






本笔记记录springcloud alibaba的学习内容,依赖项目是读书笔记分享业务,业务较为简单,有助于纯粹学习框架知识。
技术栈:后端boot mvc cloud 数据库mybatis 前端小程序不作赘述。
主要功能:用户注册登陆与积分、内容分享中心。按照功能拆分为了两个微服务。
微服务概念
划分微服务的方法:DDD领域驱动设计Domain Drive Design、面向对象理念by name等。
微服务划分的侧面:根据功能进行划分、根据通用性进行划分。
拆分的粒度:满足业务、增量迭代(每次上线不会涉及到很多的模块)、持续进化(技术的变更也不会涉及很多模块)。
后端项目结构

首先是经典三层结构:Controller、Service、Dao,然后是Domain(存放实体类entity(与数据表对应)、dto(数据转换对象,与前端传递内容与entity之间的过渡实体)、枚举类),最后是配置类。结构简单清晰。
前置工作
项目流程
- 流程图、用例图、架构图
- 敲定业务流程
- 设计api、数据模型
- 编写api文档
- 编写代码
tk-mapper通用mybatis
通用mybatis的优势在于提供了一系列增删查改的自动化代码,同时还能生成数据表的实体类,大大简化了代码量和开发工作。同时,通用mybatis对原生mybatis的侵入性较小,对于复杂的业务,仍能够使用mybatis进行开发。通用mybatis的项目地址如下,按照开发文档使用。 https://github.com/abel533/Mapper![]() https://github.com/abel533/Mapper本次学习主要利用通用mybatis数据表与实体类的简单映射,基本的增删查改功能,以及专业代码生成器。
https://github.com/abel533/Mapper本次学习主要利用通用mybatis数据表与实体类的简单映射,基本的增删查改功能,以及专业代码生成器。
通用mybatis的配置
使用前需要增加依赖,并在启动项中增加注解@MapperScan(注意该注解需要来源于tk.mybatis.spring.annotation.MapperScan包,不是mybatis的包),用来扫描mapper接口自动实例化;也可以在接口上使用@Mapper注解。依赖如下:
<!-- 通用mybatis-->
<dependency>
<groupId>tk.mybatis</groupId>
<artifactId>mapper-spring-boot-starter</artifactId>
<version>2.1.5</version>
</dependency>
<dependency>
<groupId>tk.mybatis</groupId>
<artifactId>mapper</artifactId>
<version>4.0.4</version>
</dependency>如果只有第一个依赖,可能maven无法找到。
此外,还需要加入代码生成器的plugins依赖,如下所示:
<plugin>
<groupId>org.mybatis.generator</groupId>
<artifactId>mybatis-generator-maven-plugin</artifactId>
<version>1.3.6</version>
<configuration>
<configurationFile>
${basedir}/src/main/resources/generator/generatorConfig.xml
</configurationFile>
<overwrite>true</overwrite>
<verbose>true</verbose>
</configuration>
<dependencies>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.26</version>
</dependency>
<dependency>
<groupId>tk.mybatis</groupId>
<artifactId>mapper</artifactId>
<version>4.0.0</version>
</dependency>
</dependencies>
</plugin>注意两个点:一是mysql的版本号,可以设置跟自己MySQL版本一致。二是,configurationFile标签下的configure文件的配置,需要在resources/generator包中新建一个xml配置文件,里面需要包含自动生成代码的位置及依赖的数据表、数据库连接信息等。
参考官网,修修补补得到xml文件如下所示:
<!DOCTYPE generatorConfiguration
PUBLIC "-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN"
"http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd">
<generatorConfiguration>
<properties resource="generator/config.properties"/>
<context id="Mysql" targetRuntime="MyBatis3Simple" defaultModelType="flat">
<property name="beginningDelimiter" value="`"/>
<property name="endingDelimiter" value="`"/>
<plugin type="tk.mybatis.mapper.generator.MapperPlugin">
<property name="mappers" value="tk.mybatis.mapper.common.Mapper"/>
<property name="caseSensitive" value="true"/>
</plugin>
<jdbcConnection driverClass="${jdbc.driverClass}"
connectionURL="${jdbc.url}"
userId="${jdbc.user}"
password="${jdbc.password}">
</jdbcConnection>
<!-- 实体类的存放地址-->
<javaModelGenerator targetPackage="com.itmuch.springclouddemo.domain.entity.${moduleName}"
targetProject="src/main/java"/>
<!-- mapper文件存放地址-->
<sqlMapGenerator targetPackage="com.itmuch.springclouddemo.dao.${moduleName}"
targetProject="src/main/resources"/>
<!-- 接口存放地址-->
<javaClientGenerator targetPackage="com.itmuch.springclouddemo.dao.${moduleName}"
targetProject="src/main/java"
type="XMLMAPPER"/>
<!-- 生成实体类的表-->
<table tableName="${tableName}">
<generatedKey column="id" sqlStatement="JDBC"/>
</table>
</context>
</generatorConfiguration>上述xml文件有部分注释,此外需要注意的地方有三处:①jdbcConnection中的连接信息,设置了占位值,因此需要设置配置文件,在resources/generator包下设置配置文件。②resource标签中的配置文件路径,需要修改为“generator/config.properties”。③四处注释处分别表示需要生成代码的位置。
配置文件如下所示:
jdbc.driverClass=com.mysql.cj.jdbc.Driver
jdbc.url=jdbc:mysql://127.0.0.1:3306/user_center?nullCatalogMeansCurrent=true
jdbc.user=root
jdbc.password=123456
moduleName=user
tableName=user大功告成!简单测试即可。
整合lombok
在引入lombok依赖后,如何与通用mybatis整合呢?开发文档提到:
- lombok 增加 model 代码生成时,可以直接生成 lombok 的
@Getter@Setter@ToString@Accessors(chain = true)四类注解, 使用者在插件配置项中增加<property name="lombok" value="Getter,Setter,ToString,Accessors"/>即可生成对应包含注解的 model 类。
简单业务
接口文档见:ITMuch API
cloud Alibaba组件
版本问题
在使用alibaba组件之前,非常重要的是版本的选择,具体来说,官方spring cloud、spring boot、spring cloud alibaba及其组件之间有一定的对应关系(参考:版本说明 · alibaba/spring-cloud-alibaba Wiki · GitHub)。
就我个人理解,cloud项目一般是依赖于boot项目,因此应该根据boot版本进行选择cloud及其组件的版本。boot版本以2.4为分水岭,目前大部分项目为2.4以上,那么对应的cloud版本和cloud alibaba版本如下:

确定cloud版本后,才能确定各组件的版本对应关系:

本项目使用了 2.3.2.RELEASE 的boot版本,那么对应cloud应该为 Hoxton.SR9 ,cloud alibaba为 2.2.5.RELEASE。在生产环境, 最好选择上一个稳定版本(release版本)。
基于此,pom文件需要导入依赖如下:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Hoxton.SR9</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.2.5.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>nacos
nacos的原理及架构可参考官方文档。配置的主要步骤为:下载nacos、启动nacos服务、导入pom依赖、加上注释、写配置。无需指定nacos的版本信息,会依据cloud的版本进行下载,通过maven可以查看是2.2.5版本的nacos。
<!-- 添加nacos依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>在启动类加上@EnableDiscoveryClient注解(也可以不打注解)。此外,properties配置文件需要指明该应用的注册名称和注册中心的地址。如下:
# 应用名称
spring.application.name=user-center
# 设置配置中心服务端地址
spring.cloud.nacos.config.server-addr=localhost:8848访问"localhost:8848/nacos",即可看到当前注册成功了服务:

nacos领域模型

各个领域模型的定义在properties文件中指定即可。
使用ribbon实现客户端负载均衡

ribbon是在消费端实现负载均衡的。
ribbon的初体验
提前准备了两个user-center实例,用来测试负载均衡的功能。
RestTemplate是请求发送器,将RestTemplate注册为Bean,然后调用getForObject方法,从而实现不同模块之间服务的调用。
ribbon的配置体现在:不需要pom配置(已包含在nacos中)、不需要properties配置,为RestTemplate的bean对象添加@loadBalanced即可。
@Bean
@LoadBalanced
public RestTemplate restTemplate(){
return new RestTemplate();
} @Resource
private ShareMapper shareMapper;
@Resource
private RestTemplate restTemplate;
public ShareDto getShareById(Integer id) {
Share share = shareMapper.selectByPrimaryKey(id);
ShareDto shareDto = new ShareDto();
BeanUtils.copyProperties(share,shareDto);
//获取微信昵称
Integer userId = shareDto.getUserId();
UserDto userDto = restTemplate.getForObject("http://user-center/users/{userId}", UserDto.class,userId);
log.info("http://user-center/users/{userId}");
shareDto.setWxNickname(userDto.getWxNickname());
return shareDto;上述代码中,user-center为服务方名称,ribbon能通过user-center找到注册在服务方的地址,从而实现访问。ribbon是如何根据服务名称,进行负载均衡分配,并得到服务提供方的地址呢?
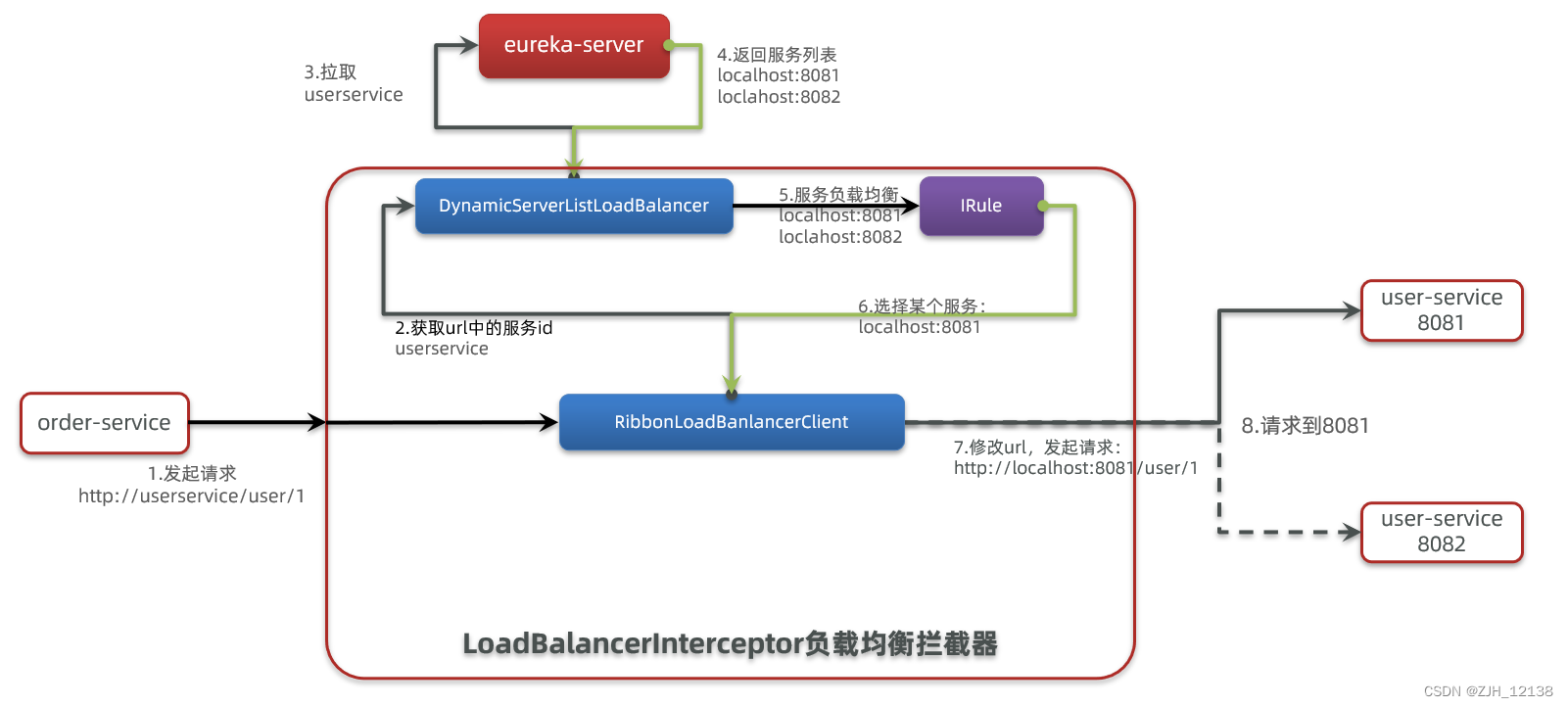
如果存在多个服务方,则通过均衡算法进行选择,以下介绍均衡算法类型及配置方法。
ribbon均衡算法及自定义配置方法
ribbon均衡规则如下所示:

使用ribbon过程中,若默认的负载均衡规则(默认是轮询规则,RoundRobinRule)无法满足需求,则需要手动配置。配置方式有两种:使用代码、使用配置文件。

