







目录
3.4.2.1 FilelnputStream(文件字节输入流)
3.4.2.2 FileOutputstream(文件字节输出流)
3.4.5.1 BufferedInputStream 与 BufferedOutputStream(字节缓冲流)
3.4.5.2 BufferedReader 与 BufferedWriter(字符缓冲流)
3.4.6.2 InputStreamReader(字符输入转换流)
3.4.6.3 OutputStreamWriter(字符输出转换流)
3.4.8.1 DataOutputstream(数据输出流)
3.4.8.2 Datalnputstream(数据输入流)
3.4.9.1 ObjectOutputstream(对象字节输出流)
前言
常用API笔记复盘【完】,后续内容在日志文件中更新!
一、集合进阶
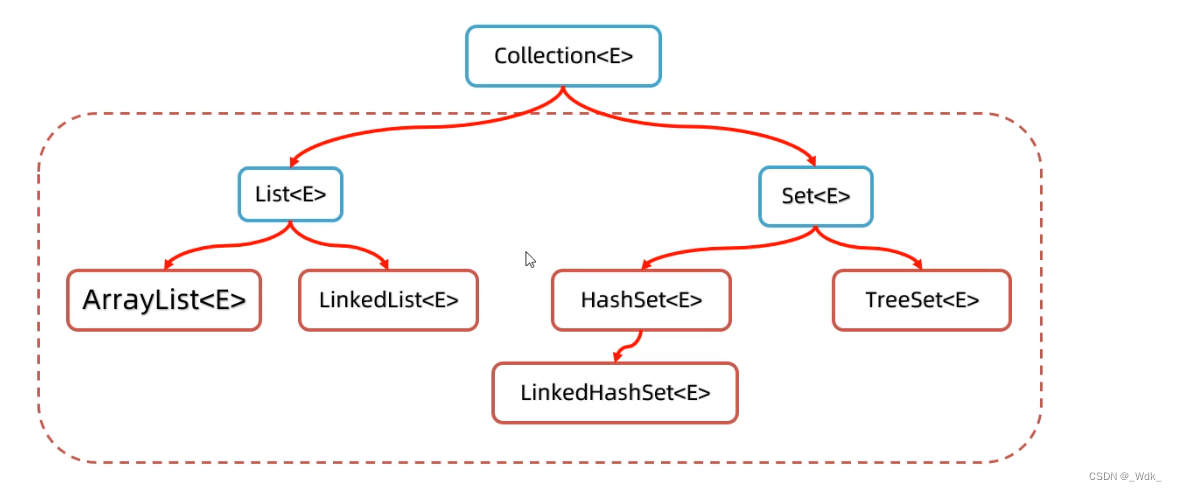
1.1 集合体系概述

- Collection代表单列集合,每个元素(数据)只包含一个值
- Map代表双列集合,每个元素包含两个值(键值对)

Collection集合特点
- List系列集合:添加的元素是有序、可重复、有索引
- ArrayList、LinekdList:有序、可重复、有索引
- Set系列集合:添加的元素是无序、不重复、无索引
- Hashset:无序、不重复、无索引
- LinkedHashset:有序、不重复、无索引
- Treeset:按照大小默认升序排序、不重复、无索引
-
package com.itheima.d1_collection; import java.util.ArrayList; import java.util.HashSet; public class CollectionTest1 { public static void main(String[] args) { //简单确认一下Collection集合的特点 ArrayList<String> list=new ArrayList<>();//有序 可重复 有索引 list.add("java1"); list.add("java2"); list.add("java1"); list.add("java2"); System.out.println(list); HashSet<String> set=new HashSet<>();//无序 不可重复 set.add("java1"); set.add("java1"); set.add("java2"); set.add("java2"); System.out.println(set); } }
1.2 Collection的常用方法
Collection是单列集合的祖宗,它规定的方法(功能)是全部单列集合都会继承的。
CollectionTest.class
package com.itheima.d1_collection;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collection;
public class CollectionTest2 {
public static void main(String[] args) {
Collection<String> c = new ArrayList<>();//多态写法
//1.public boolean add(E e):添加元素,添加成功返回true。
c.add("java1");
c.add("java1");
c.add("java2");
c.add("java2");
c.add("java3");
System.out.println(c);
// 2.public void clear():清空集合的元素。
// c.clear();
// System.out.println(c);
// 3.public boolean isEmpty():判断集合是否为空 是空返回true,反之。
System.out.println(c.isEmpty());
// 4.public int size():获取集合的大小。
System.out.println(c.size());
//5.public boolean contains(Object obj):判断集合中是否包含某个元素。
System.out.println(c.contains("java1"));
System.out.println(c.contains("java4"));
// 6.public boolean remove(E e):删除某个元素:如果有多个重复元素默认删除前面的第一个!
c.remove("java1");
System.out.println(c);
// 7.public Object[]toArray():把集合转换成数组
Object[] arr = c.toArray();
System.out.println(Arrays.toString(arr));
String []arr2=c.toArray(new String[c.size()]);
System.out.println(Arrays.toString(arr2));
System.out.println("==============================================================================================");
// 把一个集合的全部数据倒入到另一个集合中去。
Collection<String> c1=new ArrayList<>();
c1.add("java1");
c1.add("java2");
Collection<String> c2=new ArrayList<>();
c2.add("java3");
c2.add("java4");
c1.addAll(c2);//就是把c2集合的全部数据倒入到c1集合中去
System.out.println(c1);
System.out.println(c2);
}
}
1.3 Collection的遍历方式
1.3.1 迭代器
概述:迭代器是用来遍历集合的专用方式(数组没有迭代器),在java中迭代器的代表是Iterator

package com.itheima.collection_traverse;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class CollectionDemo01 {
public static void main(String[] args) {
Collection<String> c=new ArrayList<>();
c.add("赵敏");
c.add("小灶");
c.add("苏苏");
c.add("哈哈");
System.out.println(c);
// 使用迭代器遍历集合
// 1、从集合对象中获取选代器对象。
Iterator<String> it=c.iterator();
// System.out.println(it.next());
// System.out.println(it.next());
// System.out.println(it.next());
// System.out.println(it.next());
// System.out.println(it.next());//报异常,取不到数据了
while (it.hasNext()){
String ele=it.next();
System.out.println(ele);
}
}
}
1.3.2 增强for循环
- 增强for可以用来遍历集合或者数组。
- 增强for遍历集合,本质就是迭代器遍历集合的简化写法。

package com.itheima.collection_traverse;
import java.util.ArrayList;
import java.util.Collection;
public class CollectionDemo02 {
public static void main(String[] args) {
Collection<String> c=new ArrayList<>();
c.add("赵敏");
c.add("小灶");
c.add("苏苏");
c.add("哈哈");
System.out.println(c);
// 使用增强for遍历集合或者数组。
for(String ele:c){
System.out.println(ele);
}
String [] numbers={"1","2","3"};
for(String number:numbers){
System.out.println(number);
}
}
}
1.3.3 Lambda表达式遍历集合
得益于JDK 8开始的新技术Lambda表达式,提供了一种更简单、更直接的方式来遍历集合。

package com.itheima.collection_traverse;
import java.util.ArrayList;
import java.util.Collection;
import java.util.function.Consumer;
public class CollectionDemo03 {
public static void main(String[] args) {
Collection<String> c = new ArrayList<>();
c.add("赵敏");
c.add("小灶");
c.add("苏苏");
c.add("哈哈");
System.out.println(c);
c.forEach(new Consumer<String>() {
@Override
public void accept(String s) {
System.out.println(s);
}
});
c.forEach((String s) -> {
System.out.println(s);
});
c.forEach(s -> {
System.out.println(s);
});
c.forEach(s -> System.out.println(s));
c.forEach(System.out::println);
}
}
1.4 案例遍历集合中的自定义对象

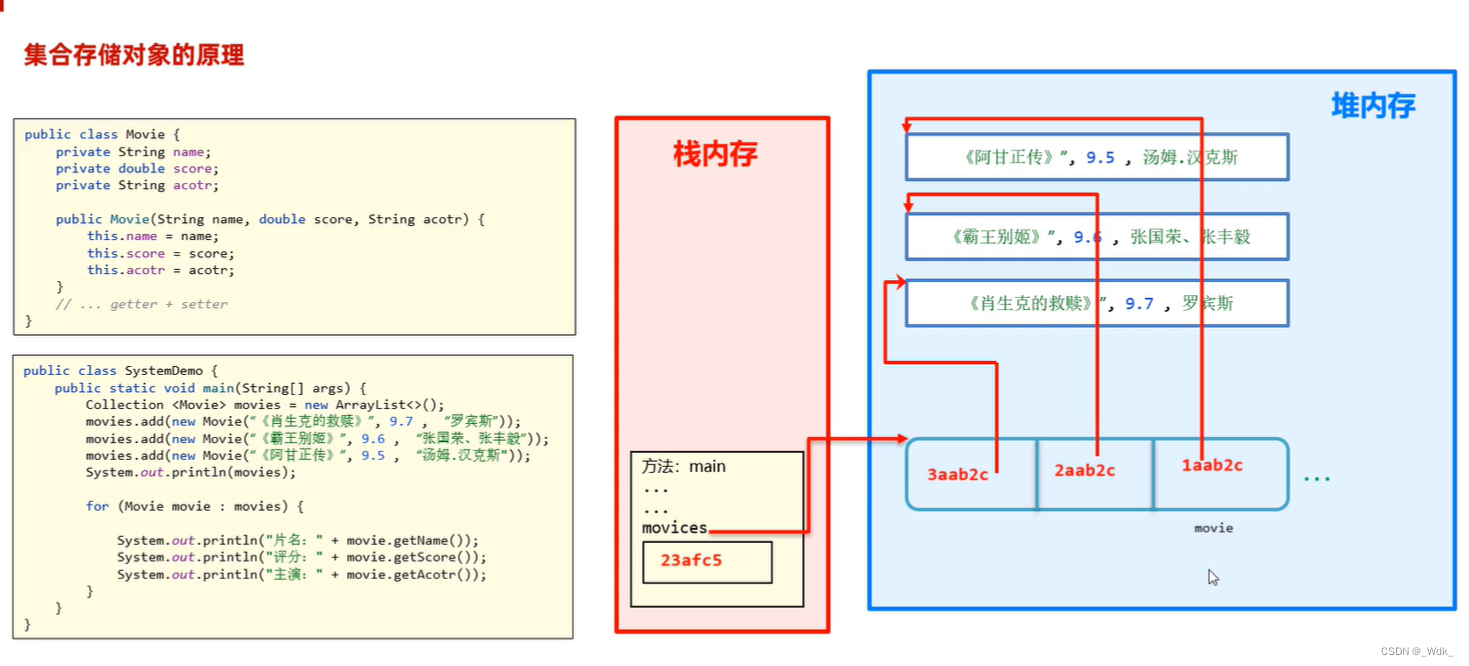
1、集合中存储的是元素的什么信息?
集合中存储的是元素对象的地址
Movie.class
package com.itheima.collection_traverse;
public class Movie {
private String name;
private double score;
private String actor;
@Override
public String toString() {
return "Movie{" +
"name='" + name + '\'' +
", score=" + score +
", actor='" + actor + '\'' +
'}';
}
public Movie() {
}
public Movie(String name, double score, String actor) {
this.name = name;
this.score = score;
this.actor = actor;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getScore() {
return score;
}
public void setScore(double score) {
this.score = score;
}
public String getActor() {
return actor;
}
public void setActor(String actor) {
this.actor = actor;
}
}
CollectionTest.class
package com.itheima.collection_traverse;
import java.util.ArrayList;
import java.util.Collection;
public class CollectionDemo04 {
// new Movie("《肖申克的救赎》", 9.7, "弗兰克·德拉邦特")
// new Movie("《霸王别姬》", 9.6, "张国荣、张丰毅")
// new Movie("《阿甘正传》", 9.5" "汤姆汉斯")
public static void main(String[] args) {
// 1、创建一个集合容器负责存储多部电影对象。
Collection<Movie> movies=new ArrayList<>();
movies.add(new Movie("《肖申克的救赎》", 9.7, "弗兰克·德拉邦特"));
movies.add(new Movie("《霸王别姬》", 9.6, "张国荣、张丰毅"));
movies.add(new Movie("《阿甘正传》", 9.5, "汤姆汉斯"));
System.out.println(movies);
for (Movie movie : movies) {
System.out.println("电影名:"+movie.getName());
System.out.println("评分:"+movie.getScore());
System.out.println("主演:"+movie.getActor());
System.out.println("=======================");
}
}
}
1.5 List集合
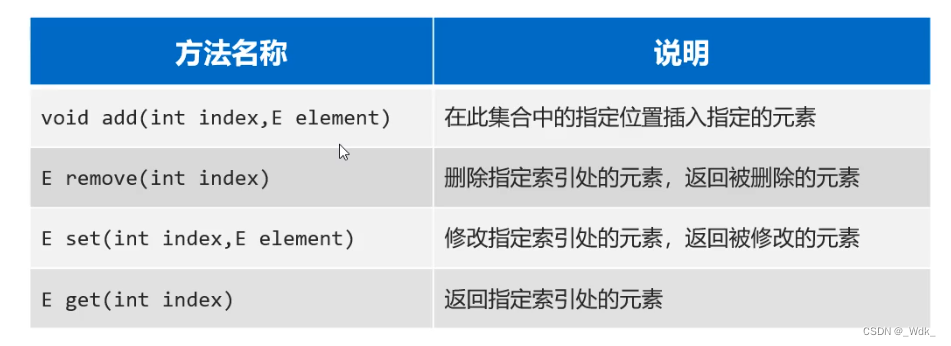
1.5.1 List集合的特有方法
List集合因为支持索引,所以多了很多与索引相关的方法,当然,Collection的功能List也都继承了。
package com.itheima.collection_list;
import java.util.ArrayList;
import java.util.List;
public class ListTest1 {
public static void main(String[] args) {
//1.创建一个ArrayList集合对象(有序、可重复、有索引)
List<String> list = new ArrayList<>();//经典代码
list.add("张三");
list.add("李四");
list.add("李四");
list.add("赵六");
System.out.println(list);
// 2.public void add(int index,E element):在某个案引位置插入元素。
list.add(2,"王五");
System.out.println(list);
//3.public E remove(int index):根据索引删除元素,返回被删除元素
System.out.println(list.remove(2));
System.out.println(list);
// 4.public E get(int index): 返回集合中指定位置的元素。
System.out.println(list.get(3));
// 5.public E set(int index,E element): 修改索引位置处的元素,修改成功后,会返回原来的数据
System.out.println(list.set(3, "赵四"));
System.out.println(list);
}
}
1.5.2 List集合的遍历方式
- for循环(因为List集合有索引)
- 迭代器
- 增强for循环
- Lambda表达式
package com.itheima.collection_list;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class ListTest2 {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("张三");
list.add("李四");
list.add("王五");
//(1)for循环
for (int i = 0; i < list.size(); i++) {
//i=0 1 2
String s = list.get(i);
System.out.println(s);
}
System.out.println("==========================================");
//(2)选代器。
Iterator<String> it = list.iterator();
while (it.hasNext()) {
String ele= it.next();
System.out.println(ele);
}
System.out.println("==========================================");
//(3)增for循环(foreach遍历)
for (String s : list) {
System.out.println(s);
}
System.out.println("==========================================");
//(4)JDK 1.8开始之后的Lambda表达式
list.forEach(System.out::println);
}
}
1.5.3 ArrayList集合的底层原理与应用场景
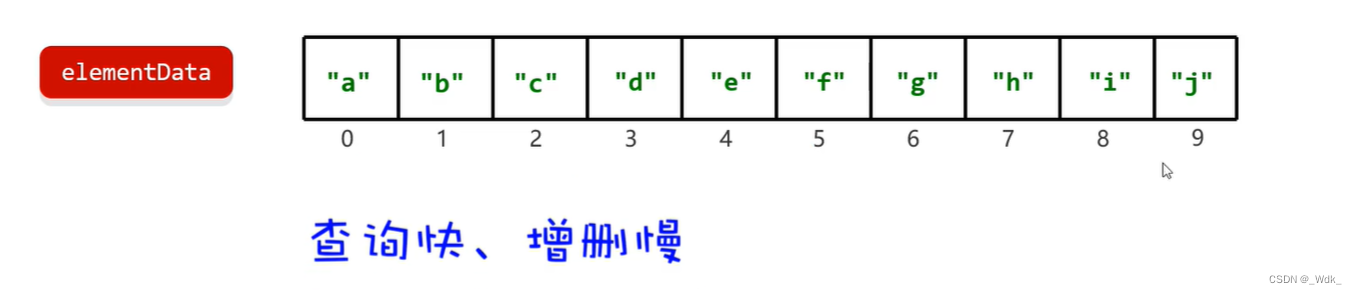
ArrayList:有序,可重复,有索引。
基于数组实现的
- 查询速度快(注意:是根据索引查询数据快):查询数据通过地址值和索引定位,查询任意数据耗时相同。
- 删除效率低:可能需要把后面很多的数据进行前移。
- 添加效率极低:可能需要把后面很多的数据后移,再添加元素;或者也可能需要进行数组的扩容
- 利用无参构造器创建的集合,会在底层创建一个默认长度为0的数组
- 添加第一个元素时,底层会创建一个新的长度为10的数组
- 存满时,会扩容1.5倍
- 如果一次添加多个元素,1.5倍还放不下,则新创建数组的长度以实际为准
-
应用场景
- ArrayList适合:根据索引查询数据比如根据随机索引取数据(高效)!或者数据量不是很大时!
- ArrayList不适合:数据量大的同时又要频繁的进行增删操作!
1.5.4 LinkedList集合的底层原理
基于双链表实现的
链表中的结点是独立的对象,在内存中是不连续的,每个结点包含数据值和下一个结点的地址
- 链表的特点1:查询慢,无论查询哪个数据都要从头开始找,
- 链表的特点2:链表增删相对快
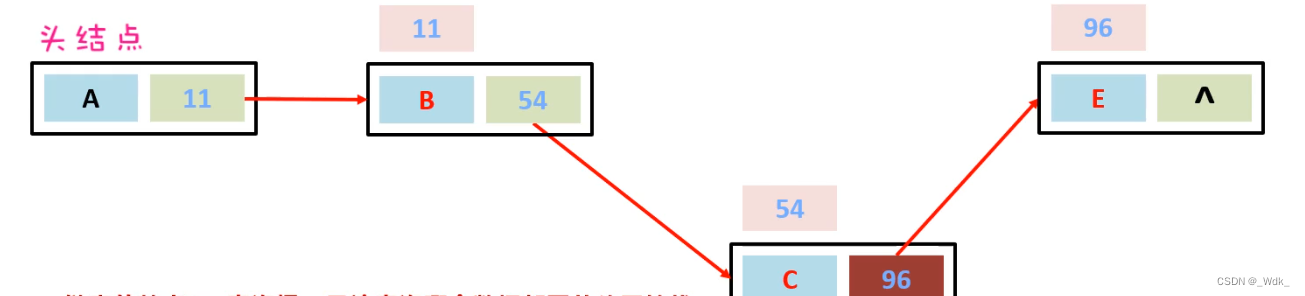
特点:查询慢,增删相对较快,但对首尾元素进行增删改查的速度是极快的


