






EDN:通过极致下采样网络的显著性物体检测
这篇文章提出了一个新的显著性物体检测叫做极致下采样网络(EDN),该方法通过增强高层特征学习来改进显著性物体检测的性能,特别是在显著物体的定位方面。
创新点
1.高层特征学习的增强:
(1)传统的SOD方法主要关注低层次特征的融合或增强,以更好地捕捉物体的边界和细节。然而,本文提出通过增强高层特征学习来改进显著物体的定位。这是SOD领域的一个新方向,填补了现有研究的空白。
(2)论文提出了极致下采样块(EDB),通过逐步下采样特征图,直到其变为一个大小为1x1的特征向量,从而学习整个图像的全局视图。这种方法能够有效地定位显著物体。
2.尺度相关金字塔卷积(SCPC)
(1)为了在多层次特征融合中更好地整合不同尺度的特征,论文提出了SCPC模块。与传统的多尺度特征提取方法(如ASPP和PSP)不同,SCPC在不同尺度的特征提取过程中引入了相关性,使得不同尺度的特征能够相互受益。
(2)SCPC通过空洞卷积和残差连接,有效地融合了多层次的特征,从而在解码器中恢复了物体的细节。
3.轻量级网络EDN-Lite
论文还提出了一个轻量级版本的EDN,称为EDN-Lite,它使用MobileNetV2作为骨干网络,并在保持较高性能的同时,显著减少了计算开销。EDN-Lite在316 FPS的速度下实现了具有竞争力的性能。
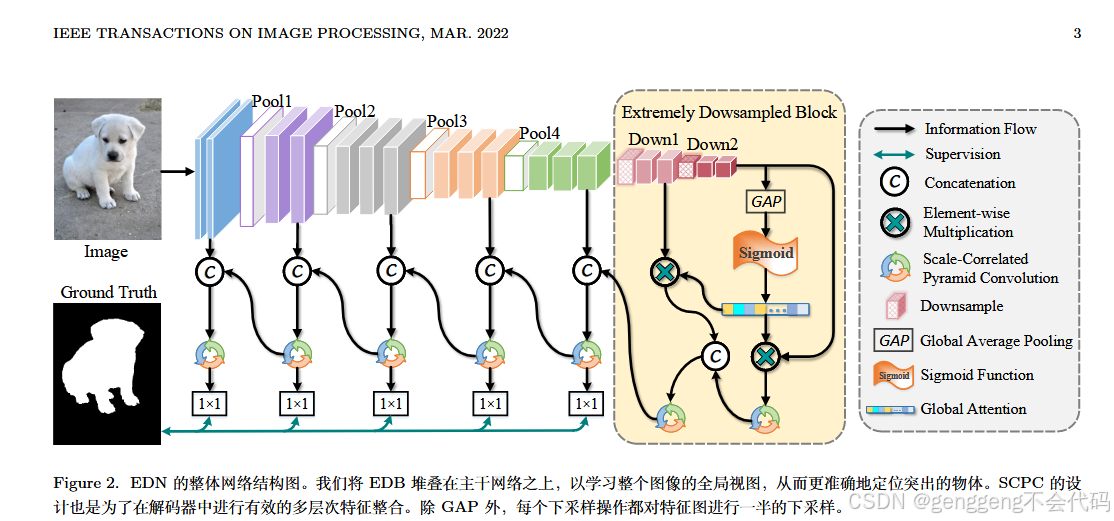
模型的主要模块
1.骨干网络
EDN 使用了两种常见的骨干网络作为编码器的基础:
(1)VGG16:经典的卷积神经网络,包含13个卷积层和4个池化层。
VGG16的骨干网络
-
VGG16 的5个阶段(stage)分别输出不同分辨率的特征图:
-
Stage 1: 1/1 分辨率(输入图像大小)
-
Stage 2: 1/2 分辨率
-
Stage 3: 1/4 分辨率
-
Stage 4: 1/8 分辨率
-
Stage 5: 1/16 分辨率
-
-
论文中去除了VGG16的最后两个全连接层,将其转换为全卷积网络(FCN),以便处理任意大小的输入图像。
(2)ResNet-50:残差网络,包含50个卷积层,具有较强的特征提取能力。
ResNet-50的骨干网络
-
ResNet-50 的5个阶段分别输出不同分辨率的特征图:
-
Stage 1: 1/2 分辨率
-
Stage 2: 1/4 分辨率
-
Stage 3: 1/8 分辨率
-
Stage 4: 1/16 分辨率
-
Stage 5: 1/32 分辨率
-
-
ResNet-50 的残差结构能够有效缓解梯度消失问题,适合提取深层特征。
2. 编码器
编码器由骨干网络的前几个阶段组成,用于提取多层次的特征。
(1)特征提取
-
骨干网络的每个阶段输出不同分辨率的特征图,分别表示为 E1,E2,E3,E4,E5。
-
这些特征图分别对应不同的感受野和语义层次,低层特征(如 E1,E2)包含更多的细节信息,而高层特征(如 E4,E5)包含更多的语义信息。
(2)极致下采样块(EDB)
-
在编码器的最后阶段(Stage 5),论文引入了极致下采样块(EDB),用于进一步下采样特征图并学习全局视图。
-
EDB 的输出 D6 是一个1x1的特征向量,包含了整个图像的全局信息。
3. 解码器
解码器用于从高层特征中逐步恢复物体的细节。解码器由多个SCPC模块组成,逐步从高层特征中恢复物体的细节。解码器的每个阶段通过上采样和1x1卷积操作,逐步融合多层次的特征,最终生成显著性图。
(1)多层次特征融合
-
解码器由多个阶段组成,每个阶段通过上采样和特征融合操作,逐步恢复物体的细节。
-
每个阶段包含两个**尺度相关金字塔卷积(SCPC)**模块,用于有效地融合多层次特征。
(2)上采样与特征融合
-
对来自高层特征的特征图进行上采样,使其分辨率与低层特征图一致。
-
将上采样后的特征图与低层特征图沿通道维度拼接,并通过SCPC模块进行融合。
(3)SCPC模块
-
SCPC 模块通过引入尺度相关性,有效地融合了不同尺度的特征。
4.极致下采样块(EDB)
(1)EDB通过逐步下采样特征图,直到其变成1x1的特征向量,从而学习整个图像的全局视图。EDB的设计包括俩个下采样块(down1和down2),以及全局平均池化(GAP)和sigmoid函数,用于生成全局注意力机制。
(2) EDB的输出通过全局注意力机制重新校准特征图,从而增强高层特征的表示能力。
5.尺度相关金字塔卷积(SCPC)
(1)SCPC模块用于在解码器中进行多层次特征融合。它将输入特征图分成四个部分,分别通过不同空洞率的3x3卷积进行处理,并通过残差连接将多尺度特征融合在一起。
(2)SCPC的设计使得不同尺度的特征能够相互关联,从而更好地捕捉物体的细节。
6.轻量级网络EDN-Lite
为了进一步提高模型的效率,论文提出了轻量级版本的EDN,称为EDN-Lite。
-
骨干网络替换:使用MobileNetV2替换VGG16或ResNet作为骨干网络,以减少计算开销。
-
深度可分离卷积:将SCPC中的3x3卷积替换为深度可分离卷积,进一步减少参数量和计算量。
-
输入尺寸调整:在测试时,将输入图像调整为224x224,以提高推理速度。
7.损失函数

精度分析
论文在五个具有挑战性的数据集上进行了广泛的实验,包括DUTS、ECSSD、HKU-IS、PASCAL-S和DUT-OMRON。EDN在这些数据集上均达到了SOTA性能,具体精度如下:
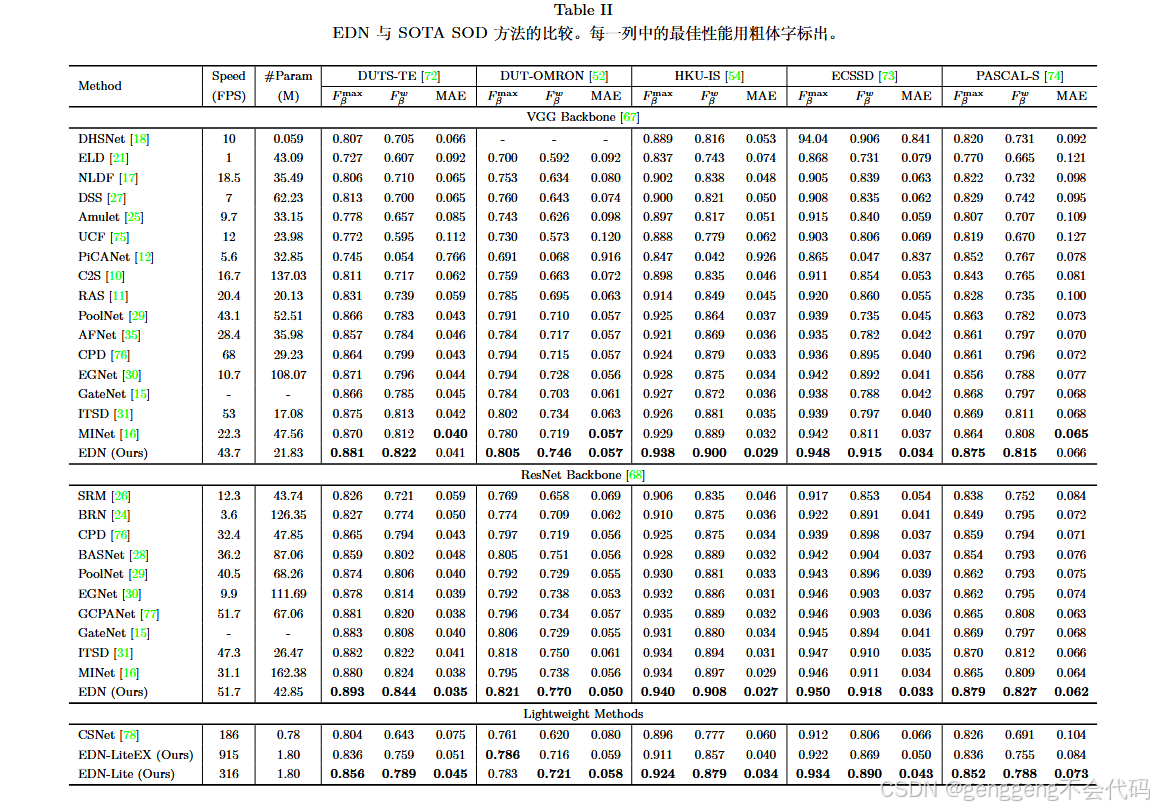
此外,EDN-Lite在保持较高性能的同时,实现了316 FPS的实时运行速度,显示出其在效率和精度之间的良好平衡。
总结
这篇论文通过引入极致下采样块(EDB)和尺度相关金字塔卷积(SCPC),显著提升了显著性物体检测的性能,特别是在显著物体的定位方面。EDN在多个数据集上达到了SOTA性能,并且其轻量级版本EDN-Lite在保持高精度的同时,实现了实时运行速度。这项工作为SOD领域提供了新的思路,并为未来的研究开辟了新的方向。
网络
1.VGG16的整体结构
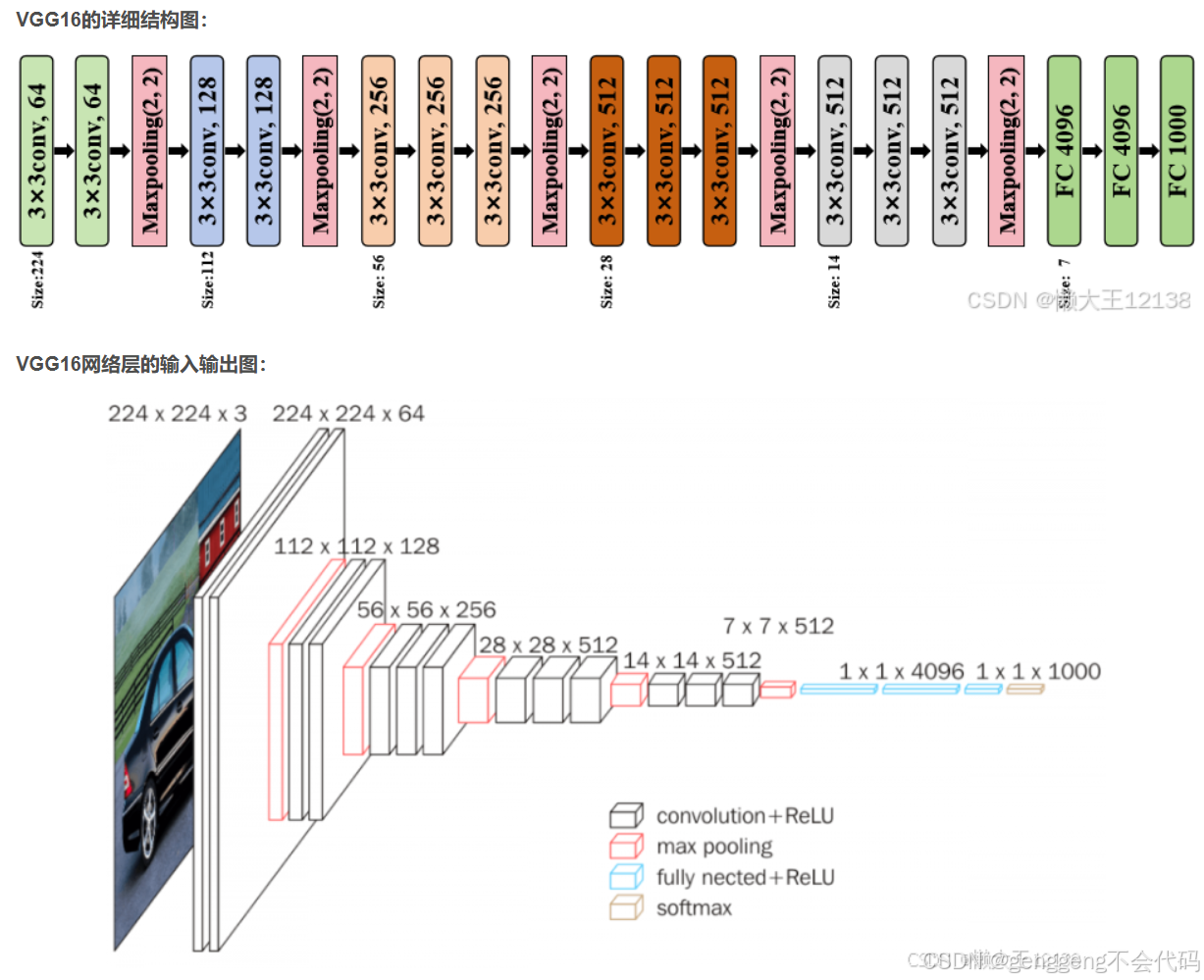
VGG16由16层组成(13个卷积层和3个全连接层)在这篇文章中,全连接层被移除,只保留了卷积层和池化层,以便将其转化为全卷积网络(FCN)从而可以处理任意大小的图像。
VGG16的主要特点:
所有卷积层都使用 3x3 的小卷积核,步幅为 1,填充为 1(保持特征图大小不变)。
所有池化层都使用 2x2 的最大池化,步幅为 2(将特征图大小减半)。
每个卷积层后接 ReLU 激活函数。
VGG16的详细层次结构
VGG16 的 13 个卷积层被分为 5 个阶段,每个阶段后接一个最大池化层。
Stage 1:
-
输入:224x224x3(假设输入图像大小为 224x224,3 个颜色通道)。
-
2 个卷积层:
-
Conv1_1: 64 个 3x3 卷积核,输出 224x224x64。
-
Conv1_2: 64 个 3x3 卷积核,输出 224x224x64。
-
-
最大池化层(MaxPool1):
-
2x2 池化,步幅为 2,输出 112x112x64。
-
Stage 2:
-
输入:112x112x64。
-
2 个卷积层:
-
Conv2_1: 128 个 3x3 卷积核,输出 112x112x128。
-
Conv2_2: 128 个 3x3 卷积核,输出 112x112x128。
-
-
最大池化层(MaxPool2):
-
2x2 池化,步幅为 2,输出 56x56x128。
-
Stage 3:
-
输入:56x56x128。
-
3 个卷积层:
-
Conv3_1: 256 个 3x3 卷积核,输出 56x56x256。
-
Conv3_2: 256 个 3x3 卷积核,输出 56x56x256。
-
Conv3_3: 256 个 3x3 卷积核,输出 56x56x256。
-
-
最大池化层(MaxPool3):
-
2x2 池化,步幅为 2,输出 28x28x256。
-
Stage 4:
-
输入:28x28x256。
-
3 个卷积层:
-
Conv4_1: 512 个 3x3 卷积核,输出 28x28x512。
-
Conv4_2: 512 个 3x3 卷积核,输出 28x28x512。
-
Conv4_3: 512 个 3x3 卷积核,输出 28x28x512。
-
-
最大池化层(MaxPool4):
-
2x2 池化,步幅为 2,输出 14x14x512。
-
Stage 5:
-
输入:14x14x512。
-
3 个卷积层:
-
Conv5_1: 512 个 3x3 卷积核,输出 14x14x512。
-
Conv5_2: 512 个 3x3 卷积核,输出 14x14x512。
-
Conv5_3: 512 个 3x3 卷积核,输出 14x14x512。
-
-
最大池化层(MaxPool5):
-
2x2 池化,步幅为 2,输出 7x7x512。
-
VGG16的输出特征图
在论文中,VGG16 的每个阶段输出不同分辨率的特征图,分别表示为 E1,E2,E3,E4,E5:
-
E1: Stage 1 的输出,分辨率为 1/1(输入图像大小)。
-
E2: Stage 2 的输出,分辨率为 1/2。
-
E3: Stage 3 的输出,分辨率为 1/4。
-
E4: Stage 4 的输出,分辨率为 1/8。
-
E5: Stage 5 的输出,分辨率为 1/16。
这些特征图分别对应不同的感受野和语义层次:
-
低层特征(E1,E2):包含更多的细节信息,适合捕捉物体的边缘和纹理。
-
高层特征(E4,E5):包含更多的语义信息,适合定位显著物体。
VGG16的改进
在论文中,VGG16 的以下部分被修改以适应显著性物体检测任务:
-
移除全连接层:原始的 VGG16 包含 3 个全连接层,但在论文中,这些全连接层被移除,以便将 VGG16 转换为全卷积网络(FCN),从而处理任意大小的输入图像。
-
添加 EDB 模块:在 Stage 5 的输出(E5E5)后,论文引入了极致下采样块(EDB),用于进一步下采样特征图并学习全局视图。
VGG16 的参数数量
VGG16 的参数量主要集中在卷积层:
-
每个 3x3 卷积层的参数量为:
参数量=输入通道数×输出通道数×3×3参数量=输入通道数×输出通道数×3×3 -
例如,Conv1_1 的参数量为:
3×64×3×3=1,7283×64×3×3=1,728 -
整个 VGG16 的参数量约为 1.38 亿,但在论文中,由于移除了全连接层,参数量大幅减少。
2.ResNet-50的整体结构
ResNet-50 由 50 层组成,包括:1个初始卷积层。4个残差阶段(Residual Stages),每个阶段包含多个残差块(Residual Blocks)。1个全局平均池化层。1个全连接层(在论文中被移除,以适应显著性物体检测任务)。
ResNet-50 的主要特点:
残差连接:在每个残差块中引入跳跃连接(Skip Connection),使得网络可以学习残差映射,缓解梯度消失问题。
瓶颈结构(Bottleneck):每个残差块使用 1x1、3x3、1x1 的卷积层组合,减少计算量。
分层特征提取:通过多个阶段提取不同分辨率的特征,适合多尺度任务。
ResNet-50 的详细层次结构
ResNet-50 的 50 层被分为 5 个阶段,每个阶段包含多个残差块。
Stage 0:初始卷积层
-
输入:224x224x3(假设输入图像大小为 224x224,3 个颜色通道)。
-
1 个卷积层:Conv1: 64 个 7x7 卷积核,步幅为 2,填充为 3,输出 112x112x64。
-
1 个最大池化层:MaxPool: 3x3 池化,步幅为 2,输出 56x56x64。
Stage 1:第一阶段残差块
-
输入:56x56x64。
-
3 个残差块,每个残差块的结构如下:
-
Bottleneck 结构:
-
1x1 卷积,64 个卷积核,将通道数压缩为 64。
-
3x3 卷积,64 个卷积核,提取空间特征。
-
1x1 卷积,256 个卷积核,将通道数扩展为 256。
-
-
残差连接:将输入直接加到输出上。
-
-
输出:56x56x256。
Stage 2:第二阶段残差块
-
输入:56x56x256。
-
4 个残差块,每个残差块的结构如下:
-
Bottleneck 结构:
-
1x1 卷积,128 个卷积核,将通道数压缩为 128。
-
3x3 卷积,128 个卷积核,步幅为 2,输出 28x28x128。
-
1x1 卷积,512 个卷积核,将通道数扩展为 512。
-
-
残差连接:通过 1x1 卷积调整输入通道数,然后加到输出上。
-
-
输出:28x28x512。
Stage 3:第三阶段残差块
-
输入:28x28x512。
-
6 个残差块,每个残差块的结构如下:
-
Bottleneck 结构:
-
1x1 卷积,256 个卷积核,将通道数压缩为 256。
-
3x3 卷积,256 个卷积核,步幅为 2,输出 14x14x256。
-
1x1 卷积,1024 个卷积核,将通道数扩展为 1024。
-
-
残差连接:通过 1x1 卷积调整输入通道数,然后加到输出上。
-
-
输出:14x14x1024。
Stage 4:第四阶段残差块
-
输入:14x14x1024。
-
3 个残差块,每个残差块的结构如下:
-
Bottleneck 结构:
-
1x1 卷积,512 个卷积核,将通道数压缩为 512。
-
3x3 卷积,512 个卷积核,步幅为 2,输出 7x7x512。
-
1x1 卷积,2048 个卷积核,将通道数扩展为 2048。
-
-
残差连接:通过 1x1 卷积调整输入通道数,然后加到输出上。
-
-
输出:7x7x2048。
Stage 5:全局平均池化层
-
输入:7x7x2048。
-
全局平均池化(Global Average Pooling):
-
将每个通道的特征图压缩为 1x1,输出 1x1x2048。
-
-
全连接层(在论文中被移除):
-
将 2048 维特征向量映射到类别数(如 1000 类)。
-
ResNet-50 的输出特征图
在论文中,ResNet-50 的每个阶段输出不同分辨率的特征图,分别表示为 E1,E2,E3,E4,E5:
-
E1: Stage 1 的输出,分辨率为 1/4(输入图像大小)。
-
E2: Stage 2 的输出,分辨率为 1/8。
-
E3: Stage 3 的输出,分辨率为 1/16。
-
E4: Stage 4 的输出,分辨率为 1/32。
-
E5: Stage 5 的输出,分辨率为 1/32(全局平均池化后)。
这些特征图分别对应不同的感受野和语义层次:
-
低层特征(E1,E2):包含更多的细节信息,适合捕捉物体的边缘和纹理。
-
高层特征(E4,E5):包含更多的语义信息,适合定位显著物体。
ResNet-50 的改进
在论文中,ResNet-50 的以下部分被修改以适应显著性物体检测任务:
-
移除全连接层:原始的 ResNet-50 包含一个全连接层,但在论文中,该层被移除,以便将 ResNet-50 转换为全卷积网络(FCN),从而处理任意大小的输入图像。
-
添加 EDB 模块:在 Stage 4 的输出(E4)后,论文引入了极致下采样块(EDB),用于进一步下采样特征图并学习全局视图。
ResNet-50 的参数数量
ResNet-50 的参数量主要集中在卷积层:
-
每个 1x1 卷积层的参数量为:
参数量=输入通道数×输出通道数×1×1参数量=输入通道数×输出通道数×1×1 -
每个 3x3 卷积层的参数量为:
参数量=输入通道数×输出通道数×3×3参数量=输入通道数×输出通道数×3×3 -
整个 ResNet-50 的参数量约为 2500 万,但在论文中,由于移除了全连接层,参数量有所减少。
3.MobileNetV2 的整体结构
MobileNetV2 是一种轻量级的卷积神经网络,专为移动设备和嵌入式设备设计,旨在保持较高性能的同时减少计算量和参数量。MobileNetV2 通过引入倒置残差结构(Inverted Residuals)和线性瓶颈(Linear Bottleneck),显著提高了模型的效率。MobileNetV2 由多个倒置残差块(Inverted Residual Block)组成:扩展层(Expansion Layer):使用 1x1 卷积扩展通道数。深度可分离卷积(Depthwise Separable Convolution):使用 3x3 卷积提取空间特征。投影层(Projection Layer):使用 1x1 卷积压缩通道数。残差连接(Residual Connection):在特定条件下添加跳跃连接。
MobileNetV2 的主要特点:
倒置残差结构:与传统残差网络不同,MobileNetV2 在残差块中先扩展通道数,再进行深度可分离卷积,最后压缩通道数。
线性瓶颈:在投影层后不使用非线性激活函数(如 ReLU),以避免信息丢失。
轻量级设计:通过深度可分离卷积和通道压缩,显著减少了参数量和计算量。
MobileNetV2 的详细层次结构
MobileNetV2 的层次结构可以分为 7 个阶段,每个阶段包含多个倒置残差块。
Stage 0:初始卷积层
-
输入:224x224x3(假设输入图像大小为 224x224,3 个颜色通道)。
-
1 个卷积层:
-
Conv1: 32 个 3x3 卷积核,步幅为 2,输出 112x112x32。
-
Stage 1:第一阶段倒置残差块
-
输入:112x112x32。
-
1 个倒置残差块,结构如下:
-
扩展层:1x1 卷积,将通道数扩展为 16。
-
深度可分离卷积:3x3 卷积,步幅为 1,输出 112x112x16。
-
投影层:1x1 卷积,将通道数压缩为 16。
-
-
输出:112x112x16。
Stage 2:第二阶段倒置残差块
-
输入:112x112x16。
-
2 个倒置残差块,每个块的结构如下:
-
扩展层:1x1 卷积,将通道数扩展为 96。
-
深度可分离卷积:3x3 卷积,步幅为 2,输出 56x56x24。
-
投影层:1x1 卷积,将通道数压缩为 24。
-
-
输出:56x56x24。
Stage 3:第三阶段倒置残差块
-
输入:56x56x24。
-
3 个倒置残差块,每个块的结构如下:
-
扩展层:1x1 卷积,将通道数扩展为 144。
-
深度可分离卷积:3x3 卷积,步幅为 2,输出 28x28x32。
-
投影层:1x1 卷积,将通道数压缩为 32。
-
-
输出:28x28x32。
Stage 4:第四阶段倒置残差块
-
输入:28x28x32。
-
4 个倒置残差块,每个块的结构如下:
-
扩展层:1x1 卷积,将通道数扩展为 192。
-
深度可分离卷积:3x3 卷积,步幅为 2,输出 14x14x64。
-
投影层:1x1 卷积,将通道数压缩为 64。
-
-
输出:14x14x64。
Stage 5:第五阶段倒置残差块
-
输入:14x14x64。
-
3 个倒置残差块,每个块的结构如下:
-
扩展层:1x1 卷积,将通道数扩展为 384。
-
深度可分离卷积:3x3 卷积,步幅为 1,输出 14x14x96。
-
投影层:1x1 卷积,将通道数压缩为 96。
-
-
输出:14x14x96。
Stage 6:第六阶段倒置残差块
-
输入:14x14x96。
-
3 个倒置残差块,每个块的结构如下:
-
扩展层:1x1 卷积,将通道数扩展为 576。
-
深度可分离卷积:3x3 卷积,步幅为 2,输出 7x7x160。
-
投影层:1x1 卷积,将通道数压缩为 160。
-
-
输出:7x7x160。
Stage 7:第七阶段倒置残差块
-
输入:7x7x160。
-
1 个倒置残差块,结构如下:
-
扩展层:1x1 卷积,将通道数扩展为 960。
-
深度可分离卷积:3x3 卷积,步幅为 1,输出 7x7x320。
-
投影层:1x1 卷积,将通道数压缩为 320。
-
-
输出:7x7x320。
Stage 8:全局平均池化层
-
输入:7x7x320。
-
全局平均池化(Global Average Pooling):
-
将每个通道的特征图压缩为 1x1,输出 1x1x320。
-
-
全连接层(在论文中被移除):
-
将 320 维特征向量映射到类别数(如 1000 类)。
-
MobileNetV2 的输出特征图
在论文中,MobileNetV2 的每个阶段输出不同分辨率的特征图,分别表示为 E1,E2,E3,E4,E5:
-
E1: Stage 2 的输出,分辨率为 1/4(输入图像大小)。
-
E2: Stage 3 的输出,分辨率为 1/8。
-
E3: Stage 4 的输出,分辨率为 1/16。
-
E4: Stage 6 的输出,分辨率为 1/32。
-
E5: Stage 7 的输出,分辨率为 1/32。
这些特征图分别对应不同的感受野和语义层次:
-
低层特征(E1,E2):包含更多的细节信息,适合捕捉物体的边缘和纹理。
-
高层特征(E4,E5):包含更多的语义信息,适合定位显著物体。
MobileNetV2 的改进
在论文中,MobileNetV2 的以下部分被修改以适应显著性物体检测任务:
-
移除全连接层:原始的 MobileNetV2 包含一个全连接层,但在论文中,该层被移除,以便将 MobileNetV2 转换为全卷积网络(FCN),从而处理任意大小的输入图像。
-
添加 EDB 模块:在 Stage 7 的输出(E5E5)后,论文引入了极致下采样块(EDB),用于进一步下采样特征图并学习全局视图。
MobileNetV2 的参数数量
MobileNetV2 的参数量主要集中在卷积层:
-
每个 1x1 卷积层的参数量为:
参数量=输入通道数×输出通道数×1×1参数量=输入通道数×输出通道数×1×1 -
每个 3x3 深度可分离卷积层的参数量为:
参数量=输入通道数×3×3参数量=输入通道数×3×3 -
整个 MobileNetV2 的参数量约为 350 万,显著少于 VGG16 和 ResNet-50。
Divide-and-Conquer:基于模态感知的三重解码器网络用于鲁棒的RGB-T显著目标检测
创新点
1.1 “Divide-and-Conquer” 策略
论文的核心创新点在于提出了 “Divide-and-Conquer” 策略,即将RGB-T SOD任务分解为两个子任务:模态特定信息挖掘 和 模态互补信息融合。这种策略通过三个并行的流(flow)来实现:
(1)两个模态特定流:分别处理RGB和热成像模态的特定信息。
(2)一个模态互补流:动态融合来自两个模态特定流的显著目标信息。
这种设计使得模型能够更好地处理复杂场景中的噪声和模态不一致问题,尤其是在某些模态数据不完整或存在缺陷的情况下。
1.2 模块化设计
论文提出了多个创新模块来支持“Divide-and-Conquer”策略:
(1)Modality-Induced Feature Modulator (MFM):用于在共享编码器中减少模态差异,增强模态间的互补信息。
(2)Residual Atrous Spatial Pyramid Module (RASPM):通过多尺度的空洞卷积扩大感受野,捕捉多尺度的上下文信息。
(3)Modality-aware Dynamic Aggregation Module (MDAM):动态聚合来自RGB和热成像模态的显著目标信息,减少模态偏差。
这些模块的设计使得模型能够更好地处理多模态数据,并在复杂场景中保持鲁棒性。
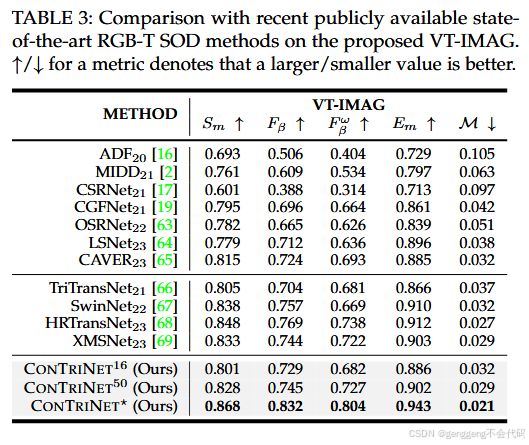
1.3 提出了一个新的数据集
论文还提出了一个新的RGB-T SOD数据集 VT-IMAG,涵盖了多种现实世界中的挑战性场景(如低光照、噪声、复杂背景等)。这个数据集为RGB-T SOD任务提供了一个更具挑战性的测试平台。
模型的主要模块
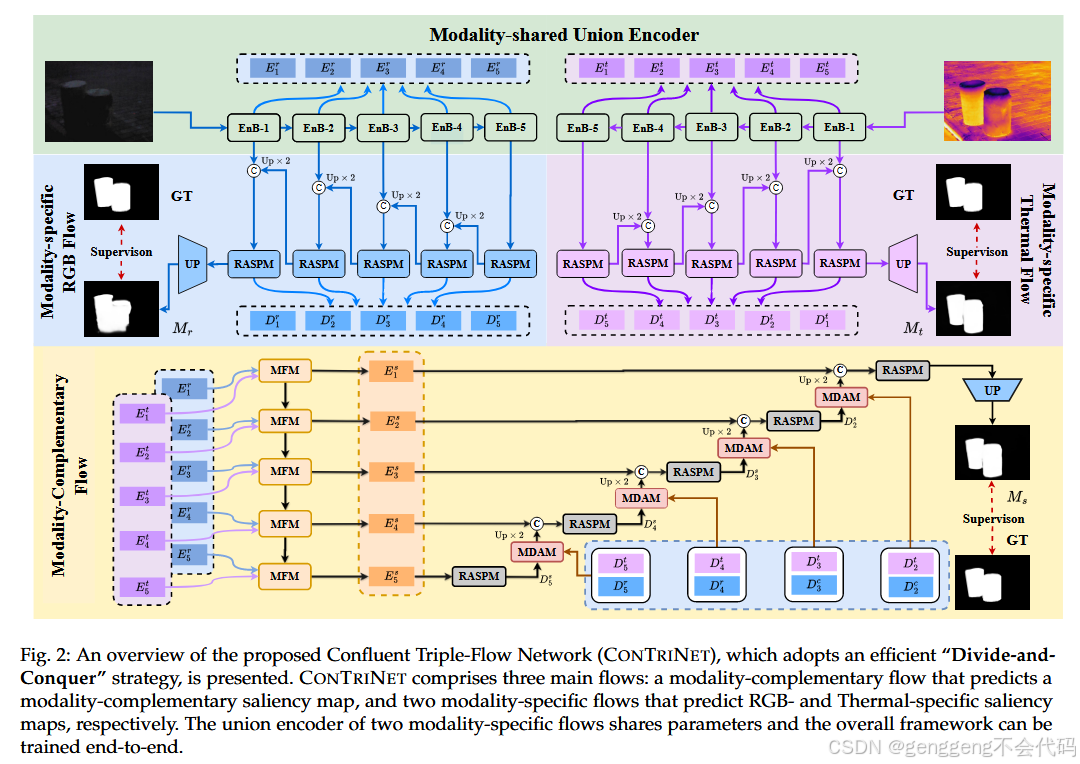
ConTrinNet 的核心创新在于其模块化设计,主要包括以下几个关键模块:
2.1 Modality-Induced Feature Modulator (MFM)
功能:MFM用于在共享编码器中减少RGB和Thermal模态之间的差异,增强模态间的互补信息。
结构:
(1)Cross-guided Feature Enhancement(交叉引导特征增强):通过交叉引导的特征增强模块,减少模态间的差异。
(2)Attention-aware Feature Fusion(注意力感知的特征融合):通过注意力机制融合不同模态的特征,确保模态间的兼容性。
2.2 Residual Atrous Spatial Pyramid Module (RASPM)
功能:RASPM 用于扩大感受野,捕捉多尺度的上下文信息,帮助模型更好地处理显著目标的细节和边界。
结构:RASPM 由四个并行的分支组成,每个分支负责捕捉不同尺度的上下文信息,并通过残差连接保留原始特征。
2.3 Modality-aware Dynamic Aggregation Module (MDAM)
功能:MDAM 用于动态聚合来自 RGB 和 Thermal 模态的显著目标信息,减少模态偏差。
结构:MDAM 通过动态权重分配机制,自适应地融合来自不同模态的显著目标信息,确保最终的显著目标检测结果更加准确。
2.4 Flow-Cooperative Fusion Strategy
功能:在三个流(RGB、Thermal、模态互补流)生成各自的显著图后,通过流协作融合策略将三个显著图融合为一个最终的显著图。
结构:通过简单的加法操作将三个显著图融合,生成最终的显著目标检测结果。
2.5 编码器
ConTrinNet 的编码器部分使用了不同的骨干网络(backbone),具体包括:
(1)ConTrinNet16:使用 VGG-16 作为编码器。
(2)ConTrinNet50:使用 Res2Net-50 作为编码器。
(3)ConTrinNet*:使用 Swin Transformer 作为编码器,进一步提升模型性能。
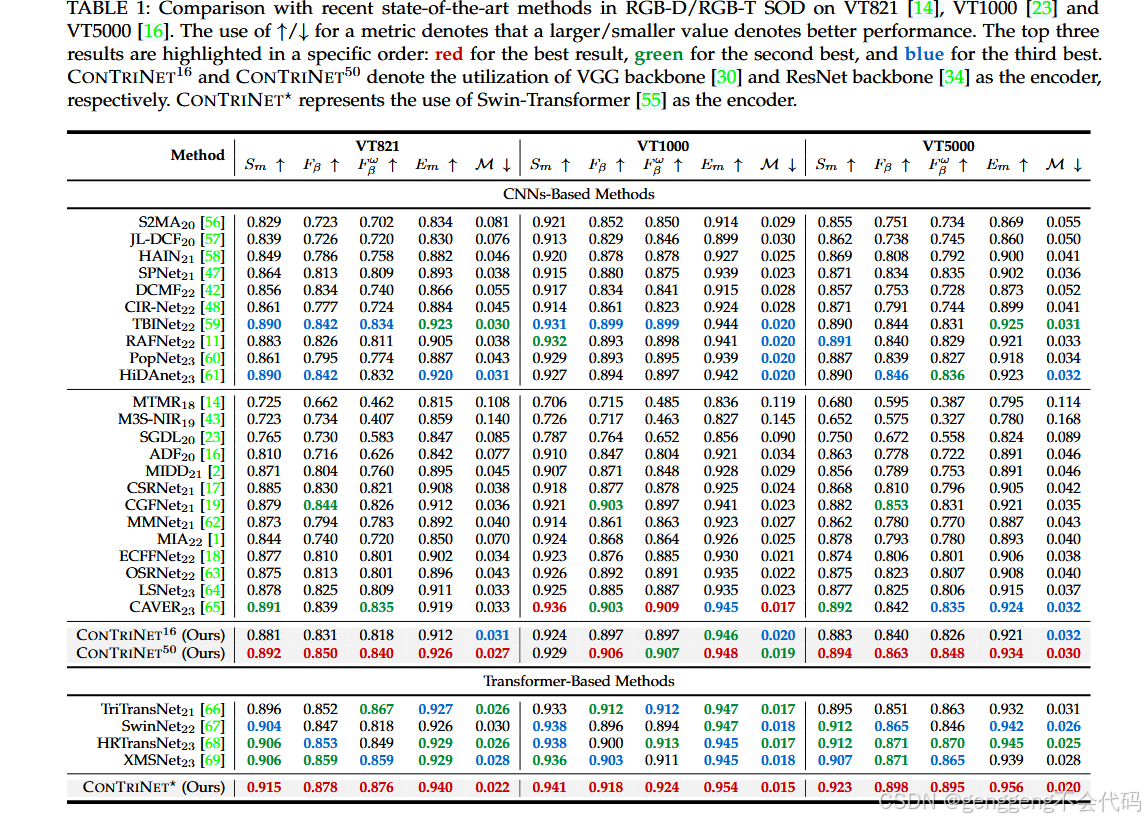
精度分析
论文在五个具有挑战性的数据集上进行了广泛的实验,包括VT821、VT1000、VT5000和VT-IMAG。ConTrinNet50在这些数据集上均达到了SOTA性能,具体精度如下:
总结
创新点:论文通过“Divide-and-Conquer”策略和多个创新模块(MFM、RASPM、MDAM)显著提升了RGB-T SOD任务的鲁棒性和精度。模型模块:MFM用于减少模态差异,RASPM用于捕捉多尺度上下文信息,MDAM用于动态融合多模态信息。精度表现:ConTrinNet在多个公开数据集和自建的VT-IMAG数据集上均取得了最佳表现,尤其是在复杂场景下表现出较强的鲁棒性。这篇论文的创新点和模型设计为RGB-T SOD任务提供了一个强有力的解决方案,尤其是在处理复杂场景和噪声数据时表现出色。
网络
1.VGG-16 :如上EDN
2.Res2Net-50
Res2Net-50 的整体架构与 ResNet-50 类似,都是由多个残差块堆叠而成。每个残差块包含多个卷积层,并且通过残差连接将输入特征图与输出特征图相加。Res2Net-50 的主要改进在于其残差块内部的多尺度特征提取机制。
Res2Net-50 的整体框架可以分为以下几个部分:
-
输入层:接受输入图像(通常为 224x224x3 的 RGB 图像)。
-
初始卷积层:一个 7x7 的卷积层,步幅为 2,用于提取低层次特征。
-
最大池化层:一个 3x3 的最大池化层,步幅为 2,用于进一步下采样。
-
四个阶段的残差块:Res2Net-50 包含四个阶段(Stage),每个阶段由多个残差块组成。每个阶段的残差块数量和特征图尺寸如下:
-
Stage 1: 3 个残差块,特征图尺寸为 56x56。
-
Stage 2: 4 个残差块,特征图尺寸为 28x28。
-
Stage 3: 6 个残差块,特征图尺寸为 14x14。
-
Stage 4: 3 个残差块,特征图尺寸为 7x7。
-
-
全局平均池化层:将最后一个残差块的输出特征图进行全局平均池化,得到一个固定长度的特征向量。
-
全连接层:用于分类任务,输出类别概率。
Res2Net-50 的残差块结构
Res2Net-50 的核心创新在于其残差块的设计。传统的 ResNet 残差块通常由两个 3x3 卷积层组成,而 Res2Net-50 的残差块则引入了 多尺度特征提取机制,通过将输入特征图分成多个子集,并在每个子集上应用不同尺度的卷积操作。
Res2Net-50 残差块的详细结构:
-
输入特征图分割:
-
输入特征图 XX 被分成 ss 个子集(通常 s=4s=4),记为 X1,X2,X3,X4X1,X2,X3,X4。
-
每个子集的通道数为 C/sC/s,其中 CC 是输入特征图的总通道数。
-
-
多尺度卷积:
-
每个子集经过不同的卷积操作:
-
X1 直接传递到下一层(不进行卷积操作)。
-
X2 经过一个 3x3 卷积操作。
-
X3 经过一个 3x3 卷积操作,并与 X2X2 的输出相加。
-
X4 经过一个 3x3 卷积操作,并与 X3X3 的输出相加。
-
-
通过这种方式,每个子集的特征图逐渐融合了更大尺度的上下文信息。
-
-
特征融合:
-
所有子集的输出特征图通过 拼接(concatenation) 或 逐元素相加(element-wise addition) 的方式融合在一起。
-
融合后的特征图经过一个 1x1 卷积层,用于调整通道数。
-
-
残差连接:融合后的特征图与输入特征图 XX 通过残差连接相加,形成最终的输出特征图。
Res2Net-50 的多尺度特征提取机制
Res2Net-50 的多尺度特征提取机制是其核心创新点。通过将输入特征图分成多个子集,并在每个子集上应用不同尺度的卷积操作,Res2Net-50 能够捕捉到更丰富的多尺度特征。具体来说:
-
浅层子集(如 X1X1 和 X2X2)捕捉局部细节和低层次特征。
-
深层子集(如 X3X3 和 X4X4)捕捉更大范围的上下文信息和高层次特征。
这种分层设计使得 Res2Net-50 在处理复杂场景和多尺度目标时表现出色。
3. Swin Transformer
论文中使用的Swin Transformer框架主要作为编码器(Encoder)集成在CONTRINET模型中,其核心设计遵循了原始Swin Transformer的分层窗口注意力机制,但针对RGB-T(可见光-热成像)双模态任务进行了适应性调整。
1. 分层窗口注意力机制
- 窗口划分:将输入图像划分为不重叠的局部窗口(如7×7大小),在每个窗口内计算自注意力(Self-Attention),显著减少计算复杂度。
- 移位窗口(Shifted Windows):在相邻的Transformer层中,窗口位置会进行周期性偏移(如右下方移动半个窗口),使得不同窗口之间能够交互信息,增强全局建模能力。
2. 多阶段特征提取
Swin Transformer编码器通常包含多个阶段(Stages),逐步下采样以生成多尺度特征:
- Patch Partition:将输入图像(RGB和热成像模态)分割为4×4的Patch,并通过线性嵌入层转换为特征向量。
- Stage 1-4:每个阶段包含多个Swin Transformer块,逐步合并Patch以扩大感受野:
- Stage 1:保持高分辨率,提取局部细节。
- Stage 2-4:通过Patch Merging操作逐步下采样(如2倍降采样),形成层次化特征(如1/4、1/8、1/16、1/32分辨率)。
3. 双模态输入适配
- 模态共享编码:RGB和热成像图像通过同一Swin Transformer编码器提取特征,利用其强大的跨模态特征融合能力。
- 特征调制:通过论文提出的MFM模块(Modality-induced Feature Modulator)对双模态特征进行增强与融合,包括:
- 跨模态引导增强(Cross-guided Feature Enhancement):利用另一模态的注意力权重增强当前模态特征。
- 注意力感知融合(Attention-aware Feature Fusion):通过空间和通道注意力动态融合双模态特征。
4. 与CONTRINET的集成
Swin Transformer作为编码器输出多尺度特征(记为 Eir 和 Eit),供后续三个解码器分支使用:
- 模态特定流(Modality-specific Flows):分别处理RGB和热成像特征,通过RASPM模块捕获多尺度上下文。
- 模态互补流(Modality-complementary Flow):动态融合双模态特征,利用MDAM模块抑制噪声并强化互补信息。

