









Hello,你们的好朋友来了!今天猜猜我给大家带来点啥干货呢?最近很多小伙伴出去面试的时候经常会被问到跟自动化测试相关的面试题。所以,今天特意给大家整理了一些经常被公司问到的自动化测试相关的面试题。停,咱先收藏起来好吗,别到时候找不到了,再问我要,我可就要装作不认识你了哈。
好了,咱废话不多说,直接上干货吧。
一. 第一个最常被问到的问题:你最熟悉的元素定位方式有哪些?
id :根据 id 来获取元素,返回单个元素, id 值一般是唯一的;
name :根据元素的 name 属性定位;
tagName :根据元素的标签名定位;
className :根据元素的样式 class 值定位;
linkText :根据超链接的文本值定位;
partialLinkText :根据超链接的部分文本值定位;
cssSelector : css 选择器定位;
xpath :通过元素的路径来定位;
优先级最高: ID
优先级其次: name
优先级再次: CSS selector
优先级再次: Xpath
二、如果一个元素无法定位,你一般会考虑哪些因素呢?
这个在我们实际自动化测试过程中也会经常遇到,那一般可以从以下几个方面去考虑:
1、元素定位的方式有误,可以检查元素定位的方法是否正确
2、页面元素加载过慢,需要添加等待时间
3、页面中有框架面,需要先切换到正确的frame框架再进行定位
三、如果一个元素无法定位,你一般会考虑哪些因素呢?
这个在我们实际自动化测试过程中也会经常遇到,那一般可以从以下几个方面去考虑:
1、元素定位的方式有误,可以检查元素定位的方法是否正确
2、页面元素加载过慢,需要添加等待时间
3、页面中有框架面,需要先切换到正确的frame框架再进行定位
四、说一说你知道的自动化测试框架
1、RobotFramework
2、Pytest
3、Unittest
4、PyUnit
五、自动化测试中有几种等待方式,它们之间有什么区别吗?
1、强制等待
time.sleep(3):这种等待方式,意味着必须要等待3秒才可以执行后续的代码。这种形式不够灵活,有可能页面3秒之内已经加载完了,但是还是需要等待3秒才能进行下一步操作。
2、隐式等待
Imlicitlywait:这种形式的等待会在时间内不断查找元素,找到后就可以停止等待。但是这种形式需要等待整个页面加载完成才能进行下一步操作。
3、显式等待
WebDriverWait:这种形式的等待,是针对某个元素进行等待,这个元素只要加载完成就可以执行后续的代码了。这种形式比较灵活。
六、什么是PO模式,它有哪三层?三者的关系是怎样的?
PO模式是一种自动化测试设计思想,是把一个页面看成一个对象,页面的元素看成对象的属性和行为。PO模式一般有三层:
基础层:封装一些最基础的方法
页面对象层:元素定位,页面操作等
测试用例层:业务逻辑,数据驱动
这三层的关系:
页面对象层继承基础层,测试用例层调用页面对象层
七、自动化测试的流程是什么?
1、编写自动化测试计划
2、设计自动化测试用例
3、开发自动化测试脚本
4、执行自动化测试脚本
5、生成自动化测试报告,并分析测试结果
八.你写的测试脚本能在不同浏览器上运行吗
当然可以,我写的用例可以在在 IE ,火狐和谷歌这三种浏览器上运行。实现的思路是封装一个方法,分别传入一个浏览器的字符串,如果传入 IE 就使用 IE ,如果传入 FireFox 就使用 FireFox ,如果传入 Chrome就使用 Chrome 浏览器,并且使用什么浏览器可以在总的 ini 配置文件中进行配置。需要注意的是每个浏览器使用的驱动不一样。
九.在你做自动化过程中,遇到了什么问题吗?举例下
这个问题,不管是自动化还是任何工作,都会被问到。主要想知道你是如何解决问题的,从而推断你问题分析和解决的能力。 当然有遇到问题和挑战,主要有以下几点: 频繁地变更 UI ,经常要修改页面对象里面代码 运行用例报错和处理,例如元素不可见,元素找不到这样异常 测试脚本复用,尽可能多代码复用 一些新框架产生的页面元素定位问题,例如 ck 编辑器,动态表格等
十.xpath和css定位都比较强大,那他们之间有什么区别?
