







二.Redis常见命令
Redis是典型的key-value数据库,key一般是字符串,而value包含很多不同的数据类型:

接下来,我们就学习常见的五种基本数据类型的相关命令。
2.1.Redis通用命令
通用指令是部分数据类型的,都可以使用的指令,常见的有:
-
KEYS:查看符合模板的所有key
-
DEL:删除一个指定的key及其value
-
EXISTS:判断key是否存在
-
EXPIRE:给一个key设置有效期,有效期到期时该key会被自动删除
-
TTL:查看一个KEY的剩余有效期
通过help [command] 可以查看一个命令的具体用法,例如:
# 查看keys命令的帮助信息:
127.0.0.1:6379> help keys
KEYS pattern
summary: Find all keys matching the given pattern
since: 1.0.0
group: generic2.2.String类型
String 类型,也就是字符串类型,是 Redis 中最简单的存储类型。根据字符串的格式不同,又可以分为 3 类,并且,虽然 Redis 的 String 类型不会对存储的数据进行类型解释,但它提供了一些命令和操作,使得可以对存储在 String 中的字符串进行自增、自减操作:
-
string:普通字符串
-
int:整数类型,可以做自增、自减操作
-
float:浮点类型,可以做自增、自减操作
不管是哪种格式,底层都是字节数组形式存储,因为它并没有对存储的内容做任何类型的限制,这意味着我们可以将任何二进制数据存储在 Redis 的 String 类型中,包括整数、浮点数、图片、序列化对象等。只不过是编码方式不同。字符串类型的最大空间不能超过512m。

1.String的常见命令
-
SET:添加或者修改已经存在的一个 String 类型的键值对
-
GET:根据 key 获取String类型的 value
-
MSET:批量添加多个 String 类型的键值对
-
MGET:根据多个 key 获取多个String类型的 value
-
INCR:让一个整型的key自增 1
-
INCRBY:让一个整型的key自增并指定步长,例如:incrby num 2 让 num 值自增 2
-
INCRBYFLOAT:让一个浮点类型的数字自增并指定步长
-
SETNX:添加一个 String 类型的键值对,前提是这个 key 不存在,否则不执行
-
SETEX:添加一个 String 类型的键值对,并且指定有效期
2.String类型的应用场景
-
常规数据的缓存,比如序列化后的对象、图片的路径、Token、Session。
-
最简单的分布式锁。比如利用 SETNX key value 命令实现的分布式锁。
2.3.Hash类型
Hash 数据类型是一种键值对的集合,其中键是唯一的字符串,值是字段及其对应的值。类似于Java 中的 HashMap 结构。
1.Hash类型的特征是:
- key 无序、不可重复
- value 无序、可重复
- 查找元素快
String结构是将对象序列化为JSON字符串后存储,当需要修改对象某个字段时很不方便:

Hash结构可以将对象中的每个字段独立存储,可以针对单个字段做CRUD:
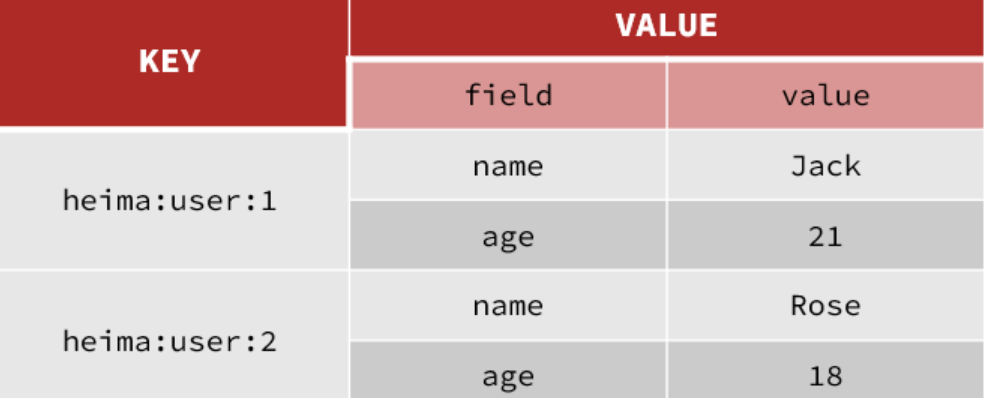
2.Hash 的常见命令
-
HSET key field value:添加或者修改hash类型key的field的值
-
HGET key field:获取一个hash类型key的field的值
-
HMSET:批量添加多个hash类型key的field的值
-
HMGET:批量获取多个hash类型key的field的值
-
HGETALL:获取一个hash类型的key中的所有的field和value
-
HKEYS:获取一个hash类型的key中的所有的field
-
HINCRBY:让key的某个field对应的value值自增并指定步长
-
HSETNX:添加一个key的field和对应的value,前提是这个field不存在,否则不执行
3.Hash类型的应用场景
存储购物车信息:由于购物车中的商品频繁修改和变动,购物车信息建议使用 Hash 存储:
-
用户 id 为 key
-
商品 id 为 field,商品数量为 value

用户购物车信息的维护具体应该怎么操作呢?
