






Redis 进阶
1、Redis 发布订阅
Redis 发布订阅是一种消息通信模式。和mq的topic类似。
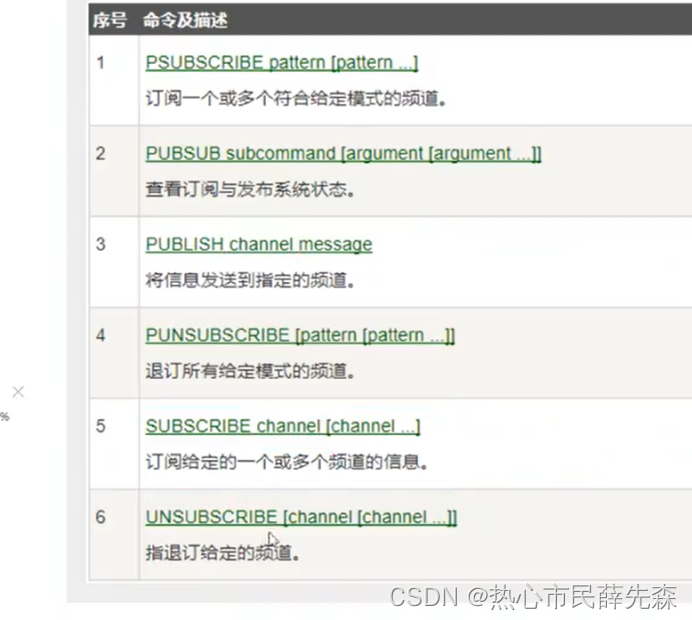
通过subscrice订阅某个频道之后。Redis-server中维护了一个字典,字典的键就是一个搁channel,而字典的值是一个链表,链表中保存了所有订阅这个的channel的客户端,subscrice命令的关键就是将客户端添加到给定channel的订阅链表中。
通过publish命令向订阅者发送消息,,redis-server会使用给定的频道作为键,在它所维护的channel字典中查找记录了订阅这个频道的所有客户端的链表,遍历这个链表,将消息发送给所有订阅者。
使用场景:
实时消息接收
实时消息沟通,聊天室
订阅,关注系统
更复杂的系统可以使用MQ
2、Redis主从复制
数据的恢复是单向的,只能由主节点到从节点,master以写为主,slave以读为主。
Info replication 查看当前节点的角色
主从复制的主要作用:
1、数据冗余
2、故障恢复
3、负载均衡,读写分离
4、高可用基石
默认情况下,每台redis服务器都是主节点,一般我们只要配置从机就好了。
命令:Slaveof host port 服务重启后,会恢复主节点身份
现实情况下我们是需要在配置文件中配置的
# replicaof <masterip> <masterport>
# masterauth <master-password>
主从复制之复制原理:
Slave 启动成功连接到master之后,会向master发送一个sync同步命令
Master接收到命令之后,启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台执行完毕之后,master将传送整个数据文件到slave,并完成一次完全同步。
全量复制:而slave服务在接收到数据库文件数据后,将其存盘并加载到内存中。
增量复制:master继续将新的所有收集到的修改命令依次传给slave,完成同步。
但是只要重新连接master,将会进行一次全量复制,数据会被同不到从机中。
3、宕机后手动配置主机(没有配置哨兵模式)
如果主机断掉连接,我们可以使用slaveof no one 让自己变成主机,其他节点可以手动连接到最新的这个主节点。
如果之前的主节点恢复之后,需要自己手动重新配置主从关系。
4、哨兵模式(自动选举master节点)
哨兵模式是一种特殊的模式,首先redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,他会独立运行。其原理就是哨兵通过不断的发送命令,等到redis服务端响应,从而监控运行的多个redis服务。
Failover(故障转移)后台监控主机故障,如果故障了根据投票数自动将从库转换为主库。
配置哨兵配置文件 sentinel.conf
Sentinel monitor 被监控的服务名 host port 1
1 代表主机挂了,slave投票,看让谁成为主机。
启动命令:redis-sentinel sentinel.conf
主机服务断开连接之后,选举新的master之后,如果原来的主节点恢复了,会变成当前主节点的从节点。
哨兵的配置文件:
port 26379(默认)
dir /tem #工作目录
Sentinel monitor mymaster 127.0.0.1 6379 2
#哨兵sentinel监控的redis节点的ip port
Sentinel auth-pass mymaster 密码
#当redis开启了密码之后,所有连接redis实例的客户端都要提供密码
Sentinel down-after-milliseconds mymaster 30000(默认)
#指定30S内,主节点没有应答哨兵,此时哨兵认为主节点下线
Sentinel notification-script mymaster /var/redis/notify.sh
#通知脚本
- Redis缓存穿透和雪崩
缓存穿透(查不到):用户想要查询一个数据,发现redis内存中没有,缓存没有命中,于是向数据库查询,发现也没有,本次查询失败。当金星频繁多次请求之后,缓存没有命中,于是会请求持久层的数据库,这会给数据库造成很大的压力,这时候就相当于出现了缓存穿透。
解决方案:
布隆过滤器
布隆过滤器是一种数据结构,对所有可能查询的参数以hash形式存储,在控制层先进行校验,不符合则丢弃,从而避免了对底层存储系统的查询压力。
缓存空对象
当存储层不命中后,及时返回的空对象也将其缓存起来,同时会设置一个过期时间,之后再访问这个数据将会从缓存中获取,保护后端数据源。
但是这个方法回有两个问题:
- 如果空值能够被存储起来,这就意味着缓存需要更多的空间存储更多的键,因为这当中可能会有很多空值的键。
- 即使对空值设置了过期时间,还是会对存在缓存层和存储层的数据会有一段时间的不一致。
缓存击穿(量太大,缓存过期):是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点及逆行访问,当这个key失效的瞬间,持续的大并发穿破缓存,直接请求数据库,就像在一个屏障上早开了一个洞。
在某个key过期的瞬间,有大量的请求并发访问,这类数据一般是热点数据,由于缓存过期,会同时访问数据库来查询最新数据,并且回写缓存,会导致数据库压力过大。
解决方案:
设置热点数据永不过期,没有设置过期时间,所以不会出现热点key过期后产生的问题。
加互斥锁。使用分布式锁,保证对每一个key同事只有一个线程去查询后台服务,其他线程没有获得分布式锁的权限,因此只需要等待即可,这种方式将高并发的压力转义到了分布式锁,因此对分布式锁的考验很大。
缓存雪崩:是指在某一个时间段,缓存集中失效过期。或者redis宕机,所有的请求都会到达存储层,存储层的调用量会暴增,造成存储层也会挂掉的情况。
解决方案:
Redis高可用,多设几台redis,这样一台挂掉之后其他的还可以继续工作,其实就是搭建的集群。
限流降级:这个思想是在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
数据预热:就是在正式部署之前,先把可能的数据先访问一边,这样部分大量访问的数据就会加载到缓存中,在即将发生大并发访问前手动触发加载缓存不同的key,设置不同的过期时间,让缓存失效的时间点尽可能均衡。
- 缓存数据一致性
掩饰双删策略:
基本思路: 在写库前后都进行删除缓存操作,并且设置合理的超时时间
基本步骤: 先删除缓存–再写数据库—休眠一段时间—再次删除缓存
注:休眠的时间是根据自己的项目的读数据业务逻辑的耗时来确定的。这样做主要是为了保证在写请求之前确保读请求结束,写请求可以删除读请求造成的缓存脏数据。
该方案的弊端: 集合双删策略+缓存超时策略设置,这样最差的结果就是在超时时间内数据存在不一致,又增加了写请求的耗时















 610
610











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









