






摘要
一 介绍
二 有关工作
2.1 显著目标检测
2.2 协同显著目标检测
2.3 图像协同分割
2.4 图像内与图像间一致性学习
三 方法
3.1 概述
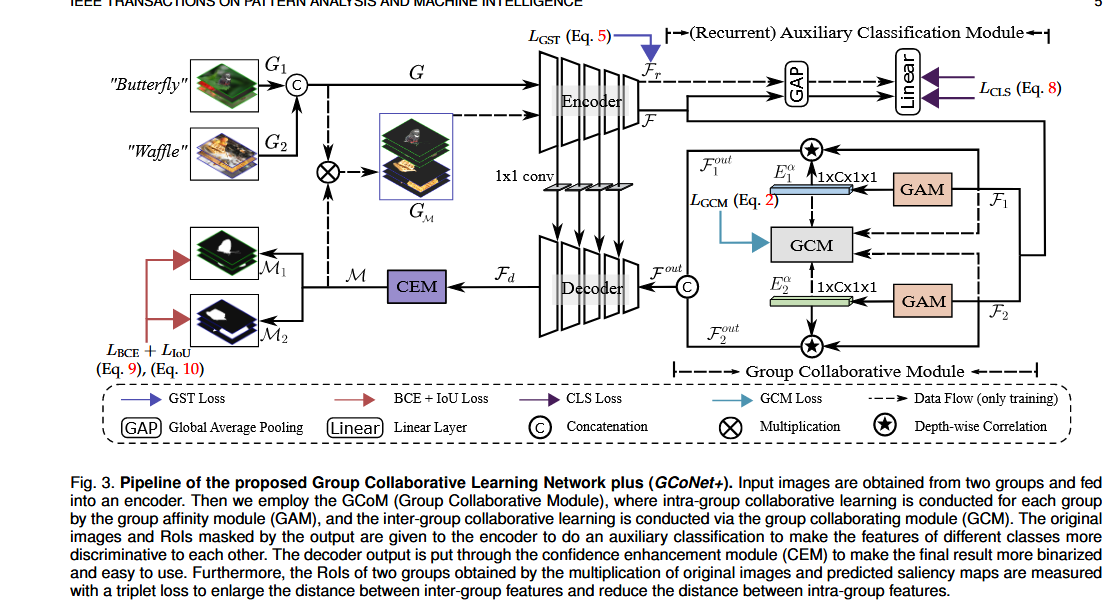
图3. 所提出的群体协作学习网络增强版(GCoNet+)的流程。输入图像来自两个图像组,并被输入到一个编码器中。然后,我们使用群体协作模块(GCoM),在该模块中,群体亲和模块(GAM)对每个组分别进行组内协作学习,而组间协作学习则通过群体协作模块(GCM)来进行。原始图像以及由输出结果所掩蔽的感兴趣区域(RoI)会被送入编码器进行辅助分类,以使不同类别的特征之间更具判别性。解码器的输出会经过置信度增强模块(CEM)处理,从而使最终结果更趋于二值化,且更便于使用。此外,通过将原始图像与预测的显著性图相乘所得到的两个组的感兴趣区域(RoI),会使用三元组损失函数进行度量,以增大组间特征的距离,并缩小组内特征的距离。
问题一:这张图的流程是什么?
这张图展示的是 GCoNet+(Group Collaborative Learning Network Plus) 的完整流程,其核心是通过 组内协作(GAM) 和 组间协作(GCM) 学习共显著目标的共性特征,同时引入 置信度增强模块(CEM) 和 三元组损失 优化输出。
1. 输入与编码器(Encoder)
-
输入图像组:
-
两组图像(如“Butterfly”组和“Waffle”组),每组包含多张同类别的图像(如不同角度/背景的蝴蝶或华夫饼)。
-
-
权重共享编码器:
-
两组图像通过同一个 共享权重的编码器(如VGG或ResNet)提取特征,生成原始特征图
 (尺寸:C×H×W)。
(尺寸:C×H×W)。 -
目的:确保不同组的特征空间一致,便于后续协作学习。
-
2. 组内协作学习(GAM: Group Affinity Module)
-
功能:
对每组图像内部的特征进行融合,生成 组共识特征图(Group Consensus Feature Map),捕捉组内共显著目标的共性。 -
流程:
-
输入:原始特征图
 。
。 -
组内特征融合:
-
通过 深度相关性(Depth-wise Correlation) 计算组内图像特征间的相似性,筛选出共性强的高响应区域。
-
生成共识特征图
 (形状:N×C)。
(形状:N×C)。
-
-
输出:每组一个统一的共识特征向量,抑制组内非共性的背景噪声。
-
3. 组间协作学习(GCM: Group Collaborative Module)
-
功能:
通过跨组对比学习,使不同类别的特征更具区分性(如“蝴蝶”与“华夫饼”)。 -
流程:
-
输入:原始特征
 。
。 -
跨组对比监督:

-
输出:优化后的特征
 。
。
-
4. 解码器(Decoder)与置信度增强模块(CEM)
-
解码器:输入优化特征
 ,通过上采样和跳跃连接恢复空间分辨率,生成初始显著性图
,通过上采样和跳跃连接恢复空间分辨率,生成初始显著性图  。
。 -
CEM模块:
-
对初始显著性图进行二值化增强,使用 GST损失(如结构相似性损失)使输出更清晰。
-
输出:最终二值化显著性图
 。
。
-
5. 三元组损失(Triplet Loss)
-
输入:原始图像与预测显著性图相乘得到的 组卷积核(如“Butterfly”组核和“Waffle”组核)。
-
作用:通过三元组损失扩大组间特征距离(如蝴蝶 vs 华夫饼),缩小组内特征距离(如不同蝴蝶图像)。
6. 辅助分类模块(ACM)与损失函数
-
ACM模块:
-
在共识特征
 上附加分类头(Linear层+Softmax),预测组别标签(如“Butterfly”或“Waffle”)。
