







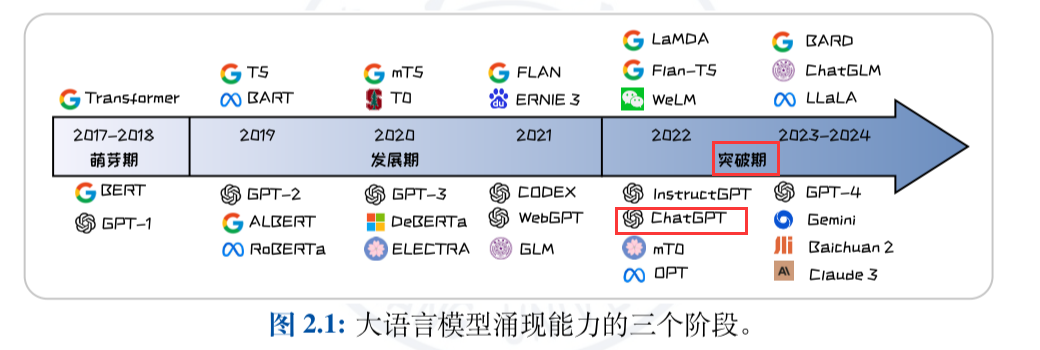
2 大语言模型架构
2.1 大数据 + 大模型 → 新智能
大语言模型的“大”:
- 模型规模的庞大
- 训练数据规模的庞大
- → 模型能力的强大
大数据 + 大模型 → 能力增强
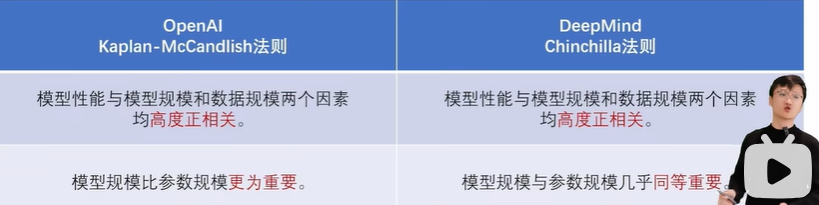
然而模型规模和数据规模的增长并非没有代价,它们带来了更高的计算成本和存储需求,这要求我们在模型设计时必须在资源消耗和性能提升之间找到一个恰当的平衡点。为了应对这一挑战,大语言模型的扩展法则(Scaling Laws)应运而生。
大数据 + 大模型 → 能力扩展
模型训练数据规模以及参数数量的不断提升,不仅带来了上述学习能力的稳步增强,还为大模型“解锁”了一系列新的能力,例如上下文学习能力、常识推理能力、数学运算能力、代码生成能力等。
值得注意的是,这些新能力并非通过在特定下游任务上通过训练获得,而是随着模型复杂度的提升凭空自然涌现。这些能力因此被称为大语言模型的涌现能力(Emergent Abilities)。



2.2 大语言模型架构预览
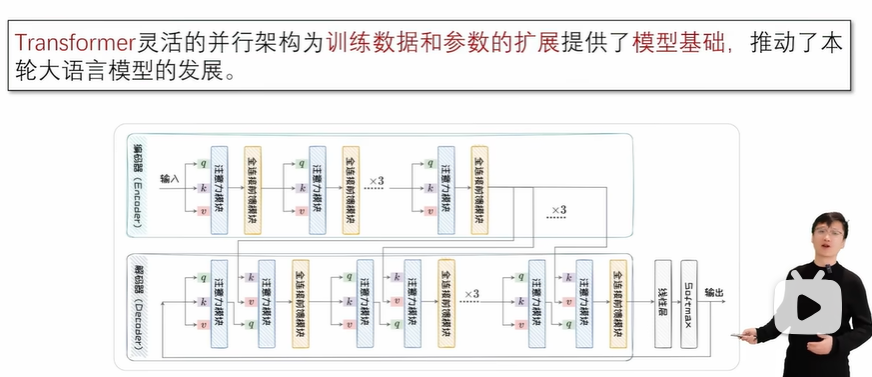

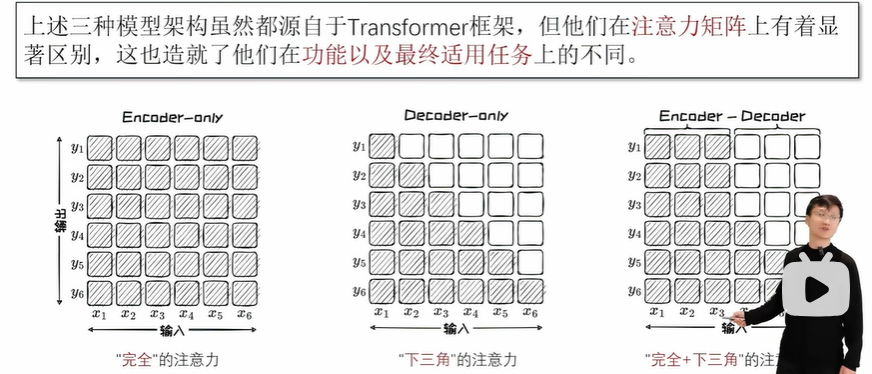

Encoder-only:适用于判别任务,不适用于生成任务。

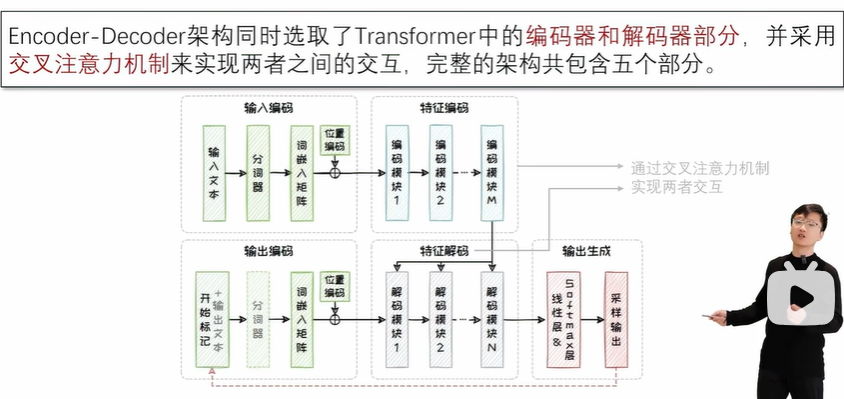
Encoder-Decoder:适用于判别任务和生成任务,但是模型训练和推理成本很大。
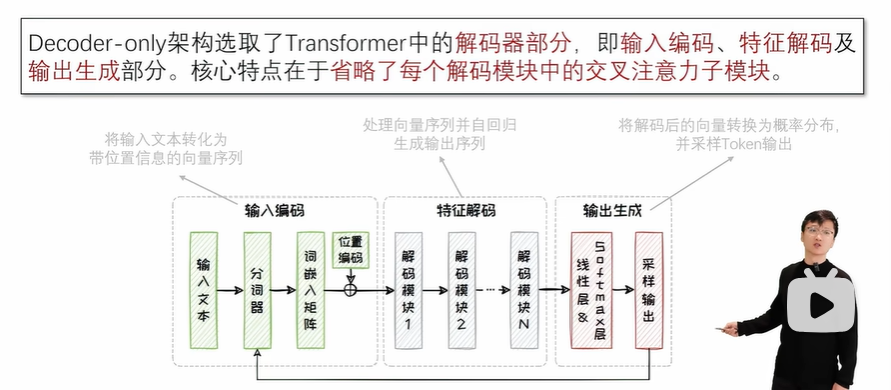
Decoder-only:不太适用于判别任务,适用于生成任务。


