







 本文介绍了Orchestrator对MySQL集群的管理。它可自动发现集群拓扑并存储信息,能自由重构复制集拓扑,自动探测故障并恢复,实现高可用。还阐述了其架构,包括单点、多点共享后端、多点非共享后端模式,最后说明了配置文件和部署步骤。
本文介绍了Orchestrator对MySQL集群的管理。它可自动发现集群拓扑并存储信息,能自由重构复制集拓扑,自动探测故障并恢复,实现高可用。还阐述了其架构,包括单点、多点共享后端、多点非共享后端模式,最后说明了配置文件和部署步骤。
Orchestrator
Orchestrator是一个MySQL高可用和复制集管理工具平台,其具有如下主要功能:
- 可以自动发现MySQL集群,通过mysql节点信息获取相关slave的信息,进而获取整个集群拓扑结构并将信息存储在后端数据库中
- 基于复制集管理规则,提供自由重构复制集拓扑结构的功能,如将某个slave节点移动到其他master下
- 自动探测故障并采取相应恢复措施,实现MySQL服务高可用的目的,减少人工介入
- 提供web UI,API以及命令行等入口操作,方便用户监控和操作集群
一、特性
1. Discover(发现)
orchestrator主动搜寻MySQL拓扑并进行映射。它能读取基本的MySQL信息,例如复制状态和配置。即使遇到故障,也可以为MySQL环境的拓扑提供流畅的可视化效果,包括复制问题。
2. Refactoring(重构)
orchestrator了解复制规则。它知道binlog文件:位置,GTID,伪GTID,Binlog服务器。重构复制拓扑可以是将副本拖放到另一个主副本下的问题。移动副本是安全的:orchestrator将拒绝非法的重构尝试。通过各种命令行选项可以实现细粒度的控制。
3. Recover(恢复)
orchestrator使用全面方法来检测主库故障和级联中间主库的故障。根据从拓扑本身获得的信息,它可以识别各种故障情况。可通过配置,orchestrator可以选择执行自动恢复(或允许用户选择手动恢复的类型)。在内部实现中间主库的恢复。orchestrator通过Hooks进行自定义脚本支持故障切换。
二、架构
-
针对复制提供故障切换,从库故障发现。基于GTID+增强半同步的高可用架构。
-
生产环境建议使用多点非共享架构,开启reft保证Orchestrator自身高可用。
-