① CSS locator 比 XPath locator 速度快 , 因为 css 是配合 html 来工作,它实现的原理是匹配对象的原理,而xpath 是配合 xml 工作的,它实现的原理是遍历的原理,所以两者在设计上, css 性能更优秀②对于 class 属性 Css 能直接匹配部分,而 Xpath 对于 class 跟普通属性一致③ xpath 可匹配祖先元素 ,css 不可以④查找兄弟元素, Css 只能查找元素后面 ( 弟弟妹妹 ) 的元素,不能向前找 ( 哥哥姐姐 )
十一. 列表推导式
列表推导式(又称列表解析式)提供了一种简明扼要的方法来创建列表。
它的结构是在一个中括号里包含一个表达式,然后是一个for语句,然后是 0 个或多个 for 或者 if 语句。那个表达式可以是任意的,意思是你可以在列表中放入任意类型的对象。返回结果将是一个新的列表,在这个以 if 和 for 语句为上下文的表达式运行完成之后产生。
列表推导式的执行顺序:各语句之间是嵌套关系,左边第二个语句是最外层,依次往右进一层,左边第一条语句是最后一层。
[x*y for x in range(1,5) if x > 2for y in range(1,4) if y < 3]
复制代码他的执行顺序是:
for x in range(1,5)
if x > 2
for y in range(1,4)
if y < 3
x*y
复制代码请用列表导式实现,根据一个列表生成一个新的列表。根据某种规则:求平方。一行代码实现。
# 请用列表导式实现,根据一个列表生成一个新的列表# 根据某种规则:求平方# 一行代码实现# 第一种并没有实现1和2list1 = [1,2,3,4,5,6]
# list2 = []# for i in list1:# print(i)# r = i * i# list2.append(r)# print(list2)# 第二种方法可实现# 用map函数也可以实现# result = map(lambda x:x*x,list1)# print(list(result))# 第三种方法可实现# 列表推导式实现# result = [i*i for i in list1]# print(result)result = [i**3 for i in list1]
print(result)
#最终只返回大于60的数字,补充i不是返回的结果,i是列表中的元素result = [i**3 for i in list1 if i**3 > 60]
print(result)
# 第四种方法可实现# 只计算大于3的数字即可result = [i**3 for i in list1 if i > 3]
print(result)
# 只计算小于3的数字即可result = [i**3 for i in list1 if i < 3]
print(result)
复制代码十二. 冒泡排序的排序思路
# 请使用冒泡排序法,将以下列表中的元素从小到大进行排序list1 = [5,3,2,10,15,13]
# 实现思路是:两个相邻的数字进行比较,大的向上浮,小的向下沉,最后一个元素是最大的
"""
现在的列表:[5,3,2,10,15,13]
1、比较5和3,具体谁大,name5大于3,所以它们两个袁术的位置就要进行交换
[3,5,2,10,15,13]
2、比较5和2,此时的列表[3,5,2,10,15,13],5比2大,所以5和2交换位置
[3,2,5,10,15,13]
3、比较5和10,那么位置不动
[3,2,5,10,15,13]
4、比较10和15,那么10和15小,所以位置不动
[3,2,5,10,15,13]
5、比较15和13,那么15比13大,所以它们交换位置
[3,2,5,10,13,15]
----------------第一轮比较结束----------
6、比较3和2,那么3比2大,所以热门交换位置
[2,3,5,10,13,15]
7、比较3和5,那么3和5小,所以它们的位置不变
[2,3,5,10,13,15]
8、比较5和10,那么5比10小,所以它们的位置不变
[2,3,5,10,13,15]
9、比较10和13,那么10比13小,所以它们的位置不变
[2,3,5,10,13,15]
经过第一轮的比较,我们已经知道了最后一个元素就是最大的,所以这里13和15就不用比较了
----------------第二轮比较结束----------
10、比较2和3,那么2比3小,所以它们的位置不变
[2,3,5,10,13,15]