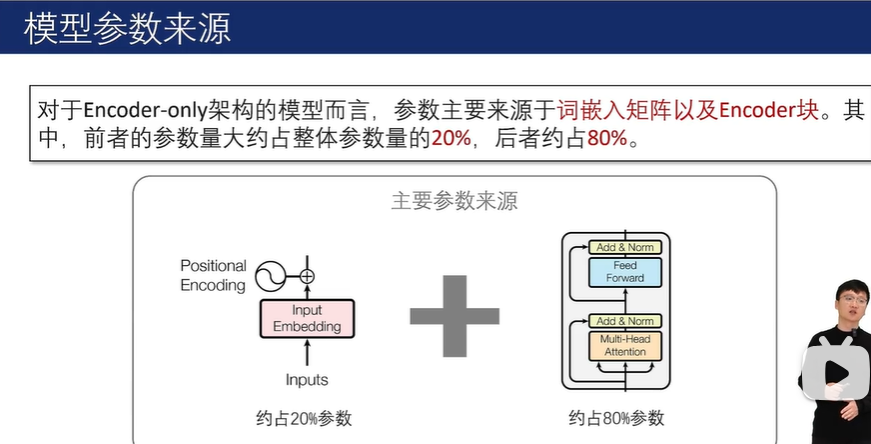
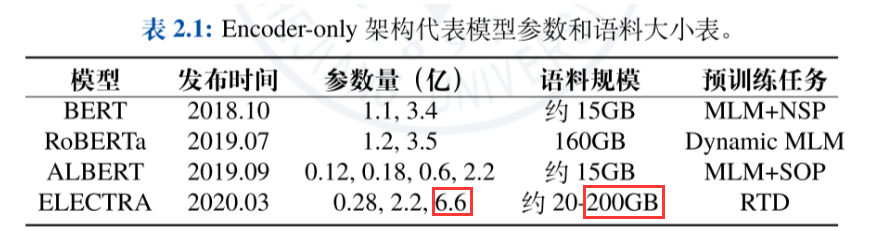
2.3 基于 Encoder-only 架构的大语言模型
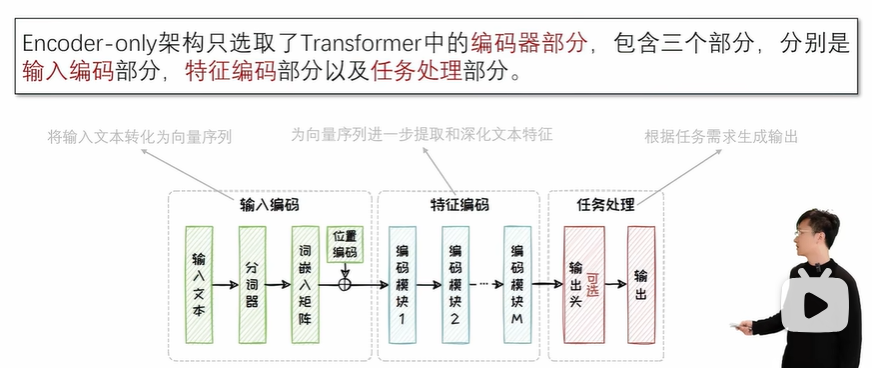
2.3.1 Encoder-only 架构
Encoder-only架构的核心在于能够覆盖输入所有内容的双向编码模型(Bidirectional Encoder Model)。在处理输入序列时,双向编码模型融合了从左往右的正向注意力以及从右往左的反向注意力,能够充分捕捉每个 Token 的上下文信息,因此也被称为具有全面的注意力机制。
但由于没有寻求参数量的突破,且只专注于判别任务,难以应对生成式任务。因此在生成式人工智能中可以发挥的作用相对有限。
2.3.2 BERT语言模型
BERT 语言模型
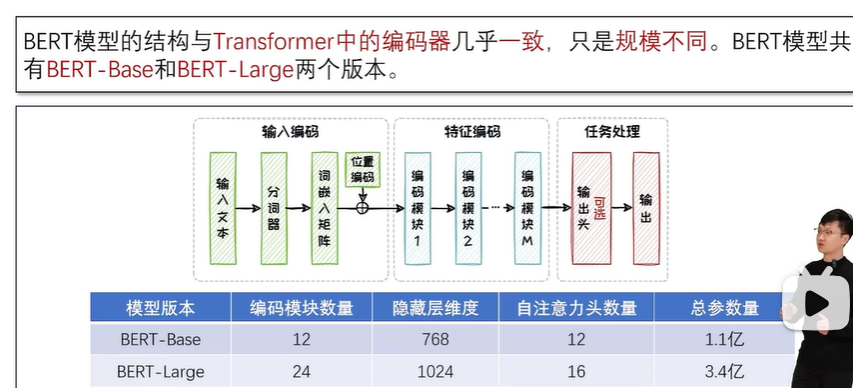


