








这里有很多博主说更改环境变量,即
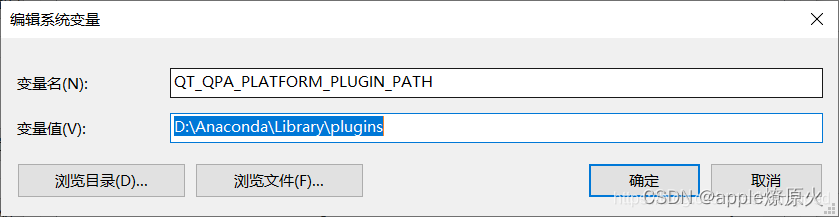
但是这样会引起其他软件的冲突,比如onedrive,还有Microsoft SQL Server Management Studio 18也连接不上主机用户。
我找到另一个方法,就是再加一句
matplotlib.use('TKAgg')就可以了,
下面是一个泰坦尼克号生还者预测的一段代码,利用泰坦尼克号数据建立了回归模型,画出混淆矩阵。matplotlib.use('TKAgg')运用
import pandas as pd
import statsmodels.api as sma
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
import matplotlib.pyplot as plt
from pylab import *
mpl.rcParams['font.sans-serif'] = ['SimHei']
train_set = pd.read_csv('D:\我的文档\研一课程\数理统计\Titanic.csv')
train_set['Sex'].replace(['female', 'male'], [0, 1], inplace=True) # onehot-encoding
print(train_set.isnull().any()) # 统计data里每一列是否有空值
print(train_set.head()) # 查看数据的前五行
train_set['Q'] = train_set.Embarked.apply(lambda x: 1 if x == 'Q' else 0)
train_set['S'] = train_set.Embarked.apply(lambda x: 1 if x == 'S' else 0)
train_set['C'] = train_set.Embarked.apply(lambda x: 1 if x == 'C' else 0)
# print(train_set['Q'])
y = train_set['Survived']
X = train_set[[
'Pclass',
'Sex',
'Age',
'SibSp',
'Parch',
'Fare',
'Q',
'S',
# 'C',
]]
print(train_set.head())
results = sma.Logit(y, X).fit()
print(results.summary())
y_predict = results.predict(X)
y_predict = round(y_predict, 0)
cm = confusion_matrix(y, y_predict)
dl = ['死亡人数', '生存人数']
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=dl)
disp = ConfusionMatrixDisplay(confusion_matrix=cm)
matplotlib.use('TKAgg')
disp.plot()
plt.xticks(fontsize=15)
plt.yticks(fontsize=15)
plt.ylabel('实际情况', fontsize=15)
plt.xlabel('预测情况', fontsize=15)
plt.show()新手上路,多多指教,文明留言!















 994
994











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









