







3.4 group by优化
分组操作,我们主要来看看索引对于分组操作的影响。
首先我们先将 tb_user 表的索引全部删除掉 。
drop index idx_user_pro_age_sta on tb_user;
drop index idx_email_5 on tb_user;
drop index idx_user_age_phone_aa on tb_user;
drop index idx_user_age_phone_ad on tb_user;
接下来,在没有索引的情况下,执行如下SQL,查询执行计划:
explain select profession , count(*) from tb_user group by profession ;
然后,我们在针对于 profession , age, status 创建一个联合索引。
create index idx_user_pro_age_sta on tb_user(profession , age , status);紧接着,再执行前面相同的SQL查看执行计划。
explain select profession , count(*) from tb_user group by profession ;
再执行如下的分组查询SQL,查看执行计划:
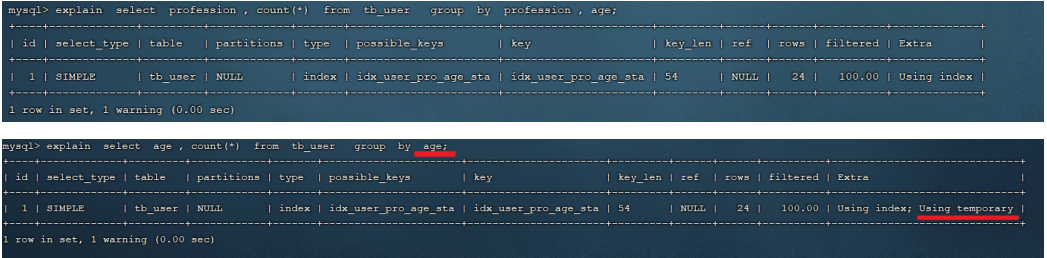
我们发现,如果仅仅根据age分组,就会出现 Using temporary ;而如果是 根据profession,age两个字段同时分组,则不会出现 Using temporary。原因是因为对于分组操作,在联合索引中,也是符合最左前缀法则的。
所以,在分组操作中,我们需要通过以下两点进行优化,以提升性能:
A. 在分组操作时,可以通过索引来提高效率。
B. 分组操作时,索引的使用也是满足最左前缀法则的。
3.5 limit优化
在数据量比较大时,如果进行limit分页查询,在查询时,越往后,分页查询效率越低。
我们一起来看看执行limit分页查询耗时对比:

通过测试我们会看到,越往后,分页查询效率越低,这就是分页查询的问题所在。
因为,当在进行分页查询时,如果执行 limit 2000000,10 ,此时需要MySQL排序前2000010 记录,仅仅返回 2000000 - 2000010 的记录,其他记录丢弃,查询排序的代价非常大 。
优化思路: 一般分页查询时,通过创建 覆盖索引 能够比较好地提高性能,可以通过覆盖索引加子查询形式进行优化。
explain
select * from tb_sku t , (select id from tb_sku order by id
limit 2000000,10) a where t.id = a.id;3.6 count优化
3.6.1 概述
select count(*) from tb_user ;在之前的测试中,我们发现,如果数据量很大,在执行count操作时,是非常耗时的。
-
- MyISAM 引擎把一个表的总行数存在了磁盘上,因此执行 count(*) 的时候会直接返回这个数,效率很高; 但是如果是带条件的count,MyISAM也慢。
- InnoDB 引擎就麻烦了,它执行 count(*) 的时候,需要把数据一行一行地从引擎里面读出来,然后累积计数。
如果说要大幅度提升InnoDB表的count效率,主要的优化思路:自己计数(可以借助于redis这样的数据库进行,但是如果是带条件的count又比较麻烦了)。
3.6.2 count用法
count() 是一个聚合函数,对于返回的结果集,一行行地判断,如果 count 函数的参数不是NULL,累计值就加 1,否则不加,最后返回累计值。
用法:count(*)、count(主键)、count(字段)、count(数字)
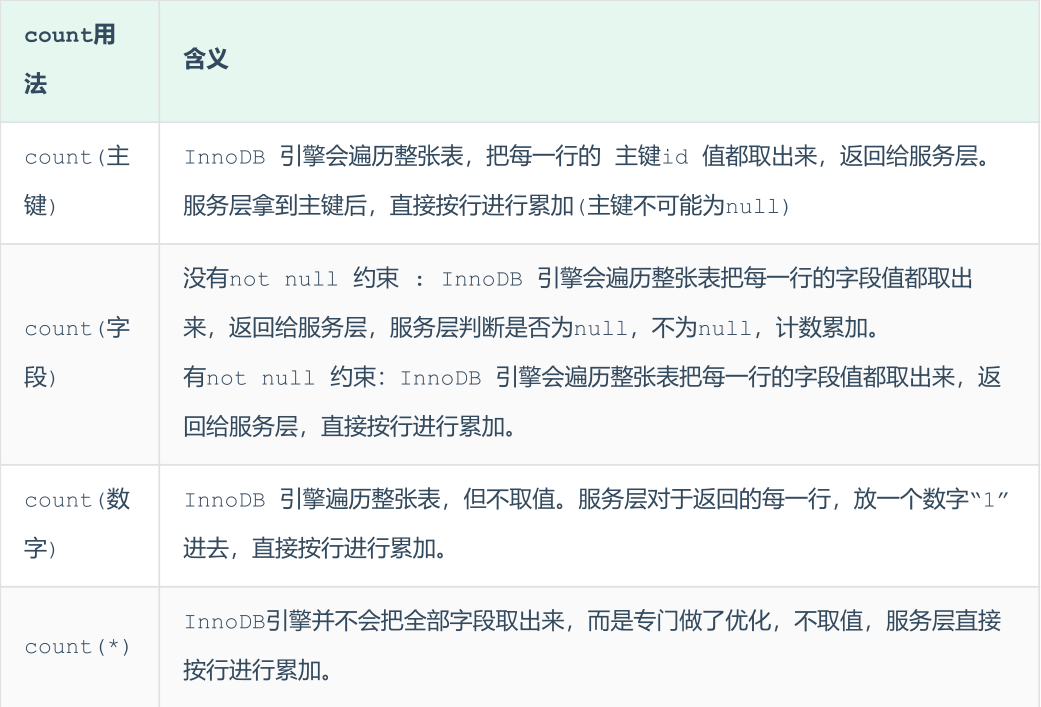
按照效率排序的话,count(字段) < count(主键 id) < count(1) ≈ count(*),所以尽量使用 count(*)。
3.7 update优化
我们主要需要注意一下update语句执行时的注意事项。
update course set name = 'javaEE' where id = 1 ;当我们在执行删除的SQL语句时,会锁定id为1这一行的数据,然后事务提交之后,行锁释放。
但是当我们在执行如下SQL时。
update course set name = 'SpringBoot' where name = 'PHP' ;当我们开启多个事务,在执行上述的SQL时,我们发现行锁升级为了表锁。 导致该update语句的性能大大降低。
InnoDB的行锁是针对索引加的锁,不是针对记录加的锁 ,并且该索引不能失效,否则会从行锁升级为表锁 。















 843
843











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