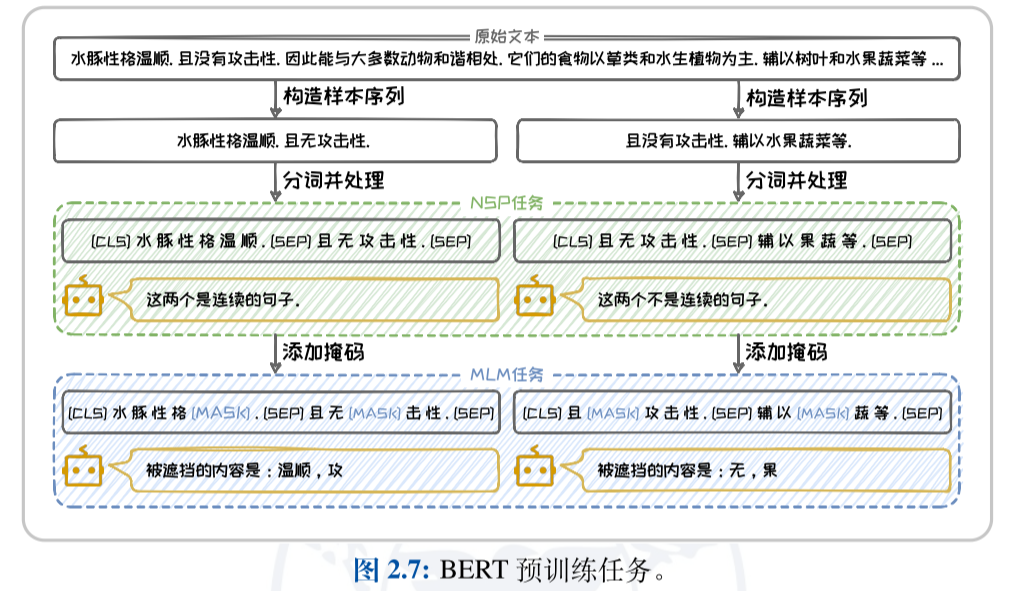
下文预测:利用模型判断样本序列中的两个句子是否为连续的。
掩码语言建模:模型需要预测这些被替换的Token的原始内容(根据前后文完成完型填空)。
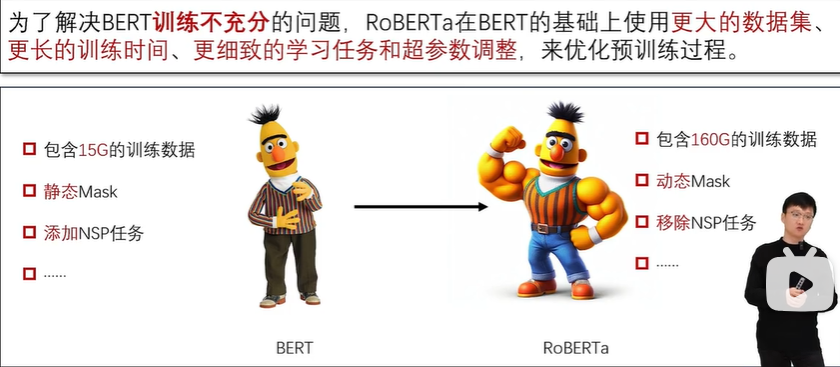
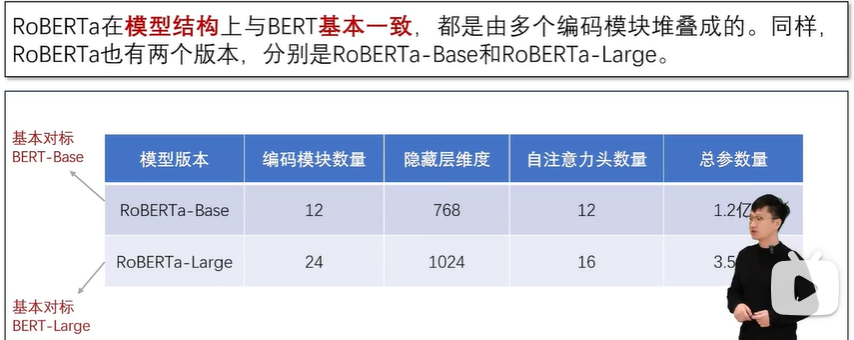
RoBERTa 语言模型



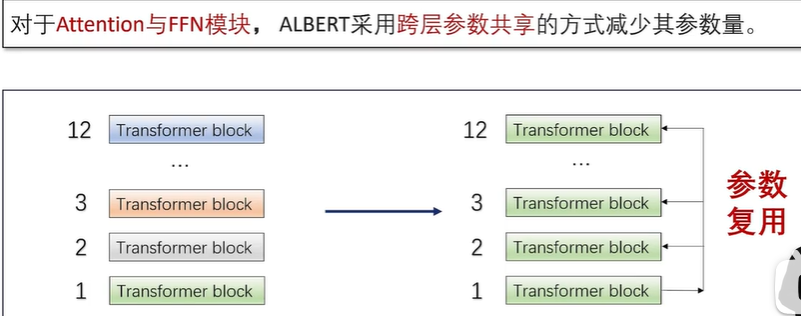
ALBERT 语言模型
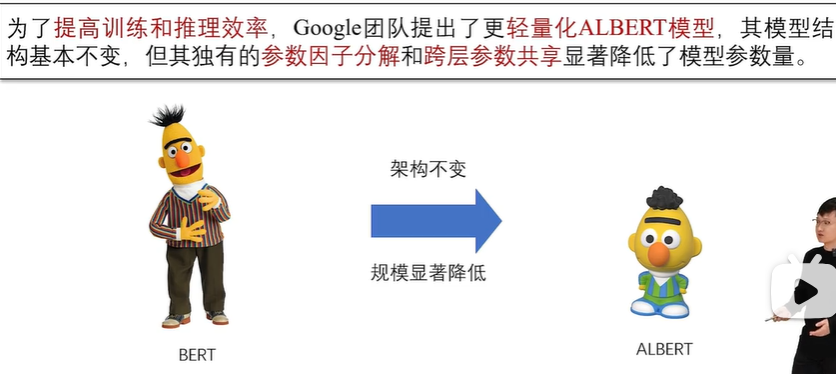
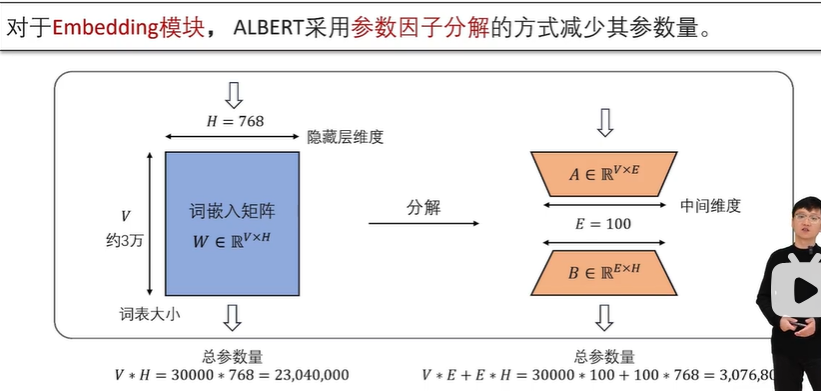
ALBERT 将 Embedding 层的矩阵先进行分解,将词表对应的独热编码向量通过一个低维的投影层下投影至维度 E,再将其上投影回隐藏状态的维度H。


