







目录
前言 (链接在评论区)(链接在评论区)(链接在评论区)
前言
我们已经学习了爬虫的许多方法,本节较为综合,实现抓取某网站(链接在评论区)的视频。本节以《未闻花名》为例,其他资源可以自行修改URL进行抓取,大同小异。

本节只对一集进行抓取,对于其他剧集可以通过嵌套循环简单地完成,这里就不赘述。
目的
抓取某网站(链接在评论区)《未闻花名》剧集
思路
首先,了解一下一般视频网站是如何操作视频资源的
用户上传 -> 转码(把视频做处理, 2K, 1080, 标清) -> 切片处理(把单个的文件进行拆分) -> 用户拉动进度条自动读取附近切片并加载
如何实现上述功能?
需要一个文件来记录:M3U8。它实际上记录了每一个切片(ts文件)的地址。
M3U(Moving Picture Experts Group Audio Layer 3 Uniform Resource Locator)这种文件格式,本质上说不是音频文件,它并不能在脱机模式下读取网络资源音频,它是音频文件的列表文件,是纯文本文件。你下载下来打开它,播放软件并不是播放它,而是根据它的记录找到网络地址进行在线播放。
而M3U8是对M3U文件的utf-8编码。
核心明确
1. 找到m3u8 (各种手段)
2. 通过m3u8下载到ts文件
3. 可以通过各种手段(不仅是编程手段) 把ts文件合并为一个mp4文件
思路流程
1. 拿到视频网站的页面源代码
2. 从源代码中提取到m3u8的url
3. 下载m3u8
4. 读取m3u8文件, 下载视频
5. 合并视频
代码实现
先导包
import requests
from lxml import etree访问页面
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.192 Safari/537.36"
}
url = "见评论区"
resp = requests.get(url, headers=headers)查看页面源代码,找m3u8
方法一:

搜索m3u8,果然有两个结果。我们定睛一看:url与next_url,它不就是本集和下一集的m3u8地址吗?直接找到了目标。
方法二:
我们看到页面中有一个播放器

这个其实就是网页中嵌套的播放器,是网页中的网页,也叫做“iframe”。其实它实际上是一个网页的内联框架,一般会在内联框架中关联网页URL从而实现网页的嵌套。
检查页面:

能得到iframe中的url(即播放器的链接,也能发现在其中隐藏的m3u8文件地址)
但我们在源代码中搜索iframe:

却搜索不到,说明网站没有直接把内联框架写在源代码中,而是通过动态请求。
我们见招拆招,我们在F12中切换到网络,刷新一下:

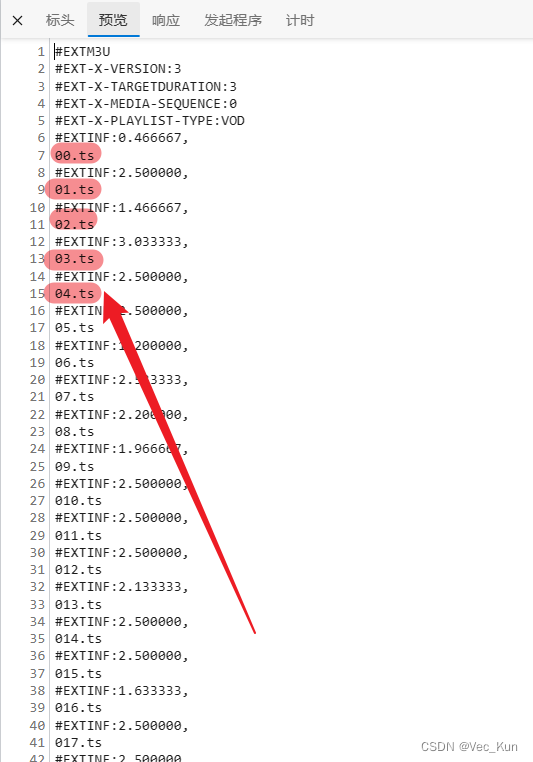
看到了index.m3u8这个选项,同样能拿到它的url,但这样不具有普适性,因为无法通过直接的网络请求在源代码中找到。
所以我们还是选用方法一来搞。
html = etree.HTML(resp.text)
dic_str = html.xpath("/html/body/div[4]/div/script[1]/text()")[0].strip("var player_aaaa=")
dic = json.loads(dic_str) # 将字符串转为字典拿信息
# print(dic.get('url')) # 得到的是url属性对应的m3u8链接
m3u8_url = dic.get('url') # 拿到m3u8的地址
# print(m3u8_url)用xpath先抓来script的文本内容,不熟悉xpath的同学可以回去看XPath解析入门。
抓到文本以后发现是一个字典,但是此时它还是字符串,我们把它转为字典:
导包
import json用json.loads()处理为字典,然后用get方法获得url后面的值,拿到m3u8地址。
然后直接下载就完事了
# 下载m3u8文件
resp2 = requests.get(m3u8_url, headers=headers)
with open("未闻花名.m3u8", mode="wb") as f:
f.write(resp2.content)
resp2.close()
print("下载完毕")带不带headers都行,一般最好能带上,也不麻烦,我没有测试不带headers会不会拦截,大家用上headers就好了,在请求标头里都能拿到。

