






大家好,我是小寒~
从今天开始,我们开始分享 FLink 系列相关的文章。如果喜欢,记得关注一波。
在Flink中有四大基石,分别是 Time、Window、CheckPoint 和 State,今天我们就先来分享一下 FLink 中的时间和窗口概念。
我们都知道flink是流式的、实时的计算引擎。
所谓的流式就是指数据源源不断的流进来,是一个无界的数据流,但是我们在进行计算的时候必须在一个有边界的范围内进行,那边界该如何确定呢?无非就两种方式,根据时间段或者数据量进行确定,根据时间段就是每隔多长时间就划分一个边界,根据数据量就是每来多少条数据划分一个边界。

时间
如果以时间段进行数据划分的话,那么时间就是一个非常重要的概念。FLink中包括三种时间概念。
EventTime
事件时间指事件发生的时间,一旦确定之后再也不会改变。它通常由事件中的时间戳描述,例如采集的日志数据中,每一条日志都会记录自己的生成时间,Flink 通过时间戳分配器访问事件时间戳。
使用事件时间的好处是不依赖操作系统的时钟,无论执行多少次,可以保证计算结果是一样的。
Ingestion Time
摄取时间是指事件进入流处理系统的时间,对于一个事件来说,使用其被读取的那一刻的时间戳作作为摄取时间。
Processing Time
处理时间指消息被计算引擎处理的时间,以各个计算节点在的本地时间为准。
窗口
流式计算是一种被设计用于处理无限数据集的数据处理引擎,而 window 是一种切割无限数据流为有限数据块的手段。所以 Window 是无限数据流处理的核心,Window 将一个无限的 stream 拆分成有限大小的“桶”,我们可以在这些桶上做计算操作。
窗口划分有两种方式,即按时间驱动进行划分(Time Window)和按数据量(Count Window)驱动进行划分。