- 用户添加商品就是往 Hash 里面增加新的 field 与 value;
- 查询购物车信息就是遍历对应的 Hash;
- 更改商品数量直接修改对应的 value 值,直接 set 或者做运算皆可。
- 删除商品就是删除 Hash 中对应的 field;
- 清空购物车直接删除对应的 key 即可。
Note:这里只是以业务比较简单的购物车场景举例,实际电商场景下,field 只保存一个商品 id 是没办法满足需求的。
2.4.List类型
Redis 中的 List 类型与 Java 中的 LinkedList 类似,底层数据结构可以看做是一个双向链表,既可以支持正向检索和也可以支持反向检索。
List 类型的特征是:
-
元素有序
-
元素可重复
-
插入和删除元素快
-
查询速度一般
Note:
- 上面的有序是指链表中元素的顺序跟插入元素的顺序一致,不是指排序的那个有序。
- 虽然双向链表在插入或者删除元素的时候,需要从链表的头或者尾查找到对应的位置,但相比于数组插入和删除元素时,需要在内存中移动元素的情况,性能还是要好很多。
常用来存储有序数据,例如:朋友圈点赞列表,评论列表等。
List 的常见命令有:
-
LPUSH key element ... :向列表左侧插入一个或多个元素
-
LPOP key:移除并返回列表左侧的第一个元素,没有则返回nil
-
RPUSH key element ... :向列表右侧插入一个或多个元素
-
RPOP key:移除并返回列表右侧的第一个元素
-
LRANGE key star end:返回一段角标范围内的所有元素
-
BLPOP和BRPOP:与LPOP和RPOP类似,只不过在没有元素时等待指定时间,而不是直接返回nil
2.5.Set类型
Redis 的 Set 结构与 Java 中的 HashSet 类似,可以看做是一个 value 为 null 的 HashMap。
1.Set 的特征:因为也是一个 hash 表,因此具备与 HashSet 类似的特征
-
元素无序
-
元素不可重复
-
查找快
-
支持交集、并集、差集等功能
2.Set 的常见命令
-
SADD key member ... :向set中添加一个或多个元素
-
SREM key member ... : 移除set中的指定元素
-
SCARD key: 返回set中元素的个数
-
SISMEMBER key member:判断一个元素是否存在于set中
-
SMEMBERS:获取set中的所有元素
-
SINTER key1 key2 ... :求key1与key2的交集
-
SDIFF key1 key2:将key1中的元素减去key1和key2的交集
例如两个集合:s1和s2:
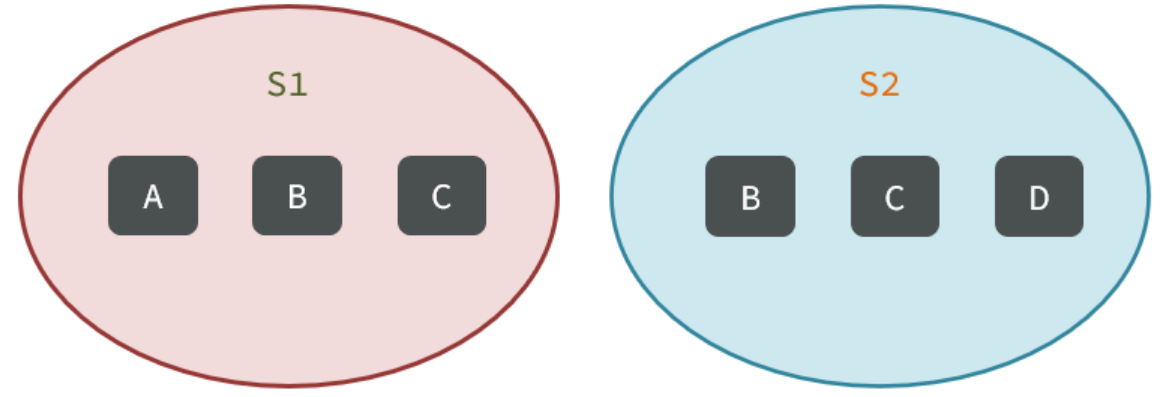
求交集:
SINTER s1 s2求s1与s2的不同:
SDIFF s1 s2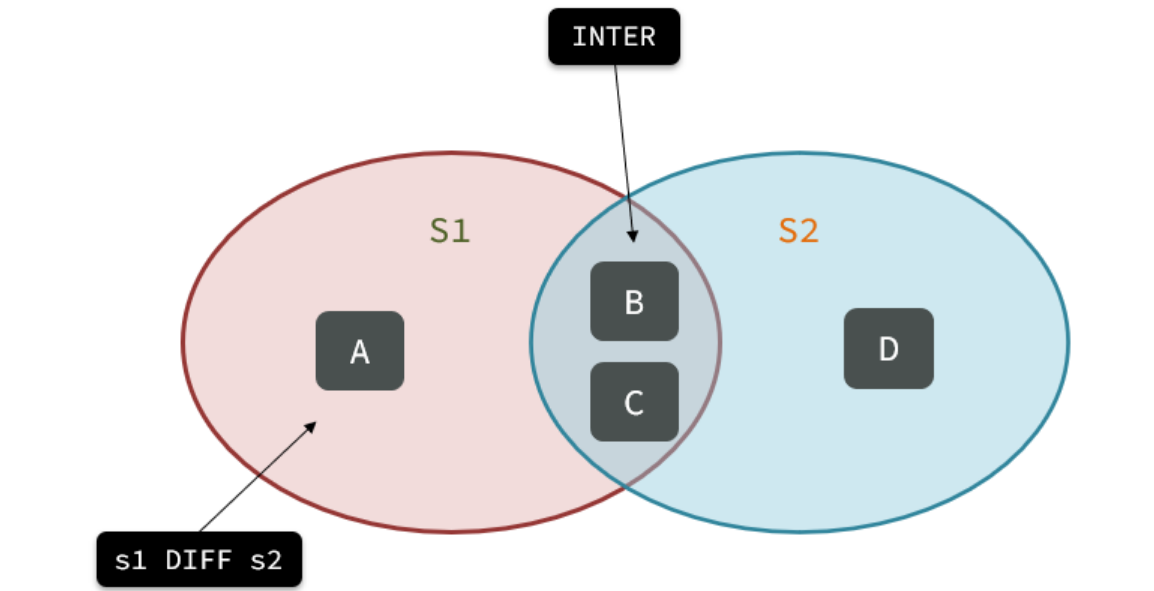
3.Set 的应用场景
-
存放的数据不能重复的场景:网站 UV 统计、文章点赞、动态点赞等。
-
需要获取多个数据源的交集、并集和差集的场景:共同好友(交集)、共同粉丝(交集)、共同关注(交集)、好友推荐(差集)、音乐推荐(差集)、订阅号推荐(差集+交集) 等等。
-
需要随机获取数据源中的元素的场景:抽奖系统、随机点名等等。
