






前言
本资源包为您带来革命性的ComfyUI一站式解决方案,包含精心优化的整合安装包与1000+套即用型工作流模板,助您零基础开启专业级AI创作。无论是角色设计、场景构建还是艺术风格转换,这些经过商业项目验证的工作流都能大幅提升您的创作效率。
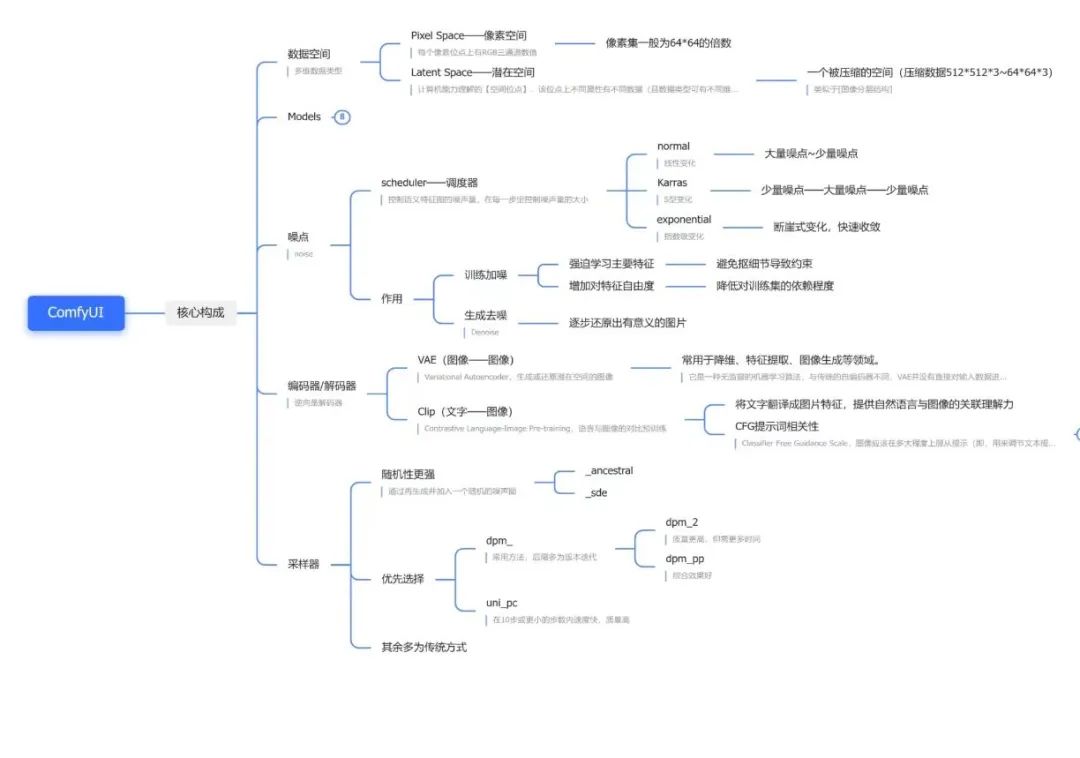
一、SD主流 UI
Stable
Diffusion(SD)因为其开源特性,有着较高的受欢迎程度,并且基于SD的开源社区及教程、插件等,都是所有工具里最多的。基于SD,有不同的操作界面,可以理解为一个工具的不同客户端。WebUI和ComfyUI是两种较为流行的操作界面选项
- WebUI :
优点 :界面友好,插件丰富,新手小白基本也能秒上手
缺点 :吃显存,对配置要求较高,出图较慢
- ComfyUI :
优点 :性能好,速度快,支持工作流的导入导出分享,对小显存友好(GPU小于3G以下依然可以工作),基于工作流,对出图逻辑理解更清晰
缺点 :对新手用户不太友好,有一定学习成本
二者各有优缺点,根据自身情况选择即可。
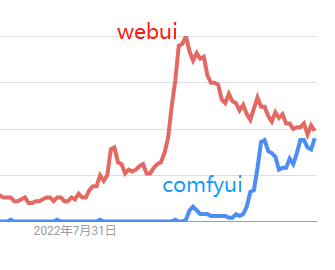
我为什么选择Comfyui?