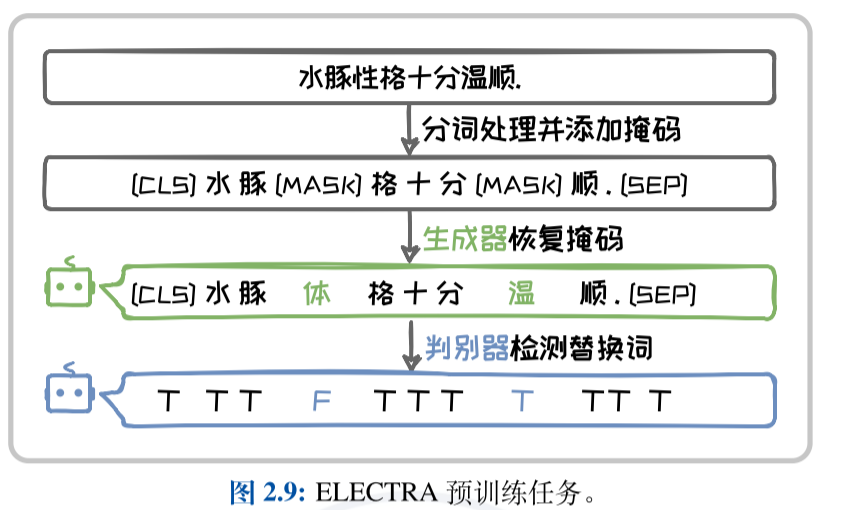
 ELECTRA语言模型
ELECTRA语言模型
通过使用生成器-判别器架构,ELECTRA 能够更高效地利用预训练数据,提高了模型在下游任务中的表现。
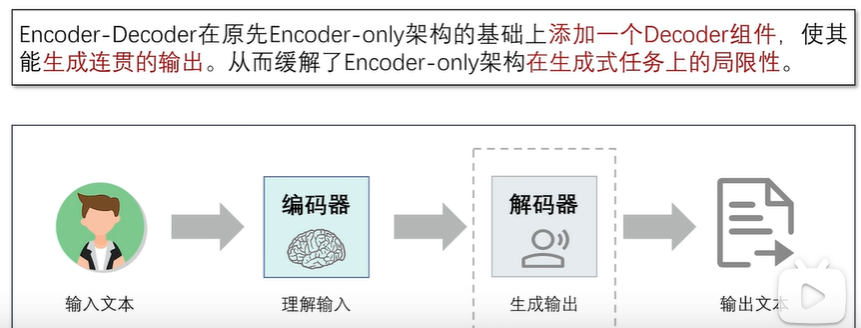
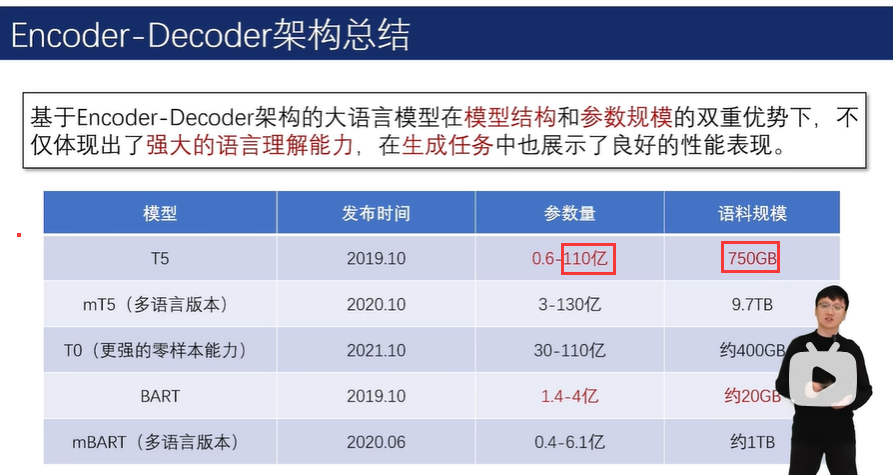
2.4 基于Encoder-Decoder架构的大语言模型
2.4.1 Encoder-Decoder架构

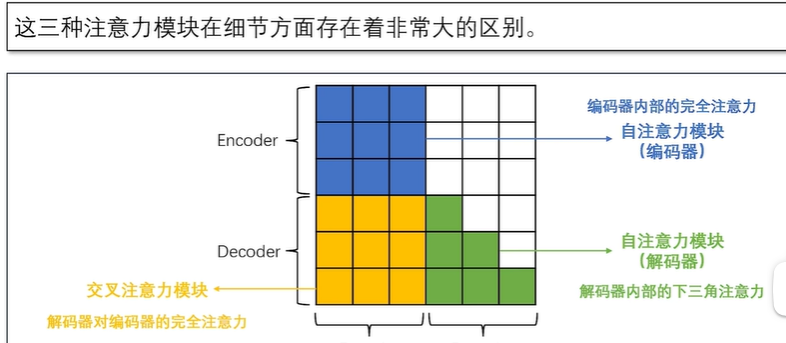
自注意力模块:在编码器中,我们需要对输入序列的上下文进行“通盘考虑”,所以采用双向注意力机制以全面捕捉上下文信息。但在解码器中,自注意力机制则是单向的,仅以上文为条件来解码得到下文,通过掩码操作避免解码器“窥视”未来的信息。
交叉注意力模块:通过将解码器的查询(query)与编码器的键(key)和值(value)相结合,实现了两个模块间的有效信息交流。
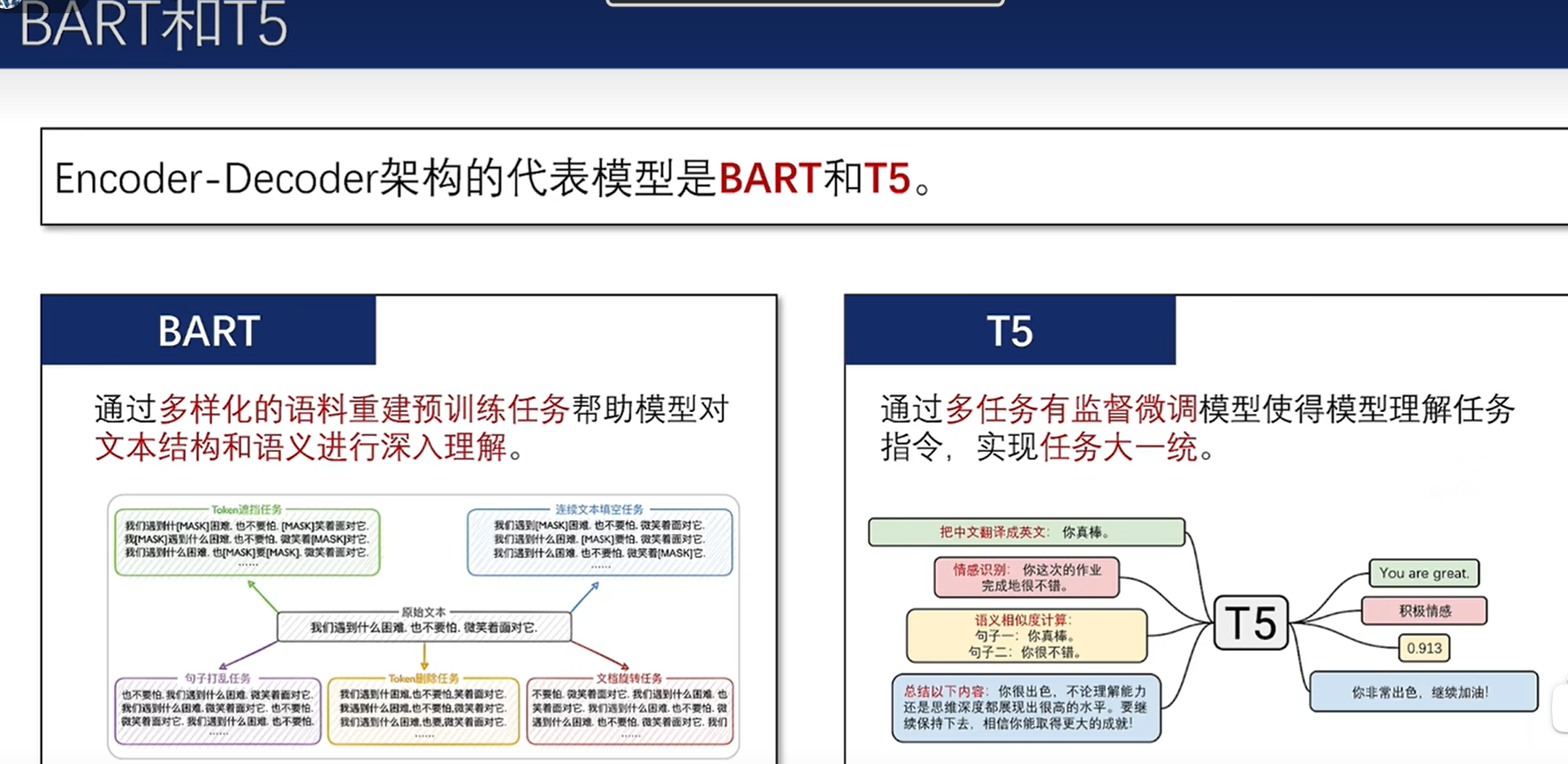
2.4.2 BART语言模型