打开下载好的m3u8文件,我们发现ts的地址都是精简版的,我们需要补齐前面的域名:
domain = m3u8_url.split("index")[0] # 拿到主域名,后面拼接ts文件链接要用
# print(domain)现在可以下载视频片段了
# 下载视频片段
def download(url):
resp3 = requests.get(domain + url)
fp = open(f"あの花_video/{url}", mode="wb")
fp.write(resp3.content)
fp.close()
resp3.close()
print("完成1片")解析m3u8文件
# 解析m3u8文件
lst = []
with open("未闻花名.m3u8", mode="r", encoding="utf-8") as f:
for line in f:
line = line.strip() # 先去掉空格, 空白, 换行符
if line.startswith("#"): # 如果以#开头. 我不要
continue
else:
lst.append(line)观察发现地址都是不带“#”的,所以我们以“#”作为筛选,取出不带井号的行作为地址加入列表。
由于有六百多个ts文件,如果串行下载的话会很耗时间,效率低下,所以用线程池的方法来做
导包
from concurrent.futures import ThreadPoolExecutor创建线程池
# 创建线程池
with ThreadPoolExecutor(50) as t:
for i in lst:
t.submit(download, f"{i}")
print("Clear All")在下载列表中的每一项都调用刚写好的download函数,把参数传入,在函数中拼接成完整的url,进行下载、保存。
遍历文件夹,调用os库,把ts拼接成一个mp4文件
导包
import os合成视频
# print(os.listdir("あの花_video"))
# 合成视频
with open("あの花_video/あの花_video.mp4", "ab+") as fv:
for file in os.listdir("あの花_video"):
with open(f"あの花_video/{file}", "rb") as fvp:
fv.write(fvp.read())
完整代码
# <video src="some_video.mp4"></video>
# 一般的视频网站是怎么做的?
# 用户上传 -> 转码(把视频做处理, 2K, 1080, 标清) -> 切片处理(把单个的文件进行拆分) 60
# 用户在进行拉动进度条的时候
# =================================
# 需要一个文件记录: 1.视频播放顺序, 2.视频存放的路径.
# M3U8 txt json => 文本
# 想要抓取一个视频:
# 1. 找到m3u8 (各种手段)
# 2. 通过m3u8下载到ts文件
# 3. 可以通过各种手段(不仅是编程手段) 把ts文件合并为一个mp4文件
"""
流程:
1. 拿到vod-play-id-61824-sid-1-nid-1.html的页面源代码
2. 从源代码中提取到m3u8的url
3. 下载m3u8
4. 读取m3u8文件, 下载视频
5. 合并视频
"""
import os
import json
import requests
from lxml import etree
from concurrent.futures import ThreadPoolExecutor