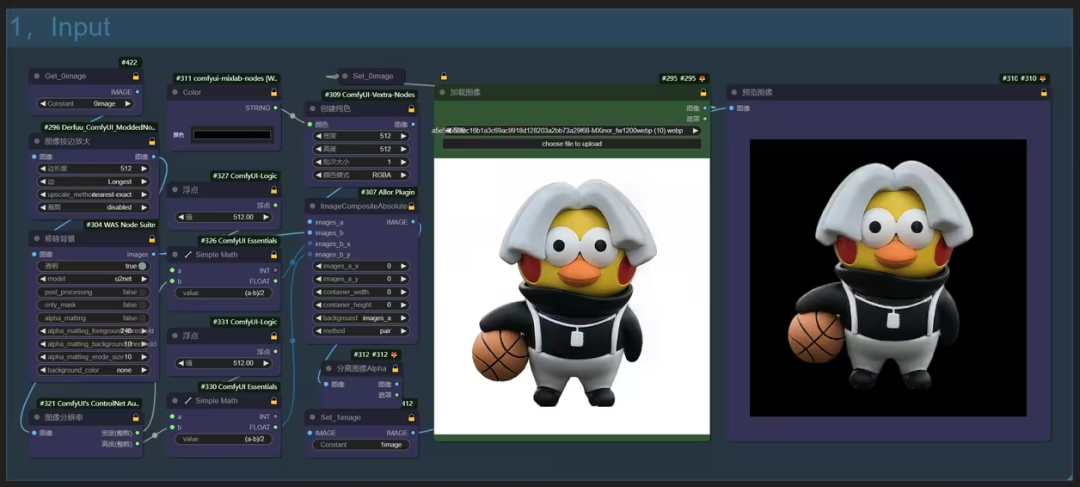
Comfyui的热度持续上升,在谷歌搜索上,有越来越多的人开始关注Comfyui。为什么会有越来越多的人关注?因为大家使用webui久了之后,发现很难对生成过程有完全的控制,或者一张图片的生产不是点击几下就能完成的,它有很多到工序:主体、配景、背景、风格、文字、特效等等各种各样的细节问题需要去控制,如果全部采用webui,操作起来非常麻烦,全部需要反复手工(尤其是要守在电脑前一个个去操作),而采用Comfyui,搭建完工作流程后,只需要点击运行,即可全流程自动完成。
二、ComfyUI 能干啥?
-
1. 基础文生图 -
2. 基础图生图 -
3. 真人转动漫/动漫转真人 -
4. 线稿上色 -
5. 老旧照片修复 -
6. 隐藏艺术字 -
7. 改变人物姿态 -
8. 四维彩超宝宝长相预测 -
9. 红包封面 -
10. 真人电子AI写真定制 -
11. 赛博朋克风格转换 -
12. 专属表情包 -
13. 手机壁纸 -
14. 更多:这里不一一举例了,类似的玩法在网上可以看到很多,ComfyUI只是一个工具,具体如何应用,就要依靠自身的想象力了