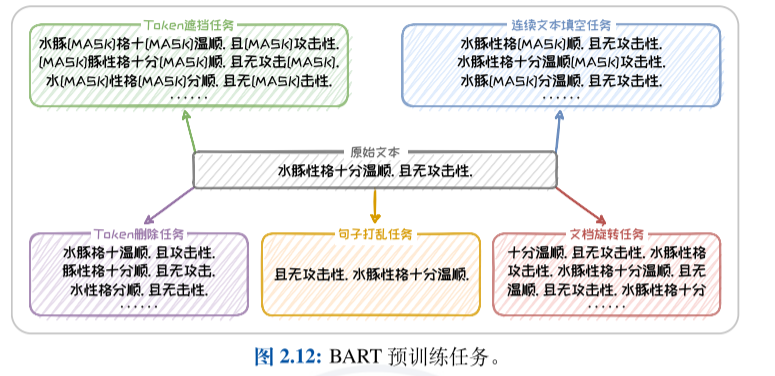
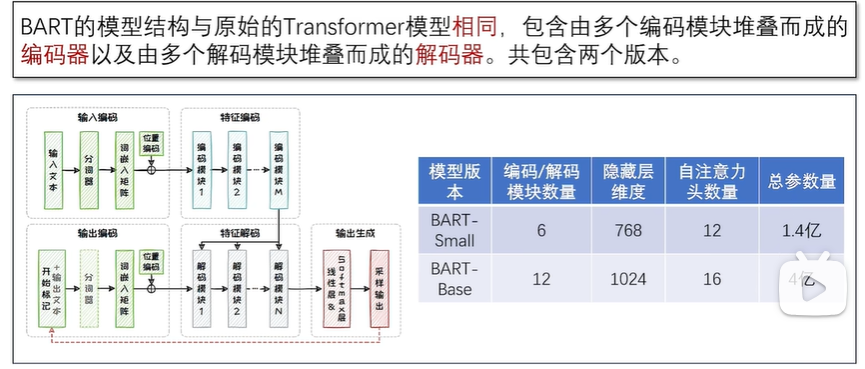
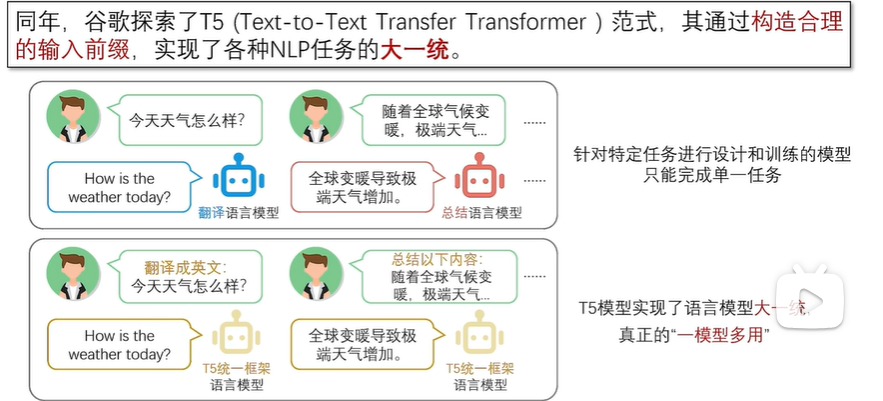
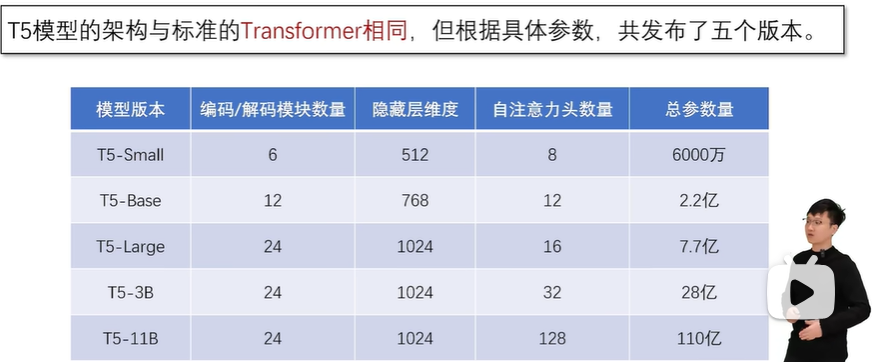
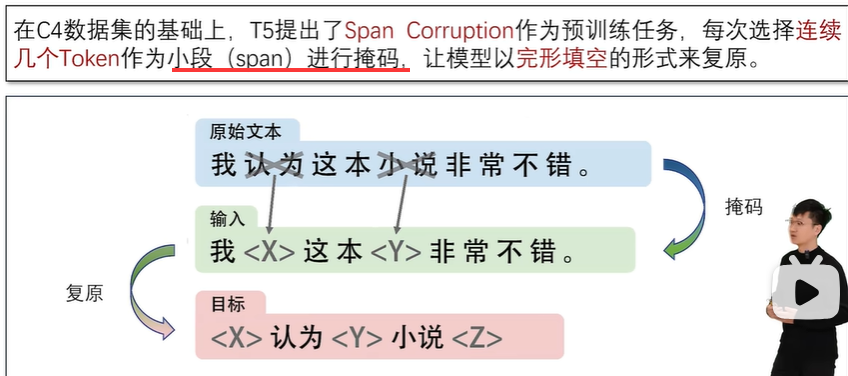
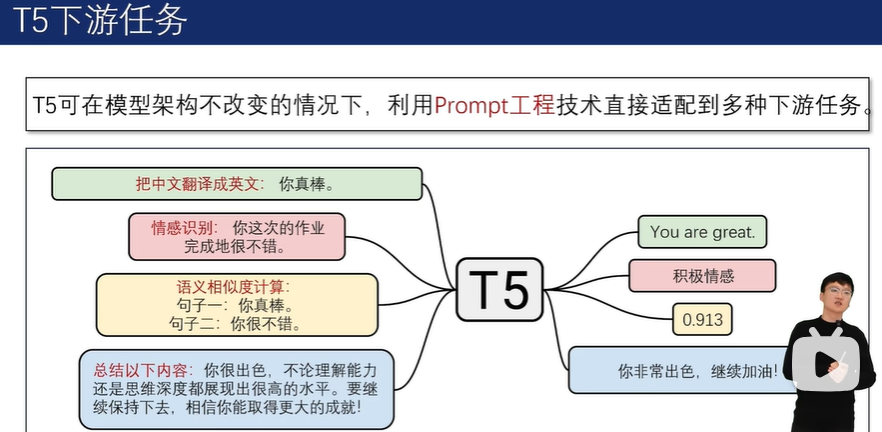
2.4.3 T5语言模型