Time Window
Time Window 可以根据窗口实现原理的不同分成三类,即滚动时间窗口(Tumbling Time Window)、滑动时间窗口(Sliding Time Window)和会话窗口(Session Window)。
Tumbling Time Window
将数据依据固定的窗口长度对数据进行划分。
特点:时间对齐,窗口长度固定,没有重叠。
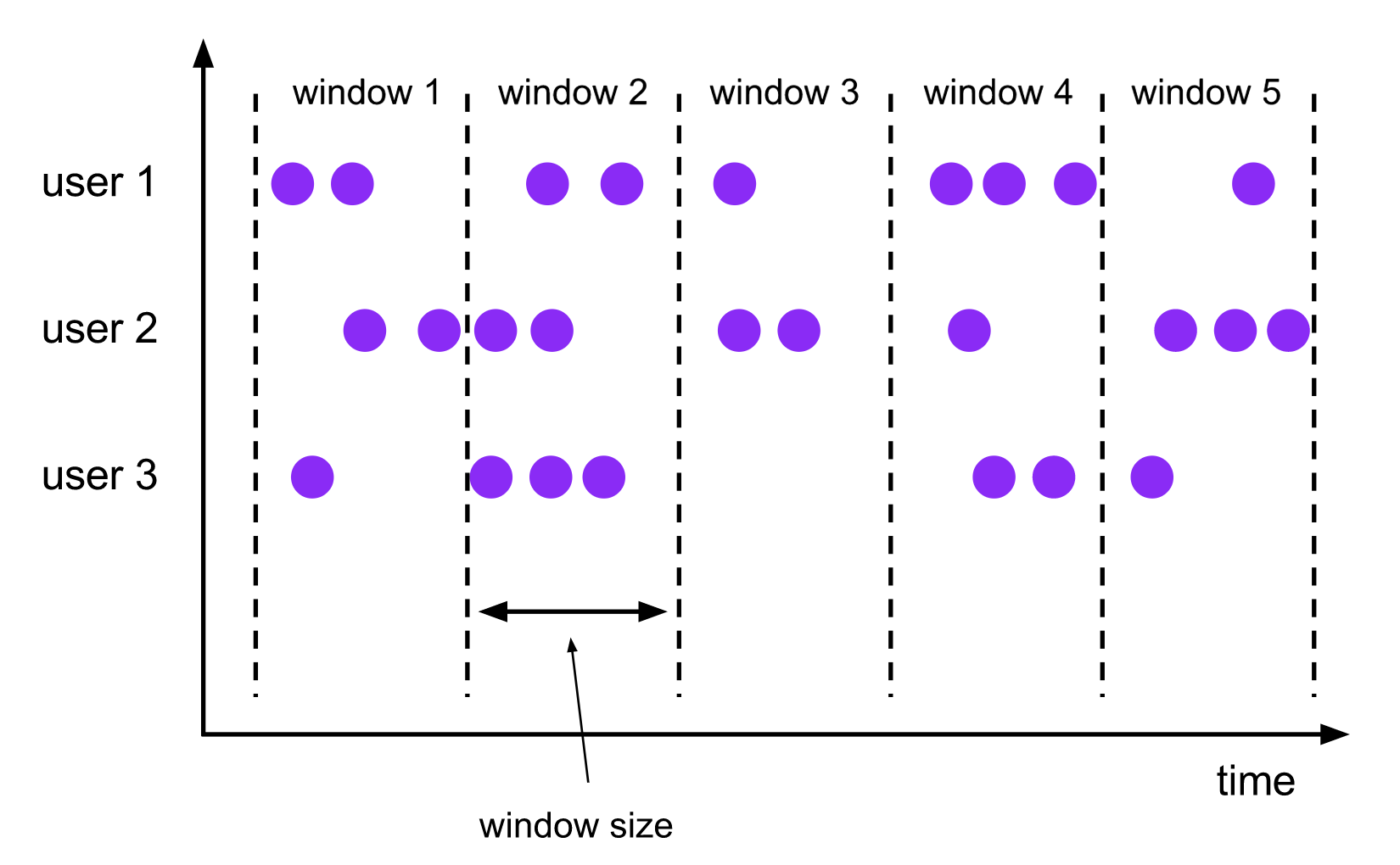
Sliding Time Window
滑动窗口由固定的窗口长度和滑动间隔组成。
特点:时间对齐,窗口长度固定,有重叠。
Session Window
session 窗口分配器通过 session 活动来对元素进行分组,session 窗口跟滚动窗口和滑动窗口相比,不会有重叠和固定的开始时间和结束时间的情况,相反,当它在一个固定的时间周期内不再收到元素,即非活动间隔产生,那么这个窗口就会关闭。
一个 session 窗口通过一个 session 间隔来配置,这个 session 间隔定义了非活跃周期的长度,当这个非活跃周期产生,那么当前的 session 窗口将关闭并且后续的元素将被分配到新的 session 窗口中去。
特点:无法事先确定窗口的长度、元素个数,窗口之间也不会相互重叠。
Count Window
Count Window 分为滚动计数窗口(Tumbling Count Window)、滑动计数窗口(Sliding Count Window)。
滚动计数窗口
滚动计数窗口和滚动时间窗口类似,只不过滚动计数窗口是按照元素的个数进行划分,而滚动时间窗口是按照时间来进行划分。
特点:累积固定个数的元素就视为一个窗口,该类型的窗口无法和时间窗口一样事先切分好。窗口元素个数相等,窗口长度不固定,无重叠。
滑动计数窗口
滑动计数窗口和滑动时间窗口类似。
特点:窗口元素个数相等,窗口长度不固定,有重叠。
窗口的原理与机制
WindowAssigner
每个数据元素进入窗口算子时,首先会被交给 WindowAssigner,WindowAssigner 决定元素被放到哪个或哪些窗口中(因为一个元素有可能属于多个窗口),在这个过程中可能会创建新窗口或者合并旧的窗口 。
数据进入窗口时,分配窗口和计算的逻辑如下图所示:
这里有一点需要注意,Window 本身只是一个 ID 标识符,其内部可能存储了一些元数据,如 TimeWindow 中有开始和结束时间,但是并不会存储窗口中的元素。窗口中的元素实际存储在 Key/Value State 中,key 为 Window,value 为元素集合(或聚合值)。为了保证窗口的容错性,该实现依赖了 Flink 的 State 机制。
Window Trigger
从上图中我们可以看到,每个 window 都有一个 Trigger,Trigger 上有定时器,用来决定一个窗口何时能够被计算或清除。每当有元素被分配到该窗口,或者之前注册的定时器超时了,那么 Trigger 都会被调用。
Trigger 触发的结果如下:
-
Continue:继续。不做任何操作。
-
Fire: 触发计算,处理窗口数据。
-
Purge: 触发清理,移除窗口和窗口中的数据。
-
Fire + Purge :触发计算+清理,处理数据并移除窗口和窗口中的数据
当数据到来的时候,调用 Trigger 判断是否需要触发计算,如果调用结果只是 Fire,则计算窗口并保留窗口原样,窗口中的数据不清理,数据保恃不变,等待下次触发计算的时候再次执行计算。窗口中的数据会被反复计算,直到触发结果是 Purge 。在清理之前,窗口和数据不会释放,所以窗口会一直占用内存。
Trigger 触发流程如下:
-
当 Trigger 触发结果是 Fire 时,窗口中的元素集合就会交给 Evictor(如果指定了的话)。Evictor 主要用来遍历窗口中的元素列表,并决定最先进入窗口的多少个元素需要被移除。剩余的元素会交给用户指定的函数进行窗口的计算。如果没有Evictor 的话,窗口中的所有元素会一起交给函数进行计算。
-
计算函数收到窗口的元素(可能经过 Evictor 的过滤 ),计算出窗口的结果值,并发送给下游。窗口的结果值可以是一个也可以是多个。 DataStream API 上可以接收不同类型的计算函数,包括预定义的 sum(),min(),max(),还有 ReduceFunction,FoldFunction,还有 WindowFunction。WindowFunction 是最通用的计算函数,其他的预定义的函数基本都是基于该函数实现的。
-
Flink 对于一些聚合类的窗口计算(如 sum )做了优化,因为聚合类的计算不需要将窗口中的所有数据都保存下来,只需要保存一个 result 值就可以了。每个进入窗口的元素都会执行一次聚合函数并修改 result 值。这样可以大大降低内存的消耗并提升性能。但是如果用户定义了 Evictor,则不会启用对聚合窗口的优化,因为 Evictor 需要遍历窗口中的所有元素,必须将窗口中所有元素都存下来。
Window Evictor
Window Evictor 可以理解为窗口数据的过滤器。Evictor 可在 Window Function 执行前或后,从 Window 中过滤元素。 Flink 内置了三种窗口数据过滤器。