上附加分类头(Linear层+Softmax),预测组别标签(如“Butterfly”或“Waffle”)。 -
损失函数:CLS Loss(交叉熵损失)约束高层语义一致性。
-
-
其他损失:
-
BCE + IoU Loss:优化分割精度。
-
GST Loss:增强显著性图的结构一致性。
-
7. 数据流与训练/推理区别
-
训练阶段:完整使用GAM、GCM、ACM、CEM和三元组损失(图中红色虚线标注)。
-
推理阶段:仅保留GAM和CEM模块(蓝色实线路径),移除GCM和ACM以提升效率。
8. 核心创新点总结
-
双路径协作:GAM(组内)提取共性,GCM(组间)抑制干扰。
-
多任务监督:分割(BCE+IoU)、分类(CLS)、结构(GST)、对比(Triplet)联合优化。
-
轻量化推理:仅保留必要模块,平衡性能与效率。
9. 图示符号对应表
3.2 组亲和性模块(GAM)
3.3 组协作模块 (GCM)
3.4 置信度增强模块 (CEM)
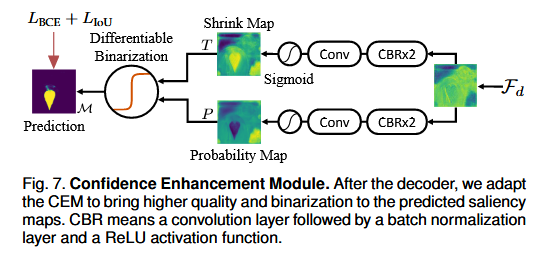
图7. 置信度增强模块。在解码器之后,我们应用置信度增强模块(CEM),以使预测的显著性图具有更高的质量和二值化程度。CBR表示一个卷积层,其后跟着一个批量归一化层和一个ReLU激活函数。
问题一:这张图的流程是什么?
这张图展示的是 置信度增强模块(Confidence Enhancement Module, CEM) 的完整流程,其核心是通过 可微分二值化 和 多层级特征融合 对初始预测的显著性图进行质量优化,最终生成高置信度的二值化分割结果。
1. 输入与模块功能
-
输入:预测显著性图(Prediction):来自解码器的初始显著性图(如Softmax输出的概率图,尺寸 H×W)。
-
功能:
-
解决初始预测的边界模糊问题,生成结构清晰、置信度高的二值化掩码。
-
通过 收缩图(Shrink Map) 和 概率图(Probability Map) 的双路径监督增强鲁棒性。
-
2. 核心流程分步解析
(1) 初始预测与损失计算
-
预测输入(Prediction):初始显著性图 M(可能为未归一化的logits或概率值)。
-
损失函数(LBCE+LIoU):计算二元交叉熵损失(BCE)和交并比损失(IoU),约束预测图与真实标签的匹配度。
(2) 可微分二值化(Differentiable Binarization)
-
二值化处理:
-
通过可微分操作(如Sigmoid或阈值化)将预测图 M 转换为两类输出:
-
收缩图(Shrink Map):生成收缩后的二值图 T,强调目标主体区域(抑制边缘噪声)。
-
概率图(Probability Map):生成概率化二值图 P,保留细节和不确定性区域。
-
-
(3) 双路径特征提取
-
收缩图路径:T 经过 卷积(Conv)→ CBR×2(卷积+批归一化+ReLU)处理,得到中间特征
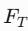 。
。 -
概率图路径:P 经过 Conv → CBR×2 处理,得到中间特征
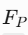 。
。
(4) 特征融合与输出
-
特征融合(
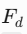 ):将
):将  按通道拼接或相加,通过Sigmoid生成最终置信图
按通道拼接或相加,通过Sigmoid生成最终置信图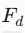 。
。 -
输出优化:
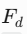 与初始预测 M 结合(如残差连接),输出高置信度的二值化显著性图。
