









1. 基本元素定位一
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# selenium = Service("../../chromedriver.exe")
# driver = webdriver.Chrome(service=Service)
# driver.get("http://www.baidu.com")
# # 使用id进行定位
# input_element = driver.find_element_by_id("kw")
# # 往输入框输入内容
# input_element.send_keys("凯学长")
# search_button = driver.find_element_by_id("su")
# # 点击搜索按钮
# search_button.click()
# 隐藏正在受到自动化测试软件的控制这句话
chrome_options = webdriver.ChromeOptions()
chrome_options.add_experimental_option('excludeSwitches',
['enable-automation'])
selenium = Service("../../chromedriver.exe")
driver = webdriver.Chrome(service=Service,options=chrome_options)
driver.get("http://www.baidu.com")
# 以下是新的写法
input_element = driver.find_element(by=By.ID,value="kw")
input_element.send_keys("凯学长")
search_button = driver.find_element(by=By.ID,value="su")
# 点击搜索按钮
search_button.click()
2. 基本元素定位二
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# selenium = Service("../../chromedriver.exe")
# driver = webdriver.Chrome(service=Service)
# driver.get("http://www.baidu.com")
# 使用id进行定位
# input_element = driver.find_element_by_id("kw")
# 往输入框输入内容
# input_element.send_keys("凯学长")
# search_button = driver.find_element_by_id("su")
# 点击搜索按钮
# search_button.click()
# 隐藏正在受到自动化测试软件的控制这句话
chrome_options = webdriver.ChromeOptions()
chrome_options.add_experimental_option('excludeSwitches',
['enable-automation'])
selenium = Service("../../chromedriver.exe")
driver = webdriver.Chrome(service=Service,options=chrome_options)
driver.get("http://www.baidu.com")
# 以下是新的写法
# input_element = driver.find_element(by=By.ID,value="kw")
# input_element.send_keys("凯学长")
# search_button = driver.find_element(by=By.ID,value="su")
# # 点击搜索按钮
# search_button.click()
# 把浏览器最大化
driver.maximize_window()
driver.get("https://www.jd.com")
# jd_search_input = driver.find_element(by=By.CLASS_NAME,value="text")
# jd_search_input.send_keys("电脑")
# jd_search_button = driver.find_element(by=By.CLASS_NAME,value="button")
# jd_search_button.click()
driver.find_element(by=By.LINK_TEXT,value="家用电器").click()
# driver.find_element(by=By.LINK_TEXT,value="平板电视").click()
# 当页面以一个新的页面打开时,将会出现多个句柄(就是浏览器的页面)
# 这个时候我们需要做的事情是切换操作句柄
# 句柄切换
# 拿到所有句柄
handlers = driver.window_handles
print(driver.title)
for h in handlers:
if h !=driver.current_window_handle:
# 切换到这个句柄上
driver.switch_to.window(h)
print("当前句柄是:" + driver.title)
driver.find_element(by=By.PARTIAL_LINK_TEXT,value="一体").click()
3. CSS选择器定位法一
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
service = Service("../../chomedriver.exe")
driver = webdriver.Chrome(service=service)
# 把浏览器最大化
driver.maximize_window()
driver.get("https://www.jd.com")
driver.find_element(by=By.CSS_SELECTOR,value="#key").send_keys("键盘")
driver.find_element(by=By.CSS_SELECTOR,
value="#search > div > div.from > button").click()
# css学习参考手册
# https://www.runoob.com/cssref/css-reference.html#animation
4. CSS选择器定位法二
- 浏览器完整的打开-关闭调用流程
from selenium import webdriver #导入webdriver包
driver=webdriver.Chrome() #初始化一个谷歌浏览器实例
driver.maximize_window() #最大化浏览器
driver.implicitly_wait(8) #设置隐式时间等待
driver.get("https://www.baidu.com") #通过get方法打开一个url站点
driver.quit() #关闭并退出浏览器
5. xpath定位法
1、相对路径定位
//标签名[@属性名="属性值"]
2、定位某个元素的父级元素
元素xpath/parent::"父级元素标签名"
//*[@id="list"]/dl/a/parent::dl
3、定位一组元素的第几个
xpath[数字] 注意:xpath是从1开始
例:定位第5个元素
//*[@id="list"]/dl/a[5]
4、定位到一组元素,但是需要从第n个开始
xpath[position()]
例:从第13个元素开始
//*[@id="list"]/dl/a[position()>12]
5、定位元素的属性值
xpath/@属性名
例:定位a标签的href属性值
//*[@id="list"]/dl/a/@href
6、定位标签的文本内容
xpath/text()
例:定位dd标签的文本内容
//*[@id="list"]/dl/a/dd/text()
6. 句柄切换和页面关闭操作
句柄,就是当前浏览器每个窗口的标识符,每个窗口的句柄具有唯一性,多用于页面切换与关闭指定页面;
接下来先做一个小实验,证明一下为啥需要用到句柄:
以百度新闻为例:


# -*- coding:utf-8 -*-
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.set_window_size(1920, 1080)
browser.get("http://news.baidu.com/") #打开百度新闻页面
time.sleep(1)
handles = browser.window_handles #获取所有窗口的句柄
print("当前窗口的句柄",handles ) #这里输出所有窗口的句柄,当前只有一个窗口,所以输出的是当前窗口的句柄
browser.find_element_by_link_text("百度新闻客户端").click() #在百度新闻页面基础上(新窗口)打开百度新闻客户端页面
handles = browser.window_handles #获取所有窗口的句柄
print("全部窗口的句柄",handles ) #这里会输出两个句柄信息,以list的方式返回

到这里,我们怎么知道当前标记的是哪个窗口的句柄呢(就是读取哪个窗口的代码)?我们可以关闭一个窗口,如果某个窗口被关闭了,那就证明标记的是哪个窗口的句柄,在后面增加下面这行代码
browser.close() #关闭当前标识的窗口
handles = browser.window_handles #获取所有窗口的句柄
print("全部窗口的句柄",handles )

我们会发现就算打开了新的窗口,并在页面上跳转到新的窗口,但是关闭的窗口仍然是最初始的窗口,所以这就证明由始至终都是标识第一个窗口的句柄,那我们就要在进行后面一系列操作之前,先标识到新窗口的句柄
这样子,我们就可以在新窗口进行一系列的操作啦,当然,切换窗口,也可以使用重定向的方式
7. 自动化元素定位防踩坑
踩坑一:StaleElementReferenceException
selenium.common.exceptions.StaleElementReferenceException: Message: stale element reference: element is not attached to the page document
异常原因: 意思是,引用的元素已过期。原因是页面刷新了,此时当然找不到之前页面的元素,就算是后退回来的页面也是不一样的。
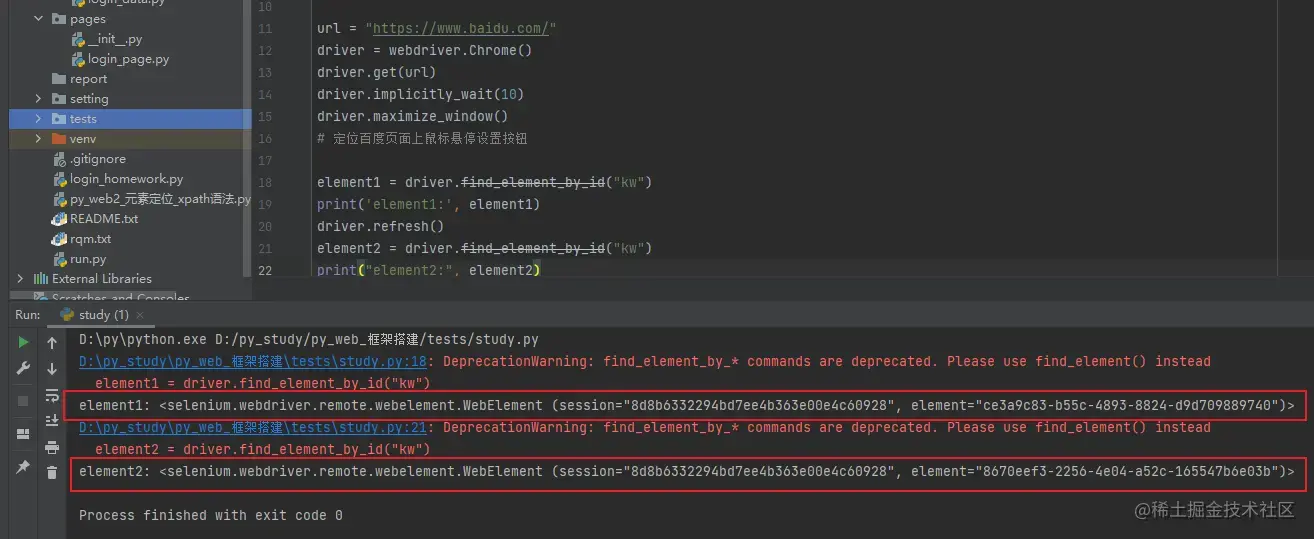
在编写脚本时一直报这个错,使用显示等待都不行,在一顿百度操作后才知道是元素被刷新了

