






 本文介绍了模糊测试的基本概念及其在软件安全领域的应用。重点讲解了AFL(American Fuzzy Lop)工具的工作原理及如何利用它进行二进制程序的安全测试。通过实际案例演示了如何搭建AFL环境并使用该工具发现PDF查看器Xpdf中的潜在漏洞。
本文介绍了模糊测试的基本概念及其在软件安全领域的应用。重点讲解了AFL(American Fuzzy Lop)工具的工作原理及如何利用它进行二进制程序的安全测试。通过实际案例演示了如何搭建AFL环境并使用该工具发现PDF查看器Xpdf中的潜在漏洞。
模糊测试是一种介于完全的手工渗透测试与完全的自动化测试之间的安全性测试类型。它充分利用了机器的能力:随机生成和发送数据;同时,也尝试将安全专家在安全性方面的经验引入进来。从执行过程来说,模糊测试的执行过程非常简单:
- 测试工具通过随机或是半随机的方式生成大量数据;
- 测试工具将生成的数据发送给被测试的系统(输入);
- 测试工具检测被测系统的状态(如是否能够响应,响应是否正确等);
- 测试工具根据被测系统的状态判断是否存在潜在的安全漏洞。
个人理解就是通过对源码进行重新编译时进行插桩(简称编译时插桩)的方式自动产生测试用例来探索二进制程序内部新的执行路径。目前,Fuzzing技术已经是软件测试、漏洞挖掘领域的最有效的手段之一。Fuzzing技术特别适合用于发现0Day漏洞,也是众多黑客或黑帽子发现软件漏洞的首选技术。虽然不能直接达到入侵的效果,但是非常容易找到软件或系统的漏洞,以此为突破口深入分析,就更容易找到入侵路径。
AFL(American Fuzzy Lop)通过记录输入样本的代码覆盖率,不断对输入进行变异,从而达到更高的代码覆盖率。AFL 采用新型的编译时插桩和遗传算法自动发现新的测试用例,这些用例会触发目标二进制文件中的新内部状态,改善了模糊测试的代码覆盖范围。
- 从源码编译程序时进行插桩,以记录代码覆盖率(Code Coverage);
- 选择一些输入文件,作为初始测试集加入输入队列(queue);
- 将队列中的文件按一定的策略进行变异”;
- 如果经过变异文件更新了覆盖范围,则将其保留添加到队列中;
上述过程会一直循环进行,期间触发了crash的文件会被记录下来。它封装了一个GCC/CLang编译器,用于对被测代码重新编译的过程中进行插桩。插桩完毕后,AFL fuzz就可以给其编译过的代码输入不同的参数参数,跟踪被测代码的执行路径,并判定对输入的变异能否触发新的已知或未知执行路径。
