






DataComp-LM: In search of the next generation of training sets for language models
1 Introduction
- 缺乏一个benchmark评估训练的数据集的好坏
- what ingredients constitute a state-of-the-art training set for language models
贡献点
-
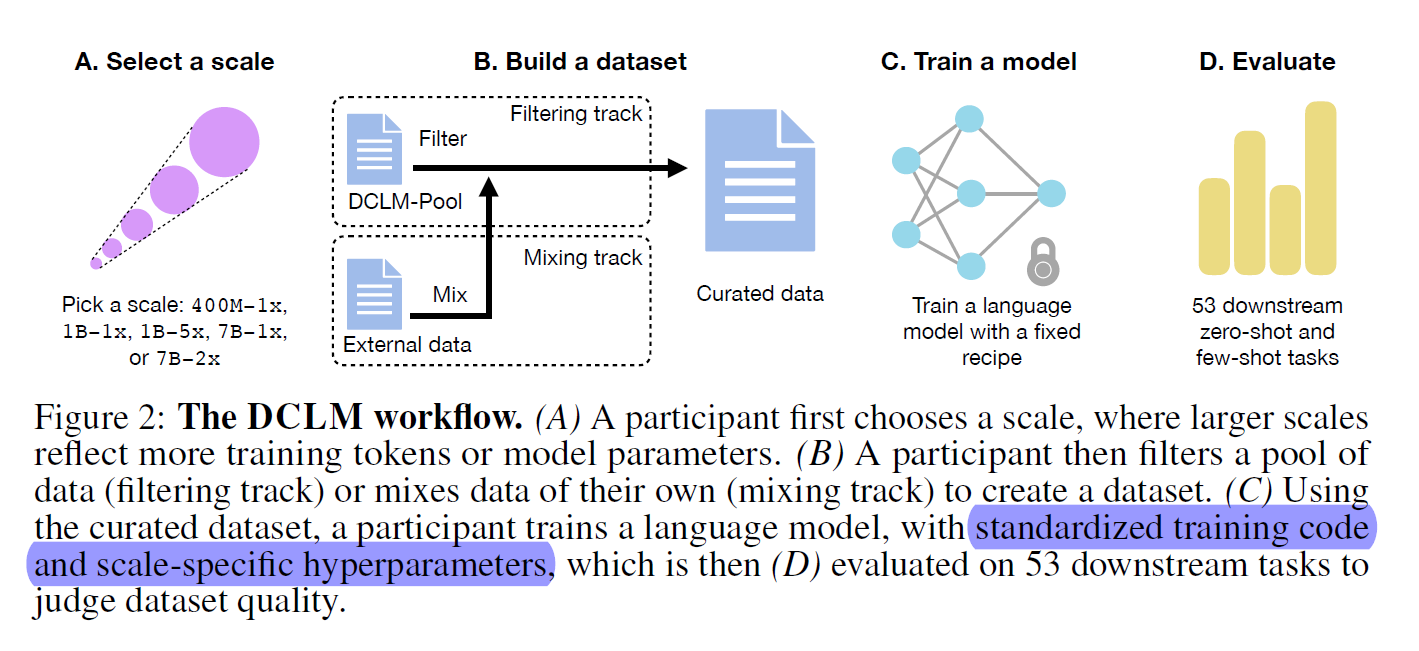
DataComp for Language Models (DCLM), the first benchmark for language model training data curation.
