






需要对一组超阈值序列进行拟合分布,经查找相关资料,了解到年最值序列一般使用广义极值分布(GEV分布),超阈值序列一般符合广义帕累托分布(GPD分布),对于两种分布各自的介绍即理论知识网上已经很多了,一搜一大把,但是具体怎么在编程软件中进行却很难搜到直接的教程,相关资料比较少,还是我查阅方式有问题。耗费了我好久的时间各种搜索,浪费了好多时间,最终发现果然还是官网帮助文档是永远的王道!
最后探索出了在MATLAB和R中进行的方法,其实很简单,是我自己!不懂!才折腾了很久,分享一下,能够为和我一样的人提供一些帮助就很好了!
(先码个开头,等这一阵忙过了码字码字)
更新更新!不好意思,最近太忙没时间码字,拖了这么久,直接把代码放上吧,也就不过多解释了
1. 数据序列的制备
年最大值序列AM或超阈值序列POT
2. 分布函数构建与KS检验
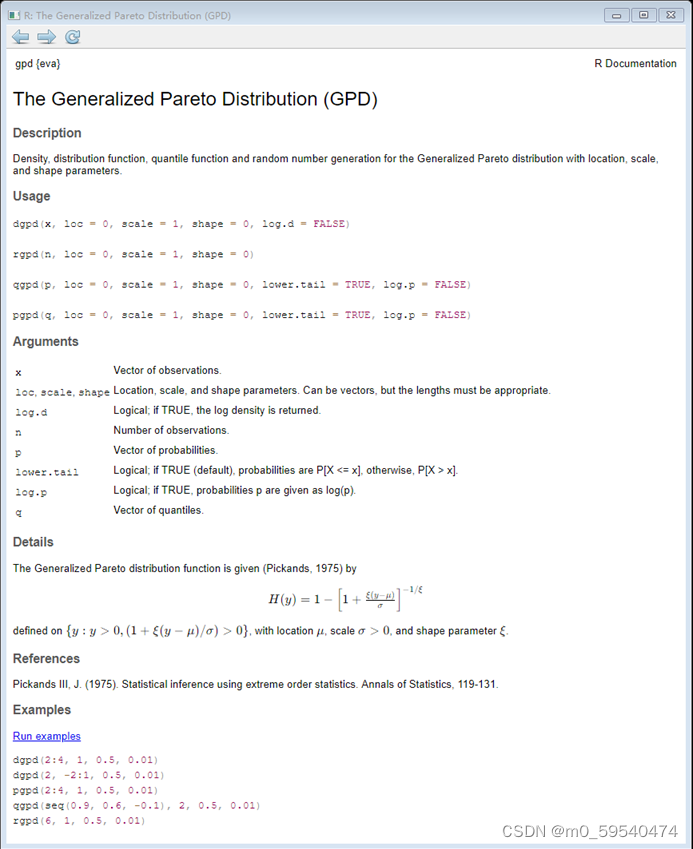
2.1 R语言代码
library(evir)
library(fExtremes)
library(POT)
## 忘记具体是哪一个了,其中之一
#AM序列---GEV拟合分布
yam <- as.numeric(am)
#拟合
a <- gev(yam)
#三个参数
xi = a$par.ests[1]
sigma = a$par.ests[2]
mu = a$par.ests[3]
#检验
kt <- ks.test(yam, "pgev", mu, sigma, xi)
#POT序列---GPD拟合分布
#原始数据序列
p1 = pr
p1th = quantile(p1, 0.99, type = 1) #阈值
p2 = p1[p1>p1th]-p1th ###注意这里最后构建分布的需要是减去阈值之后的序列p2
#拟合
a <- gpd(p2, threshold = 0, method = "ml")
#两个参数
sha = a$par.ests[1]
sca = a$par.ests[2]
#ks检验
kt <- ks.test(p2, "pgpd", loc = 0, scale = sca, shape = sha)2.2 Matlab——推荐
%GPD
thre = quantile(p, 0.9); %阈值分位数可对应修改
p1 = p(p>thre)-thre;
parmhat = gpfit(p1); %完成拟合
shape=parmhat(1);
scale=parmhat(2);
pr20=gpinv(0.95,shape, scale, thre); %重现期计算
pr50=gpinv(0.98,shape, scale, thre);
pr100=gpinv(0.99,shape, scale, thre);
%检验
test=makedist('gp','k',shape,'sigma',scale, 'theta', 1);
[h,p,k,c]=kstest(p1,'CDF',test,'Alpha',0.05);
%需要h,k,c参数
%GEV
[parmhat,parmci]=gevfit(data);
k=parmhat(1);
sigma=parmhat(2);
mu=parmhat(3);
canshu(i,1)=k;
canshu(i,2)=sigma;
canshu(i,3)=mu;
%重现期
pr20=gevinv(0.95,k,sigma,mu);
pr50=gevinv(0.98,k,sigma,mu);
pr100=gevinv(0.99,k,sigma,mu);
%检验
test=makedist('gev','k',k,'sigma',sigma,'mu',mu);
[h,p,k,c]=kstest(data,'CDF',test,'Alpha',0.05);3.简单总结
更推荐使用matlab,好像更完善一些
两个软件的参数使用的名称可能不一致,可以对照查看一下,查看帮助文档看清每个参数的含义
matlab:
Generalized Pareto parameter estimates - MATLAB gpfit - MathWorks 中国
R:















 866
866

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