我们发现,仅仅是刷新了一下页面,两次的element id是不同的,这就说明这是两个不同的元素,如果用之前的element,自然会报错
原因很明显,你用别人的身份证id去找现在的人,哪怕这两个人长的很像,他也会告诉你,对不起,你找错人啦。
解决方法:
有时我们无法避免,不确定什么时候元素就会被刷新。页面刷新后重新获取元素的思路不变,这时可以使用python的异常处理语句:try…except…,异常出现时重新执行,关键代码如下
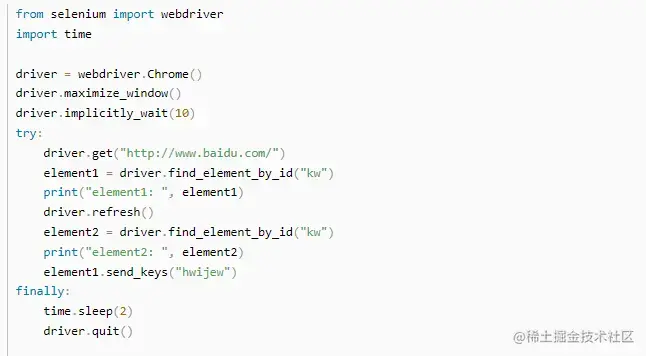
如下图:我在实际工作当中编写脚本时使用异常try捕获异常后,页面刷新后重新获取元素,可以成功找到元素了
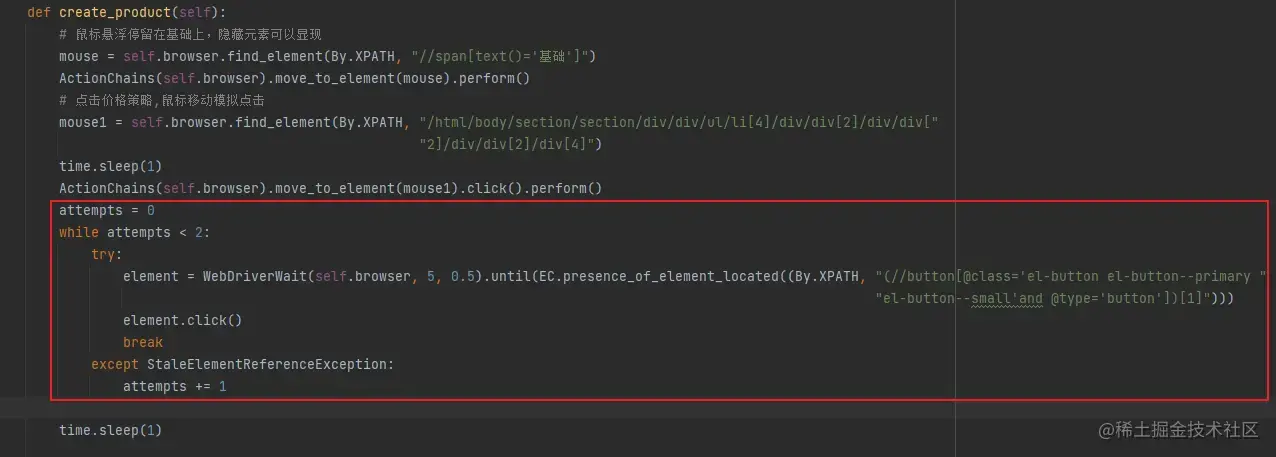
踩坑二:ElementClickInterceptedException(元素点击交互异常)
具体报错:selenium.common.exceptions.ElementClickInterceptedException: Message: element click intercepted is not clickable at point (1421, 283). Other element would receive the click:
E (Session info: chrome=104.0.5112.102)
意思是,元素定位相互覆盖,元素已经找到,但是无法点击
解决方法:
方法一:使用强制等待,但是每次都有类似的元素无法点击使用强制等待的话会延长脚本执行时间
time.sleep()
前言:之前便遇到过很多次该问题的报错,就没有管它,但是随着越来越多的元素报该错,每次使用强制等待会大大延长脚本的执行时间,于是便网上找各种方法解决该问题,最终发现是自己使用显示等待的方法错了
如下是显示等待的用法和区别
方法二:显性等待
element_to_be_clickable--元素是否可点击
vibility of element_ located--元素是否可见
presence_of_element_located--元素是否存在
如上:三种等待方法,最开始我一直使用的是presence_of_element_located,判断元素是否存在,最终还是报错,提示元素元素点击拦截异常
element_to_be_clickable--等待元素出现可以点击,便可以元素定位成功
需要先导包:
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
复制代码
element = WebDriverWait(self.browser, 5).until(
EC.element_to_be_clickable((By.XPATH, "//input[@placeholder='请输入会员手机号']")))
element.clcik()
复制代码

方法三:使用JS点击
然而有时即使已经显式等待了,却仍然会报错: ElementClickInterceptedException,这多少有点奇怪,为什么 webdriver 有时就是无法点击,我不知道,也许这和他首先执行的一些验证检查有关,反正就在这一刻,它不给你点
代码如下:
element = self.browser.find_element(By.XPATH, "(//span[@class='el-checkbox__inner'])[4]")
self.browser.execute_script("arguments[0].click();", element)
复制代码

这是通过 JavaScript 完成的点击,js可以避开一些校验
👆以上便是在编写selenium自动化时元素定位时踩的坑,以此分享防止踩坑
下面是配套资料,对于做【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!
软件测试面试小程序
被百万人刷爆的软件测试题库!!!谁用谁知道!!!全网最全面试刷题小程序,手机就可以刷题,地铁上公交上,卷起来!
涵盖以下这些面试题板块:
1、软件测试基础理论 ,2、web,app,接口功能测试 ,3、网络 ,4、数据库 ,5、linux
6、web,app,接口自动化 ,7、性能测试 ,8、编程基础,9、hr面试题 ,10、开放性测试题,11、安全测试,12、计算机基础

资料获取方式 :
















 493
493











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