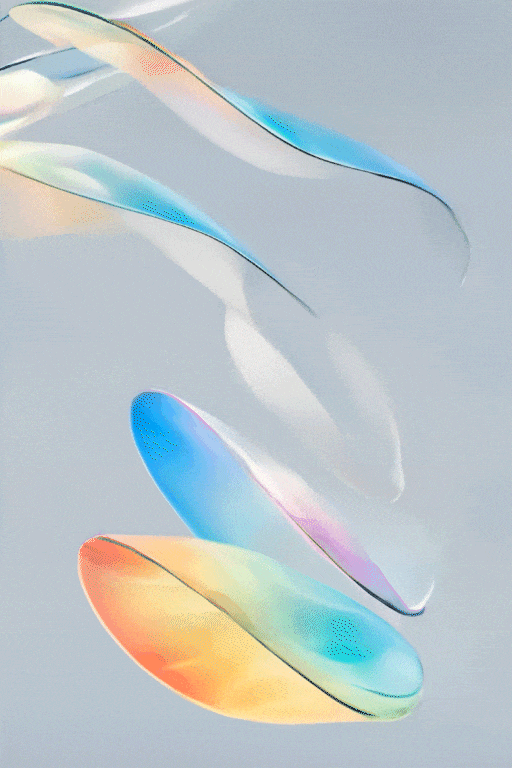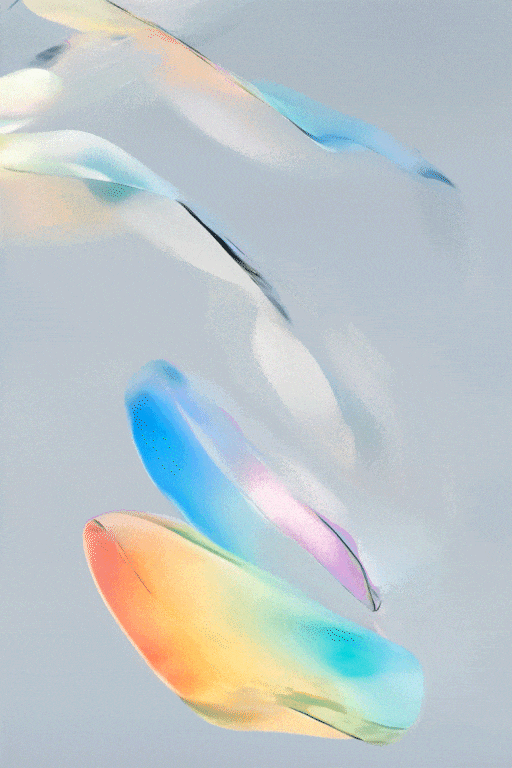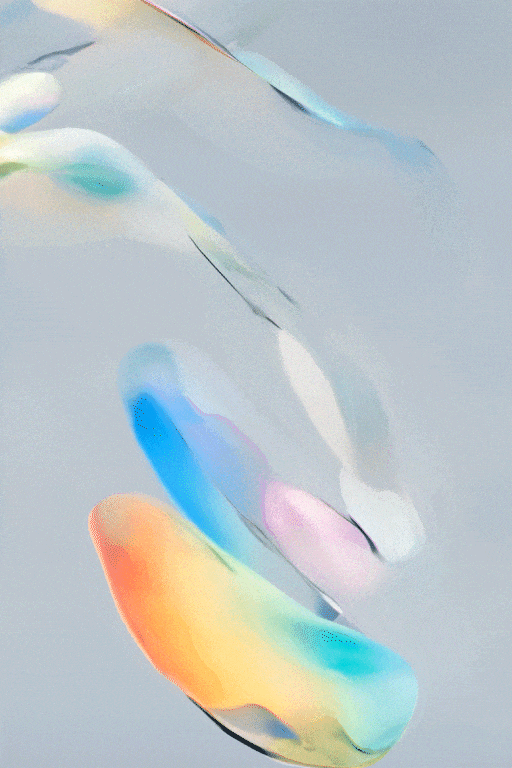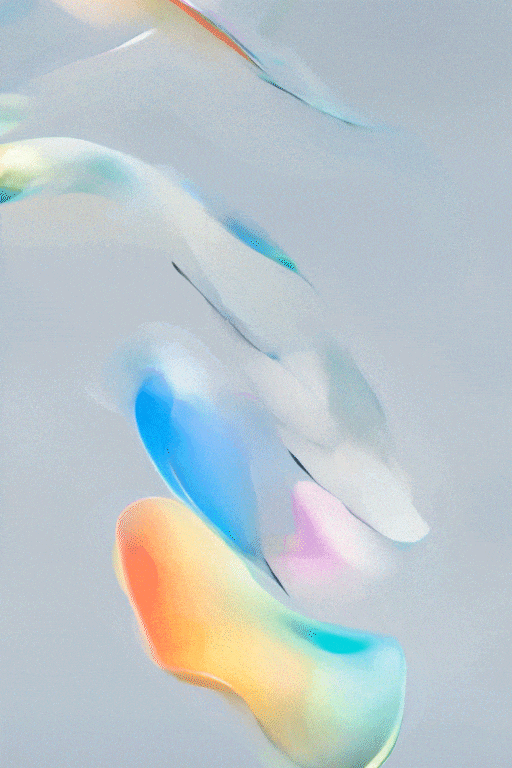
SVD图文转视频的效果展示

ComfyUI 安装方式
1.在b 站或后期圈gzh 下载整合包完成后然后解压。
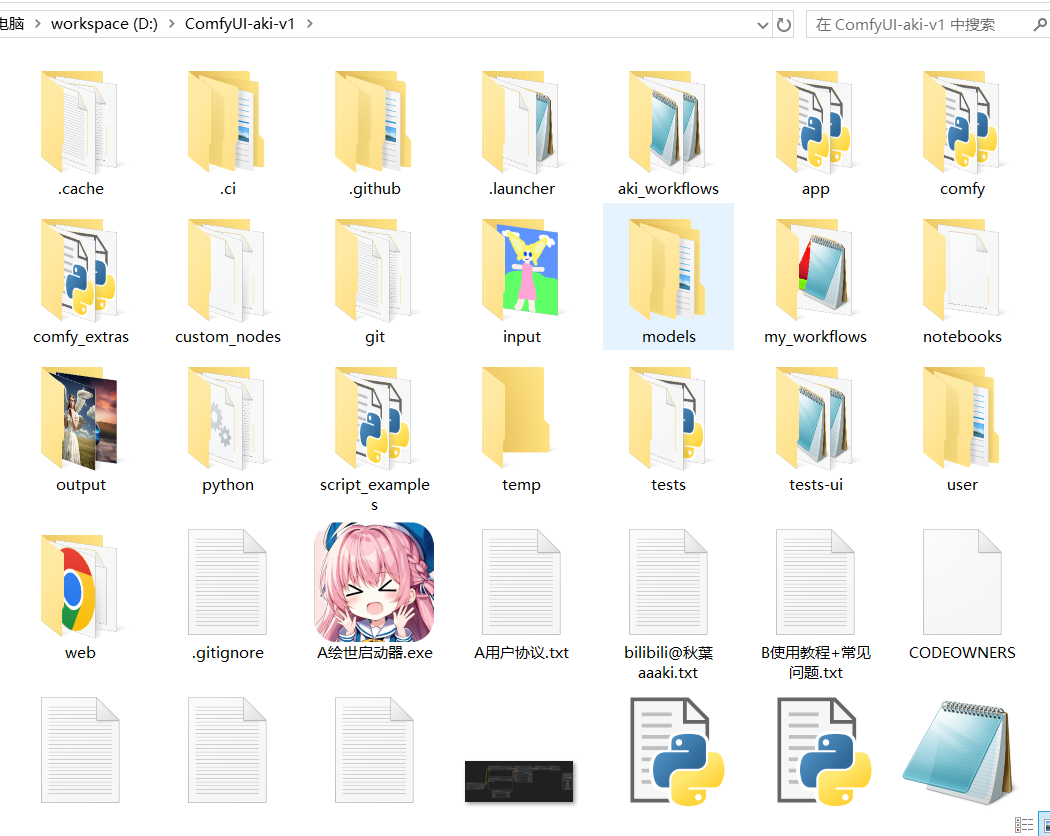
使用的磁盘最好有20g以上的空间,因为再下载一些模型还是比较占用磁盘空间的。
“A绘世启动器.exe”文件即为一键启动文件,可以先不启动,先下载好模型。
下载模型,或者和webui共用模型 模型文件通常以.safetensors结尾。
首先将comfy
ui根目录下的“extra_model_paths.yaml.example”文件重命名为“extra_model_paths.yaml”。
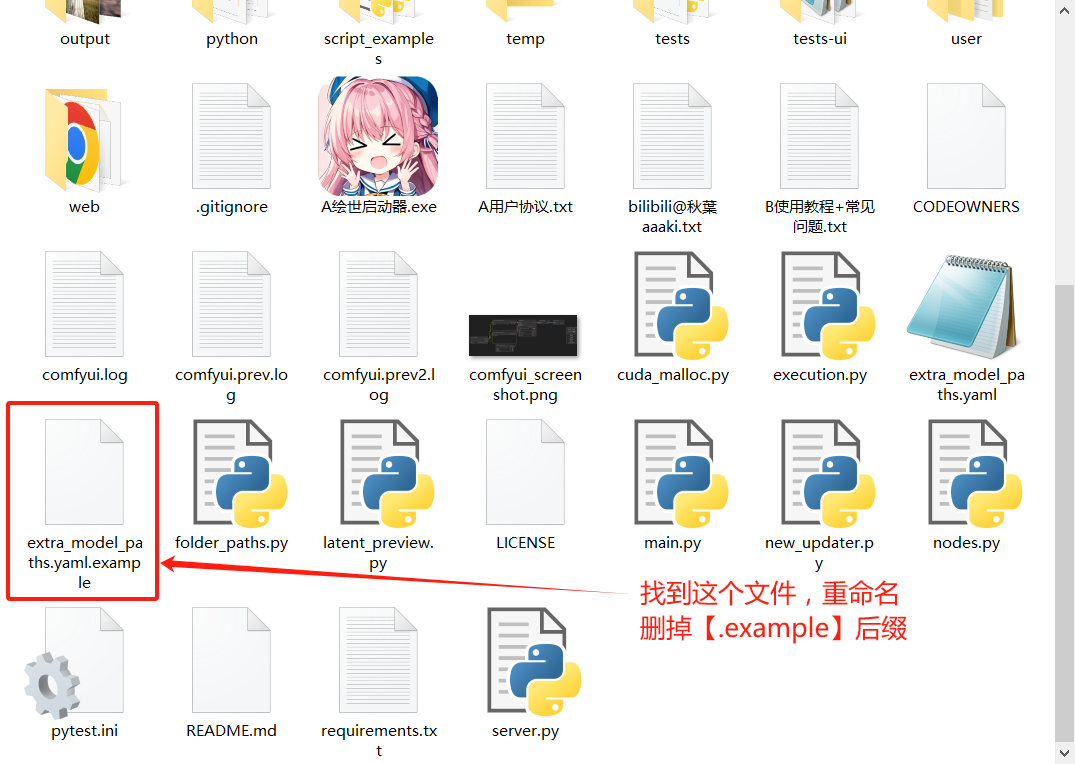
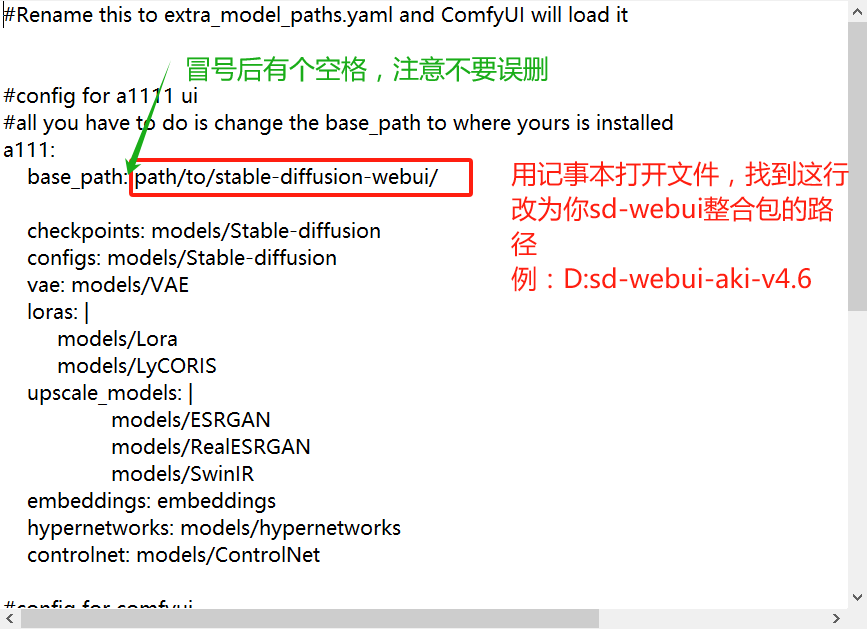
然后将base_path:后面改为你的webui目录:
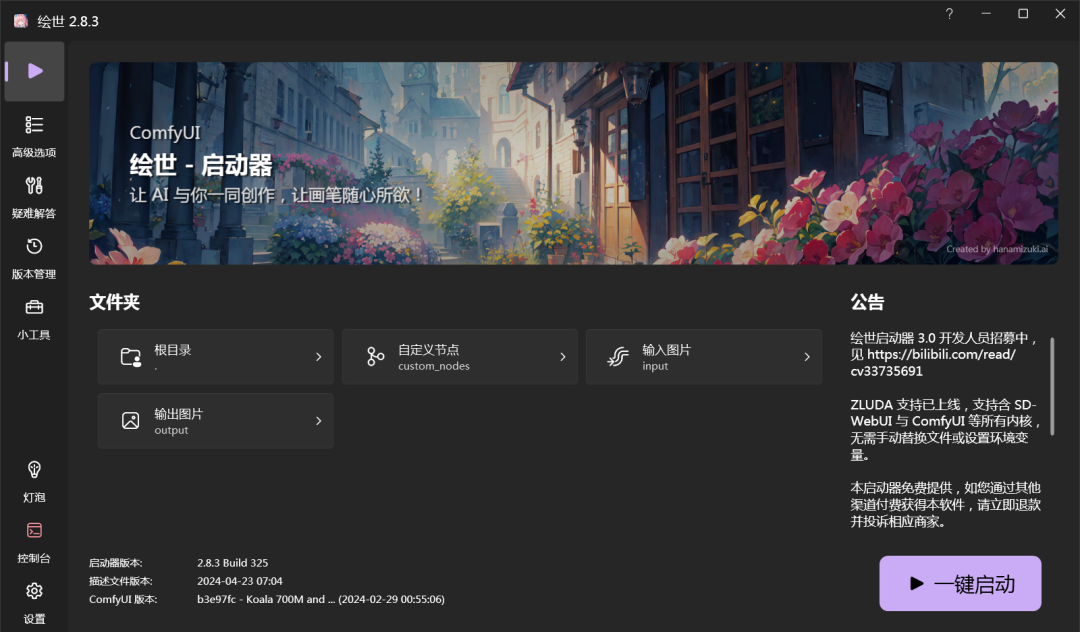
点击“A绘世启动器.exe”。启动后软件会自动更新一些文件,一般不会很久。