应用场景
LinkedList的应用场景之一:可以用来设计队列
package com.itheima.collection_list;
import java.util.LinkedList;
public class ListTest3 {
public static void main(String[] args) {
// 创建一个队列
LinkedList<String> queue=new LinkedList<>();
queue.addLast("第1号人");
queue.addLast("第2号人");
queue.addLast("第3号人");
queue.addLast("第4号人");
System.out.println(queue);
//出队
System.out.println(queue.removeFirst());
}
}
LinkedList的应用场景之一:可以用来设计栈
package com.itheima.collection_list;
import java.util.LinkedList;
public class ListTest3 {
public static void main(String[] args) {
// 1、创建一个队列
LinkedList<String> queue=new LinkedList<>();
queue.addLast("第1号人");
queue.addLast("第2号人");
queue.addLast("第3号人");
queue.addLast("第4号人");
System.out.println(queue);
//出队
System.out.println(queue.removeFirst());
System.out.println("==========================================");
//2、 创建一个栈对象
//入栈
// LinkedList<String> stack=new LinkedList<>();
// stack.addFirst("第1颗子弹");
// stack.addFirst("第2颗子弹");
// stack.addFirst("第3颗子弹");
// stack.addFirst("第4颗子弹");
// System.out.println(stack);
// //出栈
// System.out.println(stack.removeFirst());
// System.out.println(stack.removeFirst());
// System.out.println(stack);
LinkedList<String> stack=new LinkedList<>();
stack.push("第1颗子弹");
stack.push("第2颗子弹");
stack.push("第3颗子弹");
stack.push("第4颗子弹");
System.out.println(stack);
//出栈
System.out.println(stack.pop());
System.out.println(stack.pop());
System.out.println(stack);
}
}
1.6 Set集合
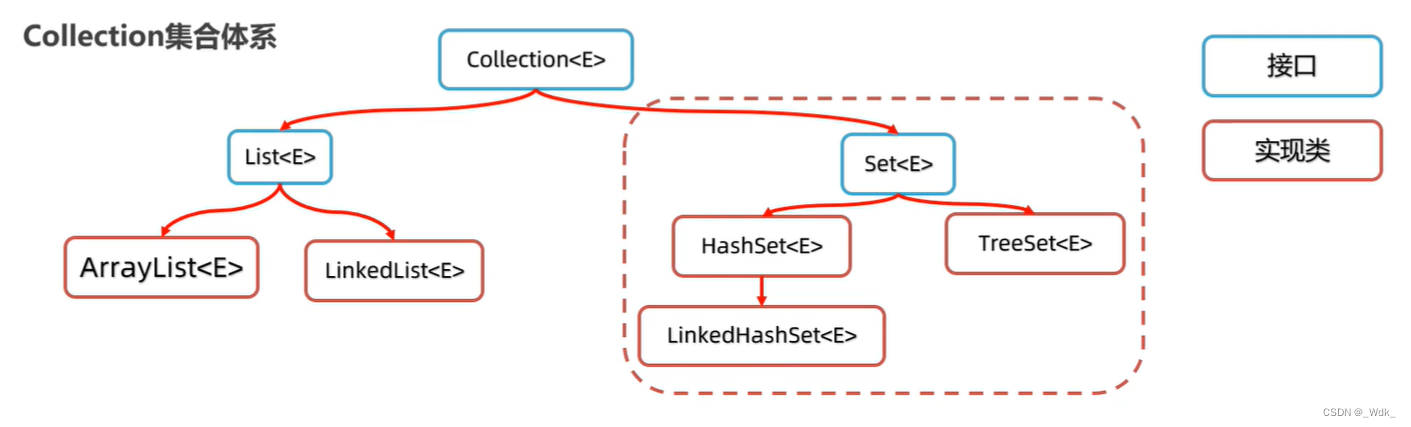
1.6.1 特点
无序:添加数据的顺序和获取出的数据顺序不一致;不重复;无索引;
- Hashset:无序、不重复、无索引。
- LinkedHashset:有序、不重复、无索引。
- TreeSet:排序、不重复、无索引
package com.itheima.collection_set;
import java.util.Set;
import java.util.TreeSet;
public class SetTest1 {
public static void main(String[] args) {
//1、创建一Set集合的对象
// Set<Integer> set=new HashSet<>();//创建了一个HashSet的集合对象。无序不重复无引
// Set<Integer> set=new LinkedHashSet<>();//有序不重复无案引
Set<Integer> set = new TreeSet<>();//可排序(升序) 可排序不重复无索引
set.add(23);
set.add(23);
set.add(22);
set.add(213);
set.add(233);
System.out.println(set);
}
}
1.6.2 Hashset集合的底层原理
注意:在正式了解Hashset集合的底层原理前,我们需要先搞清楚一个前置知识:哈希值!
哈希值
- 就是一个int类型的数值,Java中每个对象都有一个哈希值
- Java中的所有对象,都可以调用0bejct类提供的hashcode方法,返回该对象自己的哈希值
-

对象哈希值的特点
- 同一个对象多次调用hashcode()方法返回的哈希值是相同的。
- 不同的对象,它们的哈希值一般不相同,但也有可能会相同(哈希碰撞)
基于哈希表实现。
哈希表
是一种增删改查数据,性能都较好的数据结构。
JDK8之前,哈希表=数组+链表
JDK8开始,哈希表=数组+链表+红黑树
- JDK8之前Hashset集合的底层原理,基于哈希表:数组+链表
- 创建一个默认长度16的数组,默认加载因子为0.75,数组名table
- 使用元素的哈希值对数组的长度求余计算出应存入的位置判断当前位置
- 是否为null,如果是null直接存入
- 如果不为null,表示有元素,则调用equals方法比较相等,则不存;不相等,则存入数组
- JDK 8之前,新元素存入数组,占老元素位置,老元素挂下面
- JDK8开始之后,新元素直接挂在老元素下面
哈希表是一种增删改查数据性能都较好的结构。
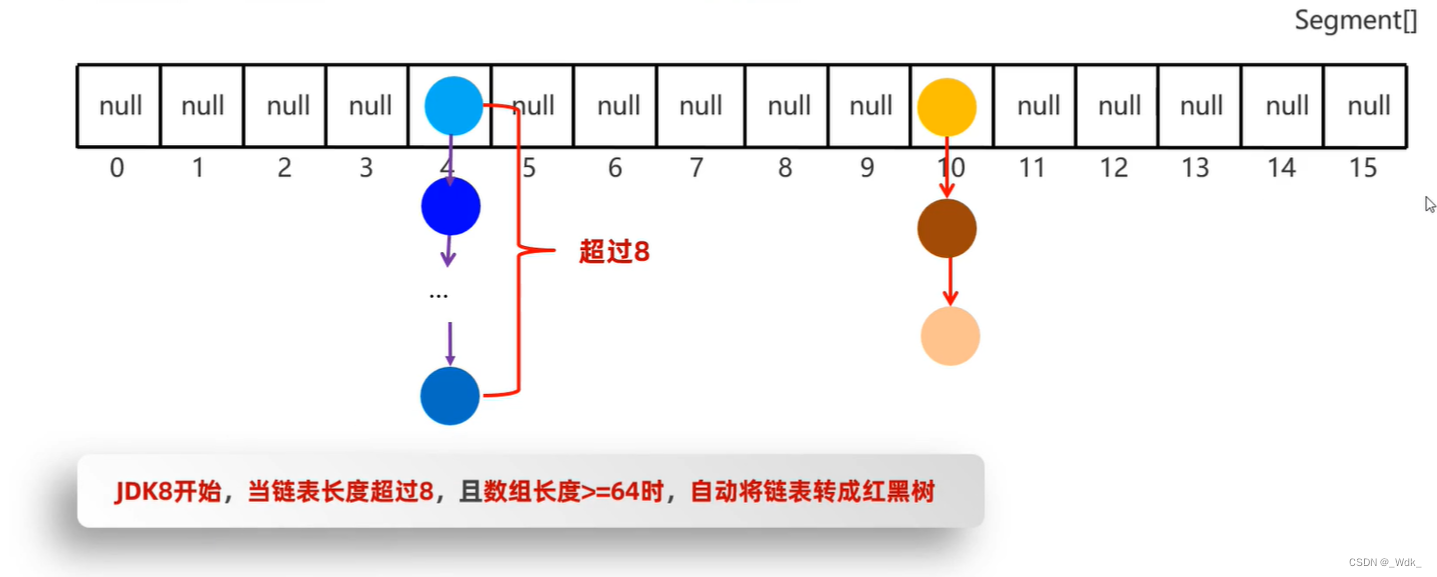
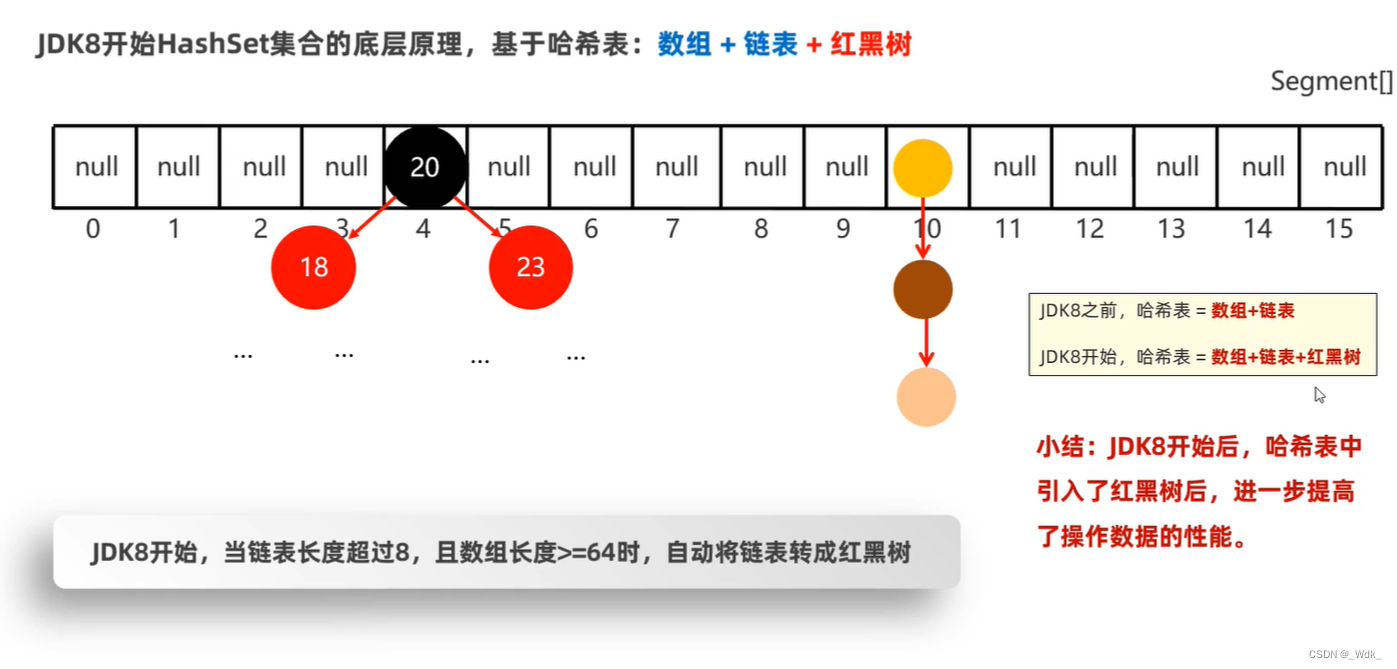
Hashset集合默认不能对内容一样的两个不同对象去重复!
比如内容一样的两个学生对象存入到Hashset集合中去,Hashset集合是不能去重复的!
Student.class
package com.itheima.collection_set;
import java.util.Objects;
public class Student {
private String name;
private int age;
private double height;
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
", height=" + height +
'}';
}
//只要两个对象内容一样,就返回true
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age && Double.compare(student.height, height) == 0 && Objects.equals(name, student.name);
}
//只要两个对象内容一样,返回两个哈希值就是一样的
@Override
public int hashCode() {
//姓名、年龄、身高计算哈希值的
return Objects.hash(name, age, height);
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public double getHeight() {
return height;
}
public void setHeight(double height) {
this.height = height;
}
public Student() {
}
public Student(String name, int age, double height) {
this.name = name;
this.age = age;
this.height = height;
}
}
SetTest.class
package com.itheima.collection_set;
import java.util.HashSet;
import java.util.Set;
public class SetTest3 {
public static void main(String[] args) {
Set<Student> students=new HashSet<>();
Student s1=new Student("至尊宝",28,169.6);
Student s2=new Student("蜘蛛精",23,169.6);
Student s3=new Student("牛魔王",28,169.6);
Student s4=new Student("牛魔王",48,169.6);
System.out.println(s3.hashCode());
System.out.println(s4.hashCode());
students.add(s1);
students.add(s2);
students.add(s3);
students.add(s4);
System.out.println(students);
}
}
1.6.3 LinkedHashset集合的底层原理
- 依然是基于哈希表(数组、链表、红黑树)实现的。
- 但是,它的每个元素都额外的多了一个双链表的机制记录它前后元素的位置
1.6.4 TreeSet集合
特点:不重复、无索引、可排序(默认升序排序,按照元素的大小,由小到大排序)
底层是基于红黑树实现的排序。
注意:
- 对于数值类型:Integer,Double,默认按照数值本身的大小进行升序排序
- 对于字符串类型:默认按照首字符的编号升序排序
- 对于自定义类型如Student对象,Treeset默认是无法直接排序的
自定义排序规则
Treeset集合存储自定义类型的对象时,必须指定排序规则,支持如下两种方式来指定比较规则。
方式一
- 让自定义的类、(如学生类)实现comparable接口重写里面的compareTo方法来指定比较规则
方式二
- 通过调用TreeSet集合有参数构造器,可以设置Comparator对象(比较器对象,用于指定比较规则
-