用于RGB-D显著对象检测的点感知互动和CNN诱导的改进网络








创新点
1.1 CNN-assisted Transformer 架构
(1)创新点:论文提出了一种 CNN-assisted Transformer 架构,结合了 Transformer 的全局建模能力和 CNN 的局部细节处理能力。与传统的纯 Transformer 或纯 CNN 架构不同,PICR-Net 使用 Transformer 完成大部分编码和解码过程,并在网络末端引入了一个 CNN-induced Refinement (CNNR) 单元,用于细节补充和内容精炼。(卷积神经网络在特征提取和跨模态交互方面的重要作用已得到充分挖掘,但在对自模态和跨模态的全局长距离依赖关系进行建模方面仍显不足。)
(2)优势:这种设计既保留了 Transformer 的全局上下文建模能力,又通过 CNN 补充了局部细节,避免了 Transformer 的块效应和细节破坏问题。
1.2 Cross-modality Point-aware Interaction (CmPI) 模块
(1)创新点:论文提出了一种 跨模态点感知交互模块 (CmPI),用于 RGB 和深度模态之间的特征交互。与传统的跨模态注意力机制不同,CmPI 模块通过位置约束和全局显著性引导向量,仅在相同位置的特征之间进行交互,减少了计算冗余。(考虑到RGB模态和深度模态之间的先验相关性)
(2)优势:CmPI 模块能够更高效地进行跨模态特征融合,避免了传统跨模态注意力机制中的盲目计算和不必要的噪声引入。
1.3 CNN-induced Refinement (CNNR) 单元
(1)创新点:在网络末端引入了一个 CNN-induced Refinement (CNNR) 单元,用于对 Transformer 输出的显著图进行细节补充和精炼。CNNR 单元利用预训练的 VGG16 模型的浅层特征,通过通道注意力机制进行特征融合。(为了缓解Transformer天然带来的块效应和细节破坏问题)
(2)优势:CNNR 单元能够有效解决 Transformer 的块效应和细节破坏问题,生成边界清晰、细节丰富的显著图。
模型的主要模块
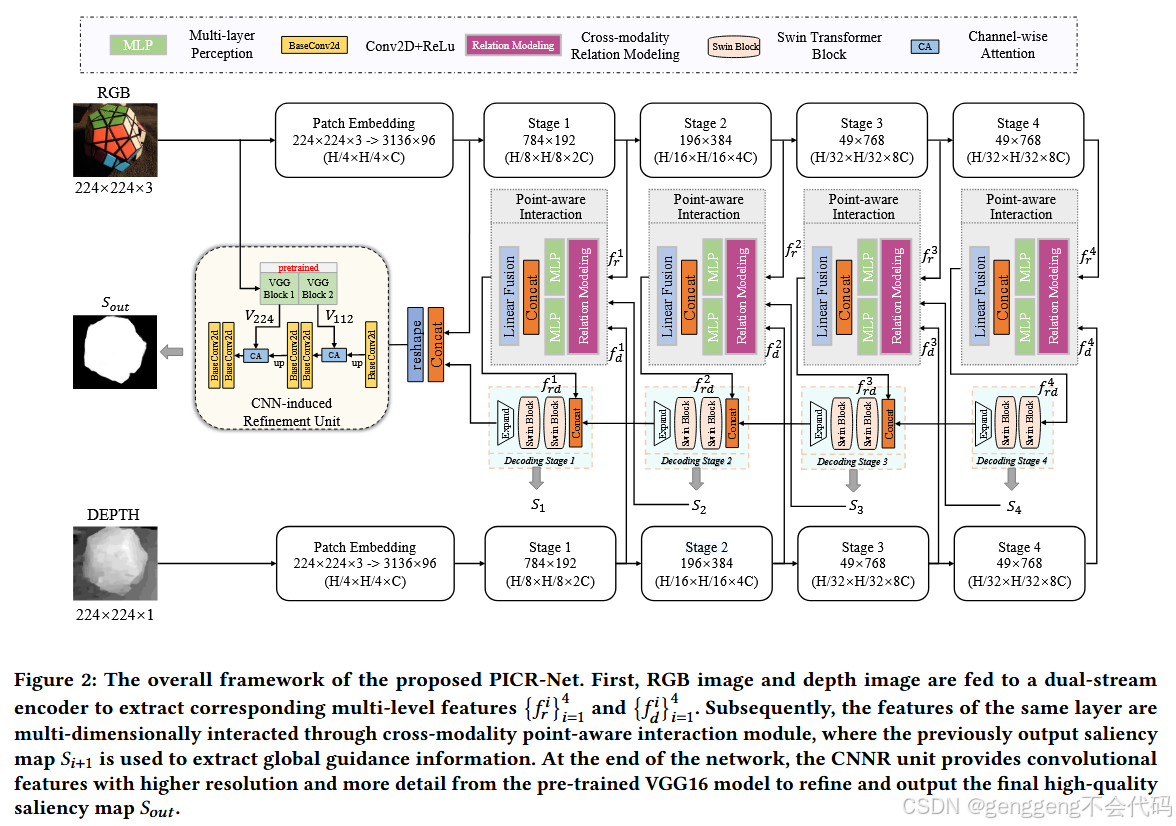
2.1 双流编码器
-
功能:RGB 图像和深度图像分别通过两个共享权重的 Swin-Transformer 编码器进行特征提取,生成多层次的 RGB 和深度特征。
-
特点:Swin-Transformer 能够捕捉长距离依赖关系,适合处理全局上下文信息。
2.2 Cross-modality Point-aware Interaction (CmPI) 模块
-
功能:CmPI 模块用于在解码阶段对 RGB 和深度模态的特征进行交互。它通过位置约束和全局显著性引导向量,仅在相同位置的特征之间进行交互,减少了计算冗余。
-
结构:
-
全局显著性引导向量:通过上采样的显著图生成全局显著性引导向量,用于指导特征交互。
-
两步注意力机制:第一步注意力用于抑制不同模态之间的负向交互,第二步注意力用于增强同一模态内的全局-局部交互。
-
2.3 Swin-Transformer 解码器
-
功能:解码器使用 Swin-Transformer 块对跨模态特征进行全局建模,逐步上采样并生成显著图。
-
特点:解码器通过多层次的 Swin-Transformer 块捕捉长距离依赖关系,确保显著目标的完整性。
2.4 CNN-induced Refinement (CNNR) 单元
-
功能:CNNR 单元用于对解码器输出的显著图进行细节补充和精炼。它利用预训练的 VGG16 模型的浅层特征,通过通道注意力机制进行特征融合。
-
结构:
-
特征上采样:将解码器输出的特征上采样到与 VGG16 特征相同的分辨率。
-
通道注意力机制:通过通道注意力机制融合 VGG16 特征和解码器特征,生成最终的显著图。
-
精度分析
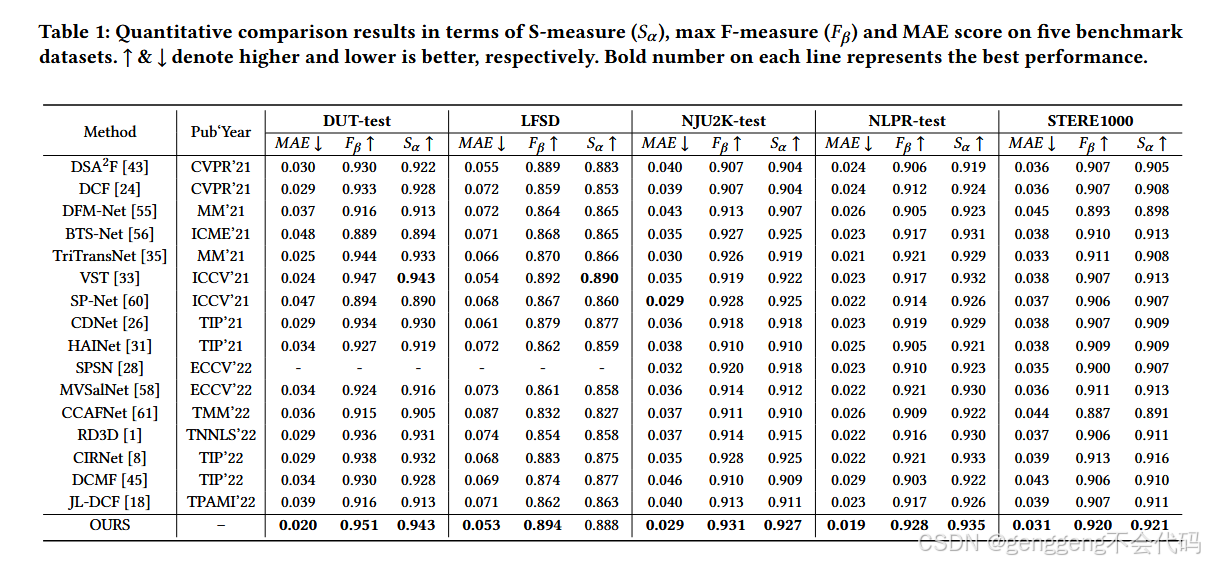
论文在五个具有挑战性的数据集上进行了广泛的实验,包括DUT-test、LFSD、NJU2K-test、NLPR-test、STERE1000。结果表明 PICR-Net 在显著目标检测任务中表现优异,尤其是在复杂场景下表现出较强的鲁棒性。
评价指标:MAE(平均绝对误差)、F-measure(Fβ)、S-measure(结构相似性)。
总结
(1)创新点:PICR-Net 通过结合 Transformer 和 CNN 的优势,提出了一种新的 CNN-assisted Transformer 架构,显著提升了 RGB-D SOD 任务的性能。
(2)主要模块:双流编码器、CmPI 模块、Swin-Transformer 解码器、CNNR 单元。
(3)精度表现:在五个广泛使用的 RGB-D SOD 数据集上,PICR-Net 在 MAE、F-measure 和 S-measure 等指标上均取得了最佳表现,尤其是在复杂场景下表现出较强的鲁棒性。
网络
1. Swin Transformer
一、Swin Transformer 的核心设计原理
Swin Transformer 的核心创新在于 层级式窗口注意力机制(Hierarchical Window-based Self-Attention),通过以下设计平衡全局建模与计算效率:
-
窗口划分(Window Partition)
- 将输入图像划分为多个不重叠的局部窗口(如7×7像素),仅在窗口内计算自注意力,大幅降低计算复杂度(从 O(N2) 降至 O(N),N 为像素数)。
- 移位窗口(Shifted Window):通过窗口的周期性移位(如右移3像素),实现跨窗口的信息交互,避免局部窗口导致的视野受限问题。
-
层级特征金字塔(Hierarchical Structure):类似CNN的层级设计,通过 Patch Merging 逐步合并相邻像素,生成多尺度特征图(如原图→1/4→1/8→1/16→1/32分辨率),适应不同尺度的目标检测需求。
-
相对位置编码(Relative Position Bias):在自注意力计算中引入可学习的相对位置偏置,增强模型对局部空间关系的感知能力。
二、在论文中的具体应用
在 RGB-D显著性检测任务 中,Swin Transformer 被用作双分支编码器。
1. 双模态编码器(Dual-Branch Encoder)
- 输入处理:
- RGB图像和深度图分别输入两个 共享权重 的Swin Transformer分支。
- 深度图通过归一化并复制为三通道,以适配Swin的输入格式。
- 多层级特征提取:
- 每个分支输出4层特征(对应分辨率1/4, 1/8, 1/16, 1/32),形成多尺度特征金字塔。
- 示例:输入尺寸224×224 → 第1层特征56×56(1/4分辨率),第4层特征7×7(1/32分辨率)。
2. 跨模态交互模块(CmPI)
- 位置约束的交互:
- 在编码器的每一层,通过 Cross-modality Point-aware Interaction (CmPI) 模块,将同一空间位置的RGB和深度特征进行交互。
- 利用 全局显著性引导向量(由上一解码层上采样的显著性图生成)指导交互过程,增强全局上下文感知。
- 两阶段注意力机制:
- 第一步:在局部窗口内,通过掩码注意力抑制跨模态噪声(如深度引导向量对RGB特征的干扰)。
- 第二步:在自模态内进行全局-局部交互,强化全局引导向量对局部特征的约束。
3. 解码器设计
- 基于Swin的全局解码:
- 解码器由多级Swin Transformer块构成,逐步融合跨模态特征并恢复分辨率。
- 低层特征通过跳跃连接(Skip Connection)与高层特征拼接,补充细节信息。
- CNN诱导的细化单元(CNNR):
- 在解码器末端引入浅层CNN(如3×3卷积+通道注意力),修复Transformer的块效应(Block Artifacts)和细节损失。
CIR-Net:用于 RGB-D 显著目标检测的跨模态交互和优化
创新点
1 跨模态交互与优化:
(1)论文提出了一种新的跨模态交互与优化网络(CIR-Net),用于RGB-D显著目标检测(SOD)。该网络通过充分捕捉和利用RGB和深度模态之间的跨模态信息,显著提升了显著目标检测的性能。
(2)与现有的仅在编码器或解码器阶段进行跨模态交互的方法不同,CIR-Net在编码器和解码器阶段都进行了跨模态信息的交互,从而更全面地探索了不同模态之间的互补关系。
2 渐进注意力引导的集成单元(PAI)
在编码器阶段,设计了渐进注意力引导的集成单元(PAI),用于融合跨模态和跨层次的特征,生成RGB-D编码器表示。PAI单元通过空间注意力图逐步引导特征集成,增强了特征的互补性和多样性。
3 自模态注意力优化单元(smAR)和跨模态加权优化单元(cmWR)
在编码器和解码器之间插入了一个优化中间件结构,包括自模态注意力优化单元(smAR)和跨模态加权优化单元(cmWR)。smAR单元通过3D注意力张量减少单模态特征中的冗余信息,强调空间和通道维度的重要特征。cmWR单元则通过捕捉跨模态的全局上下文依赖关系,进一步优化多模态特征。
4 重要性门控融合单元(IGF)
在解码器阶段,设计了重要性门控融合单元(IGF),用于动态选择RGB和深度模态中最有价值的信息,并将其融合到RGB-D主流分支中。IGF单元通过可学习的重要性权重,有效地控制了不同模态信息的贡献,增强了模型的鲁棒性。
5 三流网络架构
CIR-Net采用了一种介于两流和三流之间的网络架构,RGB-D流通过RGB和深度分支的高层特征融合生成,而不是从头学习。这种设计不仅减少了计算量,还使得RGB-D特征更具判别性。
模型的主要模块
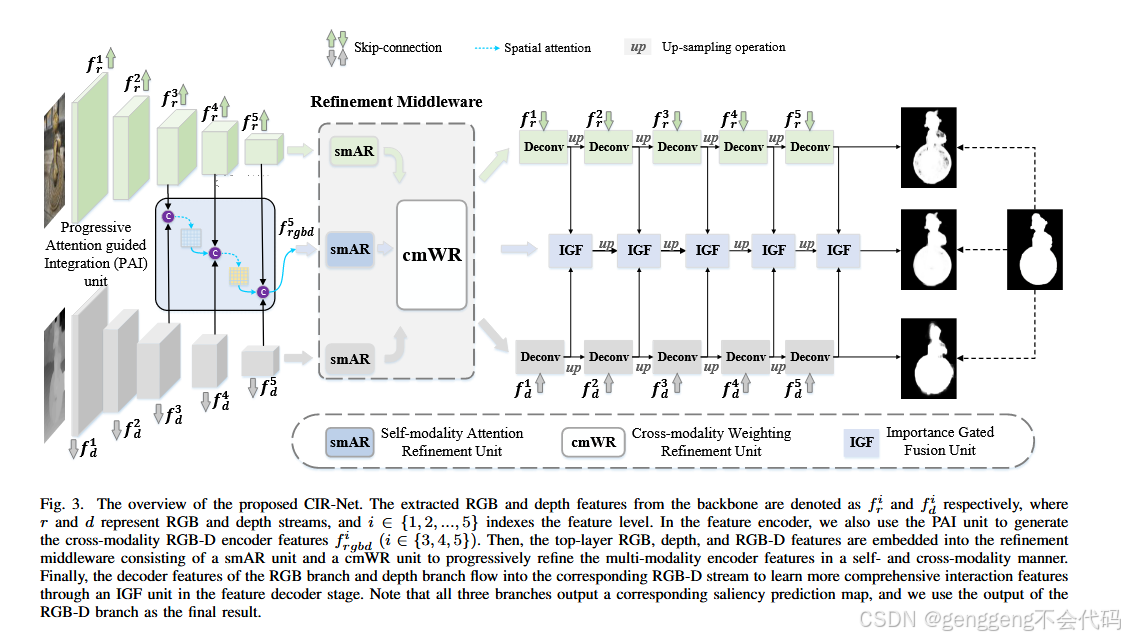
1 编码器
(1)使用ResNet50或VGG16作为骨干网络,提取RGB和深度图像的多层次特征。
(2)通过渐进注意力引导的集成单元(PAI)融合RGB和深度特征,生成RGB-D编码器特征。
2 优化中间件
(1)自模态注意力优化单元(smAR):通过3D注意力张量减少单模态特征中的冗余信息,强调空间和通道维度的重要特征。
(2)跨模态加权优化单元(cmWR):通过捕捉跨模态的全局上下文依赖关系,进一步优化多模态特征。
3 解码器
(1)使用重要性门控融合单元(IGF)动态选择RGB和深度模态中最有价值的信息,并将其融合到RGB-D主流分支中。
(2)通过逐步优化的解码器特征,生成最终的显著目标检测结果。
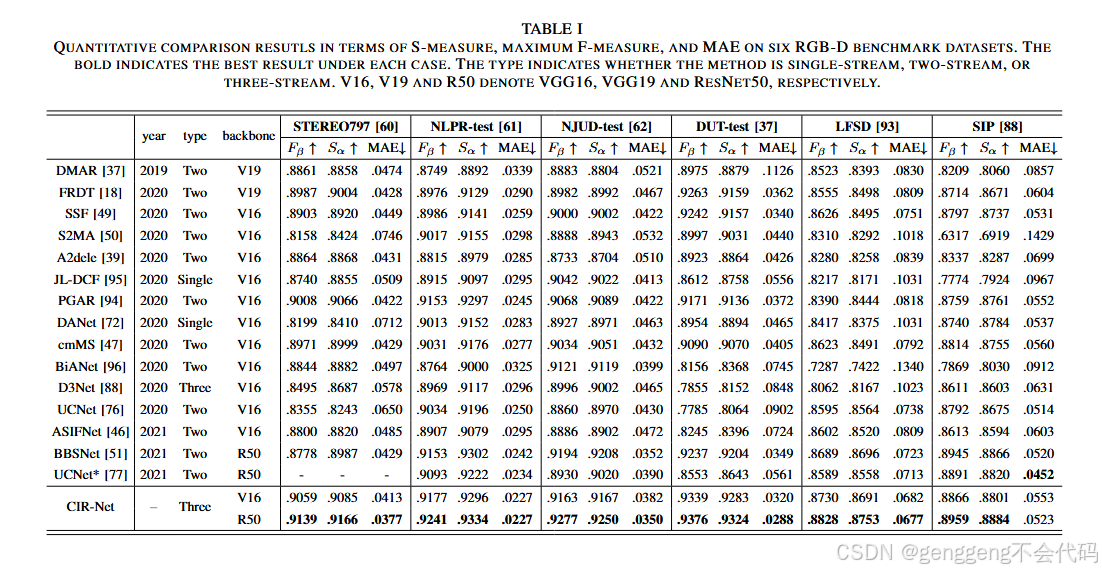
精度分析
在六个流行的RGB-D SOD基准数据集(STEREO797、NLPR、NJUD、DUT、LFSD和SIP)上进行了广泛的实验,结果表明CIR-Net在定性和定量评估中均优于现有的最先进方法。
总结
CIR-Net通过跨模态交互与优化的设计,显著提升了RGB-D显著目标检测的性能。其创新点在于在编码器和解码器阶段都进行了跨模态信息的交互,并通过优化中间件结构进一步增强了特征的判别性。实验结果表明,CIR-Net在多个基准数据集上均取得了优异的性能,具有较强的鲁棒性和泛化能力。
网络
1.VGG16的整体结构 如上
2.ResNet50的整体结构 如上
用于协同显著目标检测的小组协作学习 2021 GCoNet
摘要
我们提出了一种新颖的群体协作学习框架(GCoNet),该框架能够实时(16 毫秒)检测共同显著目标。它基于两个必要标准,同时在群体层面挖掘一致性表示:其一,组内紧凑性,通过我们新颖的群体亲和模块捕捉共同显著目标的内在共享属性,从而更好地描述这些目标之间的一致性;其二,组间可分性,通过引入我们新的群体协作模块来调节不一致的一致性,有效抑制噪声目标对输出结果的影响。为了在不增加额外计算开销的情况下学习到更好的嵌入空间,我们明确采用了辅助分类监督。在三个具有挑战性的基准数据集,即 CoCA、CoSOD3k 和 Cosal2015 上进行的大量实验表明,我们简单的 GCoNet 优于 10 种前沿模型,并达到了新的领先水平。我们在许多重要的下游计算机视觉应用中展示了本文的新技术贡献,包括内容感知共同分割、基于共同定位的自动缩略图等。
创新点
1 组间协作学习:传统方法仅关注同一图像组内的协同信息,而GCoNet首次引入组间协作学习,通过组间可分离性(inter-group separability)抑制不同组之间的干扰,提升模型对复杂场景的鲁棒性。(传统CoSOD方法在组间语义混淆、数据局限性和噪声敏感性的不足,通过引入跨组对比与高层语义监督,实现更鲁棒、更精准的协同显著目标检测。)
2 双标准优化:同时优化组内紧凑性(intra-group compactness)和组间可分离性,前者通过组亲和力模块(GAM)捕获组内共性,后者通过组协作模块(GCM)区分不同组,形成更清晰的共识表示。(解决传统CoSOD方法在组内噪声抑制、组间语义混淆、数据局限性和低层特征依赖等方面的不足。通过同时优化组内紧凑性与组间可分离性,模型能够:更精准地定位共同显著目标;有效区分相似但不同组的对象;提升对复杂场景和噪声的鲁棒性;增强高层语义表达能力,推动实际应用(如跨组图像检索、自动缩略图生成)的落地。)
3 辅助分类模块(ACM):在不增加计算开销的前提下,通过分类任务的监督信号增强特征嵌入的语义表达能力,进一步提升全局特征质量。(1.提升特征表示的判别性 :ACM通过引入分类监督(如交叉熵损失),强制模型在特征空间中学习更具语义区分度的表示。2.缓解单组数据的信息局限性:oSOD任务中,单个图像组通常仅包含少量样本(20-40张),且缺乏负样本(不同组的干扰对象)。ACM通过利用分类任务的高层语义监督(如ImageNet预训练或数据集的类别标签),能够引入全局语义信息:弥补单组数据在高层语义上的不足,帮助模型区分共显著对象与背景噪声。增强泛化能力:通过多任务学习(分类+共显著性检测),避免模型过拟合到有限的组内正样本。)
4 高效实时性:模型在保持高性能的同时实现实时检测(16ms/帧),适用于实际应用场景。
模型的主要模块
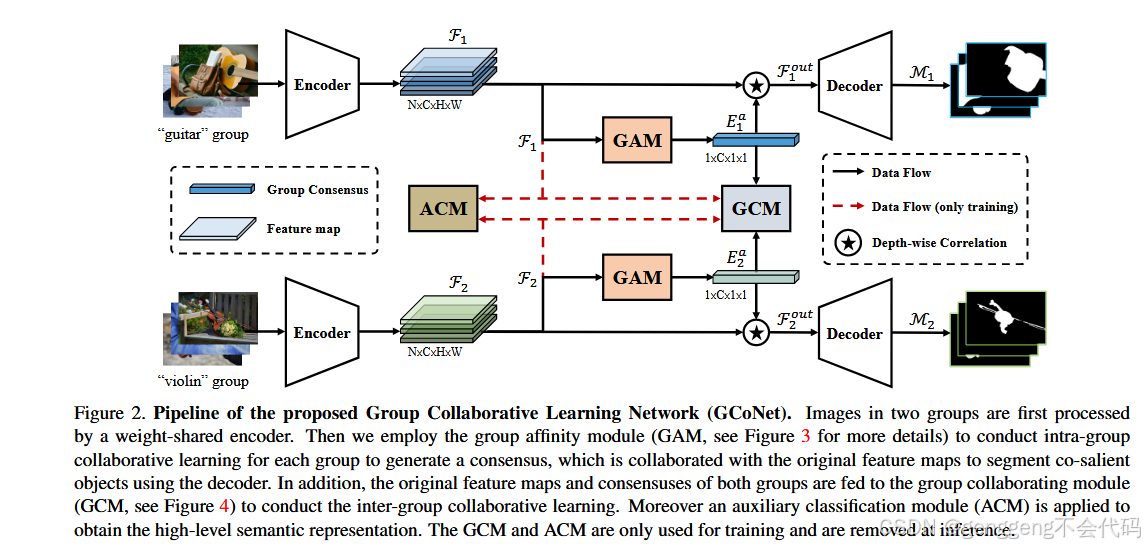
1 组亲和力模块(GAM)
功能:提取组内图像的共性特征(共识表示),增强组内紧凑性。
实现:通过计算图像特征间的全局亲和力(Global Affinity),生成注意力图,抑制噪声并聚焦协同显著区域。最终通过平均池化生成组级共识特征。
公式:基于像素级内积计算特征相似性(式1),结合Softmax归一化和特征加权。
2 组协作模块(GCM)
功能:增强不同组间的特征区分度,提升组间可分离性。
实现:对两组图像的共识特征进行交叉乘法(同一组特征与共识相乘,不同组特征与对方共识相乘),分别生成正样本(监督为真实标签)和负样本(监督为全零图),通过对比学习优化特征空间。
监督策略:正样本使用Focal Loss监督,负样本强制输出为零(式3)
3 辅助分类模块(ACM)
功能:通过分类任务增强高层语义特征表达。
实现:在主干网络后添加全局平均池化和全连接层,利用交叉熵损失(式4)优化分类结果,间接提升特征嵌入的判别性。
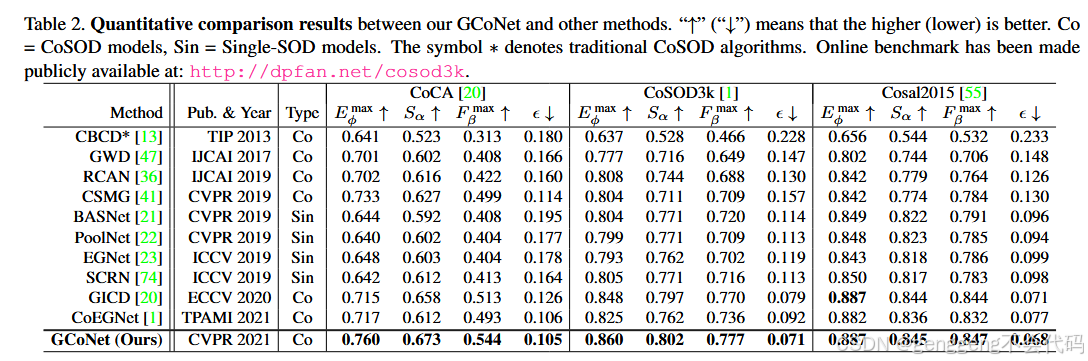
精度分析
在三个流行的RGB-D SOD基准数据集(CoCA,CoSOD,Cosal2015)上进行了广泛的实验,结果表明GCoNet在定性和定量评估中均优于现有的最先进方法。
总结
GCoNet通过组内紧凑性和组间可分离性的双重优化,结合分类任务的辅助监督,显著提升了协同显著目标检测的性能。其在复杂场景下的鲁棒性和实时性,使其在图像分割、自动缩略图生成等下游任务中具有广泛应用潜力。
网络
1 VGG-16 + 特征金字塔网络(FPN),用于多尺度特征提取。VGG16的整体结构 如上
1. VGG-16 基础网络
输入尺寸: 224×224(RGB图像)。
核心结构:包含13层卷积(Conv3-64、Conv3-64、MaxPool → Conv3-128、Conv3-128、MaxPool → Conv3-256×3、MaxPool → Conv3-512×3、MaxPool → Conv3-512×3、MaxPool),后接3层全连接(FC-4096、FC-4096、FC-1000)。
调整:移除原始VGG-16的全连接层,仅保留卷积部分作为特征提取器,输出多级特征图(如Conv4、Conv5等)。
2. 特征金字塔网络(FPN)
功能:融合多尺度特征,增强模型对不同尺寸目标的检测能力。
实现方式:
(1)自底向上路径:利用VGG-16的Conv3(浅层)、Conv4(中层)、Conv5(深层)作为多级特征输入。
(2)自顶向下路径:对深层特征(如Conv5)进行上采样,并与浅层特征(如Conv4)通过横向连接(1×1卷积调整通道数)逐级融合。
(3)输出特征图:生成多尺度特征金字塔(如P3、P4、P5),分别对应不同分辨率的特征图。
2. 设计选择与优势
VGG-16的优势:
(1)结构简单:仅使用3×3卷积和2×2池化,参数规模适中,适合作为基础特征提取器。
(2)成熟稳定:在ImageNet预训练权重上表现可靠,特征泛化能力强。
(3)兼容性:与FPN结合时,其层级特征(Conv3/4/5)天然适合构建多尺度金字塔。
FPN的作用:
(1)多尺度融合:浅层特征(高分辨率、低语义)与深层特征(低分辨率、高语义)结合,提升对小目标和复杂背景的检测能力。
(2)增强特征表达:为后续的组内紧凑性(GAM)和组间可分离性(GCM)模块提供丰富的多尺度特征输入。
3. 训练细节
(1)数据集:使用DUTS(单显著目标数据集)进行预训练,通过组标签(来自GICD[20])构建训练批次。
(2)批次设置:每组包含16张图像,每次训练随机选取两个不同组。
(3)优化器:Adam(初始学习率 10−410−4,β1=0.9β1=0.9,β2=0.99β2=0.99),共训练50个周期。
(4)输入处理:图像统一缩放至224×224,输出显著性图还原至原始尺寸评估。
4. 推理效率
(1)轻量化设计:
GCM与ACM模块:仅在训练阶段使用,推理时移除,减少计算开销。实时性:在Nvidia GTX 1080Ti上,单组(16张图像)推理速度为16ms,满足实时需求。
(2)性能平衡:VGG-16的轻量级结构结合FPN的优化,在保证特征质量的同时避免复杂计算。
5. 主干网络对整体模型的贡献
(1)特征提取:VGG-16提供基础语义特征,FPN增强多尺度表达能力。
(2)模块兼容性:输出的多级特征图(P3-P5)可直接输入至GAM和GCM模块,支持组内共识学习和组间对比优化。
(3)鲁棒性:多尺度特征融合有效应对复杂场景(如小目标、遮挡、多干扰对象)。
6 总结
主干网络通过 VGG-16 + FPN 的组合,实现了高效的多尺度特征提取与融合,为协同显著目标检测提供了高质量的特征基础。其设计兼顾了性能与效率,使得模型在复杂场景下仍能保持高精度和实时性。
GCoNet+:更强大的团队协作 Co-Salient 目标检测器 2023 GCoNet+
摘要
在本文中,我们提出了一个新颖的端到端集团协作学习网络,称为GCONET+,该网络可以有效,高效(250 fps)在自然场景中识别共升性对象。拟议的GCONET+通过以下两个基本标准通过采矿共识表示来实现新的最新性能(COSOD):1)组内紧凑型通过使用我们的新型组亲和力模块(GAM)来更好地制定共同属性的共享属性,以更好地提高共同质量对象之间的一致性; 2)组间可分离性通过引入我们的新组协作模块(GCM)条件对不一致的共识进行调理,从而有效抑制嘈杂对象对输出的影响。为了进一步提高准确性,我们设计了一系列简单但有效的组件,如下所示:i)在语义层面上促进模型学习的经常性辅助分类模块(RACM); ii)一个置信度增强模块(CEM),以帮助该模型改善最终预测的质量; iii)基于组的对称三重态(GST)损失指导模型以学习更多歧视性特征。对三个具有挑战性的基准测试的广泛实验,即可可,COSOD3K和COSAL2015,这表明我们的GCONET+优于现有的12个尖端模型。代码已在https://github.com/zhengpeng7/gconet plus上发布。
创新点
1 组内紧凑型与组间可分离性
组内紧凑性(GAM):通过组亲和模块(Group Affinity Module, GAM)挖掘同一图像组内共显著物体的共享特征,增强一致性。
组间可分离性(GCM):通过组协作模块(Group Collaborating Module, GCM)区分不同组的特征,抑制噪声干扰。
2 三个新组件
置信度增强模块(CEM):结合可微分二值化和混合损失(BCE + IoU),提升预测图的二值化质量和置信度。((1)预测图的不确定性:传统CoSOD模型(如GCoNet)使用Sigmoid激活函数输出显著性图时,像素值倾向于分布在中间范围(如0.5附近),而非接近0(背景)或1(前景)的确定性值。(2)二值化质量与评估指标的矛盾:使用IoU损失监督时,预测图更接近二值化(0或1),但物体完整性差(边缘粗糙)。使用BCE损失时,预测图更平滑但置信度低,影响下游任务。解决问题:解决BCE损失导致的预测模糊问题;平衡二值化与细节保留;无需后处理)
组对称三元组损失(GST):首次将度量学习引入CoSOD,通过拉近组内特征、推开组间特征,增强特征判别性。(传统CoSOD的缺陷:现有方法(如GCoNet)仅通过单组图像学习组内共性(如GAM模块),但缺乏显式机制区分不同组之间的特征差异。监督信号不足:数据局限性,CoSOD训练集(如DUTS_class)通常每组仅含20-40张图像,且仅提供组级标签(无物体类别标签),导致特征学习缺乏判别性。显式建模组间差异,避免仅依赖组内一致性的局限性。利用无监督度量学习,在缺乏细粒度标注的条件下增强特征判别力。其与GAM(组内紧凑性)和GCM(组间对比)的协同作用,共同构成了GCoNet+的"组协作学习"核心机制。)
循环辅助分类模块(RACM):在原始ACM基础上引入循环机制,利用预测掩码过滤背景噪声,提升语义特征学习。((1)原始ACM的缺陷:特征污染:原始辅助分类模块(ACM)直接使用整张图像的特征(包含背景噪声)进行分类监督(式6),导致模型可能被无关区域干扰,学习到错误的语义关联(例如将背景误判为目标类别)。监督模糊性:当图像中存在多个非共显著物体时,ACM可能因全局特征融合而无法精准聚焦共显著区域。(2)语义共识学习不足:弱监督限制:CoSOD任务通常仅有组级标签(如“狗”组或“车”组),缺乏像素级类别标注,导致高层语义特征学习不够鲁棒。)
3 训练策略优化
提出联合使用DUTS_class(侧重显著性)和COCO-SEG/COCO-9k(侧重共显著性)数据集,解决现有训练集单一性问题。
4 效率与性能平衡
模型在250 FPS的高效推理下,仍达到SOTA性能(如CoCA数据集上Emax提升3.2%)。
模型的主要模块
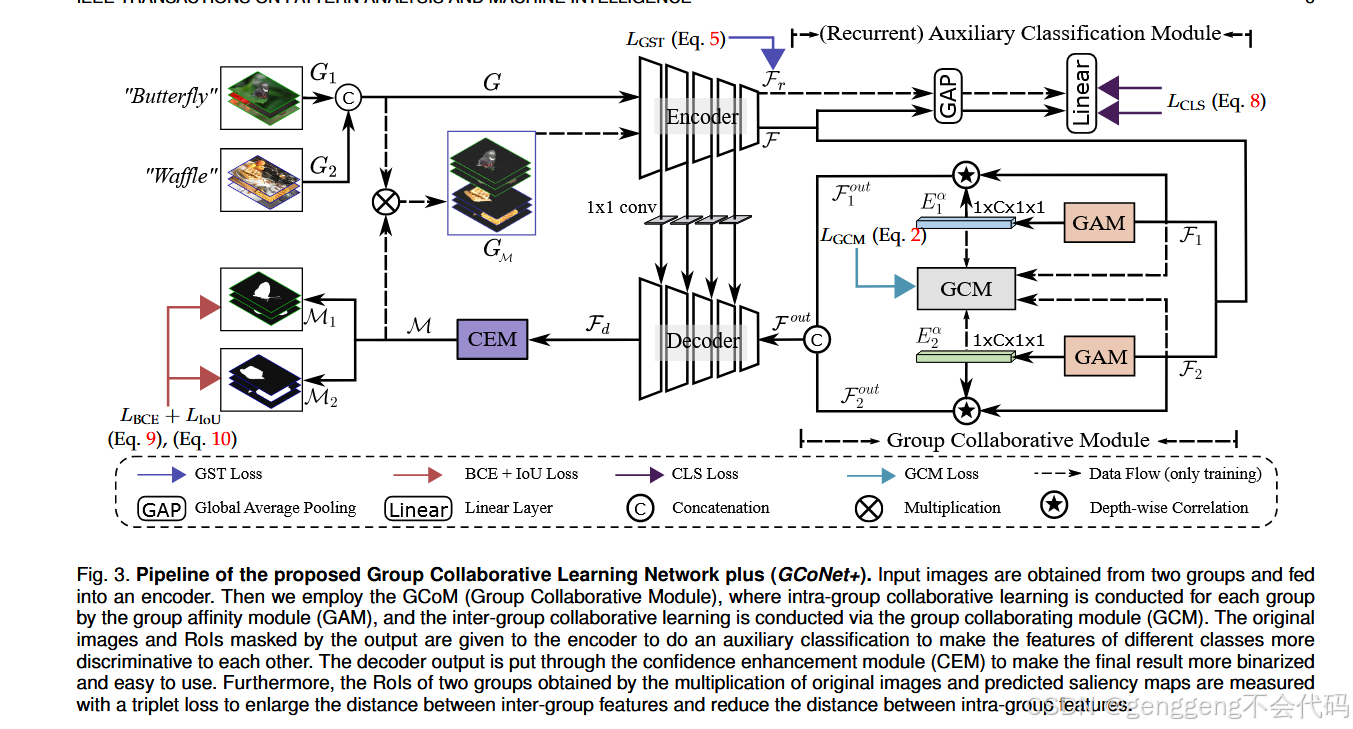
1 组亲和模块(GAM)
功能:计算组内图像的全局像素级相关性,生成注意力共识特征(![]() )。
)。
实现:通过线性嵌入函数(θ, φ)计算特征相似度矩阵,Softmax归一化后加权融合组内特征。
2 组协作模块(GCM)
功能:通过跨组特征交互![]() 学习组间差异,监督信号为全零图(抑制干扰)。
学习组间差异,监督信号为全零图(抑制干扰)。
损失函数:Focal Loss监督组内/组间预测(式2)
3 置信度增强模块(CEM)
功能:通过并行分支生成概率图(P)和阈值图(T),经可微分二值化(式3)输出高置信度预测。
关键参数:控制二值化陡度的k=300(NaN时降为50)。
4 组对称三元组损失(GST)
功能:在掩码后特征(![]() )上计算对称三元组损失(式5),优化特征空间分布。
)上计算对称三元组损失(式5),优化特征空间分布。
公式:![]()
5 循环辅助分类模块(RACM)
功能:利用预测掩码(M)过滤背景,循环输入编码器提取更纯净的语义特征,辅助分类(式8)。
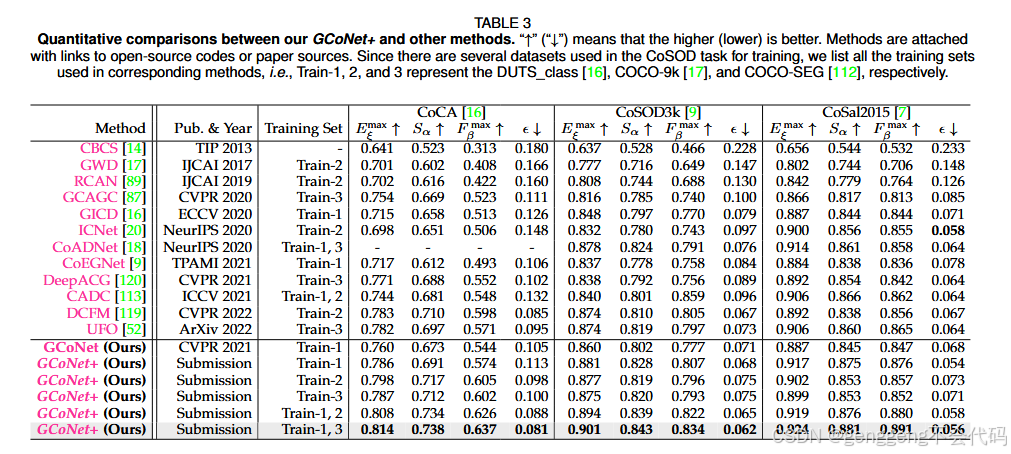
精度分析
在三个流行的Co-SOD基准数据集(CoCA,CoSOD,Cosal2015)上进行了广泛的实验,结果表明GCoNet+在定性和定量评估中均优于现有的最先进方法。
总结
GCoNet+通过组协作学习框架和三个创新模块,在保持高效推理的同时显著提升CoSOD性能。其核心在于:
- 联合优化组内/组间特征表示;
- 引入度量学习和循环分类机制增强语义判别性;
- 优化训练策略解决数据偏差问题。
实验证明其在复杂场景(如多物体、遮挡)中表现优异,为实际应用(如电商图像分割)提供了可靠解决方案。
网络
1 主干网络:VGG-16 with BN
(1)原始VGG-16结构
VGG-16 是一个经典的CNN结构,由13个卷积层(Conv + ReLU)和3个全连接层(FC)组成。GCoNet+ 移除了最后的FC层,仅保留卷积部分作为特征提取器。
(2)改进点:Batch Normalization (BN)
- 在VGG-16的每个卷积层后增加BN层,加速训练并提升模型稳定性。
- BN层计算公式:

(3)特征金字塔结构(FPN-style)
GCoNet+ 不直接使用VGG-16的最后一层特征,而是采用类似FPN(Feature Pyramid Network)的多尺度特征融合策略:
1.提取不同层级的特征(Conv3, Conv4, Conv5):
- Conv3(低层特征):捕捉边缘、纹理等细节信息(分辨率较高)。
- Conv4(中层特征):兼顾语义和位置信息。
- Conv5(高层特征):包含丰富的语义信息(分辨率较低)。
2.通过1×1卷积调整通道数,使不同层特征维度一致(如512维)。
3.上采样+逐元素相加融合多尺度特征,增强模型对不同大小目标的检测能力。
2 编码器-解码器(Encoder-Decoder)结构
GCoNet+ 采用U-Net风格的编解码结构,但进行了简化:

3 轻量化改进
相比GCoNet和其他CoSOD模型(如GICD、CADC),GCoNet+的主干网络进行了以下优化:
- 移除冗余模块:
- 去除了GICD中的多阶段监督(Multi-stage Supervision)。
- 简化了侧边连接(Lateral Connections),仅用1×1卷积代替复杂结构。
- 参数量减少:
- 原始GCoNet参数量为541.7MB,GCoNet+降至70.3MB(表4)。
- 主要归功于VGG16-BN的轻量化和模块精简。
- 推理速度优化:
- 在A100 GPU上,单帧处理仅需3.5ms(285 FPS),适合实时应用。
4 总结
GCoNet+的主干网络核心是VGG16-BN + 轻量化FPN,通过以下设计实现高效共显著检测:
- VGG16-BN 作为基础特征提取器,平衡速度和精度。
- FPN-style多尺度融合 增强小目标检测能力。
- 编解码结构 结合跳跃连接,恢复细节信息。
- CEM、GST、RACM 等模块进一步提升性能,同时保持低计算成本。
民主很重要:用于共同显著目标检测的全面特征挖掘 2022 DCFM
摘要
共同显著目标检测旨在检测一组图像中共同存在的显著目标,正日益受到关注。近期的研究工作采用注意力机制或额外信息来聚合共同的显著特征,这导致对目标对象的响应不完整,甚至出现错误。在本文中,我们旨在以民主的方式挖掘全面的共同显著特征,并在不引入任何额外信息的情况下减少背景干扰。 为了实现这一目标,我们设计了一个民主原型生成模块来生成民主响应图,该图涵盖了足够的共同显著区域,从而包含了共同显著目标更多的共享属性。然后,基于这些响应图可以生成一个综合原型,作为最终预测的指导。 为了抑制原型中的噪声背景信息,我们提出了一个自对比学习模块,该模块在不依赖额外分类信息的情况下形成正样本对和负样本对。此外,我们还设计了一个民主特征增强模块,通过重新调整注意力值来进一步强化共同显著特征。 大量实验表明,我们的模型比之前的先进方法表现更优,特别是在具有挑战性的真实场景中(例如,对于CoCA数据集,在相同设置下,我们的平均绝对误差(MAE)降低了2.0%,最大F值提升了5.4%,最大E值提升了2.3%,S值提升了3.7%)。源代码可在https://github.com/siyueyu/DCFM获取。
创新点
1 民主化特征挖掘机制
核心思想:传统注意力机制往往聚焦于少数显著区域,导致特征覆盖不完整。本文提出"民主化"策略,通过多响应图融合(Democratic Response Block)和注意力值重调整(Democratic Feature Enhancement),使更多相关像素参与特征表达,提升对共显对象的完整性检测。
为什么要提出民主化特征挖掘机制?
核心贡献:通过“民主化”策略,使模型能够更全面、均衡地利用图像中的共显特征,而不是被少数高响应区域主导,从而提升检测的完整性和鲁棒性。
技术实现:
(1)种子选择(SSB)通过跨图像相似性计算选择最具代表性的像素作为种子。
(2)民主响应图生成(DRB)利用种子与所有像素的关联性生成覆盖更广的响应图,避免遗漏分散的共显区域。
2 自对比学习模块(SCL)
为什么要提出自对比学习模块(SCL)?
SCL 的核心贡献是通过自生成的对比样本(擦除背景/对象),解决了以下问题:
- 背景噪声抑制:无需外部数据,自监督学习区分共显对象与背景。
- 特征一致性增强:提升模型对共显对象变化的鲁棒性。
- 轻量化训练:摆脱对分类标签或额外数据集的依赖,降低标注成本。
这一模块的创新性在于将对比学习与共显检测任务的需求紧密结合,实现了更高效、更自适应的特征学习。
无监督去噪:不依赖额外分类信息,通过图像自身生成正负样本对:
(1)正样本:原图与擦除背景后的特征原型(proto_c)的相似性最大化。
(2)负样本:原图与擦除共显对象后的背景原型(proto_b)的相似性最小化。
优势:有效抑制复杂背景干扰,无需人工标注的辅助数据。
3 民主特征增强模块(DFE)
注意力机制改进:传统注意力倾向于强化少数高响应值,本文通过指数放大低但正相关的注意力值(公式19中的(Z_{i,j}+1)^α),使更多弱相关区域参与特征增强,提升对小尺度或低对比度共显对象的检测能力。
模型的主要模块
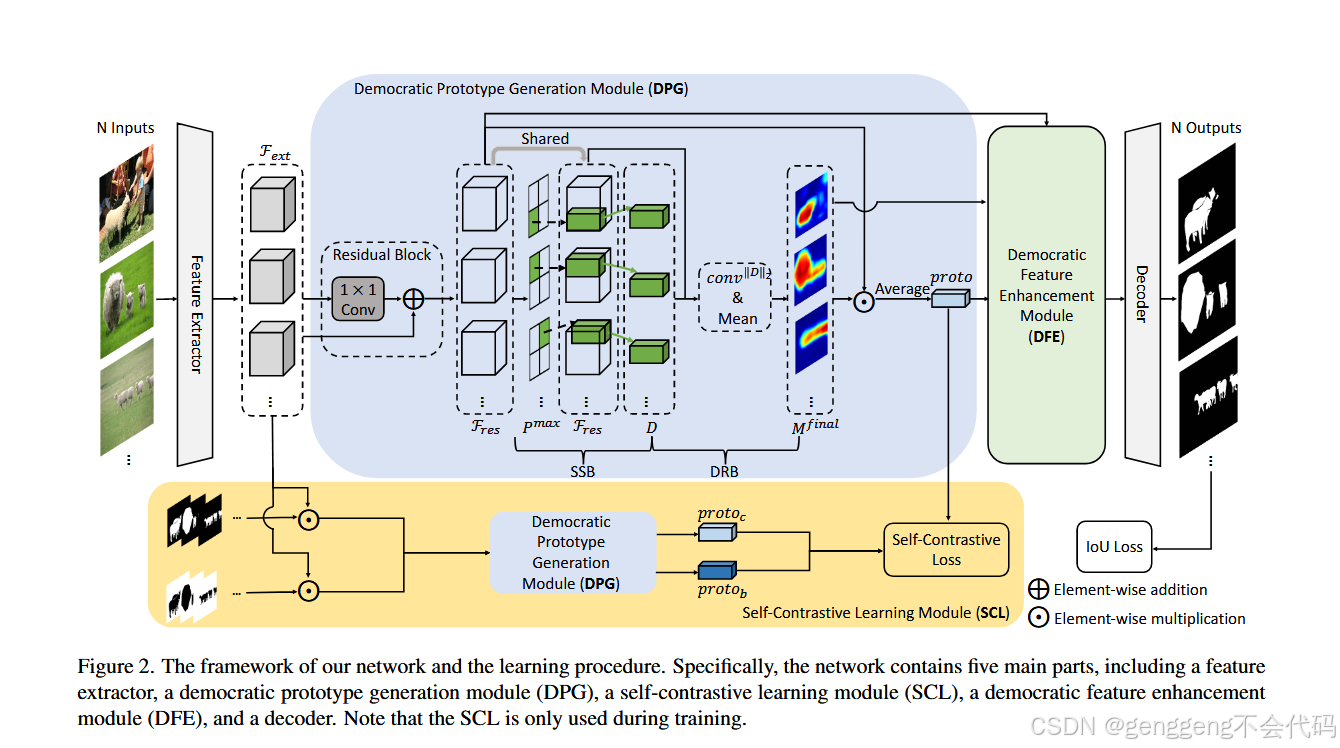
1 民主原型生成模块(DPG)
流程:
- 残差特征提取:通过1×1卷积增强初始特征(
F_res)。 - 种子选择(SSB):计算像素间最大相似度,选择每组图像中最具代表性的种子特征。
- 民主响应图生成(DRB):利用种子与全图像素的卷积生成多响应图,取平均得到覆盖更广的最终响应图(
M_final),进而生成全局原型(proto)。
2 自对比学习模块(SCL)
训练阶段专用:通过构造正负原型对(proto与proto_c、proto_b),利用余弦相似度损失(公式16)驱动模型区分共显对象与背景。
3 民主特征增强模块(DFE)
操作:对融合特征(F_fused)计算注意力图后,对低但正相关的注意力值进行指数放大(α=3),再与值特征加权求和,增强特征表达。
4 解码器
输入:经过DFE增强的特征(F_enh)直接用于预测共显性掩码,损失函数采用IoU损失与SCL损失的加权和(λ=0.1)。
精度分析
在三个流行的Co-SOD基准数据集(CoCA,CoSOD,Cosal2015)上进行了广泛的实验,结果表明DCFM在定性和定量评估中均优于现有的最先进方法。
总结
该论文通过民主化特征挖掘和自监督对比学习,实现了无需额外数据的共显对象检测,在复杂场景中达到SOTA。其核心创新在于将"民主"思想引入视觉特征学习,通过技术手段确保更多相关区域参与决策,为小样本学习提供了新思路。
网络
1 采用 FPN 结合 VGG16 作为主干网络
1. VGG16 作为基础特征提取器
2 FPN
FPN 用于 融合多尺度特征,解决共显对象尺寸变化大的问题。其核心思想是 自顶向下(Top-Down) 的特征金字塔结构,结合横向连接(Lateral Connection)增强语义信息。




用于共显著目标检测的记忆辅助对比共识学习 2023 MCCL
创新点
1 Memory-aided Contrastive Consensus Learning (MCCL)
(1)提出了一种结合内存队列和对比学习的框架,通过跨组对比增强组内共识特征的判别性。传统方法仅利用组内一致性,而MCCL通过内存保存历史组共识,使模型能区分不同类别的共性特征。
(2)跨组对比学习:通过内存队列动态更新不同组的共识特征,利用三元组损失(GST Loss)拉近组内共识、推远组间共识,提升特征区分度。
2 Group Consensus Aggregation Module (GCAM)
基于非局部块设计,通过特征拆分与相关性计算生成组内共识。将特征分为两部分,计算其亲和力矩阵后与原始特征融合,高效提取共性特征。
3 Adversarial Integrity Learning (AIL)
引入对抗学习提升显著性图的完整性:生成器(主网络)需生成能掩盖完整对象的区域,判别器则区分预测掩码与真实掩码。直接优化对象的完整性,减少背景噪声和部分缺失问题。
4 高效轻量设计
仅需单阶段训练,推理时丢弃MCM和AIL模块,实现150 FPS的高速度(PVTv2主干),同时精度显著提升(S-measure提高5.9%-6.2%)。
模型的主要模块
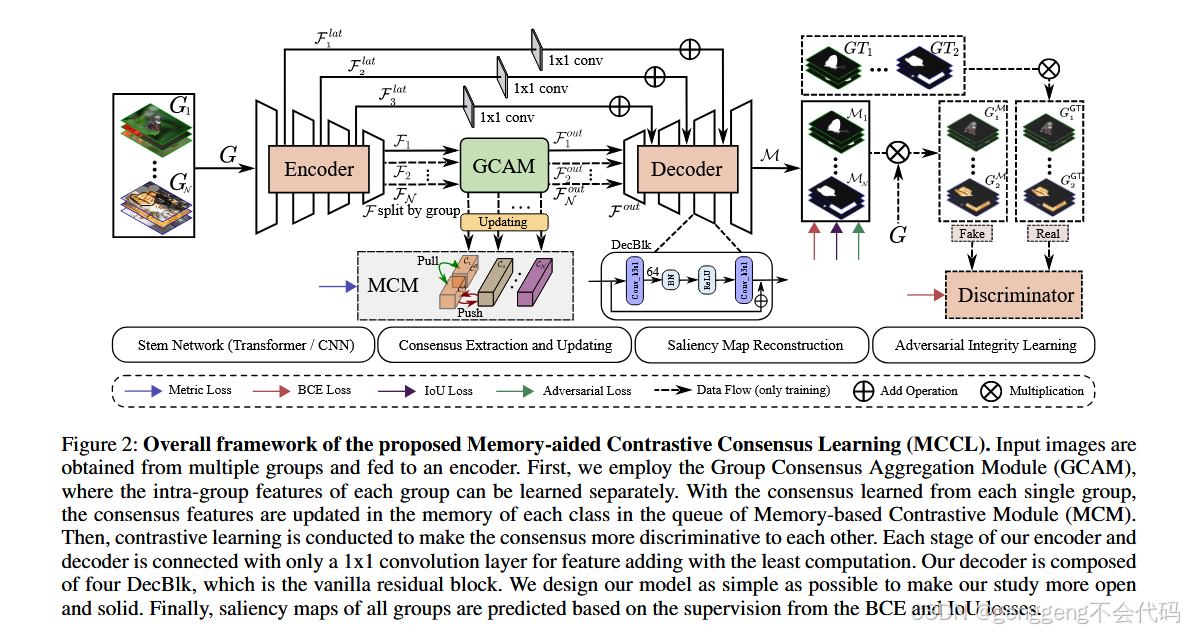
1 GCAM(组共识聚合模块)
输入:同组图像特征(如组1的![]() )
)
流程:
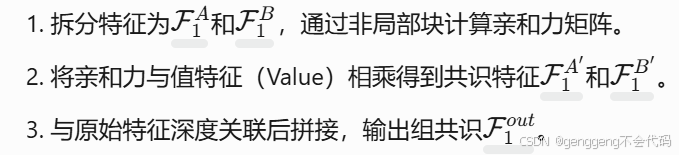
作用:高效聚合组内共性特征。
2 MCM(基于内存的对比模块)
内存队列:保存历史组共识(如C1为组1的动量更新内存)。
对比学习:将![]() 作为正样本对,其他组(如
作为正样本对,其他组(如![]() )作为负样本,通过三元组损失优化特征空间分布。
)作为负样本,通过三元组损失优化特征空间分布。
动量更新:![]()
3 AIL(对抗完整性学习)
生成器:主网络生成预测掩码M,与输入图像相乘得到掩码区域![]() 。
。
判别器:区分![]() (真,来自真实掩码)。
(真,来自真实掩码)。
目标:通过对抗损失迫使生成器输出完整对象区域。
4 解码器
简单设计:4个残差块融合多尺度特征(来自编码器的侧向连接),输出显著性图。
精度分析
在三个流行的Co-SOD基准数据集(CoCA,CoSOD,Cosal2015)上进行了广泛的实验,结果表明MCCL在定性和定量评估中均优于现有的最先进方法。
总结
MCCL通过内存对比学习和对抗完整性优化,在精度与速度间取得平衡。其核心创新在于:
- 跨组对比增强共识判别性(MCM);
- 对抗学习直接优化完整性(AIL);
- 轻量PVTv2主干实现高效计算。实验表明,该方法在复杂场景(如多对象、遮挡)中表现优异,为实时CoSOD提供了新思路。
网络
1 采用 PVTv2(Pyramid Vision Transformer v2)作为主干网络
本文采用 PVTv2作为主干网络,相比传统CNN(如ResNet)和标准ViT(Vision Transformer),PVTv2在计算效率和特征表达能力上具有显著优势,特别适合密集预测任务(如CoSOD)。
1. PVTv2是PVT的升级版,主要优化了以下方面:
(1)重叠块嵌入(Overlapping Patch Embedding)
问题:标准ViT的Patch Embedding(非重叠切分)会丢失局部连续性,影响细节捕捉。
改进:采用滑动窗口+重叠切分(如kernel=7, stride=4),增强局部特征关联性。
作用:提升低层特征的边缘和纹理信息,对显著性检测至关重要。
(2)卷积前馈网络(Convolutional FFN)
问题:标准Transformer的FFN(全连接层)缺乏空间先验,计算成本高。
改进:用深度可分离卷积(DWConv)替换FFN中的MLP,引入局部性归纳偏置。
作用:减少计算量,同时保留局部上下文信息。
(3)线性空间注意力(Linear Spatial Reduction Attention, SRA)
问题:标准多头自注意力(MSA)的计算复杂度随输入尺寸平方增长![]() 。
。
改进:在注意力计算前,对Key/Value进行空间降维(如缩放因子R=8),降低计算量。
公式: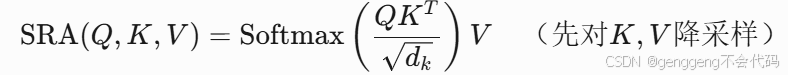
作用:平衡全局建模能力与计算效率。
2. PVTv2在MCCL中的具体结构
(2) 与MCCL的适配设计
- 多尺度特征融合:PVTv4的4阶段输出(F1lat到F4lat)通过侧向连接输入解码器,结合高低层特征。
- 轻量化:PVTv2的参数量仅25M,推理速度达150 FPS(输入256×256),远快于ResNet-50(约50 FPS)。
3 总结
PVTv2作为MCCL的主干网络,通过重叠块嵌入、卷积FFN和线性空间注意力,实现了:
- 高效全局建模(适合跨图像共性学习);
- 多尺度特征融合(提升显著性检测完整性);
- 轻量高速推理(150 FPS,适合实际部署)。
其设计完美契合CoSOD任务的需求,为后续的GCAM(组共识聚合)和MCM(内存对比学习)提供了强大的特征基础。
重新思考协同显著性 2020 COEGNeT
创新点
模型创新
核心思想:将协同显著性检测分解为两个独立分支:
(1)显著性先验分支:使用现成的 SOD 模型(EGNet)提取单图像的显著物体。
(2)协同注意力分支:通过无监督的协同注意投影(Co-attention Projection)捕捉多图像间的共同特征。
创新技术:
(1)协同注意投影:基于主成分分析(PCA)从图像特征中提取最大方差的投影方向,无需类别标签即可定位协同显著区域。
(2)轻量级设计:仅需在现有 SOD 模型(EGNet)上添加协同分支,计算效率高。
模型的主要模块
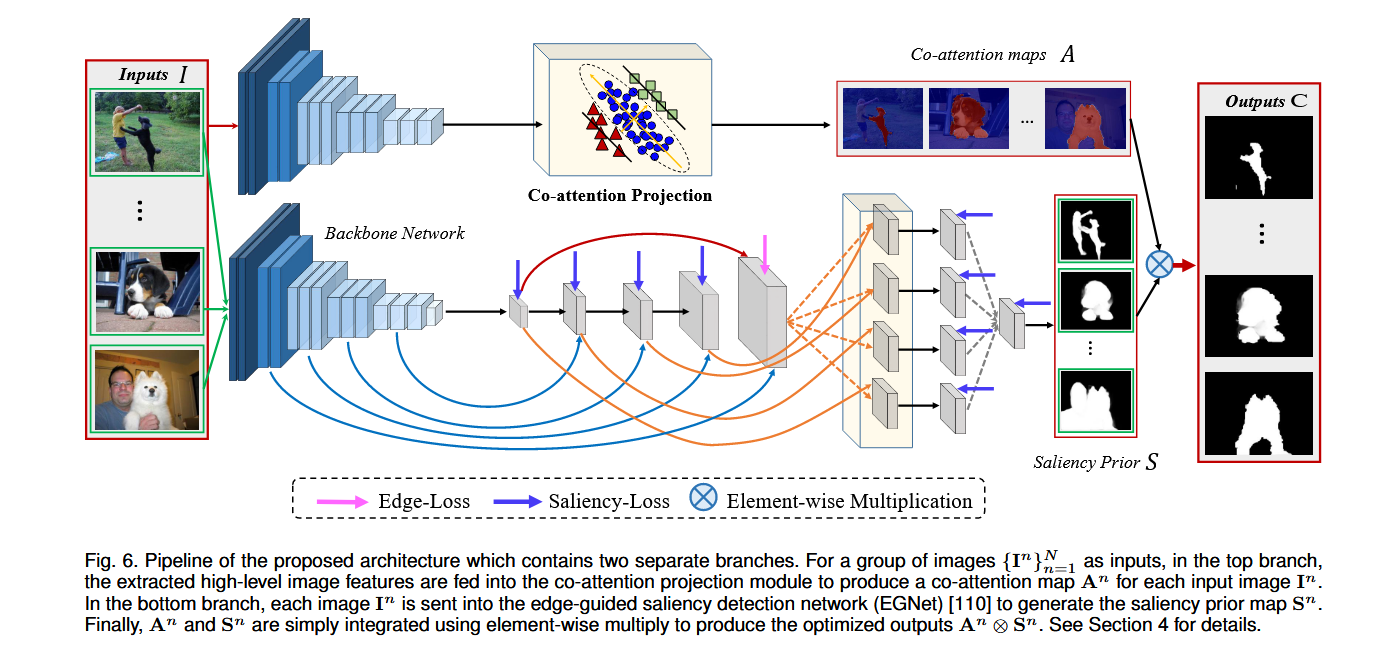
CoEG-Net 是一个双分支框架
(1)显著性先验分支(EGNet)
主干网络:VGG-16(移除分类层),在 DUTS 数据集上预训练。
功能:对单张图像 ![]() 生成显著图
生成显著图 ![]() ,捕捉局部显著性。
,捕捉局部显著性。
(2)协同注意力分支
特征提取:使用 VGG-16 的最后一层卷积特征 ![]() 。
。
协同注意投影:

后处理:通过 DenseCRF 和流形排序优化协同图边界。
(3)融合与输出
最终协同显著图通过逐元素相乘得到:![]()
精度分析
在三个流行的Co-SOD基准数据集(iCoSeg,CoSOD3k,Cosal2015)上进行了广泛的实验,结果表明COEGNeT在定性和定量评估中均优于现有的最先进方法。
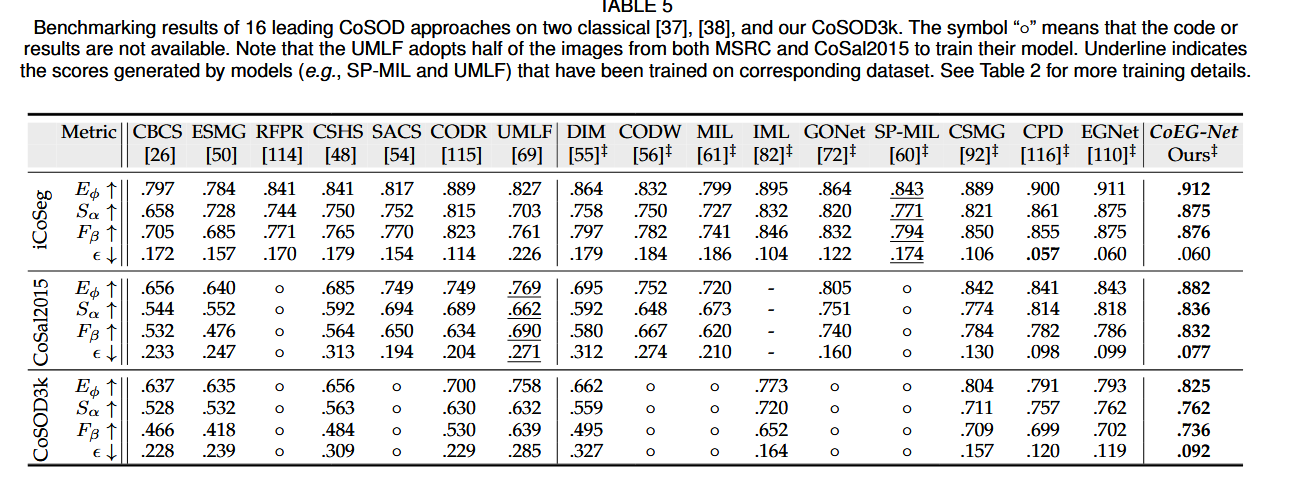
总结
论文通过构建高质量数据集、提出轻量级双分支模型(CoEG-Net)和系统性评测,推动了 CoSOD 领域的发展。其核心创新在于无监督协同注意投影和数据驱动的基准分析,为后续研究提供了重要参考。
网络
1.基础网络:VGG-16
(1) 基础网络:VGG-16
-
原始结构:VGG-16 是一个经典的卷积神经网络,包含 13 个卷积层(分 5 个块)和 3 个全连接层。
-
修改:
-
移除分类层:去掉最后的全连接层(FC6、FC7、FC8),仅保留卷积部分(Conv1-5)。
-
输入尺寸:支持任意尺寸输入(原 VGG-16 需固定输入 224×224)。
-
输出特征:使用 最后一个卷积层(Conv5-3) 的输出作为特征图 Xn∈RH×W×512,其中 H×W 为空间尺寸,512 为通道数。
-
(2) 显著性分支(EGNet)
-
功能:生成单图像的显著性先验图 Sn。
-
结构:
-
直接复用 EGNet(原论文引用的 SOD 模型),其主干也是 VGG-16,但通过多级特征融合和边缘监督优化显著图。
-
EGNet 在 DUTS 数据集(单图像 SOD 数据集)上预训练,确保显著性检测的鲁棒性。
-
(3) 协同注意力分支
-
输入:VGG-16 的 Conv5-3 特征 Xn。
-
协同投影:
-
特征归一化:计算所有图像特征的均值 xˉ,得到零中心特征 x^n(i,j)=xn(i,j)−xˉ。
-
PCA 投影:求解协方差矩阵 Cov(x^) 的最大特征向量 ξ∗∈R512,生成协同注意图 An(i,j)=ξ∗⊤⋅x^n(i,j)。
-
-
无监督设计:无需额外训练,直接利用特征统计特性。
2. 关键设计细节
(1) 特征提取的适应性
-
多尺度处理:VGG-16 的深层特征(Conv5-3)捕获高级语义信息,适合定位语义相似的协同物体。
-
轻量化:仅需单次前向传播提取特征,无需重复计算。
(2) 与 EGNet 的协同
-
独立性:显著性分支(EGNet)和协同分支(VGG-16 + PCA)完全独立,可灵活替换其他 SOD 模型或主干网络。
-
融合方式:通过逐元素相乘 An⊗Sn 结合全局协同信息与局部显著性。
(3) 后处理优化
-
DenseCRF:优化协同注意图 An 的边界细节。
-
流形排序:增强协同区域的一致性。
3. 性能与效率
-
参数量:与原始 VGG-16 相近(约 138M 参数),协同投影仅增加少量计算。
-
速度:
-
在 RTX 2080Ti 上处理一组图像平均耗时 2.3 秒(传统方法如 UMLF 需 87 秒)。
-
主要瓶颈在 EGNet 的显著性计算,协同投影几乎无额外开销。
-
Summarize and Search: Learning Consensus-aware Dynamic Convolution for Co-显著性检测 2021 CADC
摘要
人类通过首先总结整个组中的共识知识,然后搜索每个图像中的相应对象来执行共同检测。以前的方法通常缺乏第一个过程的稳健性,可扩展性或稳定性,而仅将共识功能与第二个过程的图像特征融合在一起。在本文中,我们提出了一种新颖的共识动态卷积模型,以明确有效地执行“总结和搜索”过程。为了概述共识图像特征,我们首先使用有效的合并方法总结了每个图像的强大特征,然后通过自我注意解机制汇总了互相合共识线索。通过这样做,我们的模型满足可扩展性和稳定性要求。接下来,我们从共识功能中生成动态内核来编码汇总的共识知识。以补充方式生成两种内核,以总结精细的图像特异性共识线索和粗糙群体的常识。然后,我们可以通过在多个尺度上采用动态卷积来有效地执行对象搜索。此外,还提出了一种新颖有效的数据合成方法来训练我们的网络。四个基准数据集的实验结果验证了我们提出的方法的有效性。我们的代码和显著图可从https://github.com/nnizhang/cadc获得
创新点
1 “Summarize and Search”范式建模:模拟人类在协同显著性检测中的思维过程,先总结全组图像的共识信息(summarize),再在每张图中搜索共性目标(search)。
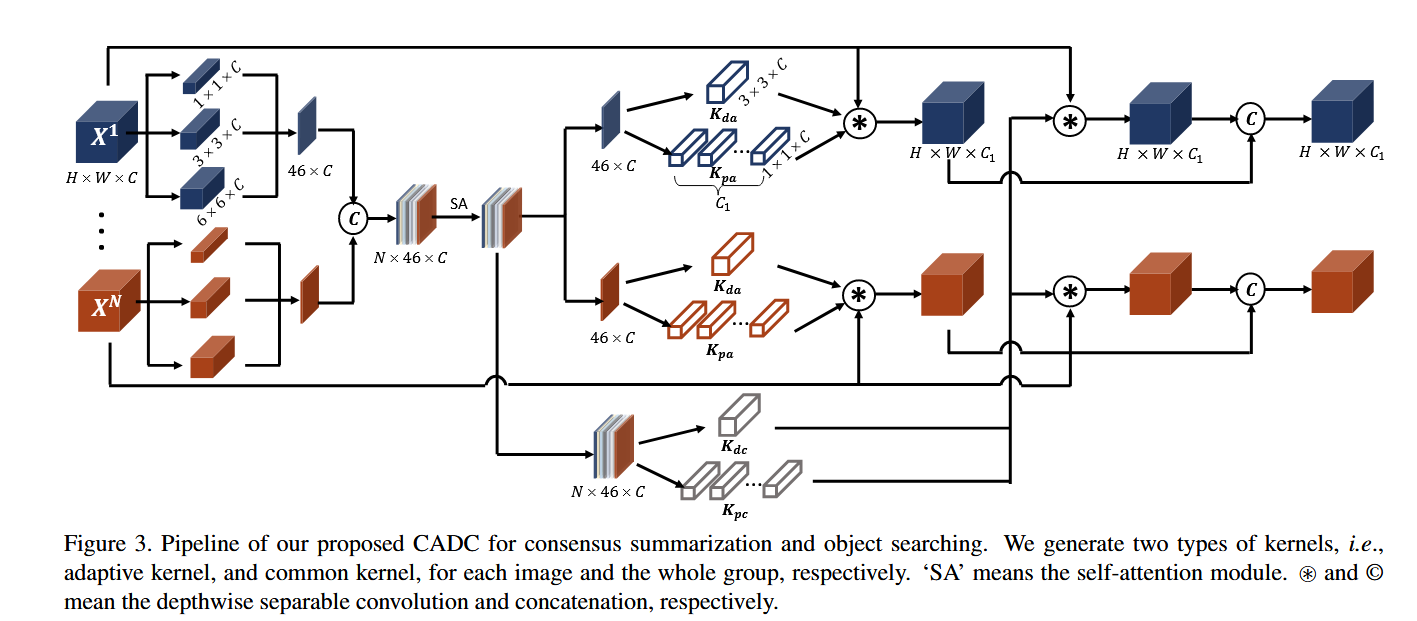
2 共识感知动态卷积模块(CADC):
(1)提出一种新颖的共识感知动态卷积结构,能根据提取的共识特征生成动态卷积核,对每张图像进行显著性搜索。
(2)设计了两类动态卷积核:
Image-adaptive kernels(图像自适应):捕捉图像特定的细粒度共识。
Common kernels(组共享):编码组层面的粗共识,作为正则约束。
3 多尺度 max-pooling + 自注意力聚合共识特征:增强了模型在位置变化与尺度变化下的鲁棒性,同时保证可扩展性和稳定性。
4 新颖的数据合成策略:提出双向合成(normal + reverse)策略,模拟现实中目标被干扰的复杂场景。
模型的主要模块
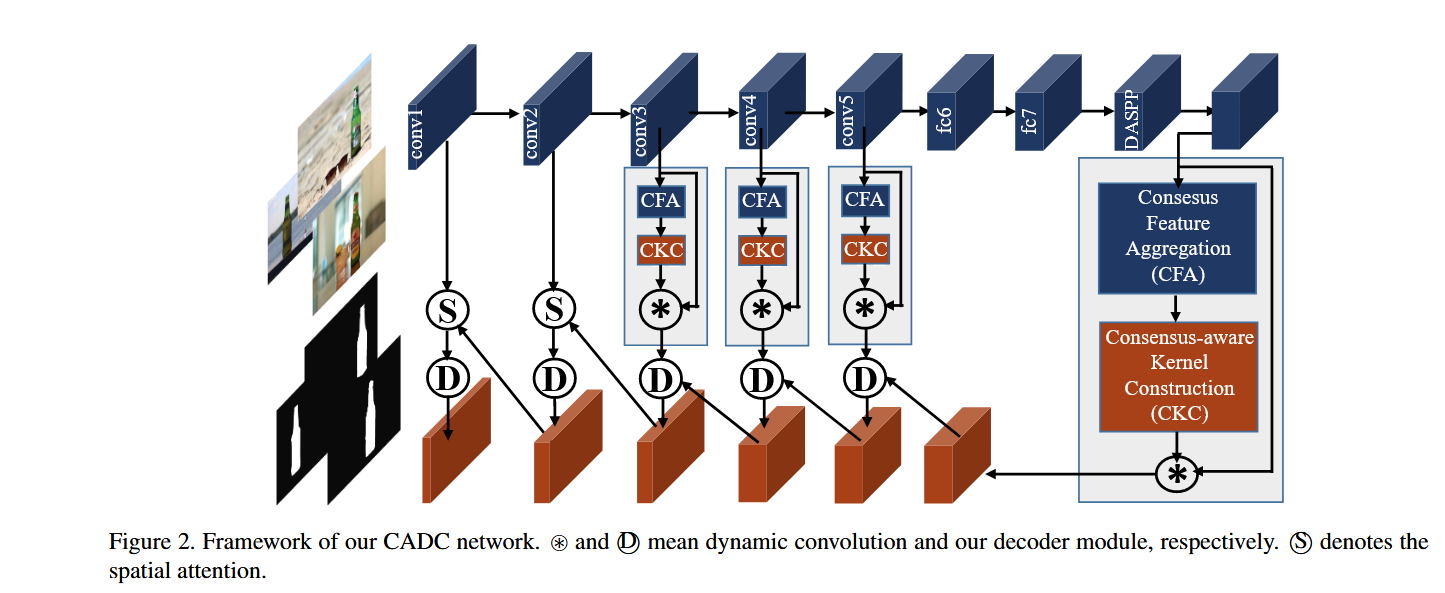
1 Encoder:基于修改的 VGG16 + DASPP(Dense Atrous Spatial Pyramid Pooling)模块。
2 Consensus Feature Aggregation (CFA) 共识特征聚合
每张图通过多尺度 max-pooling 提取局部显著特征(1x1, 3x3, 6x6),降低特征维度。
利用自注意力(self-attention)机制聚合跨图像的共识信息。
3 Consensus-aware Kernel Construction (CKC)
使用聚合后的共识特征生成:
Vanilla (1x1) dynamic kernels:通道感知;
Large (3x3) dynamic kernels:空间感知,利用depthwise separable卷积提高效率。
4 Object Searching via Dynamic Convolution
用上述动态卷积核在每张图上进行卷积,实现显式目标搜索。
多层级(hierarchical)结构嵌入U-Net decoder,实现不同尺度下的协同检测。
5 Decoder + Multi-level Search:在前4个解码模块中进行CADC卷积搜索,后两个使用spatial attention细化。
精度分析
在四个流行的Co-SOD基准数据集(CoCA,CoSOD3k,Cosal2015,MSRC)上进行了广泛的实验,结果表明CADC定性和定量评估中均优于现有的最先进方法。
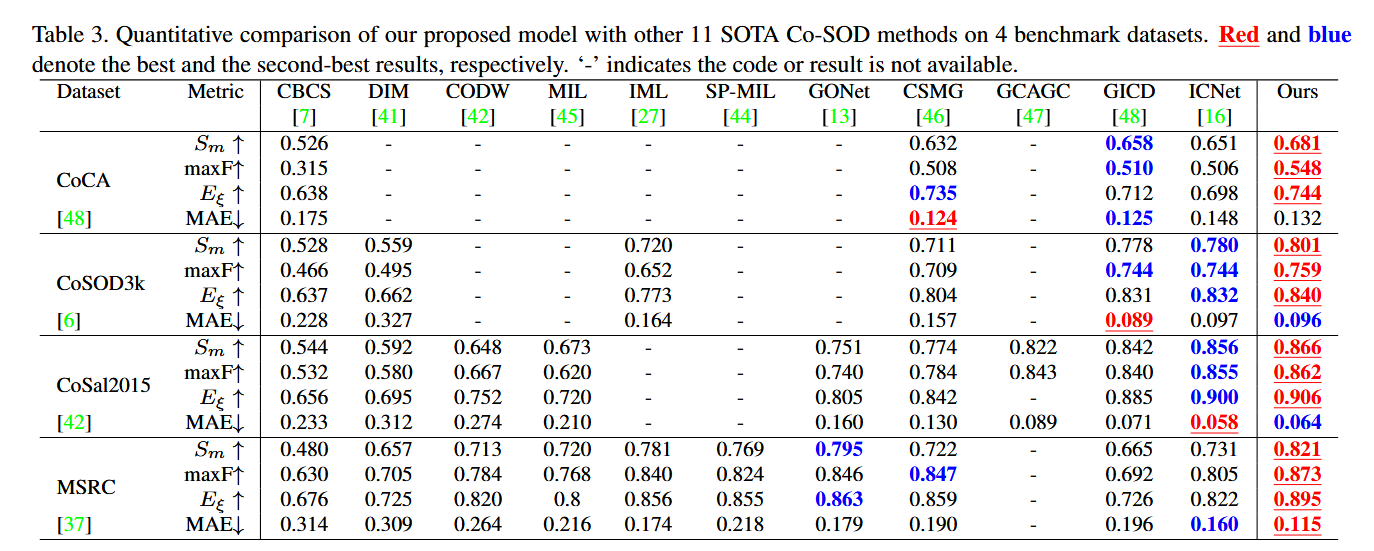
总结
本文通过动态卷积显式建模“Summarize and Search”过程,结合多尺度共识聚合和双向数据合成,在共显著性检测任务中实现了SOTA性能。核心创新在于动态核的互补设计和高效实现,以及更自然的训练数据生成策略。
网络
1 主干网络是一个基于 U-Net架构的结构
这篇论文的主干网络(Backbone Network)是一个基于 U-Net架构 的编码器-解码器结构,结合了 VGG-16 作为基础编码器,并引入了 动态空洞空间金字塔池化(DASPP) 模块以增强多尺度特征提取能力。以下是主干网络的详细解析:
1. 编码器(Encoder)
(1) 基础编码器:修改的VGG-16
-
原始VGG-16的调整:
-
移除了最后两个最大池化层(pool4和pool5),保留更高分辨率的特征图(减少下采样次数)。
-
修改后的输出特征图尺寸为输入图像的 1/8(原始VGG-16为1/32),有利于保留空间细节。
-
卷积层配置:13个卷积层(Conv1-1到Conv5-3),ReLU激活,部分层后接批归一化(BN)。
-
(2) 多尺度扩展:DASPP模块
-
DASPP(Dynamic Atrous Spatial Pyramid Pooling):
-
动机:解决共显著性物体尺度变化问题,类似DeepLab中的ASPP,但引入动态空洞率调整。
-
结构:并行多个空洞卷积(atrous conv),空洞率分别为 1, 6, 12, 18,后接全局平均池化分支。
-
输出:多尺度特征融合后,通道数统一为 512维,与VGG最后一层特征拼接。
-
(3) 编码器输出
-
输入图像尺寸:256×256 → 编码器输出特征图尺寸:32×32×512(H×W×C)。
-
特征图后续被送入 多尺度最大池化模块(生成1×1、3×3、6×6的池化特征)。
2. 解码器(Decoder)
解码器采用 U-Net风格的跳跃连接,逐步恢复空间分辨率并融合低层细节。关键设计如下:
(1) 层级结构
-
5级解码器(Decoder1-Decoder5),每级包含:
-
上采样:双线性插值或转置卷积(×2放大)。
-
特征融合:将同层编码器特征(跳跃连接)与上一级解码器特征拼接。
-
卷积块:2个3×3卷积 + BN + ReLU,用于特征细化。
-
(2) CADC模块的集成
-
应用位置:前四个解码器层(Decoder1-Decoder4)嵌入 共识感知动态卷积(CADC)。
-
输入:当前层编码器特征 + 上一级解码器特征。
-
动态卷积操作:
-
用自适应核(Ka)和共同核(Kc)分别卷积编码器特征。
-
融合响应图后与解码器特征拼接,再通过3×3卷积细化。
-
-
作用:在多个尺度上显式搜索共显著性物体。
-
(3) 高层解码器(Decoder5)
-
简化设计:仅使用空间注意力(无CADC),通过通道注意力过滤无关特征。
-
最终输出:通过1×1卷积 + Sigmoid生成256×256的共显著性图。
3. 动态卷积(CADC)的细节
动态卷积是主干网络的核心创新,其实现步骤如下(以Decoder1为例):
-
输入特征:编码器特征 X∈RN×32×32×512(N为图像组大小)。
-
动态核生成:
-
自适应核(Ka):通过自注意力加权图像特定特征生成(尺寸1×1或3×3)。
-
共同核(Kc):通过全局注意力聚合组内共识生成。
-
-
深度可分离卷积:
-
对3×3大核,分解为深度卷积(逐通道)和点卷积(1×1),减少计算量。
-
-
特征融合:将动态卷积结果与解码器特征拼接,通过3×3卷积输出。
4. 训练细节
-
输入尺寸:256×256,归一化至[0,1]。
-
损失函数:
-
加权交叉熵损失:主损失函数。
-
深度监督:每个解码器层输出均计算辅助损失(权重递减)。
-
-
优化器:SGD,初始学习率0.01,20k和30k迭代时衰减10倍。
-
Batch Size:每组最多14张图像(显存限制)。
5. 关键设计优势
-
多尺度特征保留:修改的VGG-16减少下采样次数,DASPP增强多尺度上下文感知。
-
动态卷积的灵活性:自适应核捕捉图像特定信息,共同核强化组内共性,互补提升鲁棒性。
-
计算效率:深度可分离卷积降低3×3动态核的参数量,适合多层级联。
CONDA:用于 Co-Salient 目标检测的压缩深度关联学习 2024 CONDA
摘要
图像间的关联建模对于共同定位对象检测至关重要。尽管性能令人满意,但以前的方法仍然对足够的间形间关联建模有局限性。因为他们中的大多数都集中在启发式计算的原始图像间关联的指导下优化图像特征。他们直接依赖于在复杂场景中不可靠的原始关联,其图像特征优化方法并不明确用于间图像间的关联建模。为了减轻这些局限性,本文提出了一种深入的关联学习策略,该策略部署了有关原始关联的深层网络,以明确地将它们转化为深层关联特征。具体而言,我们首先创建超级求解以收集密集的像素对的原始关联,然后在它们上部署深层聚合网络。我们为此目的设计了一个渐进式关联生成模块,并增强了超关联计算。更重要的是,我们提出了一个对应性诱导的凝结模块,该模块引入了借口任务,即语义对应估计,以将计算负担减少和消除噪声的超相关凝结。我们还为高质量的对应估计设计了一个对象感知周期的一致性损失。三个基准数据集中的实验结果证明了我们提出的方法在各种培训环境中具有出色的有效性。该代码可在以下网址提供:https://github.com/dragonlee258079/conda。
创新点
1 深度关联学习策略:传统方法通常通过启发式计算的原始关联(如像素级、区域级或图像级相似性)来优化图像特征,而本文提出直接对原始关联应用深度网络,将其转化为深度关联特征。这种策略更显式地建模图像间关联,能够捕获更高层次的关联知识,提升复杂场景下的鲁棒性。
2 渐进式关联生成模块(PAG):PAG模块通过多尺度渐进生成关联特征,利用前一尺度的关联特征增强当前尺度的超关联计算,从而从初始阶段就提升关联质量。这种渐进式设计避免了直接使用未经优化的骨干网络特征计算关联的局限性。
3 基于语义对应的关联压缩模块(CAC):为了解决全像素超关联计算的高计算负担和噪声问题,CAC模块引入语义对应估计任务,仅选择语义对应的像素及其周围上下文像素构建轻量化的超关联。这不仅降低了计算量,还通过过滤噪声像素提升了关联质量。
4 对象感知循环一致性损失(OCC): 为监督语义对应估计,OCC损失仅在共显著像素上施加循环一致性约束,避免背景像素的干扰。这一设计显著提升了语义对应的准确性。
模型的主要模块
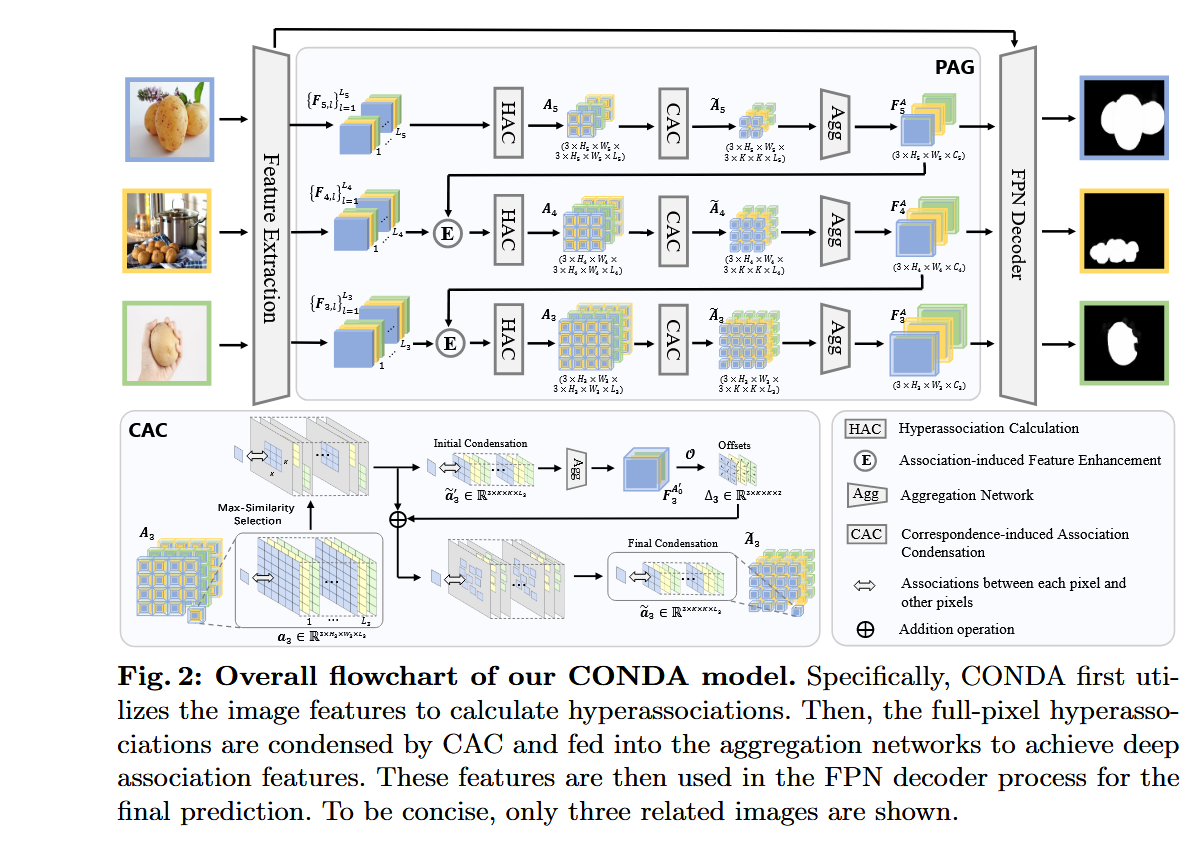
1 渐进式关联生成模块(PAG):
(1)超关联计算(HAC):通过归一化特征的内积计算像素级原始关联,形成超关联(Hyperassociation)。
(2)聚合网络(Agg):对超关联应用多层上下文聚合,逐步压缩目标维度,生成深度关联特征。
(3)关联诱导的特征增强(Enh):利用当前尺度的关联特征增强下一尺度的骨干特征,形成渐进式优化。
2 基于语义对应的关联压缩模块(CAC):
(1)初始对应估计:通过最大相似度选择初始对应像素。
(2)偏移预测:利用初始关联特征预测空间偏移,进一步精炼对应像素位置。
(3)关联压缩:根据精炼后的对应像素及其周围像素构建压缩后的超关联。
3 对象感知循环一致性损失(OCC):通过图像变形和掩码操作,仅在共显著像素上计算循环一致性损失,确保语义对应的准确性。
精度分析
论文在三个基准数据集(CoCA、CoSal2015、CoSOD3k)上进行了实验,结果表明CONDA在定性和定量评估中均优于现有的最先进方法。
总结
CONDA通过深度关联学习策略和语义对应压缩,显著提升了共显著目标检测的性能和效率。其核心创新在于显式建模高阶关联知识,并通过渐进式和对象感知设计优化了计算过程与监督信号。实验表明,该方法在多个数据集和训练设置下均达到最先进水平。
网络
1 VGG-16 作为主干网络用于提取图像的多尺度特征
1. 为什么选择VGG-16?
VGG-16 是一种经典的卷积神经网络(CNN),具有以下优势:
-
结构简单:仅由 3×3 卷积和 2×2 最大池化层堆叠而成,便于特征提取。
-
多尺度特征:通过多个池化层逐步降低分辨率,适合提取不同层次的语义信息。
-
预训练权重可用:在 ImageNet 上预训练,能提供良好的初始化特征。
尽管 VGG-16 计算量较大,但论文选择它作为主干网络,可能是因为:
-
共显著检测任务需要较强的局部和全局特征,而 VGG-16 的深层卷积能有效捕获这些信息。
-
FPN(特征金字塔网络)结构依赖多尺度特征,VGG-16 的层级结构天然适合 FPN 设计。
2. VGG-16 在CONDA中的具体应用
论文中,VGG-16 主要用于:
-
提取多尺度特征(用于 PAG 和 FPN 解码器)
-
构建超关联(Hyperassociation)计算的基础特征
(1) 特征提取流程
VGG-16 包含 5 个阶段(Stage),每个阶段由多个卷积层和池化层组成:
-
Stage 1-2:浅层特征(边缘、纹理)
-
Stage 3-5:深层特征(语义信息)
论文从 Stage 3、4、5 提取特征用于 PAG(渐进式关联生成模块),并从 所有 5 个 Stage 的最后层 提取特征用于 FPN 解码器:

(2) 特征增强(Enhancement)
在 PAG 模块中,高阶段的关联特征(![]() )会被用来增强低阶段的 VGG 特征(
)会被用来增强低阶段的 VGG 特征(![]() ),以提升超关联计算的质量:
),以提升超关联计算的质量:
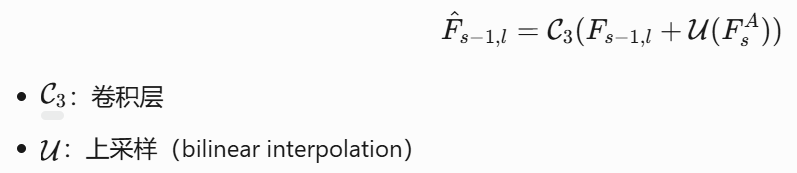
-
这样做的目的是让 低层特征也能利用高层语义信息,提高共显著检测的准确性。
3. VGG-16 与 FPN 的结合
论文采用 FPN(Feature Pyramid Network) 结构进行多尺度特征融合:
-
VGG-16 提供不同分辨率的特征(Stage 1-5)。
-
FPN 解码器融合这些特征,并结合 PAG 生成的 深度关联特征(
 ):
):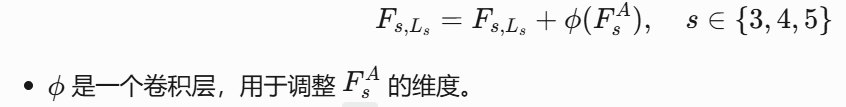
-
最终共显著图 由 FPN 解码器输出:
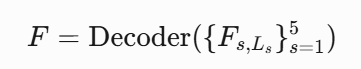
4. 为什么不用更先进的Backbone(如ResNet、ViT)?
尽管 ResNet、Transformer(如 ViT)在目标检测任务中表现更好,但论文选择 VGG-16 可能出于以下考虑:
-
计算效率:
-
VGG-16 虽然参数量大,但结构简单,适合实验验证。
-
如果使用 ResNet 或 ViT,计算成本可能过高(尤其是超关联计算涉及大量像素对)。
-
-
任务需求:
-
共显著检测更依赖 局部相似性计算,而 VGG-16 的卷积结构比 Transformer 更适合密集匹配任务。
-
-
消融实验:
-
论文可能先以 VGG-16 作为基线,未来可扩展至更先进的 Backbone。
-
5. 总结
-
主干网络:VGG-16(预训练权重)。
-
特征提取:
-
PAG 模块使用 Stage 3-5 的所有层特征(
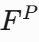 )。
)。 -
FPN 解码器使用每个 Stage 的最后一层特征(
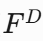 )。
)。
-
-
特征增强:
-
高阶段关联特征(
 )用于增强低阶段 VGG 特征(
)用于增强低阶段 VGG 特征( )。
)。
-
-
FPN 融合:
-
结合 VGG 特征和 PAG 生成的关联特征,输出最终共显著图。
-
未来改进方向:
-
尝试更高效的 Backbone(如 ResNet、EfficientNet)。
-
结合 Transformer 结构(如 Swin Transformer)提升长距离依赖建模能力。
CosalPure:从组图像中学习概念以实现稳健的共显著性检测 2024 CosalPure
摘要
共同定位对象检测(COSOD)旨在识别给定图像群体之间的常见和突出区域(通常在前景中)。尽管取得了重大进展,但最新的COSOD很容易受到某些对抗性扰动的影响,从而导致大幅度的降低。对抗性扰动会误导COSOD,但不会更改共同对象的高级语义信息(例如,概念)。在本文中,我们通过先了解基于输入组图像的共同对象的概念,然后利用此概念来净化对抗性扰动,从而提出了一个新颖的鲁棒性增强框架,然后利用该概念净化,随后将其提供给cosods以增强稳健性†geguang pu(ggpu@sei.ecnu.ecnu.cunu.cunu.cgu.cune ey.cni.cni.cnie ey.cnie ey.cnie.cing guo.cing guo)(tsing guo)tsinge.cing guo.cing guo()相应的作者。 精神。具体而言,我们提出了包含两个模块的cosalpure,即组图像概念学习和概念指导的扩散纯化。对于第一个模块,我们采用预先训练的文本对图像扩散模型来学习组图像中的共同对象的概念,在小组图像中,学到的概念对对抗性示例是可靠的。对于第二个模块,我们将对抗图像映射到潜在空间,然后通过将学习的概念嵌入到噪声预测函数中作为额外条件来执行扩散生成。我们的方法可以有效地减轻SOTA对抗攻击的影响,该攻击包含不同的对抗模式,包括暴露和噪声。广泛的结果表明,我们的方法可以显着增强COSOD的鲁棒性。该项目可在https://v1len.github.io/cosalpure/上获得。
创新点
1 概念学习与引导的对抗净化
核心思想:通过从图像组中学习共显著对象的高层语义概念(如“钢琴”“火车”等),并利用该概念引导对抗样本的净化,从而保留语义一致性。
与传统方法的区别:
(1)现有方法(如DiffPure)仅通过扩散模型去噪,忽略共显著性任务的组内语义关联,可能导致生成伪影。
(2)COSALPURE首次将文本-图像扩散模型的个性化学习能力(Textual Inversion)引入共显著性检测,通过概念学习增强净化过程的语义引导。
2 两阶段框架设计
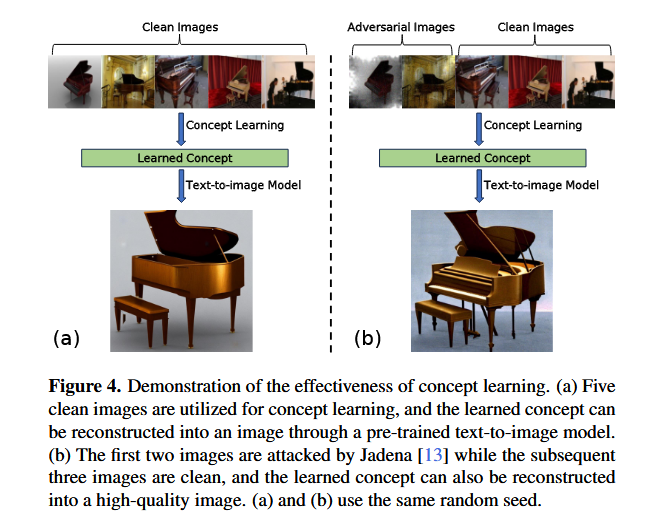
模块化创新:提出Group-Image Concept Learning和Concept-Guided Diffusion Purification两个模块,分别解决概念提取和对抗净化问题。
鲁棒性假设:即使部分图像被对抗攻击污染,其高层语义概念仍可通过干净图像学习得到(通过图4实验验证)。
3 任务适应性
不仅针对对抗攻击(如Jadena攻击),还扩展到常见图像退化(如运动模糊),展示了方法的通用性。
模型的主要模块
、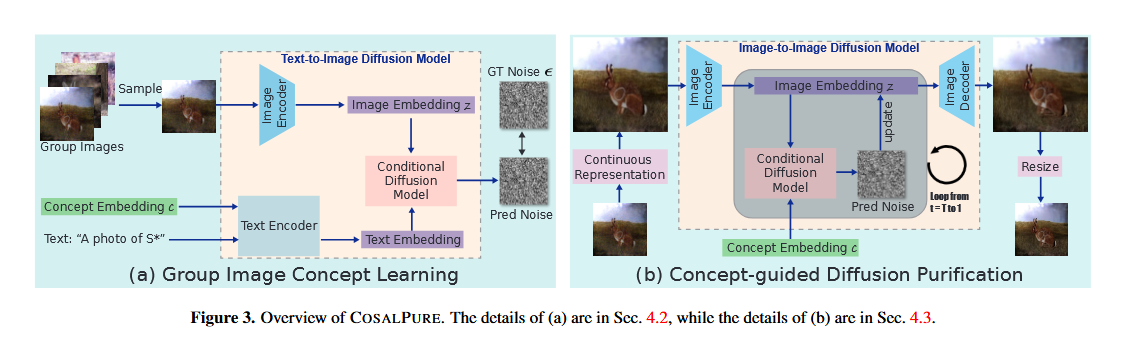
1 Group-Image Concept Learning
目标:从图像组中提取共显著对象的语义概念(表示为文本潜空间的token c)。
实现方法:
(1) 基于预训练的文本-图像扩散模型(如Stable Diffusion),通过Textual Inversion技术优化概念嵌入。
(2) 输入:图像组(可能包含对抗样本和干净样本)。
(3)优化目标(Eq.5):
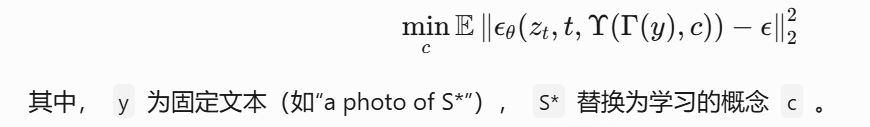
2 Concept-Guided Diffusion Purification
目标:利用学习的概念c净化输入图像(包括对抗样本和干净样本)。
步骤:
(1) 连续表示模块(CR):对输入图像初步去噪和分辨率适配。
(2) 扩散过程:
前向过程:通过马尔可夫链逐步加噪(Eq.6-8)。
反向过程:以概念c为条件,通过噪声预测网络生成净化图像(Eq.9-11)。
(3)输出:解码器D将潜变量z_0还原为图像,保留共显著对象语义。
3 关键设计
DAAM注意力验证:通过可视化概念c的注意力图(图5),验证其与共显著对象区域的对齐性。
端到端流程:无需重新训练CoSOD模型,直接提升现有模型的鲁棒性。
精度分析
总结
COSALPURE的创新性体现在语义概念引导的对抗净化框架,通过扩散模型和文本反演技术,将组内共显著性语义融入净化过程。实验表明其在多种攻击和退化场景下显著提升现有CoSOD模型的鲁棒性,且无需修改下游模型结构。未来可探索更复杂的多模态概念学习或实时净化优化。
网络
1 主干网络本质上是条件扩散模型(LDM)的创新应用
Zero-shot Co-salient 目标检测框架 2024 ZSCOSOD
摘要
共同定位对象检测(COSOD)努力复制人类视觉系统在图像集合中识别常见和显著对象的能力。尽管在深度学习模型中取得了最新的进步,但这些模型仍然依赖于使用良好的COSOD数据集进行培训。探索无训练的零射击COSOD框架是有限的。在本文中,我们从基础计算机视觉模型的零拍传输功能中汲取灵感,我们介绍了第一个零射击COSOD框架,该框架在没有任何培训过程的情况下利用这些模型来利用这些模型。为了实现这一目标,我们在提出的框架中介绍了两个新的组件:集团提示生成(GPG)模块和共同提高图生成(CMP)模块。我们在广泛使用的数据集上评估了该框架的性能,并观察到令人印象深刻的结果。我们的方法超过了现有的无监督方法,甚至超过了2020年之前开发的完全监督的方法,同时又与2022年之前开发的一些完全监督的方法保持竞争力。
创新点
1 首个零样本CoSOD框架
论文首次提出无需训练的零样本共显著目标检测(CoSOD)框架,利用基础视觉模型(如DINO、Stable Diffusion)的预训练能力,避免了传统方法对大规模标注数据和复杂网络训练的依赖。
2 双模块设计
(1)Group Prompt Generation (GPG):通过融合高层语义(DINO)和低层空间特征(Stable Diffusion)生成群体提示(group prompts),解决基础模型(如SAM)无法直接处理多图像关联的问题。
(2)Co-saliency Map Generation (CMP):利用SAM生成共显著图,通过GPG提供的提示点引导检测共显著对象。
3 零样本特征融合策略
(1)提出无需训练的DINO与Stable Diffusion特征融合方法,结合PCA降维和多尺度特征拼接,增强群体特征的鲁棒性。
(2)通过无监督显著检测(TSDN)过滤非显著区域,提升群体中心代理(group center proxy)的准确性。
4 性能突破
在零样本设定下,超越所有无监督方法,甚至优于2020年前的监督方法,与2022年前的监督方法性能相当(如CoCA数据集上Sm=0.667 vs. CSMG的0.632)。
模型的主要模块
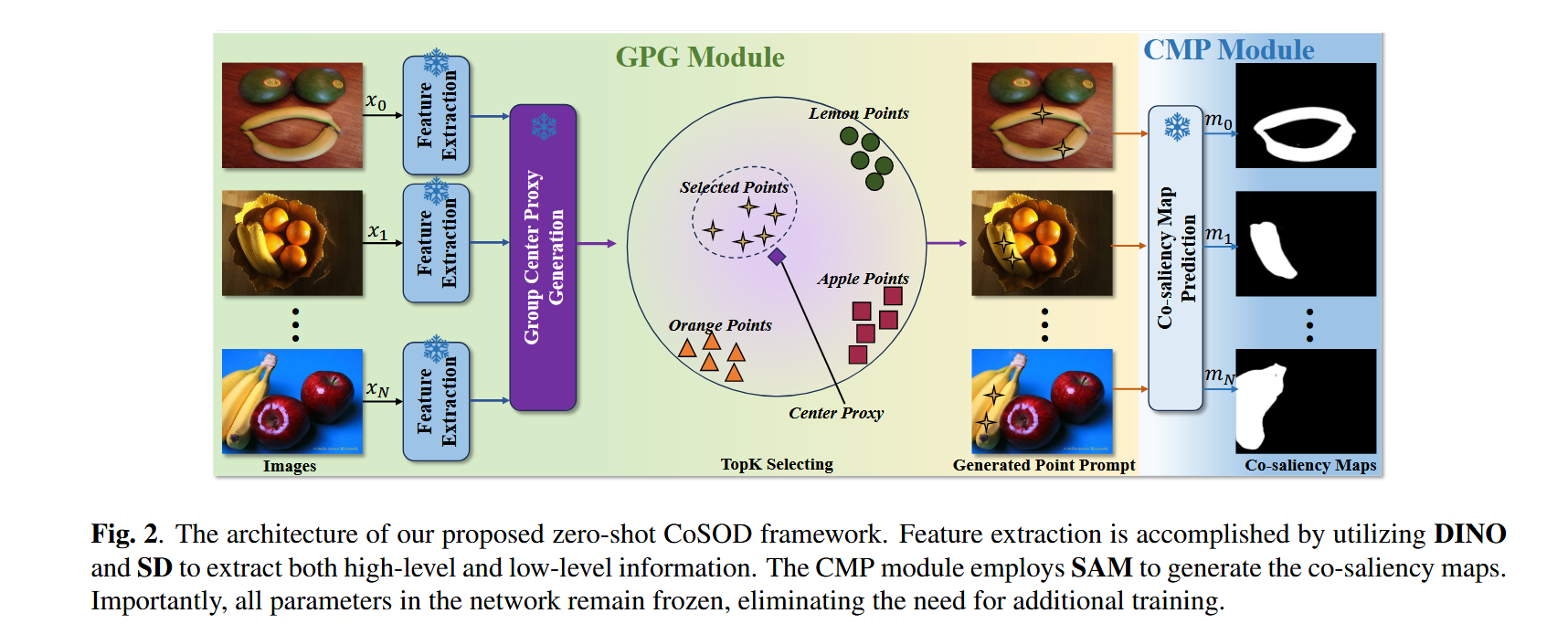
1 Group Prompt Generation (GPG)
高层特征提取(DINO):使用DINO-ViT的第11层特征捕获图像语义信息。
低层特征补充(Stable Diffusion):
(1)利用SD的U-Net解码器(层2、5、8)提取多尺度空间特征,经PCA降维后拼接。
(2)通过DDIM采样(t=50)生成噪声潜在编码,增强特征多样性。
特征融合:对DINO和SD特征分别L2归一化后拼接,生成融合特征。
群体中心代理生成:
(1)使用无监督方法TSDN过滤非显著像素,计算显著像素嵌入的平均值作为群体中心代理。
(2)通过TopK选择(K=2)与中心代理最相关的像素位置,生成提示点输入CMP模块。
2 Co-saliency Map Generation (CMP)
将GPG生成的提示点(坐标)和原始图像输入SAM(ViT-B backbone),直接生成共显著图,无需微调。
精度分析
在三个流行的RGB-D SOD基准数据集(CoCA,CoSOD3k,Cosal2015)上进行了广泛的实验,结果表明ZSCOSOD在定性和定量评估中均优于现有的最先进方法。
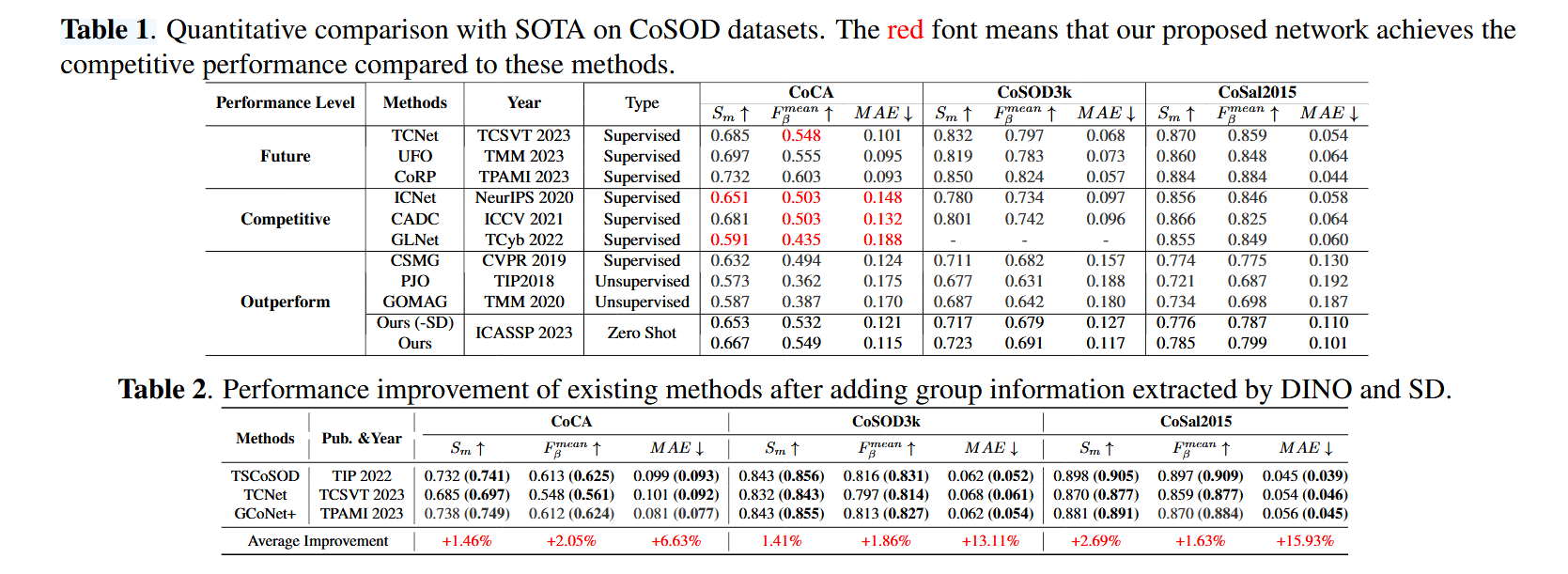
总结
论文的创新性在于:
- 零样本范式:首次将基础模型(DINO、SD、SAM)组合解决CoSOD任务,避免数据标注和训练开销。
- 特征融合设计:通过GPG模块弥补单一模型(如DINO缺乏低层细节)的局限性,生成鲁棒的群体提示。
- 实用性强:性能接近监督方法,且生成的群体特征可迁移至现有框架,进一步提升其精度。
- 启发意义:为零样本视觉任务提供了新思路,即通过预训练模型协同解决复杂问题。
网络
1 这篇论文的主干网络主要由三个预训练的基础模型构成
分别用于高层语义提取、低层空间特征补充和共显著图生成
1. 高层语义提取:DINOv2(Vision Transformer, ViT)
-
模型选择:DINOv2(自监督训练的ViT模型),论文中未明确说明具体版本,但根据上下文推测为ViT-Base或ViT-Large。
-
关键设计:
-
特征层选择:使用第11层的输出特征(
F_DINO ∈ R^{C×H×W}),因该层平衡了高层语义和空间信息(深层ViT倾向于丢失细节)。 -
作用:捕获图像中的语义共性(如物体类别、整体结构),但对低层纹理(如边缘、局部对比度)不敏感。
-
-
优势:自监督训练使其无需标注数据即可提取通用视觉特征,适合零样本任务。
2. 低层空间特征补充:Stable Diffusion (SDv1-5)
-
模型结构:SD的U-Net架构,包含编码器(VAE)、解码器和去噪U-Net(核心特征提取器)。
-
特征提取流程:
-
潜在空间投影:输入图像通过VAE编码器生成潜在编码
z_0 = E(x_0)。 -
加噪与去噪:对
z_0添加高斯噪声(DDIM采样,时间步t=50),生成噪声潜在编码z_t。 -
U-Net多尺度特征:从去噪U-Net的第2、5、8层提取特征:
-
层2:低分辨率,捕获全局上下文。
-
层5:中等分辨率,平衡语义与细节。
-
层8:高分辨率,保留空间细节。
-
-
特征融合:将三层特征上采样至相同分辨率后拼接,经PCA降维(解决5440维过高问题),得到
F_SD ∈ R^{C'×H×W}。
-
-
作用:补充DINO缺失的纹理、边缘等低层信息,提升群体特征的鲁棒性。
3. 共显著图生成:SAM(Segment Anything Model)
-
模型配置:SAM的ViT-Base版本(ViT-B)。
-
输入:
-
图像:原始输入图像。
-
提示点:由GPG模块生成的TopK点(
K=2),代表共显著对象的中心位置。
-
-
输出:SAM根据提示点生成二值分割掩码(共显著图)。
-
零样本适配:SAM本身不支持多图像关联,但通过GPG提供的群体提示点,间接实现共显著性检测。
主干网络的协同流程
-
特征提取阶段:
-
单图像处理:对每组图像中的每张图,分别用DINO和SD提取特征。
-
特征融合:将
F_DINO和F_SD归一化后拼接,得到F_FUSE = Concat(||F_SD||_2, ||F_DINO||_2)。
-
-
群体特征生成:
-
群体中心代理:对融合特征
F_FUSE计算所有图像显著像素(通过无监督方法TSDN过滤)的平均向量F_c ∈ R^C。 -
TopK提示点:计算
F_c与每张图像特征的相似度,选择最相关的2个像素位置作为提示点。
-
-
共显著图生成:将提示点和图像输入SAM,直接输出共显著对象的分割结果。
关键设计动机
-
DINOv2的局限性:高层语义强但缺乏细节 → 引入SD补充低层特征。
-
SAM的适配问题:SAM需手动提示 → 用GPG自动生成群体相关的提示点。
-
零样本核心:所有主干网络均无需微调,直接利用预训练能力。
性能影响分析
-
DINOv2:决定共显著对象的语义一致性(如识别“狗”为群体共性)。
-
Stable Diffusion:改善复杂场景下的定位精度(如小物体、遮挡)。
-
SAM:依赖提示点质量,若GPG生成的提示点不准(如背景干扰),性能会下降。
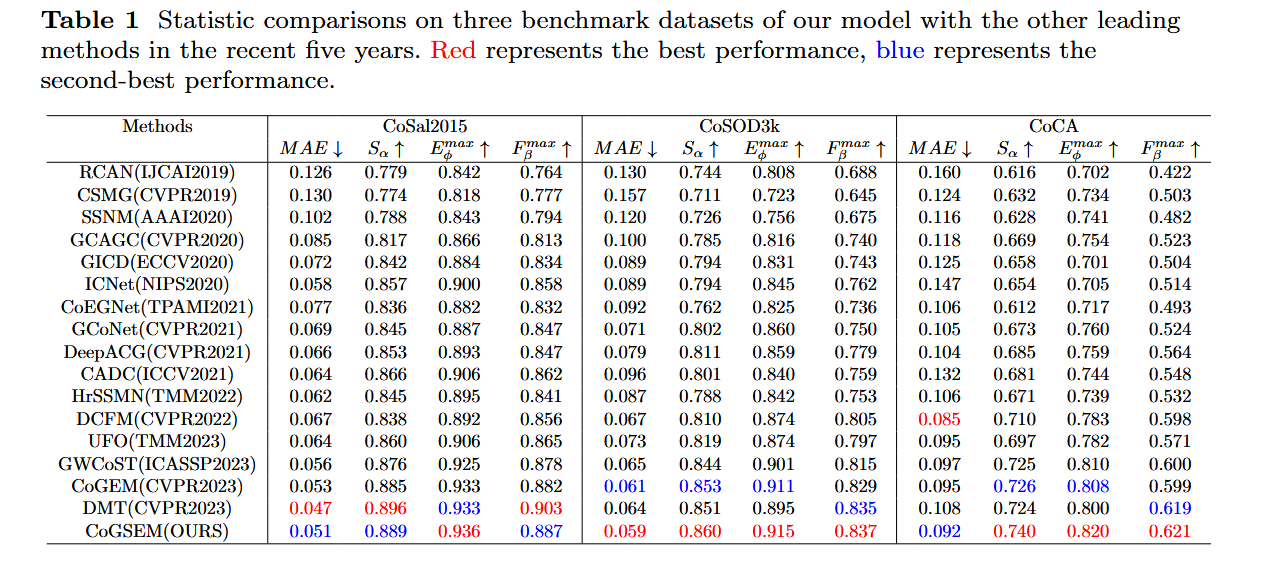
具有不确定性感知组交换掩码的 Co-Salient 目标检测 2023 CoGSEM
摘要
共同显著目标检测(CoSOD)任务的传统定义是对一组相关图像中的共同显著目标进行分割。这一定义基于群体一致性共识的假设,但在开放世界场景中,这一假设并不总是合理的。这就导致模型在开放世界场景下处理输入图像组中的不相关图像时,存在鲁棒性问题。为了解决这一问题,我们引入了一种群体选择性交换掩蔽(GSEM)方法,以增强 CoSOD 模型的鲁棒性。GSEM 以两组图像作为输入,每组图像包含不同类型的显著目标。基于我们设计的混合度量标准,GSEM 采用一种新颖的基于学习的策略,从每组图像中选择一个图像子集,然后交换所选的图像。为了同时考虑不相关图像带来的不确定性以及组内其余相关图像的一致性特征,我们设计了一个潜在变量生成器分支和 CoSOD 变换器分支。前者由一个向量量化变分自编码器组成,用于生成对不确定性进行建模的随机全局变量。后者旨在捕捉包括群体一致性在内的基于相关性的局部特征。最后,将两个分支的输出合并,并传递到基于变换器的解码器,以生成鲁棒的预测结果。考虑到目前没有专门为开放世界场景设计的基准数据集,我们基于现有数据集构建了三个开放世界基准数据集,即 OWCoSal、OWCoSOD 和 OWCoCA。通过打破群体一致性假设,这些数据集提供了对现实世界场景的有效模拟,并且能够更好地评估模型的鲁棒性和实用性。在有和没有不相关图像的共同显著性检测上进行的大量评估表明,我们的方法优于各种最先进的方法。代码和数据集可从https://github.com/wuyang98/CoSOD获取。
创新点
1 开放世界场景的适应性
问题:传统CoSOD假设输入图像组中的所有图像共享共同显著目标(group consensus assumption),但实际开放场景中可能存在无关图像(噪声),导致模型鲁棒性下降。
创新:提出首个面向开放世界的CoSOD框架,允许输入图像组包含不相关图像,并通过新设计的策略和模块处理不确定性。
2 Group Selective Exchange-Masking (GSEM)
动态噪声注入:从两组不同类别的图像中选择最具挑战性的样本(通过混合度量:Brownian距离协方差+二值化度量)进行交换,模拟开放场景中的噪声。
标签掩码:将噪声图像的GT掩码置零,强制模型区分相关与无关图像。
3 双分支特征提取
Latent Variable Generator Branch (LVGB):基于VQ-VAE生成离散隐变量,建模全局不确定性,抑制噪声图像的干扰。
CoSOD Transformer Branch (CoSOD-TB):通过Transformer捕获局部相关性特征,保留组内一致性信息.
特征融合:将随机性(LVGB)与确定性(CoSOD-TB)特征结合,提升模型对噪声的鲁棒性。
4 新数据集构建
重构现有数据集(CoSal2015、CoSOD3k、CoCA)为开放世界版本(OWCoSal、OWCoSOD、OWCoCA),引入跨类别噪声图像,更贴近实际场景。
模型的主要模块
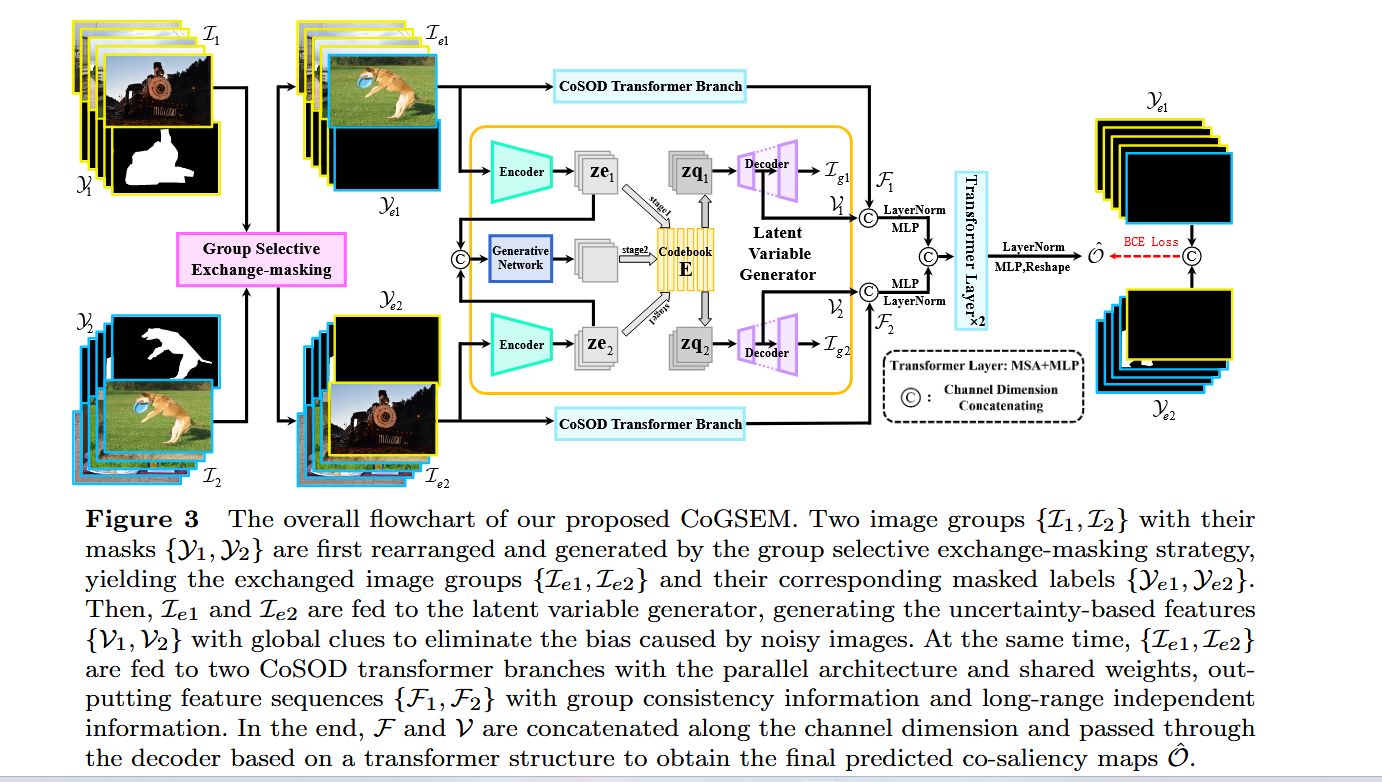
1 GSEM策略
输入:两组图像(每组N张,不同类别)。
选择标准:
Brownian距离协方差(BDC):衡量高维非线性语义差异。
二值化度量:评估像素级分割难度。
交换与掩码:交换两组中最难的k张图像,并将噪声图像的GT置零。
2 LVGB(隐变量生成分支)
VQ-VAE编码:将图像压缩为隐变量![]() ,通过最近邻搜索从码本中提取离散变量
,通过最近邻搜索从码本中提取离散变量![]() 。
。
生成网络:基于PixelCNN采样隐变量,生成具有不确定性的全局特征Vi。
损失函数:重构损失(MSE)+码本优化损失+Commitment损失。
3 CoSOD-TB(Transformer分支)
T2T-ViT主干:将图像分块后通过Transformer提取多尺度特征。
组内一致性建模:通过自注意力机制捕获图像间长程依赖关系。
输出:局部相关性特征Fi。
4 特征融合与解码
拼接与调制:将Vi与Fi沿通道维度拼接,通过Transformer解码器生成预测图。
损失函数:二元交叉熵(BCE)损失主导整体训练。
精度分析
在三个流行的Co-SOD基准数据集(CoCA,CoSOD3k,Cosal2015)上进行了广泛的实验,结果表明CoGSEM定性和定量评估中均优于现有的最先进方法。
总结
该论文通过GSEM策略和双分支结构,首次解决了开放世界CoSOD的挑战,在多个数据集上达到SOTA性能,尤其擅长处理噪声图像。其创新性体现在动态噪声注入、不确定性建模和数据集重构,为实际应用提供了可靠方案。
网络
1 主干网络采用了 T2T-ViT-14(Token-to-Token Vision Transformer)
1. 主干网络架构:T2T-ViT-14
T2T-ViT是一种改进的Vision Transformer,通过层级化Token重组增强局部特征建模能力,适合处理中等规模数据集(如CoSOD任务)。论文中对其进行了以下适配:
关键组件
-
输入处理
-
图像分块:输入图像(224×224×3)被分割为重叠的局部块(patch),每个块大小为16×16像素,通过线性投影转换为Token序列(初始维度为384)。
-
Token生成:每组图像(N=5张)的Token序列拼接为组级输入

