







1,什么是索引?
索引是存储引擎用于快速查找数据记录的一种数据结构(索引依赖与存储引擎),当我们通过mysql进行查找操作时,首先会去查找索引如果存在则通过索引查找相关数据,如果不存在则会全表扫描进行查找
2,使用索引的优缺点
优点:
1,提高检索效率,降低了数据库的IO成本
2,在多表联合查询的时候可以加快表与表之间的连接,加快查询速度
3,在使用order by 和group by是可减少排序,分组时间
缺点
1,索引的创建和维护都会花费大量的时间,并且随着数据量的增大所需时间也越多
2,降低了表的更新速度,每次更新都要对索引进行维护
3,每创建一个索引都需要在磁盘上开辟存储空间
3,Mysql中的数据存储
在一个表中我们将表中的数据以页作为基本单位进行存储,一个页的大小为16KB,当一个页存满后再存到另一个页中
4,B+树的推演
compact行格式说明
mysql5.1中默认的行格式为compact,其他版本默认的为dynamic在创建表的时候可以使用row_format=xxxx进行指定,我们这里以compact为例进行说明,一条完整的记录分为两大部分一部分是额外信息另一部分是真实信息
为了方便理解我们简化一下额外信息的组成
record_type:表示记录的类型 0,表示普通的用户记录 1,表示目录项记录(后面会用到)
2,表示最小记录 3,表示最大记录
next_record:表示下一条记录的地址

每个页的地址并不是连续之间通过双向链表连接 默认安装主键的大小进行存放数据

在查找数据时我们进行逐页的遍历显然是比较浪费时间的,我们将每页的最小数据和对应的页地址抽取出来(我们称为目录项)

此时我们进行查找时可以先查找目录项来确定在那个数据页里面这就节省了不少的时间,但现在的目录项是不连续的我们便参照数据页的组成把目录项页组成一个数据页

当存放目录项的页被存满时我们便新建一个页用来存放目录项,我们将这两个目录页再抽取出来目录项组成一个目录页
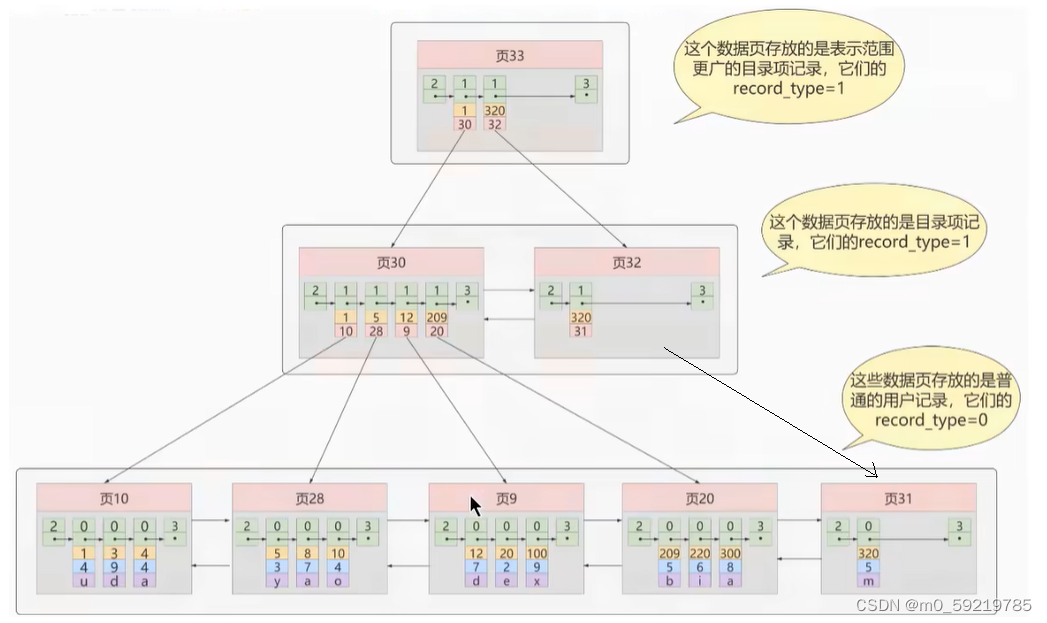
这就是B+树的结构一般来说B+树的层数不会超过4层
每个页的大小为16KB我们假设一条记录的大小为160B一页大概可以存100条记录那么三层的B+树可以存的记录数为 100×100×100×100=100000000 就是一亿条记录
5,B+树的更正
我们在推演B+树的时候为了方便理解是由最底层开始构建的,实际在B+数的构建过程中是由根节点开始的,当我们的第一页的数据存储满了后我们便将抽取出来的数据项放在第一页中将记录放到第二层中,如果第一页的数据项存储满了,我们便把第一页抽取出来的目录项放在第一页之前的目录项放在第二层,第二层的记录放到第三层
6,聚簇索引,二级索引,联合索引
聚簇索引:
并不是一种新的索引类型而是一种数据存储形式 所有的数据都存在子叶子节点上也就是说索引即数据,数据即索引 这种索引并不需要我们自己手动创建,InnoDB会默认创建,创建规则会按主键的大小进行排序 如果没有主键会采用非空且唯一的字段代替 如果两者都不存在会隐式的创建一个主键 在使用InnoDB时我们默认设置主键为自增主键 每个SQL表有且只有一个聚簇索引
二级索引 :
二级索引也叫做非聚簇索引 当我们查找的条件不是主键时就用到了二级索引

