







一. 情绪原因识别概述
1.1 什么是情绪原因识别
大部分针对情绪分析的研究主要集中在情绪识别和情绪分类方面,只关注情绪的类别,属于比较浅层的情绪分析任务。情绪原因识别是近年来出现的深层次文本分析与理解的研究,它能针对文本中出现的情绪关键词,自动识别出导致其产生的原因信息。该研究建立在标注语料库的基础之上,而语料库的建立基本依赖人工标注,非常匮乏,相关的研究技术还不成熟。因此,目前有关情绪原因识别的研究相对较少,主流方法采用的是基于语言学规则和基于统计的策略。
1.2 示例
接下来通过一段文本来说明什么是情绪原因识别
就比如这么一段文本:“早知道他们会拍照, 我先收拾收拾啊”。有网友看了这组图片后表示,〈cause id=0〉一看到医生那个拥抱的姿势〈/cause〉,立刻就被〈keyword〉戳中泪点〈/keyword〉,为这样的医生点赞。〈category name=“happiness”/〉
上面这个例子是经标注后的语料,情绪关键词和其情绪类别都已给出并做好了标注,需要根据该情绪关键词分析并理解文本语义关系,从而在上下文中识别出导致情绪关键词“戳中泪点”产生的情绪原因子句。在上面这个语料中,〈cause id=0〉与〈/cause〉之间的内容为情绪原因子句,其中 id 表示文本中情绪原因子句的编号,〈keyword〉与〈/keyword〉之间的内容为情绪关键词,〈category name=“happiness”/〉表示情绪类别为喜。
另外,在一些文本中,情绪关键词也可能包含多个情绪原因子句,这种情况下,需要将它们全部识别出来。
情绪原因识别即通过给定情绪关键词找到导致其产生的原因,其示例如表 1 所示。在表 1 中,对上面这个例子中情绪关键子句S0 周围的子句(位置分别为S-2 ,S-1 ,S0 ,S1 和 S2 等)给出其是否属于情绪原因子句的标签,如果是情绪原因子句,则标为“1”,否则标为“0”。

