






Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。Elasticsearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。
Why Elasticsearch?
由于需要提升项目的搜索质量,最近研究了一下Elasticsearch,一款非常优秀的分布式搜索程序。最开始的一些笔记放到github,这里只是归纳总结一下。
首先,为什么要使用Elasticsearch?最开始的时候,我们的项目仅仅使用MySQL进行简单的搜索,然后一个不能索引的like语句,直接拉低MySQL的性能。后来,我们曾考虑过sphinx,并且sphinx也在之前的项目中成功实施过,但想想现在的数据量级,多台MySQL,以及搜索服务本身HA,还有后续扩容的问题,我们觉得sphinx并不是一个最优的选择。于是自然将目光放到了Elasticsearch上面。
根据官网自己的介绍,Elasticsearch是一个分布式搜索服务,提供Restful API,底层基于Lucene,采用多shard的方式保证数据安全,并且提供自动resharding的功能,加之github等大型的站点也采用Elasticsearch作为其搜索服务,我们决定在项目中使用Elasticsearch。
对于Elasticsearch,如果要在项目中使用,需要解决如下问题:
- 索引,对于需要搜索的数据,如何建立合适的索引,还需要根据特定的语言使用不同的analyzer等。
- 搜索,Elasticsearch提供了非常强大的搜索功能,如何写出高效的搜索语句?
- 数据源,我们所有的数据是存放到MySQL的,MySQL是唯一数据源,如何将MySQL的数据导入到Elasticsearch?
对于1和2,因为我们的数据都是从MySQL生成,index的field是固定的,主要做的工作就是根据业务场景设计好对应的mapping以及search语句就可以了,当然实际不可能这么简单,需要我们不断的调优。
而对于3,则是需要一个工具将MySQL的数据导入Elasticsearch,因为我们对搜索实时性要求很高,所以需要将MySQL的增量数据实时导入,笔者唯一能想到的就是通过row based binlog来完成。而近段时间的工作,也就是实现一个MySQL增量同步到Elasticsearch的服务。
Lucene
Elasticsearch底层是基于Lucene的,Lucene是一款优秀的搜索lib,当然,笔者以前仍然没有接触使用过。:-)
Lucene关键概念:
- Document:用来索引和搜索的主要数据源,包含一个或者多个Field,而这些Field则包含我们跟Lucene交互的数据。
- Field:Document的一个组成部分,有两个部分组成,name和value。
- Term:不可分割的单词,搜索最小单元。
- Token:一个Term呈现方式,包含这个Term的内容,在文档中的起始位置,以及类型。
Lucene使用Inverted index来存储term在document中位置的映射关系。
譬如如下文档:
- Elasticsearch Server 1.0 (document 1)
- Mastring Elasticsearch (document 2)
- Apache Solr 4 Cookbook (document 3)
使用inverted index存储,一个简单地映射关系:
| Term | Count | Docuemnt |
|---|---|---|
| 1.0 | 1 | <1> |
| 4 | 1 | <3> |
| Apache | 1 | <3> |
| Cookbook | 1 | <3> |
| Elasticsearch | 2 | <1>.<2> |
| Mastering | 1 | <2> |
| Server | 1 | <1> |
| Solr | 1 | <3> |
对于上面例子,我们首先通过分词算法将一个文档切分成一个一个的token,再得到该token与document的映射关系,并记录token出现的总次数。这样就得到了一个简单的inverted index。
Elasticsearch关键概念
要使用Elasticsearch,笔者认为,只需要理解几个基本概念就可以了。
在数据层面,主要有:
- Index:Elasticsearch用来存储数据的逻辑区域,它类似于关系型数据库中的db概念。一个index可以在一个或者多个shard上面,同时一个shard也可能会有多个replicas。
- Document:Elasticsearch里面存储的实体数据,类似于关系数据中一个table里面的一行数据。
document由多个field组成,不同的document里面同名的field一定具有相同的类型。document里面field可以重复出现,也就是一个field会有多个值,即multivalued。 - Document type:为了查询需要,一个index可能会有多种document,也就是document type,但需要注意,不同document里面同名的field一定要是相同类型的。
- Mapping:存储field的相关映射信息,不同document type会有不同的mapping。