package com.itheima.collection_set; import java.util.Objects; public class Student implements Comparable<Student>{ private String name; private int age; private double height; @Override public String toString() { return "Student{" + "name='" + name + '\'' + ", age=" + age + ", height=" + height + '}'; } //只要两个对象内容一样,就返回true @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Student student = (Student) o; return age == student.age && Double.compare(student.height, height) == 0 && Objects.equals(name, student.name); } //只要两个对象内容一样,返回两个哈希值就是一样的 @Override public int hashCode() { //姓名、年龄、身高计算哈希值的 return Objects.hash(name, age, height); } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } public double getHeight() { return height; } public void setHeight(double height) { this.height = height; } public Student() { } public Student(String name, int age, double height) { this.name = name; this.age = age; this.height = height; } @Override // 如果认为左边对象大于右边对象返回正整数 // 如果认为左边对象小于右边对象返回负整数 // 如果认为左边对象等于右边对象返回0 // 需求:按照年龄升序排序、 public int compareTo(Student o) { return this.age-o.age; } }Test.class
package com.itheima.collection_set;
import java.util.Set;
import java.util.TreeSet;
public class SetTest4 {
public static void main(String[] args) {
Set<Integer> set1 = new TreeSet<>();
set1.add(6);
set1.add(4);
set1.add(5);
set1.add(1);
System.out.println(set1);
//TreeSet就近选择自己自带的比较器对象进行排序
Set<Student> students = new TreeSet<>((o1, o2) -> Double.compare(o1.getHeight(), o2.getHeight()));
//比较身高
students.add(new Student("蜘蛛精", 23, 169.7));
students.add(new Student("紫霞", 22, 169.8));
students.add(new Student("至尊宝", 26, 165.5));
students.add(new Student("牛魔王", 22, 183.5));
System.out.println(students);
}
}
1.7 集合体系总结
1.如果希望记住元素的添加顺序,需要存储重复的元素,又要频繁的根据索引查询数据?
- 用ArrayList集合(有序、可重复、有索引),底层基于数组的。(常用)
2.如果希望记住元素的添加顺序,且增删首尾数据的情况较多?
- 用LinkedList集合(有序、可重复、有索引),底层基于双链表实现的
3.如果不在意元素顺序,也没有重复元素需要存储,只希望增删改查都快?
- 用HashSet集合(无序,不重复,无索引),底层基于哈希表实现的。(常用)
4.如果希望记住元素的添加顺序,也没有重复元素需要存储,且希望增删改查都快?
- 用LinkedHashset集合(有序,不重复,无索引),底层基于哈希表和双链表。
5.如果要对元素进行排序,也没有重复元素需要存储?且希望增删改查都快?
- 用TreeSet集合,基于红黑树实现。
1.8 注意事项:集合的并发修改异常问题
1.集合的并发修改异常
- 使用迭代器遍历集合时,又同时在删除集合中的数据,程序就会出现并发修改异常的错误。
- 由于增强for循环遍历集合就是迭代器遍历集合的简化写法,因此,使用增强for循环遍历集合,又在同时删除集合中的数据时,程序也会出现并发修改异常的错误
2.怎么保证遍历集合同时删除数据时不出bug?
- 使用迭代器遍历集合,但用迭代器自己的删除方法删除数据即可
- 如果能用for循环遍历时:可以倒着遍历并删除;或者从前往后遍历,但删除元素后做i --操作
package com.itheima.collection_exception;
import java.util.ArrayList;
import java.util.List;
public class CollectionTest1 {
public static void main(String[] args) {
List<String> list=new ArrayList<>();
list.add("王麻子");
list.add("李小龙");
list.add("李龙");
list.add("李小");
list.add("刘德华");
list.add("周杰伦");
list.add("周润发");
list.add("周星驰");
System.out.println(list);
// 需求:找出集合中全部带“李”的名字,并从集合中删除。
/* Iterator<String> it=list.iterator();
while (it.hasNext()){
String name=it.next();
if(name.contains("李")){
list.remove(name);
}
}name
System.out.println(list);*/
//用for循环遍历删除带李字的集合
// for (int i = 0; i < list.size(); i++) {
// String name=list.get(i);
// if(name.contains("李")){
// list.remove(name);
// i--;
// }
// }
// System.out.println(list);
//或者倒着删也可以
System.out.println("=========================================================");
// 需求:找出集合中全部带“李”的名字,并从集合中删除
// Iterator<String> it=list.iterator();
// while (it.hasNext()){
// String name=it.next();
// if(name.contains("李")){
// it.remove();
// }
// }
// System.out.println(list);
// 使用增强for循环遍历集合并删除数据,没有办法解决bug.
// for (String name : list) {
// if(name.contains("李")){
// list.remove(name);
// }
// }
// list.forEach(name->{
// if(name.contains("李")){
// list.remove(name);
// }
// });
// System.out.println(list);
}
}
1.9 Collection的其他相关知识
1.9.1 前置知识:可变参数
就是一种特殊形参,定义在方法、构造器的形参列表里,格式是:数据类型.参数名称;
可变参数的特点和好处
- 特点:可以不传数据给它;可以传一个或者同时传多个数据给它;也可以传一个数组给它。
- 好处:常常用来灵活的接收数据。
可变参数的注意事项:
- 可变参数在方法内部就是一个数组
- 一个形参列表中可变参数只能有一个
- 可变参数必须放在形参列表的最后面
package com.itheima.d1_parameter;
import java.util.Arrays;
public class ParamTest1 {
public static void main(String[] args) {
//特点:
test();
test(10);// 不传数据
test(10,20,30);// 传输多个数据给它
test(10,20,30,40);// 传输一个数组给可变参数
}
// 注意事项1:一个形参列表中,只能有一个可变参数。
// 注意事项2:可变参数必须放在形参列表的最后面
public static void test(int...nums){
//可变参数在方法内部,本质就是一个数组。
System.out.println(nums.length);
System.out.println(Arrays.toString(nums));
System.out.println("===================================================================");
}
}
1.9.2 Collections
是一个用来操作集合的工具类
Student.class
package com.itheima.conllections;
import java.util.Objects;
public class Student implements Comparable<Student>{
private String name;
private int age;
private double height;
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
", height=" + height +
'}';
}
//只要两个对象内容一样,就返回true
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age && Double.compare(student.height, height) == 0 && Objects.equals(name, student.name);
}
//只要两个对象内容一样,返回两个哈希值就是一样的
@Override
public int hashCode() {
//姓名、年龄、身高计算哈希值的
return Objects.hash(name, age, height);
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public double getHeight() {
return height;
}
public void setHeight(double height) {
this.height = height;
}
public Student() {
}
public Student(String name, int age, double height) {
this.name = name;
this.age = age;
this.height = height;
}
@Override
// 如果认为左边对象大于右边对象返回正整数
// 如果认为左边对象小于右边对象返回负整数
// 如果认为左边对象等于右边对象返回0
// 需求:按照年龄升序排序、
public int compareTo(Student o) {
return this.age-o.age;
}
}
CollectionTest.class
package com.itheima.conllections;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class CollectionTest1 {
public static void main(String[] args) {
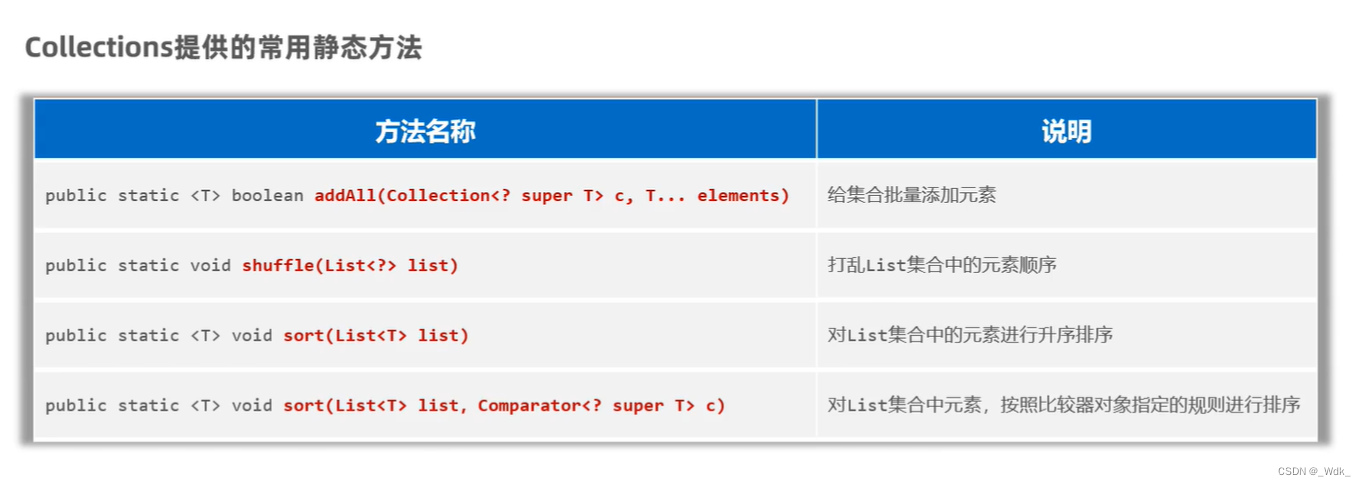
// 1、public static <T> boolean addAl(collection<? super T>c,T...elements):为集合批最添加数据
List<String> names=new ArrayList<>();
Collections.addAll(names,"张三","李四","王五");
System.out.println(names);
// 2、public static void shuffle(List<?> list): 打乱List集合中的元素顺序。
Collections.shuffle(names);
System.out.println(names);
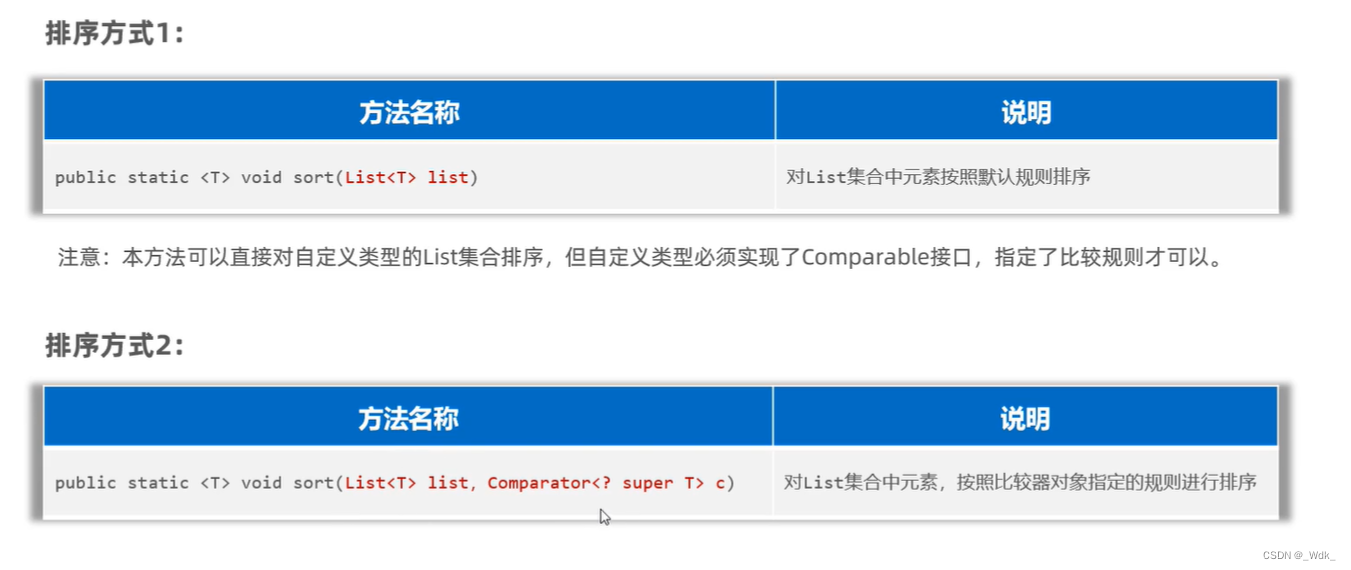
//3、 public static <T> void sort(List<T> list):对List集合中的元素进行升序排序。
// List<Integer> list=new ArrayList<>();
// list.add(3);
// list.add(4);
// list.add(5);
// Collections.sort(list);
// System.out.println(list);
List<Student> students=new ArrayList<>();
students.add(new Student("张三",18,1.75));
students.add(new Student("李四",19,1.75));
students.add(new Student("李四",19,1.75));
students.add(new Student("王五",20,1.75));
Collections.sort(students);
// System.out.println(students);
//4、public static <T> void sort(List<T> list,Comparator<?super T>c):对List集合中元素,按照比较器对象指定的规则进
Collections.sort(students,( o1, o2) -> o1.getAge()-o2.getAge());
System.out.println(students);
}
}
1.9.3 综合案例

Card.class
package com.itheima.collection_test;
public class Card {
private String number;
private String color;
//每张牌是存在大小的
private int size;//0 , 1 ,2 ....
public Card() {
}
public Card(String number, String color, int size) {
this.number = number;
this.color = color;
this.size = size;
}
public String getNumber() {
return number;
}
public void setNumber(String number) {
this.number = number;
}
public String getColor() {
return color;
}
public void setColor(String color) {
this.color = color;
}
public int getSize() {
return size;
}
public void setSize(int size) {
this.size = size;
}
@Override
public String toString() {
return "Card{" +
"number='" + number + '\'' +
", color='" + color + '\'' +
", size=" + size +
'}';
}
}
GameDemo.class
package com.itheima.collection_test;
// 大小王:"👑","🌙"
// 点数:"A","2","3","4","5","6","7","8","9","10","J","Q","K"
// 花色:"♥","♠","♣","♦"
//点数分别要组合4种花色,大小王各一张。
//斗地主:发出51张牌,剩下3张作为底牌。
public class GameDemo {
public static void main(String[] args) {
//1、牌类
//2、房间
Room room = new Room();
room.start();
}
}
Room.class
package com.itheima.collection_test;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
public class Room {
//必须有一副牌
private List<Card> allCards = new ArrayList<>();
public Room() {
// 1、做出54张牌,存入到集合allCards
// a、点数:个数确定了,类型确定
String[] numbers = {"3", "4", "5", "6", "7", "8", "9", "10", "J", "Q", "K", "A", "2"};
// b、花色:个数确定了,类型确定。
String[] colors = {"♥", "♣", "♦", "♠"};
int size = 0;
//c、遍历点数,再遍历花色,组织牌
for (String number : numbers) {
size++;
for (String color : colors) {
Card c = new Card(number, color, size);
allCards.add(c);
}
}
//单独存入小大王
Card c1 = new Card("", "小王", ++size);
Card c2 = new Card("", "大王", ++size);
Collections.addAll(allCards, c1, c2);
System.out.println("新牌:" + allCards);
}
public void start() {
//1、洗牌:allCards
Collections.shuffle(allCards);
System.out.println("洗牌后:" + allCards);
//2、发牌,首先肯定要定义三个玩家
List<Card> linHuChong = new ArrayList<>();
List<Card> jiuMoZhi = new ArrayList<>();
List<Card> renYingYing = new ArrayList<>();
for (int i = 0; i < allCards.size(); i++) {
Card c = allCards.get(i);
//判断牌发给谁
if (i % 3 == 0) {
//请啊冲发牌
linHuChong.add(c);
}else if(i%3==0){
//请啊鸠发牌
jiuMoZhi.add(c);
}else if(i%3==2){
//请盈盈接牌
renYingYing.add(c);
}
//3、对3个玩家的牌进行排序
sortCards(linHuChong);
sortCards(jiuMoZhi);
sortCards(renYingYing);
//4、看牌
System.out.println("林胡冲:" + linHuChong);
System.out.println("啊鸠:" + jiuMoZhi);
System.out.println("任盈盈:" + renYingYing);
//地主的底牌
List<Card> lastThreeCards=allCards.subList(allCards.size()-3,allCards.size());//截取集合,从索引位置到边界位置的截取
System.out.println("底牌:"+lastThreeCards);
jiuMoZhi.addAll(lastThreeCards);
sortCards(jiuMoZhi);
System.out.println("啊鸠抢到地主"+jiuMoZhi);
}
}
private void sortCards(List<Card> cards) {
Collections.sort(cards, new Comparator<Card>() {
@Override
public int compare(Card o1, Card o2) {
return o1.getSize()-o2.getSize();//升序
//return o2.getSize()-o1.getSize();//降序
}
});
}
}
1.10 Map集合
1.10.1 Map集合的概述
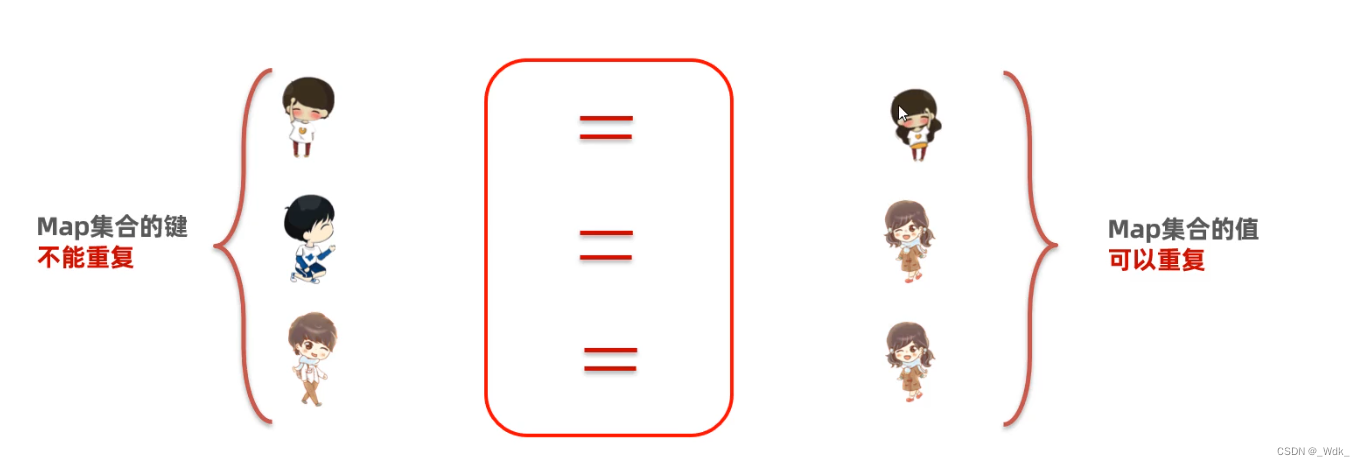
- Map集合称为双列集合,格式:{key1=value1,key2=value2,key3=value3,…},一次需要存一对数据做为一个元素
- Map集合的每个元素"key=value"称为一个键值对/键值对对象/一个Entry对象,Map集合也被叫做"键值对集合"
- Map集合的所有键是不允许重复的,但值可以重复,键和值是一一对应的,每一个键只能找到自己对应的值
Map集合在什么业务场景下使用 ?
需要存储一一对应的数据时,就可以考虑使用Map集合来做
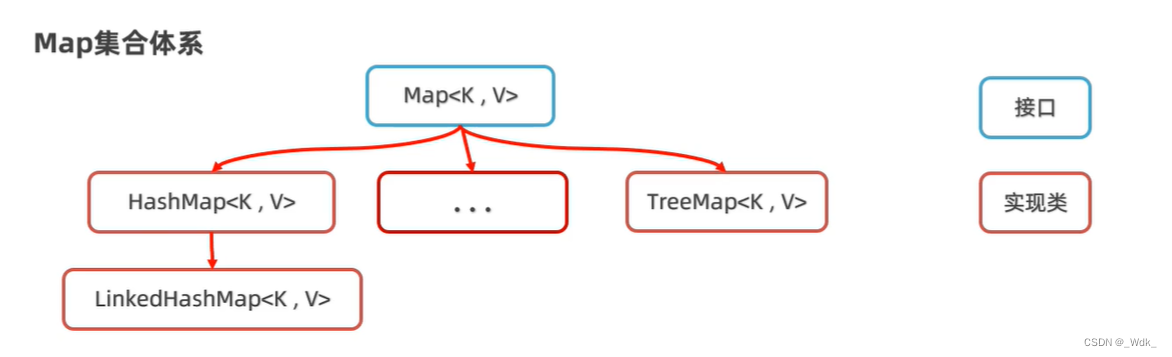
Map集合体系的特点
注意:Map系列集合的特点都是由键决定的,值只是一个附属品,值是不做要求的
- HashMap(由键决定特点):无序、不重复、无索引;(用的最多)
- LinkedHashMap (由键决定特点):由键决定的特点:有序、不重复、无索引。
- TreeMap (由键决定特点):按照大小默认升序排序、不重复、无索引。
MapTest.class
package com.itheima.Map;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.TreeMap;
public class MapTest1 {
public static void main(String[] args) {
// Map<String,Integer> map=new HashMap<>();//用的比较多!! 按照键无序,不重复,无案引。
Map<String,Integer> map=new LinkedHashMap<>();// 有序,不重复,无索引。
map.put("手表",100);
map.put("手表",220);//后面的重复的数据会覆盖前面的数据(键),值不重复
map.put("手机",2);
map.put("Java",2);
map.put(null,null);
System.out.println(map);
Map<Integer,String> map1=new TreeMap<>();
map1.put(23,"java");
map1.put(23,"MySQL");
map1.put(19,"李四");
map1.put(20,"王五");
System.out.println(map1);
}
}
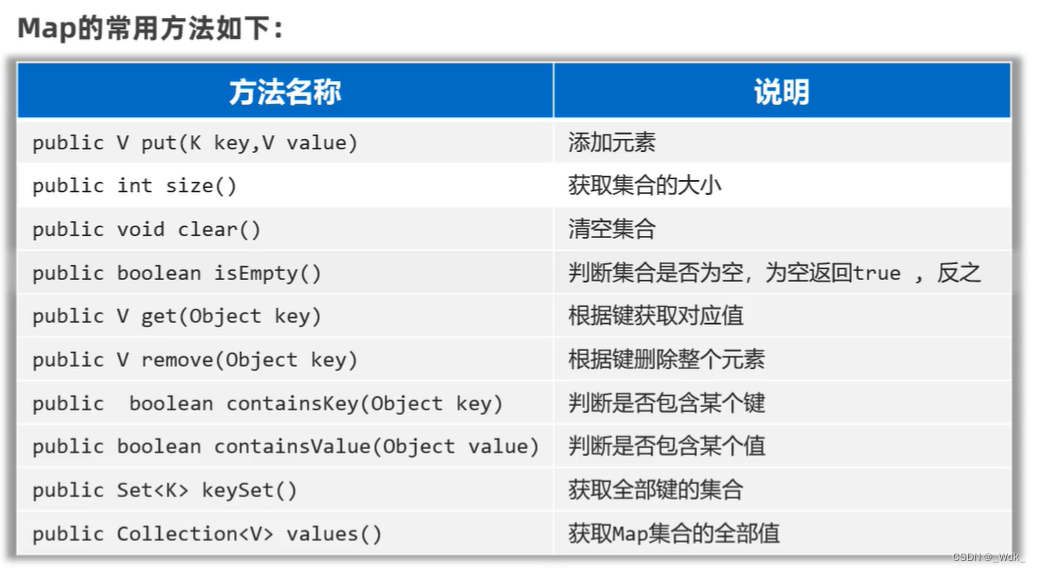
1.10.2 Map集合的常用方法
1.为什么要先学习Map的常用方法?
Map是双列集合的祖宗,它的功能是全部双列集合都可以继承过来使用的。
package com.itheima.Map;
import java.util.*;
public class MapTest2 {
public static void main(String[] args) {
Map<String, Integer> map = new LinkedHashMap<>();// 有序,不重复,无索引。
map.put("手表", 100);
map.put("手表", 220);//后面的重复的数据会覆盖前面的数据(键),值不重复
map.put("手机", 2);
map.put("Java", 2);
map.put(null, null);
System.out.println(map);
// 2.public int size():获取集合的大小
System.out.println(map.size());//一对 元素算一个
//3、public void clear():清空集合
// map.clear();
// 4.public boolean isEmpty():判断集合是否为空,为空返回true,反之!
System.out.println(map.isEmpty());
// 5.public V get(Object key): 根据键获取对应值
System.out.println(map.get("手表"));
System.out.println(map.get("手机"));
System.out.println(map.get("zhang"));
// 6.public V remove(Object key):根据键删除整个元素(删除键会返回键的值)
System.out.println(map.remove("手表"));
System.out.println(map);
// 7.public boolean containsKey(Object key): 判断是否包含某个键 ,包含返回true,反之
System.out.println(map.containsKey("手表"));//false
System.out.println(map.containsKey("手机"));//true
System.out.println(map.containsKey("java"));//false,精确匹配,区分大小写
System.out.println(map.containsKey("Java"));//true
// 8.public boolean containsValue(object value): 判断是否包含某个值。
System.out.println(map.containsValue(220));
System.out.println(map.containsValue(2));
System.out.println(map.containsValue("211"));
// 9.public Set<K> keySet():获取Map集合的全部键。
Set<String> keys=map.keySet();
System.out.println(keys);
//10.public Collection<V>values();获取Map集合的全部值
Collection<Integer> values = map.values();
System.out.println(values);
// 11.把其他Map集合的数据倒入到自己集合中来。(拓展)
Map<String, Integer> map1 = new HashMap<>();
map1.put("java1",10);
map1.put("java2",20);
Map<String, Integer> map2 = new HashMap<>();
map1.put("java3",10);
map1.put("java2",222);
map1.putAll(map2);//putAll :把map2集合中的元素全部倒入到一份map1集合中去
System.out.println(map1);
System.out.println(map2);
}
}
1.10.3 Map集合的遍历方式
1.键找值
- 先获取Map集合全部的键,再通过遍历键来找值
2.键值对
- 把“键值对“看成一个整体进行遍历(难度较大)
3.Lambda
- JDK1.8开始之后的新技术(非常的简单)
1.键找值