11、比较3和5
[2,3,5,10,13,15]
12、比较5和10
[2,3,5,10,13,15]
----------------第三轮比较结束----------
13、比较2和3,那么2比3小,所以它们的位置不变
[2,3,5,10,13,15]
14、比较3和5
[2,3,5,10,13,15]
----------------第四轮比较结束----------
这个时候意味着后边的4个已经确认了他们的顺序
15、比较2和3,那么2比3小,所以它们的位置不变
[2,3,5,10,13,15][3,5,2,10,15,13][3,2,5,10,15,13][3,2,5,10,15,13][3,2,5,10,15,13][3,2,5,10,13,15][2,3,5,10,13,15][2,3,5,10,13,15][2,3,5,10,13,15][2,3,5,10,13,15][2,3,5,10,13,15][2,3,5,10,13,15][2,3,5,10,13,15][2,3,5,10,13,15][2,3,5,10,13,15][2,3,5,10,13,15][2,3,5,10,13,15]
"""
复制代码十四. 冒泡排序法--代码实现
# 请使用冒泡排序法,将以下列表中的元素从小到大进行排序list1 = [5,3,2,10,15,13]
# 实现思路是:两个相邻的数字进行比较,大的向上浮,小的向下沉,最后一个元素是最大的
"""
现在的列表:[5,3,2,10,15,13]
1、比较5和3,具体谁大,name5大于3,所以它们两个袁术的位置就要进行交换
[3,5,2,10,15,13]
2、比较5和2,此时的列表[3,5,2,10,15,13],5比2大,所以5和2交换位置
[3,2,5,10,15,13]
3、比较5和10,那么位置不动
[3,2,5,10,15,13]
4、比较10和15,那么10和15小,所以位置不动
[3,2,5,10,15,13]
5、比较15和13,那么15比13大,所以它们交换位置
[3,2,5,10,13,15]
----------------第一轮比较结束----------
6、比较3和2,那么3比2大,所以热门交换位置
[2,3,5,10,13,15]
7、比较3和5,那么3和5小,所以它们的位置不变
[2,3,5,10,13,15]
8、比较5和10,那么5比10小,所以它们的位置不变
[2,3,5,10,13,15]
9、比较10和13,那么10比13小,所以它们的位置不变
[2,3,5,10,13,15]
经过第一轮的比较,我们已经知道了最后一个元素就是最大的,所以这里13和15就不用比较了
----------------第二轮比较结束----------
10、比较2和3,那么2比3小,所以它们的位置不变
[2,3,5,10,13,15]
11、比较3和5
[2,3,5,10,13,15]
12、比较5和10
[2,3,5,10,13,15]
----------------第三轮比较结束----------
13、比较2和3,那么2比3小,所以它们的位置不变
[2,3,5,10,13,15]
14、比较3和5
[2,3,5,10,13,15]
----------------第四轮比较结束----------
这个时候意味着后边的4个已经确认了他们的顺序
15、比较2和3,那么2比3小,所以它们的位置不变
[2,3,5,10,13,15][3,2,5,10,13,15][3,2,5,10,15,13][3,2,5,10,15,13][3,2,5,10,15,13][3,5,2,10,15,13][5,3,2,10,15,13]
"""
# 具体冒号排序的代码实现
def bubble_sort(blist):
list_len = len(blist)
print("传入参数列表的长度是{}".format(list_len))
# 如何能够获取到相邻的两个元素# 外层循环就是用来控制轮次的
for i in range(0,list_len-1):
for j in range(list_len-1):
print("此时我们要排序的元素是{}和{}".format(blist[j],blist[j+1]))
# 排序,交换位置
if blist[j] > blist[j+1]:
# 我们使用python特有的交换方法来进行交换
blist[j],blist[j+1] = blist[j+1],blist[j]