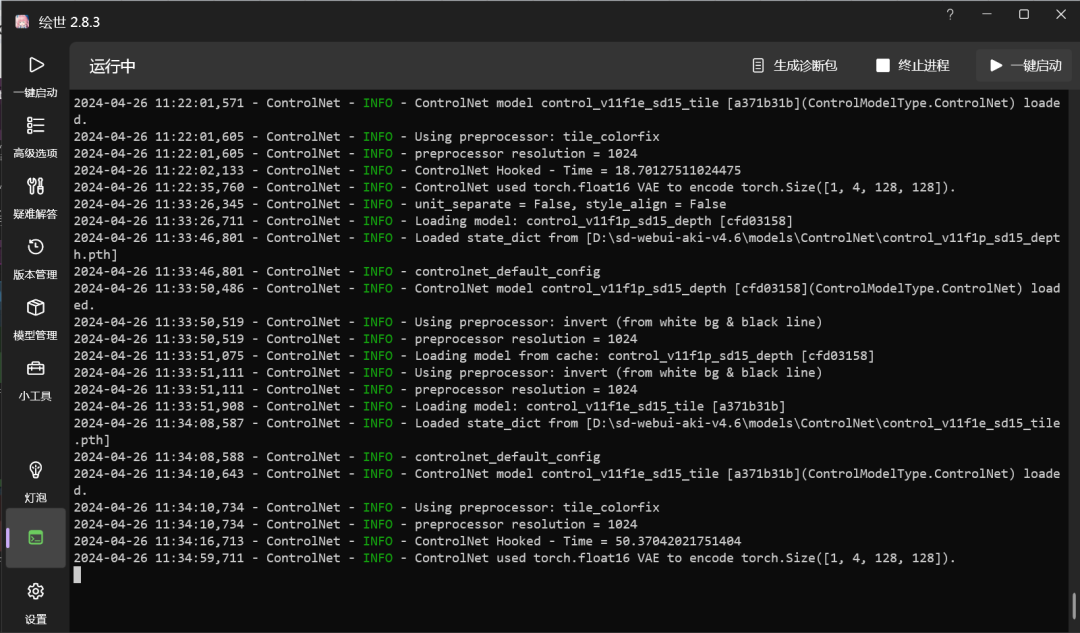
然后点击右下角的“一键启动”,第一次启动,可能比较慢,等一会即可,启动完成会自动打开浏览器。如果使用过程中遇到问题,可以查看左下角“控制台”页面里的日志。
设置中文 第一次打开如果是英文,可以设置一下语言。先点击小齿轮,进入设置页面:
然后滑到最下面,找到:AGLTranslation-langualge选项,改为中文即可。

ComfyUI 工作流基础教程
No.1
文生图工作流
原理简介
1、首先将prompt文本 转换为词特征向量
2、词特征向量 和随机图向量 一起encode降维输入潜空间 ,进行屡次降噪
输出图 = 输入图 -【(根据prompt预测的噪声+根据随机图预测的噪声-根据随机图预测的噪声)* 权重系数 +根据随机图预测的噪声】* 降噪次数
3、输出数据decode
在软件中,已经内置了许多工作流模版,下图对文生图作为基础工作流的各模块进行一个简单介绍。
下图中工作流对应文生图原理,根据Base Model生成词特征向量和随机图进行解码、屡次降噪、并编码生成图片。

ComfyUI 文生图基本工作流
提示词撰写
写提示词需要注意,长度约60字,SD的提示词不像自然语言生图的工具直接组织为句子输入,输入形式为关键词排列,越关键的越靠前,或使用权重设置如(keyword:1.4)提高权重;(keyword:0.7)降低权重