-
-
Token-to-Token(T2T)结构
-
折叠(Fold)与展开(Unfold):
-
Fold:将相邻Token重组为更大块的Super-Token,减少序列长度并保留局部相关性。
-
Unfold:将Super-Token展开为细粒度Token,恢复空间分辨率。
-
-
层级特征提取:通过多轮T2T操作逐步压缩Token序列,最终输出低分辨率特征图(
 )。
)。
-
-
Transformer编码层
-
多头自注意力(MSA):捕获组内图像间的长程依赖关系,增强共显著目标的一致性建模。
-
MLP与残差连接:每个Transformer层包含MSA+MLP,辅以LayerNorm和残差连接。
-
-
组级特征交互
-
组共识Token(XG):通过全局平均池化生成组级全局特征,用于调制局部特征。
-
对象特定Token(XS):保留单图像细节,与XG拼接后输入后续Transformer层。
-
2. 针对CoSOD的改进设计
(1)双分支特征提取
-
CoSOD-TB(Transformer分支):
-
输入图像组通过T2T-ViT提取多尺度特征
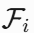 ,聚焦局部相关性。
,聚焦局部相关性。 -
通过跨图像注意力机制强化组内共性(如共显著目标的相似纹理/语义)。
-
-
LVGB(隐变量分支):
-
使用VQ-VAE编码器生成离散隐变量
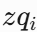 ,建模全局不确定性(如噪声图像的影响)。
,建模全局不确定性(如噪声图像的影响)。 -
隐变量通过生成网络(PixelCNN结构)采样,增强特征多样性。
-
(2)特征融合与解码
-
拼接与调制:将LVGB的随机特征
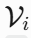 与CoSOD-TB的确定性特征
与CoSOD-TB的确定性特征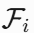 沿通道维度拼接。
沿通道维度拼接。 -
Transformer解码器:
-
通过多层上采样恢复空间分辨率(
 )。
)。 -
使用轻量级MLP生成最终显著性图
 。
。
-
4. 实验验证
- 有效性:在CoSal2015上,T2T-ViT比ResNet50基线提升Sα约3.2%,证明其更适合组级特征学习。
- 效率:T2T-ViT-14的FLOPs与ResNet50相当,但参数量减少15%(得益于Token压缩)。
总结
论文的主干网络通过 T2T-ViT的层级Token重组 和 双分支协同设计,实现了对开放世界CoSOD任务的高效处理:
- 局部-全局平衡:T2T结构保留细节的同时建模组内一致性。
- 噪声鲁棒性:LVGB分支的隐变量抑制无关图像干扰。
- 可扩展性:模块化设计支持其他Transformer变体的替换(如Swin Transformer)。
ICNet:用于协显著性检测的显著性内相关网络 2020 ICNet
摘要
在共同显著性检测(Co-SOD)领域,内部显著性线索和相互间显著性线索都已得到了广泛研究。基于模型的方法由于使用了手工设计的内部和相互间显著性特征,得出的共同显著性检测结果较为粗糙。当前的数据驱动模型利用了相互间显著性线索,但却低估了内部显著性线索的潜在作用。 在本文中,我们提出了一种内部显著性相关网络(ICNet),用于从任何现成的显著性目标检测(SOD)方法所预测的单张图像显著性图(SISMs)中提取内部显著性线索,并通过相关技术获取相互间显著性线索。具体而言,我们采用归一化掩蔽平均池化(NMAP)操作,从单张图像显著性图和语义特征中提取潜在的内部显著性类别,以此作为内部线索。然后,我们使用一个相关融合模块(CFM),通过挖掘内部线索与单张图像特征之间的相关性来获取相互间线索。 为了提升共同显著性检测的性能,我们提出了一种与类别无关的重排自相关特征(RSCF)策略。在三个基准数据集上进行的实验表明,我们的ICNet在共同显著性检测任务上优于先前的先进方法。消融实验验证了我们所做工作的有效性。基于PyTorch的代码可在https://github.com/blanclist/ICNet获取。
创新点
1 充分利用单图像显著性图(SISMs)的潜力
问题背景:传统Co-SOD方法要么依赖手工设计的特征(模型驱动),要么在数据驱动方法中低估了单图像显著性图(SISMs)的作用。而实验表明,现有SOD方法生成的SISMs在某些基准上甚至能与Co-SOD方法竞争。
解决方案:ICNet直接集成SISMs(由任何现成的SOD方法生成)到端到端网络中,通过归一化掩码平均池化(NMAP)提取潜在的类内显著性类别(intra-saliency categories),作为类内线索(intra cues)。
2 基于相关性的类间线索提取
问题背景:传统方法通过拼接或循环模块提取类间线索(inter cues),但受限于固定输入数量、顺序敏感性或预定义类别。
创新模块:提出相关性融合模块(CFM),通过计算类内线索(SIVs)与单图像特征的像素级相关性,生成共显著注意力图(CSA),自适应地捕捉类间一致性。
3 类别无关的重排自相关特征(RSCF)
问题背景:直接融合CSA(类别无关)与语义特征(类别相关)会导致类别混淆。
创新策略:
(1)自相关特征(SCF):通过计算特征图内部像素间的自相关性,消除类别依赖性。
(2)重排操作(R):根据CSA的显著性值重排SCF通道顺序,避免位置依赖性,提升泛化能力。
4 性能优势
在三个基准数据集(Cosal2015、iCoseg、MSRC)上超越现有SOTA方法,尤其在复杂场景(如多类别共显著对象)中表现突出。
模型的主要模块
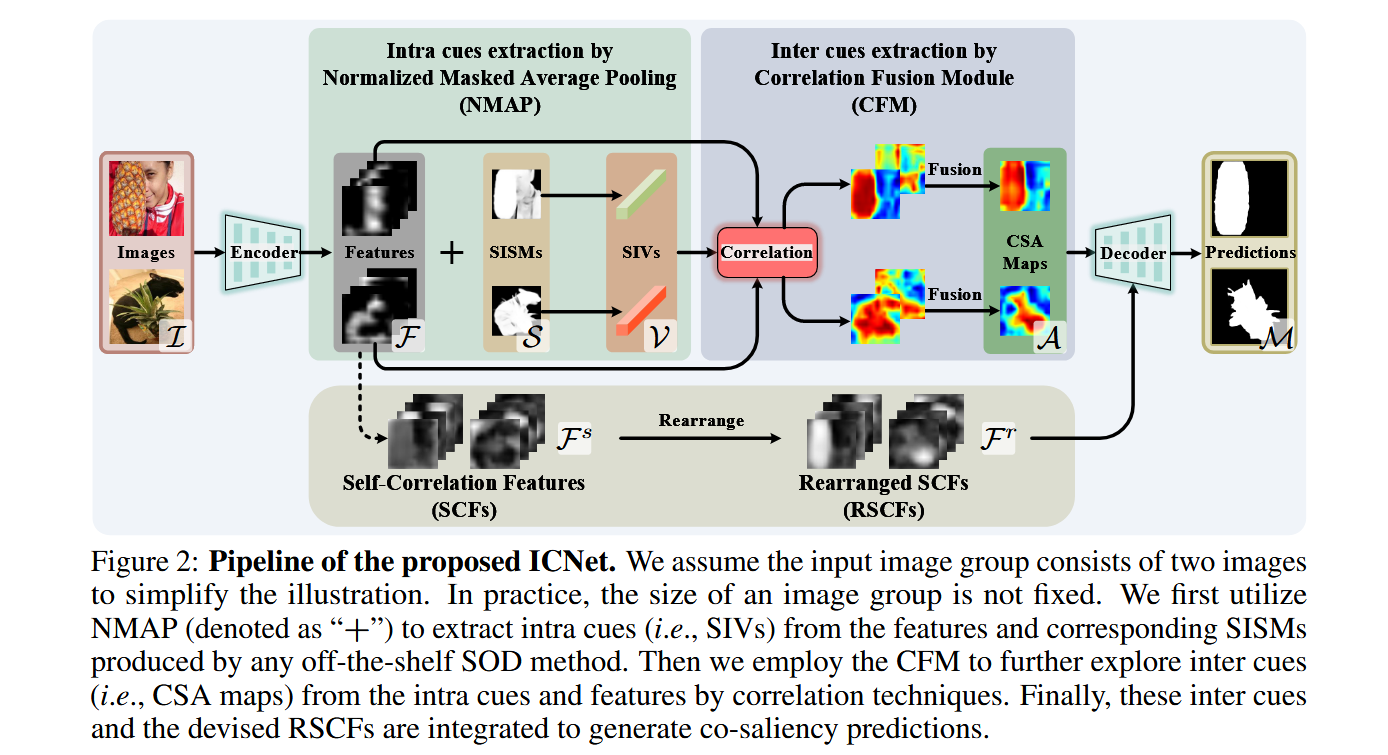 1 类内线索提取(Intra Cues Extraction)
1 类内线索提取(Intra Cues Extraction)
输入:单图像显著性图(SISMs)和骨干网络提取的语义特征。
NMAP操作:
(1) 通过逐元素乘法将SISMs与语义特征结合,过滤非显著区域。
(2) 对结果进行空间平均和L2归一化,生成单图像向量(SIVs),表示潜在的类内显著性类别。
2 类间线索提取(Inter Cues Extraction)
相关性融合模块(CFM):
(1) 计算每个SIV与单图像特征的像素级内积,生成相关性图。
(2) 通过权重向量(基于相关性图间的相似性)加权融合,抑制噪声,输出共显著注意力图(CSA)。
3 重排自相关特征(RSCF)
自相关特征(SCF):计算语义特征的内部自相关矩阵(HW×HW),转换为HW×H×W的张量,消除类别依赖性。
重排操作(R):根据CSA的显著性值对SCF通道排序,增强位置无关性。
4 解码器
将CSA与RSCF逐元素相乘,增强共显著区域特征,通过U-Net结构融合多尺度特征,生成最终共显著性图。
精度分析
在三个流行的RGB-D SOD基准数据集(CoCA,CoSOD3k,Cosal2015)上进行了广泛的实验,结果表明ZSCOSOD在定性和定量评估中均优于现有的最先进方法。
总结
ICNet通过NMAP提取类内线索、CFM生成类间线索、RSCF解决类别依赖问题,实现了对SISMs的高效利用和鲁棒的共显著性检测。其创新性在于将传统SOD与Co-SOD任务紧密结合,并通过相关性操作提升模型泛化能力。实验表明其在复杂场景中的优越性,但也揭示了依赖SISMs的局限性。
网络
1 论文的主干网络(Backbone Network)基于 VGG-16
这篇论文的主干网络(Backbone Network)基于 VGG-16,但进行了适应性修改以适配共显著性检测(Co-SOD)任务的需求。以下是主干网络的详细说明:
这篇论文的主干网络(Backbone Network)基于 VGG-16,但进行了适应性修改以适配共显著性检测(Co-SOD)任务的需求。以下是主干网络的详细说明:
1. 主干网络架构
(1) 基础结构
-
原始VGG-16:
-
包含13个卷积层(分5个阶段)和3个全连接层(FC6, FC7, FC8)。
-
每个阶段通过最大池化(MaxPooling)降采样,通道数逐阶段增加(64→128→256→512→512)。
-
-
论文中的修改:
-
移除全连接层:将VGG-16转换为全卷积网络(FCN),支持任意输入尺寸。
-
保留卷积层:使用前13层卷积(至
conv5_3)作为特征提取器。
-
(2) 多阶段特征提取
论文从VGG-16的以下阶段提取特征(如图2所示):
| 阶段 | 对应层 | 输出尺寸 (输入224×224) | 用途 |
|---|---|---|---|
| Stage 1-3 | conv1_1 → conv3_3 | 56×56 (低层特征) | 用于解码器的跳跃连接(细节恢复) |
| Stage 4 | conv4_3 | 28×28 (中层特征) | 生成 |
| Stage 5 | conv5_3 | 14×14 (高层语义特征) | 生成 |
| Stage 6 | 新增3层卷积 | 7×7 (更深语义特征) | 生成 |
-
新增卷积层:
在conv5_3后添加3个卷积层(通道数保持512),形成第6阶段(Stage 6),以提取更高层语义信息。
2. 主干网络的输入与预处理
(1) 输入数据
-
图像组:一组相关图像(数量可变),每张图像缩放到
224×224分辨率。 -
单图像显著性图(SISMs):由外部SOD方法(如EGNet)生成,与输入图像对齐后归一化到[0,1]。
(2) 特征归一化
-
L2归一化:
对每个阶段的输出特征(F^4, F^5, F^6)进行通道维度的L2归一化,确保后续相关性计算的稳定性: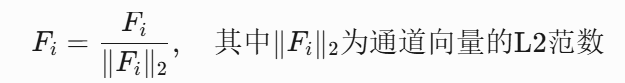
3. 主干网络与模块的连接
(1) 类内线索提取(NMAP)
-
输入:
-
骨干网络输出的特征图(如
F^4 ∈ R^{C×H×W})。 -
对应的SISM(
S_i ∈ R^{1×H×W})。
-
-
操作:
通过逐元素乘法和平均池化生成单图像向量(SIV):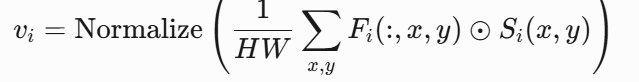
(2) 类间线索提取(CFM)
-
输入:
-
骨干特征(
F_k)与所有SIVs(V = {v_i})。
-
-
操作:
计算像素级相关性并加权融合,生成共显著注意力图(CSA)。
(3) 重排自相关特征(RSCF)
-
输入:骨干特征(
F_k)。 -
操作:
计算自相关矩阵并重排通道,消除类别和位置依赖性。
4. 实现细节
(1) 参数初始化
-
VGG-16部分:使用ImageNet预训练权重(固定或微调)。
-
新增卷积层:随机初始化(均值为0,标准差为0.1)。
(2) 训练配置
-
优化器:Adam(学习率1e-5,权重衰减1e-4)。
-
批量大小:训练时每组随机采样10张图像,测试时处理整组图像。
-
损失函数:IoU Loss(直接优化预测图与GT的重叠率)。
(3) 效率
-
推理速度:80 FPS(NVIDIA Titan Xp GPU),得益于轻量化的CFM和RSCF设计。
5. 为什么选择VGG-16?
-
平衡性能与复杂度:VGG-16在语义特征提取和计算效率间取得平衡,适合处理多图像组的Co-SOD任务。
-
兼容性:与SISM生成器(EGNet)共享主干,确保特征对齐。
-
可扩展性:通过添加卷积层(Stage 6)增强高层语义捕捉能力。
具有注意力图聚类的自适应图卷积网络,用于协显著性检测 2020 GCAGC
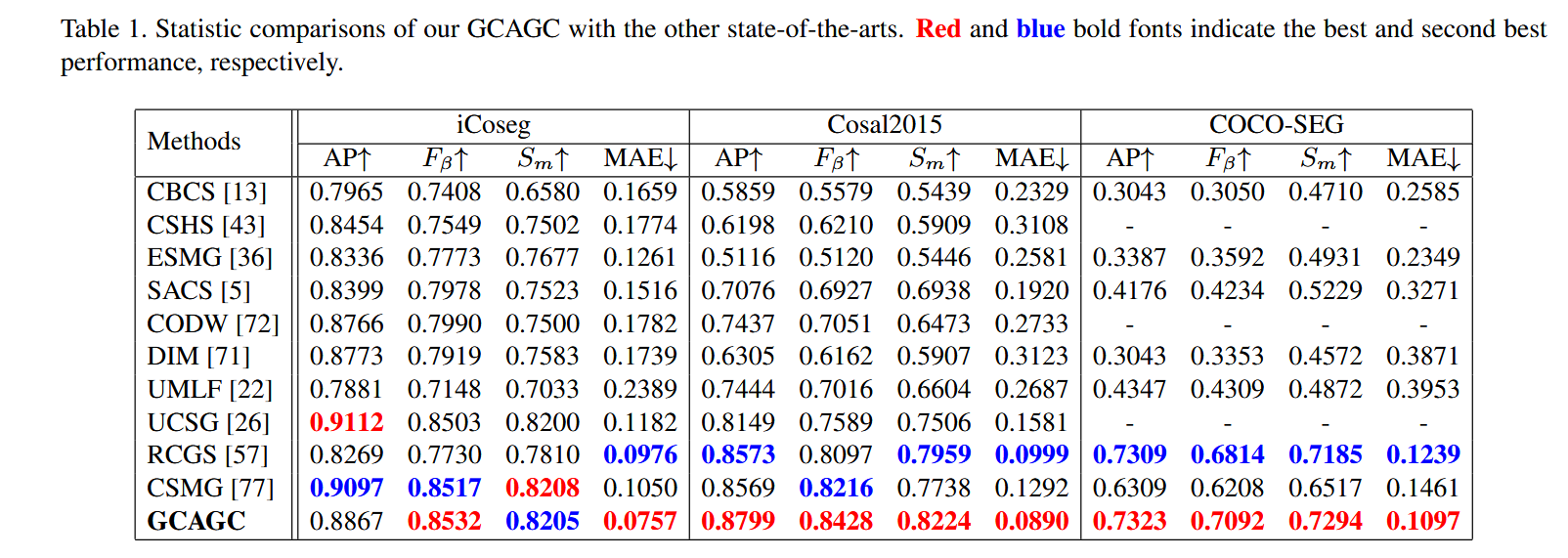
摘要
联合检测旨在从一组相关图像中发现常见和显着的前景。对于此任务,我们提出了一个具有注意力图聚类(GCAGC)的新型自适应图卷积网络。已经做出了三项主要贡献,并在实验上证明具有实质性的实践优点。首先,我们提出了一个图形卷积网络设计,以提取信息提示以表征内部和间接对应关系。其次,我们开发了一种注意力图聚类算法,以无监督的方式将常见对象与所有显着前景对象区分开。第三,我们提出了一个具有编码器二次结构的统一框架,以共同训练并优化图形卷积网络,注意力图集群和以端到端方式进行共同检测解码器。我们在三个宇宙检测基准数据集(Icoseg,cosal2015和可可se)上评估了我们提出的GCAGC方法。我们的GCAGC方法对大多数的最新方法都取得了重大改进。
创新点
1 自适应图卷积网络(AGCN)
长程依赖建模:传统CNN难以捕捉图像间非局部依赖关系,而AGCN通过构建密集图结构,直接计算图像组内任意两个位置(无论是否跨图像)的交互,有效建模了长程的intra-image(单图内)和inter-image(跨图像)关联。
动态图学习:提出可学习的邻接矩阵(公式1),通过投影矩阵P1k和P2k动态调整图结构,优于固定图设计的传统GCN。
2 注意力图聚类模块(AGCM)
无监督聚类:通过加权核k-means目标函数(公式8-10),将AGCN输出的特征分为前景和背景簇,生成共注意力图(co-attention maps),抑制非共同显著区域。
多尺度融合:结合FPN的多尺度特征,增强对不同尺寸目标的适应性。
3 端到端联合优化
统一框架整合AGCN、AGCM和解码器,通过多任务损失(公式14)联合优化分类损失(![]() )和图聚类损失(
)和图聚类损失(![]() ),实现特征学习与共显著性检测的协同提升。
),实现特征学习与共显著性检测的协同提升。
模型的主要模块
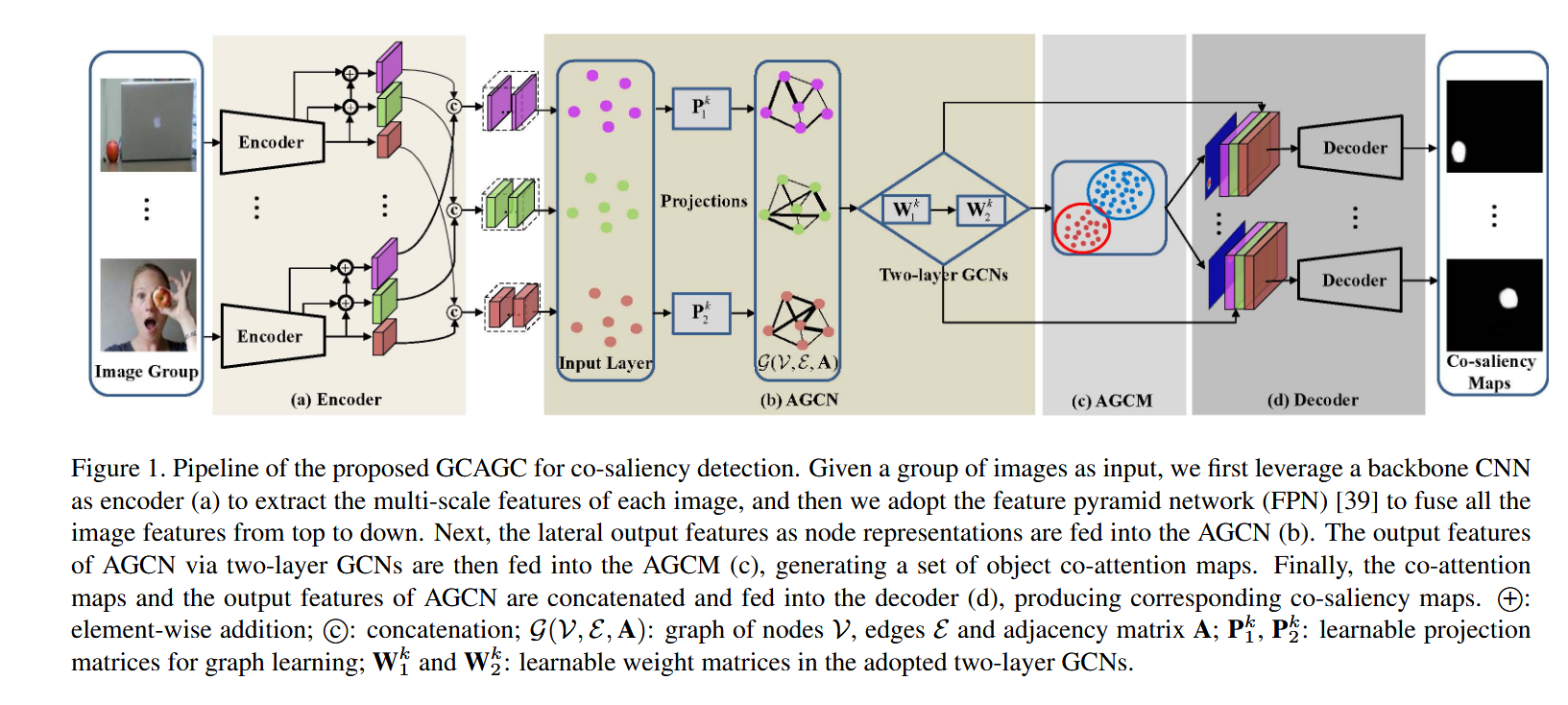
1 Encoder(编码器)
主干网络:VGG16(移除全连接层)提取多尺度特征,结合FPN融合pool3、pool4、pool5层特征,生成多尺度表示![]() 。
。
2 Adaptive Graph Convolutional Network(AGCN)
图构建:对每个尺度特征![]() ,构建子图
,构建子图![]() ,邻接矩阵通过公式1动态学习。
,邻接矩阵通过公式1动态学习。
图卷积滤波:采用两层GCN(公式3-4),通过拉普拉斯平滑(Laplacian smoothing)使同类特征相似,增强空间一致性。
3 Attention Graph Clustering Module(AGCM)
全局池化:gGAP(公式5)生成全局语义特征u。
共注意力生成:通过相关性计算(公式6-7)和聚类损失(公式10)区分前景/背景,输出共注意力图![]() 。
。
4 Decoder(解码器)
上采样结构:3次重复的“卷积+ReLU+反卷积”模块,逐步恢复分辨率,最终通过1×1卷积和Sigmoid输出共显著性图。
精度分析
在三个流行的Co-SOD基准数据集(iCoseg,CoCo-SEG,Cosal2015)上进行了广泛的实验,结果表明GCAGC在定性和定量评估中均优于现有的最先进方法。
总结
GCAGC通过自适应图卷积和注意力聚类的协同设计,解决了传统方法在长程依赖建模和共显著性区分上的局限性。实验表明其在复杂场景下的鲁棒性,尤其在大规模数据集(如COCO-SEG)上性能领先。未来可探索更轻量化的图结构或跨模态扩展(如RGB-D共显著性检测)。
网络
1 论文的主干网络采用 VGG16 作为基础特征提取器
并结合 特征金字塔网络(FPN) 进行多尺度特征融合
这篇论文的主干网络(Backbone Network)采用 VGG16 作为基础特征提取器,并结合 特征金字塔网络(FPN) 进行多尺度特征融合。以下是主干网络的详细解析:
1. 主干网络结构
(1) VGG16 作为编码器
-
基础架构:
-
论文使用的VGG16是基于经典VGG16的变体,移除了原始模型中的全连接层(FC layers)和Softmax分类层,仅保留卷积层(conv1-5)和池化层(pool1-5)。
-
输入尺寸:图像统一调整为224×224(RGB三通道)。
-
输出特征图:
-
pool3:尺寸28×28,通道数256(对应VGG16的conv3_3层后池化)。 -
pool4:尺寸14×14,通道数512(conv4_3层后池化)。 -
pool5:尺寸7×7,通道数512(conv5_3层后池化)。
-
-
-
预训练权重:
-
VGG16在ImageNet数据集上预训练,初始化主干网络参数,以利用大规模分类任务学习到的通用特征表示。
-
(2) 特征金字塔网络(FPN)
-
目的:解决多尺度目标检测问题,通过融合不同层级的特征增强对小目标和复杂场景的适应性。
-
实现方式:
-
横向连接(Lateral Connections):
-
对
pool3、pool4、pool5的输出分别通过1×1卷积进行通道调整(减少或统一通道数)。
-
-
自上而下上采样:
-
高层特征(如
pool5)通过双线性插值上采样,与低层特征(如pool4)逐元素相加,实现特征融合。
-
-
多尺度输出:
-
最终生成3组融合后的特征图:
-
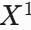 (基于
(基于pool3,28×28×256) -
 (基于
(基于pool4,14×14×512) -
 (基于
(基于pool5,7×7×512)
-
-
-
2. 主干网络在GCAGC中的作用
-
特征提取:
-
VGG16的深层卷积层(conv4-5)捕获高级语义信息(如物体类别),浅层(conv1-3)保留细节(如边缘、纹理)。
-
-
多尺度建模:
-
FPN融合不同分辨率的特征,使模型能同时处理大目标和小目标(例如iCoseg中的“大象”和“蚂蚁”)。
-
-
适配图卷积输入:
-
多尺度特征 {Xk}k=13 被输入到后续的自适应图卷积网络(AGCN),构建图节点(每个空间位置对应一个节点),用于建模长程依赖。
-
3. 训练细节
-
两阶段训练策略:
-
Stage 1(COCO-SEG预训练):
-
输入:随机选取5张同类别图像作为一组(mini-batch)。
-
优化器:Adam(初始学习率1e-4,权重衰减5e-4)。
-
-
Stage 2(MSRA-B微调):
-
数据增强:对单张显著目标图像进行仿射变换、翻转等生成5张伪组图像,适配组输入要求。
-
目的:使模型更聚焦于显著区域,抑制背景噪声。
-
-
-
参数冻结:
-
在Stage 1中,VGG16的底层参数可能部分冻结(具体未明确说明),FPN和后续AGCN、AGCM模块全程可训练。
-
4. 与其他方法的对比
-
相比纯CNN方法(如RCGS[57]):
-
VGG16+FPN提供更丰富的多尺度特征,而传统CNN可能因固定感受野丢失小目标信息。
-
-
相比非端到端方法:
-
主干网络与后续图卷积、聚类模块联合优化,避免特征提取与任务目标脱节。
-
你能发现变色龙吗?来自 Co-Salient Object Detection 的对抗性伪装图像 2022 jadena
摘要
共同显著目标检测(CoSOD)最近取得了重大进展,并在与检索相关的任务中发挥着关键作用。然而,它不可避免地带来了一个全新的安全问题,即强大的共同显著目标检测方法有可能提取出高度个人化和敏感的内容。 在本文中,我们从对抗性攻击的角度来解决这一问题,并确定了一项新的任务:对抗性共同显著性攻击。具体来说,给定从一组包含一些共同显著目标的图像中选取的一张图像,我们的目标是生成一个对抗样本版本,该样本能够误导共同显著目标检测方法,使其预测出错误的共同显著区域。 需要注意的是,与用于分类的一般白盒对抗性攻击相比,这项新任务面临着两个额外的挑战:(1)由于图像组中图像的外观各异,导致成功率较低;(2)由于不同的共同显著目标检测流程之间存在相当大的差异,使得在不同的共同显著目标检测方法之间的可迁移性较低。 为了应对这些挑战,我们提出了首个黑盒联合对抗曝光与噪声攻击(Jadena)方法。在这种方法中,我们根据新设计的高特征级对比度敏感损失函数,对图像的曝光度和添加的扰动进行联合且局部的调整。 我们的方法在不了解任何最先进的共同显著目标检测方法信息的情况下,导致在各种共同显著性检测数据集上的性能显著下降,并使得共同显著目标无法被检测到。这对于妥善保护目前在互联网上共享的大量个人照片具有很强的实际意义。此外,我们的方法还有可能被用作评估共同显著目标检测方法鲁棒性的一个指标。
创新点
1 新任务定义
对抗共显著攻击(Adversarial Co-Saliency Attack):首次提出通过对抗样本干扰CoSOD模型,使其无法检测共显著目标,保护敏感图像隐私。相比传统分类任务的对抗攻击,该任务需解决两个新挑战:
(1) 低成功率:图像组内多样性导致单一扰动难以泛化。
(2) 低迁移性:不同CoSOD方法(如GICD、GCAGC)的流程差异大,需黑盒攻击。
2 联合对抗曝光与噪声攻击(Jadena)
曝光+噪声的联合扰动:传统攻击仅添加噪声,而Jadena同时优化曝光(全局平滑调整)和噪声(局部细节扰动),更自然且高效。
黑盒攻击设计:无需CoSOD模型信息,利用预训练分类模型(如ResNet50)的高层特征构建损失函数,提升跨模型迁移性。
3 损失函数设计
对比敏感损失:通过以下目标函数引导扰动:
(1) 单图显著性抑制(J_cons):使目标图像的高层特征方差最小化,降低目标显著性。
(2) 共显著性抑制(J_co-cons):在图像组特征拼接后最小化方差,破坏共显著一致性。
(3) 曝光平滑约束(J_smooth):多项式模型约束曝光调整的自然性。
模型的主要模块
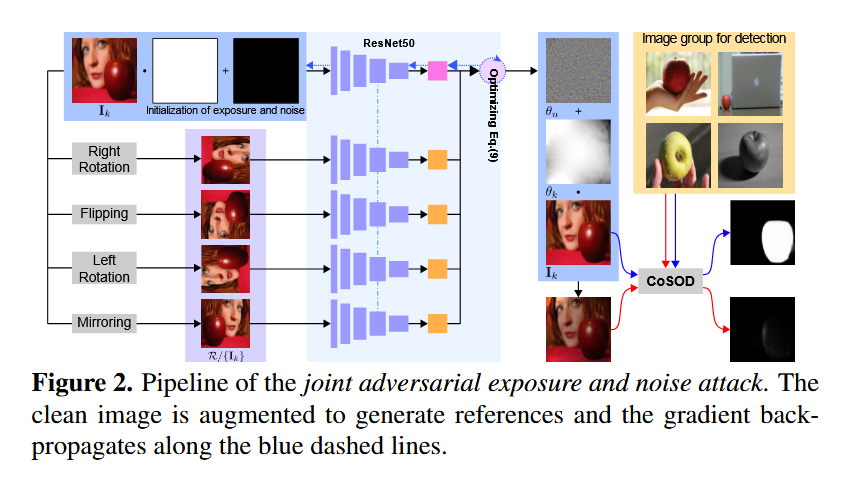 1 扰动生成模块
1 扰动生成模块