流程如下:先是用afl-gcc编译源代码afl_test.c,然后以testcase.txt为输入,启动afl-fuzz程序,将testcase作为程序的输入执行程序,afl会在这个testcase的基础上进行自动变异输入,使得程序产生crash。
对afl环境搭建,下载AFL源码,然后make:

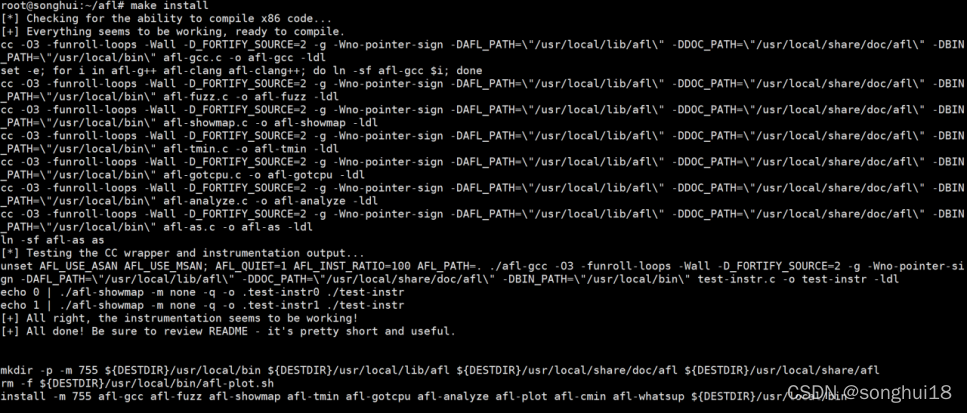
输入afl-,检验是否编译成功:
把上面的afl_test.c进行编译:
afl-gcc -g -o afl_test afl_test.c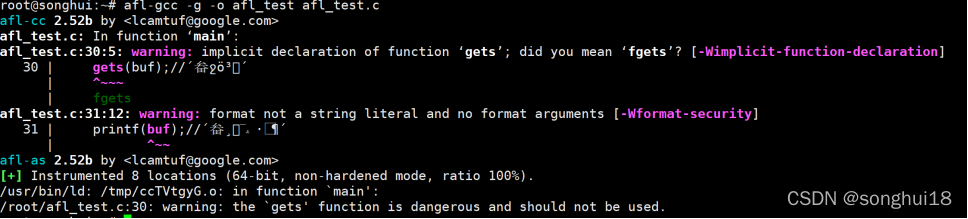
我们可以看到编译的时候,就有warning。如果是编译一个c++的源码,那就需要用afl-g++。
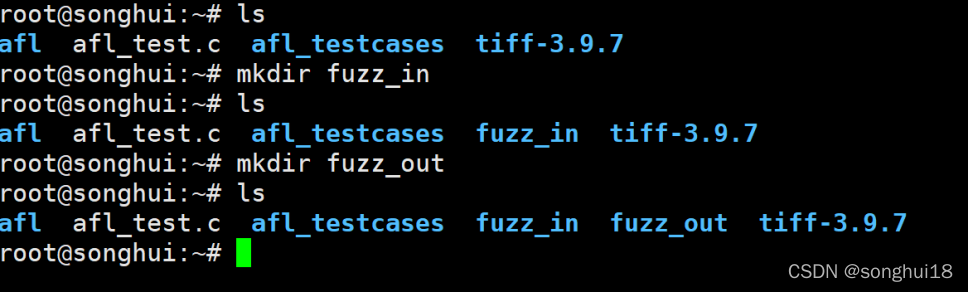
接着建立两个文件夹:fuzz_in和fuzz_out,用来存放程序的输入和fuzz的输出结果。
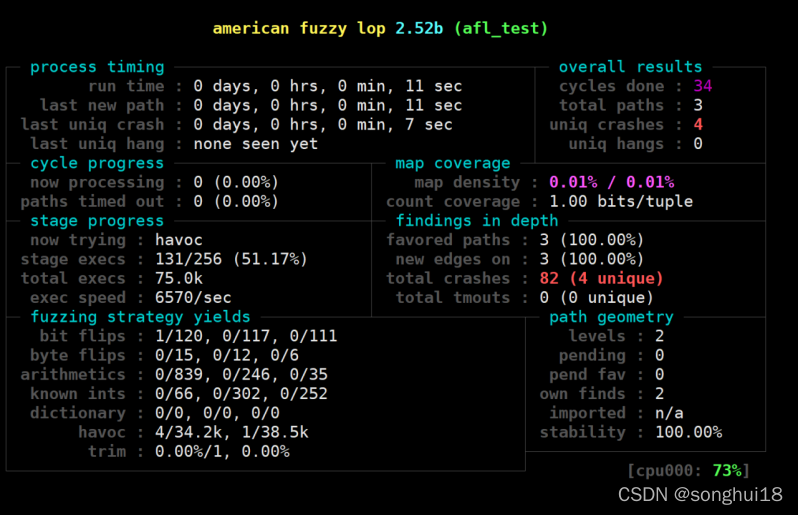
