







 本文详细描述了如何使用Python爬取中国网的新闻数据,包括制作Excel索引(抓取并保存新闻标题、链接和发布时间),以及将部分新闻正文内容保存为Word文档。通过requests和BeautifulSoup库处理静态和部分动态网页,最后将数据转换并存储为Excel和Word文件。
本文详细描述了如何使用Python爬取中国网的新闻数据,包括制作Excel索引(抓取并保存新闻标题、链接和发布时间),以及将部分新闻正文内容保存为Word文档。通过requests和BeautifulSoup库处理静态和部分动态网页,最后将数据转换并存储为Excel和Word文件。
一、制作新闻的Excel索引
-
观察网页
-
导入相关库
-
请求数据
-
解析数据
-
保存excel文件
二、将新闻正文内容保存为word
-
观察网页
-
导入相关库
-
对子网页的内容进行爬取并保存成word:以一个子网页为例
-
1、请求数据
-
2、解析数据并存储word
-
循环爬取多个子网页的内容并保存成word
三、全套代码及运行结果
一、制作新闻的Excel索引
观察网页
首先进入网页:http://news.china.com.cn/node_7247300.htm,再通过翻页,对比第1页,第2页以及最后1页的网址,发现它们之间存在着差别,则此网页为静态网页。
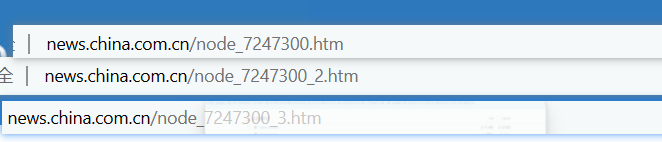
根据对比,除了第一页网址不同外,其他页面下的网址为http://news.china.com.cn/node_7247300_{i}.htm,i为其页码,在之后的爬取中,可用for循环和if-else来对不同的页面数据进行爬取。
导入相关库
引入所需的第三方库,代码如下:
import requests import pandas as pd from bs4 import Beautifulsoup
请求数据
对于静态网页,我们可用Requests库请求数据。先点击“网页”后刷新网页找到所需的第一个链接“node_7247300.htm”,再点击“标头”可知,网页的请求方式为“GET”。

运行代码,显示Requests[200],即请求成功,则无需伪装请求头。但为防止乱码,我们使用r.encoding=r.apparent_encoding。过程如下:
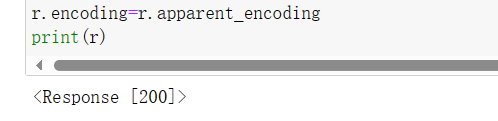
import requests from bs4 import BeautifulSoup import pandas as pd items = [] url='http://news.china.com.cn/node_7247300.htm' r=requests.get(url) r.encoding=r.apparent_encoding print(r)
解析数据
检查页面,发现所有新闻都储存在‘div’标签下的class_="layout_news"中,每行新闻在上述标签的‘div’,class_="plist1_p"标签下,且在此标签‘h2’下不同新闻的子链接位于’a’标签的’href’中,新闻标题位于’h2’标签中,对应新闻发布时间位于’div’,class_="time"标签中。因此,可以采用BeautifulSoup库解析数据。
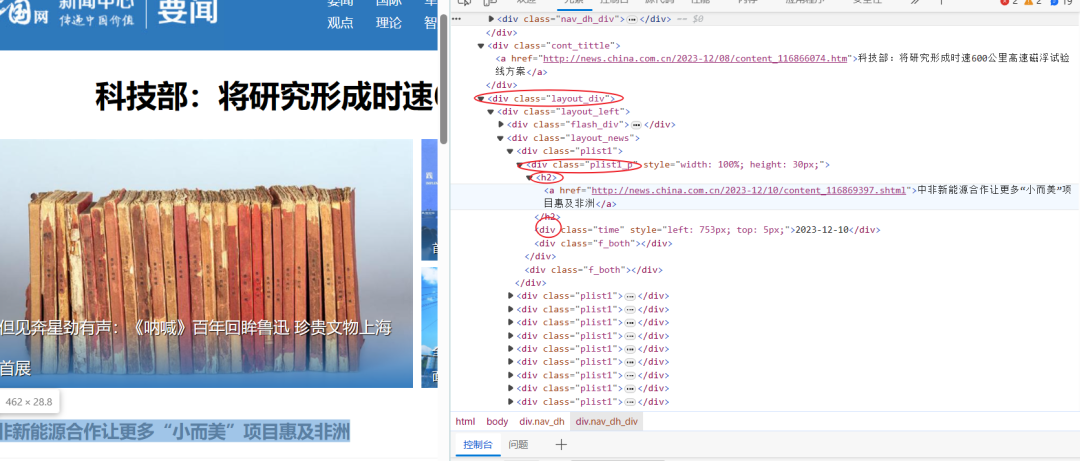
由前面的分析,知除首页外,通用网址为http://news.china
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