print("此时的列表的形状是:{}".format(blist))
print("========第{}轮比较结束========".format(i+1))
# bubble_sort(list1)
bubble_sort([3,5,67,89,90])
复制代码打印结果:
传入参数列表的长度是5
此时我们要排序的元素是3和5
此时的列表的形状是:[3, 5, 67, 89, 90]
此时我们要排序的元素是5和67
此时的列表的形状是:[3, 5, 67, 89, 90]
此时我们要排序的元素是67和89
此时的列表的形状是:[3, 5, 67, 89, 90]
此时我们要排序的元素是89和90
此时的列表的形状是:[3, 5, 67, 89, 90]
========第1轮比较结束========
此时我们要排序的元素是3和5
此时的列表的形状是:[3, 5, 67, 89, 90]
此时我们要排序的元素是5和67
此时的列表的形状是:[3, 5, 67, 89, 90]
此时我们要排序的元素是67和89
此时的列表的形状是:[3, 5, 67, 89, 90]
此时我们要排序的元素是89和90
此时的列表的形状是:[3, 5, 67, 89, 90]
========第2轮比较结束========
此时我们要排序的元素是3和5
此时的列表的形状是:[3, 5, 67, 89, 90]
此时我们要排序的元素是5和67
此时的列表的形状是:[3, 5, 67, 89, 90]
此时我们要排序的元素是67和89
此时的列表的形状是:[3, 5, 67, 89, 90]
此时我们要排序的元素是89和90
此时的列表的形状是:[3, 5, 67, 89, 90]
========第3轮比较结束========
此时我们要排序的元素是3和5
此时的列表的形状是:[3, 5, 67, 89, 90]
此时我们要排序的元素是5和67
此时的列表的形状是:[3, 5, 67, 89, 90]
此时我们要排序的元素是67和89
此时的列表的形状是:[3, 5, 67, 89, 90]
此时我们要排序的元素是89和90
此时的列表的形状是:[3, 5, 67, 89, 90]
========第4轮比较结束========
Process finished with exit code0复制代码十五. 快速排序法的思想与实现
# 请使用快速排序法实现将以下列表中的元素从小到大的排序
list1 = [5,3,2,10,15,13]
"""
核心思想是
1、从列表中取出任意一个元素,但是我们一般取第一个
2、把这个取出米的元素作为比较的标准
3、把比这个元素小的放在左边
4、把比这个元素大的放在右边
"""defquick_sort(quick_list):
print("现在的列表是:{}".format(quick_list))
if quick_list == []:
print("------寻找结束,此时列表为空-------")
return []
first = quick_list[0]
# 使用列表推导式加上递归实现print("开始寻找比第一个元素《《小》》的元素,第一个元素是{}".format(first))
less = quick_sort([l for l in quick_list[1:] if l <first])
print("开始寻找比第一个元素《《大》》的元素,第一个元素是{}".format(first))
more = quick_sort([m for m in quick_list[1:] if m >= first])
print("*****此时返回的列表是{}*****".format(less +[first] + more))
return less +[first] + more
# print(quick_sort(list1))print(quick_sort([4,2,56,35,78,46,89,1]))
复制代码打印结果:
现在的列表是:[4, 2, 56, 35, 78, 46, 89, 1]
开始寻找比第一个元素《《小》》的元素,第一个元素是4
现在的列表是:[2, 1]
开始寻找比第一个元素《《小》》的元素,第一个元素是2
现在的列表是:[1]
开始寻找比第一个元素《《小》》的元素,第一个元素是1
现在的列表是:[]
------寻找结束,此时列表为空-------
开始寻找比第一个元素《《大》》的元素,第一个元素是1
现在的列表是:[]
------寻找结束,此时列表为空-------