Prompt内容一般包含
-
主体
-
环境(地点,灯光,天气)
-
作画形式(油画、水粉、素描、相机……)
-
风格(年代、人物、艺术类型、国家……)
其他注意事项
-
构图建议使用图生图
-
在prompt中使用别人训练好的embedding模型可以生成特定的视觉特征(某特定人物、某物种……)
embedding:filename
尺寸设置
宽和高必须是8的倍数,Batch_size决定了一次生成多少张图像(可能影响速度,建议一次一张)

尺寸设置参数
采样器参数设置
(参数设置可以参考模型作者提供的最佳方案)
**Seed:**随机种子数,这个数字控制每次生成的图片相似程度,图片需要保持一致的时候,该数字不变
Control-after-generated:
生成完之后种子数的变化情况设置
**Step:**降噪步数
CFG :Prompt权重系数(一般6-8)
**Sampler-name:**采样器名称
**Scheduler:**调度器名称(降噪)
**Denoise:**初始噪声(文生图一般为1)
Lora配置
添加lora模块,更改clip、model连线,更换作者推荐的Vae模块等其他参数
添加模块
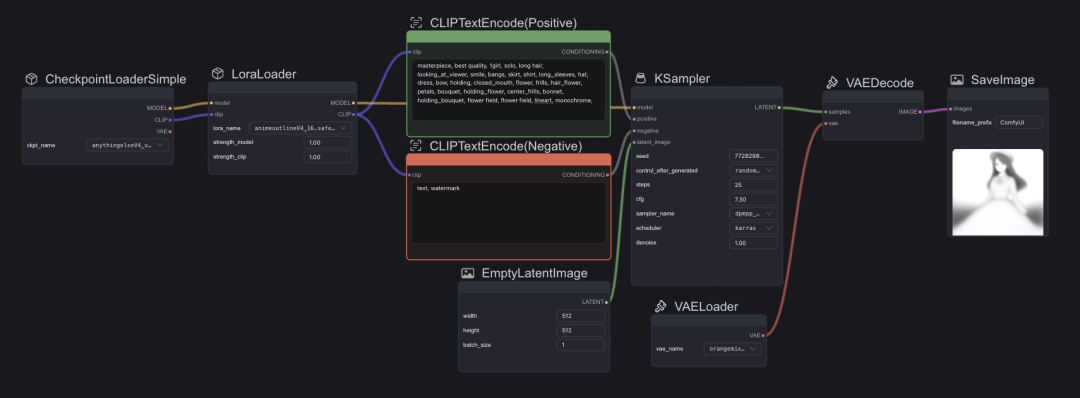