同时需要注意的是,Orchestrator的server端需要和对外提供服务的MySQL放在一起的,Orchestrator的专属后端可以放到远程服务器上,这点在配置文件中也有体现。
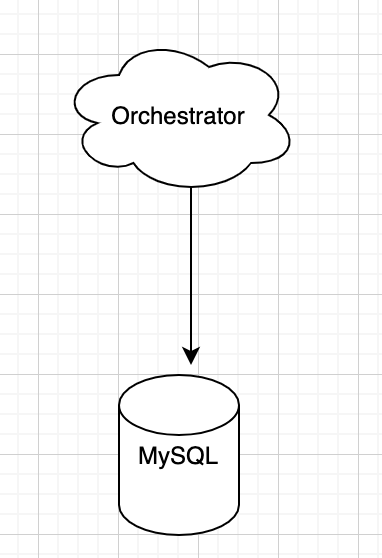
1. 单点模式
单个Orchestrator对应单个后端MySQL
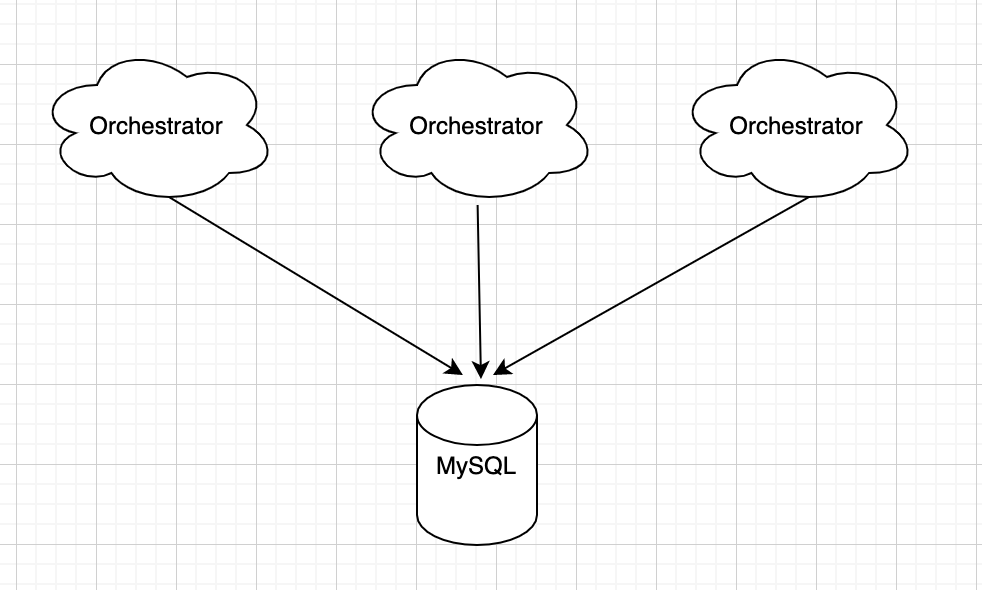
2. 多点共享后端
(1)后端单点
后端可以为单点写或者主从模式,多个Orchestrator共享一个写节点后端
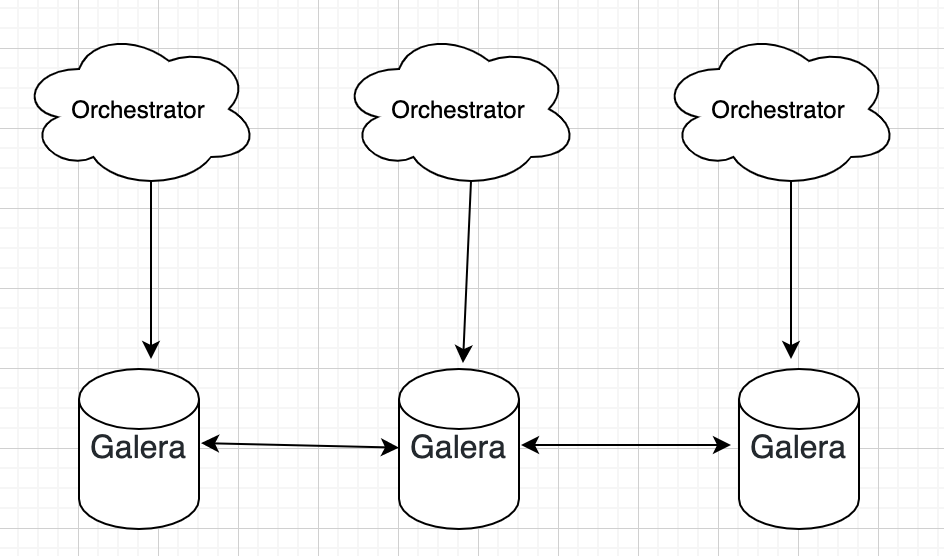
(2)后端多点
后端为多点写集群模式,Orchestrator之间数据相互同步
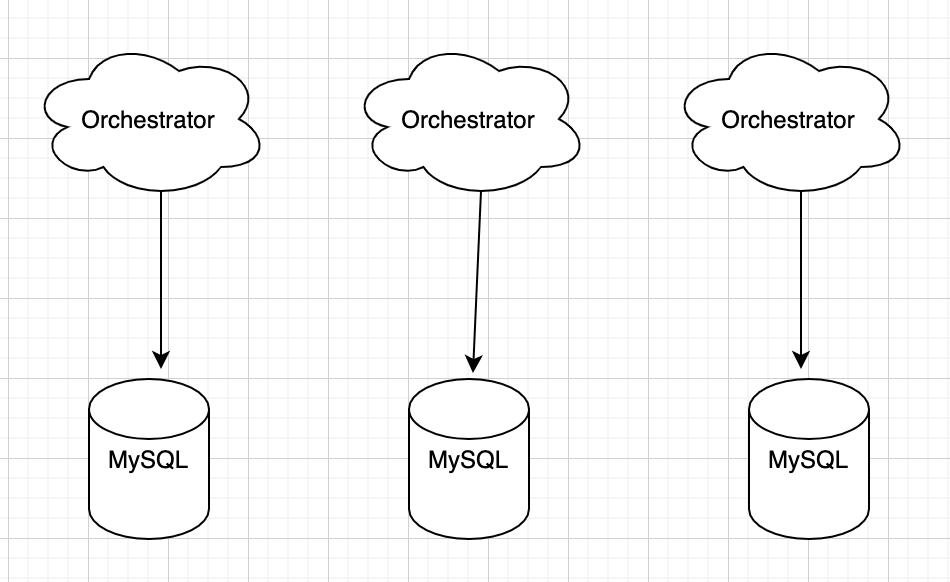
3. 多点非共享后端
后端相互独立,每个后端为自己的Orchestrator提供服务
三、配置文件
{
"Debug": true, #debug模式,输出详细信息
"EnableSyslog": false, #是否输出到系统日志里
"ListenAddress": ":3000", #orchestrator的监听端口,web端口
"MySQLTopologyUser": "failover", #后端被管理的mysql实例中的账号,所有实例都要有,本次为3307端口
"MySQLTopologyPassword": "123456", #密码
"MySQLTopologyCredentialsConfigFile": "", #验证的配置文件,账号密码可以直接写入文件,读取
"MySQLTopologySSLPrivateKeyFile": "", #ssl验证文件
"MySQLTopologySSLCertFile": "",
"MySQLTopologySSLCAFile": "",
"MySQLTopologySSLSkipVerify": true, #跳过验证
"MySQLTopologyUseMutualTLS": false, #使用TLS验证
"MySQLOrchestratorHost": "127.0.0.1", #orchestrator的IP,也可以是本机IP
"MySQLOrchestratorPort": 3306, #orchestrator所在的端口,本次为3306