1.3 解决方法
目前有关情绪原因识别的研究相对较少,主流方法采用的是基于语言学规则和基于统计的策略。针对神经网络模型在情绪原因识别任务中的良好表现,论文综合考虑文本和子句特征,提出了一种模型AM-BiLSTM识别情绪原因。该模型将情绪原因识别任务视为一个分类问题,依赖双向长短时记忆网络和注意力机制进行建模, 通过 softmax 对训练结果进行分类,得到情绪原因识别结果。
二.系统结构
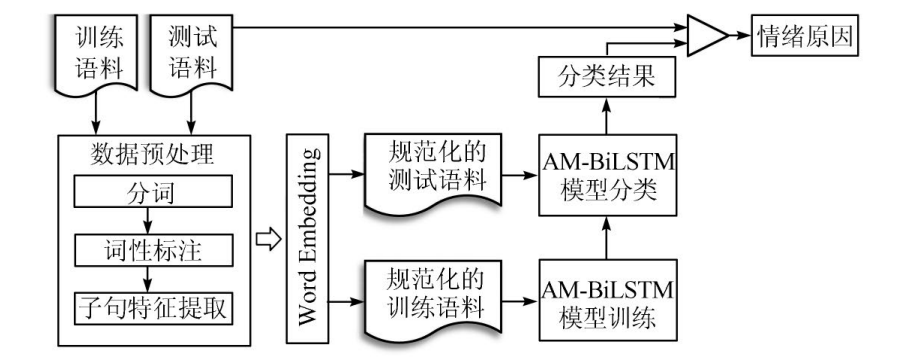
1)数据预处理。首先利用 Jieba 分词工具对训练数据和测试数据进行分词和词性标注处理,然后提取每个子句中名词、动词并统计其数目。触发情绪产生的原因主要是一类事物或者一系列行为,而这两类原因一般分别由名词和动词组成,所以本文选择了这两类词性作为子句词性特征。然后,经统计发现,情绪原因子句一般会出现在情绪关键子句周围,而且越靠近出现的概率越大,因此系统提取了子句相对于情绪关键子句的位置特征。最后,将情绪关键词本身作为标志词,也能为分类任务提供一定的语义信息。
2)语料规范化。在这个模块中,首先利用 Word2Vec 进行字符向量训练,得到每个字符的向量。然后将提取的子句特征与子句本身进行融合,得到每个子句的句向量表示。
3)模型训练与分类。使用训练语料训练基于注意力机制的 AM-BiLSTM 模型,并选用 softmax 分类器为子句进行分类。softmax 作为最常用的分类器,可以将神经网络的输出变成 0 到 1 的概率分布。最后利用训练好的模型对测试语料进行预测,得到最终的分类结果。
4)情绪原因子句提取。在此模块中,将分类结果与测试语料作对比,找到情绪原因子句并提取出来,并将其作为情绪原因识别的最终结果。同时,可以利用最终结果和标注好的测试语料测试系统的性能。
三、AM - BiLSTM模型结构
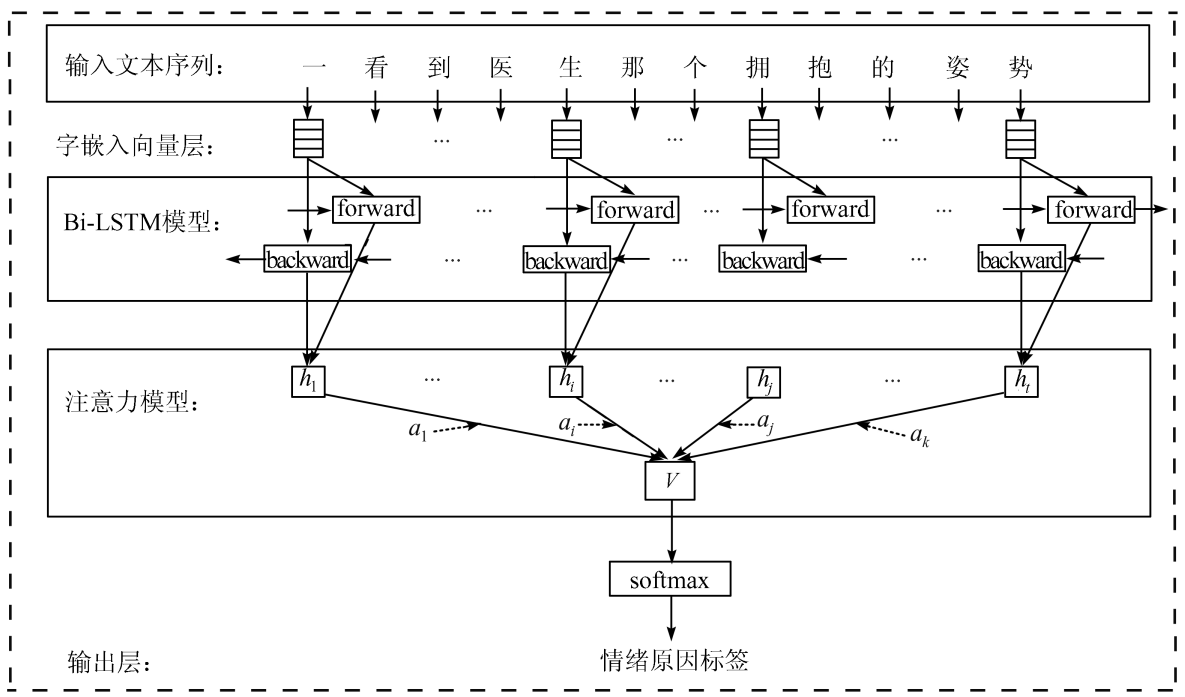
3. 1 文本向量化
使用深度学习算法来处理数据,需要先将文本向量化。本文采用的是 Mikolov 提出的 Word2Vec 方法,该方法有连续词袋模型 CBOW和 Skip - Gram 两种模型。本文字符向量训练采用的是连续词袋模型 CBOW。Word2Vec能够将文本中的字符转化为向量空间中的向量,而向量之间的相似度则可以表示文本中的语义相似度。研究表明,加入了预先训练的字符向量可以有效地提升自然语言处理模型的性能,本文在规范化语料的模块中加入了预先训练好的字符向量。
3.2 双向长短时记忆网络
先将子句中每个字的向量进行组合形成子句向量,然后与子句中提取的特征向量融合,作为 Bi-LSTM 模型的输入进行训练。
3.3 注意力机制
针对Bi-LSTM输出的特征矩阵,通过注意力机制对其中的特征向量赋予权重,含有重要信息越多的向量,其权重越大。
四.实验结果与分析
4.1 数据集
论文使用的文本语料来自 NTCIR - 13 会议中情绪原因分析 ECA任务提供的公开数据集,由 3 000 个新闻文本组成,其中 2500 条为训练集,500条为测试集,每个文本都标 注了情绪关键词以及对应的类别和原因。其中,情绪类别分为 6 种基本状态:happiness(喜)、anger (怒)、sadness(哀)、fear(惧)、disgust(恶)和 surprise(惊)。下表是数据集的相关统计信息。

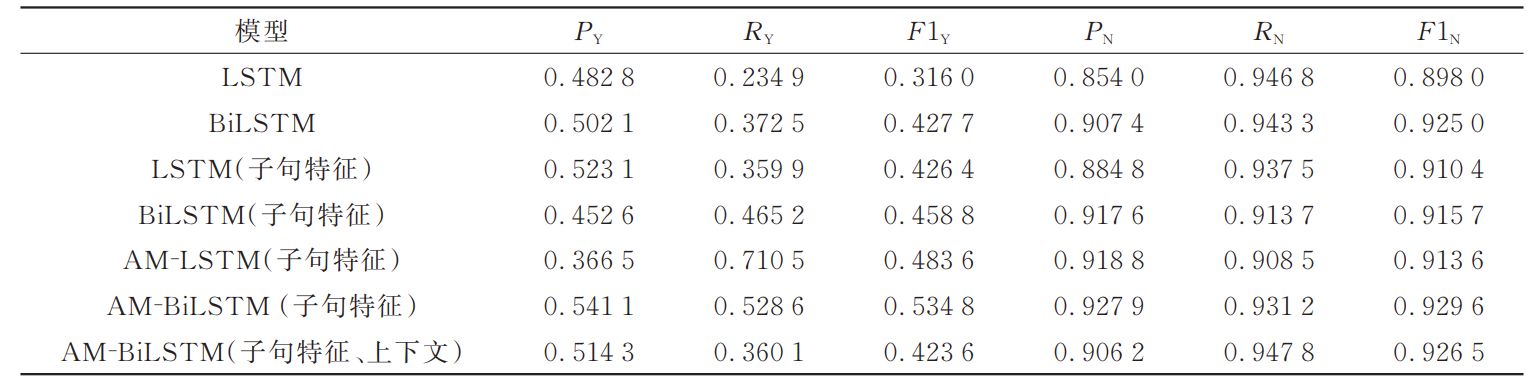
4.2 实验结果



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