package com.itheima.Map_traverse;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class MapTest1 {
public static void main(String[] args) {
// 准备一个Map集合。
Map<String, Double> map = new HashMap<>();
map.put("张三", 162.5);
map.put("李四", 165.8);
map.put("王五", 170.6);
map.put("赵六", 172.2);
map.put("田七", 189.3);
System.out.println(map);
//1、 准备一个Map集合。
Set<String> keys=map.keySet();
System.out.println(keys);
// 2、遍历全部的键,根据键获取其对应的值
for (String key : keys) {
//根据键获取对应的值
double value=map.get(key);
System.out.println(key+"--->" +value);
}
}
}
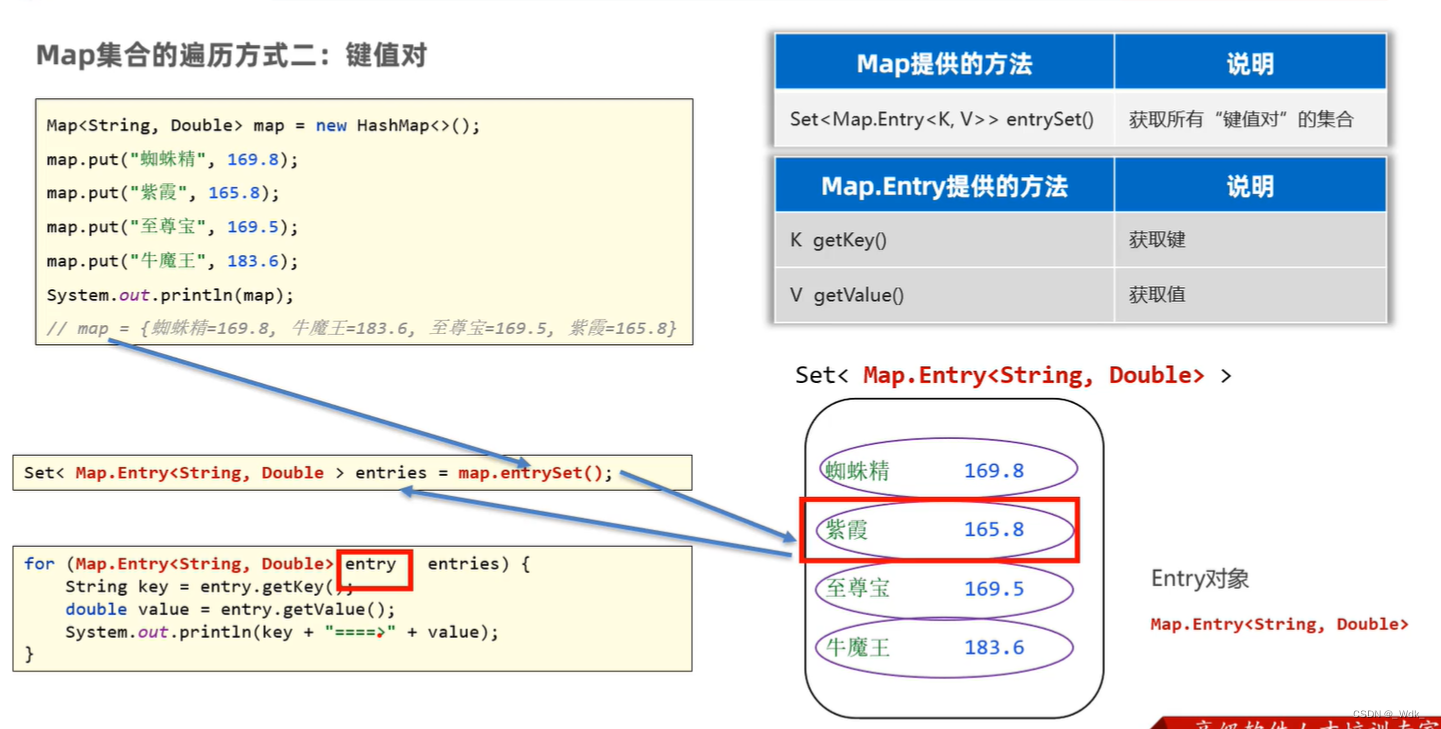
2.键值对
package com.itheima.Map_traverse;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class MapTest2 {
public static void main(String[] args) {
Map<String, Double> map = new HashMap<>();
map.put("张三", 162.5);
map.put("李四", 165.8);
map.put("王五", 170.6);
map.put("赵六", 172.2);
map.put("田七", 189.3);
System.out.println(map);
// map ={张三=162.5,李四=165.8,王五=170.6,赵六=172.2 田七=189.3}
// entries =[(张三=162.5),(李四=165.8),(王五=170.6),(赵六=1172.2),(田七=189.3)]
// entry
// 1、调用Map集合提供entrySet方法,把Map集合转换成键值对类型的Set集合
Set<Map.Entry<String, Double>> entries = map.entrySet(); //CTRL+ALT+V :快速填补
for (Map.Entry<String, Double> entry : entries) {
String key = entry.getKey();
Double value = entry.getValue();
System.out.println(key+"---------->"+value);
}
}
}
3.Lambda
package com.itheima.Map_traverse;
import java.util.HashMap;
import java.util.Map;
public class MapTest3 {
public static void main(String[] args) {
Map<String, Double> map = new HashMap<>();
map.put("张三", 162.5);
map.put("李四", 165.8);
map.put("王五", 170.6);
map.put("赵六", 172.2);
map.put("田七", 189.3);
System.out.println(map);
map.forEach((k,v)->{
System.out.println(k+"---"+v);
});
// map.forEach(new BiConsumer<String, Double>() {
// @Override
// public void accept(String k, Double v) {
// System.out.println(k+"---"+v);
// }
// });
}
}
1.10.4 Map集合的案例

package com.itheima.Map_traverse;
import java.util.*;
public class MapDemo4 {
public static void main(String[] args) {
// 1、把80个学生选择的景点数据拿到程序中来。
List<String> data = new ArrayList<>();
String[] selects = {"A", "B", "C", "D"};
Random r=new Random();
for (int i = 1; i <= 80; i++) {
// 每次模拟一个学生选择一个景点,存入到集合中去。
int index = r.nextInt(selects.length);
data.add(selects[index]);
}
System.out.println(data);
// 2、开始统计每个最点的投票人数
//准备一个Map集合用于统计最终的结果
Map<String, Integer> result = new HashMap<>();
// 3、开始遍历80个景点数据
for (String s : data) {
// 问间Map集合中是否存在该景点
if(result.containsKey(s)){
//说明这个景点之前统计过,其值+1,存入Map集合中去
result.put(s,result.get(s)+1);
}else {
// 说明这个最点是第一次统计,存入"景点=1”
result.put(s,1);
}
}
System.out.println(result);
}
}
1.10.5 HashMap集合的底层原理
HashMap跟HashSet的底层原理是一模一样的,都是基于哈希表实现的
实际上:原来学的Set系列集合的底层就是基于Map实现的,只是Set集合中的元素只要键数据,不要值数据而已

HashMap底层是基于哈希表实现的
- HashMap集合是一种增删改查数据,性能都较好的集合
- 但是它是无序,不能重复,没有索引支持的(由键决定特点)
- HashMap的键依赖hashCode方法和equals方法保证键的唯一
- 如果键存储的是自定义类型的对象,可以通过重写hashCode和equals方法,这样可以保证多个对象内容一样时,HashMap集合就能认为是重复的,
Student.class
package com.itheima.map_impl;
import java.util.Objects;
public class Student {
private String name;
private int age;
private double height;
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age && Double.compare(student.height, height) == 0 && Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age, height);
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
", height=" + height +
'}';
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public double getHeight() {
return height;
}
public void setHeight(double height) {
this.height = height;
}
public Student() {
}
public Student(String name, int age, double height) {
this.name = name;
this.age = age;
this.height = height;
}
}
Test1HashMap .class
package com.itheima.map_impl;
import java.util.HashMap;
import java.util.Map;
public class Test1HashMap {
public static void main(String[] args) {
Map<Student, String> map = new HashMap<>();
map.put(new Student("张三", 18, 1.75), "Java");
map.put(new Student("李四", 19, 1.85), "C++");
map.put(new Student("李四", 19, 1.85), "C++");
map.put(new Student("王五", 20, 1.55), "Python");
map.put(new Student("赵六", 21, 1.65), "JavaScript");
System.out.println(map);
}
}
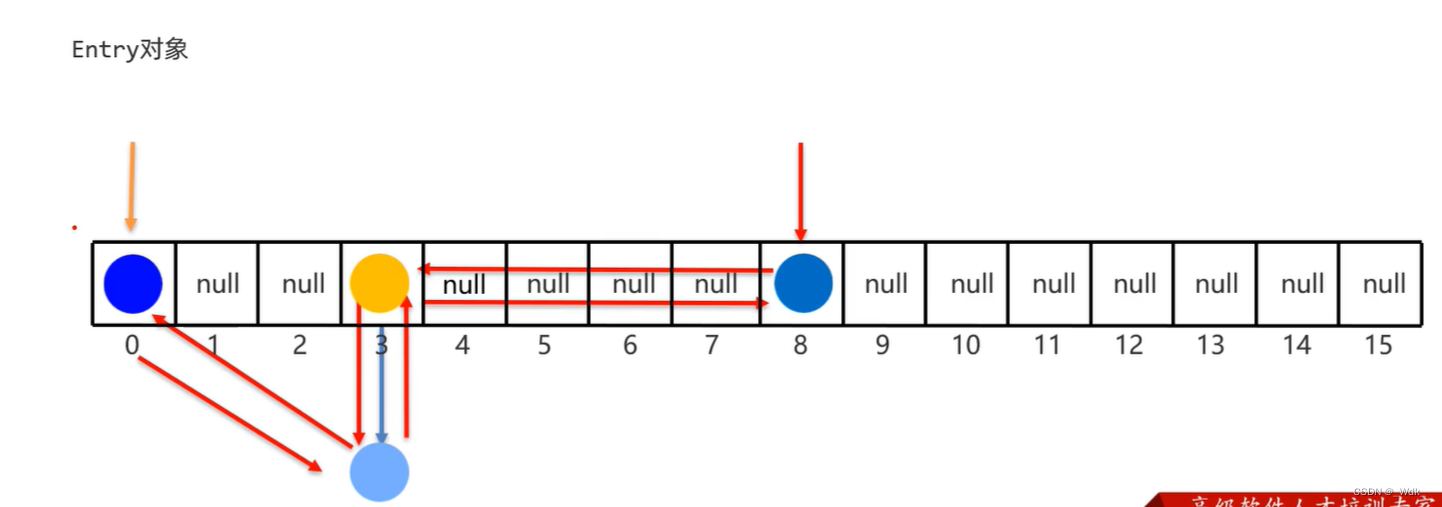
1.10.6 LinkedHashMap集合的原理
- 底层数据结构依然是基于哈希表实现的,只是每个键值对元素又额外的多了一个双链表的机制记录元素顺序(保证有序)。
- 实际上:原来学习的LinkedHashset集合的底层原理就是LinkedHashMap。
-
1.10.7 TreeMap集合的原理
- 特点:不重复、无索引、可排序(按照键的大小默认升序排序,只能对键排序
- 原理:TreeMap跟TreeSet集合的底层原理是一样的,都是基于红黑树实现的排序。
TreeMap集合同样也支持两种方式来指定排序规则
- 让类实现Comparable接口,重写比较规则。
- TreeMap集合有一个有参数构造器,支持创建Comparator比较器对象,以便用来指定比较规则。
Student.class
package com.itheima.map_impl;
import java.util.Objects;
public class Student implements Comparable<Student> {//实现comparable接口
private String name;
private int age;
private double height;
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age && Double.compare(student.height, height) == 0 && Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age, height);
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
", height=" + height +
'}';
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public double getHeight() {
return height;
}
public void setHeight(double height) {
this.height = height;
}
public Student() {
}
public Student(String name, int age, double height) {
this.name = name;
this.age = age;
this.height = height;
}
//重写comparaTo方法
@Override
public int compareTo(Student o) {
return this.age-o.age;//升
}
}
TreeHashMapTest.class
package com.itheima.map_impl;
import java.util.Map;
import java.util.TreeMap;
public class Test3TreeMap {
public static void main(String[] args) {
//也可以用new comparable重写方法来使用student键的排序
Map<Student,String> map = new TreeMap<>(( o1, o2) -> Double.compare(o2.getHeight(),o1.getHeight()));
map.put(new Student("张三", 18, 1.75), "Java");
map.put(new Student("李四", 19, 1.85), "C++");
map.put(new Student("李四", 19, 1.85), "C++");
map.put(new Student("王五", 20, 1.55), "Python");
map.put(new Student("赵六", 21, 1.65), "JavaScript");
System.out.println(map);
}
}
1.10.8 补充知识:集合的嵌套
指的是售合中的元素又是一个集合

package com.itheima.collection_nesting;
import java.util.*;
//江苏省 =“南京市","扬州市","苏州市”,"无锡市","常州市”
// 湖北省 =“武汉市”,"孝感市”“十堰市”,“宜昌市”,"鄂州市”
// 河北省 =“石家庄市”,“唐山市”,“邢台市",“保定市",“张家口市”
public class Test {
public static void main(String[] args) {
// 1、定义一个Map集合存储全部的省份信息,和其对应的市信息。
Map<String, List<String>> map=new HashMap<>();
List<String> cities1=new ArrayList<>();
Collections.addAll(cities1,"南京市","扬州市","苏州市","无锡市","常州市");
map.put("江苏省",cities1);
List<String> cities2=new ArrayList<>();
Collections.addAll(cities2,"武汉市","孝感市","十堰市","宜昌市","鄂州市");
map.put("湖北省",cities2);
List<String> cities3=new ArrayList<>();
Collections.addAll(cities3,"石家庄市","唐山市","邢台市","保定市","张家口市");
map.put("河北省",cities3);
System.out.println(map);
List<String> cities=map.get("江苏省");
/* for (String city : cities) {
System.out.println(city);
}*/
map.forEach((p,c)->System.out.println(p+"----->"+c));
}
}
二、JDK8新特性:Stream
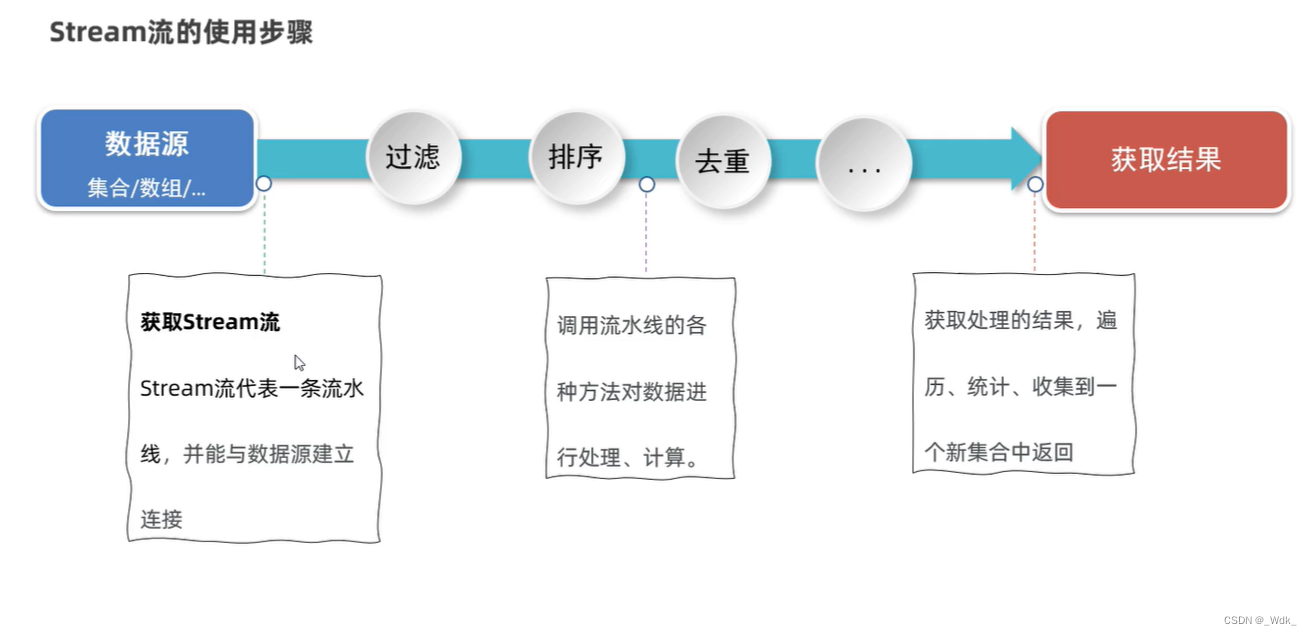
2.1 Stream概述
- 也叫Stream流,是Jdk8开始新增的一套API(java.util.stream.*),可以用于操作集合或者数组的数据
- 优势:Stream流大量的结合了Lambda的语法风格来编程,提供了一种更加强大,更加简单的方式操作集合或者数组中的数据,代码更简洁,可读性更好。
-
package com.itheima.stream; import java.util.ArrayList; import java.util.Collections; import java.util.List; import java.util.stream.Collectors; public class StreamTest1 { public static void main(String[] args) { List<String> names =new ArrayList<>(); Collections.addAll(names,"张三丰","张无忌","周芷若","赵敏","张强"); System.out.println(names); List<String> list =new ArrayList<>(); for (String name : names) { if(name.startsWith("张")&&name.length()==3){ list.add(name); } } System.out.println(list); //使用Stream流来编写 List<String> list2=names.stream().filter(s -> s.startsWith("张")).filter(s -> s.length()==3).collect(Collectors.toList()); System.out.println(list2); } }
2.2 Stream常用方法
1. 获取集合的Stream流

