







时序动作定位 | CO2-Net:弱监督时间动作定位的跨模态共识网络(ACM MM 2021)_六个核桃Lu的博客-CSDN博客
原文链接:https://arxiv.org/pdf/2107.12589.pdf
Cross-Modal Consensus Network For Weakly Supervised Temporal Action Localization论文总结
一、任务背景
-
从预训练的提取器中提取的特征是为修剪视频动作分类而训练的,而不是针对WS - TAL任务,导致不可避免的冗余和次优化。所以需要对特征进行重新标定,以减少任务无关的信息冗余。(对特征提取器进行微调需要高时间和高计算成本,本文认为对特征重校准是相对高效的方式)
二、贡献点
-
提出了一个跨模态共识网络( CO2-Net ),主要介绍了两个相同的跨模态共识模块( CCM ),设计了一个跨模态注意力机制,利用主模态的全局信息和辅助模态的跨模态局部信息过滤掉与任务无关的信息冗余。
-
此外,进一步探讨了模态间的一致性,将来自每个CCM的注意力权重作为来自另一个CCM的注意力权重的伪目标,以保持来自两个CCM的预测之间的一致性,形成相互学习的方式。(将互相学习第一个用于时间动作定位。)
三、研究内容
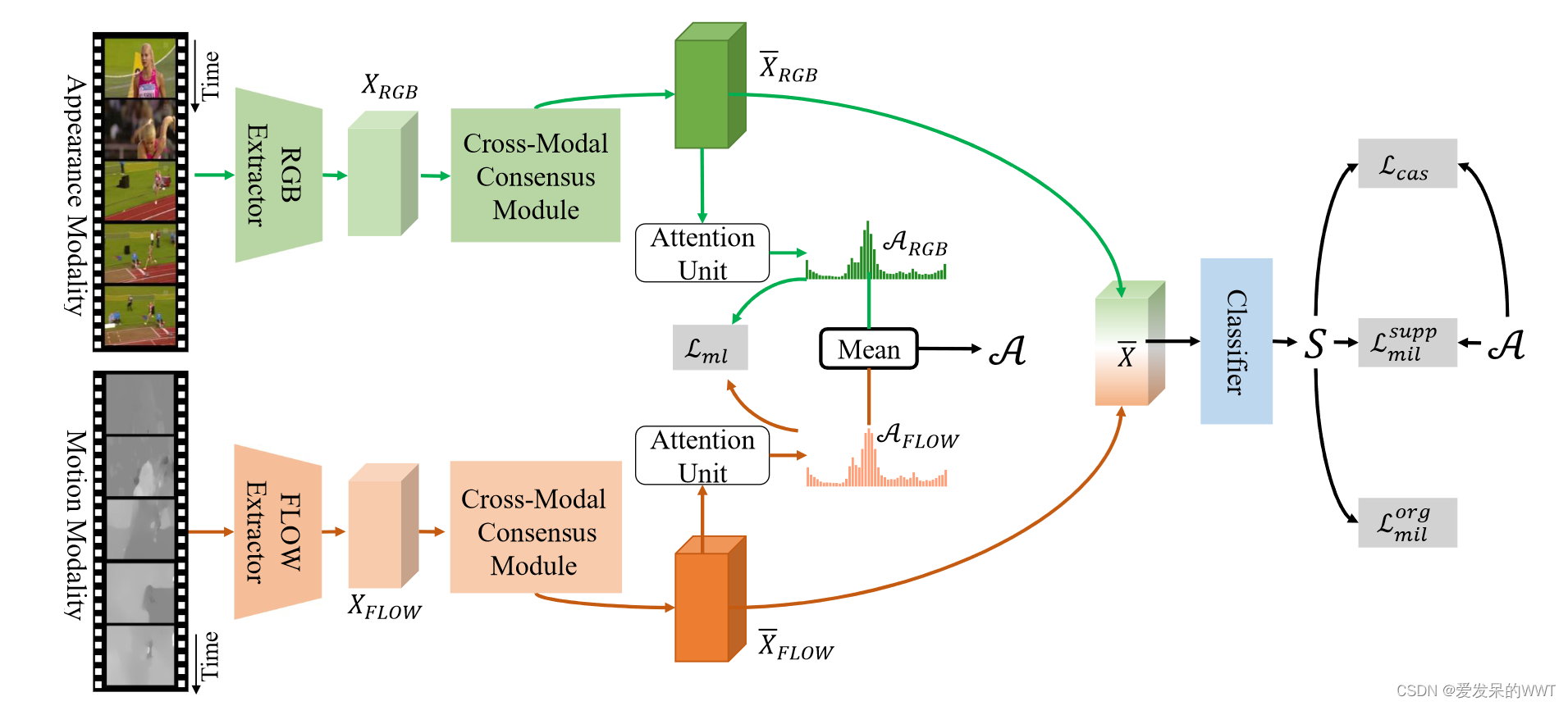
1.Pipeline
-
网络流程:
-
把RGB和FLOW特征送到两个相同的CCM模块中。在每个CCM中,我们选择两个模态中的一个作为主模态来增强,通过借助自身的全局上下文和来自另一个(辅助)模态的跨模态局部聚焦信息,去除与任务无关的信息冗余。因此获得这个模态的更多的任务特异性表征。
-
然后,使用增强的特征通过由两个卷积层组成的注意力单元产生注意力权重,该权重表示每个片段成为前景的概率。聚合生成的这两个注意力权重,产生最终的注意力权重,可用于测试阶段。此外,我们还将两个增强的特征进行融合,并将其输入到分类器中预测分类概率。
-
右半部分表示优化过程,S是背景类,使用融合后的注意力权重A抑制背景片段,做乘法。
-
2.模块各部分
-
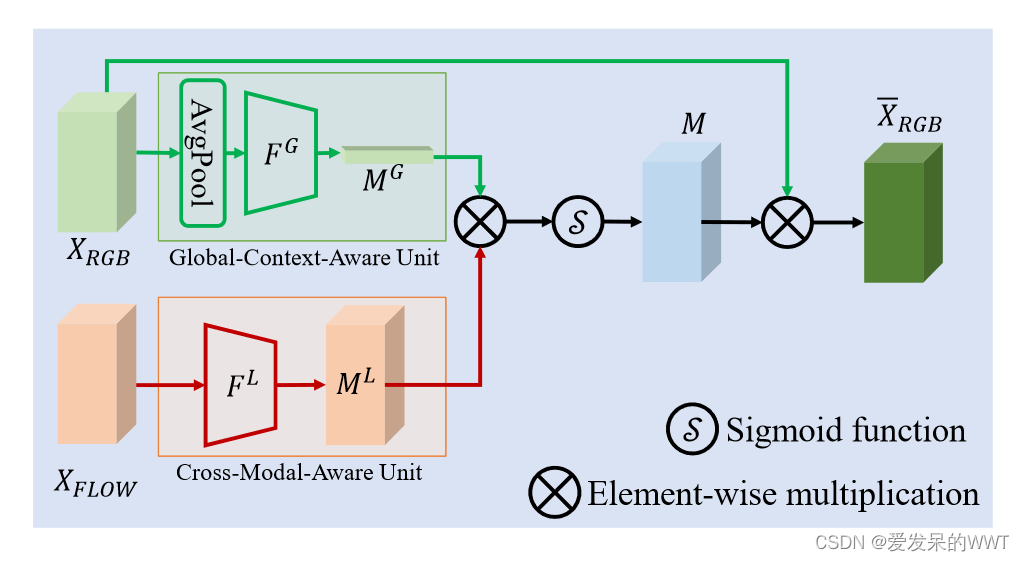
CCM模块(以RGB作为主模态为例):产生校准权重
-
主模态通过全局平均池化和卷积,辅助模态通过卷积,两个结果相乘得到M,再通过Sigmoid函数生成通道重校准权重来增强原始主模态特征XRGB。