使用代码配置不同粒度的规则
使用Java代码配置负载均衡规则,虽然麻烦, 但自定义程度较高,能单独为某一个服务群配置轮询,也能配置全局规则。为某个服务群进行单独配置的步骤如下:
1、在content-center项目中,为启动类增加@LoadBalancer注解后,构建user-center的configuration,主要依赖外部config。这里的外部表示com.wut之外的包,不被启动类中的注解扫描。
@Configuration
@RibbonClient(name = "user-center" , configuration = RibbonConfig.class)
public class UsercenterRibbonConf {
}注意三个点:@RibbonClient注解、name变量、configuration变量指向外部config类。
2、设置具体的外部轮询规则类,并将其交由spring容器管理。注意该外部配置类不要被com.wut扫描。
@Configuration
public class RibbonConfig {
@Bean
public IRule ribbonRule(){
return new RandomRule();
}
}如此便使用Java代码的方式实现了随机轮询算法,多次访问测试接口后,两个示例的访问量不完全相同。
注意,上述UsercenterRibbonConf配置类中,注解@RibbonClient中的configuration参数指定的是自己构建的外部config,理论上可以多元化,但是本例只是用作演示,故直接返回了randomRule。实际上,如果要采用random方案,没必要引入外部类,直接在configuration参数赋值“com.netflix.loadbalancer.RoundRobinRule.class”即可。
使用属性方式配置轮训规则
在服务消费方content-srv的properties文件中,添加如下配置,可以为user-center服务群增加轮询规则。
user-center.ribbon.NFLoadBalancerRuleClassName=com.netflix.loadbalancer.RandomRule其中user-center为服务名称,“=”右为轮训规则的全路径,统计如下:
======================后续补充===============
全局轮训规则的指定
全局轮询规则依赖Java方式的配置,在局部配置的基础上进行修改,configuration类如下,注解名称修改为RibbonClients,不指定服务提供方的名称。
@Configuration
@RibbonClients(defaultConfiguration = RibbonConfig.class)
public class UsercenterRibbonConf {
}使用代码还能配置其他规则
在外部configuration类中,除了轮询规则外,还能配置其他内容:

配置方法与轮询方法一致,采用代码方式 即可。
为轮询规则增加权重
此处思路为:获取服务提供方名称,获取nacos的api,借助nacos轮询算法,将传递服务名称,选择一个服务实例,最后返回即可。
@Slf4j
public class NacosWeightedRibbonConf extends AbstractLoadBalancerRule {
@Resource
private NacosDiscoveryProperties nacosDiscoveryProperties;
@Override
public void initWithNiwsConfig(IClientConfig iClientConfig) {
}
@Override
public Server choose(Object o) {
try {
BaseLoadBalancer loadBalancer = (BaseLoadBalancer)this.getLoadBalancer();
//获取服务方名称
String serverName = loadBalancer.getName();
//借助nacos的权重负载均衡方案,此处获取nacos的api
NamingService namingService = nacosDiscoveryProperties.namingServiceInstance();
//核心:找到服务实例,此处依赖了nacos的加权轮询算法,权重可以在nacos交互界面指定。
Instance instance = namingService.selectOneHealthyInstance(serverName);
log.info("找到的示例为:port = {}, instance = {}",instance.getPort(), instance);
return new NacosServer(instance);
} catch (NacosException e) {
return null;
}
}
}权重在nacos可视化界面中指定。
@Slf4j
public class NacosSameWeightedRibbonConf extends AbstractLoadBalancerRule {
@Resource
private NacosDiscoveryProperties nacosDiscoveryProperties;
@Override
public void initWithNiwsConfig(IClientConfig iClientConfig) {
}
@Override
public Server choose(Object o) {
try {
//获取服务提供方的名称
BaseLoadBalancer loadBalancer = (BaseLoadBalancer) getLoadBalancer();
String serverName = loadBalancer.getName();
//根据名称获取当前服务方所属的cluster及其实例列表
String clusterName = nacosDiscoveryProperties.getClusterName();
NamingService namingService = nacosDiscoveryProperties.namingServiceInstance();
List<Instance> allInstancesList = namingService.selectInstances(serverName, true);
//确定实例列表,通过对比实例列表分组与需求方分组的cluster是否是同一个,否则采用普通的轮询。
List<Instance> selectInstanceList = allInstancesList.stream().filter(instance -> Objects.equals(instance.getClusterName(), clusterName)).collect(Collectors.toList());
List<Instance> instanceListSelected = new ArrayList();
if(selectInstanceList == null) {
//true表示cluster均不匹配
instanceListSelected = allInstancesList;
log.info("发生跨群调用:cluster_name={}",clusterName);
}else{
instanceListSelected = selectInstanceList;
}
//根据instanceListSelected这个instanceList,采用加权随机轮训算法
Instance instance = myBalancer.getInstanceByRandomWeight(instanceListSelected);
log.info("找到的示例为:port = {}, instance = {}",instance.getPort(), instance);
return new NacosServer(instance);
} catch (NacosException e) {
return null;
}
}
}
class myBalancer extends Balancer{
public static Instance getInstanceByRandomWeight(List<Instance> instanceListSelected){
return getHostByRandomWeight(instanceListSelected);
}
}OpenFeign优雅的远程调用
openfeign也属于cloud alibaba组件之一,用来进行远程调用。方法如下:
①加入依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
<version>2.2.5.RELEASE</version>
</dependency>②添加注解:
启动类需要加上:
@EnableFeignClients("com.wut.config")
③进行配置,配置路径名称为feign的配置路径。
在("com.wut.config")中,新增接口:
@FeignClient(name = "user-srv")
public interface UserSrvFeignClient {
@GetMapping("/user/{id}")
UserDto findUserByUserId(@PathVariable("id") Integer id);
}上述接口中,首先是注解@FeignClient依赖,名称是服务提供者的名称。其次,feign还支持mvc注解GetMapping,但是需要加上@PathVAriable。
当调用该接口中的findUserById方法时,相当于 调用:http://user-srv/user/{id}。
openFeign的其他配置【以feign日志为例】:
Feign日志的级别如下,默认是NONE,即不打印任何日志。