StreamTest.class
package com.itheima.stream;
import java.util.*;
import java.util.stream.Stream;
public class StreamTest2 {
public static void main(String[] args) {
//1、如何获取List集合的Stream流?
List<String> names=new ArrayList<>();
Collections.addAll(names,"张三","李四","王五","赵六","田七");
Stream<String> stream = names.stream();
//2、如何获取Set集合的Stream流?
Set<String> set=new HashSet<>();
Collections.addAll(set,"张曼玉","刘德华","蜘蛛侠","钢铁侠","美国队长");
Stream<String> stream1 = set.stream();
stream1.filter(s-> s.contains("侠")).forEach(s -> System.out.println(s));
// 3、如何获取Map集合的Stream流?
Map<String,Double> map=new HashMap<>();
map.put("古力娜扎",182.3);
map.put("迪丽热巴",168.9);
map.put("马尔扎哈",190.5);
map.put("刘嘉玲",168.3);
map.put("古天乐",180.3);
Set<String> keys = map.keySet();
Stream<String> ks = keys.stream();
Collection<Double> values = map.values();
Stream<Double> vs = values.stream();
Set<Map.Entry<String, Double>> entries = map.entrySet();
Stream<Map.Entry<String, Double>> kvs = entries.stream();
kvs.filter(e->e.getKey().contains("扎")).forEach(e-> System.out.println(e.getKey()+"--->"+e.getValue()));
// 4、如何获取数组的Stream流?
String[] names2={"张宝珊","东方总败","刘大能","哈哈哈哈"};
Stream<String> s1 = Arrays.stream(names2);
Stream<String> s2 = Stream.of(names2);
}
}
2.3 Stream常见的中间方法
中间方法指的是调用完成后会返回新的Stream流,可以继续使用(支持链式编程)。

StreamTest.class
package com.itheima.stream;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.stream.Stream;
public class StreamTest3 {
public static void main(String[] args) {
List<Double> scores=new ArrayList<>();
Collections.addAll(scores, 100.0, 99.0, 88.0, 77.0, 66.0, 55.0, 44.0, 33.0, 22.0, 11.0);
// 需求1:找出成绩大于等于60分的数据,并升序后,再输出。
scores.stream().filter(s->s>=60).sorted().forEach(s-> System.out.println(s));
System.out.println("=====================================================");
List<Student> students=new ArrayList<>();
Student s1=new Student("张三", 33, 123.1);
Student s2=new Student("李四", 24, 23.23);
Student s3=new Student("王五", 35, 120.3);
Student s4=new Student("赵六", 26, 15.2);
Student s5=new Student("赵六", 35, 155.1);
Collections.addAll(students, s1, s2, s3, s4, s5);
// 需求2:找出年龄大于等于23,且年龄小于等于30岁的学生,并按照年龄降序输出
students.stream().filter(s->s.getAge()>=23&&s.getAge()<=30)
.sorted((o1,o2)->o2.getAge()-o1.getAge())
.forEach(s-> System.out.println(s));
System.out.println("=====================================================");
// 需求3:取出分数最高的前3名学生,并输出
students.stream().sorted((o1,o2)->Double.compare(o2.getScore(),o1.getScore()))
.limit(3)
.forEach(System.out::println);
System.out.println("=====================================================");
// 需求4:取出分数倒数的2名学生,并输出。
students.stream().sorted((o1,o2)->Double.compare(o2.getScore(),o1.getScore()))
.skip(students.size()-2)
.forEach(System.out::println);
System.out.println("=====================================================");
// 需求5:找出分数超过100的学生叫什么名字,要求去除重复的名字,再输出。
// distinct去重复,自定义类型的对象(希望内容一样就认为重复,重写hashCode,equals)
students.stream().filter(s->s.getScore()>=100)
.map(Student::getName)//映射方法,把集合里的名字直接映射到改流里,相当于该流里目前只有集合中的名字
.distinct()
.forEach(System.out::println);
System.out.println("=====================================================");
//Stream流的合并
Stream<String> st1 = Stream.of("张三", "李四");
Stream<String> st2 = Stream.of("张三2", "李四2");
Stream<String> allStr = Stream.concat(st1, st2);
allStr.forEach(System.out::println);
}
}
2.4 Stream的终结方法
终结方法指的是调用完成后,不会返回新Stream了,没法继续使用流了。
StraemTest.class
package com.itheima.stream;
import java.util.*;
import java.util.stream.Collectors;
public class StreamTest4 {
public static void main(String[] args) {
List<Student> students = new ArrayList<>();
Student s1 = new Student("张三", 18, 172.3);
Student s2 = new Student("李四", 19, 182.2);
Student s3 = new Student("王五", 20, 170.2);
Student s4 = new Student("赵六", 22, 190.3);
Student s5 = new Student("田七", 23, 182.1);
Student s6 = new Student("发发发", 26, 132.9);
Student s7 = new Student("发发发", 26, 132.9);
Collections.addAll(students, s1, s2, s3, s4, s5, s6, s7);
// 需求1:请计算出分数超过168的学生有几人。
long size = students.stream().filter(s -> s.getScore() >= 168).count();
System.out.println(size);
System.out.println("===============================================");
// 需求2:请找出分数最高的学生对象,并输出。
Student s = students.stream()
.max((o1, o2) -> Double.compare(o1.getScore(), o2.getScore()))
.get();
System.out.println(s);
System.out.println("===============================================");
// 需求3:请找出分数最低的学生对象,并输出。
Student ss = students.stream().min((o1, o2) -> Double.compare(o1.getScore(), o2.getScore())).get();
System.out.println(ss);
// 需求4:请找出分数超过170的学生对象,并放到一个新集合中去返回。
List<Student> students1 = students.stream()
.filter(a -> a.getScore() > 170)
.collect(Collectors.toList());
System.out.println(students1);
System.out.println("===============================================");
Set<Student> students2 = students.stream()
.filter(a -> a.getScore() > 170)
.collect(Collectors.toSet());
System.out.println(students2);
System.out.println("===============================================");
//需求5:请找出分数超过170的学生对象,并把学生对象的名字和分数,存入到一个Map集合返回
Map<String, Double> map = students.stream()
.filter(a -> a.getScore() > 170)
.distinct()
.collect(Collectors
.toMap(Student::getName, Student::getScore));
System.out.println(map);
System.out.println("===============================================");
//
// students.stream()
// .filter(a -> a.getScore() > 170)
// .toArray();
Student[] arr = students.stream()
.filter(a -> a.getScore() > 170)
.toArray(len -> new Student[len]);
System.out.println(Arrays.toString(arr));
}
}

三、File、IO流
有些数据想长久保存起来,咋整?
- 文件是非常重要的存储方式,在计算机硬盘中。
- 即便断电,或者程序终止了,存储在硬盘文件中的数据也不会丢失。
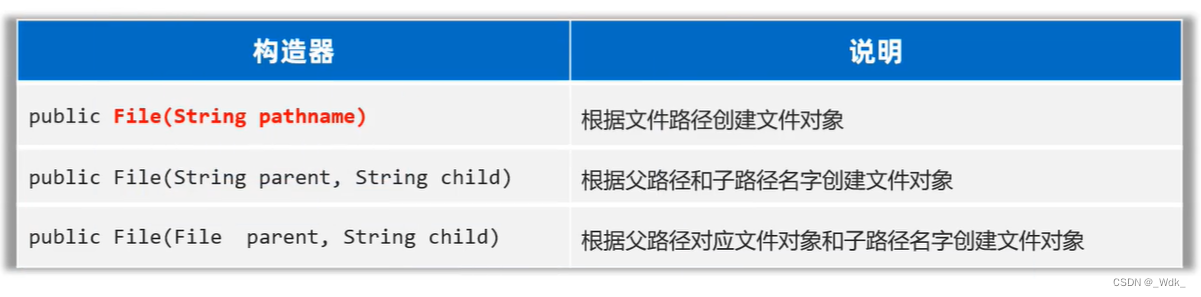
3.1 File
File是java.io.包下的类, File类的对象,用于代表当前操作系统的文件(可以是文件、或文件夹)

注意:File类只能对文件本身进行操作,不能读写文件里面存储的数据
File:代表文本
3.1.1 File创建对象
FileTest
package com.itheima.File;
import java.io.File;
public class FileTest1 {
public static void main(String[] args) {
//1I创建一个File对象,指代某个具体的文件。
//路径分隔符
// File f1=new File("D:\\code\\123.txt");
// File f1=new File("D:/code/123.txt");
File f1 = new File("D:" + File.separator + "code" + File.separator + "123.txt");
System.out.println(f1.length());//返回文件的字节大小 (文件属性里面) 文件大小
File f2 = new File("D:/code");
System.out.println(f2.length());
System.out.println(f2.exists());
// 注意:File对象可以指代一个不存在的文件路径
File f3 = new File("D:/code/21312.txt");
System.out.println(f3.length());
System.out.println(f3.exists());//false
//我现在要定位的文件是在模块中,应该怎么定位呢?
// 绝对路径:带盘符的
// File f4=new File("D:\\code\\javasepro\\opp-app3\\src\\com\\itheima\\File\\itheima.txt");
//相对路径(重点):不带盘符,默认是直接去工程下寻找文件的。
File f4=new File("opp-app3\\src\\com\\itheima\\File\\itheima.txt");
System.out.println(f4.length());
}
}
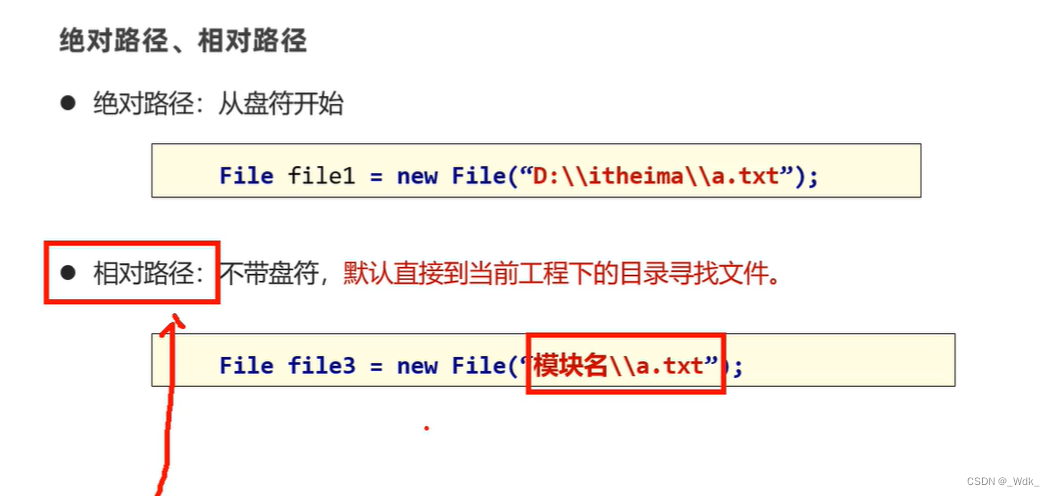
3.1.2 File常用方法
3.1.2.1 判断文件类型、获取文件信息
package com.itheima.File;
import java.io.File;
import java.text.SimpleDateFormat;
public class FileTest2 {
public static void main(String[] args) {
//1、创建文件对象,指代某个文件
File f1=new File("D:/code/123.txt");
//File f1=new File("D:/code");//判断文件
//2、public boolean exists():判断当前文件对象,对应的文件路径是否存在,存在返回true.
System.out.println(f1.exists());
// 3、public boolean isFile(): 判断当前文件对象指代的是否是文件,是文件返回true,反之。
System.out.println(f1.isFile());
// 4、public boolean isDirectory() : 判断当前文件对象指代的是否是文件夹,是文件夹返回true,反之。
System.out.println(f1.isDirectory());
// 5.public String getName():获取文件的名称(包含后缀)
System.out.println(f1.getName());
// 6.public long length():获取文件的大小,返回字节个数
System.out.println(f1.length());
// 7.public long lastModified():获取文件的最后修改时间。
long time=f1.lastModified();
SimpleDateFormat sdf=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
System.out.println(sdf.format(time));
// 8.public String getPath():获取创建文件对象时,使用的路径
File f2=new File("D:/code/123.txt");
File f3=new File("opp-app3\\src\\com\\itheima\\File\\itheima.txt");
System.out.println(f2.getPath());
System.out.println(f3.getPath());
// 9.public string getAbsolutePath():获取绝对路径
System.out.println(f2.getAbsolutePath());
System.out.println(f3.getAbsolutePath());
}
}
3.1.2.2 创建文件、删除文件
注意:delete方法默认只能删除文件和空文件夹,删除后的文件不会进入回收站
package com.itheima.File;
import java.io.File;
public class FileTest3 {
public static void main(String[] args) throws Exception {
//1、public boolean createNewFile():创建一个新文件(文件内容为空),创建成功返回true,反之。
File f1 = new File("D:/code/itheima2.txt");
System.out.println(f1.createNewFile());
//2、public boolean mkdir():用于创建文件爽,注意:只能创建一级文件夹
// File f2=new File("D:/code/aaa");
// System.out.println(f2.mkdir());
//3、public boolean mkdirs():用于创建文件夹,注意:可以创建多级文件夹
//File f3=new File("D:/code/aaa/bbb/ccc");
//4、public boolean delete():删或者空文件,注意:不能删除非空文件夹。
System.out.println(f1.delete());
}
}
3.1.2.3 遍历文件夹
package com.itheima.File;
import java.io.File;
import java.util.Arrays;
public class FileTest4 {
public static void main(String[] args) {
// 1、public String[] list():获取当前目录下所有的"一级文件名称"到一个字符串数组中去返回。
File f1 = new File("D:/code");
String[] names = f1.list();
for (String name : names) {
System.out.println(name);
}
// 2、public File[] listFiles():(重点)获取当前目录下所有的"一级文件对象"到一个文件对象数组中去返回(重点)
File[] files = f1.listFiles();
for (File file : files) {
System.out.println(file.getAbsolutePath());
}
//当主调是文件,或者路径不存在时,返回null
File f=new File("D:/code/123.txt");
File[] files1 = f.listFiles();
System.out.println(files1);
//当主调是空文件夹时,返回一个长度为0的数组[]
File f2=new File("D:/code/aaa");
File[] files2 = f2.listFiles();
System.out.println(Arrays.toString(files2));
}
}
使用listFiles方法时的注意事项:
- 当主调是文件,或者路径不存在时,返回null
- 当主调是空文件夹时,返回一个长度为0的数组
- 当主调是一个有内容的文件夹时,将里面所有一级文件和文件夹的路径放在File数组中返回
- 当主调是一个文件夹,且里面有隐藏文件时,将里面所有文件和文件夹的路径放在File数组中返回,包含隐藏文件
- 当主调是一个文件夹,但是没有权限访问该文件夹时,返回null
3.2 前置知识:方法递归
3.2.1 概述
什么是方法递归?
- 递归是一种在程序设计语言中广泛应用。
- 从形式上说:方法调用自身的形式称为方法递归(recursion)
递归的形式
- 直接递归:方法自己调用自己。
- 间接递归:方法调用其他方法,其他方法又回调方法自己
使用方法递归时需要注意的问题:
- 递归如果没有控制好终止,会出现递归死循环,导致栈内存溢出错误
3.2.2 应用、执行流程、算法思想

package com.itheima.recursion;
public class RecursionTest2 {
public static void main(String[] args) {
System.out.println(f(5));
}
public static int f(int n) {
//终结点
while (true) {
if (n == 1) {
return 1;
} else {
return f(n - 1) * n;
}
}
}
}
3.2.3 其他应用:文件搜索

package com.itheima.recursion;
import java.io.File;
public class RecursionTest3 {
public static void main(String[] args) {
try {
searchFile(new File("D:/"),"WeChat.exe");
} catch (Exception e) {
System.out.println("没有找到");
}
}
/*
* 去目录下搜索某个文件
* dir 目录
* fileName 要搜索文件的名称
* */
public static void searchFile(File dir, String fileName) throws Exception {
//1、把非法的情况拦截
if (dir == null || !dir.exists() || dir.isFile()) {
return;// 代表无法搜索
}
// 2、dir不是null,存在,一定是目录对象
// 获取当前目录下的全部一级文件对象。
File[] files = dir.listFiles();
//3、判断当前目录下是否存在一级文件对象,以及是否可以拿到一级文件对象。
if (files != null && files.length > 0) {
// 4、遍历全部一级文件对象
for (File f : files) {
//5、判断文件是否是文件,还是文件夹
if (f.isFile()) {
// 是文件,判断这个文件名是否是我们要找的
if (f.getName().contains(fileName)) {
System.out.println("找到了:"+f.getAbsolutePath());
Runtime runtime=Runtime.getRuntime();
runtime.exec(f.getAbsolutePath());
}
} else {
// 是文件夹,继续重复这个过程(递归)
searchFile(f, fileName);
}
}
}
}
}
3.3 前置知识:字符集
3.3.1 字符集概述
标准ASCII字符集
- ASCll(American Standard Code for Information Interchange):美国信息交换标准代码,包括了英文、符号等。
- 标准ASCI使用1个字节存储一个字符,首尾是0,总共可表示128个字符,对美国佬来说完全够用。
GBK(汉字内码扩展规范,国标)
- 汉字编码字符集,包含了2万多个汉字等字符,(GBK中一个中文字符编码成两个字节的形式存储)
- 注意:GBK兼容了ASCII字符集。

