






简介
我作为解决方案架构师已经工作多年,我经常看到同样的错误。通常,公司希望发展他们的数据平台,因为当前的解决方案不能满足他们的需求,这是一个很好的理由。但很多时候他们从错误的起点开始:
- 确定需求和未来的解决方案,但忘记当前解决方案的回顾步骤。
- 确定某些产品是主要问题。通常这涉及选择另一种产品作为解决这些问题的神奇解决方案。
- 识别技术孤岛但没有知识孤岛,因此不支持足够的数据治理解决方案。
- 不要彻底规划当前解决方案和新解决方案之间的共存计划。迁移永无止境,旧产品永不关闭。
我想原因很简单,同时也很难改变:
- 最后,我们是人,通常我们不喜欢听到我们做错了什么。我们没有运用足够的批判性思维。
- 犯错的文化是不好的。有时,这种分析可以克服责备的感觉。
- 追溯步骤需要大量的精力和时间。此时此刻,我们的社会处于一种急躁和即时满足的文化中。
犯错误并识别它们是学习过程的一部分。这是一个很好的指标,表明我们正在努力改进和发展我们的解决方案。但是我们必须深入分析并了解原因(什么,为什么等),以避免每次都犯同样的错误。
没有神奇的数据产品,或者至少,我不知道它们。一个全球数据平台有很多用例,并不是所有用例都可以通过同一个数据产品来解决。我记得当 RDBMS 数据库是所有用例的解决方案时。许多公司会在非常大的 RDMBS (OLTP/OLAP) 数据库上投入大量资金和精力,如 Teradata、Oracle Exadata、IBM 或 DB2。在那之后,出现了大数据生态系统和 NoSQL,每个人再次开始设计大数据湖,甚至使用 Impala 和 Hive 等解决方案作为数据仓库。这些解决方案很多都失败了,因为它们只是顺应潮流而进行的技术变革,但几乎没有人分析过原因:
- 我们有多少工作负载?哪些工作正常,哪些不正常?
- 原因是什么?数据模型会不会有问题?
- 我们如何消费数据?
- 延迟是问题吗?延迟差距在哪里?
- 我们是否遵循自动化范式?
- 我们的架构是否非常复杂?
今天,我们处于一个更复杂的场景中。有更多的数据产品(和营销)加入了新的云方法。云比以往任何时候都更需要改变我们的文化、愿景和方法。
在我们的数据平台中拥有多个产品会在许多方面增加解决方案的复杂性,例如操作、共存或集成,但同时使我们能够灵活地提供不同的质量,并避免锁定供应商场景。我们必须利用云的优势。其中之一是降低运营成本和工作量,从而在各种服务方面提供更好的解决方案。 对技术感兴趣朋友可以加这个扣扣2779571288交流。
逻辑数据结构和数据虚拟化
这种架构提供了一个单一层,使用户和应用程序能够访问数据,将数据的位置与特定的技术存储库产品分开。这种方法允许我们在不影响系统运行的情况下改进数据存储库层,从而改善用户的数据集成体验。这种能力也是使我们的 BI 层更加敏捷的基础。Logic Data Fabric 帮助我们快速适应不断变化的业务需求,使我们能够添加新技术功能,减少集成工作和上市时间。
今天,混合多云解决方案引起了很多兴趣。Denodo 等公司 多年来一直致力于提供专注于数据结构和数据虚拟化的解决方案。
将 Logic Data Fabric 与 数据虚拟化相结合 是一种强大的工具,但会变得如此复杂并将所有逻辑集中在一个地方。这是需要考虑的事情。
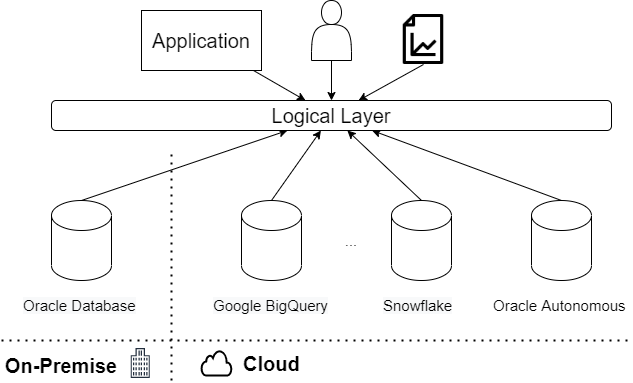
目前,最常见的场景之一是将 On-Premise 解决方案迁移到 Cloud 或 Multi-Cloud 解决方案。在这些情况下,数据迁移和数据集成是一些挑战。
- 将数据从本地数据库迁移到新的云数据平台。
- 将当前解决方案与新数据平台集成。
- 验证数据的质量。
这些任务并不容易执行,每次更改我们的数据存储库之一时,我们都必须这样做。成功的关键之一是提供一个逻辑数据层,该层根据某些标准提供来自不同来源的数据。

