







1.背景与目标
在出成绩之前,我们需要时刻关注报考学校的最新通知,以免错过重要信息。然而,手动刷新网页的方式既耗时又费力。为此,我们可以利用Python爬虫技术,实现学校最新通知的实时爬取与推送,确保信息获取的及时性与准确性。
2.推送方式选择
要实现通知的实时推送,我们需要选择一个合适的推送方式。经过对比,我发现虾推啥(虾推啥 - 一行代码推送手机通知)这一公众号推送方式非常适合我们的需求。通过关注公众号并获取个人token,我们可以轻松实现文字通知的实时推送,确保微信能够及时收到重要信息。
3.爬虫执行频率设置
为了避免对目标网站造成过大的访问压力,我们需要合理设置爬虫的执行频率。考虑到信息的时效性和访问的合理性,我建议将爬取速度设置为每小时一次。这样既能保证及时获取最新通知,又能避免对网站造成过大的负担。
4.爬虫部署位置选择
为了实现24小时不间断的自动爬取与推送功能,我们需要选择一个合适的部署位置。考虑到本地设备的限制和实时推送的需求,我建议将爬虫部署在云服务器上。阿里云服务器是一个不错的选择,经过学生认证和测试,我们可以免费使用两个月,轻松搭建起自己的爬虫环境。
5.实施步骤
5.1 注册并获取虾推啥token:首先,关注虾推啥公众号并注册账号,获取个人token,以便后续实现推送功能。

5.2 编写Python爬虫代码:使用Python编写爬虫代码,包括请求学校网站、解析网页内容、提取最新通知等步骤。确保爬虫能够准确获取所需信息。
(1)打开需要解析的网页,找到第一篇文章,右键单击“检查”选项。

(2)开始分析网页内容,可以看到p中有 class="newscontent" ,span中存放的是文章的日期,a中的href存放的是网页链接。

(3)编写爬虫代码:
# 定义要爬取的网页URL
url = "https://zs.gpnu.edu.cn/bkzn/a2023sefdzsb.htm"
# 定义基础URL,用于拼接相对链接以形成完整的URL
bs_url = "https://zs.gpnu.edu.cn/"
# 导入requests库,用于发送HTTP请求
import requests
# 使用requests库的get方法发送GET请求到指定的URL
r = requests.get(url)
# 设置响应内容的编码为utf-8,确保中文内容能够正确显示
r.encoding = "utf-8"
# 检查请求是否成功(HTTP状态码是否为200)
if r.status_code != 200:
# 如果请求不成功,则抛出一个异常
raise Exception()
# 获取响应的文本内容
html_doc = r.text
# 导入BeautifulSoup库,用于解析HTML文档
from bs4 import BeautifulSoup
# 使用BeautifulSoup库解析HTML文档
soup = BeautifulSoup(html_doc, "html.parser")
# 查找所有class为"newscontent"的<p>标签
dev_nodes = soup.find_all("p", class_="newscontent")
# 遍历每一个找到的<p>标签
for dev_node in dev_nodes:
# 在当前<p>标签中查找<a>标签,通常<a>标签包含链接
link = dev_node.find("a")
# 在当前<p>标签中查找<span>标签,通常用于存放日期信息
date = dev_node.find("span")
# 打印拼接后的完整链接(使用基础URL加上相对链接,并去掉链接开头的三个字符,为了去掉某些特殊字符或路径),链接的文本以及日期信息
print(bs_url + link["href"][3:], link.get_text(), date.get_text())(4)尝试在pycharm中运行代码,输出为以下内容。将网页中所有文章的网址、标题、日期全部输出出来了。

5.3 实现推送功能:在爬虫代码中集成推送功能,将获取到的最新通知通过公众号推送给用户。
(1)使用datetime模块获取当日信息,并将其格式化为带方括号的字符串形式,比较今日日期与网页上的日期是否一致,如果日期匹配则是成绩出了。无论日期是否匹配,代码都会发送一个默认的GET请求到另一个URL,通知用户成绩还未出。
from datetime import datetime
# 获取当前系统日期和时间
now = datetime.now()
# 将当前日期格式化为 "yyyy-mm-dd" 的格式,并在前后加上方括号
formatted_date = f"[{now.strftime('%Y-%m-%d')}]"
# 假设 date.get_text() 是一个函数,它返回一个与 formatted_date 格式相同的日期字符串
# 比较格式化后的当前日期与网页中的日期是否一致
if formatted_date == date.get_text():
# 如果日期一致,则打印出链接的完整URL、链接文本和日期信息
print(bs_url + link["href"][3:], link.get_text(), date.get_text())
# 准备发送 POST 请求的数据,通知有新公告
mydata = {
'text': '有新公告!有可能是成绩出了', # 通知的标题
'desp': '内容:' + link.get_text() + '<br>' \ # 通知的描述,包含公告内容
'网址:' + bs_url + link["href"][3:] + '<br>' \ # 公告的链接
'日期:' + date.get_text() # 公告的日期
}
# 发送 POST 请求到指定的 URL,通知服务有新公告
requests.post('https://wx.xtuis.cn/你的token.send', data=mydata)
# 无论日期是否匹配,都发送一个 GET 请求通知用户成绩还未出(可不写,当成绩出了才发送)
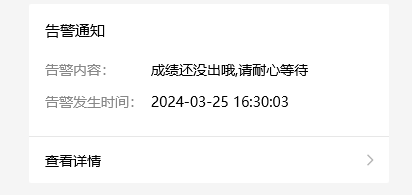
requests.get('https://wx.xtuis.cn/你的token.send?text=成绩还没出哦,请耐心等待&desp=成绩未出')5.4 部署爬虫到云服务器:将编写好的爬虫代码部署到阿里云服务器上,确保服务器能够24小时运行。
(1)打开阿里云服务器(阿里云-计算,为了无法计算的价值)