Unicode字符集(统一码,也叫万国码)
Unicode是国际组织制定的,可以容纳世界上所有文字、符号的字符集。
UTF-8
- 是Unicode字符集的一种编码方案,采取可变长编码方案,共分四个长度区:1个字节,2个字节,3个字节,4个字节
- 英文字符、数字等只占1个字节(兼容标准ASCII编码),汉字字符占用3个字节
- 注意1:字符编码时使用的字符集,和解码时使用的字符集必须一致,否则会出现乱码
- 注意2:英文,数字一般不会乱码,因为很多字符集都兼容了ASCII编码
3.3.2 字符集的编码、解码操作
- 编码:把字符按照指定字符集编码成字节。
- 解码:把字节按照指定字符集解码成字符。

package com.itheima.charset;
import java.util.Arrays;
public class CharSetTest1 {
public static void main(String[] args) throws Exception {
//1、编码
String data = "a我你";
byte[] bytes = data.getBytes();//默认是按照平台字符集(UTF-8)进行编码的。
System.out.println(Arrays.toString(bytes));
// 按照指定字符集进行编码
byte[] byte1 = data.getBytes("GBK");
System.out.println(Arrays.toString(byte1));
// 2、解码
String s1=new String(bytes);//按照平台默认编码(UTF-8)解码
System.out.println(s1);
String s2=new String(byte1,"GBK");
System.out.println(s2);
}
}
3.4 IO流
用于读写数据的(可以读写文件,或网络中的数据..)
IO流:读写数据
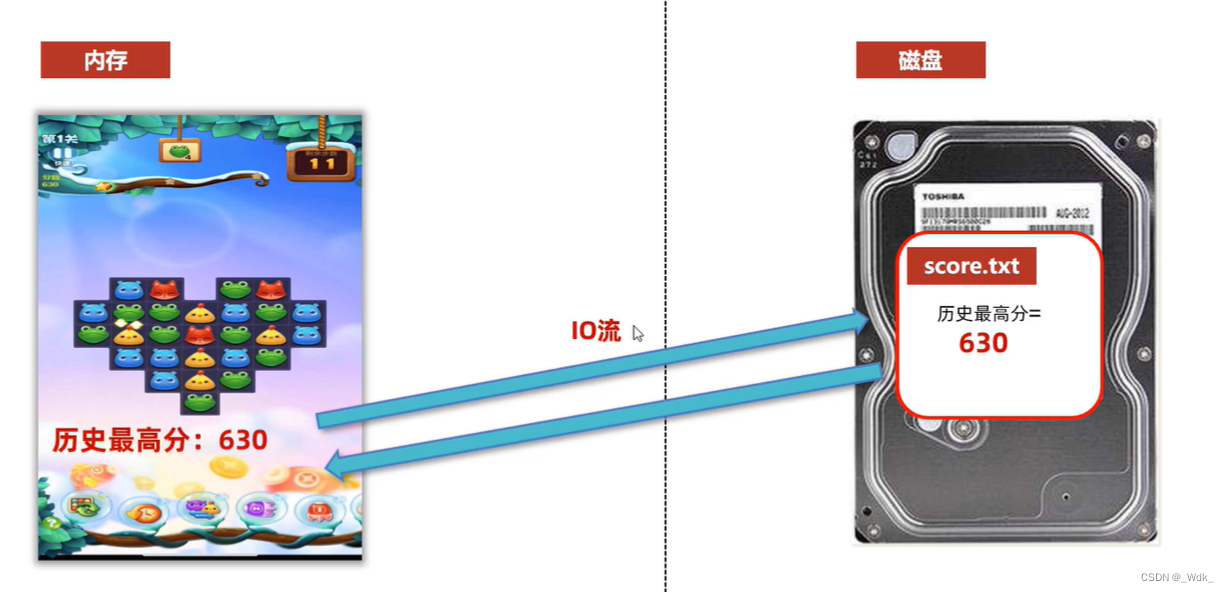
3.4.1 IO流概述
- I指Input,称为输入流:负责把数据读到内存中去
- O指Output,称为输出流:负责写数据出去
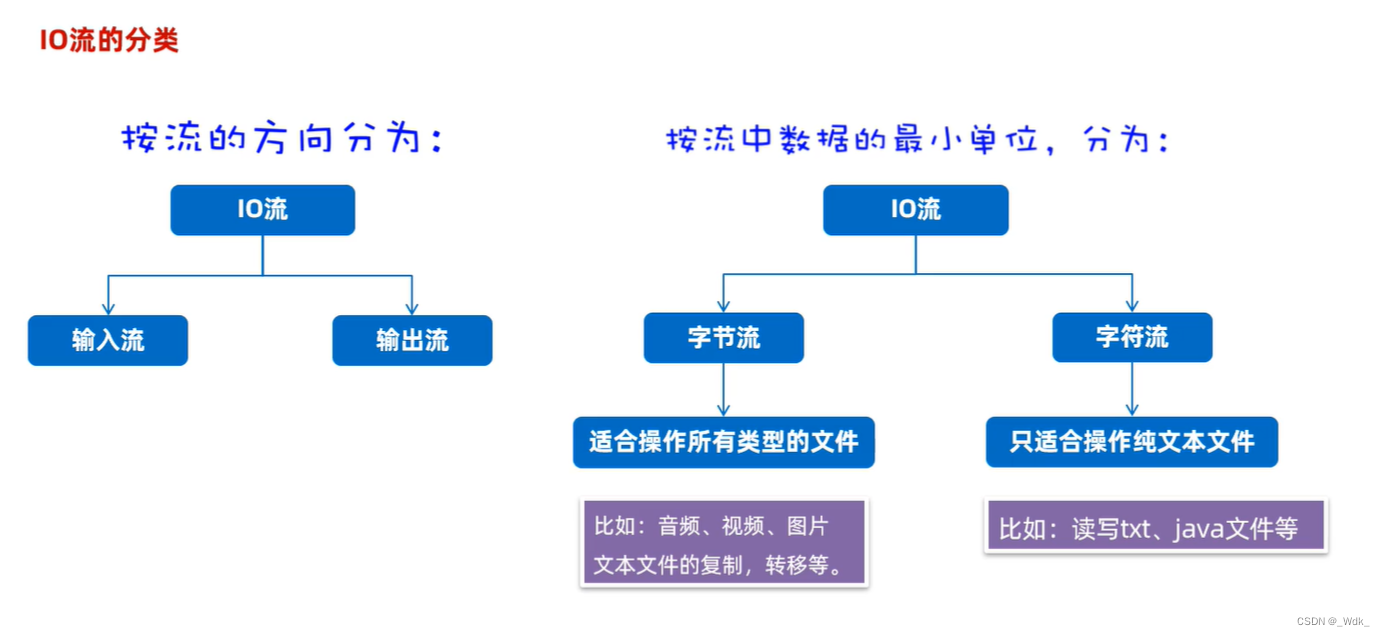
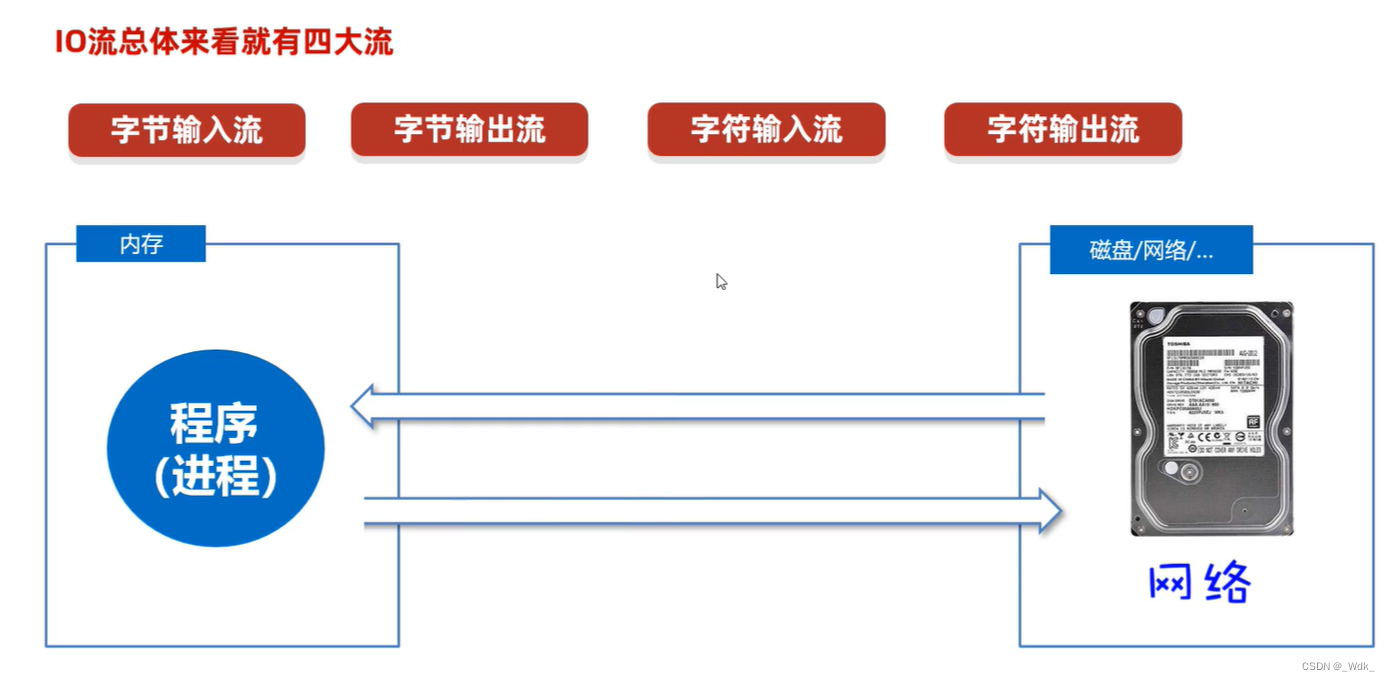
总结流的四大类:
- 字节输入流:以内存为基准,来自磁盘文件/网络中的数据以字节的形式读入到内存中去的流
- 字节输出流:以内存为基准,把内存中的数据以字节写出到磁盘文件或者网络中去的流。
- 字符输入流:以内存为基准,来自磁盘文件/网络中的数据以字符的形式读入到内存中去的流。
- 字符输出流:以内存为基准,把内存中的数据以字符写出到磁盘文件或者网络介质中去的流。
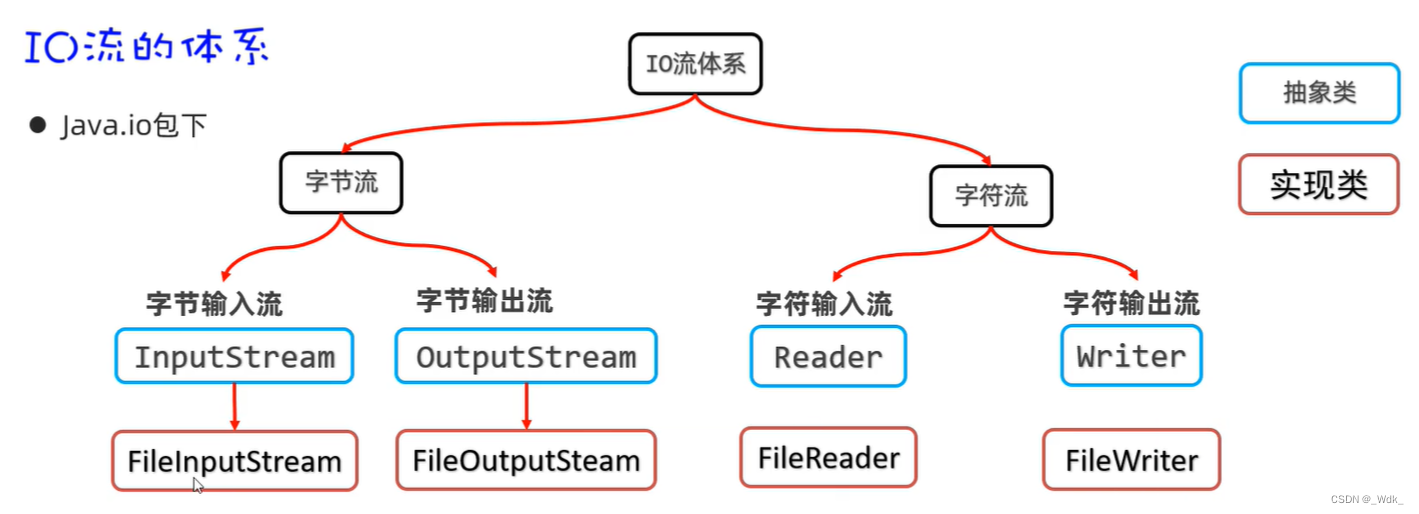
3.4.2 IO字节流
3.4.2.1 FilelnputStream(文件字节输入流)
1.文件字节输入流:每次读取一个字节
作用:以内存为基准,可以把磁盘文件中的数据以字节的形式读入到内存中去。


FileInputStream.class
package com.itheima.byte_stream;
import java.io.FileInputStream;
import java.io.InputStream;
public class FileInputStreamTest1 {
public static void main(String[] args) throws Exception {
// 1、创建文件字节输入流管道,与源文件接通
// InputStream is = new FileInputStream(new File("opp-app3\\src\\com\\itheima\\byte_stream\\itheima01.txt"));
// 简化写法:推荐使用。
InputStream is = new FileInputStream("opp-app3\\src\\com\\itheima\\byte_stream\\itheima01.txt");
// 2、开始读取文件的字节数据。
int b1 = is.read();
System.out.println((char) b1);
int b2 = is.read();
System.out.println((char) b2);
//无字符,返回-1
int b3 = is.read();
System.out.println(b3);
}
}
注:使用FilelnputStream每次读取一个字节,读取性能较差,并且读取汉字输出会乱码。
上述代码使用循环的方法
package com.itheima.byte_stream;
import java.io.FileInputStream;
import java.io.InputStream;
public class FileInputStreamTest1 {
public static void main(String[] args) throws Exception {
// 1、创建文件字节输入流管道,与源文件接通
// InputStream is = new FileInputStream(new File("opp-app3\\src\\com\\itheima\\byte_stream\\itheima01.txt"));
// 简化写法:推荐使用。
InputStream is = new FileInputStream("opp-app3\\src\\com\\itheima\\byte_stream\\itheima01.txt");
// // 2、开始读取文件的字节数据。
// int b1 = is.read();
// System.out.println((char) b1);
// int b2 = is.read();
// System.out.println((char) b2);
//
// //无字符,返回-1
// int b3 = is.read();
// System.out.println(b3);
//
//3、使用循环改造上述代码
int b;
while ((b=is.read())!=-1){
System.out.println((char) b);
}
// 读取数据的性能很差!
// 读取汉字输出会乱码!!无法避免的!!
//流使用完毕之后,必须关闭!释放系统资源!
is.close();
}
}
2.文件字节输入流:每次读取一多字节
package com.itheima.byte_stream;
import java.io.FileInputStream;
import java.io.InputStream;
public class FileInputStreamTest2 {
public static void main(String[] args) throws Exception {
//1、创建一个字节输入流对象代表字节输入流管道与源文件接通
InputStream is = new FileInputStream("opp-app3\\src\\com\\itheima\\byte_stream\\itheima02.txt");
// 2、开始读取文件中的字节数据:每次读取多个字节。
// 每次读取多个字节到字节数组中去,返回读取的字节数量,读取完毕会返回-1.
byte[] buffer=new byte[3];
int len = is.read(buffer);
String rs = new String(buffer);
System.out.println(rs);
System.out.println("当次读取的字节数量:"+len);
int len2=is.read(buffer);
// 注意:读取多少,倒出多少
String rs2=new String(buffer,0,len2);
System.out.println(rs2);
System.out.println("当次读取的字节数量:"+len2);
int len3=is.read(buffer);
System.out.println(len3);
}
}
注意事项
使用Filelnputstream每次读取多个字节,读取性能得到了提升,但读取汉字输出还是会乱码
使用字节流读取中文,如何保证输出不乱码,怎么解决?
定义一个与文件一样大的字节数组,一次性读取完文件的全部字节
package com.itheima.byte_stream;
import java.io.FileInputStream;
import java.io.InputStream;
public class FileInputStreamTest2 {
public static void main(String[] args) throws Exception {
//1、创建一个字节输入流对象代表字节输入流管道与源文件接通
InputStream is = new FileInputStream("opp-app3\\src\\com\\itheima\\byte_stream\\itheima02.txt");
// // 2、开始读取文件中的字节数据:每次读取多个字节。
//
// // 每次读取多个字节到字节数组中去,返回读取的字节数量,读取完毕会返回-1.
// byte[] buffer=new byte[3];
// int len = is.read(buffer);
// String rs = new String(buffer);
// System.out.println(rs);
// System.out.println("当次读取的字节数量:"+len);
//
// int len2=is.read(buffer);
// // 注意:读取多少,倒出多少
// String rs2=new String(buffer,0,len2);
// System.out.println(rs2);
// System.out.println("当次读取的字节数量:"+len2);
//
// int len3=is.read(buffer);
// System.out.println(len3);
//3、使用循环改造
byte[] buffer = new byte[3]; //
int len;//记住每次读取了多少个字节。
while ((len = is.read(buffer)) != -1) {
//注意:读取多少,倒出多少。
String rs = new String(buffer, 0, len);
System.out.println(rs);
}
// 性能得到了明显的提升!!
// 这种方案也不能避免读取汉字输出乱码的问题!!
is.close();//关闭流
}
}
3.文件字节输入流:一次读取完全部字节
可以解决字节流读取中文输出乱码的问题!

- 方式一:自己定义一个字节数组与被读取的文件大小一样大,然后使用该字节数组,一次读完文件的全部字节。
package com.itheima.byte_stream;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStream;
public class FileInputStreamTest3 {
public static void main(String[] args) throws Exception {
InputStream is=new FileInputStream("opp-app3\\src\\com\\itheima\\byte_stream\\itheima03.txt");
File f=new File("opp-app3\\src\\com\\itheima\\byte_stream\\itheima03.txt");
long size=f.length();
byte[] buffer=new byte[(int)size];
int len=is.read(buffer);
System.out.println(new String(buffer));
System.out.println(size);
System.out.println(len);
}
}
- 方式二:Java官方为InputStream提供了如下方法,可以直接把文件的全部字节读取到一个字节数组中返回。
直接把文件数据全部读取到一个字节数组可以避免乱码,是否存在问题?
- 如果文件过大,创建的字节数组也会过大,可能引起内存溢出。
- 读写文本内容更适合:字符流
- 字节流:适合做数据的转移,如:文件复制等
package com.itheima.byte_stream;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStream;
public class FileInputStreamTest3 {
public static void main(String[] args) throws Exception {
//1、一次性读取完文件的全部字节到一个字节数组中去。
// 创建一个字节输入流管道与源文件接通
InputStream is=new FileInputStream("opp-app3\\src\\com\\itheima\\byte_stream\\itheima03.txt");
File f=new File("opp-app3\\src\\com\\itheima\\byte_stream\\itheima03.txt");
// 2、准备一个字节数组,大小与文件的大小正好一样大。
// long size=f.length();
// byte[] buffer=new byte[(int)size];
// int len=is.read(buffer);
// System.out.println(new String(buffer));
// System.out.println(size);
// System.out.println(len);
byte[] buffer=is.readAllBytes();
System.out.println(new String(buffer));
}
}
3.4.2.2 FileOutputstream(文件字节输出流)
1.文件字节输出流:写字节出去
作用:以内存为基准,把内存中的数据以字节的形式写出到文件中去


package com.itheima.byte_stream;
import java.io.FileOutputStream;
import java.io.OutputStream;
public class FileInputStreamTest4 {
public static void main(String[] args) throws Exception {
//1、 创建一个字节输出流管道与源文件接通
// OutputStream os = new FileOutputStream("opp-app3\\src\\com\\itheima\\byte_stream\\itheima.txt");
//追加数据的管道
OutputStream os = new FileOutputStream("opp-app3\\src\\com\\itheima\\byte_stream\\itheima.txt",true);
//2、开始写字节数据出去
os.write(97);//97就hi一个字节,代表a
os.write('b');//'b' 也是一个字节
byte[] bytes="啊哈哈哈哈aa".getBytes();
os.write(bytes);
os.write(bytes,0,15);
//换行
os.write("\r\n".getBytes());
os.close();//关闭流
}
}
3.4.2.3 文件的复制
package com.itheima.byte_stream;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.OutputStream;
public class CopyTest1 {
public static void main(String[] args) throws Exception {
// 需求:复制照片。
// 1、创建一个字节输入流管道与源文件接通
InputStream is=new FileInputStream("D:/code/123.txt");
// 2、创建一个字节输出流管道与目标文件接通。
OutputStream os=new FileOutputStream("F:/123.txt");
// 3、创建一个字节数组,负责转移字节数据。
byte[] buffer=new byte[1024*8];//1KB
//4、创建一个字节数组,负责转移字节数据。读多少写出去多少。
int len;//用来记住每次读取了多少个字节
while ((len=is.read(buffer))!=-1){
os.write(buffer,0,len);
}
os.close();
is.close();
System.out.println("复制完成!");
}
}
3.4.3 释放资源方式
3.4.3.1 try-catch-finally
finally代码区的特点:无论try中的程序是正常执行了,还是出现了异常,最后都一定会执行finally区,除非JVM终止。

作用:一般用于在程序执行完成后进行资源的释放操作(专业级做法)
package com.itheima.resource;
public class Test1 {
public static void main(String[] args) {
try {
System.out.println(10 / 2);
// return;//跳出方法
//System.exit(0);//虚拟机
} catch (Exception e) {
e.printStackTrace();
} finally {
System.out.println("==========finally===========执行了一次");
}
}
public static int chu(int a,int b ){
try {
return a/b;
}catch (Exception e){
e.printStackTrace();;
return -1;//代表出现异常
}finally {
//千万不要在finally中返回数据!!
}
}
}
package com.itheima.resource;
import java.io.*;
public class Test2 {
public static void main(String[] args) {
InputStream is = null;
OutputStream os = null;
try {
//1、创建一个字节输入流与源文件连接
is = new FileInputStream("opp-app3\\src\\com\\itheima\\resource\\itheima1.txt");
//2、创建一个字节输出流管道与目标文件接通。
os = new FileOutputStream("opp-app3\\src\\com\\itheima\\resource\\itheima1copy.txt");
//3、创建一个字节数组,负责转移字节数据
byte[] buffer = new byte[1024];
//4、从字节输入流中读取字节数据,写出去到字节输出流中,读多少写多少
int len;//记住每次读取多少个字节
while ((len = is.read(buffer)) != -1) {
os.write(buffer, 0, len);
}
System.out.println("复制完成");
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (os != null) os.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
if (is != null) is.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
3.4.3.2 try-with-resource

该资源使用完毕后,会自动调用其close()方法,完成对资源的释放!