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.192 Safari/537.36"
}
url = "http://www.i110dy.com/vod-play-id-61824-sid-1-nid-1.html"
resp = requests.get(url, headers=headers)
html = etree.HTML(resp.text)
dic_str = html.xpath("/html/body/div[4]/div/script[1]/text()")[0].strip("var player_aaaa=")
dic = json.loads(dic_str) # 将字符串转为字典拿信息
# print(dic.get('url')) # 得到的是url属性对应的m3u8链接
m3u8_url = dic.get('url') # 拿到m3u8的地址
# print(m3u8_url)
domain = m3u8_url.split("index")[0] # 拿到主域名,后面拼接ts文件链接要用
# print(domain)
resp.close()
# 下载m3u8文件
resp2 = requests.get(m3u8_url, headers=headers)
with open("未闻花名.m3u8", mode="wb") as f:
f.write(resp2.content)
resp2.close()
print("下载完毕")
# 下载视频片段
def download(url):
resp3 = requests.get(domain + url)
fp = open(f"あの花_video/{url}", mode="wb")
fp.write(resp3.content)
fp.close()
resp3.close()
print("完成1片")
# 解析m3u8文件
lst = []
with open("未闻花名.m3u8", mode="r", encoding="utf-8") as f:
for line in f:
line = line.strip() # 先去掉空格, 空白, 换行符
if line.startswith("#"): # 如果以#开头. 我不要
continue
else:
lst.append(line)
# 创建线程池
with ThreadPoolExecutor(50) as t:
for i in lst:
t.submit(download, f"{i}")
print("Clear All")
# print(os.listdir("あの花_video"))
# 合成视频
with open("あの花_video/あの花_video.mp4", "ab+") as fv:
for file in os.listdir("あの花_video"):
with open(f"あの花_video/{file}", "rb") as fvp:
fv.write(fvp.read())
运行效果
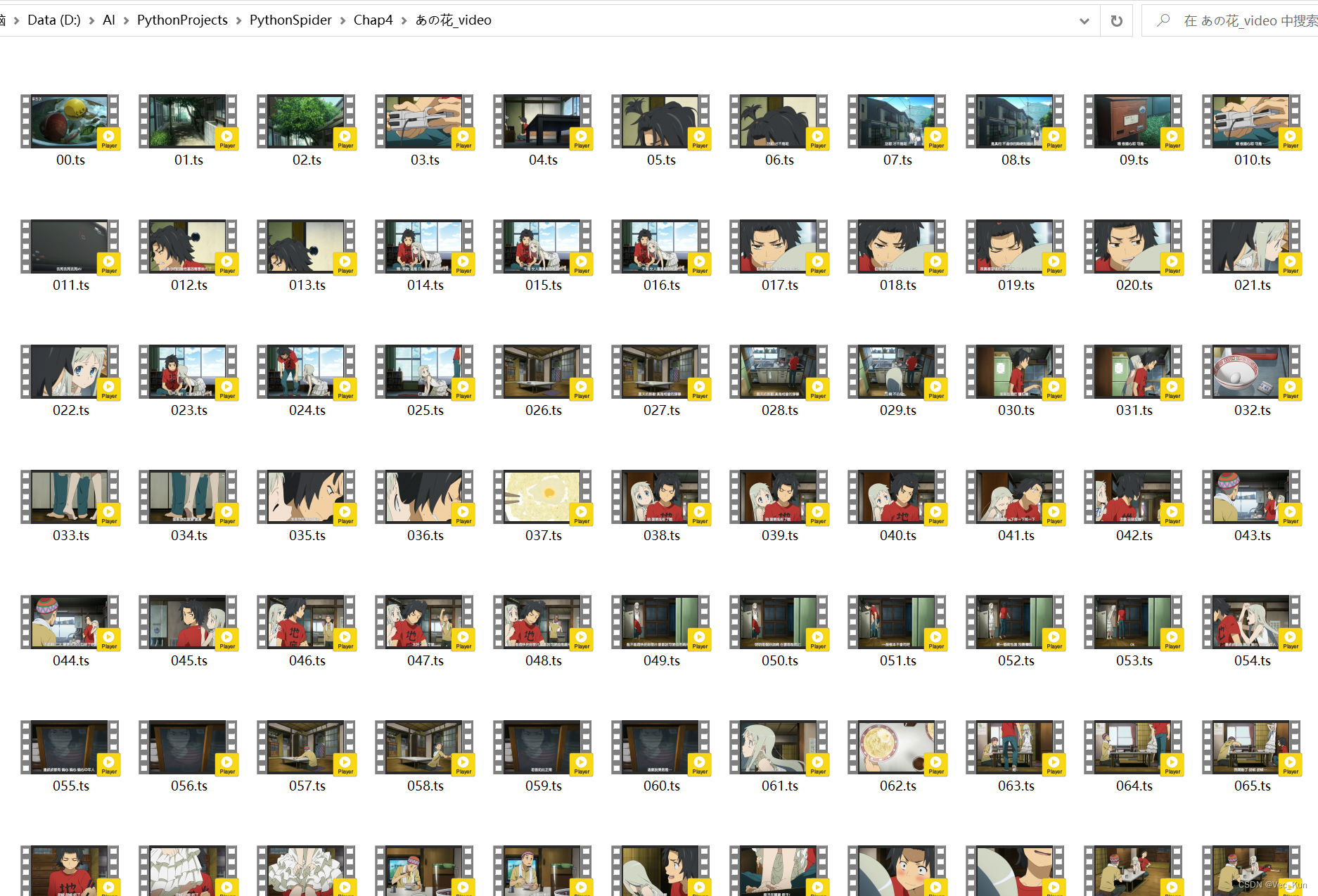
可以看到片段下载完毕,在文件夹最后也合成了完整视频。

总结
本节较为综合,运用多方面知识对某网站(链接在评论区)(链接在评论区)(链接在评论区)《未闻花名》动漫作了简单的爬取,适合新手小白训练,涉及多个模块,可以锻炼能力。

















 1469
1469











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











