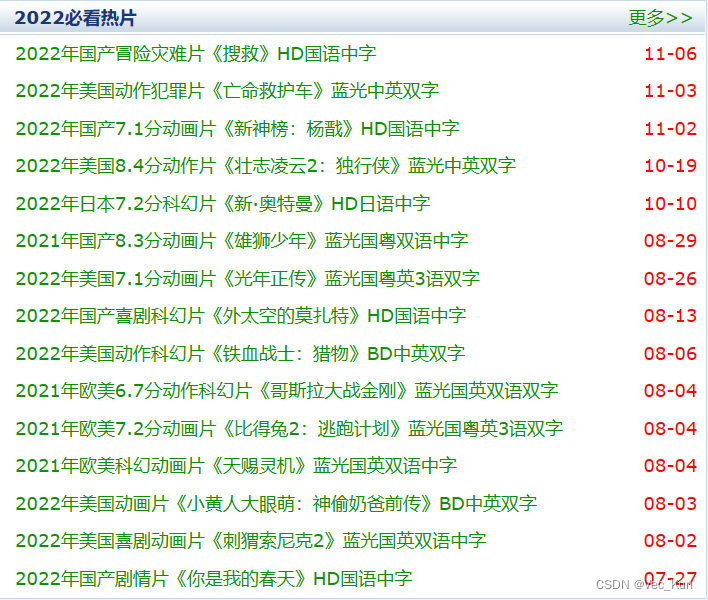
思路
1. 定位到2022必看片
2. 从2022必看片中提取子页面的链接地址
3. 请求子页面的链接地址,拿到我们想要的下载地址
代码实现
第一步,先导包
import re
import requests复习一下,re库就是Regular Expression,即Python的正则库,用于数据分析。requests库是我们请求网页所用的库。
第二步,请求源代码
domain = "见评论区" # domain就是url,换了个说法
resp = requests.get(domain) # 如果报错,可能是http's'的问题。那么就需要加一个参数' verify = False ',不进行安全校验
print(resp.text)这里可能出现两个问题:
1. resp报错,这里可能是http's'的问题,https和http的区别就在于是否进行安全校验。我们访问https网页如果报错,那就在requests.get()中添加参数verify=False,就可以跳过安全校验步骤了
2. print网页源代码时我们发现,涉及到中文的时候打印出了乱码,这个时候我们要敏锐的感觉到一定是编码方式的问题!html默认的编码方式和PyCharm是一致的,都是UTF-8。但是此时出现了乱码我们就要去寻找这个网页的编码方式有何不同。
第三步,debug第二步
1. 修改resp行函数为
resp = requests.get(domain, verify=False)2. 观察发现网页源代码的头部标签中规定了此网页的编码方式:
<META http-equiv=Content-Type content="text/html; charset=gb2312">中charset=gb2312,所以我们应该采用gb2312编码。
注:如果想了解更多关于HTML头部标签的知识,请访问HTML头部
resp.encoding = 'gb2312' # 指定字符集
print(resp.text)
resp.close()此时再打印源代码就不会出现乱码了
第四步,正则法定位信息
1. 先检查页面源代码定位
可以观察到,从<ul>开始,每一个<li>中 包含我们对应的资源名称和链接,这正是我们需要的。
其实, <ul>指的是无序列表,而每一个<li>代表无序列表中的每一个列表项;<div>是浏览器的块级元素,表达这一部分是一个整体。如果想了解更多关于HTML列表和HTML块级元素的知识,请点击下面的超链接
2. 正则法定位上述源代码
# 定位成功
obj1 = re.compile(r"2022必看热片.*?<ul>(?P<ul>.*?)</ul>", re.S)
result1 = obj1.finditer(resp.text)
for it in result1:
ul = it.group('ul')
# print(ul)我们还是用惰性搜索拿出了中间一大堆<li>包裹的信息,还是很准确的,但是我们不能直接把这个拿来用,我们要进行重定位,把信息细节提取出来,不要其余多余的代码
3. 再次正则,拿出想要的信息
# html中,a标签表示超链接,点击对应的对象就会跳转到href引用的链接中,title是鼠标选中以后浮现出的提示文字,主要需要href中的子页面链接
# 提取子页面链接
obj2 = re.compile(r"<a href='(?P<href>.*?)'", re.S)
result2 = obj2.finditer(ul)
child_href_list = []
for i in result2:
href = i.group('href')
# 拼接子页面url地址:域名+子页面地址(这里多了一个斜杠,要strip掉)
child_href = domain + href.strip("/")
# print(child_href) # 为了方便,把它们装进列表里
child_href_list.append(child_href) # 把子页面链接保存起来
# 37 + 38 = child_href_list = [child_href]
# child_href_list = [child_href]这里<a>标签就是表示超链接,herf元素的含义就是引用子链接,是基于当前域名添加路径定位到我们需要的位置。所以我们需要把之前代码中写到的域名domain和子页面地址拼接起来。
打印出来发现链接多了一个斜杠,我们使用strip函数去掉,然后递归地保存到列表中就好了。
关于超链接<a>的知识请访问HTML链接
第五步,访问提取子页面内容