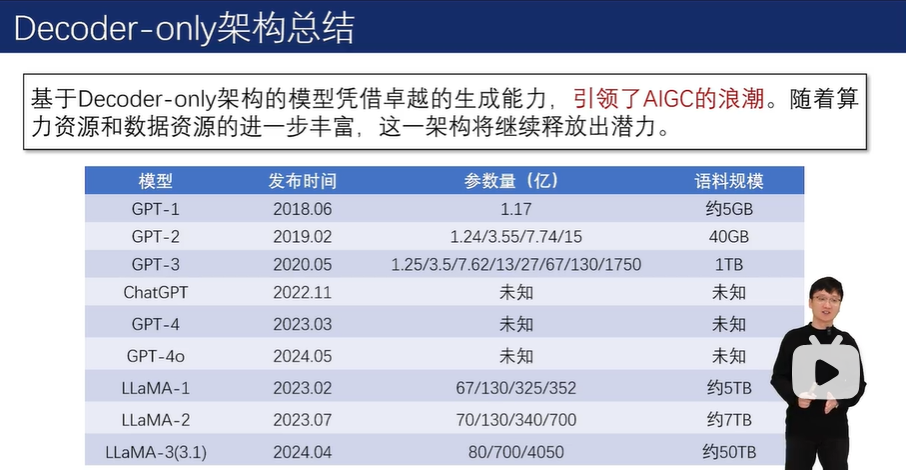
2.5 基于Decoder-only架构的大语言模型
2.5.1 Decoder-only架构


