







题目描述
给定一个非空字符串 s 和一个包含非空单词列表的字典 wordDict,在字符串中增加空格来构建一个句子,使得句子中所有的单词都在词典中。返回所有这些可能的句子。
说明:
分隔时可以重复使用字典中的单词。
你可以假设字典中没有重复的单词。
输入:
s = "catsanddog"
wordDict = ["cat", "cats", "and", "sand", "dog"]
输出:
[
"cats and dog",
"cat sand dog"
]
输入:
s = "pineapplepenapple"
wordDict = ["apple", "pen", "applepen", "pine", "pineapple"]
输出:
[
"pine apple pen apple",
"pineapple pen apple",
"pine applepen apple"
]
解释: 注意你可以重复使用字典中的单词。
前缀树
要解决这个问题,先要了解什么是前缀树,Trie树, 可以用于大量有限范围的数据的存储和查找,比如qq号 ,每个数字的变化范围在0-9, 即树的每一层有10个节点,假设10位的qq号,树的深度也就10层,可以存储 10的10次方个数,远远小于用哈希表存储。
本题都是小写字母组成的单词,每个节点有26个儿子,分别代表该字符是否存在。以 wordDict = [“cat”, “cats”, “and”, “sand”, “dog”] 为例,组成的前缀树:
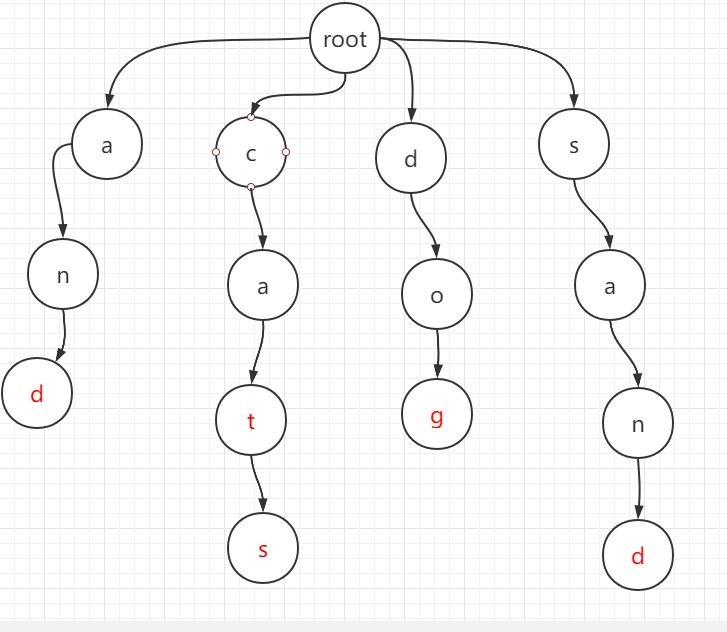
其中红色代表可以作为一个单词的结尾,然后我们dfs 深度搜索这棵前缀树即可。
代码
// 首先定义前缀树节点
class TrieNode{
public:
vector<TrieNode*> son;
bool isEnd; // 是否可以作为结尾
TrieNode():isEnd(0){
son = vector<TrieNode*>(26,0);
}
};
// 定义前缀树
class Trie{
public:
TrieNode* root;
Trie(){
root = new TrieNode();
}
// 向前缀树中添加字符串
void add(string str){
TrieNode* temp = root;
for(int i=0;i<str.size();++i){
if(temp->has[str[i] - 'a'] ==nullptr){
// 没有该字符
temp->has[str[i] - 'a'] = new TrieNode();
}
temp = temp->has[str[i] - 'a'];
if(i==str.size()-1){
temp->isEnd = 1;
}
}
}
};
class Solution {
public:
vector<string> result;
TrieNode* allroot = nullptr;
void dfs(TrieNode* begin, const string& s, int i , string cur){
int index = s[i] - 'a';
cur+=s[i];
if(begin->has[index]!=nullptr){
begin = begin->has[index];
if(i == s.size()-1){
if(begin->isEnd == 1){
result.emplace_back(cur);
return ;
}
}else{
dfs(begin,s,i+1,cur);
if(begin->isEnd == 1){
cur+=' ';
dfs(allroot,s,i+1,cur);
}
}
}
}
vector<string> wordBreak(string s, vector<string>& wordDict) {
Trie* t1 = new Trie();
// 把字典中的所有单词 添加到 前缀树中去
for(const auto& i:wordDict){
t1->add(i);
}
// 进行递归查找吧
string cur = "";
allroot = t1->root;
dfs(t1->root,s,0,cur);
return result;
}
};
提交通过
欢迎各位小伙伴提出改进与批评,谢谢!















 1135
1135











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