源代码90行开始出现了我们需要的信息,如图所示
# 提取子页面内容
obj3 = re.compile(r'◎片 名(?P<moviename>.*?)<br />.*?<td '
r'style="WORD-WRAP: break-word" bgcolor="#fdfddf"><a href="(?P<download>.*?)">', re.S)
for href in child_href_list:
child_resp = requests.get(href)
child_resp.encoding = 'gb2312'
# print(child_resp.text)
result3 = obj3.finditer(child_resp.text)
for j in result3:
moviename = j.group("moviename")
download = j.group("download")
print(moviename)
print(download)
# break # 测试用
child_resp.close()根据已知信息,写出正则表达式,进行预处理,拿到片名和迅雷种子。
之后进行递归,把子页面列表中的链接都遍历一遍,就得到了2022必看榜单片名及种子了。
完整代码
# 思路:
# 1.定位到2022必看片
# 2.从2022必看片中提取子页面的链接地址
# 3.请求子页面的链接地址,拿到我们想要的下载地址。(迅雷种子)
import re
import requests
domain = "见评论区" # domain就是url,换了个说法
resp = requests.get(domain, verify=False) # 如果报错,可能是http's'的问题。那么就需要加一个参数' verify = False ',不进行安全校验
# print(resp.text) # 中文编码默认是utf-8,但是test出现乱码,说明编码方式出现问题
# 观察发现<META http-equiv=Content-Type content="text/html; charset=gb2312">中charset=gb2312,所以采用gb2312编码
resp.encoding = 'gb2312' # 指定字符集
# print(resp.text)
resp.close()
# 定位成功
obj1 = re.compile(r"2022必看热片.*?<ul>(?P<ul>.*?)</ul>", re.S)
result1 = obj1.finditer(resp.text)
for it in result1:
ul = it.group('ul')
# print(ul)
# html中,a标签表示超链接,点击对应的对象就会跳转到href引用的链接中,title是鼠标选中以后浮现出的提示文字,主要需要href中的子页面链接
# 提取子页面链接
obj2 = re.compile(r"<a href='(?P<href>.*?)'", re.S)
result2 = obj2.finditer(ul)
child_href_list = []
for i in result2:
href = i.group('href')
# 拼接子页面url地址:域名+子页面地址(这里多了一个斜杠,要strip掉)
child_href = domain + href.strip("/")
# print(child_href) # 为了方便,把它们装进列表里
child_href_list.append(child_href) # 把子页面链接保存起来
# 37 + 38 = child_href_list = [child_href]
# child_href_list = [child_href]
# 提取子页面内容
obj3 = re.compile(r'◎片 名(?P<moviename>.*?)<br />.*?<td '
r'style="WORD-WRAP: break-word" bgcolor="#fdfddf"><a href="(?P<download>.*?)">', re.S)
for href in child_href_list:
child_resp = requests.get(href)
child_resp.encoding = 'gb2312'
# print(child_resp.text)
result3 = obj3.finditer(child_resp.text)
for j in result3:
moviename = j.group("moviename")
download = j.group("download")
print(moviename)
print(download)
# break # 测试用
child_resp.close()
运行结果
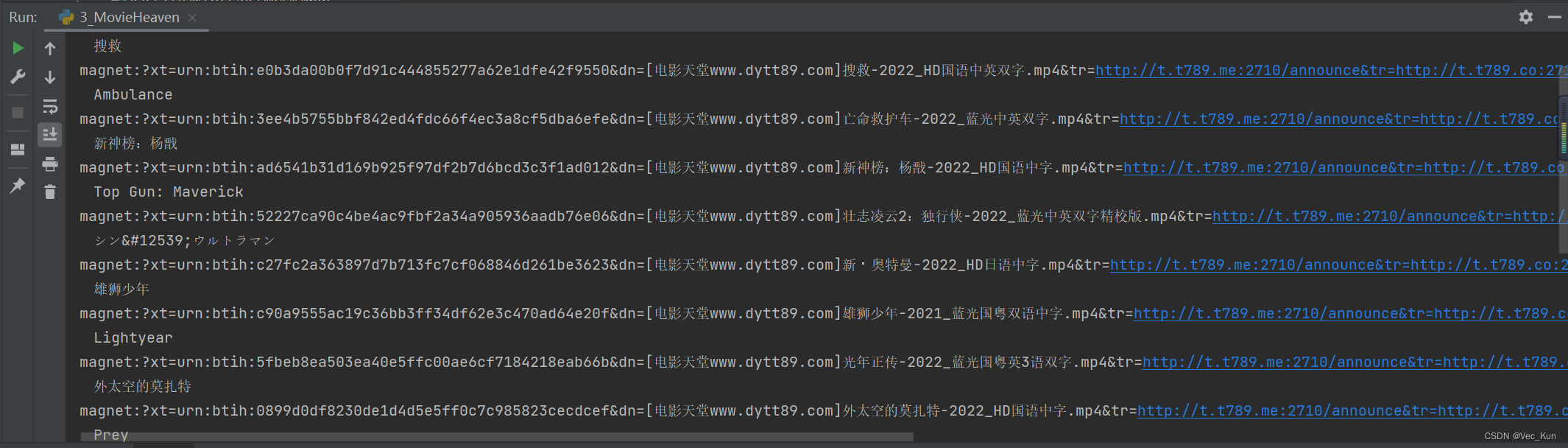
可以看到片名和迅雷种子都成功提取了,完成!
总结
我们今天又用正则法爬取2022必看电影名和其迅雷下载链接,再次锻炼了re模块的使用方法。下一期我们将简要介绍一下HTML语法,方便我们今后bs4和xpath的学习。关于 HTML教程我主页已经有一个专栏供大家学习了,这里放个传送门HTML教程

















 715
715











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