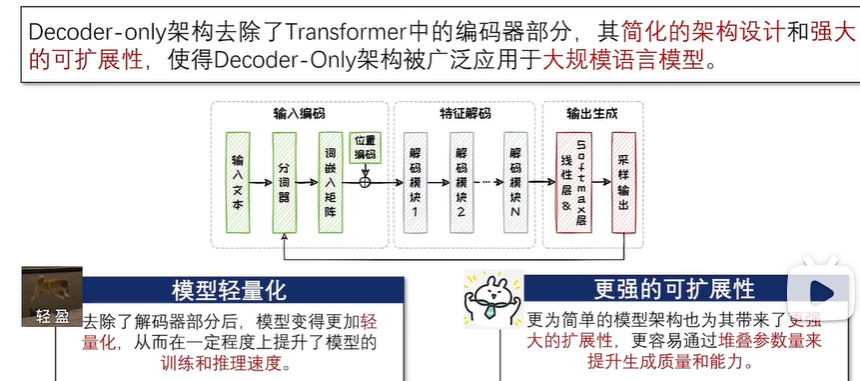

从第三代开始,GPT 系列逐渐走向了闭源。而 LLaMA 系列虽然起步较晚,但凭借着同样出色的性能以及始终坚持的开源道路,也在 Decoder-only 架构领域占据了一席之地。
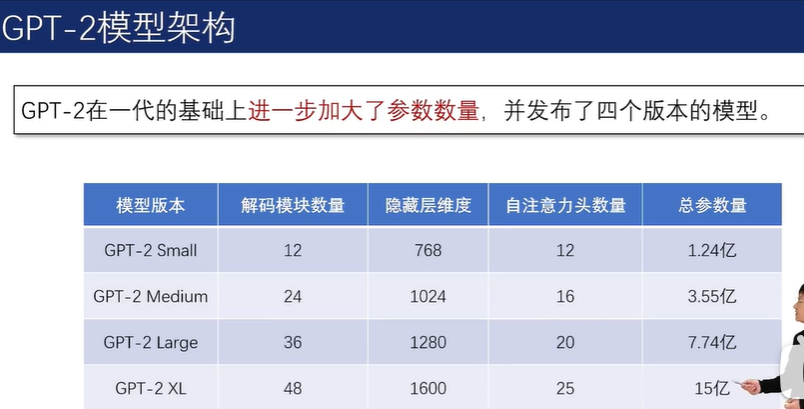
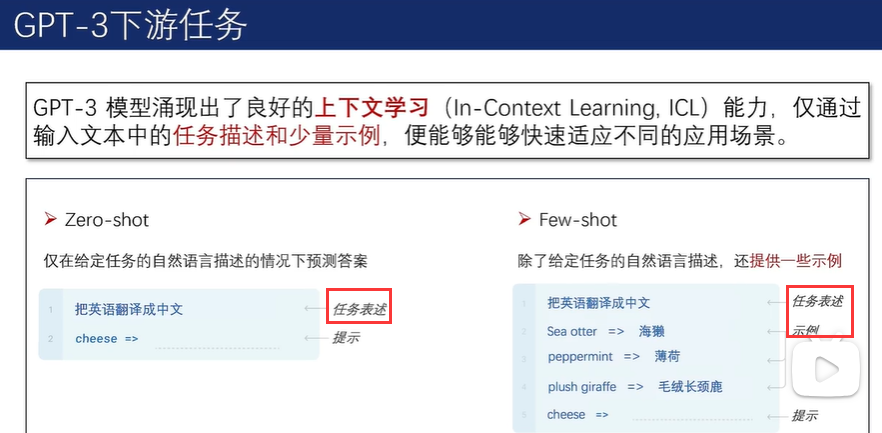
2.5.2 GPT系列模型
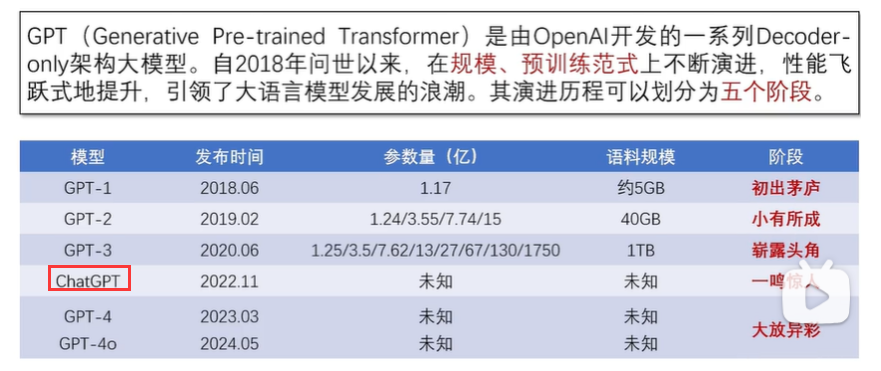
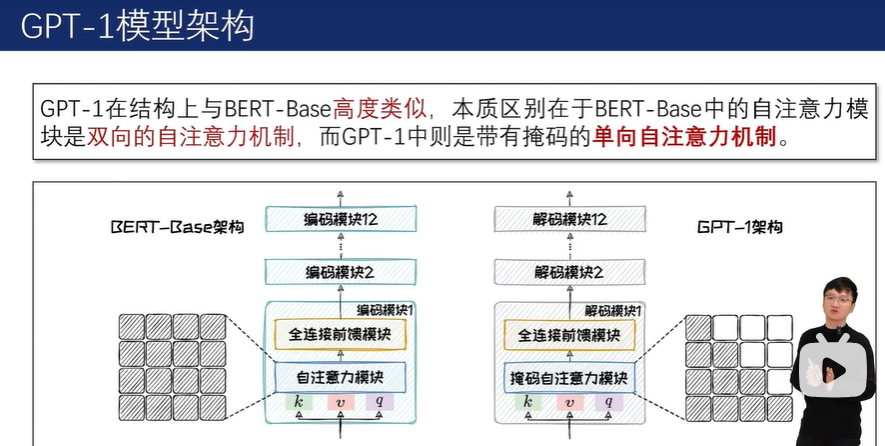
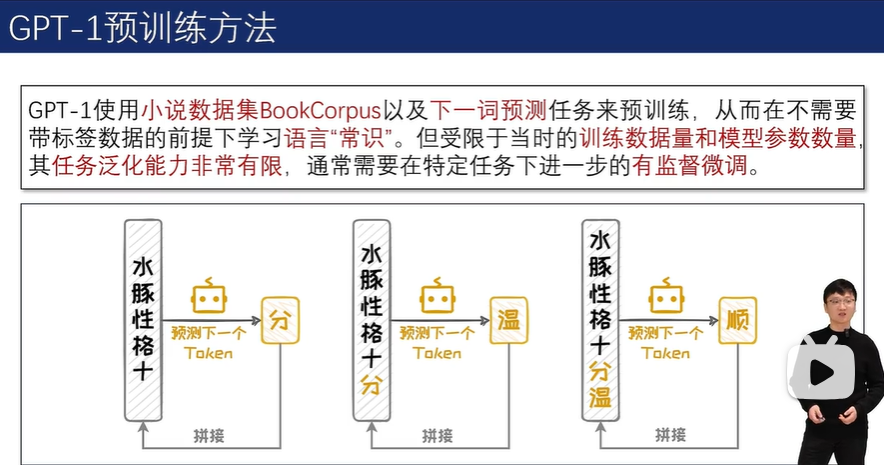
在预训练方法上,GPT-1 采用下一词预测任务,即基于给定的上文预测下一个可能出现的Token。以自回归的方法不断完成下一词预测任务,模型可以有效地完成文本生成任务。
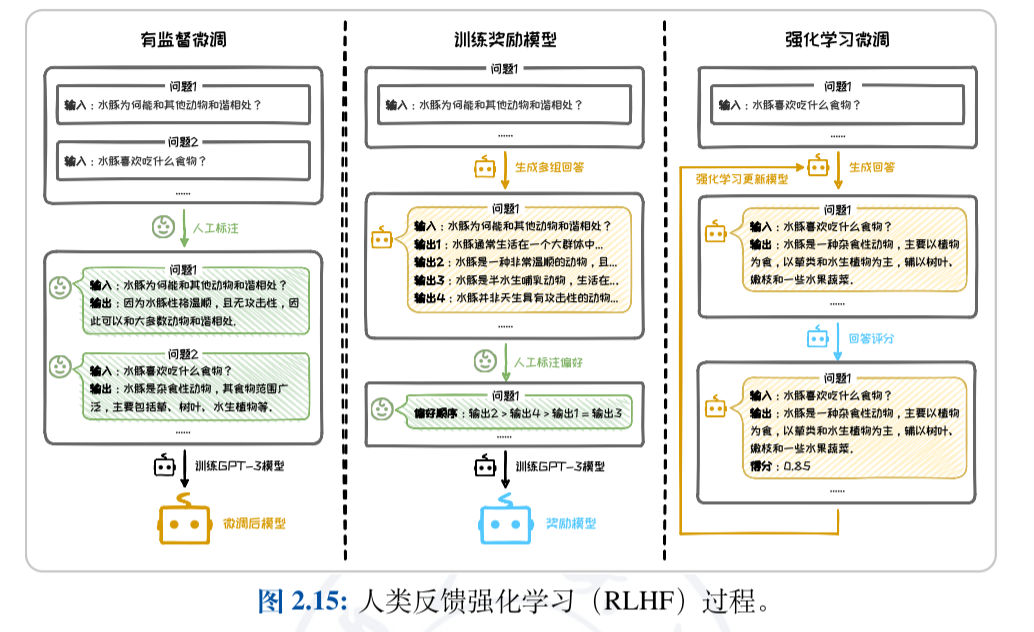
尽管 GPT-1 模型在预训练后展现出了一定的潜力,但其任务泛化能力仍受限于当时的训练数据量和模型参数数量。为了提升模型在特定下游任务上的表现,通常需要进一步的有监督微调。微调过程涉及使用针对特定任务的标注数据来优化模型的参数,其中模型的输入和输出均以文本序列的形式呈现。