使用 Set 实现抽奖系统怎么做?如果想要使用 Set 实现一个简单的抽奖系统的话,直接使用下面这几个命令就可以了:
-
SADD key member1 member2 ...:向指定集合添加一个或多个元素。
-
SPOP key count:随机移除并获取指定集合中一个或多个元素,适合不允许重复中奖的场景。
-
SRANDMEMBER key count : 随机获取指定集合中指定数量的元素,适合允许重复中奖的场景。
2.6.SortedSet类型
Redis的SortedSet是一个可排序的set集合,与Java中的TreeSet有些类似,但底层数据结构却差别很大。SortedSet中的每一个元素都带有一个score属性,可以基于score属性对元素排序,默认升序,底层的实现是一个跳表(SkipList)加 hash表。
在 Redis 中,SortedSet 的默认分数是根据元素的插入顺序来确定的。也就是说,当用户向SortedSet 添加元素时,因为SortedSet默认是升序排序,所以如果未指定元素的分数,默认情况下 Redis 会将其插入到有序集合的末尾,并为该元素分配一个自动生成的分数,这个分数是最大的。
1.SortedSet 的特征:
-
可排序
-
元素不可重复
-
查询速度快
2.SortedSet的常见命令
-
ZADD key score member:添加一个或多个元素到sorted set ,如果已经存在则更新其score值
-
ZREM key member:删除sorted set中的一个指定元素
-
ZSCORE key member : 获取sorted set中的指定元素的score值
-
ZRANK key member:获取sorted set中的指定元素的排名
-
ZCARD key:获取sorted set中的元素个数
-
ZCOUNT key min max:统计score值在给定范围内的所有元素的个数
-
ZINCRBY key increment member:让sorted set中的指定元素自增,步长为指定的increment 值
-
ZRANGE key min max:按照score排序后,获取指定排名范围内的元素
-
ZRANGEBYSCORE key min max:按照score排序后,获取指定score范围内的元素
-
ZDIFF、ZINTER、ZUNION:求差集、交集、并集
3.SortedSet类型的应用场景
因为 SortedSet 的可排序特性,经常被用来实现排行榜这样的功能。
注意:SortedSet 所有的排名默认都是升序,如果要降序则在命令的Z后面添加REV即可,例如:
升序获取sorted set中的指定元素的排名:ZRANK key member
降序获取sorted set中的指定元素的排名:ZREVRANK key memeber
2.7 GEO类型
GEO 就是 Geolocation 的简写形式,是基于 SortedSet 实现的,代表地理坐标。Redis 在 3.2 版本中加入了对 GEO 的支持,允许存储地理坐标信息,帮助我们根据经纬度来检索数据。
1.GEO 常见命令
-
GEOADD:添加一个地理空间信息,包含:经度(longitude)、纬度(latitude)、值(member)
-
GEODIST:计算指定的两个点之间的距离并返回
-
GEOHASH:将指定member的坐标转为hash字符串形式并返回
-
GEOPOS:返回指定member的坐标