根据提示,crashes文件夹里面是我们产生crash的样例,hangs里面是产生超时的样例,queue里面是每个不同执行路径的测试用例,我按照教程查看了crash的6个样例,至此整个学习过程完成 。
接下来利用AFL测试xpdf程序。这是一个pdf查看器的漏洞,可能通过精心制作的文件导致无限递归,由于程序中每个被调用的函数都会在栈上分配一个栈帧,如果一个函数被递归调用太多次,就会导致栈内存耗尽和程序崩溃。因此,远程攻击者可以利用它进行 DoS 攻击。
首先进行安装:
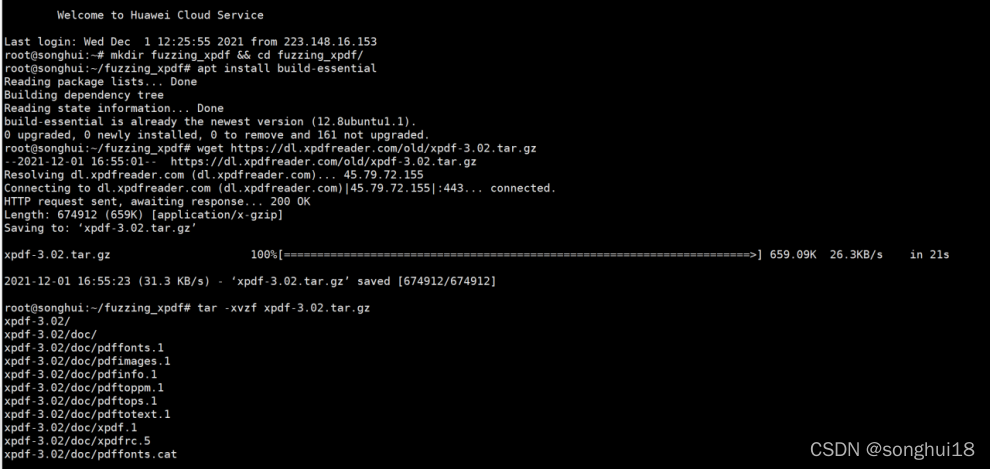
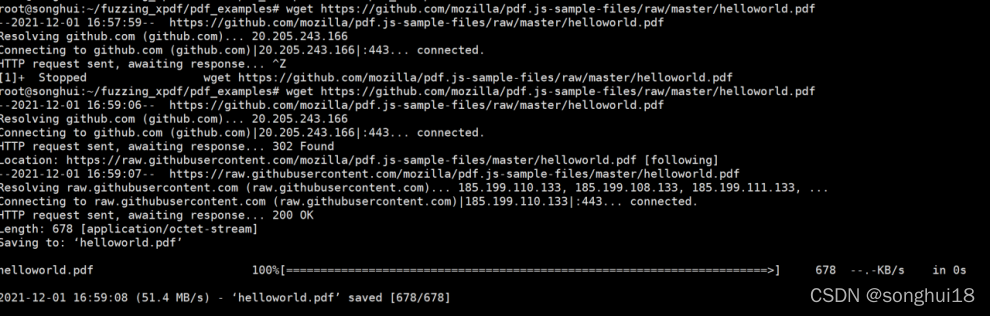 构建 Xpdf,进行测试:
构建 Xpdf,进行测试:
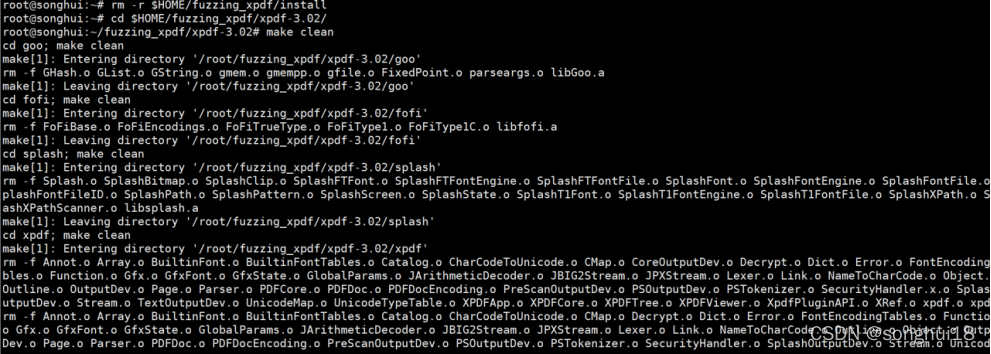
清理所有以前编译的目标文件和可执行文件:
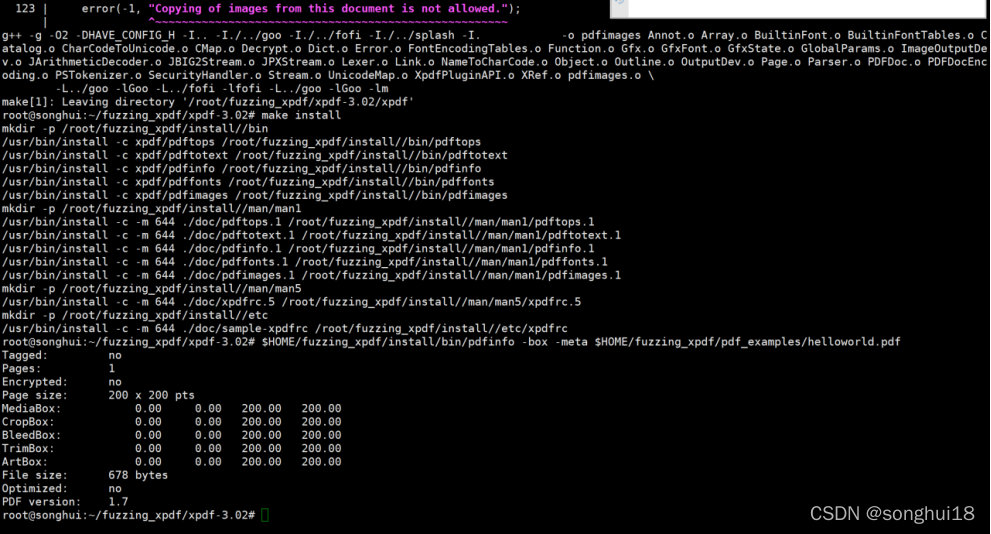
使用afl-clang-fast编译器构建 xpdf :

我们可以看到有很多warning,这些都有可能生成crash:
在make的时候加入AFL_USE_ASAN=1 make -j 4,就可以使用动态内存错误检查器ASAN:

编译成功后,开始fuzz:
afl-fuzz -i $HOME/fuzzing_xpdf/pdf_examples/ -o $HOME/fuzzing_xpdf/out/ -s 123 -- $HOME/fuzzing_xpdf/install/bin/pdftotext @@ $HOME/fuzzing_xpdf/output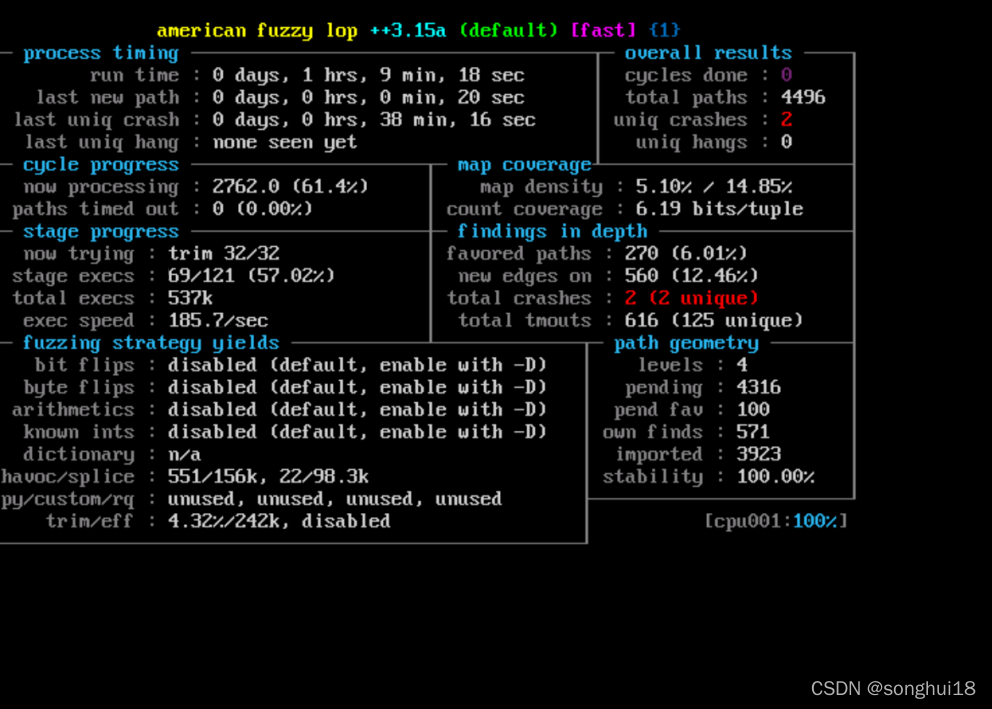
由于实验环境是服务器环境,无法查看多核编译界面,于是进入虚拟机继续试验。采用的虚拟机为Ubuntu-X64,首先更改虚拟机配置。跳过环境安装等步骤,然后利用AFL_USE_ASAN=1 make 进行编译,编译成功后,开始fuzz,与此同时我们可以使用afl自带的pdf字典测试样例,拷贝到input目录中:
按照实验要求,尝试在利用多进程执行afl-fuzz:
screen afl-fuzz -i $HOME/fuzzing_xpdf/input/ -o $HOME/fuzzing_xpdf/out/ -M 1 -- $HOME/fuzzing_xpdf/install/bin/pdftotext @@ $HOME/fuzzing_xpdf/output
