









 该论文提出了一种利用知识增强的深度学习方法来生成音乐旋律,首先通过构建旋律骨架来定义音乐的重要音符,然后动态填充装饰音。这种方法旨在解决数据驱动方法中的结构稀疏问题,提供音乐生成的可控性。研究包括节奏和音高两个维度的旋律骨架提取,并通过Transformer-XL和循环Transformer模型进行生成。主观评价显示结合节奏和音调骨架的效果最佳。
该论文提出了一种利用知识增强的深度学习方法来生成音乐旋律,首先通过构建旋律骨架来定义音乐的重要音符,然后动态填充装饰音。这种方法旨在解决数据驱动方法中的结构稀疏问题,提供音乐生成的可控性。研究包括节奏和音高两个维度的旋律骨架提取,并通过Transformer-XL和循环Transformer模型进行生成。主观评价显示结合节奏和音调骨架的效果最佳。
记录一下所阅读的大佬论文。

吴云:利用知识增强的深度学习探索分层骨骼引导的旋律生成
看标题一头雾水。。
//
摘要写的很明了,用知识增强先生成旋律的重要音符来构建音乐结构,之后动态的(不理解)将装饰音进行填充。主观评价指标(。。。懂得都懂)
研究提供了一个多学科的视角来设计旋律层次结构,并弥合了数据驱动和基于知识的方法之间的差距,用于许多音乐生成任务。(论文原文)
正文:
引言部分列了今年来旋律生成的发展,引用了Pop Music Transformer ,Popmag,Musenet等一众主流模型,随后引出论文出发点:在当前数据驱动为核心的端到端为主流的方法中,旋律数据稀疏问题导致生成的旋律中出现不合理的音符等现象;以及音乐生成的可控性。
论文出发点没什么新意,毕竟结构问题是目前音乐生成领域的一个大的困惑点。。
结构化音乐生成方法:
1:首先生成音乐的层次结构表示或者小节级的音乐结构关系图,并以这种并行结构作为附加信息进而生成旋律;
缺点:前提是需要识别音乐的表层层次结构,已提取音乐的长期结构特征,但音乐结构边界算法的研究不足阻碍了改策略的发展。且很少有人关注旋律之下的深层结构的组织逻辑,它是由各种音乐事件之间不同的结构重要性层次组织起来的。(理解为结构的结构,套娃)。
2:大多数方法还是遵顼从左到右的(端到端)旋律生成方法,平等的对待每一个音符(理解为构成音乐结构的音乐可视为重要的音符,其他为修饰音)。
旋律骨架提取框架:
悟韵(Wuyun)的核心理念:音乐旋律骨骼架构
从音高和节奏两个维度出发,确定旋律音符之间结构重要性的主导和从属关系。
节奏维度:
不同音符分辨率下4/4拍子强弱拍子分布的节奏模式。

节奏的骨骼提取。节奏骨架由每个小节的格律重音、格律重音上的agogic重音和切分音上的agogic重音组成。(延长音符的持续时间(agogic重音))
乐理知识:格律重音和节奏重音是符号旋律资料中的两种主要重音。格律重音是落在一个小节的强拍位置上的重音。格律重音具有周期性和循环性,其分布模式取决于格律的类型。节奏重音是在节奏中处于强势位置的重音,它强调的是不受拍子结构限制的一点。