启动
此时设置完所有的模型和参数,按照教程的参数设置运行后依然会发现出图很糊,据说M系列Mac容易遇到该问题,根据教程,在终端pip安装
torchvision==0.16.2,成功解决该问题。
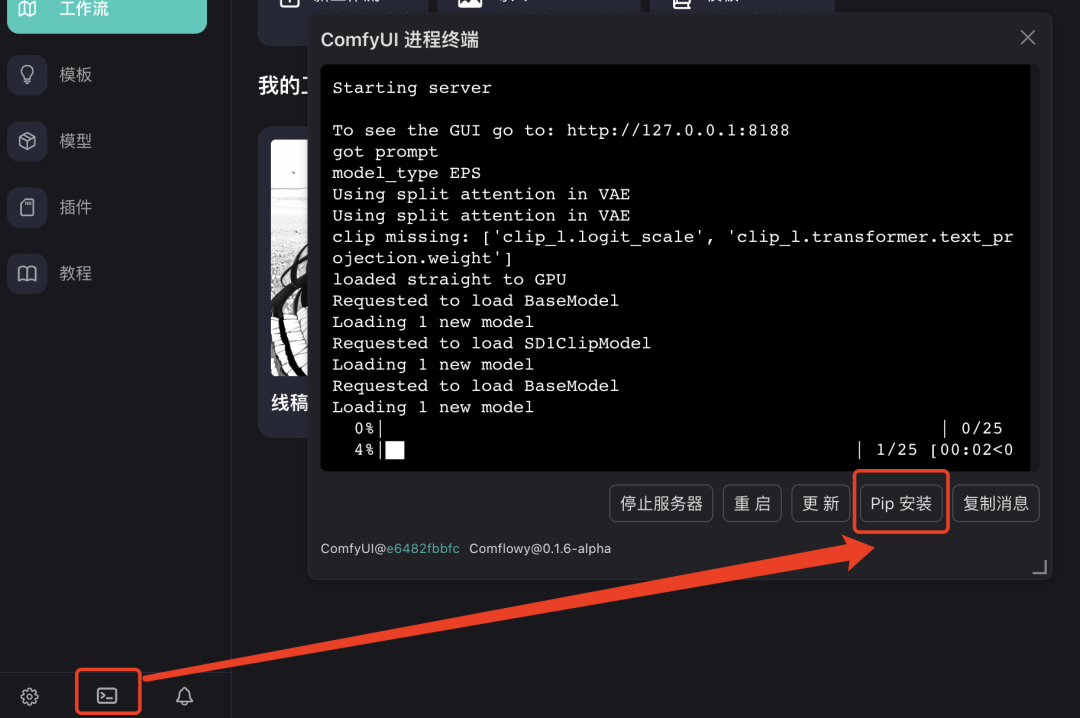
打开终端进行pip安装,输入 torchvision==0.16.2
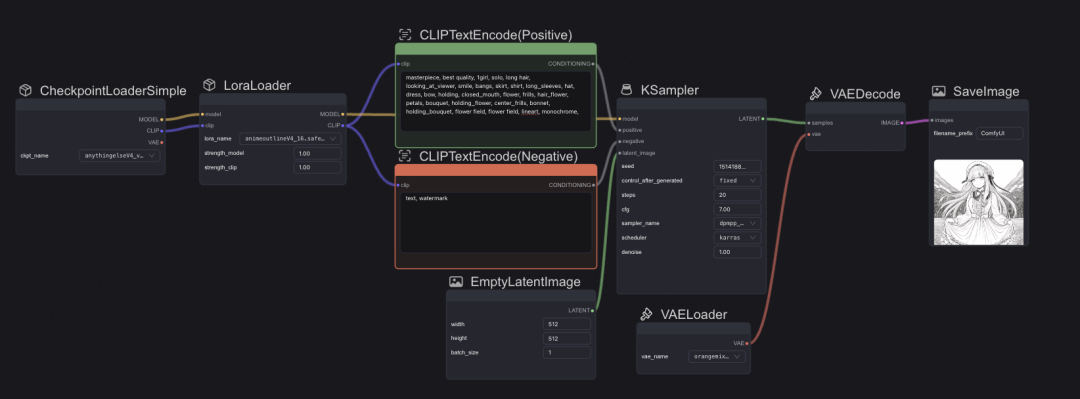
解决图片输出模糊的问题
No.2
图生图工作流
方法一:重绘 - 基于输入图进行重新绘制
输入图代替随机图,和文字一起作为潜空间的输入。
方法二:参考 - 基于输入图参考进行内容补充(unCLIP)、风格迁移(Style)拓展
先对图文进行解码,然后和随机图一起输入潜空间
unCLIP model workflow

对于unCLIP重绘方式,可以直接使用模版搭好的工作流,其中增加了上图所示三个模块,并将初始CheckpointLoader、对应的unclip模型进行替换(模型:sd2.1-unclip,
对应随机图尺寸 768 * 768)
当使用两张图进行元素融合,可以看到结果大致实现将鸭子和水波元素进行了混合,但与预期效果差距较大,但融合的元素难以控制,若要提高符合预期的质量仍然需要进行更多的参数调整。