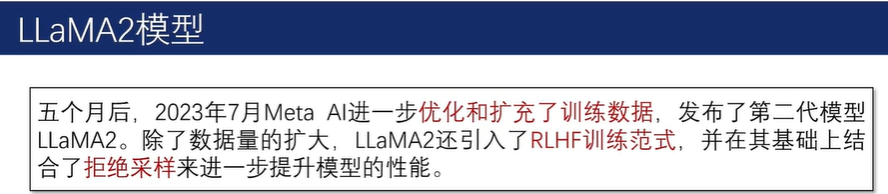
2.5.3 LLaMA系列模型

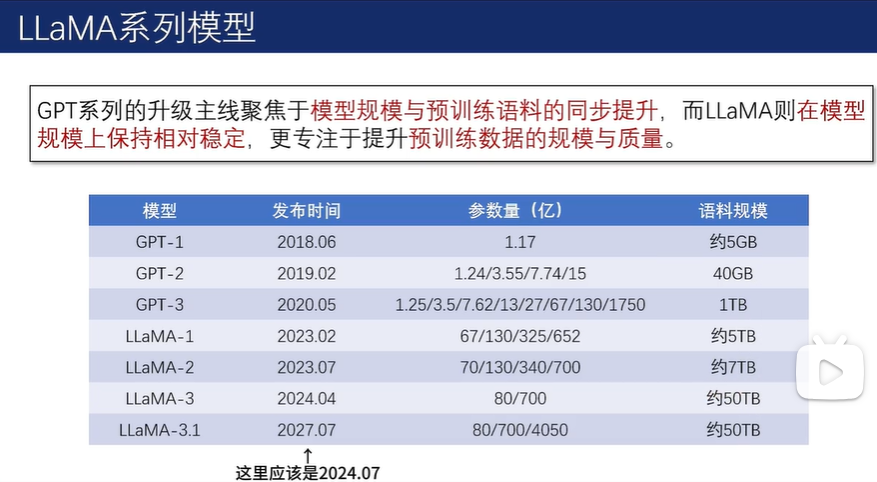

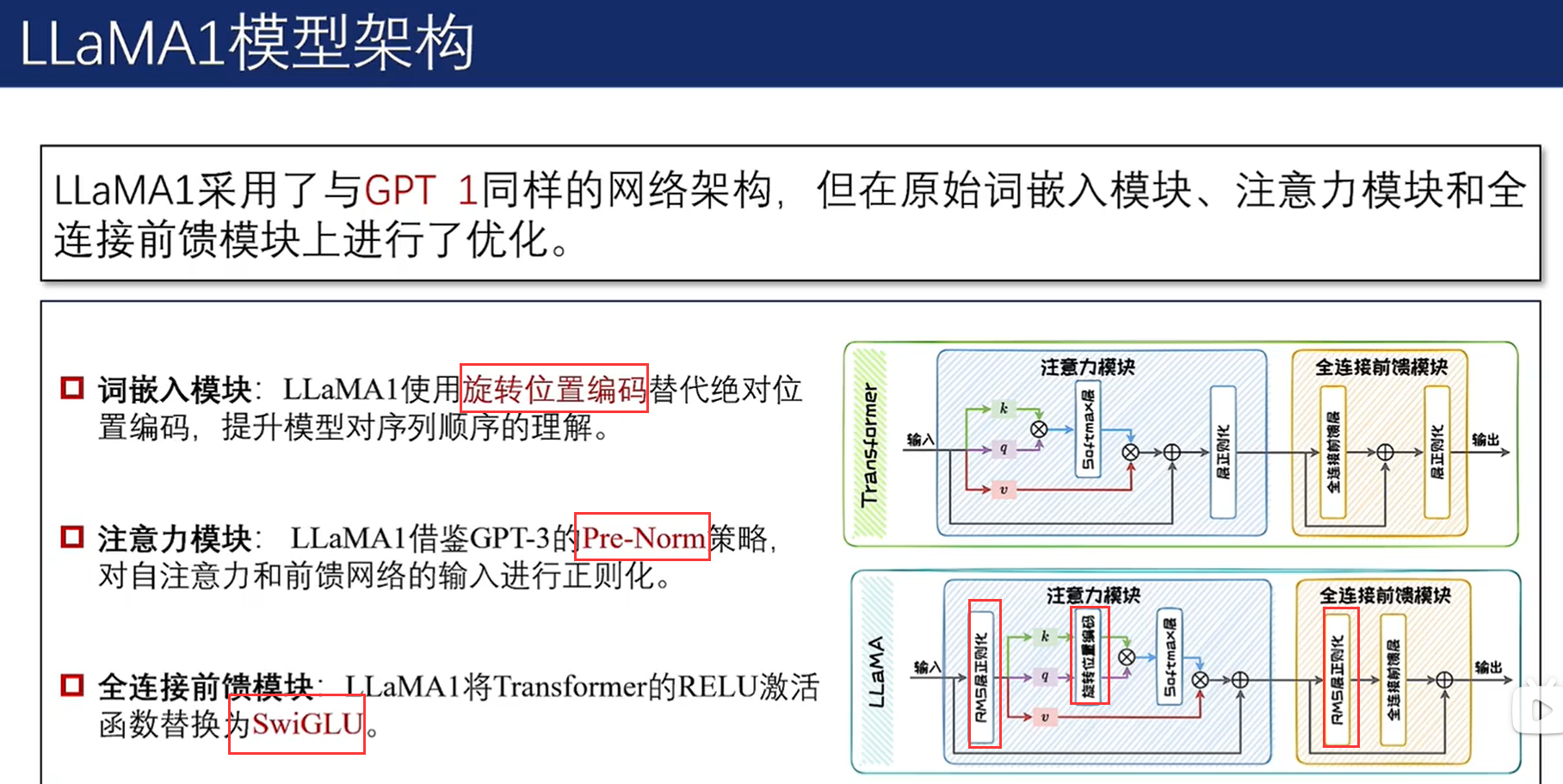
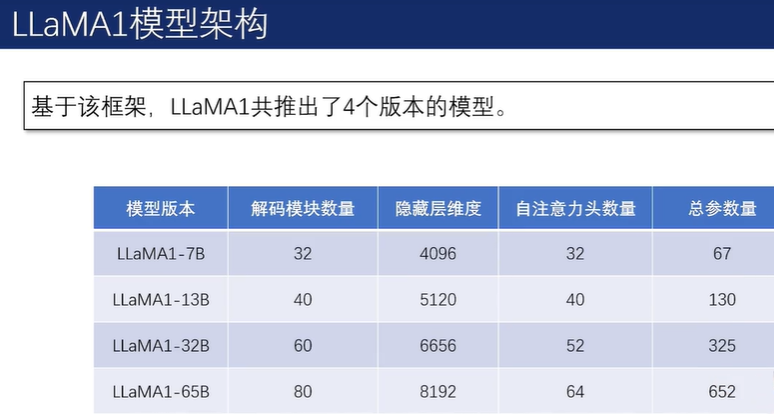
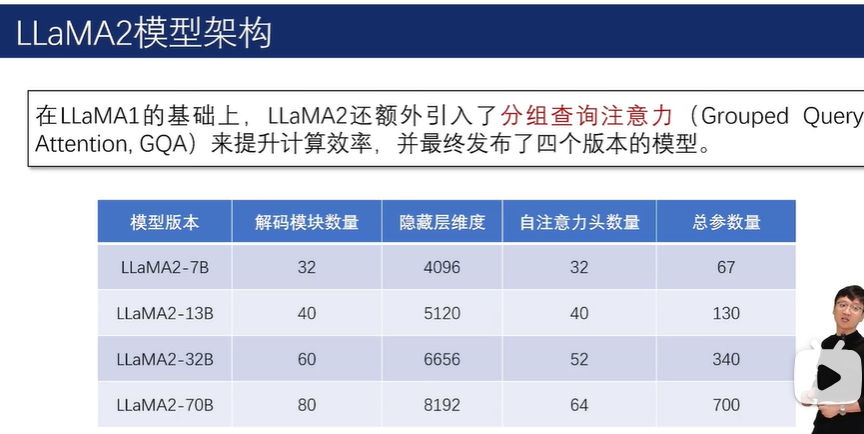
在分组查询注意力机制下,键(key)以及值(value)不再与查询(query)一一对应,而是一组查询共享相同的键和值,从而有效降低内存占用并减少模型总参数量。





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