-
GEORADIUS:指定圆心、半径,找到该圆内包含的所有member,并按照与圆心之间的距离排序后返回。6. 以后已废弃
-
GEOSEARCH:在指定范围内搜索member,并按照与指定点之间的距离排序后返回。范围可以是圆形或矩形。6.2. 的新功能
-
GEOSEARCHSTORE:与GEOSEARCH功能一致,不过可以把结果存储到一个指定的key。 6.2. 的新功能
Note:在GEO的底层,SortedSet 中的 value 代表 member,score 对应经纬度
2.GEO的应用场景
实现附近商户功能
2.8 BitMap类型
Bitmap 存储的是连续的二进制数字,通过 Bitmap,只需要一个 bit 位来表示某个元素对应的值或者状态,key 就是对应元素本身 ,所以 Bitmap 本身会极大的节省储存空间。
可以将 Bitmap 看作是一个存储二进制数字的数组,数组中每个元素的下标叫做偏移量(offset)。

1.Bitmap的常见命令
-
SETBIT:向指定位置(offset)存入一个0或1
-
GETBIT :获取指定位置(offset)的bit值
-
BITCOUNT :统计BitMap中值为1的bit位的数量
-
BITFIELD :操作(查询、修改、自增)BitMap中bit数组中的指定位置(offset)的值
-
BITFIELD_RO :获取BitMap中bit数组,并以十进制形式返回
-
BITOP :将多个BitMap的结果做位运算(与 、或、异或)
-
BITPOS :查找bit数组中指定范围内第一个0或1出现的位置
2.Bitmap的应用场景
可以用 BitMap 统计活跃用户,具体步骤如下:
如果想要使用 Bitmap 统计活跃用户的话,可以使用精确到天的日期作为 key,然后用户 ID 为 offset,如果当日活跃过就设置为 1。例如:
初始化数据:
SETBIT 20210308 1 1
(integer) 0
SETBIT 20210308 2 1
(integer) 0
SETBIT 20210309 1 1
(integer) 0
统计 20210308~20210309 总活跃用户数:
BITOP and desk1 20210308 20210309
(integer) 1
BITCOUNT desk1
(integer) 1
统计 20210308~20210309 在线活跃用户数:
BITOP or desk2 20210308 20210309
(integer) 1
BITCOUNT desk2
(integer) 2
2.9 HyperLogLog类型
Hyperloglog 是从 Loglog 算法派生的概率算法,基于 String 数据类型实现,用于统计向 HLL 中存储的元素数量,但 HLL 不需要存储所有的元素,因此无论单个 HLL 存储多少元素,其内存永远小于16kb,内存占用低的令人发指,作为代价,其测量结果是概率性的,有小于0.81%的误差。Hyperloglog 我们会用就可以了,相关算法原理大家可以参考:
HyperLogLog 算法的原理讲解以及 Redis 是如何应用它的 - 掘金 (juejin.cn)
1.常用命令
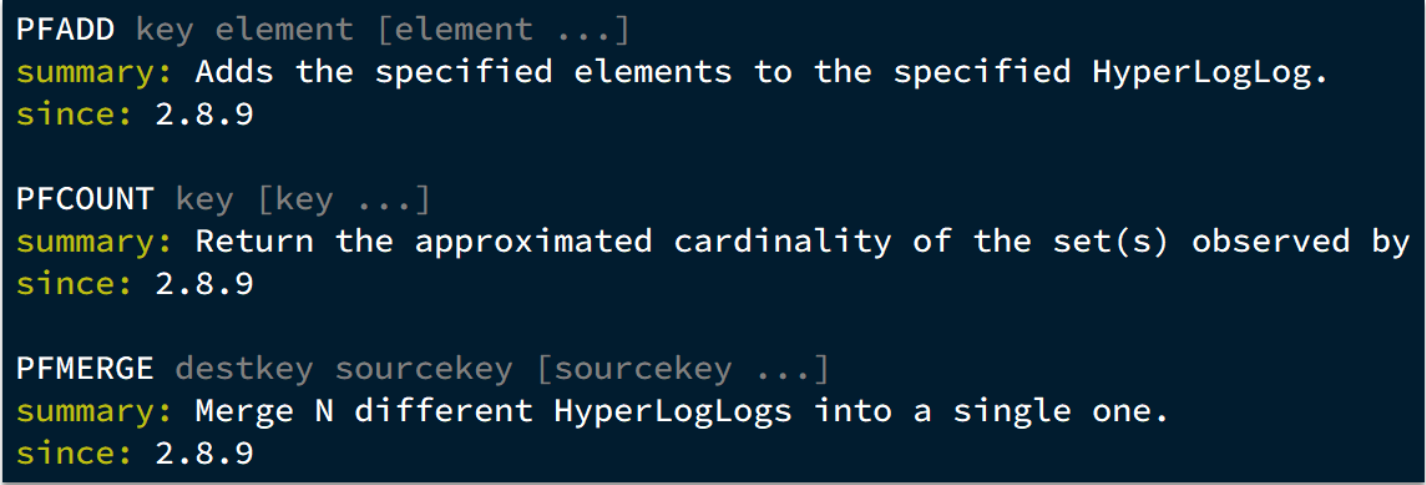
2.应用场景:一般用于UV统计
2.10.如何设计Key结构
Redis 如何区分不同类型的 key 呢?