C:带有C大调弦的螺旋阵列的螺距级螺旋中的张力测量示意图。图中右侧为“Hey Jude”旋律前八小节音符的张力值。(D)音调骨架提取。音调骨架由节奏单元中张力值最小的音符组成。
越重要的音符张力越小。
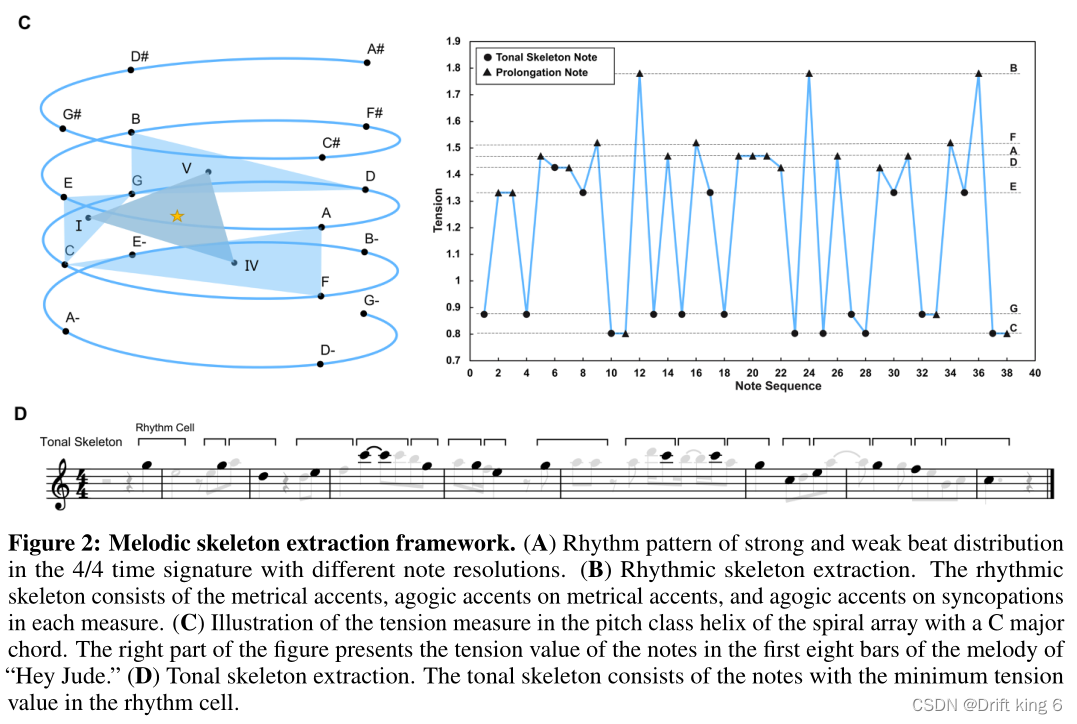
音乐骨骼架构标准:
1.使用节奏骨架音符的位置作为个体语境的边界;
2.根据旋律的重复频和该节奏单元的音符数量,将两个或三个连续的音符组合在一起作为每个片段中的最小节奏单元。“节奏单元”一词定义为“小的节奏和旋律设计,可以孤立或可以构成主题上下文的一部分。
3.采用数学音调张力模型,通过计算螺旋数组中每个单音与全局键之间的距离来量化每个音符的张力值,选择每个节奏单元中张力值最小的音符作为音调骨架音符。
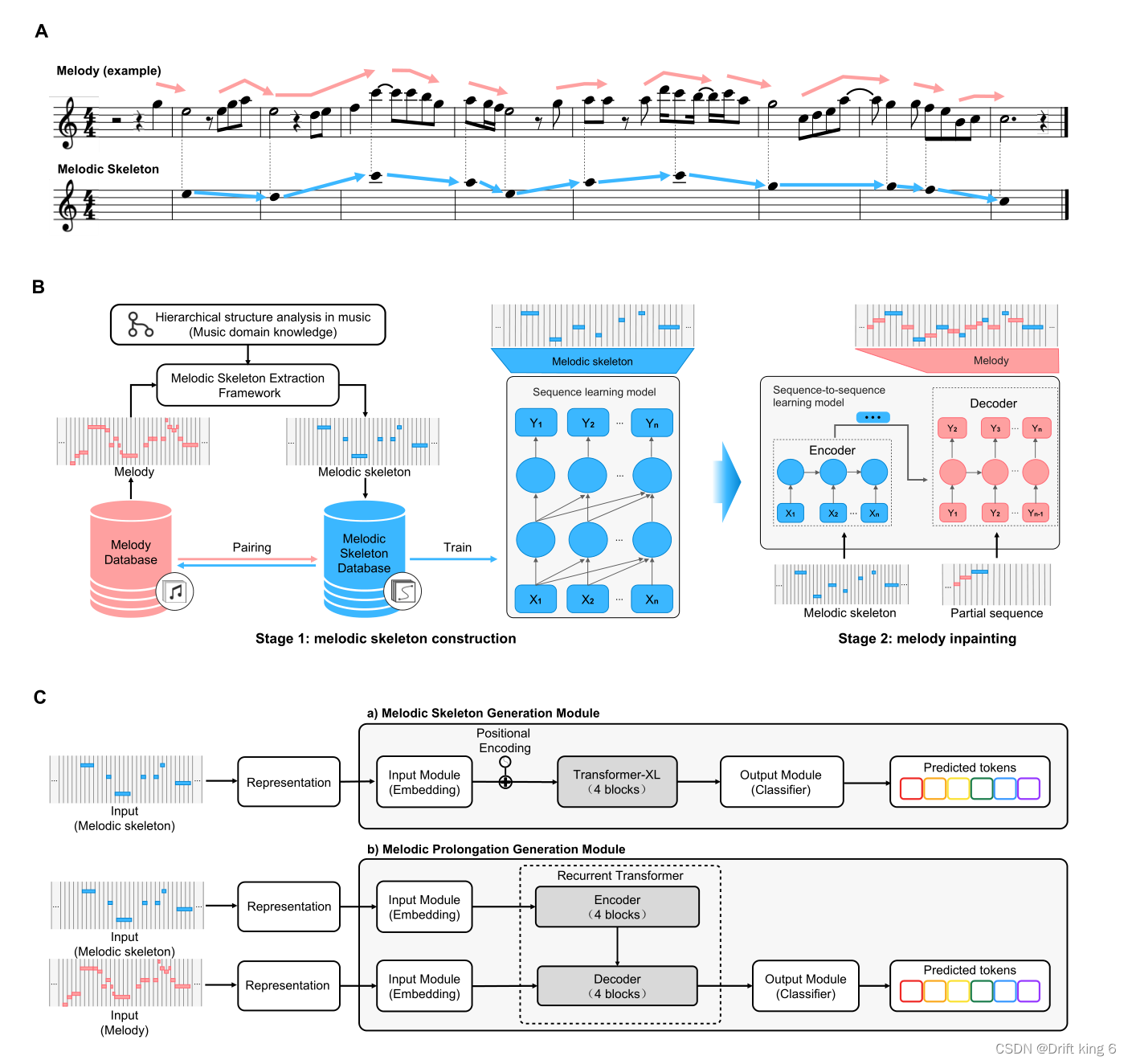
WUYUN架构:如图
首先,利用MeMIDI符号音乐表示方法将旋律MIDI文件及其旋律骨架转换为音乐事件序列作为模型训练的输入数据;
然后,设计了一个分层的旋律生成体系结构,其中有两个生成模块分别负责旋律骨架的构建和旋律的修补。
在旋律骨架构建阶段,使用Transformer-XL模型,仅使用解码器作为旋律骨架生成模块,在捕获长期依赖方面具有显著的性能优势。为了提高旋律骨架构建的能力,在提取的旋律骨架数据库上训练Transformer-XL模型。
在旋律修补阶段,在一个序列到序列的设置中使用基于循环Transformer(应该是直接使用Popmag,也是本团队的成果)的编码器-解码器架构作为旋律修补模块,以旋律骨架为条件完成旋律,即填充旋律骨架音符之间的缺失信息。
在本文中,旋律修补问题可以定义为:给定一个旋律骨架序列Cs,生成一个旋律补绘序列Cm。编码器将旋律骨架序列的离散输入符号c映射为高维连续向量,作为条件输入输入解码器,解码器以自回归的方式生成输出序列Cm。旋律骨架序列将保存在最终生成的旋律中。该方法为用户提供了一个与旋律生成模型交互的入口,通过在两个阶段之间调整旋律骨架音符来控制旋律运动。
