







 本文介绍了Domain Separation Networks(DSNs),它通过学习图像表示的私有和共享子空间来实现域适应。DSNs包含私有和共享编码器,以及共享解码器和分类器。通过差异损失、相似损失和重构损失,DSNs能够分离并适配源域和目标域的特征,从而在非监督域适应中表现出优越性能。
本文介绍了Domain Separation Networks(DSNs),它通过学习图像表示的私有和共享子空间来实现域适应。DSNs包含私有和共享编码器,以及共享解码器和分类器。通过差异损失、相似损失和重构损失,DSNs能够分离并适配源域和目标域的特征,从而在非监督域适应中表现出优越性能。
前言
受私有共享组件分析工作的启发,我们显式地学习了提取图像表示,这些图像表示被划分为两个子空间:一个组件是每个域的私有组件,另一个组件是跨域共享的。我们的模型不仅被训练在源域中执行我们关心的任务,而且使用分区表示来重构来自这两个域的图像。我们的新体系结构产生了一个模型,该模型在一系列非监督域适应场景上的性能优于最先进的模型,并且还生成了私有和共享表示的可视化,从而支持对域适应过程的解释。模型引入了每个域的私有子空间的概念,它捕获了域的特定属性,比如背景和低层图像统计。共享子空间通过使用自动编码器和显式丢失函数来实现,它捕获域共享的表示。通过找到一个与私有子空间正交的共享子空间,我们的模型能够分离每个域特有的信息,并在此过程中生成对当前任务更有意义的表示。
Domain Separation Networks (DSNs)
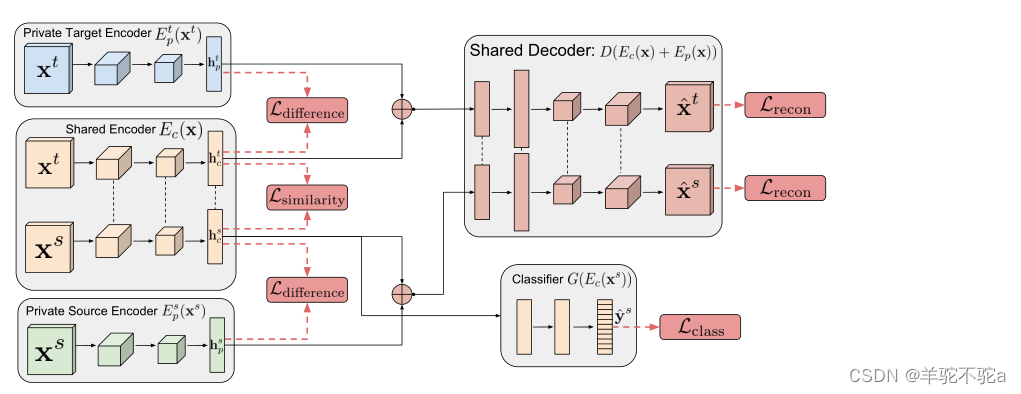
网络结构包含:
- Private Target Encoder
: 目标域私有编码器,用来提取目标域的私有特征。
- Private Source Encoder
: 源域私有编码器,用来提取源域的私有特征。
- Shared Encoder
: 共享编码器,用来提取源域和目标域的公有特征。
- Shared Decoder
: 共享解码器,用来将私有特征和公有特征组成的样本进行解码,即对输入x进行重构。
- Classifier
: 分类器,在训练时用来对源域样本进行分类,在训练完成时就可以直接用在目标域数据上进行分类。
(一)首先忽略右下角的分类器,剩下部分就是自编码器的结构。源域样本 首先进入
和
,之后两个编码器分别输出
和
。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