例如,需要存储用户、商品信息到redis,有一个用户id是1,有一个商品id恰好也是1,此时如果使用id作为key,那就会冲突了,该怎么办?
我们可以通过给key添加前缀加以区分,不过这个前缀不是随便加的,有一定的规范:
Redis 的 key 允许有多个单词形成层级结构,多个单词之间用 : 隔开,格式如下:
项目名:业务名:类型:id这个格式并非固定,也可以根据自己的需求来删除或添加词条。这样以来,我们就可以把不同类型的数据区分开了。从而避免了key的冲突问题。
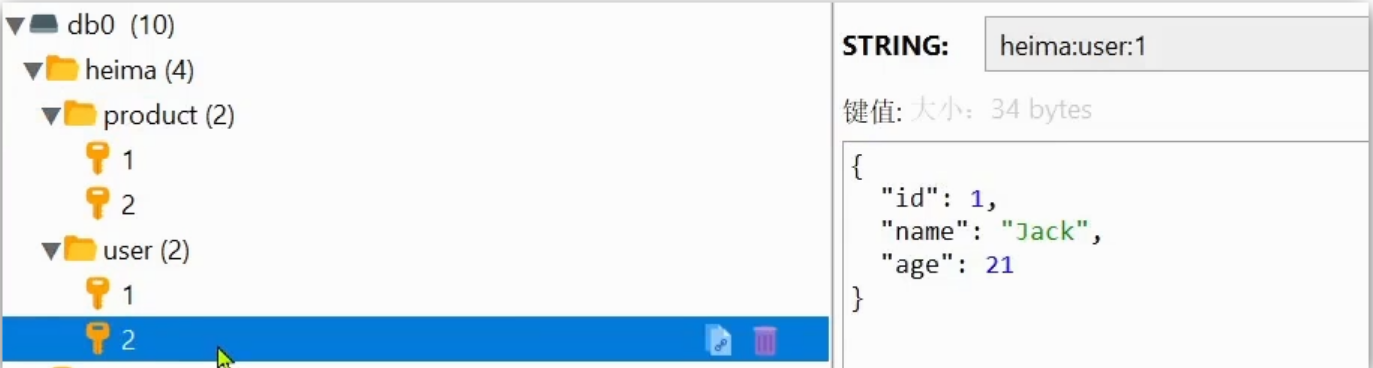
例如我们的项目名称叫 heima,有 user 和 product 两种不同类型的数据,我们可以这样定义key:
-
user 相关的 key:heima:user:1
-
product 相关的 key:heima:product:1
如果 Value 是一个 Java 对象,例如一个 User 对象,则可以将对象序列化为 JSON 字符串后存储:
| KEY | VALUE |
|---|---|
| heima:user:1 | {"id":1, "name": "Jack", "age": 21} |
| heima:product:1 | {"id":1, "name": "小米11", "price": 4999} |
并且,在 Redis 的桌面客户端中,还会以相同前缀作为层级结构,让数据看起来层次分明,关系清晰:
三.Redis的Java客户端
在Redis官网中提供了各种语言的客户端,地址:Get started using Redis clients | Redis

其中Java客户端也包含很多:
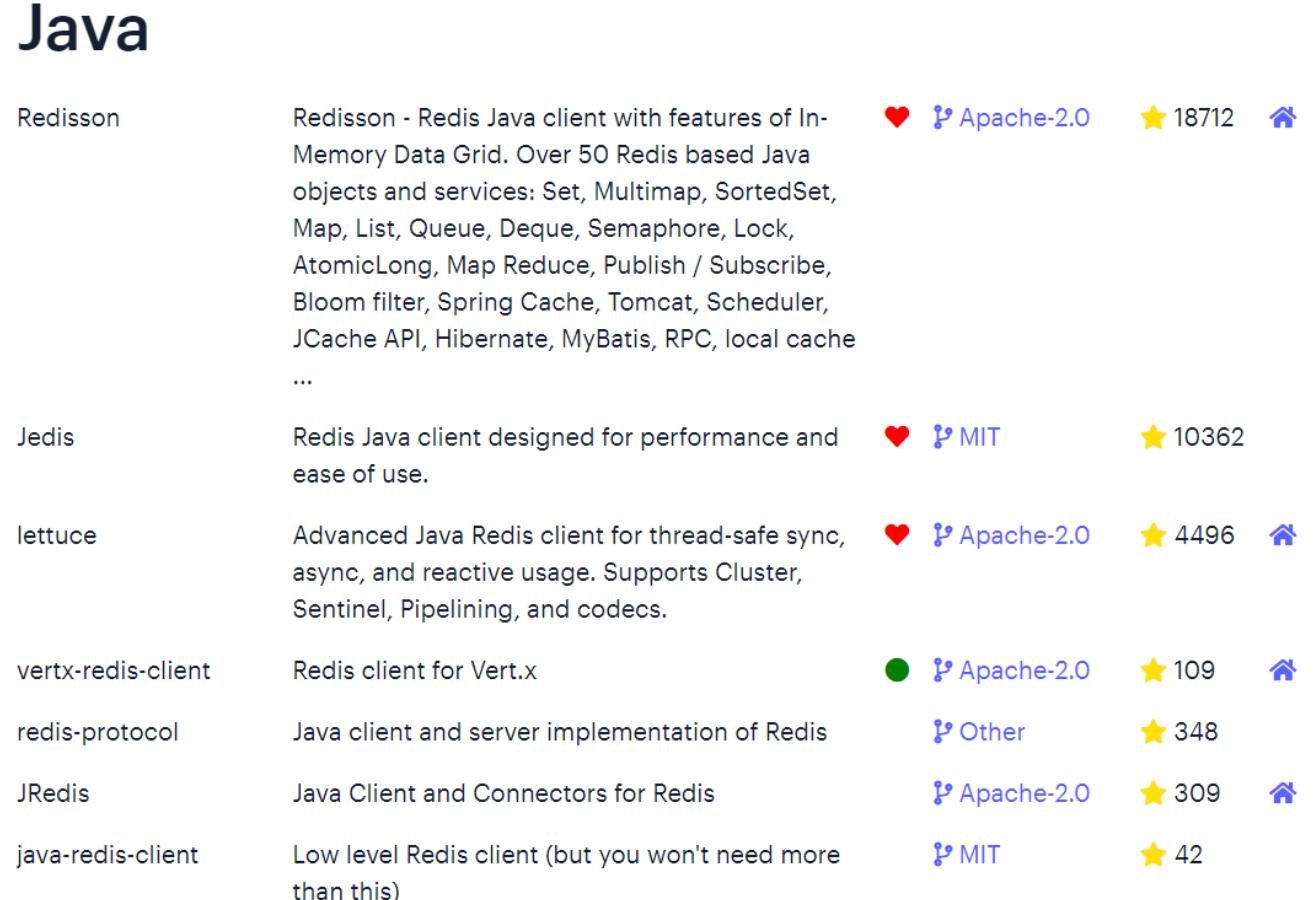
标记为 * 的就是推荐使用的java客户端,包括:
-
Jedis 和 Lettuce:这两个客户端主要是提供了 Redis 命令对应的 API,方便我们操作Redis,而 SpringDataRedis 又对这两种做了抽象和封装,因此我们后期会直接以SpringDataRedis来学习。
-
Redisson:是在Redis基础上实现了分布式的可伸缩的java数据结构,例如Map、Queue等,而且支持跨进程的同步机制:Lock、Semaphore等待,比较适合用来实现特殊的功能需求。
3.1.Jedis客户端
Jedis的官网地址: https://github.com/redis/jedis
3.1.1 Jedis的使用步骤
我们先来个快速入门:
第一步:引入依赖:
<!--jedis-->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.7.0</version>
</dependency>
<!--单元测试-->
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter</artifactId>
<version>5.7.0</version>
<scope>test</scope>
</dependency>第二步:建立连接
新建一个单元测试类,在类中定义一个连接Redis服务的方法,内容如下:
private Jedis jedis;
@BeforeEach
void setUp() {
// 1.建立连接
// jedis = new Jedis("192.168.150.101", 6379);
jedis = JedisConnectionFactory.getJedis();