-
值得注意的是,MG和ML在自注意力模块中可以被视为"Query"和"Key"。
-
-
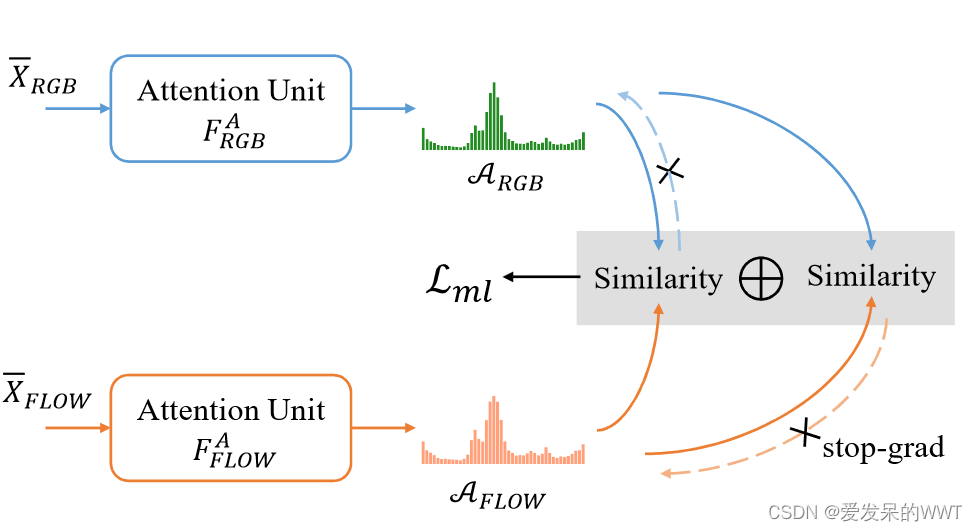
双模态特异性注意力单元:产生时间注意力权重,得到前景概率
-
-
将增强后的特征输入到注意力单元(3个卷积层)中,分别得到模式特异性的注意力权重Argb和Aflow,做加和平均得到A,即能够更好地表示片段为前景的概率。
-
最后,将两种类型的增强特征\overline{X}RGB和\overline{X}FLOW串联起来形成\overline{X},并将其输入到包含三个卷积层的分类器中,以生成给定视频的时序类激活图。
-
3.损失函数(上图右半部分)
总的损失函数:![]()
-
Lmil:top-k多实例学习中的损失,包含两部分,应用到背景S和抑制背景\overline{S}中的
-
Lcas:协同相似性损失在融合X和抑制背景S中
-
Lml:
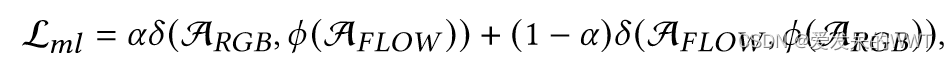
-
用到三个注意力权重:Argb,Aflow,融合后的A。
-
公示表示:应用互学习(mutual learning)。符号从左到右依次是,α超参数,δ相似性度量函数,Ф截断输入梯度的函数。
-
将ARGB和AFLOW分别视为彼此的伪标注,使它们能够相互学习,对齐注意力权重。这里,我们采用均方误差MSE作为相似性函数 .(除MSE外,实验部分还讨论了应用于等式的其他相似性度量函数(即Jensen - Shannon ( JS ))散度、库尔贝克-莱布勒( KL )散度和平均绝对误差( MAE ) ))
-
-
Loppo:
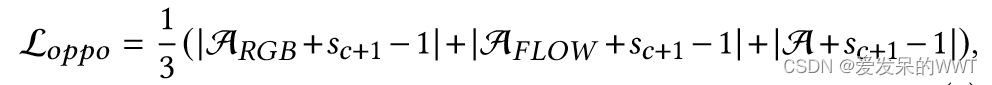
-
Sc+1,片段是背景的概率。注意力权重的分布应该与S中背景类的概率分布相反(opposite)
-
-
Lnorm:正则
4.实验
-
公共数据集:THUMOS14上(mAP@0.5=38.4%),将tIoU阈值进一步划分,平均mAP选取不同的阈值区间来表明结果的相对优越性。低阈值提升效果最好。这些结果表明,利用不同模态的信息来减少与任务无关的信息冗余,有利于时间动作定位。在ActivityNet1.2上(Avg mAP=26.4%),整体上仍然优于SOTA方法,提升效果不明显。
-
消融实验(探究的很全面):每个部分的损失函数;不同类型的互学习损失;主模态和辅助模态的不同组合;与其他融合方法进行比较。