对于熟悉MySQL的童鞋,我们只需要大概认为Index就是一个db,document就是一行数据,field就是table的column,mapping就是table的定义,而document type就是一个table就可以了。
Document type这个概念其实最开始也把笔者给弄糊涂了,其实它就是为了更好的查询,举个简单的例子,一个index,可能一部分数据我们想使用一种查询方式,而另一部分数据我们想使用另一种查询方式,于是就有了两种type了。不过这种情况应该在我们的项目中不会出现,所以通常一个index下面仅会有一个type。
在服务层面,主要有:
- Node: 一个server实例。
- Cluster:多个node组成cluster。
- Shard:数据分片,一个index可能会存在于多个shards,不同shards可能在不同nodes。
- Replica:shard的备份,有一个primary shard,其余的叫做replica shards。
Elasticsearch之所以能动态resharding,主要在于它最开始就预先分配了多个shards(貌似是1024),然后以shard为单位进行数据迁移。这个做法其实在分布式领域非常的普遍,codis就是使用了1024个slot来进行数据迁移。
因为任意一个index都可配置多个replica,通过冗余备份的方式保证了数据的安全性,同时replica也能分担读压力,类似于MySQL中的slave。
Restful API
Elasticsearch提供了Restful API,使用json格式,这使得它非常利于与外部交互,虽然Elasticsearch的客户端很多,但笔者仍然很容易的就写出了一个简易客户端用于项目中,再次印证了Elasticsearch的使用真心很容易。
Restful的接口很简单,一个url表示一个特定的资源,譬如/blog/article/1,就表示一个index为blog,type为aritcle,id为1的document。
而我们使用http标准method来操作这些资源,POST新增,PUT更新,GET获取,DELETE删除,HEAD判断是否存在。
这里,友情推荐httpie,一个非常强大的http工具,个人感觉比curl还用,几乎是命令行调试Elasticsearch的绝配。
# create
http POST :9200/blog/article/1 title="hello elasticsearch" tags:='["elasticsearch"]'
# get
http GET :9200/blog/article/1
# update
http PUT :9200/blog/article/1 title="hello elasticsearch" tags:='["elasticsearch", "hello"]'
# delete
http DELETE :9200/blog/article/1
# exists
http HEAD :9200/blog/article/1理很简单,首先使用mysqldump获取当前MySQL的数据,然后在通过此时binlog的name和position获取增量数据。
一些限制:
- binlog一定要变成row-based format格式,其实我们并不需要担心这种格式的binlog占用太多的硬盘空间,MySQL 5.6之后GTID模式都推荐使用row-based format了,而且通常我们都会把控SQL语句质量,不允许一次性更改过多行数据的。
- 需要同步的table最好是innodb引擎,这样mysqldump的时候才不会阻碍写操作。
- 需要同步的table一定要有主键,好吧,如果一个table没有主键,笔者真心会怀疑设计这个table的同学编程水平了。多列主键也是不推荐的,笔者现阶段不打算支持。
- 一定别动态更改需要同步的table结构,Elasticsearch只能支持动态增加field,并不支持动态删除和更改field。通常来说,如果涉及到alter table,很多时候已经证明前期设计的不合理以及对于未来扩展的预估不足了。
使用
1. elasticsearch 命令的基本格式
RESTful接口URL的格式:
http://localhost:9200/<index>/<type>/[<id>]
其中index、type是必须提供的。id是可选的,不提供es会自动生成。index、type将信息进行分层,利于管理。index可以理解为数据库;type理解为数据表;id相当于数据库表中记录的主键,是唯一的。
注:在url网址后面加"?pretty",会让返回结果以工整的方式展示出来,适用所有操作数据类的url。"?"表示引出条件,"pretty"是条件内容。
2. elasticsearch基本的增删改
2.1 elasticSearch增加
向store索引中添加一些书籍
| 1 2 3 4 5 6 7 8 9 |
|
注:curl是linux下的http请求,-H "Content-Type: application/json"需要添加,否则会报错{"error":"Content-Type header [application/x-www-form-urlencoded] is not supported","status":406}
加"pretty"