// 2.设置密码
jedis.auth("123321");
// 3.选择库
jedis.select(0);
}第三步:测试
@Test
void testString() {
// 存入数据
String result = jedis.set("name", "虎哥");
System.out.println("result = " + result);
// 获取数据
String name = jedis.get("name");
System.out.println("name = " + name);
}
@Test
void testHash() {
// 插入hash数据
jedis.hset("user:1", "name", "Jack");
jedis.hset("user:1", "age", "21");
// 获取
Map<String, String> map = jedis.hgetAll("user:1");
System.out.println(map);
}第四步:释放资源
@AfterEach
void tearDown() {
if (jedis != null) {
jedis.close();
}
}3.1.2.连接池
Jedis本身是线程不安全的,并且频繁的创建和销毁连接会有性能损耗,因此我们推荐大家使用Jedis连接池代替Jedis的直连方式。
package com.heima.jedis.util;
import redis.clients.jedis.*;
public class JedisConnectionFactory {
private static JedisPool jedisPool;
static {
// 配置连接池
JedisPoolConfig poolConfig = new JedisPoolConfig();
poolConfig.setMaxTotal(8);
poolConfig.setMaxIdle(8);
poolConfig.setMinIdle(0);
poolConfig.setMaxWaitMillis(1000);
// 创建连接池对象,参数:连接池配置、服务端ip、服务端端口、超时时间、密码
jedisPool = new JedisPool(poolConfig, "192.168.150.101", 6379, 1000, "123321");
}
public static Jedis getJedis(){
return jedisPool.getResource();
}
}3.2.SpringDataRedis客户端
SpringData是Spring中数据操作的模块,包含对各种数据库的集成,其中对Redis的集成模块就叫做SpringDataRedis,官网地址:Spring Data Redis
-
提供了对不同Redis客户端的整合(Lettuce和Jedis)
-
提供了RedisTemplate统一API来操作Redis
-
支持Redis的发布订阅模型
-
支持Redis哨兵和Redis集群
-
支持基于Lettuce的响应式编程
-
支持基于JDK、JSON、字符串、Spring对象的数据序列化及反序列化
-
支持基于Redis的JDKCollection实现
SpringDataRedis中提供了RedisTemplate工具类,其中封装了各种对Redis的操作。并且将不同数据类型的操作API封装到了不同的类型中:

3.2.1.RedisTemplate的使用步骤