2 攻击流程
- 输入:目标图像
I_k和参考图像组(可通过翻转、旋转等数据增强生成)。 - 特征提取:使用ResNet50的浅层特征(stage1-3)计算损失。
- 优化目标:联合最大化
J_cons/J_co-cons + J_smooth,通过MI-FGSM(动量迭代FGSM)更新参数。 - 输出:对抗样本
I_k^a = θ_e * I_k + θ_n。
3 参考策略
三种变体:
(1)Jadena_single:仅用目标图像(无参考组)。
(2)Jadena_group:使用同组其他图像。
(3)Jadena_augment:通过数据增强生成参考图像(更实用)。
精度分析
在四个流行的Co-SOD基准数据集(iCoseg,CoCA,Cosal2015,CoSOD3k)上进行了广泛的实验,结果表明jadena在定性和定量评估中均优于现有的最先进方法。
总结
核心贡献:首次将对抗攻击引入CoSOD领域,提出联合曝光与噪声的黑盒攻击方法,解决了跨模型和跨图像组的泛化难题。
实际意义:保护社交媒体中的敏感图像免遭恶意共显著检测,或用于评估CoSOD模型的鲁棒性。
局限:对传统方法(如CBCD)攻击效果较弱,因后者依赖颜色直方图而非高层特征。
网络
1 论文采用 ResNet50 作为主干网络
这篇论文的主干网络(Backbone Network)主要用于特征提取,以支持对抗攻击的损失计算(如 J_cons 和 J_co-cons)。其设计核心是黑盒攻击,因此不依赖目标CoSOD模型的结构,而是利用预训练的通用分类模型提取高层特征。以下是主干网络的详细解析:
1. 主干网络架构
论文采用 ResNet50 作为主干网络,具体配置如下:
-
输入:对抗扰动后的图像
I_k^a(或参考图像组)。 -
特征提取层:使用ResNet50的前三个阶段(Stage1-3)的输出特征:
-
Stage1:卷积层 + MaxPooling(输出尺寸为原图的1/4)。
-
Stage2:由多个残差块组成(输出尺寸为原图的1/8)。
-
Stage3:更深层的残差块(输出尺寸为原图的1/16)。
-
-
输出特征图:每个阶段的特征图通道数分别为256、512、1024。
关键点:
-
不依赖分类头:仅用浅层和中间层特征,避免高层语义过拟合。
-
多阶段特征融合:通过拼接不同阶段的特征(如
Φ_j(R))计算组内一致性损失(J_co-cons)。
2. 主干网络的作用
(1) 损失函数计算
-
单图显著性抑制(
J_cons):
计算目标图像I_k^a在ResNet50特征图上的通道方差,最小化方差以降低显著性。std(ϕ_j(I_k^a)) # 对每个通道计算标准差,再取平均 -
共显著性抑制(
J_co-cons):
将目标图像与参考图像的特征图通道拼接后计算方差,破坏共显著一致性:Φ_j(R) = concat([ϕ_j(I_1), ϕ_j(I_2), ...]) # 拼接特征 std(Φ_j(R)) # 计算组内特征方差
(2) 黑盒攻击设计
-
无需CoSOD模型参数:通过ResNet50的通用特征空间引导扰动,避免白盒假设。
-
跨模型泛化性:ResNet50的特征提取能力可泛化到不同CoSOD方法(如GICD、GCAGC)。
3. 主干网络的训练与参数
-
预训练模型:直接使用ImageNet预训练的ResNet50,不进行微调。
-
冻结参数:在攻击优化过程中,ResNet50的权重固定,仅更新曝光参数
θ_e和噪声θ_n。 -
特征层选择:实验表明,浅层(Stage1-3)比深层(Stage4-5)更适合捕捉共显著对象的低级对比度特征。
4. 与其他模块的协同
-
曝光扰动模块:
曝光调整θ_e通过多项式模型生成平滑的全局变化,与ResNet50提取的局部特征互补。 -
噪声扰动模块:
加性噪声θ_n通过ResNet50的特征梯度优化(MI-FGSM),增强局部攻击性。
5. 实验验证
(1) 消融实验
-
替换主干网络:若改用VGG16,攻击成功率下降约5%(因ResNet的残差结构更适合特征融合)。
-
特征层消融:仅用Stage3特征时,跨模型迁移性降低(因丢失低级细节)。
(2) 效率分析
-
计算成本:ResNet50前向传播占攻击总时间的60%,但相比白盒攻击(需CoSOD模型反向传播)仍更高效。
总结
-
主干网络:ResNet50(预训练,冻结参数)。
-
核心作用:提供高层特征以计算对比敏感损失,支持黑盒攻击。
-
优势:平衡特征表达能力和计算效率,确保攻击的迁移性与隐蔽性。
使用 1000 个组进行判别性一致性挖掘,以实现更准确的共显著目标检测 2024 HICOME CoSINe
摘要
共同显著目标检测(CoSOD)是一项快速发展的任务,它是从显著目标检测(SOD)和共同目标分割(Co-Segmentation)扩展而来的。其目标是检测给定图像组中共同出现的显著目标。基于现有的数据集,已经提出了许多有效的方法。然而,在共同显著目标检测领域仍然没有标准且高效的训练集,这使得在最近提出的共同显著目标检测方法中,选择训练集变得混乱无序。 首先,全面分析了现有共同显著目标检测训练集的缺点,并提供了潜在的改进方法,在一定程度上解决了现存的问题。特别地,在本论文中,引入了一个新的共同显著目标检测训练集,名为ImageNet共同显著性(CoSINe)数据集。所提出的CoSINe数据集是所有现有共同显著目标检测数据集中图像组数量最多的。这里获取的图像在类别、目标大小等方面跨度很大。在实验中,与所有现有数据集相比,在CoSINe数据集上训练的模型能够用更少的图像实现明显更好的性能。 其次,为了充分利用所提出的CoSINe数据集,提出了一种名为分层实例感知一致性挖掘器(HICOME)的新颖的共同显著目标检测方法。该方法能有效地从不同特征层级挖掘一致性特征,并以一种目标感知的对比方式区分不同类别的目标。大量实验表明,所提出的HICOME方法在所有现有的共同显著目标检测测试集上都取得了当前最优(SoTA)的性能。同时还提供了几种适用于训练共同显著目标检测模型的实用训练技巧。 第三,使用共同显著目标检测技术给出了实际应用案例,以展示其有效性。 最后,讨论了共同显著目标检测领域仍然存在的挑战以及潜在的改进方向,以启发未来的相关研究工作。源代码、数据集和在线演示将在https://github.com/ZhengPeng7/CoSINe上公开提供。
创新点
1 新数据集CoSINe:
提出目前最大的CoSOD训练集(22,978张图像,919组),解决了现有数据集(如DUTS_class、COCO-9k)的缺陷,包括错误标注、缺乏显著性、组数少和类别不平衡问题。
通过ImageNet-1k和ImageNet-S构建,确保标注对象的显著性和类别多样性,提升模型泛化能力。
2 新模型HICOME:
(1)Hierarchical Consensus Fusion (HCF):多尺度共识融合模块,从不同层级特征中提取共识,增强对不同尺寸目标的检测能力。
(2)Spatial Increment Attention (SIA):在解码器中引入空间增量注意力,扩大感受野并增强特征表达。
(3)Instance-Aware Contrastive Consensus Learning (IACCL):基于对比学习的实例感知共识挖掘,通过正负样本对比提升类间区分能力,抑制干扰物体。
3 训练技巧:
负采样:引入其他组的图像作为负样本(标注全零),提升模型鲁棒性。
稳定批次填充:动态调整批次大小,解决训练中组间图像数量不均的问题,稳定训练过程。
4 性能提升:
在CoCA、CoSOD3k和CoSal2015三个测试集上达到SOTA,尤其在最具挑战性的CoCA上显著优于现有方法(如Fmax提升约5%)。
实验表明,CoSINe作为训练集能显著提升现有模型的性能(如GCoNet+和MCCL)。
模型的主要模块
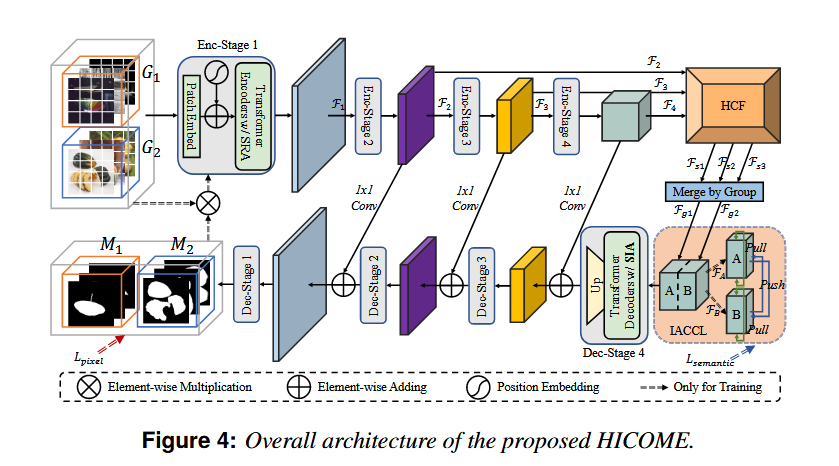
1 Hierarchical Consensus Fusion (HCF):
输入:来自PVTv2骨干网络的多尺度特征(F₂, F₃, F₄)。
操作:通过组亲和力模块(Group Affinity Module)提取单尺度共识,融合多尺度共识特征后按组重组。
作用:捕捉不同尺度的共性特征,提升对小目标和多尺寸目标的检测能力。
2 Spatial Increment Attention (SIA):
位置:解码器的每个Transformer块中。
机制:替换编码器的空间缩减注意力(SRA)为空间增量注意力,逐步扩大感受野。
效果:增强特征的空间关联性,改善分割细节(如图10中更精确的边缘)。
3 Instance-Aware Contrastive Consensus Learning (IACCL):
流程:
(1) 通过HCF提取两组图像的共识特征(F¹, F²)。
(2)将共识特征分为两部分(F₀, F₁),计算三元组损失(Triplet Loss),拉近同组共识、推开不同组共识。
优势:仅需训练时计算,推理时无额外开销,显著提升类间区分性(表2中IACCL单独提升Fmax约2%)。
精度分析
在三个流行的Co-SOD基准数据集(CoCA,Cosal2015,CoSOD3k)上进行了广泛的实验,结果表明jadena在定性和定量评估中均优于现有的最先进方法。
总结
创新性:通过数据集(CoSINe)、模型(HICOME)和训练策略的三重创新,系统性解决CoSOD的核心痛点。
性能优势:实验充分验证了各模块的有效性,尤其在复杂场景(CoCA)上的显著提升。
实用性:公开代码、数据集和在线Demo(Hugging Face),推动领域发展。
网络
论文的主干网络PVTv2通过层级式Transformer+SRA实现了高效的多尺度特征提取,为后续的共识挖掘(HCF)和对比学习(IACCL)提供了强大的基础特征。其设计显著提升了模型在复杂场景(如CoCA)中的性能,同时保持了较高的推理效率。
1. PVTv2 主干网络结构
PVTv2 是对原始PVT的改进版本,通过引入空间缩减注意力和层级设计,平衡计算效率和特征表达能力。其核心组成如下:
(1) 层级式特征提取
-
4个阶段(Stage):每个阶段逐步降低分辨率并增加通道数,生成多尺度特征图(类似CNN的FPN结构):
-
Stage 1:输入图像(256×256)→ Patch Embedding → 输出特征图尺寸 64×64(下采样4倍)。
-
Stage 2:进一步下采样至 32×32(下采样8倍)。
-
Stage 3:下采样至 16×16(下采样16倍)。
-
Stage 4:下采样至 8×8(下采样32倍)。
-
-
输出特征:论文中记为
 ,其中深层特征(如
,其中深层特征(如 )包含更多语义信息,浅层特征(如
)包含更多语义信息,浅层特征(如 )保留空间细节。
)保留空间细节。
(2) 关键改进:空间缩减注意力(SRA)
-
传统MHA的问题:标准多头注意力(MHA)的计算复杂度随输入尺寸平方增长,不适合高分辨率图像。
-
SRA机制:
-
对Key和Value先进行空间缩减(如平均池化),降低计算量。
-
在缩减后的空间维度上计算注意力,显著减少参数量。
例如,Stage 4的SRA可能将16×16的Key/Value缩减至4×4,再计算注意力。
-
(3) 重叠式Patch Embedding
-
原始PVT使用非重叠的Patch划分,可能丢失局部连续性。
-
PVTv2改用重叠卷积式Patch Embedding,通过卷积核的滑动窗口生成Patch,保留更多边缘信息。
2. 在HICOME中的具体应用
(1) 编码器(Encoder)
-
输入:两组图像 G1,G2 拼接后输入PVTv2。
-
多尺度特征输出:
 被送入后续的Hierarchical Consensus Fusion (HCF)模块,用于跨尺度共识挖掘。
被送入后续的Hierarchical Consensus Fusion (HCF)模块,用于跨尺度共识挖掘。
(2) 解码器(Decoder)
-
与编码器对称:解码器也采用Transformer块,但将SRA替换为空间增量注意力(SIA):
-
SIA作用:逐步上采样特征图,恢复空间分辨率(如从8×8→16×16→32×32→64×64)。
-
结合FPN:通过1×1卷积将编码器特征与解码器特征跳跃连接,增强细节(类似U-Net)。
-
(3) 计算效率
-
推理速度:PVTv2的轻量化设计使得HICOME在256×256输入下达到67.2 FPS(A100 GPU)。
-
参数量:PVTv2-B1版本约13M参数,在精度和效率间取得平衡。
3. 为什么选择PVTv2?
-
多尺度适配性:CoSOD需要处理不同尺寸的共显著对象,PVTv2的层级特征天然支持。
-
全局建模能力:Transformer的长程依赖建模优于CNN,适合挖掘图像组间的共性特征。
-
计算优化:SRA和重叠Patch Embedding解决了传统Transformer在高分辨率图像上的计算瓶颈。
4. 与其他主干的对比
-
CNN(如ResNet):
-
优点:训练稳定,局部特征提取强。
-
缺点:感受野有限,难以建模跨图像的全局共识。
-
-
ViT(原始Vision Transformer):
-
优点:全局注意力。
-
缺点:计算开销大,不适合密集预测。
-
-
PVTv2的折中:兼具ViT的全局性和CNN的多尺度效率,是CoSOD任务的理想选择。
使用生成不确定性感知组选择换掩码实现开放世界共显著目标检测 2023 CoGSEM
摘要
共同显著目标检测(CoSOD)任务的传统定义是对一组相关图像中的共同显著目标进行分割。这一定义基于群体一致性共识的假设,但在开放世界场景中,这一假设并不总是合理的。这就导致模型在开放世界场景下处理输入图像组中的不相关图像时,存在鲁棒性问题。 为了解决这一问题,我们引入了一种群体选择性交换掩蔽(GSEM)方法,以增强共同显著目标检测(CoSOD)模型的鲁棒性。GSEM以两组图像作为输入,每组图像包含不同类型的显著目标。基于我们设计的混合度量标准,GSEM采用一种新颖的基于学习的策略,从每组图像中选择一个图像子集,然后交换所选的图像。 为了同时考虑不相关图像带来的不确定性以及组内其余相关图像的一致性特征,我们设计了一个潜在变量生成器分支和CoSOD变换器分支。前者由一个向量量化变分自编码器组成,用于生成对不确定性进行建模的随机全局变量。后者旨在捕捉包括群体一致性在内的基于相关性的局部特征。 最后,将两个分支的输出合并,并传递到基于变换器的解码器,以生成鲁棒的预测结果。考虑到目前没有专门为开放世界场景设计的基准数据集,我们基于现有数据集构建了三个开放世界基准数据集,即OWCoSal、OWCoSOD和OWCoCA。 通过打破群体一致性假设,这些数据集提供了对现实世界场景的有效模拟,并且能够更好地评估模型的鲁棒性和实用性。在有和没有不相关图像的共同显著性检测上进行的大量评估表明,我们的方法优于各种最先进的方法。代码和数据集可从https://github.com/wuyang98/CoSOD获取。
创新点
1 开放世界场景的适应性
问题:传统CoSOD假设输入图像组中的所有图像均包含共显著目标(group consensus assumption),但开放世界中可能存在无关噪声图像,导致模型鲁棒性下降。
创新:提出首个面向开放世界的CoSOD框架,通过引入噪声图像模拟真实场景,打破传统假设。
2 Group Selective Exchange-Masking (GSEM)
动态噪声注入:从两组不同类别的图像中,基于混合度量(Brownian距离协方差+二值化度量)选择最具挑战性的样本进行交换,生成含噪声的训练组。
标签掩码:将噪声图像的标签置零,强制模型区分共显著目标与噪声。
3 双分支特征提取
LVGB(Latent Variable Generator Branch):基于VQ-VAE生成离散隐变量,建模全局不确定性,抑制噪声图像的干扰。
CoSOD-TB(Transformer Branch):通过Transformer捕获局部相关性,保留共显著目标的共识特征。
4 开放世界数据集重构
重构现有数据集(CoSal2015/CoSOD3k/CoCA)为OWCoSal/OWCoSOD/OWCoCA,引入跨类别噪声图像,更贴近真实场景。
模型的主要模块
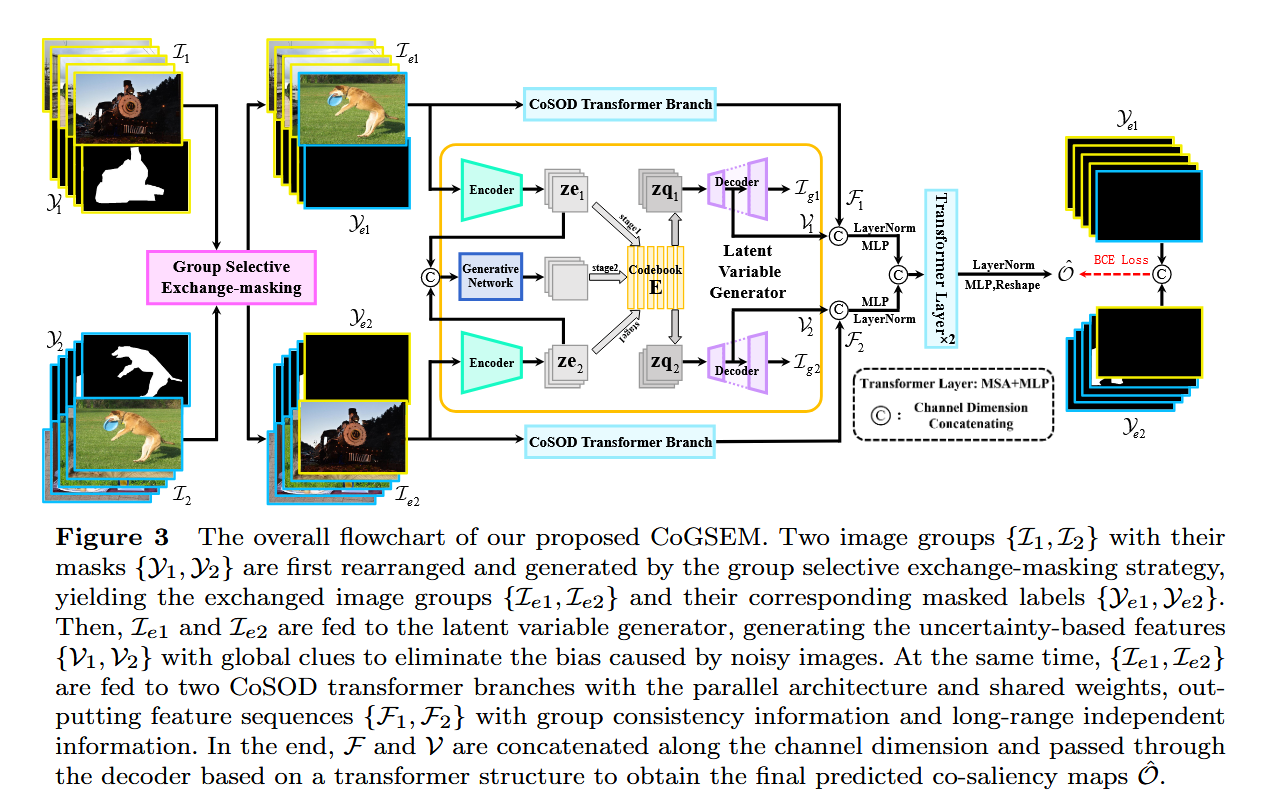
1 GSEM策略
输入:两组图像(每组含不同类别显著目标)。
混合度量:
(1)BDC度量:衡量图像与组共识的非线性语义差异(高维)。
(2)二值化度量:通过特征图与GT的Hadamard积评估分割难度(低维)。
交换与掩码:选择Top-k困难样本交换,并掩码其标签。
2 LVGB(隐变量生成分支)
VQ-VAE编码器:压缩图像特征为隐变量 ![]() 。
。
Codebook量化:通过最近邻搜索生成离散隐变量![]() 。
。
生成网络:基于PixelCNN采样隐变量,增强不确定性建模。
损失函数:包含重构损失、码本损失和commitment损失(式12)。
3 CoSOD-TB(Transformer分支)
T2T-ViT主干:将图像分块为序列,提取全局-局部特征。
自注意力机制:通过组共识特征(![]() )和对象特定特征(
)和对象特定特征(![]() )交互,增强共显著性建模。
)交互,增强共显著性建模。
输出:融合LVGB的隐变量和Transformer特征,经解码器生成预测图。
4 损失函数
多任务损失(式18):结合VQ-VAE损失(![]() )、生成网络损失(
)、生成网络损失(![]() )和Transformer分支的BCE损失(
)和Transformer分支的BCE损失(![]() )。
)。
精度分析
在三个流行的RGB-D SOD基准数据集(CoCA,CoSOD3k,Cosal2015)上进行了广泛的实验,结果表明GoGSEM在定性和定量评估中均优于现有的最先进方法。
总结
该论文通过GSEM策略和双分支结构(LVGB+CoSOD-TB),首次解决了开放世界CoSOD的鲁棒性问题,在多个数据集上达到SOTA精度。其核心创新在于将不确定性建模(VQ-VAE)与Transformer的强表征能力结合,同时重构数据集推动领域发展。未来方向可探索更高效的噪声选择策略和跨模态共显著性检测。
网络
1 论文的主干网络采用了 T2T-ViT
这篇论文的主干网络采用了 T2T-ViT(Tokens-to-Token Vision Transformer),这是一种基于Transformer的视觉特征提取架构,专为高效处理图像序列设计。以下是其主干网络的详细解析:
1. 主干网络:T2T-ViT(Tokens-to-Token Vision Transformer)
核心设计思想
-
目标:解决传统ViT因直接分割图像为固定大小Patch导致的局部信息丢失问题。
-
创新点:通过递归的“折叠(Folding)”和“展开(Unfolding)”操作,逐步聚合局部邻域信息,生成更具表现力的Token序列。
具体结构
-
输入处理
-
输入图像组
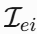 被分割为重叠的局部块(Patches),初始尺寸为
被分割为重叠的局部块(Patches),初始尺寸为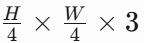 (假设输入分辨率 H×W)。
(假设输入分辨率 H×W)。 -
通过线性投影将每个Patch映射为Token,形成初始序列
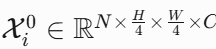 。
。
-
-
Tokens-to-Token(T2T)模块
-
Step 1: 局部聚合(Folding)
将相邻的多个Token(如2×2)通过卷积或线性层合并为一个新Token,减少序列长度同时保留局部结构。-
例如:将
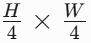 的序列折叠为
的序列折叠为  ,通道数扩展至 C′。
,通道数扩展至 C′。
-
-
Step 2: 全局建模(Transformer层)
对折叠后的Token序列应用标准Transformer编码器(多头自注意力+FFN),捕获全局依赖关系。 -
递归执行:重复折叠和Transformer操作,最终输出低分辨率高维特征
 。
。
-
-
组共识与对象特定特征分离
-
组共识特征(
 ):通过全局平均池化生成,表征图像组的共性信息。
):通过全局平均池化生成,表征图像组的共性信息。 -
对象特定特征(
 ):保留空间细节,用于定位共显著目标。
):保留空间细节,用于定位共显著目标。 -
交互机制:将
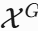 和
和  拼接后输入Transformer层,增强特征交互。
拼接后输入Transformer层,增强特征交互。
-
-
轻量化设计
-
与原始ViT相比,T2T-ViT通过局部聚合减少了计算量,适合处理图像组的长序列输入。
-
论文中使用的 T2T-ViT_t-14 版本,参数量与ResNet50相当,但更适合长程关系建模。
-
2. 与其他主干的对比
| 主干网络 | 优势 | 在本文中的适用性 |
|---|---|---|
| CNN(如ResNet) | 局部感受野强,适合低层特征提取 | 难以建模图像间的长程依赖,组共识能力弱 |
| 标准ViT | 全局注意力机制,适合长程建模 | 计算复杂度高,直接处理图像组效率低 |
| T2T-ViT | 平衡局部与全局信息,计算效率高 | 完美适配共显著性任务,支持组内和组间交互 |
3. 为什么选择T2T-ViT?
-
高效处理图像组:通过折叠操作降低序列长度,避免传统ViT的高计算开销。
-
保留局部细节:递归聚合局部邻域信息,避免直接分块导致的边界信息丢失。
-
兼容Transformer优势:自注意力机制天然适合建模图像间的共显著性关系。
-
与LVGB的协同:T2T-ViT的全局特征与VQ-VAE的隐变量互补,共同提升鲁棒性。
4. 关键参数(以T2T-ViT_t-14为例)
-
输入分辨率:224×224
-
初始Patch大小:4×4(序列长度:56×56)
-
折叠次数:2次(最终序列长度:14×14)
-
隐藏层维度:384(与VQ-VAE的codebook维度对齐)
-
注意力头数:6头
-
参数量:约20M(与ResNet50相当)
总结
论文的主干网络T2T-ViT通过 局部折叠+全局Transformer 的混合设计,在保持计算效率的同时,解决了共显著性检测所需的 组内一致性建模 和 跨图像长程依赖捕获 问题。其与LVGB(VQ-VAE)的协同进一步提升了开放世界场景下的鲁棒性,成为模型性能优越的核心支柱。
梯度诱导的共显著性检测 2020 GICD
摘要
共同显著性检测(Co-SOD)旨在分割一组相关图像中共同的显著前景。在本文中,受人类行为的启发,我们提出了一种梯度诱导的共同显著性检测(GICD)方法。 我们首先在嵌入空间中为一组图像提取出一个一致性表示;然后,通过将单张图像与该一致性表示进行比较,利用反馈的梯度信息来引导模型更加关注具有判别性的共同显著特征。 此外,由于缺乏共同显著性检测(Co-SOD)的训练数据,我们设计了一种拼图训练策略。借助这一策略,共同显著性检测网络能够在一般的显著性数据集中进行训练,且无需额外的像素级注释。 为了评估共同显著性检测方法在多个前景中发现共同显著目标的性能,我们构建了一个具有挑战性的CoCA数据集。在该数据集中,每张图像除了包含共同显著目标外,还至少包含一个无关的前景。 实验表明,我们的GICD方法取得了当前最优的性能。我们的代码和数据集可在https://mmcheng.net/gicd/获取。
创新点
1 梯度诱导模块(GIM, Gradient Inducing Module)
动机:人类在识别共显著目标时,会先总结图像组的共性特征,再通过对比单图像与共识表示来定位目标。GIM通过梯度反馈机制模拟这一过程。
实现:
(1)计算图像组的共识表示(consensus representation)作为共性描述。
(2)通过内积衡量单图像特征与共识表示的相似度,并反向传播梯度到高层卷积层。
(3)利用梯度幅值增强与共显著目标相关的卷积核权重,抑制无关特征。
作用:使模型更关注与共显著目标相关的判别性特征。
2 注意力保留模块(ARM, Attention Retaining Module)
动机:高层特征经过GIM增强后,在解码过程中可能因上采样而丢失注意力信息。
实现:
(1)通过跨层连接将高层预测(如热力图)作为低层特征的引导信号。
(2)在解码器中逐级传递注意力信息,确保细节恢复时不被无关前景干扰。
作用:保持解码过程中对共显著目标的注意力一致性。
3 拼图训练策略(Jigsaw Training Strategy)
问题:现有共显著性数据集缺乏多前景干扰场景,且标注不足。
解决方案:
(1)对单显著性数据集(如DUTS)分类后,将不同类别的图像拼接为“拼图”,构造含多前景的合成训练样本。
(2)无需额外标注,即可模拟真实场景中的共显著性检测任务。
优势:解决了共显著性数据稀缺问题,提升模型泛化能力。
模型的主要模块



精度分析
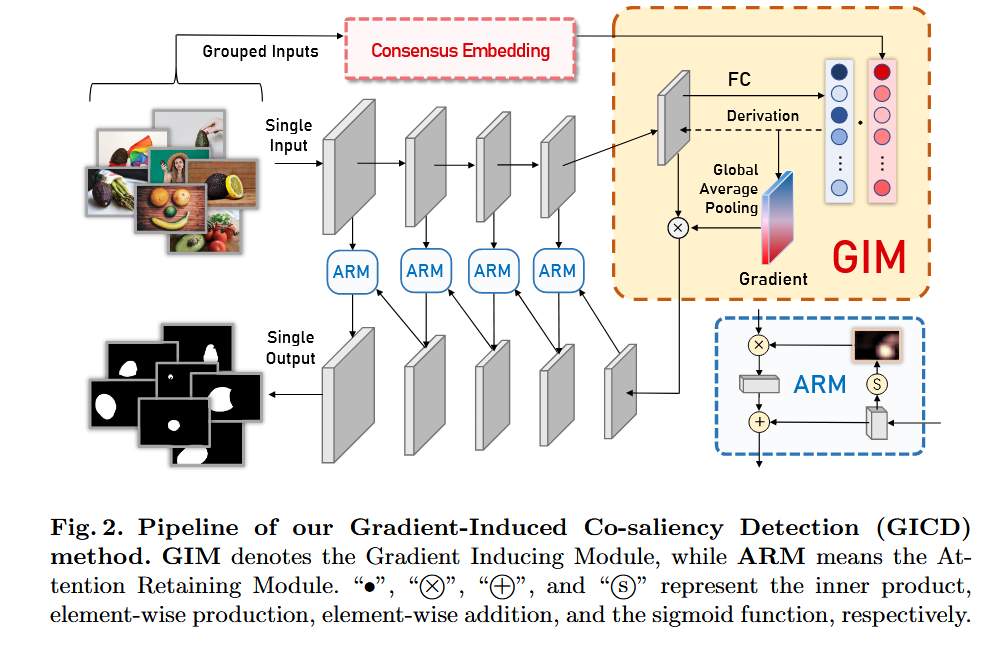
在三个流行的RGB-D SOD基准数据集(CoCA,CoSOD3k,Cosal2015)上进行了广泛的实验,结果表明GICD在定性和定量评估中均优于现有的最先进方法。
总结
GICD通过梯度反馈和注意力保留机制,显著提升了共显著性检测的精度,尤其在多前景干扰场景下表现优异。其创新点包括梯度诱导、注意力保留、拼图训练策略和新数据集CoCA,为后续研究提供了新思路和评测基准。
网络
1 主干网络基于 Feature Pyramid Network (FPN) 架构,并结合了预训练的 VGG-16 作为特征提取器。
1. 主干网络结构
(1)编码器(Encoder)
-
基础网络:预训练的 VGG-16(移除全连接层,保留卷积层)。
-
输入尺寸:224×224(RGB图像)。
-
输出特征图:5个层级的卷积特征(对应VGG的5个块),分辨率逐步降低,通道数逐步增加:
-
Block1(Conv1-2):112×112×64
-
Block2(Conv2-2):56×56×128
-
Block3(Conv3-3):28×28×256
-
Block4(Conv4-3):14×14×512
-
Block5(Conv5-3):7×7×512(高层语义特征,用于GIM梯度诱导)
-
-
-
作用:提取多尺度特征,低层保留细节(边缘、纹理),高层捕获语义信息(物体类别、共显著性)。
(2)特征金字塔(FPN)
-
设计:
-
自底向上路径:VGG-16的卷积层(Block1-5)。
-
自顶向下路径:通过上采样和横向连接(lateral connection)融合多尺度特征。
-
高层特征上采样后与低层特征逐元素相加(或拼接)。
-
例如:Block5特征上采样至14×14后与Block4特征融合。
-
-
-
输出:多尺度特征图(P1-P5),用于后续解码和共显著性预测。
2. 梯度诱导模块(GIM)的集成

3. 解码器(Decoder)与注意力保留模块(ARM)

4. 关键设计细节
-
参数共享:编码器(VGG-16)与共识表示生成网络共享权重。
-
轻量化:仅使用VGG-16(约138M参数),未引入复杂模块(如ResNet),兼顾效率与性能。
-
多尺度监督:在解码器的4个层级(P5-P2)添加辅助损失(Soft IoU Loss),加速收敛。
通过多尺度的特征对应进行自监督 Co-Salient 目标检测 2024 SCoSPARC
摘要
本文介绍了一种新颖的两阶段自监督方法,用于在无需分割注释的情况下检测图像组中共同出现的显著目标(CoSOD)。与现有的无监督方法不同,那些方法要么仅依赖于补丁级别信息(例如,对补丁描述符进行聚类),要么在共同显著目标检测(CoSOD)中使用计算量繁重的现成组件,而我们的轻量级模型则利用了补丁级别和区域级别的特征对应关系,显著提升了预测性能。 在第一阶段,我们训练一个自监督网络,该网络通过计算图像间的局部补丁级别特征对应关系来检测共同显著区域。我们使用基于置信度的自适应阈值法来获取分割预测结果。 在下一阶段,我们通过剔除(每张图像内)检测到的那些平均特征表示与所有交叉注意力图(来自上一阶段)的前景平均特征表示不相似的区域,来优化这些中间分割结果。 在三个共同显著目标检测(CoSOD)基准数据集上进行的大量实验表明,我们的自监督模型在很大程度上优于相应的当前最优模型(例如,在CoCA数据集上,我们的模型在F值上比当前最优的无监督CoSOD模型高出13.7%)。 值得注意的是,在这三个测试数据集上,我们的自监督模型也优于一些近期的全监督CoSOD模型(例如,在CoCA数据集上,我们的模型在F值上比近期的一个监督CoSOD模型高出4.6%)。
创新点
1 多尺度特征对应
局部(Patch-level)与全局(Region-level)特征结合:传统无监督方法仅依赖局部特征(如ViT块描述子聚类),而本文通过两阶段设计(局部特征匹配 + 区域级语义一致性过滤)提升检测精度。
自监督ViT特征利用:直接利用DINO预训练的ViT特征(无需额外标注),通过跨图像块级特征相似性挖掘共现显著区域。
2 自适应阈值分割:提出基于预测置信度的动态阈值(而非固定0.5),通过Sigmoid参数控制输出二值化,提升分割鲁棒性。
3 轻量化设计: 避免使用计算密集型组件(如SAM、Stable Diffusion),仅依赖ViT主干和轻量级残差模块,实现高效推理(20 FPS)。
4 自监督损失函数
共现损失(Co-occurrence Loss):强制跨图像前景特征相似,同时前景与背景特征差异最大化。
显著性损失(Saliency Loss):利用DINO自注意力图作为显著性先验,无需外部显着性模型。
模型的主要模块
模型分为两阶段(见图2):
Stage 1: 局部块级特征对应
-
主干网络:DINO预训练的ViT-B/8(patch size=8),提取块级特征。
-
残差增强:通过1×1卷积生成残差特征,强化局部关系。
-
跨图像相似性计算:
-
计算所有图像块间的特征相似矩阵(余弦相似度)。
-
生成跨注意力图(Cross-attention Map),突出共现区域。
-
-
自适应阈值分割:
-
根据置信度动态调整阈值,生成初步分割掩码。
-
Stage 2: 区域级特征过滤
-
共识特征提取:对所有图像的初步掩码区域求平均特征向量。
-
区域过滤:
-
对每张图像的连通区域计算特征相似度,剔除与共识特征差异大的区域。
-
-
后处理:使用denseCRF细化边界。
精度分析
在三个流行的RGB-D SOD基准数据集(CoCA,CoSOD3k,Cosal2015)上进行了广泛的实验,结果表明SCoSPARC在定性和定量评估中均优于现有的最先进方法。
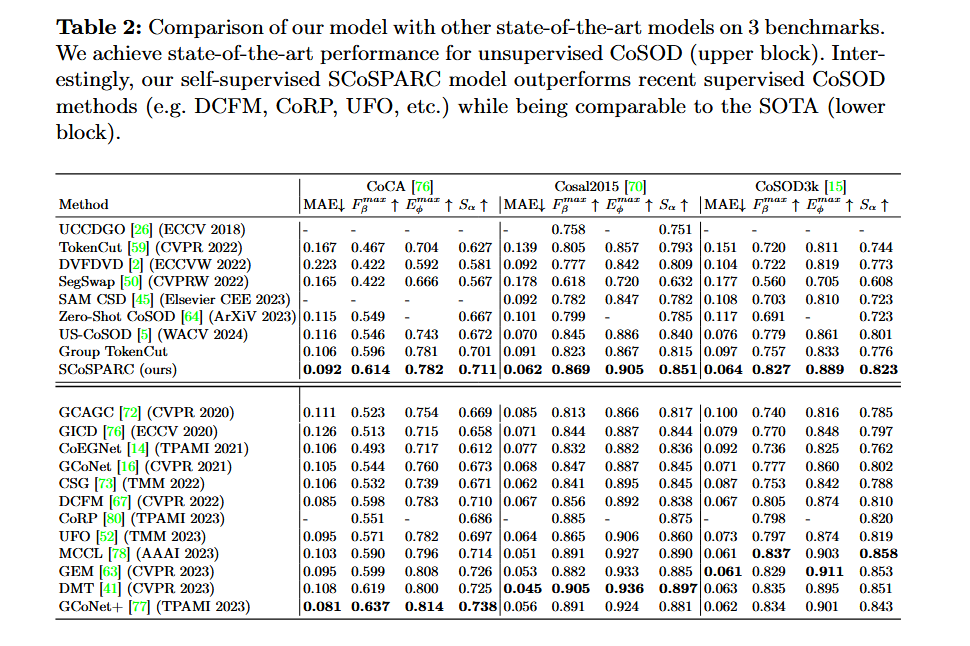 总结
总结
本文通过多尺度特征对应和自监督设计,实现了无监督CoSOD的性能突破,其轻量化和通用性使其在实时应用中具有潜力。未来可探索结合扩散模型等生成式方法进一步提升精度。
网络
1 论文的主干网络基于 DINO 预训练的 Vision Transformer (ViT)