在这项工作中,我们重点设计了基于知识增强深度学习的分层骨架引导旋律生成架构,遵循结构和延伸的分层组织原则。因此,我们在NLP中使用公共语言模型来使WuY un体系结构易于访问。这两个生成模块的能力可以进一步优化;然而,本研究的目标并不是找到最优的神经网络。(说的很直白)
评价指标:
虽然音乐生成的研究领域是多学科的,但大多数研究人员主要关注的是具有不同改进目标的生成模型,而不是它们对量化音乐复杂性的贡献。因此,几乎所有提出的客观评价指标都难以应用于比较不同的音乐创作系统,并且对未来的发展需求缺乏可持续性。(统一的客观评价指标难以指定的原因,之一,这句话挺受用)。
写上述内容主要是为了解释一下文章使用了主观评价指标的原因,但文章中“更好的客观评价结果并不意味着更好的生成音乐的结构和音乐性”的描述总感觉有些此地无银三百两的意思。。。(我瞎说的)
主观评价:李克特五分制量表。
对比实验:为了比较从节奏维度和音高维度提取的旋律骨架变体的效果,基于旋律骨架的不同设置对WuYun的表现进行了综合评估:
1.Downbeat(强拍)只使用格律重音作为旋律骨架(32.8%)。
2. Long Note(长音)只使用了重音作为旋律骨架(27.4%)。
3.节奏用有节奏的骨架音符作为旋律骨架(33.8%)。
4. Tonic (主音)以主调骨架音符为旋律骨架(43.2%)。
5. 交互使用节奏骨架音符和音调骨架音符的交集作为旋律骨架(14.2%)。
6. 韵律骨架音与调性骨架音的结合作为旋律骨架音(62.8%)。
7. 随机选择25%的旋律音符作为旋律骨架(25%)。
8. 随机选取50%旋律音符作为旋律骨架(50%)。
9. 随机选择75%的旋律音符作为旋律骨架(75%)。

结果:
与一些SOTA(均为端到端)比较:如上图
总结:本文以生成结构性更强的音乐旋律为出发点,设计了一个两段式的音乐生成架构。根据音乐分析和作曲理念等专业知识,从旋律和节奏两个维度,对音乐序列中的重要音符进行定义,界定出音乐结构的骨骼,进行使用骨骼序列训练网络,进而将骨骼架构作为条件,在此基础上添枝加叶,生成最终的音乐。本文并没有在神经网络上进行过多的探索,个人感觉以后的音乐AI发展,音乐专业知识的重要性会越来越明显。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