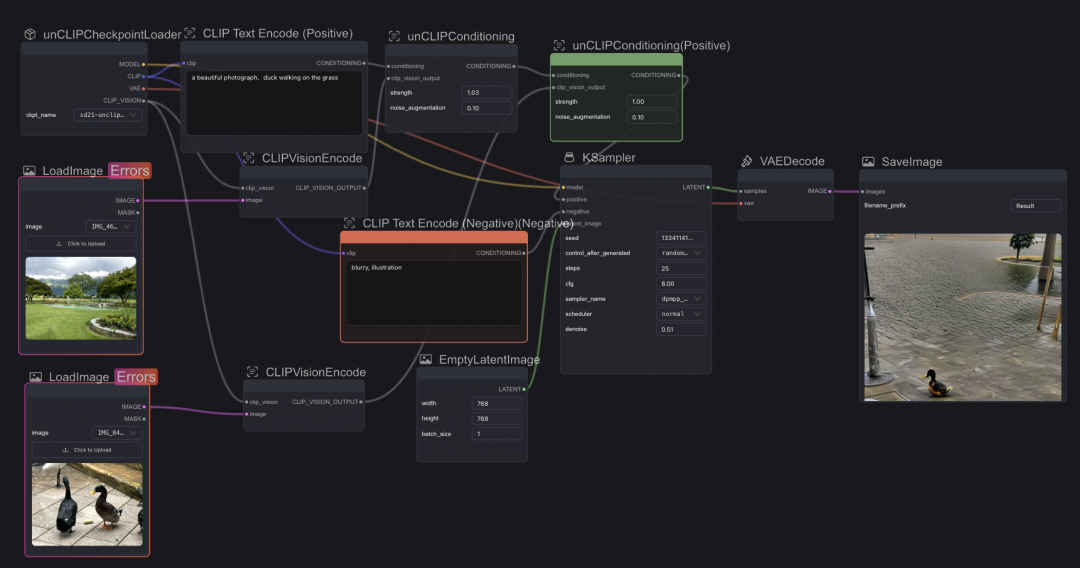
初始输入图片高度调整为768 跑unCLIP工作流
Style model workflow
风格迁移工作流中则需要将上传的图片编码为向量、理解风格、理解提示词,通过Style节点处理后导入采样器,一般为名画、人物雕塑类。
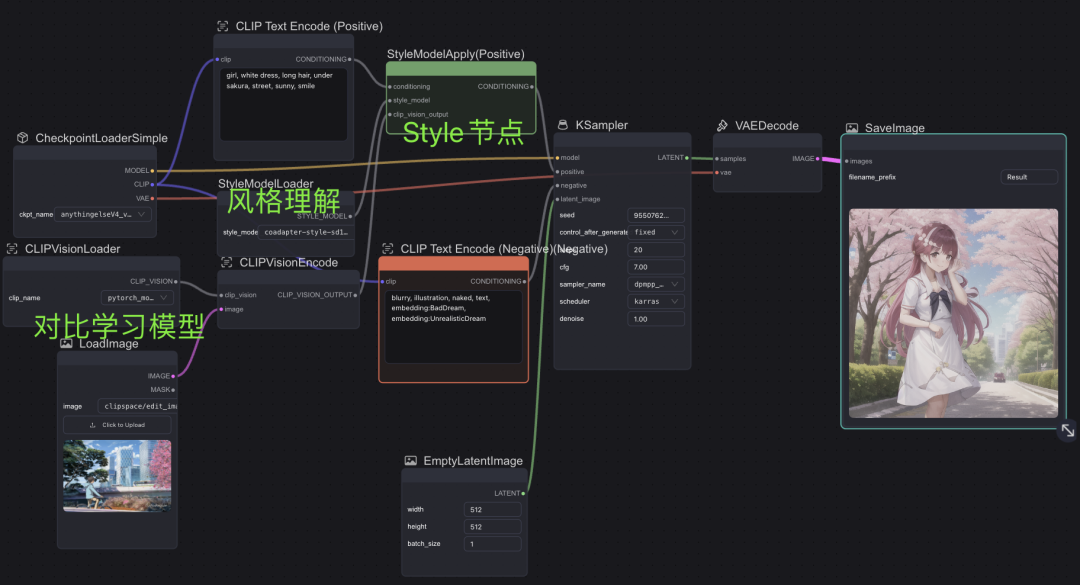
跑Style Model Workflow
此处使用了新海城画风的图片输入,整体而言,风格更加依赖模型,同样参数下,模型AnythingElse为二次元专用生成了左边的效果,DreamShaper为写实风生成了右边的效果,输出图风格更多与模型风格、prompt内容更相关,与上传的风格迁移的参考图片关系不大。

AnythingElse(左),DreamShaper(右)
这份完整版的comfyui整合包已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、ComfyUI配置指南
- 报错指南
- 环境配置
- 脚本更新
- 后记
- …
二、ComfyUI基础入门
- 软件安装篇
- 插件安装篇
- …
三、 ComfyUI工作流节点/底层逻辑详解
- ComfyUI 基础概念理解
- Stable diffusion 工作原理
- 工作流底层逻辑
- 必备插件补全
- …
四、ComfyUI节点技巧进阶/多模型串联
- 节点进阶详解
- 提词技巧精通
- 多模型节点串联
- …
五、ComfyUI遮罩修改重绘/Inpenting模块详解
- 图像分辨率
- 姿势
- …

六、ComfyUI超实用SDXL工作流手把手搭建
- Refined模型
- SDXL风格化提示词
- SDXL工作流搭建
- …

这里直接将该软件分享出来给大家吧~
这份完整版的comfyui整合包已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
1.stable diffusion安装包
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.SD从0到落地实战演练

如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名SD大神的正确特征了。
这份完整版的comfyui整合包已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 1286
1286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