MyConnection.class
package com.itheima.resource;
public class MyConnection implements AutoCloseable{
@Override
public void close() throws Exception {
System.out.println("释放了与某个硬件的链接资源");
}
}
Test.class
package com.itheima.resource;
import java.io.*;
public class Test3 {
public static void main(String[] args) {
try (//1、创建一个字节输入流与源文件连接
InputStream is = new FileInputStream("opp-app3\\src\\com\\itheima\\resource\\itheima1.txt");
//2、创建一个字节输出流管道与目标文件接通。
OutputStream os = new FileOutputStream("opp-app3\\src\\com\\itheima\\resource\\itheima1copy.txt");
// 注意:这里只能放置资源对象。(流对象)
//什么是资源呢?资源都是会实现AutoCloseable接口,资源都会有一个close方法,并且资源放到这里后
//用完之后,会被自动调用其close方法完成资源的释放操作。
MyConnection conn = new MyConnection();
) {
//3、创建一个字节数组,负责转移字节数据
byte[] buffer = new byte[1024];
//4、从字节输入流中读取字节数据,写出去到字节输出流中,读多少写多少
int len;//记住每次读取多少个字节
while ((len = is.read(buffer)) != -1) {
os.write(buffer, 0, len);
}
System.out.println(conn);
System.out.println("复制完成");
System.out.println(conn);
} catch (Exception e) {
e.printStackTrace();
}
}
}
3.4.4 IO字符流
- 字节流:适合复制文件等,不适合读写文本文件
- 字符流:适合读写文本文件内容
3.4.4.1 FileReader(文件字符输入流)
1.文件字符输入流-读字符数据进来
作用:以内存为基准,可以把文件中的数据以字符的形式读入到内存中去

package com.itheima.char_stream;
import java.io.FileReader;
import java.io.Reader;
public class FileReaderTest1 {
public static void main(String[] args) {
try (
// 1、创建一个文件字符输入流管道与源文件接通
Reader fr=new FileReader("opp-app3\\src\\com\\itheima\\char_stream\\itheima01.txt");
){
// 2、读取文本文件的内容了
// int c;//记住每次读取字符编号
// while ((c=fr.read())!=-1){
// System.out.print((char)c);//不要换行
// }
//每次读取一个字符的形式,性能背定是比较差的
// 3、每次读取多个字符。
char[] buffer=new char[3];
int len;//记住每次读取了多少个字符。
while ((len=fr.read(buffer))!=-1){
// 读取多少倒出多少
System.out.print(new String(buffer,0,len));
}
// 性能是比较不错的!
} catch (Exception e) {
e.printStackTrace();
}
}
}
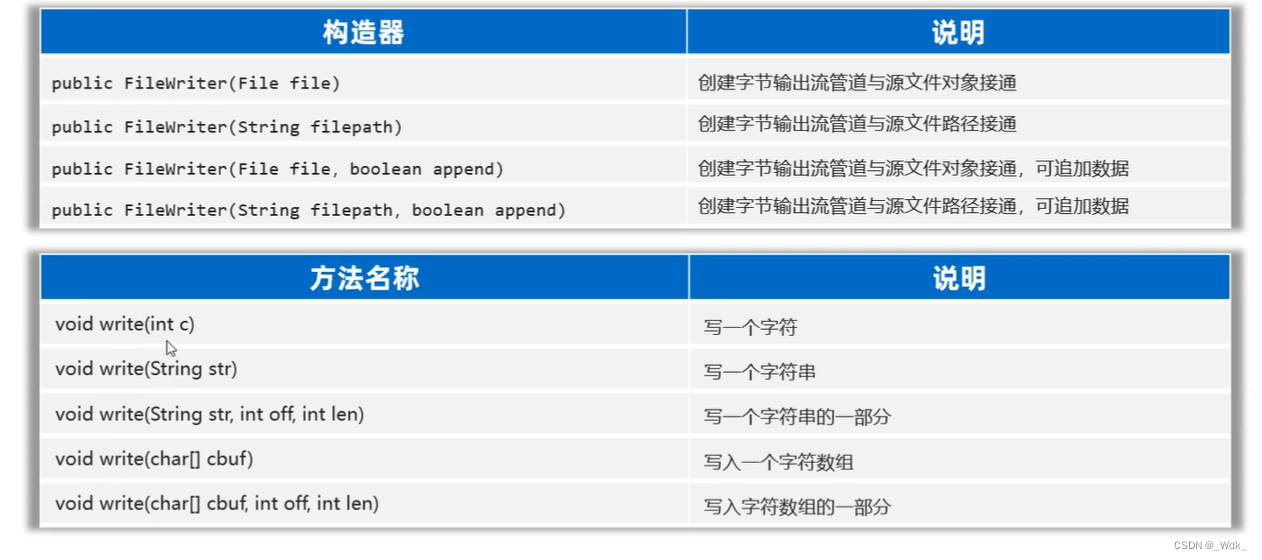
3.4.4.2 FileWriter(文件字符输出流)
作用:以内存为基准,把内存中的数据以字符的形式写出到文件中去
文件字符输出流-写字符数据出去

FileReaderTest.class
package com.itheima.char_stream;
import java.io.FileWriter;
import java.io.IOException;
import java.io.Writer;
public class FileReaderTest2 {
public static void main(String[] args) {
try (
//0、创建一个文件字符输出流管道与目标文件接通,
// Writer fw=new FileWriter("opp-app3\\src\\com\\itheima\\char_stream\\itheima01.txt");
Writer fw=new FileWriter("opp-app3\\src\\com\\itheima\\char_stream\\itheima01.txt",true);
)
{
//1、public void write(int c):写一个字符出去
fw.write('a');
fw.write(97);
fw.write('哈');
fw.write("\r\n");
//2、public void write(string c)写一个字符串出去
fw.write("一二三四五六七八九十");
fw.write("\r\n");
// 3、public void write(String c,int pos ,int len):写字符串的一部分出去
fw.write("一二三四五六七八九十",2,4);
fw.write("\r\n");
// 4、public void write(char[] buffer):写一个字符数组出去
char[] buffer={'a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z'};
fw.write(buffer);
fw.write("\r\n");
//5、public void write(char[]buffer ,int pos ,int len):写字符数组的一部分出去
fw.write(buffer,0,2);
fw.write("\r\n");
} catch (IOException e) {
e.printStackTrace();
}
}
}
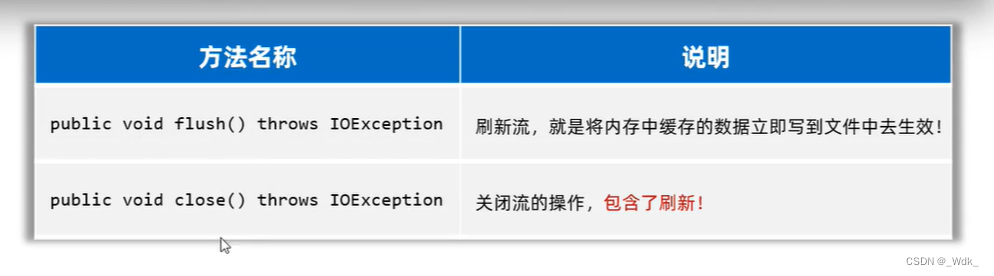
字符输出流使用时的注意事项
- 字符输出流写出数据后,必须刷新流,或者关闭流,写出去的数据才能生效
FileReaderTest.class
package com.itheima.char_stream;
import java.io.FileWriter;
import java.io.IOException;
import java.io.Writer;
public class FileReaderTest3 {
public static void main(String[] args) throws IOException {
Writer fw = new FileWriter("opp-app3\\src\\com\\itheima\\char_stream\\itheima01.txt");
//写字符数据出去
fw.write('a');
fw.write('b');
fw.write('c');
fw.write('d');
fw.write("\r\n");
fw.write("一二三四五六七八九十");
fw.write("\r\n");
fw.write("一二三四五六七八九十");
// fw.flush(); //刷新流
// fw.write("张三");
fw.close();// 关闭流,关闭流包含刷新的操作
// fw.write("张三");
}
}
字节流、字符流的使用场景小结
- 字节流适合做一切文件数据的拷贝(音视频,文本);
- 字节流不适合读取中文内容输出字符流适合做文本文件的操作(读,写)。
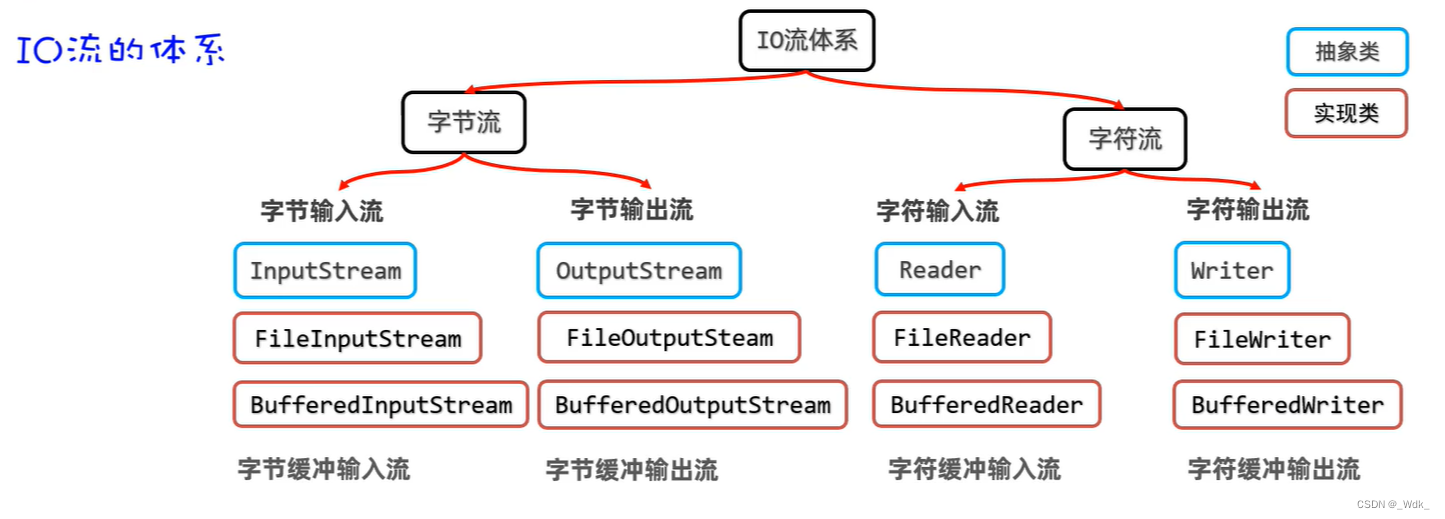
3.4.5 IO缓冲流
缓冲流的作用:对原始流进行包装,以提高原始流读写数据的性能
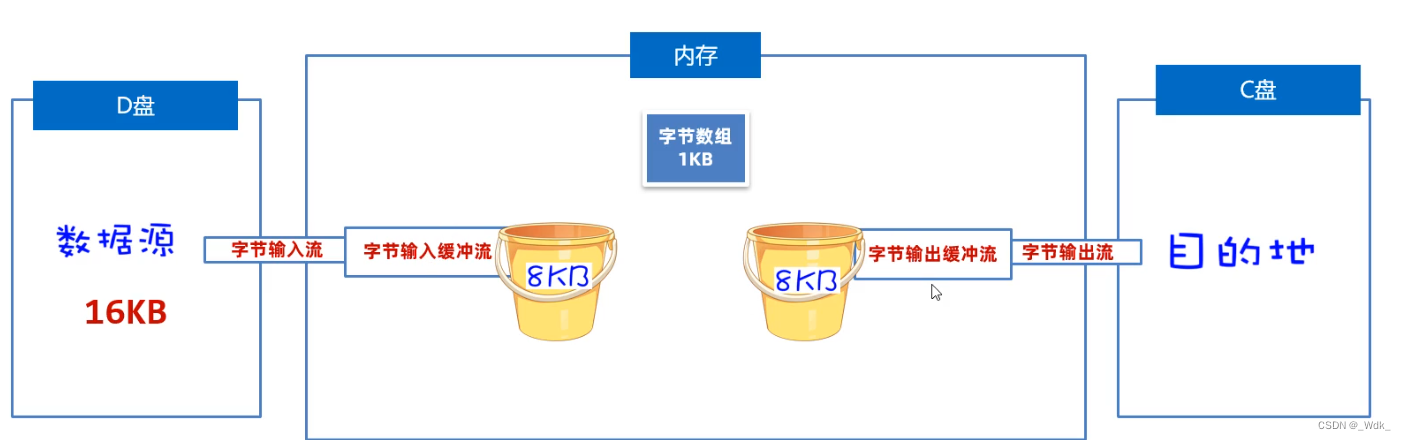
3.4.5.1 BufferedInputStream 与 BufferedOutputStream(字节缓冲流)
作用:提高字节流读写数据的性能
原理:字节缓冲输入流自带了8KB缓冲池;字节缓冲输出流也自带了8KB缓冲池

package com.itheima.buffered_stream;
import java.io.*;
public class BufferedInputStreamTest1 {
public static void main(String[] args) {
try (
InputStream is=new FileInputStream("opp-app3\\src\\com\\itheima\\buffered_stream\\itheima01.txt");
OutputStream os=new FileOutputStream("opp-app3\\src\\com\\itheima\\buffered_stream\\itheima01_copy.txt");
// 1、定义一个字节缓冲输入流包装原始的字节输入流
InputStream bis=new BufferedInputStream(is);
OutputStream bos=new BufferedOutputStream(os);
){
byte []buffer=new byte[1024*8];
int len;
while((len=bis.read(buffer))!=-1){
os.write(buffer,0,len);
}
System.out.println("复制完成!");
} catch (IOException e) {
e.printStackTrace();
}
}
}
3.4.5.2 BufferedReader 与 BufferedWriter(字符缓冲流)
1. BufferedReader(字符缓冲输入流)
作用:自带8K(8192)的字符缓冲池,可以提高字符输入流读取字符数据的性能。

BufferedReaderTest.class
package com.itheima.buffered_stream;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.Reader;
public class BufferedReaderTest1 {
public static void main(String[] args) {
try (
Reader fr=new FileReader("opp-app3\\src\\com\\itheima\\buffered_stream\\itheima02.txt");
// 1、定义一个字符缓冲输入流包装原始的字符输入流
BufferedReader br=new BufferedReader(fr);
){
char[] buffer=new char[3];
int len;
while ((len=br.read(buffer))!=-1){
System.out.print(new String(buffer,0,len));
}
String line;//记住每次读取的每一行数据
while ((line=br.readLine())!=null){
System.out.println(line);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
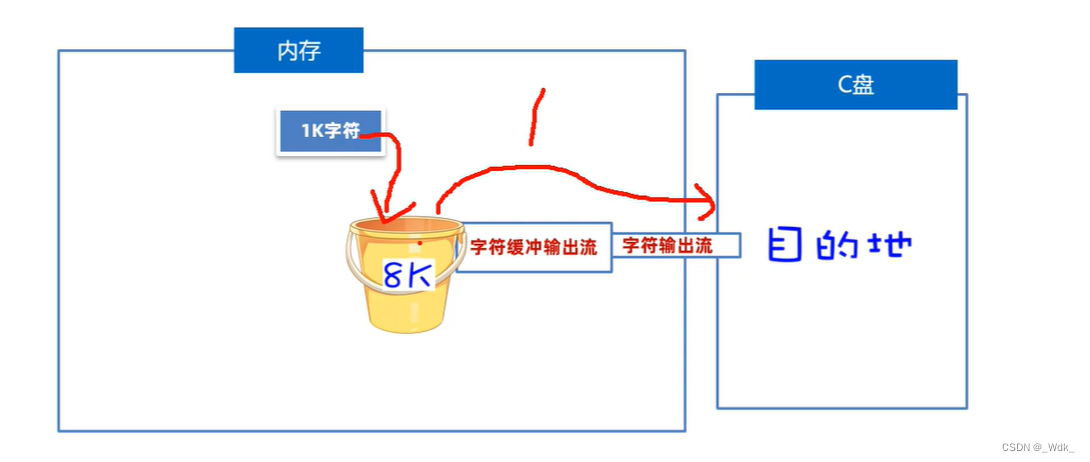
2. BufferedWriter(字符缓冲输出流)
作用:自带8K的字符缓冲池,可以提高字符输出流写字符数据的性能
package com.itheima.buffered_stream;
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.Writer;
public class BufferedWriterTest1 {
public static void main(String[] args) {
try (
//0、创建一个文件字符输出流管道与目标文件接通,
// Writer fw=new FileWriter("opp-app3\\src\\com\\itheima\\char_stream\\itheima01.txt");
Writer fw=new FileWriter("opp-app3\\src\\com\\itheima\\buffered_stream/itheima01out.txt",true);
BufferedWriter bw=new BufferedWriter(fw)
)
{
//1、public void write(int c):写一个字符出去
bw.write('a');
bw.write(97);
bw.write('哈');
bw.newLine();//自带的总动换行
//2、public void write(string c)写一个字符串出去
bw.write("一二三四五六七八九十");
bw.newLine();//自带的总动换行
// 3、public void write(String c,int pos ,int len):写字符串的一部分出去
bw.write("一二三四五六七八九十",2,4);
bw.newLine();//自带的总动换行
// 4、public void write(char[] buffer):写一个字符数组出去
char[] buffer={'a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z'};
bw.write(buffer);
bw.newLine();//自带的总动换行
//5、public void write(char[]buffer ,int pos ,int len):写字符数组的一部分出去
bw.write(buffer,0,2);
} catch (Exception e) {
e.printStackTrace();
}
}
}
3.4.5.3 原始流、缓冲流的性能分析[重点]