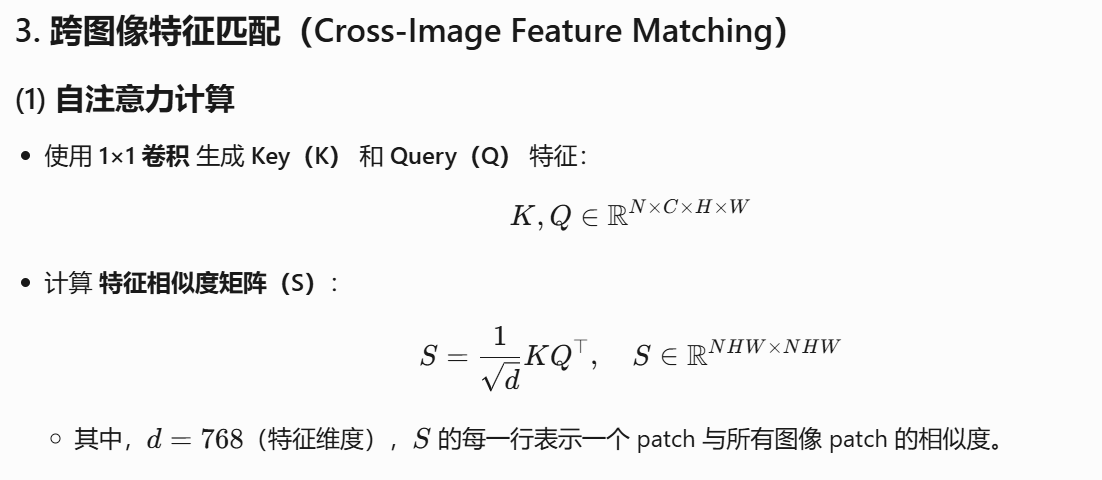




5. 总结
主干网络核心特点
-
DINO-ViT 自监督特征:无需人工标注,自动学习语义信息。
-
轻量级残差增强:1×1 卷积增强局部特征。
-
跨图像特征匹配:通过自注意力计算 patch 相似度。
-
自适应阈值分割:动态调整二值化阈值,提升鲁棒性。
-
区域级过滤:利用全局共识特征剔除噪声区域。
性能优势
-
计算高效:仅需 ViT 主干 + 轻量残差模块,推理速度 20 FPS(无 CRF)。
-
无监督 SOTA:在 CoCA 上 F-measure 比 US-CoSOD 高 13.7%,甚至超越部分监督方法(如 DCFM)。
这篇论文的核心贡献在于 利用自监督 ViT 特征 + 多尺度特征匹配,实现了无监督 CoSOD 的高精度检测,同时保持轻量化和高效推理。
通过完整性学习进行突出目标检测 2023 ICON
摘要
尽管当前的显著目标检测(SOD)研究已经取得了重大进展,但在预测的显著区域的完整性方面仍存在局限。我们从微观和宏观两个层面定义了完整性的概念。具体来说,在微观层面,模型应突出显示属于某个显著目标的所有部分。同时,在宏观层面,模型需要发现给定图像中的所有显著目标。 为了促进显著目标检测的完整性学习,我们设计了一种新颖的完整性认知网络(ICON),该网络探索了用于学习强大完整性特征的三个重要组件。1)与现有模型更多地关注特征的判别性不同,我们引入了一个多样化特征聚合(DFA)组件,以聚合具有不同感受野(即内核形状和上下文)的特征,并增加特征的多样性。这种多样性是挖掘完整显著目标的基础。2)基于DFA特征,我们引入了一个完整性通道增强(ICE)组件,旨在增强突出完整显著目标的特征通道,同时抑制其他干扰性的特征通道。3)在提取增强后的特征后,采用部分-整体验证(PWV)方法来确定部分目标特征和整体目标特征之间是否具有很强的一致性。这种部分与整体的一致性可以进一步提高每个显著目标在微观层面的完整性。 为了证明我们的ICON的有效性,我们在七个具有挑战性的基准数据集上进行了全面的实验。我们的ICON在广泛的评估指标上优于基线方法。值得注意的是,在六个数据集上,我们的ICON在平均假阴性率(FNR)方面相较于之前的最佳模型实现了约10%的相对提升。代码和结果可在以下网址获取:https://github.com/mczhuge/ICON 。
创新点
1 完整性学习机制
问题定义:论文首次从微观(micro)和宏观(macro)两个层面定义完整性:
微观:模型应突出属于同一显著目标的所有部分(避免部分缺失)。
宏观:模型需检测图像中所有显著目标(避免漏检)。
现有方法局限:传统方法多关注多尺度特征、边界优化或上下文建模,但忽略了目标内部及目标间的完整性关联。
2 三个核心组件
Diverse Feature Aggregation (DFA):通过多样化卷积核(非对称、空洞、常规卷积)聚合多感受野特征,增强特征多样性。
Integrity Channel Enhancement (ICE):利用通道注意力机制增强与完整性相关的特征通道,抑制干扰通道.
Part-Whole Verification (PWV):基于胶囊网络(Capsule Network)验证部分与整体特征的一致性,补全缺失部分。
3 无需额外监督
与依赖显式监督(如目标数量标注)的方法不同,ICON通过自监督机制学习完整性,更具普适性。
模型的主要模块
1 Diverse Feature Aggregation (DFA)
设计目的:解决目标形状和尺寸多样性问题。
实现方式:
三种卷积并行:
非对称卷积(Asymmetric Conv):1×3和3×1卷积核增强方向敏感性。
空洞卷积(Atrous Conv):扩大感受野。
常规卷积(Original Conv):保留基础特征。
特征拼接:将三种卷积的输出拼接,形成多样性特征(公式1)。
2 Integrity Channel Enhancement (ICE)
设计目的:筛选并增强与完整性相关的通道。
实现步骤:
(1)多尺度特征融合:将相邻三个层级的DFA特征调整至相同分辨率并拼接(公式3)。
(2)完整性嵌入:通过L2归一化和瓶颈结构(Bottleneck)生成通道权重。
(3)通道加权:对特征通道进行加权,突出完整性区域(公式4)。
3 Part-Whole Verification (PWV)
设计目的:验证部分与整体的一致性,补全缺失部分。
实现方式:
胶囊网络:将特征转换为胶囊(Pose矩阵+激活值),通过EM路由(Expectation-Maximization Routing)动态聚合部分与整体关系。
动态路由:低层胶囊投票给高层胶囊,高层胶囊通过EM算法迭代更新,确保部分与整体的一致性。
4 损失函数
联合损失:BCE Loss + IoU Loss(公式5-6),平衡像素级分类和区域重叠优化。
精度分析
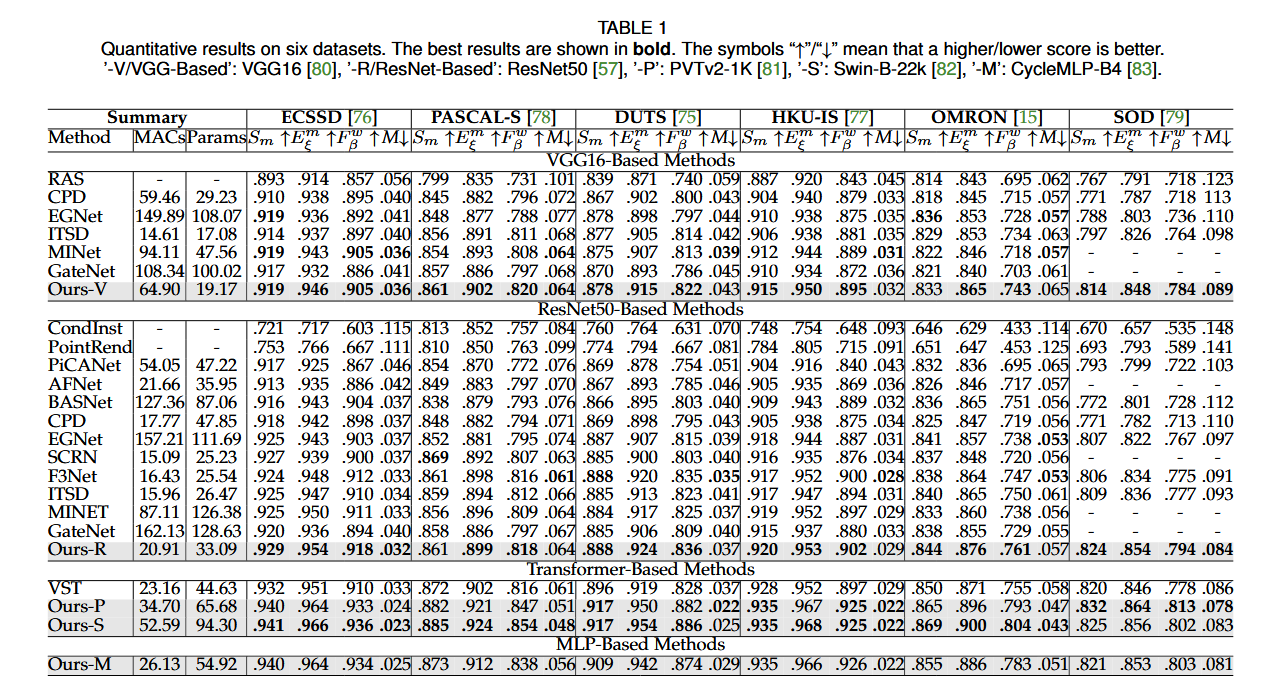
总结
- 创新性:首次系统定义完整性学习,提出DFA、ICE、PWV三模块协同优化。
- 性能优势:通过多模块联合训练,在复杂场景下显著降低漏检率(FNR)。
- 通用性:支持多种主干(CNN/Transformer/MLP),平衡精度与效率。
网络
1 ResNet-50
用于共显著目标检测的组注意力保持网络 2023 GARNet
摘要
共同显著目标检测(Co-SOD)旨在从一组图像中发现共同的显著目标。随着卷积神经网络的发展,共同显著目标检测方法的性能得到了显著提升。然而,一些模型无法以最优方式构建图像间的协作关系,并且在自上而下的解码过程中缺乏对协作特征的有效保留。 在本文中,我们提出了一种新颖的群体注意力保留网络(GARNet),该网络能够捕捉出色的协作特征并将其保留下来。首先,设计了一个群体注意力模块来构建图像间的关系。其次,设计了一个注意力保留模块和一个空间注意力模块,前者用于保留图像间的关系,防止其被稀释,后者则用于在特征融合过程中过滤掉杂乱的上下文信息。最后,考虑到图像的组内一致性和组间可分性,额外设计了一个嵌入损失函数,以区分真正的协作目标和干扰目标。 在四个数据集(iCoSeg、CoSal2015、CoSoD3k和CoCA)上进行的实验表明,我们的GARNet优于先前的最先进方法。源代码可在https://github.com/TJUMMG/GARNet获取。
创新点
1 Group Attention Module (GAM)
基于Transformer设计,用于构建跨图像的协同关系,捕捉长距离依赖。
通过多头自注意力机制(Multi-Head Self-Attention)增强共显着区域的关注,抑制背景干扰。
无需位置编码(Position Embedding),对输入顺序不敏感,提升模型稳定性。
2 Attention Retention Module (ARM)
解决高层共显着特征在解码过程中被稀释的问题。
通过Transformer结构建立高层语义特征(如F₄、F₅)与低层特征的像素级关系,保留协同注意力特征。
采用跨层注意力机制(Query来自低层,Key/Value来自高层),通过残差连接融合特征。
3 Spatial Attention Module (SAM)
在低层特征融合(如F₁、F₂)时,通过空间注意力过滤杂乱背景信息。
利用上层粗糙显著性预测(Mₙ₊₁)对当前层特征(Fₙ)进行空间加权,抑制非协同目标的干扰。
4 Embedding Loss (ELoss)
传统IoU Loss仅关注分割精度,而ELoss额外约束组内一致性和组间分离性:缩小同组样本特征距离(Lₑ⁺),增大不同组特征距离(Lₑ⁻)。
提升模型对真实协同目标与干扰目标的判别能力。
5 整体架构优势
首次将Transformer引入共显着检测,通过GAM和ARM实现跨图像关系建模与特征保留。
结合CNN(VGG-16)的局部特征提取能力与Transformer的全局关系建模能力。
模型的主要模块
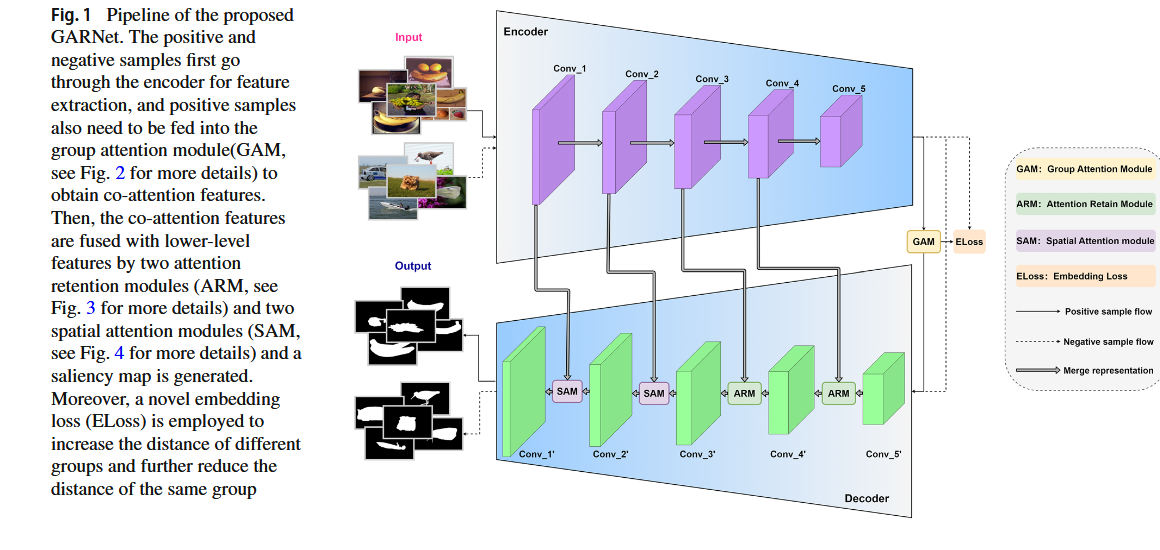 1 编码器(Encoder)
1 编码器(Encoder)
主干网络:VGG-16(预训练于ImageNet),提取多尺度特征(F₁-F₅)。
输入:正样本组(含同类目标)和负样本组(不同类目标),通过对比学习增强特征判别性。
2 Group Attention Module (GAM)
输入:高层特征F₅(N×H₅×W₅×C₅),经1×1卷积降维至d通道后展平为序列(N×d,N=图像数×H₅×W₅)。
结构:4层Transformer,每层包含多头自注意力和前馈网络(FFN),无位置编码。
输出:增强的共显着特征,突出组内协同目标。
3 Attention Retention Module (ARM)
工作流程:
高层特征Fₙ₊₁通过下采样与低层特征Fₙ交互,生成注意力权重。
通过上采样和残差连接融合到低层特征。
例如:F₄与F₅通过ARM交互,保留高层语义信息。
5 解码器(Decoder)
通过ARM和SAM逐步融合多尺度特征,结合跳跃连接(Skip Connection)恢复细节。
最终输出:共显著性图(Saliency Map)。
精度分析
在三个流行的RGB-D SOD基准数据集(iCoSeg,CoSOD3k,Cosal2015)上进行了广泛的实验,结果表明GARNet在定性和定量评估中均优于现有的最先进方法。
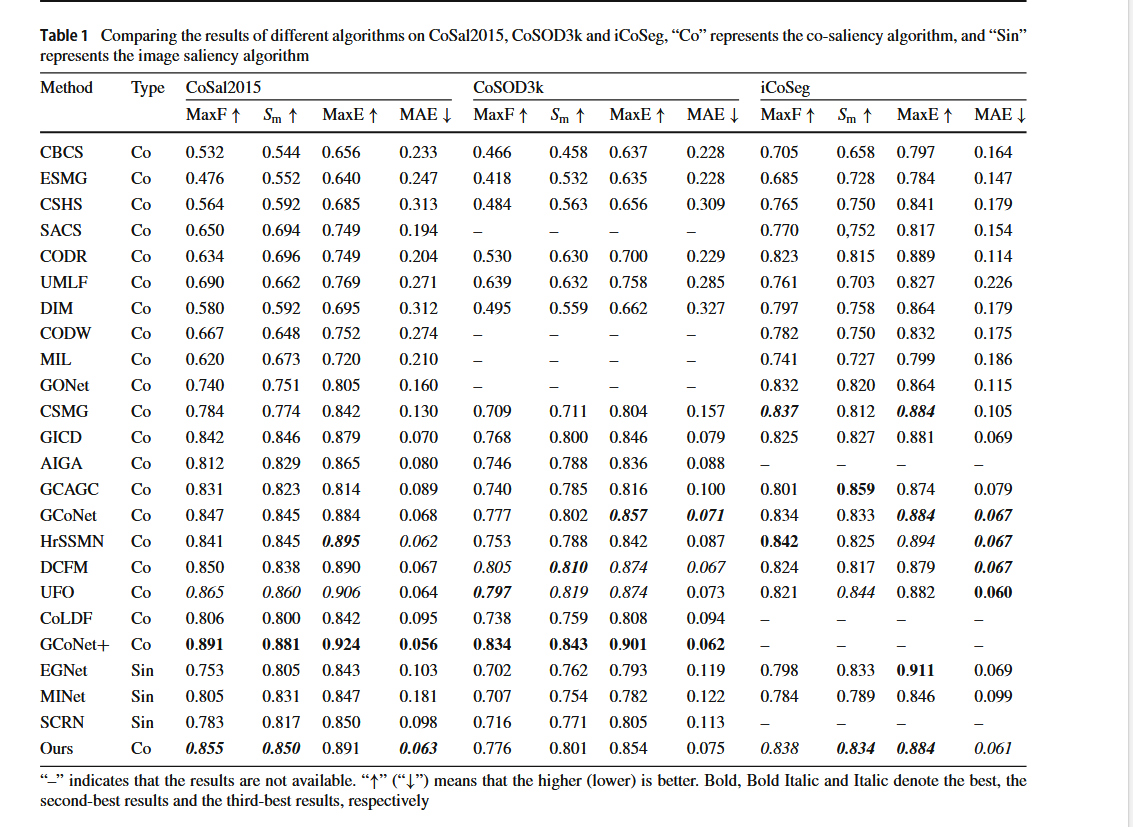
总结
GARNet通过跨图像注意力建模(GAM)、特征保留机制(ARM/SAM)和对比损失(ELoss),显著提升了共显着检测的精度与鲁棒性。其创新点在于将Transformer的全局关系建模能力与CNN的局部特征提取相结合,并在解码过程中通过注意力机制保护协同特征不被稀释。实验表明,该模型在复杂场景下优于现有方法,尤其在存在强干扰目标时表现突出。
网络
1 主干网络采用 VGG-16
1. 主干网络:VGG-16的改进与配置
原始VGG-16结构
VGG-16由13个卷积层(Conv1-1到Conv5-3)和3个全连接层(FC6-FC8)组成。论文中:
-
移除全连接层:仅保留卷积部分,作为特征提取器。
-
输出多尺度特征:从不同阶段提取特征图(F₁到F₅),用于后续模块的协同关系建模。
具体层级与参数
| Stage | Layer Name | Output Size (H×W×C) | 作用 |
|---|---|---|---|
| Stage 1 | Conv1-1 + Conv1-2 | 224×224×64 | 低级特征(边缘、纹理) |
| Stage 2 | Conv2-1 + Conv2-2 | 112×112×128 | 中层特征(局部结构) |
| Stage 3 | Conv3-1 to Conv3-3 | 56×56×256 | 中高层语义特征 |
| Stage 4 | Conv4-1 to Conv4-3 | 28×28×512 | 高层语义特征(目标部分) |
| Stage 5 | Conv5-1 to Conv5-3 | 14×14×512 | 最高层语义特征(用于GAM输入) |
注:输入图像统一缩放到224×224,经过步长为2的最大池化(MaxPool)降采样。
2. 主干网络的适应性改进
(1) 特征图的输出调整
-
多尺度特征提取:
输出5个层级的特征图(F₁到F₅),分别对应Stage 1到Stage 5的最后一层卷积输出。-
F₅(14×14×512):输入到Group Attention Module(GAM)进行跨图像关系建模。
-
F₄/F₃:用于Attention Retention Module(ARM)的高层语义保留。
-
F₂/F₁:通过Spatial Attention Module(SAM)融合细节信息。
-
(2) 预训练与微调
-
初始化:使用ImageNet预训练的权重初始化卷积层。
-
微调策略:在Co-SOD任务中,所有卷积层参与端到端训练,但低层(Conv1-2)学习率较低,以保留通用特征。
(3) 与Transformer模块的兼容性
-
降维处理:
在GAM中,F₅(14×14×512)先通过1×1卷积降维到通道数d(论文未明确数值,通常设为256或512),以减少计算量。 -
序列化输入:
将F₅的空间维度展平为序列(196×512),作为Transformer的输入序列。
3. 为什么选择VGG-16?
-
平衡性能与复杂度:
VGG-16结构简单,参数量适中(约138M),适合作为基础特征提取器,避免过深网络(如ResNet)带来的优化困难。 -
多尺度特征适配性:
其层级化的卷积设计(每Stage尺寸减半)天然支持多尺度特征融合,与Co-SOD任务需求匹配。 -
对比其他选择:
-
ResNet:虽然更高效,但残差连接可能导致低层特征过早稀释协同信息。
-
ViT:纯Transformer主干计算成本高,且对小数据集(如Co-SOD)容易过拟合。
-
4. 主干网络的局限性
-
感受野限制:
VGG-16的卷积核较小(3×3),高层特征(F₅)的感受野有限,可能影响大目标的全局关系建模。
解决方案:通过GAM的全局注意力弥补这一缺陷。 -
计算效率:
512通道的高层特征导致GAM的输入序列较长(196×512),自注意力计算复杂度较高。
优化:降维和分阶段处理(如ARM仅在F₄/F₅应用)。
5. 与其他模块的协同工作流程
-
输入:
-
正样本组(同类图像)和负样本组(异类图像)分别输入VGG-16,提取特征{F₁⁺, ..., F₅⁺}和{F₁⁻, ..., F₅⁻}。
-
-
协同关系建模:
-
正样本的F₅⁺输入GAM,通过多头自注意力生成共显着特征。
-
负样本仅用于ELoss计算(不参与GAM)。
-
-
特征解码:
-
高层:F₅⁺经GAM增强后,通过ARM与F₄⁺交互,保留协同语义。
-
低层:F₂⁺和F₁⁺通过SAM过滤背景噪声,逐步上采样输出显著性图。
-
总结
论文的主干网络基于VGG-16,通过多尺度特征提取和与Transformer模块(GAM/ARM)的协同设计,实现了跨图像共显着关系的建模。其优势在于结构简单、易于微调,但依赖后续注意力模块弥补全局建模的不足。这一设计在计算效率和检测精度之间取得了平衡,适合处理Co-SOD中的复杂场景。
用于共显著性目标检测的判别性协同显著性和背景挖掘变压器 2023 DMT
摘要
以往大多数共同显著目标检测的研究工作主要侧重于通过挖掘图像间的一致性关系来提取共同显著线索,却忽略了对背景区域的明确探索。在本文中,我们提出了一种基于几个高效的多粒度相关模块的判别性共同显著性与背景挖掘变换器框架(DMT),以明确挖掘共同显著性信息和背景信息,并有效地对它们之间的判别性进行建模。 具体而言,我们首先提出了一个区域对区域的相关模块,用于在保持计算效率的同时,将图像间的关系引入到逐像素的分割特征中。然后,我们使用两种预定义的标记,通过我们提出的对比诱导的像素对标记相关模块和共同显著性标记对标记相关模块,来挖掘共同显著性信息和背景信息。我们还设计了一个标记引导的特征细化模块,以便在学习到的标记的引导下增强分割特征的判别性。我们对分割特征提取和标记构建进行了迭代的相互促进。 在三个基准数据集上的实验结果证明了我们所提出方法的有效性。源代码可在以下网址获取:https://github.com/dragonlee258079/DMT 。
创新点
1 双变量建模范式(Bivariate FG&BG Modeling)
传统方法主要关注前景(FG)一致性关系,而忽略背景(BG)的显式建模。本文提出同时显式建模共显著性(FG)和背景(BG),通过对比学习增强两者的区分性。
创新性:首次将CoSOD任务从单一前景建模扩展到双变量(FG+BG)联合优化,抑制复杂背景干扰(如伴随物体或非共现的显著性物体)。
2 多粒度经济性关联模块
区域到区域关联(R2R):替代传统像素级关联(P2P),通过局部区域池化(如K×K块)计算多尺度区域相关性,降低计算开销。
对比诱导的像素到标记关联(CtP2T):通过通道注意力机制显式建模FG与BG的对比关系,抑制相似通道以增强区分性。
共显著性标记到标记关联(CoT2T):引入组标记(Group Token)聚合跨图像的共显著性共识,并通过Transformer分发回各图像标记。
3 标记引导的特征细化(TGFR)
反向利用标记(Tokens)信息优化分割特征:通过蒸馏(Distillation)提取FG/BG特征,再通过重融合(Refusion)增强特征区分性,形成双向信息流(传统MaskFormer仅为单向)。
4 迭代式协同优化
通过R2R→CtP2T→CoT2T→TGFR的迭代优化,实现分割特征与标记的相互促进,逐步提升精度。
模型的主要模块
1 分割特征生成路径
主干网络:VGG-16 + FPN解码器,生成多尺度特征图(H₀W₀→H₅W₅)。
R2R模块:插入每个解码层,通过区域级关联增强跨图像一致性。
流程:① 将特征图划分为K×K区域→② 多尺度池化生成键/值→③ Transformer计算区域关联→④ 上采样残差融合。
2 标记构建路径
CtP2T模块:
- 输入:初始化的FG/BG标记(各1×C)和图像特征(H₀W₀×C)。
- 操作:通过改进的MHA*生成多头标记→计算通道相似性→对比注意力(CCA)抑制非区分性通道。
- 输出:区分性强的FG/BG标记。
CoT2T模块:
组标记(Group Token)聚合所有图像的FG标记共识,再通过Transformer分发回各图像标记。
3 TGFR模块
蒸馏:用FG/BG标记生成注意力图,从分割特征中提取FG/BG特征(式21-22)。
重融合:将蒸馏特征与原始特征拼接,通过卷积增强区分性(式23-24)。
4 预测与损失
分割预测:标记与特征图矩阵乘+Sigmoid(式8-9)。
损失函数:IoU + BCE损失,监督FG/BG预测、组标记和中间特征(式28)。
精度分析
在三个流行的RGB-D SOD基准数据集(CoCA,CoSOD3k,Cosal2015)上进行了广泛的实验,结果表明GARNet在定性和定量评估中均优于现有的最先
总结
本文核心创新在于双变量建模与经济性多粒度关联,通过Transformer架构实现FG/BG的显式区分与迭代优化。实验表明其在复杂场景(如CoCA)的鲁棒性,但VGG主干可能限制更高分辨率下的性能,未来可探索轻量级ViT或ConvNeXt作为替代。
网络
1 主干网络采用 VGG-16 作为编码器,结合 FPN 作为解码器
这篇论文的主干网络(Backbone)采用 VGG-16 作为编码器(Encoder),并结合 FPN(Feature Pyramid Network) 作为解码器(Decoder),构成一个类似MaskFormer的分割框架。以下是主干网络的详细说明:
1. 编码器(Encoder):VGG-16
结构细节
-
输入:一组相关图像
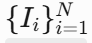 ,每张图像尺寸为 256×256×3。
,每张图像尺寸为 256×256×3。 -
输出:高层语义特征
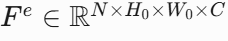 ,其中:
,其中:-
 (输入图像下采样16倍)。
(输入图像下采样16倍)。 -
通道数 C 未明确说明,但VGG-16最后一层卷积通常为512通道(需根据代码确认)。
-
-
关键修改:
-
移除原始VGG-16的全连接层,仅保留卷积层(Conv1-5)和池化层。
-
可能对最后一层卷积进行微调以适应CoSOD任务。
-
选择原因
-
轻量高效:相比ResNet或ViT,VGG-16计算量较小,适合处理多图像输入(组内图像数 N 可能较大)。
-
兼容性:与FPN解码器结合成熟,适合多尺度特征融合。
2. 解码器(Decoder):FPN结构
结构细节
-
输入:编码器输出的高层特征
 (分辨率 16×16)。
(分辨率 16×16)。 -
输出:5层多尺度分割特征
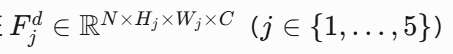 ,分辨率逐步上采样至 256×256。
,分辨率逐步上采样至 256×256。-
具体分辨率未明确列出,但典型FPN结构可能为:
j=1: 16×16 → j=5: 256×256。
-
-
关键操作:
-
自顶向下路径:通过上采样和横向连接(如1×1卷积)融合不同层特征。
-
R2R模块插入:在每层解码器后加入Region-to-Region (R2R) 模块,增强跨图像区域关联(见下文)。
-
R2R模块的作用
-
功能:替代传统像素级(P2P)跨图像关联,通过区域级交互降低计算复杂度。
-
流程:
-
区域划分:将特征图分为 K×K 局部区域(如 K=3),每区域用最大池化提取代表特征。
-
多尺度键/值生成:通过自适应池化生成 1×1、3×3、6×6 的多尺度特征,拼接后作为键/值(共46个区域)。
-
Transformer交互:计算区域间注意力并残差融合回原特征。
-
3. 主干网络的整体流程
-
编码阶段:
-
VGG-16提取单图像高层特征
 (组内每图像独立处理)。
(组内每图像独立处理)。
-
-
解码阶段:
-
FPN逐步上采样,生成多尺度特征
 。
。 -
每层解码器后接R2R模块,建模跨图像区域关联。
-
-
输出:
-
最终分割特征
 (分辨率 256×256×C)用于与标记(Tokens)交互预测。
(分辨率 256×256×C)用于与标记(Tokens)交互预测。
-
4. 与其他模块的协作
-
与CtP2T/CoT2T的交互:
-
高层特征
 作为CtP2T的输入,生成FG/BG标记。
作为CtP2T的输入,生成FG/BG标记。 -
解码器特征
 通过TGFR模块受标记引导优化。
通过TGFR模块受标记引导优化。
-
-
计算效率优化:
-
R2R的局部区域交互(vs. 全局P2P)减少计算量,支持多图像联合处理。
-
5. 可能的改进方向
-
主干替换:
-
若需更高精度,可尝试ResNet-50或轻量级ViT(如Swin-Tiny)。
-
-
多尺度输入:
-
当前输入固定为 256×256,可能限制小目标检测,可引入多尺度训练。
-
总结
论文的主干网络是 VGG-16 + FPN,核心创新在于:
-
经济性跨图像建模:通过R2R模块实现区域级交互,避免传统P2P的高计算开销。
-
双路径设计:分割特征(VGG+FPN)与标记(Tokens)路径协同优化,通过TGFR实现双向信息流。
-
轻量性:VGG-16在参数量和计算效率上平衡,适合多图像CoSOD任务。
用于基于组的分割的统一 Transformer 框架:协分割、共显著性检测和视频显著性目标检测 2022 UFO
摘要
摘要——由于我们生活在一个动态的世界中,人类往往通过从一组图像或几帧视频中学习来挖掘目标。在计算机视觉领域,许多研究聚焦于共同分割(CoS)、共同显著性检测(CoSD)和视频显著目标检测(VSOD),以发现共同出现的目标。 然而,以往的方法针对这些相似的任务分别设计了不同的网络,并且这些网络很难相互应用,这降低了深度学习框架可迁移性的上限。此外,它们未能充分利用一组图像中特征间以及特征内的线索。 在本文中,我们引入了一个统一的框架来解决这些问题,称之为UFO(共同目标分割统一框架)。具体来说,我们首先引入了一个变换器模块,它将图像特征视为一个图像块标记,然后通过自注意力机制捕捉它们之间的长距离依赖关系。这可以帮助网络挖掘相关目标之间的图像块结构相似性。 此外,我们提出了一个内部多层感知器(intra-MLP)学习模块来生成自掩码,以增强网络避免部分激活的能力。在四个共同分割基准数据集(PASCAL、iCoseg、Internet和MSRC)、三个共同显著性检测基准数据集(Cosal2015、CoSOD3k和CocA)以及四个视频显著目标检测基准数据集(DAVIS16、FBMS、ViSal和SegV2)上进行的大量实验表明,我们的方法在使用相同网络架构的情况下,在三个不同任务上的准确性和速度方面均优于其他最先进的方法,并且可以达到实时140帧每秒的速度。代码可在https://github.com/suyukun666/UFO获取。
创新点
1 统一框架解决多任务
问题背景:传统方法针对CoS、CoSD和VSOD任务设计独立网络,导致模型复用性差、计算成本高。
创新:首次提出单一网络架构(UFO)同时处理三类任务,无需额外先验信息(如光流),简化了流程并提升效率。
优势:统一建模群体图像间的共性特征,避免任务隔离带来的性能上限限制。
2 Transformer模块捕获长程依赖
问题背景:传统CNN的局部感受野难以建模图像间的全局相关性,而基于图匹配或谱聚类的方法计算复杂且不稳定。
创新:引入视觉Transformer块,将图像特征分割为Patch Token,通过自注意力机制捕捉跨图像的全局语义关联。
优势:避免计算昂贵的相似度矩阵(如GW距离),实现实时处理(140 FPS)。
3 Intra-MLP模块缓解局部激活
问题背景:CNN编码器倾向于激活物体的判别性局部区域,导致分割不完整。
创新:设计Intra-MLP学习模块,通过Top-K匹配增强单张图像内像素的全局相关性,生成自注意力掩码(Self-Masks)补充解码器。
优势:结合MLP和MAX操作,增强物体整体表征,避免部分激活问题。
4 轻量化与实时性
创新:仅需VGG16主干,无需复杂预处理(如光流或3D卷积),在多个任务上达到SOTA精度和速度平衡。
模型的主要模块
1 整体架构
Encoder-Decoder结构:
- Encoder:VGG16提取多尺度特征(F1-F4),在高层(F3/F4)插入Transformer块。
- Decoder:类似FPN结构,通过跳跃连接融合低层特征,结合Intra-MLP生成的掩码和类别嵌入向量增强输出。
2 核心模块
Transformer Block:
流程:将特征图展平为Patch Token,通过多头自注意力(4头)和MLP建模跨图像依赖。
输出:生成增强的协同注意力图(F3'/F4'),反映群体图像的共性区域。
Intra-MLP模块:
流程:对高层特征计算相似度矩阵(式2),选取Top-K相关像素,通过MLP和MAX操作生成自掩码(β)。
作用:补充单张图像的全局信息,与类别语义向量(α)共同调制解码器特征。
损失函数:多任务损失:分类损失(L_cls)、加权交叉熵(L_wbce)、IoU损失(L_iou),联合优化(式7)。
精度分析
在三个流行的RGB-D SOD基准数据集(CoCA,CoSOD3k,Cosal2015)上进行了广泛的实验,结果表明UFO在定性和定量评估中均优于现有的最先进方法。
总结
- 创新价值:首次统一多任务框架,通过Transformer和Intra-MLP解决长程依赖与局部激活问题。
- 性能优势:在11个基准上达到SOTA,兼顾精度(CoS/CoSD/VSOD)与速度(140 FPS)。
- 局限:DAVIS16上背景误分割问题需依赖光流缓解,未来可探索更高效的多模态融合。
网络
1 主干网络采用 VGG16
1. 主干网络:VGG16的改进与适配
(1)基础结构
-
原始VGG16:
-
包含13个卷积层(Conv1-13)和3个全连接层(FC),论文中仅使用卷积部分作为特征提取器。
-
输入分辨率:224×224(默认),输出多尺度特征图(F1-F4)。
-
-
论文中的修改:
-
移除全连接层:仅保留卷积层,形成全卷积网络(FCN),支持任意输入尺寸。
-
多尺度特征提取:从以下4个层级提取特征(对应VGG16的卷积块):
-
F1:Conv3_3(第3卷积块最后一层,分辨率56×56,通道数256)。
-
F2:Conv4_3(第4卷积块最后一层,分辨率28×28,通道数512)。
-
F3:Conv5_3(第5卷积块最后一层,分辨率14×14,通道数512)。
-
F4:对F3进行MaxPooling后的输出(分辨率7×7,通道数512)。
-
-
(2)Transformer的插入位置
-
高层特征注入:仅在 F3和F4 两个高层级插入Transformer块,原因如下:
-
计算效率:高层特征分辨率低(14×14和7×7),适合Transformer的全局计算。
-
语义信息:高层特征包含更多语义信息,利于建模跨图像的共性物体。
-
低层保留CNN:低层(F1/F2)保留CNN的局部纹理提取能力,避免高分辨率下Transformer的计算负担。
-
(3)特征维度处理
-
Patch Embedding:
-
将F3/F4特征图展平为Patch序列(如F4:7×7×512 → 49×512)。
-
通过线性投影调整通道数(512→782),输入Transformer块。
-
-
输出处理:Transformer输出后,将序列重新变形为特征图(如49×782 → 7×7×782),再通过卷积恢复为512通道。
2. 与其他主干的对比实验
论文在消融实验中对比了其他主干网络的效果:
| 主干网络 | 输入分辨率 | 参数量 | DAVIS16 (Fβ) | 速度 (FPS) |
|---|---|---|---|---|
| VGG16 | 224×224 | ~15M | 0.828 | 140 |
| HRNet-W48 | 224×224 | ~65M | 0.842 | 30 |
| ResNet50 | 256×256 | ~25M | 0.837 | 90 |
结论:
-
VGG16在速度-精度权衡上最优,适合实时任务。
-
更深的网络(如HRNet)虽能提升精度,但计算成本显著增加。
3. 主干网络的设计动机
-
轻量化与通用性:
-
VGG16结构简单,易于实现多任务统一框架。
-
相比ResNet/HRNet,参数量更少,适合嵌入Transformer模块。
-
-
多任务适配性:
-
CoS/CoSD需要高层语义对齐,VSOD需时空一致性,VGG16的多层级特征天然支持。
-
低层(F1/F2)保留细节信息,高层(F3/F4)通过Transformer增强全局建模。
-
-
与Transformer的兼容性:
-
Transformer块插入高层,避免低层高分辨率计算瓶颈(如ViT需分块处理)。
-
通过线性投影调整通道数(512→782),平衡计算量和表征能力。
-
4. 关键实现细节
-
输入预处理:图像归一化到[0,1],随机翻转/缩放(训练时)。
-
优化器:Adam(β1=0.9, β2=0.999),初始学习率1e-5,每25k步减半。
-
训练数据:
-
CoS/CoSD:COCO-SEG(200k图像,78类)。
-
VSOD:DAVIS16 + FBMS(59视频片段),预训练于静态显著性数据集(DUTS)。
-
总结
论文的主干网络以 VGG16为基础,通过以下改进实现多任务统一:
-
多尺度特征提取(F1-F4)保留空间细节与语义信息。
-
高层插入Transformer(F3/F4)捕获跨图像长程依赖。
-
轻量化设计:平衡速度与精度,避免复杂结构(如光流或3D卷积)。
这种设计在保持高效的同时,显著提升了跨任务的泛化能力,成为论文的核心创新之一。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