Delta Evictor
阀值过滤器。本质上来说就是一个自定义规则,计算窗口中每个数据记录,然后与一个事先定义好的阀值做比较,丢弃超过阀值的数据记录。
CountEvictor
计数过滤器。在Window中保留指定数量的元素。并从窗口头部开始丢弃其余元素。
TimeEvictor
时间过滤器。保留Window中最近一段时间内的元素,并丢弃其余元素。
Window 函数
数据经过 WindowAssigner 后,已经被分配到不同的 Window 中,接下来要通过窗口函数对窗口内的数据进行处理。窗口函数主要分为两种。
1、增量计算函数
增量计算函数指的是窗口保存一份中间数据,每流入一个新元素,新元素都会和中间数据两两合一,生成新的中间数据,再保存到窗口中,如 ReduceFunction、AggregateFunction、FoldFunction。
增量计算的优点是数据到达后立即计算,窗口只保留中间结果,计算效率高,但是增量计算函数模式是事先确定的,能够满足大部分的计算需求,对于特殊业务需求可能无法满足。
2、全量计算函数
全量计算指的是先缓存该窗口的所有元素,等到触发条件后对窗口内的所有元素执行计算。Flink 内置的 ProcessWindowFunction 就是全量计算函数,通过全量缓存,实现灵活计算,计算效率比增量聚合稍低,毕竟要占用更多的内存。
WaterMark(水印)
在流处理中,从事件的产生,到Flink读取到数据,再到 Flink 多个算子处理数据,在这个过程中会受到网络、背压等原因,导致数据是乱序的。所谓乱序,就是指 Flink 接收到的事件的先后顺序不是严格按照事件的 Event Time 顺序排列的。
为了保证计算结果的正确性,需要等待数据,这带来了计算的延迟。对于延迟太久的数据,不可能无限期地等下去,所以必须有一个机制,来保证特定的时间后,一定会触发窗口进行计算,这个触发机制就是 WaterMark。
Watermark 是用于处理乱序事件的,而正确的处理乱序事件,通常用 Watermark 机制结合 Window 来实现。
数据流中的 Watermark 用于表示 timestamp 小于 Watermark 的数据,都已经到达了,因此,Window 的执行也是由 Watermark 触发的。
Watermark 可以理解成一个延迟触发机制,我们可以设置 Watermark 的延时时长 t,每次系统会校验已经到达的数据中最大的事件时间 maxEventTime,然后认定 EventTime 小于 maxEventTime - t 的所有数据都已经到达,如果有窗口的停止时间小于等于 maxEventTime – t,那么这个窗口就会被触发执行。
上图中,我们设置的允许最大延迟到达时间为 2s,所以时间戳为 7s 的事件对应的 Watermark 是 5s,时间戳为 12s 的事件的 Watermark 是 10s,如果我们的窗口1 是 1s~5s,窗口2 是 6s~10s,那么时间戳为 7s 的事件到达时的 Watermarker 恰好触发窗口1,时间戳为 12s 的事件到达时的 Watermark 恰好触发窗口2。
多流的 WaterMark
在实际的流计算中,一个作业往往会处理多个 Source 的数据,多 Source 的数据进行 GroupBy 分组,那么来自不同 Source 的相同 key 值会 shuffle 到同一个处理节点,并携带各自的 WaterMark。Flink 内部要保证 WaterMark 保持单调递增,多个 Source 的 WaterMark 汇集到一起可能不是单调递增的,Flink 会选择所有流中最小的 WaterMark 向下游发送。
如上图所示,Source 算子产生各自的 WaterMark,并随着数据流流向下游的 map 算子,map 算子是无状态计算,所以会将 WaterMark 向下透传。Window 算子收到上游两个输入的 WaterMark 后,选择其中较小的发送给下游。














 9876
9876











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