(2)学生可以领取免费的服务器使用,这里我以轻量服务器为例,查找轻量服务器

(3)选择轻量服务器

(4)设置服务器配置

(5)转到服务台查看服务器ip地址。

(6)使用远程连接工具连接

(7)登录到你的云服务器后,执行宝塔面板安装命令,阿里云服务器网使用的CentOS操作系统,命令如下:
su
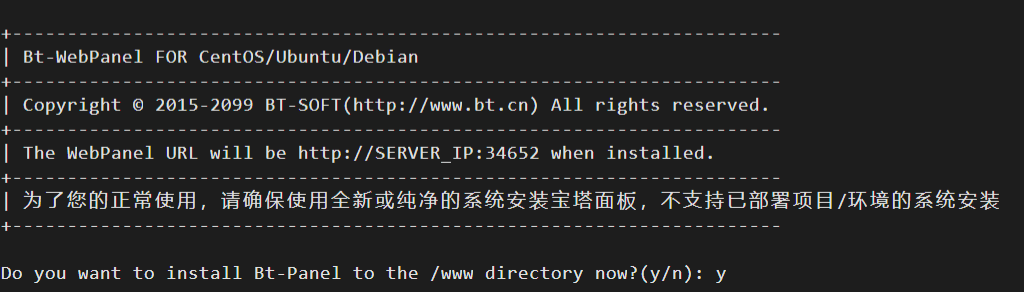
yum install -y wget && wget -O install.sh https://download.bt.cn/install/install_6.0.sh && sh install.sh ed8484bec执行宝塔Linux面板安装命令后,会提示如下:
Do you want to install Bt-Panel to the /www directory now?(y/n): y保持默认,回复个字母“y”,如下图:
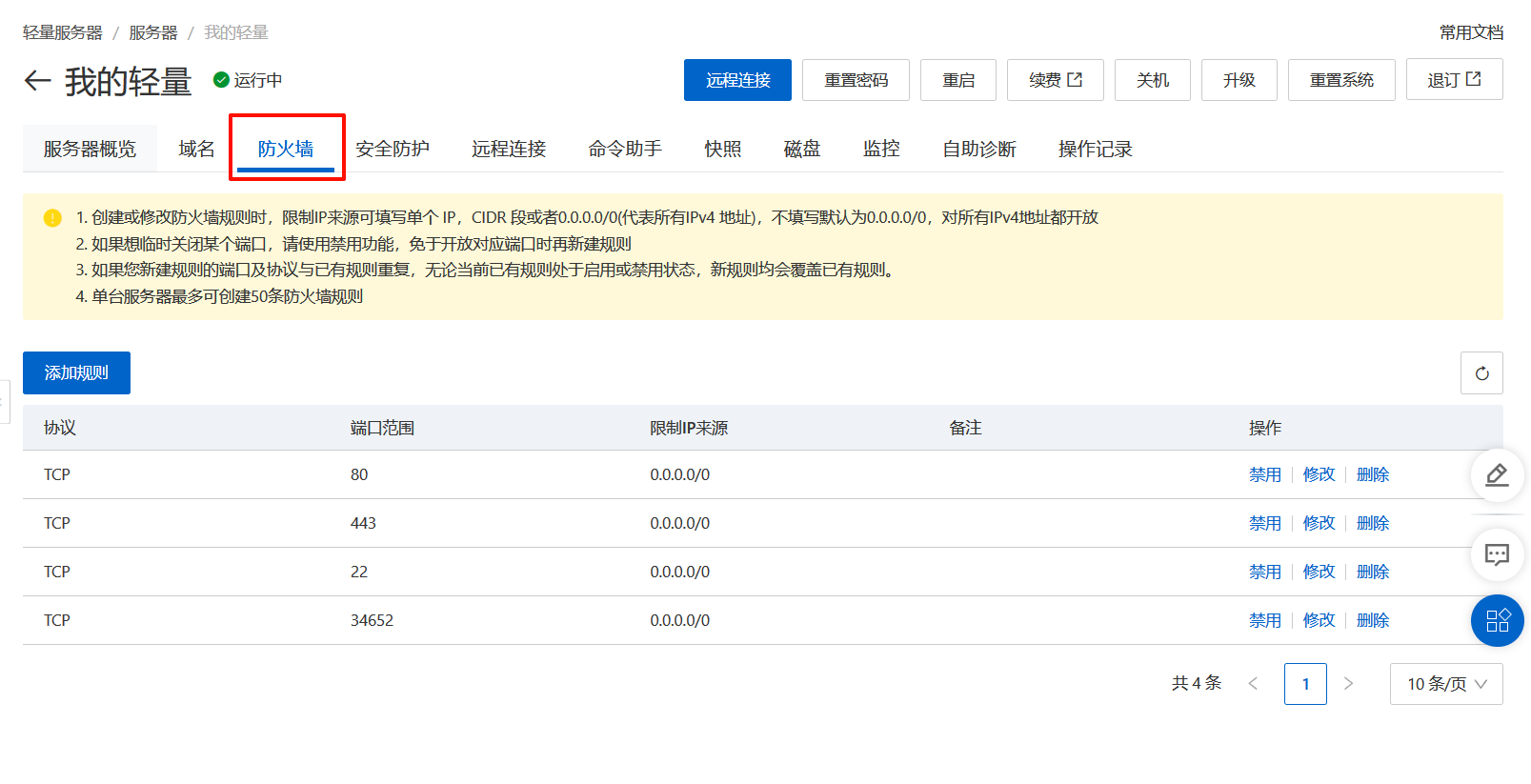
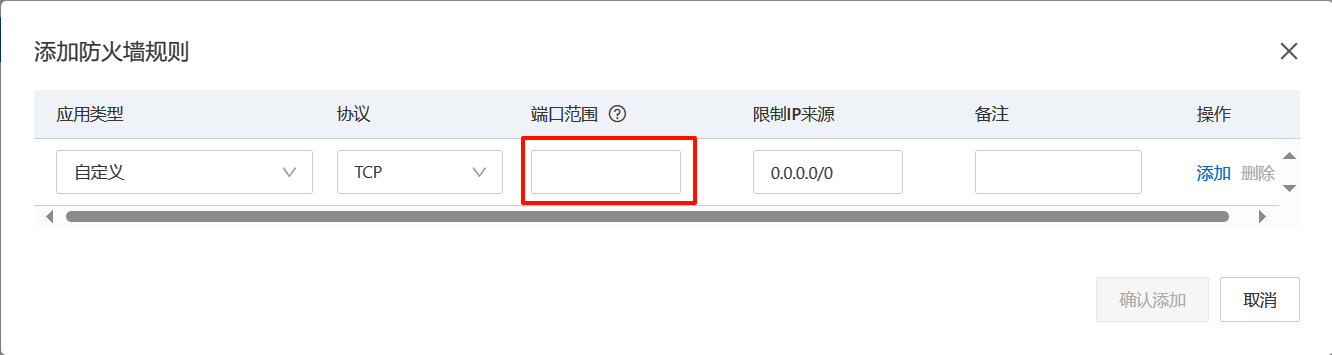
(8)安装好后会有提示IP地址、用户名、密码和端口号。在阿里云中开放端口号。
(9)输入外网面板地址,使用账号密码登录。网页提示安装LNMP,确认并安装好LNMP组件。
(10)安装所需要的BeautifulSoup库,并在命令行中编辑好Python代码。
pip3 install beautifulsoup4vim /root/main.py
url = "https://zs.gpnu.edu.cn/bkzn/a2023sefdzsb.htm"
bs_url= "https://zs.gpnu.edu.cn/"
import requests
r = requests.get(url)
r.encoding = "utf-8"
if r.status_code != 200:
raise Exception()
html_doc = r.text
from bs4 import BeautifulSoup
soup =BeautifulSoup(html_doc, "html.parser")
dev_nodes= soup.find_all("p",class_="newscontent")
for dev_node in dev_nodes:
link = dev_node.find("a")
date=dev_node.find("span")
from datetime import datetime
now = datetime.now()
formatted_date = f"[{now.strftime('%Y-%m-%d')}]"
if formatted_date == date.get_text():
print(bs_url + link["href"][3:], link.get_text(), date.get_text())
mydata = {
'text': '有新公告!有可能是成绩出了',
'desp': '内容:' + link.get_text() + '<br>' \
'网址:' + bs_url + link["href"][3:] + '<br>' \
'日期:' + date.get_text()
}
requests.post('https://wx.xtuis.cn/你的token.send', data=mydata)
requests.get('https://wx.xtuis.cn/你的token.send?text=成绩还没出哦,请耐心等待&desp=成绩未出')5.5 设置爬虫执行频率:在Linux中设置合理的执行频率,如每小时执行一次。
crontab -e
0 * * * * python3 /root/main.py这样便完成了一个完整的自动抓取并推送学校最新通知的实践流程。


















 914
914

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