不加"pretty"

加"pretty"与不加"pretty"的区别就是返回结果工整与不工整的差别,其他操作类似。为了使返回结果工整,以下操作都在url后添加"pretty"
2.2 elasticSearch删除
删除一个文档
| 1 |
|

2.3 elasticSearch更新(改)
①可以通过覆盖的方式更新
| 1 2 3 4 5 6 7 8 9 |
|

② 通过_update API的方式单独更新你想要更新的
| 1 2 3 4 5 |
|

3. elasticSearch查询
elasticSearch查询分三种,一是浏览器查询,二是curl查询,三是请求体查询GET或POS。
注:采用_search的模糊查询(包括bool过滤查询、 嵌套查询、range范围过滤查询等等),url可以不必指定type,只用指定index查询就行,具体例子看"2.1.4 elasticSearch查询 ③query基本匹配查询"节点的具体查询实例
3.1 浏览器查询
通过浏览器IP+网址查询
| 1 |
|

3.2 在linux通过curl的方式查询
3.2.1 通过ID获得文档信息
| 1 |
|

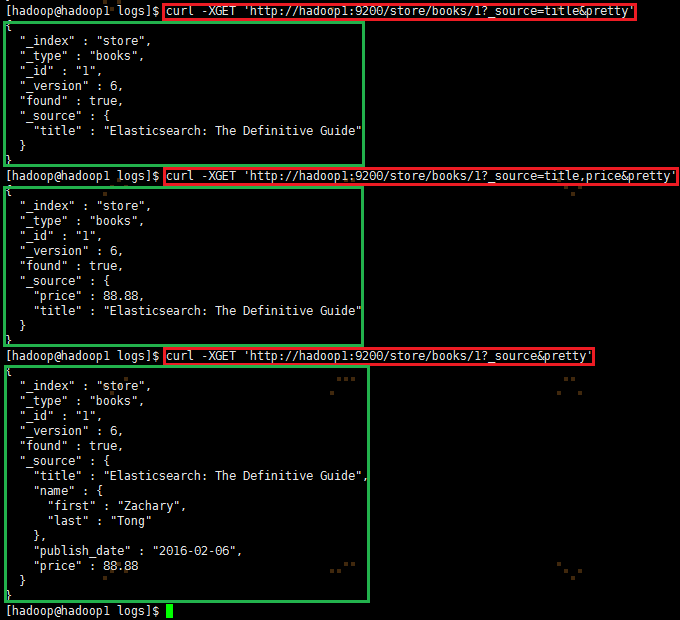
3.2.2 通过_source获取指定的字段
| 1 2 3 |
|
3.2.3 query基本匹配查询
查询数据前,可以批量导入1000条数据集到elasticsearch里,具体参考"4 elasticSearch批处理命令 4.1 导入数据集"节点,以便数据查询方便。
① "q=*"表示匹配索引中所有的数据,一般默认只返回前10条数据。
| 1 2 3 4 5 6 7 |
|
② 匹配所有数据,但只返回1个
| 1 2 3 4 |
|
注:如果size不指定,则默认返回10条数据。
③ 返回从11到20的数据(索引下标从0开始)
| 1 2 3 4 5 |
|
④ 匹配所有的索引中的数据,按照balance字段降序排序,并且返回前10条(如果不指定size,默认最多返回10条)
| 1 2 3 4 |
|
⑤ 返回特定的字段(account_number balance) ,与②通过_source获取指定的字段类似
| 1 2 3 4 |
|
⑥ 返回account_humber为20的数据
| 1 2 3 |
|
⑦ 返回address中包含mill的所有数据
| 1 2 3 |
|
⑧ 返回地址中包含mill或者lane的所有数据
| 1 2 3 |
|
⑨ 与第8不同,多匹配(match_phrase是短语匹配),返回地址中包含短语"mill lane"的所有数据
| 1 2 3 |
|
3.2.4 bool过滤查询,可以做组合过滤查询、嵌套查询等
SELECT * FROM books WHERE (price = 35.99 OR price = 99.99) AND (publish_date != "2016-02-06")
类似的,Elasticsearch也有 and, or, not这样的组合条件的查询方式,格式如下:
| 1 2 3 4 5 6 7 8 |
|
说明:
filter:过滤
must:条件必须满足,相当于and
should:条件可以满足也可以不满足,相当于or
must_not:条件不需要满足,相当于not
3.2.4.1 filter查询
①filter指定单个值
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|