这些功能为我们设计迁移和共存策略提供了很大的灵活性。
例如,我们可以开始在两个平台(本地和云)上复制相同的数据集。逻辑层将根据时间戳从数据存储库之一检索数据集。
避免耦合数据存储库中的所有逻辑
在过去的几年里,人们付出了很多努力来将数据和逻辑分离到不同的层中。在我看来,这是正确的方法。
将逻辑和数据放在同一层会涉及诸如孤岛、单体、锁定供应商或性能问题等问题。通常,数据存储库是最昂贵的层。我记得我付出了很多努力来为其他更具成本效益的分布式解决方案提供数英里的 PL/SQL。
我认为很多时候 云数据解决方案提供了不切实际的可扩展性。 当然,我们可以扩大我们的解决方案,但成本是多少?目前,一些开发团队不太关注流程优化,因为与 On-Premise 不同,在云中,它可以无限制地扩展。问题是成本,很多时候出来需要大量的精力和时间来解决它。
我们不应该忘记分布式数据库出现在云之前。云解决方案在许多情况下为我们提供了更好的性能、按需付费、更少的操作任务以及仅在我们需要时扩展资源。但在许多情况下,我们在内部部署的技术是相同的。
我再次看到与几年前相比,有多少团队重新大规模应用相同的方法。这并不意味着我们不能在 Snowflake 中使用流/任务或在 Oracle 自治数据库中使用 PLSQL,但也不能将它们用作全局方法和所有用例。我们冒着再次构建单体的风险。
不要误会我的意思:Snowflake、Big Query、Oracle 自治数据库和其他新的数据产品都是很棒的产品,具有很棒的功能,但关键是在我们的数据策略中正确使用它们。
避免建造沙堡
在延迟或数据处理并发方面的性能不佳是设计和构建新数据平台的原因之一。我们必须避免在当前解决方案和新解决方案之间创建依赖关系。因为众所周知,“链条与最薄弱的环节一样强大”。
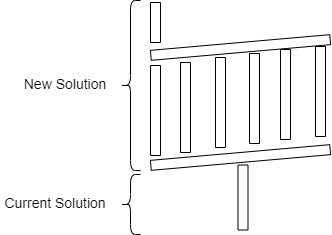
一个常见的场景是在当前解决方案之上设计新解决方案,这意味着它们之间存在很强的依赖性。我们会将问题从一个平台传播到另一个平台,并增加对当前解决方案产生影响的风险。例如,很多时候新数据平台的数据源是当前的:
- 如果我们对数据的延迟有问题,在数据流中添加一个新的步骤并不是一个好的解决方案。这种方法会增加延迟问题。
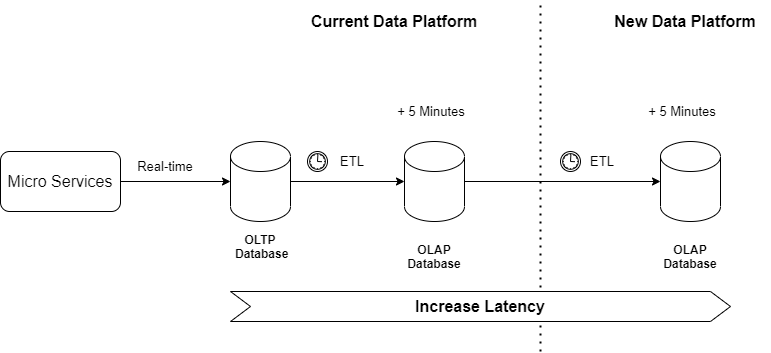
- 如果我们对当前解决方案的可用性和/或性能有问题,我们将增加这个问题,因为我们正在添加一个新的使用者。数据复制可能会给数据库系统带来沉重的负担。
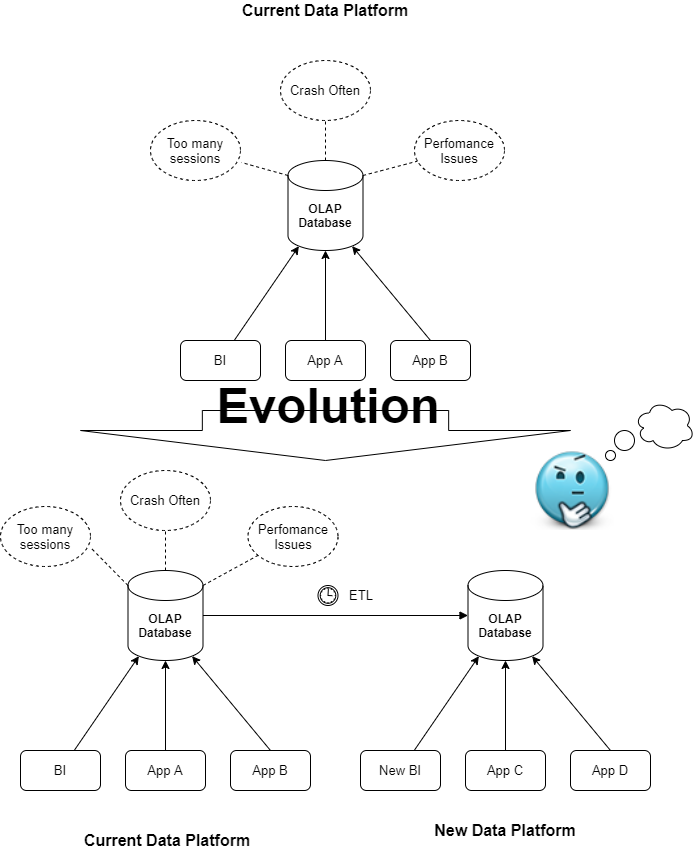
另一种常见情况是更改数据存储库,但保持相同的摄取方法和数据模型。在许多公司中,ETL 是主要的复制过程,通常涉及性能或数据质量问题。我们更改数据存储库并不重要,因为基于 ETL 的复制总是涉及相同的问题。
结论
设计一个成功的新数据平台通常来自于理解我们为什么会在这里。 了解过去对于理解现在、设计未来和避免再次犯同样的错误很重要。
新的技术改进和架构需要改变我们的工作和思考方式。作为一个团队,我们必须不断发展以避免在云中应用本地环境中的相同方法。团队文化和架构模式比产品更重要。
一开始,从时序要求的角度来看,在当前不起作用的东西之上构建新的解决方案似乎是一个很好的策略。通常,它会产生更多的问题,消耗团队的努力并引起团队和用户的不满。 对技术感兴趣朋友可以加这个扣扣2779571288交流。















 2796
2796











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