与聚簇索引不同的是二级索引的数用户记录只有两部分一个是建立索引的字段值 令一个是主键的值
我们在使用二级索引进行数据查找的时候会进行回表操作,比如我们要通过年龄(这个字段已经建立了索引)来查找一个表中的所有字段 我们通过二级索引查到对应的年龄后根据对应的id去聚簇索引中再次查找便可以得到所有字段的值
联合索引:
当我们的查询条件不再是一个字段的时候比如说是两个字段这个时候我们需要为这个两个字段都建立索引在查询的时候便用的了联合索引

7,目录项的唯一性
我们之前在构建二级索引的目录项的时候一个目录项只有两部分组成 分别是 索引字段和页地址
假如有两个字段值一样的记录我们就无法通过字段值来保证唯一性了(这里页地址不参与唯一性)
这时加入主键就可以保证唯一性了

8,不同存储引擎对B+树索引的支持

注:B+树的官方叫法为B-Tree
Memory 的默认索引时hash索引但也支持B+树索引
InnoDB 中的索引分为聚簇索引和非聚簇索引
MyISAM 的叶子节点存放的并不是数据而是地址因此MyISAM的索引为二级索引
9,MyISAM的索引
MyISAM的把数据和索引分开存储的 .myd文件用来存放数据 .myi用来存放索引 .frm用来存储表结构
MyISAM的索引结构
叶子节点的存放的数据为 索引字段值+数据记录地址 页被存满后之抽取索引字段

10,B树和B+树的区别
B树结构如下
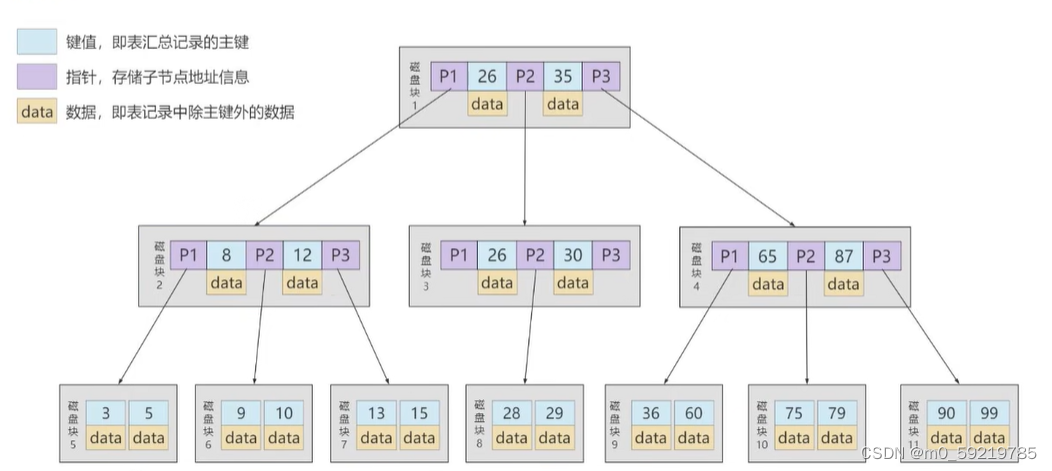
通过与B+树的对比,两种最大区别就是B树叶子节点和非叶子节点都会存储完整的数据,这就会导致相同的数据量B树的层数就更多














 6397
6397











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