SpringBoot 已经提供了对 SpringDataRedis 的支持,使用非常简单。
首先,新建一个maven项目,然后按照下面步骤执行:
第一步:引入依赖
在一个springboot项目中导入redis的依赖坐标,即可使用 SpringDataRedis 提供的功能
<!--redis依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>第二步:配置Redis
spring:
redis:
host: 192.168.150.101
port: 6379
password: 123321
lettuce:
pool:
max-active: 8
max-idle: 8
min-idle: 0
max-wait: 100ms第三步:注入RedisTemplate
因为有了SpringBoot的自动装配,我们可以拿来就用:
@SpringBootTest
class RedisStringTests {
@Autowired
private RedisTemplate redisTemplate;
}第四步:编写测试
@SpringBootTest
class RedisStringTests {
@Autowired
private RedisTemplate edisTemplate;
@Test
void testString() {
// 写入一条String数据
redisTemplate.opsForValue().set("name", "虎哥");
// 获取string数据
Object name = stringRedisTemplate.opsForValue().get("name");
System.out.println("name = " + name);
}
}3.2.2.自定义序列化
RedisTemplate可以接收任意Object作为值写入Redis:
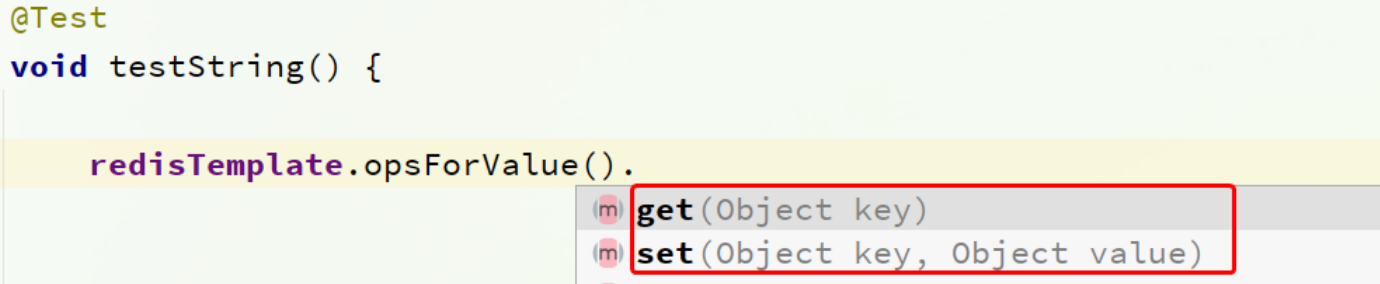
只不过写入前会把Object序列化为字节形式,默认是采用JDK序列化,得到的结果是这样的:

缺点:
-
可读性差
-
内存占用较大
我们可以自定义RedisTemplate的序列化方式,代码如下:
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory connectionFactory){
// 创建RedisTemplate对象
RedisTemplate<String, Object> template = new RedisTemplate<>();
// 设置连接工厂
template.setConnectionFactory(connectionFactory);
// 创建JSON序列化工具
GenericJackson2JsonRedisSerializer jsonRedisSerializer =
new GenericJackson2JsonRedisSerializer();
// 设置Key的序列化
template.setKeySerializer(RedisSerializer.string());
template.setHashKeySerializer(RedisSerializer.string());
// 设置Value的序列化
template.setValueSerializer(jsonRedisSerializer);
template.setHashValueSerializer(jsonRedisSerializer);