注:带有key-value键值对的都需要加 -H “Content-Type: application/json”
②filter指定多个值
| 1 2 3 4 5 6 7 8 9 10 11 |
|

3.2.4.2 must、should、must_not查询
①must、should、must_not与term结合使用:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 |
|

②must、should、must_not与match结合使用
bool表示查询列表中只要有任何一个为真则认为匹配:
| 1 2 3 4 5 6 7 8 9 10 |
|
返回age年龄大于40岁、state不是ID的所有数据:
| 1 2 3 4 5 6 7 8 9 10 11 12 |
|
3.2.4.3 bool嵌套查询
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|

3.2.4.4 filter的range范围过滤查询
第一个示例,查找price价钱大于20的数据:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
|
注:boost:设置boost查询的值,默认1.0

第二个示例,使用布尔查询返回balance在20000到30000之间的所有数据:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
3.2.4 elasticSearch聚合查询
第一个示例,将所有的数据按照state分组(group),然后按照分组记录数从大到小排序(默认降序),返回前十条(默认)
| 1 2 3 4 5 6 7 8 9 10 |
|
可能遇到的问题:elasticsearch 进行排序的时候,我们一般都会排序数字、日期,而文本排序则会报错:Fielddata is disabled on text fields by default. Set fielddata=true on [state] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead.如:

解决方案:5.x后对排序,聚合这些操作,用单独的数据结构(fielddata)缓存到内存里了,需要单独开启,官方解释在此fielddata。聚合前执行如下操作,用以开启fielddata:
| 1 2 3 4 5 6 7 8 |
|

说明:bank为index,_mapping为映射,account为type,这三个要素为必须,”state“为聚合"group_by_state"操作的对象字段
聚合查询成功示例:

第二个示例,将所有的数据按照state分组(group),降序排序,计算每组balance的平均值并返回(默认)
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|

4. elasticSearch批处理命令
4.1 导入数据集
你可以点击这里下载示例数据集:accounts.json
导入示例数据集:
| 1 2 |
|

注:_bulk表示批量处理,"@accounts.json"或者"@/home/hadoop/accounts.json"可以用相对路径或者绝对路径表示。
查看accounts.json导入情况,使用 curl 'hadoop1:9200/_cat/indices?v'

可以看到已经成功导入1000条数据记录
4.2 批量创建索引
5. elasticSearch其他常用命令
注:url后面的"v"表示 verbose 的意思,这样可以更可读(有表头,有对齐),如果不加v,不会显示表头
5.1. 查看所有index索引,输入命令 curl 'hadoop1:9200/_cat/indices?v'

说明:index:索引为store,pri:5个私有的分片,rep:1个副本,docs.count:store索引里面有2个文档(即里面有2条数据记录),docs.deleted:删除了0条记录,store.size:数据存储总大小(包括副本),pri.store.size:分片数据存储的大小。
不加v,不会显示表头,可读性差

5.2. 检测集群是否健康,确保9200端口号可用 curl 'hadoop1:9200/_cat/health?v'

5.3. 获取集群的节点列表 curl 'hadoop1:9200/_cat/nodes?v'
















 205
205











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