如果要设置日志级别,也就是设置Feign的配置,如果采用代码进行配置,可以采用以下步骤:
①构建配置类,配置类不可被重复扫描。可用两种方式:1、位于扫描类外;2、不加@Configuration注解。
//不要加configuration注解,避免重复扫描
public class UserSrvFeignLog {
@Bean
public Logger.Level level() {
return Logger.Level.FULL;
}
}②在feign配置接口上补充configuration属性。
@FeignClient(name = "user-srv" , configuration = UserSrvFeignLog.class)
public interface UserSrvFeignClient {
@GetMapping("/user/{id}")
UserDto findUserByUserId(@PathVariable("id") Integer id);
}③在yaml文件中补充等级级别
logging:
level:
com.wut.config.UserSrvFeignLog: debug
如果直接采用属性配置:
feign:
client:
config:
user-srv:
loggerLevel: full
feign的全局配置
如果采用代码的方式进行配置,
全局配置就是将服务名称user-srv换成default即可,表示对user-srv的路径映射的日志采用full级别。
ribbon和feign配置方法的对比
ribbon主要是实现服务方选取与负载均衡,feign是更方便实现需求方与服务方之间的服务调用。但两者的配置方式有相似性,如两者都是属性优先级高于代码优先级。
其中,ribbon可以设置很多配置,如果采用代码配置的方式,均可以放在X 类中(Y同理)。如果采用属性的话,直接罗列即可。

此外,ribbon不需要在启动类增加注解,feign需要在启动类中增加@EnableFeignCLient注解,并设置config包路径。
父子上下文的扫描重叠问题
重叠后会导致事务失效。重叠的意思是:启动类使用了@SpringbootApplication注解,会扫描所在的包中,被@Component注解的类。详见:Spring父子上下文解析 - 简书 (jianshu.com)
服务容错sentinel
几种方案:超时、限流、仓壁模式、断路器。
本次主要学习sentinel库,用来实现轻量级的流量控制、熔断控制等功能。
导入依赖,无需版本号。
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>同时,结合actuator直观判断sentinel效果,需要引入actuator依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-actuator</artifactId>
</dependency>并暴漏actuator接口:
management:
endpoint:
web:
exposure:
include: '*'
使用sentinel控制台
sentinel使用的是懒加载,当访问某一端口后,才会显示出当前服务

设置限流规则,当限流后,出现以下提示:Blocked by Sentinel (flow limiting)
sentinel提供了灵活且强大的限流能力,界面如下所示。

其中,资源名一般填写接口,表示限流的路径;来源可以设置为微服务名称,以微服务为单位进行限流控制;流控效果有如下三种:【后续可深入学习源码】
| 名称 | 解释 | 适用场景 |
| 快速失败 | 若超过阈值,直接展示:Blocked by Sentinel (flow limiting) | 严格控制场景,会直接拒绝超过阈值的请求 |
| WarmUp | 低谷是阈值/3,峰值是阈值,过程中会平滑上升 | 峰值出现情况较少场景,如秒杀。 |
| 排队等待 | 所有请求都会被处理,不过要经过先来后到的顺序 | 需处理所有请求,因服务器性能因素而限流 |
流控模式也有三种,每种流控模式都能选择三种流控效果。
| 直接 | 最简单,就是直接对资源名的接口进行限流 |
| 关联 | 需设置关联资源(也是接口),若关联资源达到阈值也会限流 |
| 链路 | 只收集制定链路接口的流量,对api进行限流 |
对于链路的详细解释,假设存在链路:a->b->c,目标资源是c,入口资源是a,则限流对a、c有用,b不受限制。
sentinel熔断降级

慢调用比例 (SLOW_REQUEST_RATIO):选择以慢调用比例作为阈值,需要设置允许的慢调用 RT(即最大的响应时间),请求的响应时间大于该值则统计为慢调用。当单位统计时长(statIntervalMs)内的请求数目大于设置的最小请求数目,并且慢调用的比例大于阈值,则接下来的熔断时长内请求会自动被熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求响应时间小于设置的慢调用 RT 则结束熔断,若大于设置的慢调用 RT 则会再次被熔断。
sentinel热点规则
对api限流甚至对参数的值进行限流。其中索引表示请求参数的顺序(参数需为基本类型或string)。适用于: 某些个别参数请求较高的场景。