"MySQLOrchestratorDatabase": "orchestrator", #orchestrator元数据的数据库名称
"MySQLOrchestratorUser": "root", #管理orchestrator数据库的账户
"MySQLOrchestratorPassword": "123456", #密码
"MySQLOrchestratorCredentialsConfigFile": "",
"MySQLOrchestratorSSLPrivateKeyFile": "",
"MySQLOrchestratorSSLCertFile": "",
"MySQLOrchestratorSSLCAFile": "",
"MySQLOrchestratorSSLSkipVerify": true,
"MySQLOrchestratorUseMutualTLS": false,
"MySQLConnectTimeoutSeconds": 1, #orchestrator连接mysql超时秒数
"DefaultInstancePort": 3307, #mysql实例的端口,本次为3307,对外提供服务的实例
"DiscoverByShowSlaveHosts": true, #是否启用审查和自动发现
"InstancePollSeconds": 5, #orchestrator探测mysql间隔秒数
"SkipMaxScaleCheck": true, #没有MaxScale binlogserver设置为true
"UnseenInstanceForgetHours": 240, #忘记看不见的实例的小时数
"SnapshotTopologiesIntervalHours": 0, #快照拓扑调用之间的小时间隔。默认值:0(禁用)
"InstanceBulkOperationsWaitTimeoutSeconds": 10, #执行批量(多个实例)操作时在单个实例上等待的时间
"HostnameResolveMethod": "none", #解析主机名,默认default 不解析为none
"MySQLHostnameResolveMethod": "@@hostname", #MySQL主机名解析
"SkipBinlogServerUnresolveCheck": true, #跳 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