TimeTest.class
package com.itheima.buffered_stream;
import java.io.*;
public class TimeTest {
public static void main(String[] args) {
// copy();//低级字节流一个一个复制耗时速度极慢,极不推荐!!!
copy2();//可以调整数组内存空间的大小,空间越大跟缓冲字节数组耗时时间差不多
// copy3();//缓冲流一个一个字节复制耗时速度较慢
copy4();//可以调整缓冲池的内存大小,适当的选择使用低级字节流使用字节数组复制的方法
}
private static final String SRC_FILE = "D:\\code\\基础语法.mp4";
private static final String DEST_FILE="D:\\code\\";
private static void copy() {
long startTime=System.currentTimeMillis();
try (
InputStream is = new FileInputStream(SRC_FILE);
OutputStream os = new FileOutputStream(DEST_FILE+"1.mp4");
) {
int b;
while ((b = is.read()) != -1) {
os.write(b);
}
} catch (Exception e) {
e.printStackTrace();
}
long endTime=System.currentTimeMillis();
System.out.println("低级字节流一个一个复制耗时:"+(endTime-startTime)/1000.0+"s");
}
private static void copy2() {
long startTime=System.currentTimeMillis();//获得当前时间的毫秒值
try (
InputStream is = new FileInputStream(SRC_FILE);
OutputStream os = new FileOutputStream(DEST_FILE+"2.mp4");
) {
byte[] buffer=new byte[1024*32];//32kB
int len;
while((len=is.read(buffer))!=-1){
os.write(buffer,0,len);
}
} catch (Exception e) {
e.printStackTrace();
}
long endTime=System.currentTimeMillis();
System.out.println("低级字节流使用字符数组复制耗时:"+(endTime-startTime)/1000.0+"s");
}
private static void copy3() {
long startTime=System.currentTimeMillis();
try (
InputStream is = new FileInputStream(SRC_FILE);
BufferedInputStream bis=new BufferedInputStream(is);
OutputStream os = new FileOutputStream(DEST_FILE+"3.mp4");
BufferedOutputStream bos=new BufferedOutputStream(os);
) {
int b;
while ((b = bis.read()) != -1) {
bos.write(b);
}
} catch (Exception e) {
e.printStackTrace();
}
long endTime=System.currentTimeMillis();
System.out.println("缓冲流一个一个字节复制耗时:"+(endTime-startTime)/1000.0+"s");
}
private static void copy4() {
long startTime=System.currentTimeMillis();//获得当前时间的毫秒值
try (
InputStream is = new FileInputStream(SRC_FILE);
BufferedInputStream bis=new BufferedInputStream(is,32*1024);//设置缓冲池的内存大小
OutputStream os = new FileOutputStream(DEST_FILE+"4.mp4");
BufferedOutputStream bos=new BufferedOutputStream(os,32*1024);
) {
byte[] buffer=new byte[1024*32];//32kB
int len;
while((len=bis.read(buffer))!=-1){
bos.write(buffer,0,len);
}
} catch (Exception e) {
e.printStackTrace();
}
long endTime=System.currentTimeMillis();
System.out.println("缓冲流使用字符数组复制耗时:"+(endTime-startTime)/1000.0+"s");
}
}
3.4.6 IO转换流
3.4.6.1 引出问题:不同编码读取时会乱码
-
如果代码编码和被读取的文本文件的编码是一致的,使用字符流读取文本文件时不会出现乱码!
-
如果代码编码和被读取的文本文件的编码是不一致的,使用字符流读取文本文件时就会出现乱码!
package com.itheima.transform_stream;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.Reader;
public class Test1 {
public static void main(String[] args) {
try (
// 1、创建一个文件字符输入流与源文件接通
//代码编码:UTF-8文件的编码:UTF-8
// 代码编码:UTF-8 文件的编码:GBK
//UTF-8 一个汉字占用3个字节 GBK一个汉字占用2个字节
Reader fr = new FileReader("opp-app3\\src\\com\\itheima\\transform_stream\\itheima.txt");
// 2、把文件字符输入流包装成缓冲字符输入追
BufferedReader br = new BufferedReader(fr);
) {
String Line;
while ((Line = br.readLine()) != null) {
System.out.println(Line);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
3.4.6.2 InputStreamReader(字符输入转换流)
- 解决不同编码时,字符流读取文本内容乱码的问题。
- 解决思路:先获取文件的原始字节流,再将其按真实的字符集编码转成字符输入流,这样字符输入流中的字符就不乱码了。
InputStreamReaderTest.class
package com.itheima.transform_stream;
import java.io.*;
public class InputStreamReaderTest {
public static void main(String[] args) {
try (
//1、得到文件的原始字节流(GBK的字节流形式)
InputStream is = new FileInputStream("opp-app3\\src\\com\\itheima\\transform_stream\\itheima2.txt");
// 2、把原始的字节输入流按照指定的字符集编码转换成字符输入流
Reader isr = new InputStreamReader(is, "GBK");
//3、把字符输入流包装成缓冲字符输入流
BufferedReader br=new BufferedReader(isr);
) {
String Line;
while ((Line=br.readLine())!=null){
System.out.println(Line);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
3.4.6.3 OutputStreamWriter(字符输出转换流)

- 作用:可以控制写出去的字符使用什么字符集编码,
- 解决思路:获取字节输出流,再按照指定的字符集编码将其转换成字符输出流,以后写出去的字符就会用该字符集编码了

package com.itheima.transform_stream;
import java.io.*;
public class OutputStreamWriterTest {
public static void main(String[] args) {
try ( //指定写出去的字符编码
// 1、创建一个文件字节输出流
OutputStream os = new FileOutputStream("opp-app3\\src\\com\\itheima\\transform_stream\\itheima3.txt");
Writer osw = new OutputStreamWriter(os, "GBK");
BufferedWriter bw = new BufferedWriter(osw);
) {
bw.write("你好,中国");
bw.write("\r\n");
bw.write("你好,中国");
bw.write("\r\n");
bw.write("你好,中国");
} catch (Exception e) {
e.printStackTrace();
}
}
}
3.4.7 IO打印流
作用:打印流可以实现更方便、更高效的打印数据出去,能实现打印啥出去就是啥出去。
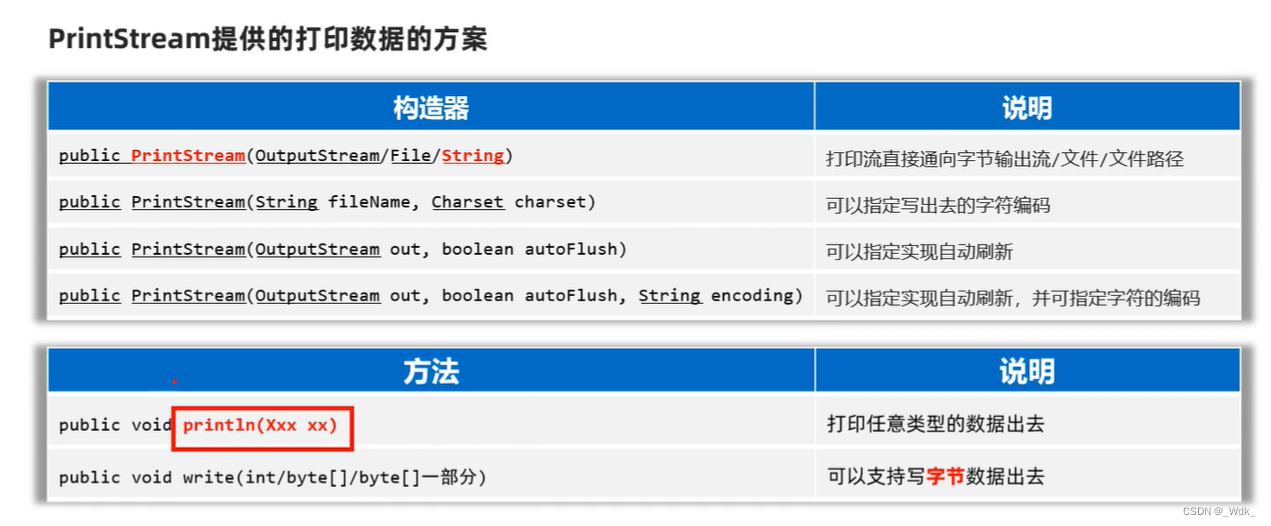

package com.itheima.printstream;
import java.io.PrintWriter;
import java.nio.charset.Charset;
public class PrintTest1 {
public static void main(String[] args) {
try (
// 1、创建一个打印流管道
//PrintStream ps = new PrintStream("opp-app3\\src\\com\\itheima\\printstream\\itheima01.txt", Charset.forName("UTF-8"));//可以写字节
PrintWriter ps=new PrintWriter("opp-app3\\src\\com\\itheima\\printstream\\itheima01.txt", Charset.forName("UTF-8"))// PrintWriter可以写字符 ,且不能追加字符,除非转换成低级流
) {
ps.println("你好!");
ps.println(11);
ps.println('a');
ps.println(true);
ps.println(1.1);
//写字节出去
ps.write(97);// a
} catch (Exception e) {
e.printStackTrace();
}
}
}
PrintStream和PrintWriter的区别
- 打印数据的功能上是一模一样的:都是使用方便,性能高效(核心优势)
- PrintStream继承自字节输出流OutputStream,因此支持写字节数据的方法。
- PrintWriter继承自字符输出流Writer,因此支持写字符数据出去
3.4.7.1 输出语句的重定向
可以把输出语句的打印位置改到某个文件中去
package com.itheima.printstream;
import java.io.PrintStream;
public class PrintTest2 {
public static void main(String[] args) {
System.out.println("老骥伏枥");
System.out.println("志在千里");
try (
PrintStream ps = new PrintStream("opp-app3\\src\\com\\itheima\\printstream\\itheima02.txt");
){
//把系统默认的打印流对象改成自己设置的打印流
System.setOut(ps);
System.out.println("烈士暮年");
System.out.println("壮心不已");
} catch (Exception e) {
e.printStackTrace();
}
}
}
3.4.8 IO数据流
3.4.8.1 DataOutputstream(数据输出流)
允许把数据和其类型一并写出去

package com.itheima.d17_stream.d7_data_stream;
import java.io.*;
public class DataOutPutStreamTest1 {
public static void main(String[] args) {
//1、创建一个数据输出流包装低级的字节输出流
try (
DataOutputStream dos = new DataOutputStream(new FileOutputStream("opp-app3\\src\\com\\itheima\\d17_stream\\d7_data_stream\\itheima01.txt"));
) {
dos.writeInt(97);
dos.writeDouble(97.2);
dos.writeBoolean(true);
dos.writeUTF("士大夫");
} catch (Exception e) {
e.printStackTrace();
}
}
}
3.4.8.2 Datalnputstream(数据输入流)
用于读取数据输出流写出去的数据。

package com.itheima.d17_stream.d7_data_stream;
import java.io.DataInputStream;
import java.io.FileInputStream;
public class DataInPutStreamTest2 {
public static void main(String[] args) {
//1、创建一个数据输出流包装低级的字节输出流
try (
DataInputStream dis = new DataInputStream(new FileInputStream("opp-app3\\src\\com\\itheima\\d17_stream\\d7_data_stream\\itheima01.txt"));
) {
int i = dis.readInt();
System.out.println(i);
double d = dis.readDouble();
System.out.println(d);
boolean b = dis.readBoolean();
System.out.println(b);
String rs = dis.readUTF();
System.out.println(rs);
} catch (Exception e) {
e.printStackTrace();
}
}
}
3.4.9 IO序列化流
- 对象序列化:把Java对象写入到文件中去
- 对象反序列化:把文件里的ava对象读出来

3.4.9.1 ObjectOutputstream(对象字节输出流)
可以把Java对象进行序列化:把Java对象存入到文件中去。
注意:对象如果要参与序列化,必须实现序列化接口(iava.io.Serializable)
ObjectOutPutStream.class
package com.itheima.d17_stream.d8_object_stream;
import java.io.FileOutputStream;
import java.io.ObjectOutputStream;
// 注意:对象如果需要序列化,必须实现序列化接口。
public class Test1ObjectOutPutStream {
public static void main(String[] args) {
try(
// 2、创建一个对象字节输出流包装原始的字节 输出流。
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("opp-app3\\src\\com\\itheima\\d17_stream\\d8_object_stream\\itheima01.txt"));
) {
// 1、创建一个Java对象。
User user=new User("admin","张三",32,"666888xyz");
//3、序列化对象到文件中去
oos.writeObject(user);
System.out.println("序列化对象成功!");
} catch (Exception e) {
e.printStackTrace();
}
}
}
3.4.9.2 Objectlnputstream(对象字节输入流)
可以把Java对象进行反序列化:把存储在文件中的Java对象读入到内存中来。

如果要一次序列化多个对象,咋整?
- 用一个ArrayList集合存储多个对象,然后直接对集合进行序列化即可
- 注意:ArrayList集合已经实现了序列化接口!
student.class
package com.itheima.d17_stream.d8_object_stream;
import java.io.Serializable;
public class User implements Serializable {
private String lgoinName;
private String userName;
private int age;
// transient修饰的成员变量,不参与序列化
private transient String passWord;
public User() {
}
@Override
public String toString() {
return "User{" +
"lgoinName='" + lgoinName + '\'' +
", userName='" + userName + '\'' +
", age=" + age +
", passWord='" + passWord + '\'' +
'}';
}
public String getLgoinName() {
return lgoinName;
}
public void setLgoinName(String lgoinName) {
this.lgoinName = lgoinName;
}
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getPassWord() {
return passWord;
}
public void setPassWord(String passWord) {
this.passWord = passWord;
}
public User(String lgoinName, String userName, int age, String passWord) {
this.lgoinName = lgoinName;
this.userName = userName;
this.age = age;
this.passWord = passWord;
}
}
ObjectOutPutStream.class
package com.itheima.d17_stream.d8_object_stream;
import java.io.FileInputStream;
import java.io.ObjectInputStream;
// 注意:对象如果需要序列化,必须实现序列化接口。
public class Test2ObjectOutPutStream {
public static void main(String[] args) {
try (
// 1、创建一个对象字节输入流管道,包装 低级的字节输入流与源文件接通
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("opp-app3\\src\\com\\itheima\\d17_stream\\d8_object_stream\\itheima01.txt"));
) {
//2、反序列化对象到文件中去
User user=(User) ois.readObject();
System.out.println(user);
System.out.println("反序列化对象成功!");
} catch (Exception e) {
e.printStackTrace();
}
}
}
3.4.10 补充知识:IO框架
1. 什么是框架?
- 解决某类问题,编写的一套类、接口等,可以理解成一个半成品,大多框架都是第三方研发的。
- 好处:在框架的基础上开发,可以得到优秀的软件架构,并能提高开发效率
- 框架的形式:一般是把类、接口等编译成class形式,再压缩成一个.jar结尾的文件发行出去
2. 什么是IO框架?
封装了lava提供的对文件、数据进行操作的代码,对外提供了更简单的方式来对文件进行操作,对数据进行读写等。
3.Commons-io
Commons-io是apache开源基金组织提供的一组有关io操作的小框架,目的是提高io流的开发效率。

绑定一个目前2024.6.6号的查看的版本:
步骤:
- 导入commons-io.jar框架到项目中去。
- 在项目中创建一个文件夹:lib
- 将commons-io.jar文件复制到lib文件夹
- 在jar文件上点右键,选择 Add as Library->点击OK
- 在类中导包使用
package com.itheima.d17_stream.d7_commons_io;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
public class CommonIOTest1 {
public static void main(String[] args) throws IOException {
// FileUtils.copyFile(new File("opp-app3\\src\\com\\itheima\\d17_stream\\d7_commons_io\\a.txt"), new File("opp-app3\\src\\com\\itheima\\d17_stream\\d7_commons_io\\b.txt"));
// FileUtils.copyDirectory(new File("opp-app3\\src\\com\\itheima\\d17_stream\\d7_commons_io\\a.txt"), new File("opp-app3\\src\\com\\itheima\\d17_stream\\d7_commons_io\\b.txt"));
// FileUtils.deleteDirectory("");
// Java提供的原生的一行代码搞定很多事情
//Files.copy(Path.of("opp-app3\\src\\com\\itheima\\d17_stream\\d7_commons_io\\a.txt"),Path.of("opp-app3\\src\\com\\itheima\\d17_stream\\d7_commons_io\\b.txt"));
System.out.println(Files.readString(Path.of("opp-app3\\src\\com\\itheima\\d17_stream\\d7_commons_io\\a.txt")));
}
}
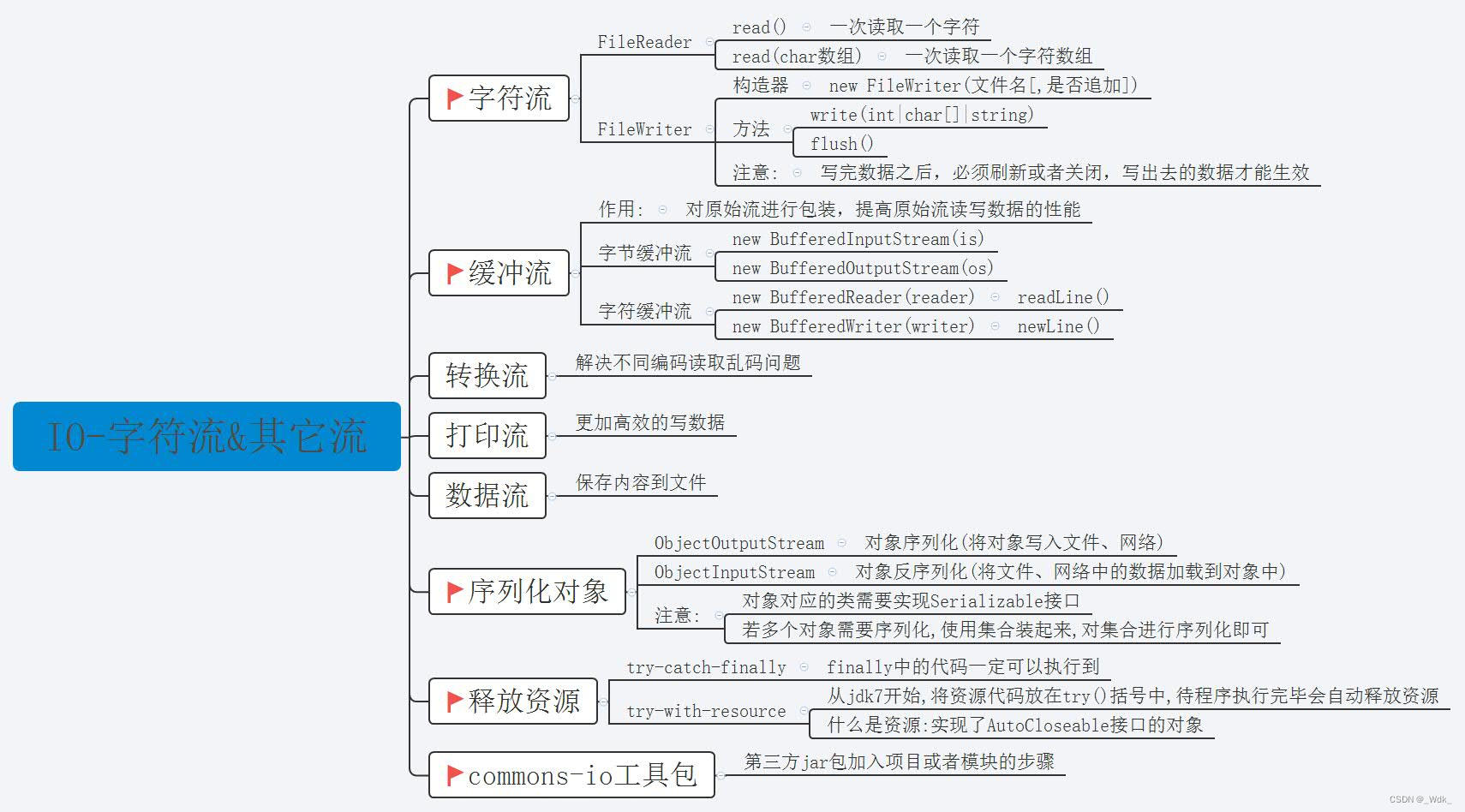















 7386
7386

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