将sentinel与spring进行整合

使用api为资源限流
不仅仅能在交互界面为spring接口增加限流规则,还能对资源进行保护,使用的核心sentinel API为sphU(定义、保护资源)、Tracer(跟踪异常并进行统计)、ContextUtil(统计调用来源)。
public class TestController {
@GetMapping("/test-sentinel-api")
public String testSentinelApi(@RequestParam(required = false) String a) {
String resourceName = "sentinel-test-sourcename";
String originName = "test-origin";
ContextUtil.enter(resourceName,originName);
Entry entry = null;
try {
//定义一个sentinel保护的资源
entry = SphU.entry(resourceName);
if (StringUtils.isEmpty(a)) {
throw new IllegalArgumentException("a不能为空");
}
return a;
}catch (BlockException be) {
//如果被降级或者限流,则会抛出BlockException异常。
log.info("未找到资源:{}",be);
return "被限流了";
}catch (IllegalArgumentException ie) {
//创建catch分支,记录IllegalArgumentException异常。
Tracer.trace(ie);
return "请输入参数";
}finally {
if (entry !=null) {
//entry不为空,一定要退出。
entry.exit();
}
ContextUtil.exit();
}
}
}@sentinelResource注解
上述代码比较麻烦,可以使用注解@sentinelResource进行简化。配置项总结如下:
Alibaba Sentinel 配置项总结_慕课手记 (imooc.com)![]() https://www.imooc.com/article/289384
https://www.imooc.com/article/289384
@GetMapping("/test-sentinel-annotation")
@SentinelResource(value = "sentinel-test-sourcename" , blockHandler = "testSentinelBlock", blockHandlerClass = SentinelBlockConf.class , fallback = "testSentinelFallback" ,fallbackClass = SentinelFallbackConf.class )
public String testSentinelAnnotation(@RequestParam(required = false) String a) {
if (StringUtils.isEmpty(a)) {
throw new IllegalArgumentException("a不能为空");
}
return a;
}
}
注意注解中的属性,包含两类四个。其中block表示被限流后的处理类;fallback表示出现其他异常后的处理类。各个处理类需要与Controller方法同名同参,且用static修饰。如下:
@Component
@Slf4j
public class SentinelBlockConf {
//被限流时,进行异常处理
public static String testSentinelBlock (String a , BlockException be) {
//如果被降级或者限流,则会抛出BlockException异常。
log.info("未找到资源:{}",be);
return "因block被限流了";
}
}@Component
@Slf4j
public class SentinelFallbackConf {
//捕获异常,进行处理,此处的异常是指除了blockexception的异常
public static String testSentinelFallback(String a, Throwable throwErr) {
//如果被降级或者限流,则会抛出BlockException异常。
log.info("未找到资源:{}", throwErr);
return "因fallback被限流了。";
}
}@SentinelRestTemplate注解
该注解使用在RestTemplate上。
Feign整合sentinel
加配置feign.sentinel.enabled,表示资源在跨服务调用的同时更符合restful。
RocketMQ
启动rocketMQ服务,首先启动命名服务器:start mqnamesrv.cmd;然后启动broker服务器:start mqbroker.cmd -n 127.0.0.1:9876 autoCreateTopicEnable=true。
RocketMQ使用初探
三步骤:加依赖、加注解、加配置