*****此时返回的列表是[1]*****
开始寻找比第一个元素《《大》》的元素,第一个元素是2
现在的列表是:[]
------寻找结束,此时列表为空-------
*****此时返回的列表是[1, 2]*****
开始寻找比第一个元素《《大》》的元素,第一个元素是4
现在的列表是:[56, 35, 78, 46, 89]
开始寻找比第一个元素《《小》》的元素,第一个元素是56
现在的列表是:[35, 46]
开始寻找比第一个元素《《小》》的元素,第一个元素是35
现在的列表是:[]
------寻找结束,此时列表为空-------
开始寻找比第一个元素《《大》》的元素,第一个元素是35
现在的列表是:[46]
开始寻找比第一个元素《《小》》的元素,第一个元素是46
现在的列表是:[]
------寻找结束,此时列表为空-------
开始寻找比第一个元素《《大》》的元素,第一个元素是46
现在的列表是:[]
------寻找结束,此时列表为空-------
*****此时返回的列表是[46]**********此时返回的列表是[35, 46]*****
开始寻找比第一个元素《《大》》的元素,第一个元素是56
现在的列表是:[78, 89]
开始寻找比第一个元素《《小》》的元素,第一个元素是78
现在的列表是:[]
------寻找结束,此时列表为空-------
开始寻找比第一个元素《《大》》的元素,第一个元素是78
现在的列表是:[89]
开始寻找比第一个元素《《小》》的元素,第一个元素是89
现在的列表是:[]
------寻找结束,此时列表为空-------
开始寻找比第一个元素《《大》》的元素,第一个元素是89
现在的列表是:[]
------寻找结束,此时列表为空-------
*****此时返回的列表是[89]**********此时返回的列表是[78, 89]**********此时返回的列表是[35, 46, 56, 78, 89]**********此时返回的列表是[1, 2, 4, 35, 46, 56, 78, 89]*****
[1, 2, 4, 35, 46, 56, 78, 89]
Process finished with exit code 0
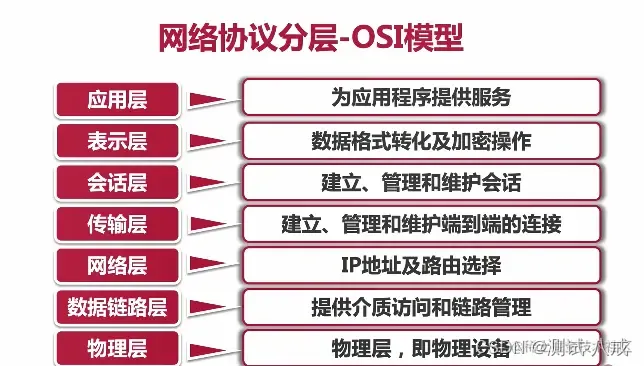
复制代码十六. 网络协议分层
网络协议分层-OSI模型
网络协议分层-OSI模式-举例说明

OSI七层协议与TCP/IP五层协议及对应网络协议

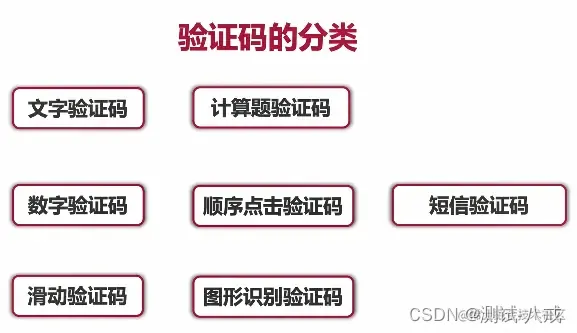
十七. web自动化测试中的验证码问题
你是如何解决登录时验证码的问题的?
验证码的分类
解决验证码的思路
关闭
万能验证码
绕过
验证码的处理方法
(1)取消验证码----->找开发把验证码代码注释掉,适用于测试环境
(2)万能验证码----->找开发把验证码值设置为恒定的,适用于生产环境
(3)识别验证码----->识别成功率不能保证,且只能识别比较简单的验证码
(4)cookie跳过验证码--->通过记录cookie,实现自动登录
(5)半自动化输入验证码---->遇到验证码时暂停一段时间,手动输入验证码复制代码十八. 如何管理自动化测试用例?
根据项目的大小
根据项目的阶段(项目之初,项目迭代,项目稳定)
十九. 什么时候开展自动化测试
项目运行相对比较稳定的时候
从项目流程看自动化测试执行的环境

二十.id,name,class,xpath, css selector这些属性,你最偏爱哪一种,为什么?
css 、xpath 几乎所有的元素都可以定位到,但是它们的短处在于页面上更改了元素后位置很容易改变,所以首先使用的还是id或者name等。
二十一.如何去定位页面上动态加载的元素?
触发动态加载元素的事件,直至动态元素出现,进行定位
二十二.如何去定位属性动态变化的元素?
xpath或者css通过同级、父级、子级进行定位
点击链接以后,Selenium是否会自动等待该页面加载完毕?
会的
如有不懂还要咨询下方小卡片,博主也希望和志同道合的测试人员一起学习进步
在适当的年龄,选择适当的岗位,尽量去发挥好自己的优势。
我的自动化测试开发之路,一路走来都离不每个阶段的计划,因为自己喜欢规划和总结,
测试开发视频教程、学习笔记领取传送门!!!

















 784
784











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









