







以下我们在Centos7操作系统上以Elasticdump为例来进行一下安装
环境准备
开始安装
使用elasticdump工具需要使用到npm,所以需要安装相关的依赖
安装NODE(如果已有可跳过)
- 进入到/opt/app目录下,下载并解压node
wget https://nodejs.org/dist/v10.15.0/node-v10.15.0-linux-x64.tar.xz
tar -xf node-v10.15.0-linux-x64.tar.xz
- 配置环境变量
vim /etc/profile
PATH=$PATH:/opt/app/node-v10.15.0-linux-x64/bin
- 保存退出,让环境变量生效
source /etc/profile
通过npm安装elasticdump
本地安装和全局安装的区别在于它是否自动给你设置环境变量,其他的没有区别
-
本地安装
npm install elasticdump- 使用命令:
/opt/app/node_modules/elasticdump/bin/elasticdump
- 使用命令:
-
全局安装
npm install elasticdump -g- 使用命令:
elasticdump
- 使用命令:
导入导出
通用命令
# 全量
elasticdump --input Es地址/Es索引 --output Es地址/Es索引 --type=类型
# 部分
elasticdump --input Es地址/Es索引 --output Es地址/Es索引 --searchBody "{\"query\":{\"term\":{\"username\": \"admin\"}}}"
-
参数解释说明
- input可以为Es中的某个索引,也可以为Json文件
- output可以为Es中的某个索引,也可以为Json文件
- 类型可以为:data/mapping/analyzer
- 如果想一次性操作某个类型对应的所有的index,则需要input和output后面无需跟索引名称,需要指定–all=true即可
- 导出为文件,–overwrite=true,覆盖写入
- 指定每一批处理多少条,–limit=xxxx(default:100)
- 要检索多少个对象,–size=xxxx(-1代表无限制)
- 并发性,–concurrency=xxxx(default:1)
- 添加自定义参数,–params
- 添加headers,–headers {“User-Agent”: “elasticdump”}
示例一:数据导出为JSON文件
elasticdump --input {protocol}://{host}:{port}/{index} --output ./data.json --type=data
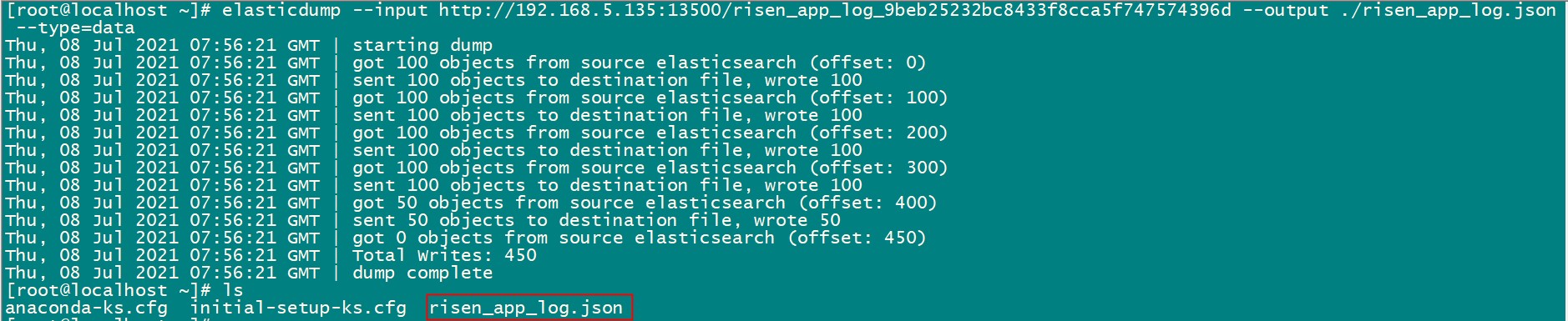
- 导出数据为JSON文件Demo示例
elasticdump --input http://192.168.5.135:13500/risen_app_log_9beb25232bc8433f8cca5f747574396d --output ./risen_app_log.json --type=data
示例二:数据直接导入到Es
elasticdump --input {protocol}://{host}:{port}/{index} --output {protocol}://{host}:{port}/{index} --type=data
示例三:mapping导出为JSON文件
elasticdump --input {protocol}://{host}:{port}/{index} --output ./mapping.json --type=mapping
示例四:mapping直接导入到Es
elasticdump --input {protocol}://{host}:{port}/{index} --output {protocol}://{host}:{port}/{index} --type=mapping
示例五:分词器导出为JSON文件
elasticdump --input {protocol}://{host}:{port}/{index} --output ./analyzer.json --type=analyzer
示例六:mapping直接导入到Es
elasticdump --input {protocol}://{host}:{port}/{index} --output {protocol}://{host}:{port}/{index} --type=analyzer
JSON文件导入
导入顺序最好按照:analyzer,mapping,data这个顺序,防止出现分词实效,除非你没有analyzer
- 注意事项
- 在需要导入的ES创建索引,并且保持索引和type和mapping文件中的一致
- 是否存在mapping.json,这个取决于你是否导出,没倒出也可以自己手动建立
- 否存在相同索引(是否为同一ES中),存在需要修改导出的mapping.json中的索引信息,不存在可以直接导入
elasticdump --input ./data.json --output {protocol}://{host}:{port} --type=data
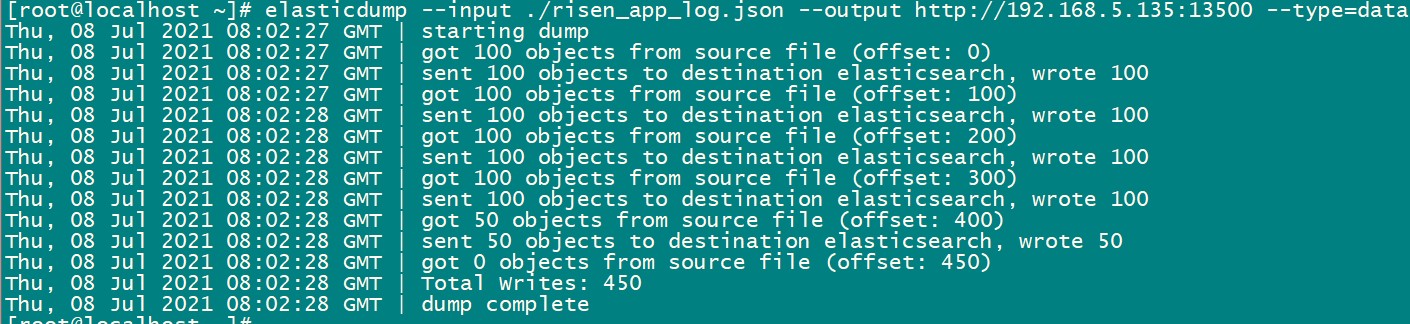
以上就是针对elasticsearch的数据导入导出简单的示例了,当然elasticdump还有更多的指定配置项。



















 4181
4181

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