对生产者的rocketMQ使用如下:
1、选择版本2.0.3的依赖。
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-spring-boot-starter</artifactId>
<version>2.0.3</version>
</dependency>2、没有注解,生产者的配置如下:
rocketmq:
name-server: 127.0.0.1:9876
producer:
group: test-group3、选择contentsrv作为消息生产者,完成功能:①查询当前分享动态的状态(是否存在);②变更share的审核属性(AuditStatus和Reason);③如果审核后的share状态为PASS,则修改用户积分(需要跨服务)。
重点在第三步,采用rocketMQ方案,将修改用户积分的需求需要消息体在contentsrv与usersrv两个服务之间传送,前者生产消息,后者消费该消息,并处理其中的业务逻辑(变更积分)。生产者的业务代码如下:
@Service
public class ShareAdminService {
@Resource
private ShareMapper shareMapper;
@Resource
private RocketMQTemplate rocketMQTemplate;
public Share auditById(Integer id, ShareAdminDto shareAdminDto) {
//查询当前share是否存在
Share share = shareMapper.selectByPrimaryKey(id);
if(share == null) {
throw new IllegalArgumentException("该条动态不存在!");
}
if(!"NOT_YET".equals(share.getAuditStatus())) {
throw new IllegalArgumentException("该条动态已经被审核!");
}
// 变更审核状态,并补充原因
share.setReason(shareAdminDto.getReason());
share.setAuditStatus(shareAdminDto.getAuditStatusEnums().toString());
shareMapper.updateByPrimaryKey(share);
// 如果状态为修改为pass,则需要用户中心变更积分,可以使用异步
rocketMQTemplate.convertAndSend("test-add-bonus",
UserAddBonusMsgDto
.builder()
.userId(share.getUserId())
.bonus(50)
.build());
return share;
}
}4、消息消费者(usersrv)消费消息,同样需要遵循加依赖、写配置、加注解(与消费者一致),新建类AddBonusListener监听消息体,业务代码如下:
@Service
@RocketMQMessageListener(consumerGroup = "consumer-group" , topic = "test-add-bonus")
public class AddBonusListener implements RocketMQListener<UserAddBonusMsgDto> {
@Resource
private UserMapper userMapper;
@Resource
private BonusEventLogMapper bonusEventLogMapper;
@Override
public void onMessage(UserAddBonusMsgDto userAddBonusMessage) {
//为相应的用户变更积分
Integer userId = userAddBonusMessage.getUserId();
User user = userMapper.selectByPrimaryKey(userId);
user.setBonus(user.getBonus()+userAddBonusMessage.getBonus());
userMapper.updateByPrimaryKeySelective(user);
// 将积分变更写入日志记录中
bonusEventLogMapper.insert(BonusEventLog.builder()
.userId(userId)
.value(userAddBonusMessage.getBonus())
.event("CONTRIBUTION")
.createTime(new Date())
.description("CONTRIBUTION-BONUS")
.build());
}
}业务逻辑比较简单,重点是@RockerMQMessageListener注解,参数包括:consumerGroup、topic,topic必须与生产者的topic一致。
分布式事务的实现
为什么要分布式事务?
在上述业务逻辑中,生产者的步骤分为了3步,前两步是本地服务实现,最后积分操作需要跨微服务。如果本地服务成功,但是跨服务失败,此时也无法对本地服务进行回退,因此需要完成分布式事务。
使用rocketMQ实现分布式事务的流程:

参考资料:(52条消息) 基于RocketMQ分布式事务 - 完整示例_rocketmq 分布式事务_架构攻城之路的博客-CSDN博客
几个概念
半消息:生产者发送半消息至broker,但broker并不对其进行转发,这意味着消费者展示无法进行消费。消费者能够对其进行消费的前提是:二次确认的(第4步)结果是commit时,broker才会转发至消费者进行消费。
半消息是需要跨服务的消息,内容其实与全消息的内容一致,可以直接给消费者消费,但前提是需要本地业务(将share的属性进行更新)成功commit。因此,其内容应该与之前的一致,只是写法不同。
事务状态回查:在broker收到半消息后,会等待生产者对本地事务结果的二次确认,若确认为commit,则会讲半消息发送给消费者;若确认为rollback,则会丢弃半消息。若一直没有收到该状态确认,则会进行回查(第5步)。
分布式事务消费端业务代码
遵循以上流程图中的顺序。
1、发送半消息。
当前端审核为pass后,开启当前业务流程,可以发送半消息。
//如果接受到的审核结果为pass,则发送半消息给rocketMQ,需要消费者(用户中心)来变更积分并增加日志。
if(AuditStatusEnums.PASS.equals(shareAdminDto.getAuditStatusEnums())) {
//如果是pass,表明需要变更积分,首先想brocker发送半消息。(pass是事务中的第一步,只有pass状态才开启半消息发送。)
//方法sendMessageInTransaction需四个参数,事务生产组名、消费者名、消息体、参数。消息体包含UserAddBonusMsgDto对象,消息头包含shareAdminDto
rocketMQTemplate.sendMessageInTransaction(
"test-transaction",
"test-add-bonus",
MessageBuilder.withPayload(UserAddBonusMsgDto
.builder()
.userId(share.getUserId())
.bonus(50)
.build())
.setHeader(RocketMQHeaders.TRANSACTION_ID, UUID.randomUUID().toString())
.setHeader("shareId", share.getId())
.build(),
shareAdminDto);
}else {
//若用户状态不为pass,则不需要跨服务的事务,只需要变更share信息即可,不用变更用户积分。
this.auditByIdInDB(id, shareAdminDto);
}重点:rocketMQTemplate类中的sendMessageInTransaction方法就是rocketMQ提供的分布式事务消息,需要四个参数:
String txProducerGroup, String destination, Message<?> message, Object arg
因此,txProducerGroup表示事务组名称,这个需要与生产者中的监听器的名称保持一致;destination需要与消费者的保持一致。Message的来源package org.springframework.messaging.support,由spring支持,通过设置负载(withPayLoad)和消息头(Header)的方式将携带所需信息,这里的参数多为json类型;arg表示其他参数,此处设置了shareAdminDto。
2、执行本地事务。
本地事务业务就是,更新share中的信息,将share中的审核结果及其原因进行更新。代码与发送半消息的代码处于同一类中。调用方其实是事务的监听者,这个后面会讲到。
//独立出“变更share信息”功能,该功能也属于事务中的一部分
@Transactional(rollbackFor = Exception.class)
public void auditByIdInDB(Integer id, ShareAdminDto shareAdminDto) {
Share shareTem = Share.builder()
.id(id)
.auditStatus(shareAdminDto.getAuditStatusEnums().toString())
.reason(shareAdminDto.getReason())
.build();
shareMapper.updateByPrimaryKeySelective(shareTem);//注意这里是仅更新有参数的值,因此new一个share没有关系。
}
//独立出“变更share信息”功能的同时,进一步记录日志记录,作为事务是否成功提交的证据(是上一版的进阶不是平行关系)
@Transactional(rollbackFor = Exception.class)
public void auditByIdInDBWithLog(Integer id, ShareAdminDto shareAdminDto, String transactionId) {
//首先执行变更用户的业务代码
this.auditByIdInDB(id, shareAdminDto);