与初始预测 M 结合(如残差连接),输出高置信度的二值化显著性图。
3. 关键操作说明
-
CBR模块:由 卷积(Conv) + 批归一化(BN) + ReLU激活 组成,用于特征非线性变换。
-
可微分二值化:
-
通过Sigmoid函数 σ 实现:
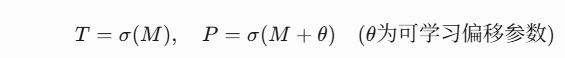
-
确保梯度可回传,支持端到端训练。
-
4. 技术优势
-
双路径监督:收缩图强化主体区域,概率图保留细节,互补提升边界精度。
-
结构清晰性:通过二值化强制分离前景/背景,避免模糊预测。
-
端到端训练:所有操作(包括二值化)可微分,与主网络联合优化。
5. 图示符号对应表

3.5 基于组的对称三元组损失
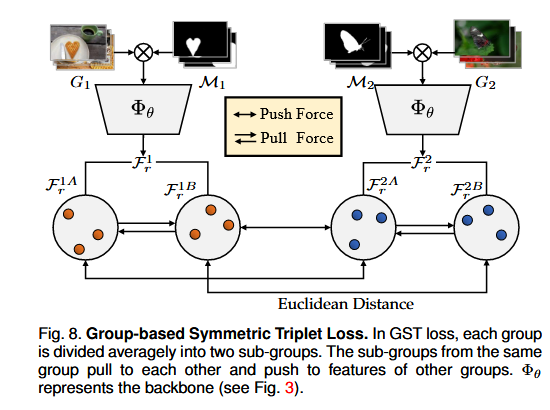
图8. 基于群组的对称三元组损失函数。在基于群组的对称三元组(GST)损失函数中,每个群组被平均划分为两个子群组。来自同一群组的子群组相互吸引,同时排斥其他群组的特征。Φθ表示主干网络(见图3)。
问题一:这张图的流程是什么?
这张图展示的是 基于组的对称三元组损失(Group-based Symmetric Triplet Loss, GST Loss) 的流程设计,其核心是通过 组内拉近(Pull Force) 和 组间推远(Push Force) 优化特征空间分布,从而增强共显著目标的判别性。
1. 输入与预处理
-
输入图像组:两组图像
 (如“吉他”组和“小提琴”组),每组包含多张同类别的图像。
(如“吉他”组和“小提琴”组),每组包含多张同类别的图像。 -
特征提取:通过共享权重的骨干网络
 (如ResNet)提取特征,生成两组特征映射
(如ResNet)提取特征,生成两组特征映射  。
。
2. 子组划分与特征点生成
-
子组划分:
-
每组特征
 均匀划分为两个子组:
均匀划分为两个子组:
-
划分方式:可按空间区域(如上下/左右分块)或随机采样。
-
-
特征点表示:每个子组通过全局平均池化(GAP)或卷积压缩,生成特征向量(图中点状表示)。
3. 对称三元组损失计算
(1) 组内拉近(Pull Force)
-
目标:缩小同一组内子组的特征距离。
-
计算方式:
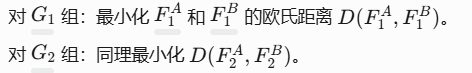
-
数学形式:
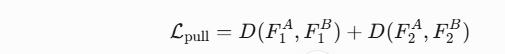
(2) 组间推远(Push Force)
-
目标:扩大不同组间子组的特征距离。
-
计算方式:
-
最大化
 组任意子组间的距离
组任意子组间的距离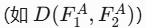 。
。
-
-
数学形式:
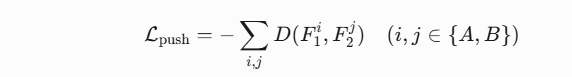
(3) 对称损失整合
-
总损失:
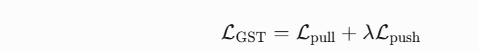
-
λ 为权重系数,平衡拉近与推远的强度。
-
4. 可视化与符号说明
-
图中箭头:
-
灰色双向箭头(Pull Force):组内子组相互拉近。
-
黑色单向箭头(Push Force):组间子组相互推远。
-
-
标注关键点:

-
Euclidean Distance:用于计算特征点间的距离。
-
5. 技术优势
-
对称性设计:每组均分两个子组,避免传统三元组损失中锚点选择的偏差。
-
判别性增强:组内特征更紧凑,组间特征更分散,提升共显著目标的区分度。
-
端到端兼容:可嵌入主网络(如GCoNet)联合训练,无需额外标注。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