// 返回
return template;
}
}这里采用了 JSON 序列化来代替默认的 JDK 序列化方式。最终结果如图:
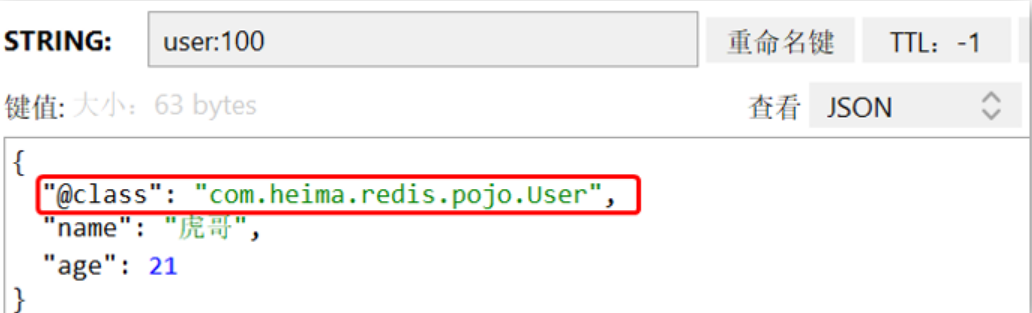
整体可读性有了很大提升,并且能将Java对象自动的序列化为JSON字符串,并且查询时能自动把JSON反序列化为Java对象。不过,其中记录了序列化时对应的class名称,目的是为了查询时实现自动反序列化。这会带来额外的内存开销。
3.2.3.StringRedisTemplate
为了节省内存空间,我们可以不使用JSON序列化器来处理value,而是统一使用String序列化器,要求只能存储String类型的key和value。当需要存储Java对象时,手动完成对象的序列化和反序列化。
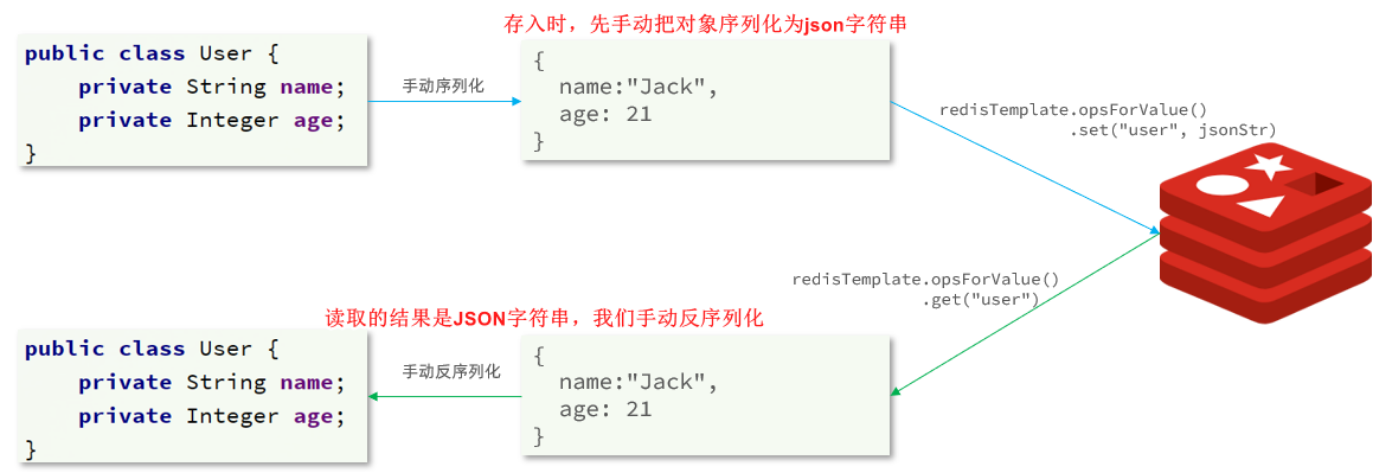
因为存入和读取时的序列化及反序列化都是我们自己实现的,SpringDataRedis就不会将class信息写入Redis了。
这种用法比较普遍,因此SpringDataRedis就提供了RedisTemplate的子类:StringRedisTemplate,它的key和value的序列化方式默认就是String方式。

省去了我们自定义RedisTemplate的序列化方式的步骤,而是直接使用:
@Autowired
private StringRedisTemplate stringRedisTemplate;
// JSON序列化工具
private static final ObjectMapper mapper = new ObjectMapper();
@Test
void testSaveUser() throws JsonProcessingException {
// 创建对象
User user = new User("虎哥", 21);
// 手动序列化
String json = mapper.writeValueAsString(user);
// 写入数据
stringRedisTemplate.opsForValue().set("user:200", json);
// 获取数据
String jsonUser = stringRedisTemplate.opsForValue().get("user:200");
// 手动反序列化
User user1 = mapper.readValue(jsonUser, User.class);
System.out.println("user1 = " + user1);
}3.2.4 RedisTemplate和StringRedisTemplate的区别
RedisTemplate 和 StringRedisTemplate 都是 Spring Data Redis 提供的用于操作 Redis 的模板类。它们之间的区别主要在于要存储的数据的序列化和反序列化的处理方式。
-
RedisTemplate 使用的是 JDK 自带的序列化方式将数据序列化为字节数组存储到 Redis 中。但是,这种方式存储的数据在Redis中是不可读的二进制形式。
-
StringRedisTemplate 继承了 RedisTemlate。但是,修改了 key 和 values 序列化的方式,存储的数据更易读,适用于存储字符串类型的数据。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