//增加事务日志
RocketmqTransactionLog.builder().transactionId(transactionId).log("success-tx").build();
}3、执行本地事务、回查事务状态
上述方法中的业务代码比较简单,但切入点的设置需要新建本地事务监听器AddBonusTransactionListener。
@RocketMQTransactionListener(txProducerGroup = "test-transaction")
public class AddBonusTransactionListener implements RocketMQLocalTransactionListener {
@Resource
private ShareAdminService shareAdminService;
@Resource
private RocketmqTransactionLogMapper rocketmqTransactionLogMapper;
@Override
//执行本地事务
public RocketMQLocalTransactionState executeLocalTransaction(Message message, Object o) {
MessageHeaders headers = message.getHeaders();
//获取本地事务流程中必备的ID和shareDto
Integer shareId = Integer.valueOf((String) headers.get("shareId"));
String transactionID = (String) headers.get(RocketMQHeaders.TRANSACTION_ID);
//执行本地事务
try {
shareAdminService.auditByIdInDBWithLog(shareId, (ShareAdminDto) o, transactionID);
return RocketMQLocalTransactionState.COMMIT;
} catch (Exception e) {
return RocketMQLocalTransactionState.ROLLBACK;
}
}
@Override
//二次检查本地事务是否commit,即第5步的过程
public RocketMQLocalTransactionState checkLocalTransaction(Message message) {
MessageHeaders headers = message.getHeaders();
//获取半消息中的已提交的事务id
String transactionID = (String) headers.get(RocketMQHeaders.TRANSACTION_ID);
//若事务表中包含该id,说明执行成功
RocketmqTransactionLog rocketmqTransactionLog = rocketmqTransactionLogMapper.selectOne(
RocketmqTransactionLog.builder().transactionId(transactionID).build()
);
if(rocketmqTransactionLog != null) {
return RocketMQLocalTransactionState.COMMIT;
}
return RocketMQLocalTransactionState.ROLLBACK;
}
}重点:本地事务监听类包含两个方法,本地事务的执行方法executeLocalTransaction和事务执行状态查询方法checkLocalTransaction。
前者是调用执行本地的业务方法auditByIdInDB,其步骤为:①获取消息头信息,以便拿到事务id等信息;②执行本地方法(需要保持事务一致性的方法),变更sahre的属性状态;③如果本地方法成功,则事务返回状态commit,否则回滚。
后者作用是,当broker未收到Producer事务的确认消息时,会进行回查(第5步)。回查逻辑是查看事务日志记录表,如果存在记录,则表明本地事务成功提交。
gateway网关


几个概念:
路由(Route):是构建网关的基本模块,他是ID,目标URL,一系列的断言和过滤器组成,如果断言为true,则匹配该路由。
断言(Predicates):输入类型是一个ServerWebExchange。我们可以使用它来匹配来自HTTP请求的任何内容,例如headers或参数。
过滤器(Filter):Gateway中的filter分两种类型,一种是GateWay Filter,一种是Gloabl Filter。过滤器将会对请求和响应进行修改处理。
主要学习断言和过滤器的使用。
断言predicate及其自定义
其中,断言是匹配请求和路由的关键,断言工厂有如下几种类型:















 834
834











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