-
验证了跨模态共识模能更好地融合两种模态来提高性能。此外,尽管CO2 - Net在使用CCM过滤信息冗余后也串联了两类特征,但表6中' Concat '和' CCM '的结果表明,我们使用CCM的方法在原始特征上的表现明显优于使用' Concat '的方法,显示了特征再校准对于更有代表性的特征的意义。
-
最后再对有效性的证明上,和其他算法对比进行了可视化呈现。(定位边界更准确了,可以看到还是假阳性的问题还是存在)
四、一些自问自答
1.为什么用的是1.2?
-
改进的是ECCV2018的W-TALC: Weakly-supervised Temporal Activity Localization and Classification这篇论文的代码,它用的是ActivityNet1.2的特征
2.为何能过滤掉信息冗余?
-
想法基于直觉:RGB和FLOW特征从给定数据的不同角度包含模态特异性信息(即外观和运动信息)。因此,可以借助来自自身的全局上下文信息和来自不同模态不同视角的局部上下文信息来过滤掉某个模态中包含的冗余信息。
-
CCM模块的设计:借助主模态的全局信息,CCM可以利用辅助模态的不同视角信息来判断主模态的某一部分是否为任务无关信息冗余。因此,在分别过滤原始RGB特征和FLOW特征中的冗余后,我们从两个CCM中获得了RGB增强特征和FLOW增强特征。
3.为什么叫CO2?
-
a CrOss-modal cOnsensus NETwork (CO2-Net)
4.为什么主模态是全局信息,辅助模态是局部信息?
-
主模态在用了平均池化+卷积,压缩XRGB聚合了视频级特征,辅助模态只有卷积,没有全局平均池化。
-
实验证明这种组合方法可以得到更好的效果
5.模态间的一致性是什么意思?伪目标?如何做到相互学习?
-
增强特征输出的特异性注意力权重ARGB和AFLOW分别视为彼此的伪标注,使它们能够相互学习(应用互学习损失),对齐注意力权重。
6.为什么说用到了模态融合的内容?
-
视频是典型的多模态媒体,从不同的角度表征信息。利用不同模态的不同角度的信息来重新校准每个模态的表示。
-
把RGB,和FLOW在文章里称为两种模态,分别代表不同角度的信息。
7.受到什么的启发?
-
self-attention和se-block


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