screen afl-fuzz -i $HOME/fuzzing_xpdf/input/ -o $HOME/fuzzing_xpdf/out/ -S 2 -- $HOME/fuzzing_xpdf/install/bin/pdftotext @@ $HOME/fuzzing_xpdf/output
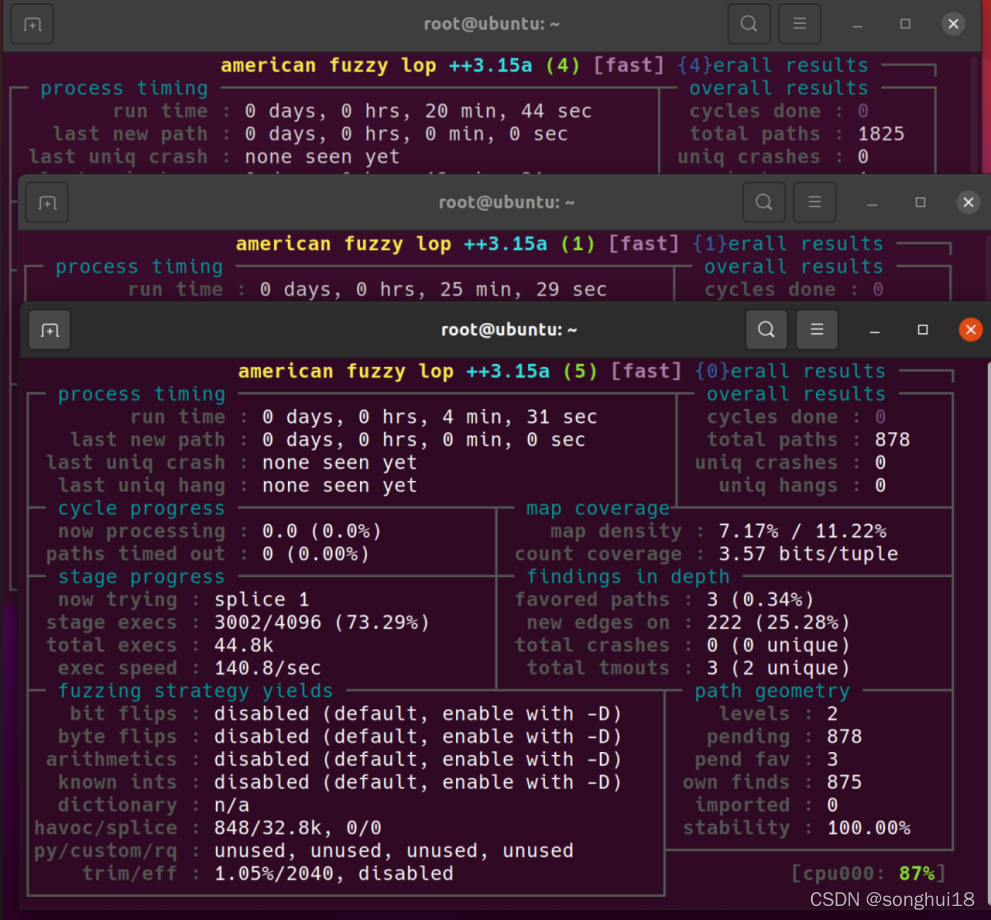
screen afl-fuzz -i $HOME/fuzzing_xpdf/input/ -o $HOME/fuzzing_xpdf/out/ -S 3 -- $HOME/fuzzing_xpdf/install/bin/pdftotext @@ $HOME/fuzzing_xpdf/output实验结果如下,我们可以看到主从进程同时进行,速度整体是有提升:
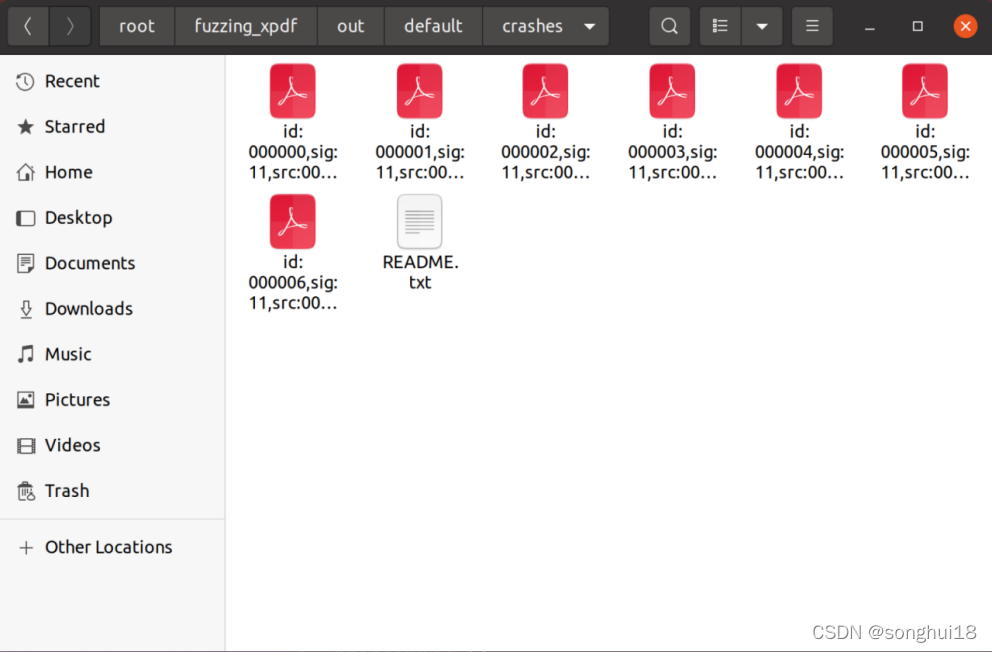
进入out文件夹就可以查看已经找到的crashes:



















 2130
2130

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