细节
researchers propose new training sets and data curation algorithms and then evaluate their datasets by training language models with a fixed training recipe on their data
-
DCLM-POOL, a corpus of 240 trillion tokens derived from Common Crawl [42]. DCLMPOOL
is the largest public corpus for language model training and forms the cornerstone
of the DCLM filtering track, where participants aim to curate the best possible training set
out of DCLM-POOL. -
investigation of scaling trends for dataset design:
- 400M parameters can still provide signal on which training sets perform better at larger scales. —— 设计了五个参数规模,验证数据集的有效性;
- filtering model can have a large impact on performance——一个简单的二分类器最好
-
combine our results into DCLM-BASELINE, a new state-of-the-art public training set for language model,训了个模型
3 The DataComp for language models (DCLM) benchmark
3.1 DCLM-POOL

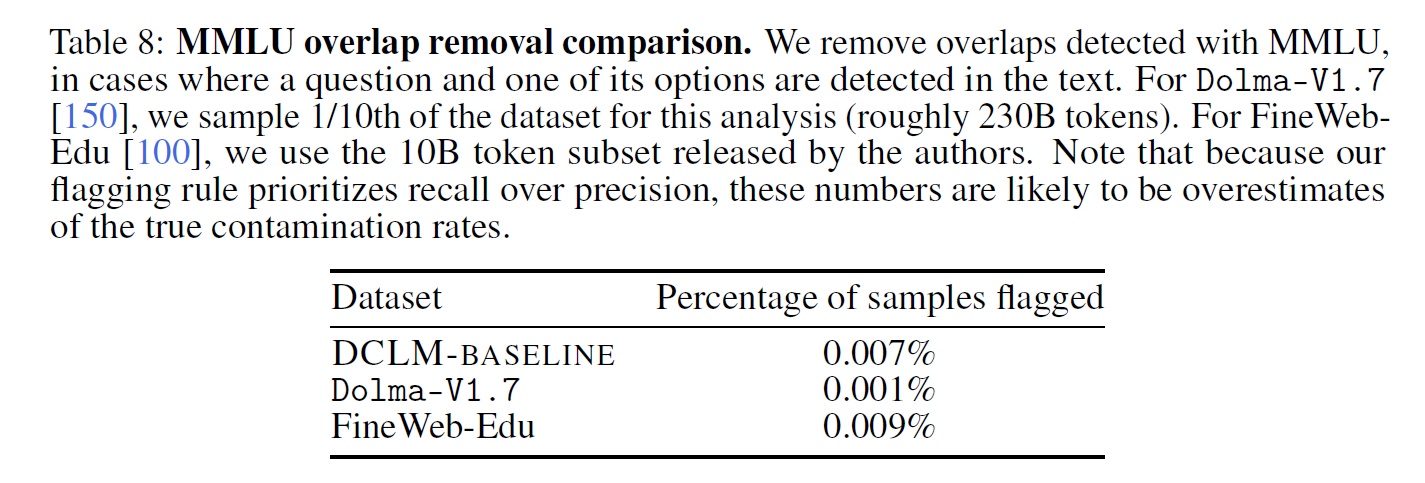
release decontamination tooling instead of decontaminating DCLM-POOL directly because the effect of such samples on downstream performance remains largely unclear.
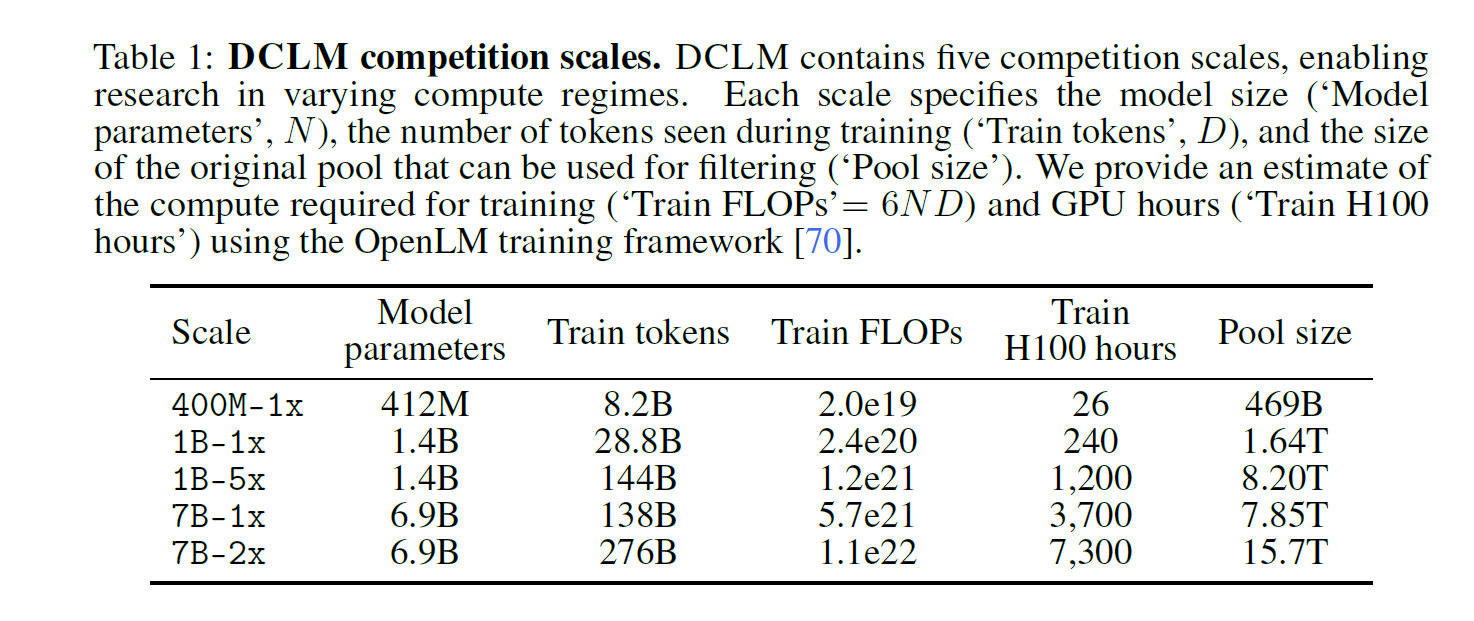
3.2 Competition scales: Supporting participants with different compute constraints
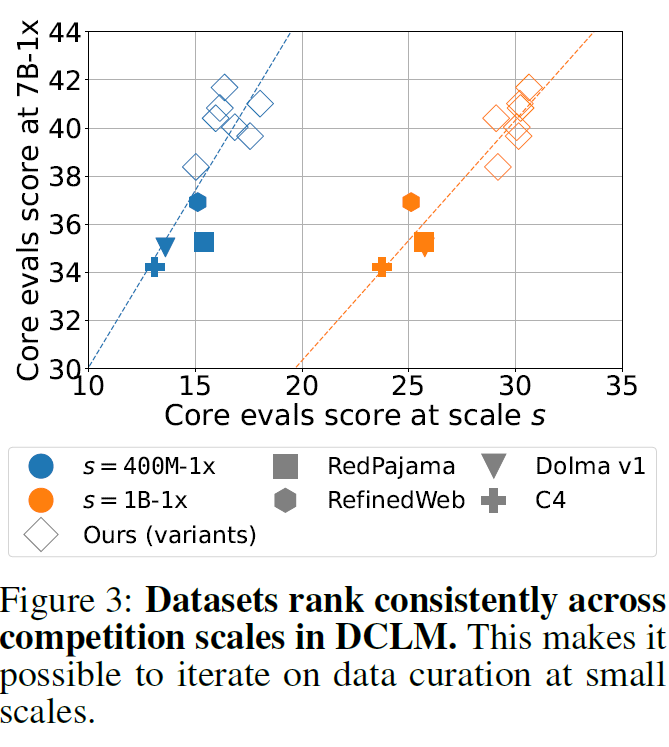
we plot the performance of 10 methods at the 7B-1x scale as a function of their 400M-1x and 1B-1x performance. We find high rank correlation between the smaller 400M-1x, 1B-1x results and larger 7B-1x results (Pearson’s r = 0.885 and r = 0.919, respectively), suggesting better curation strategies at smaller
scales transfer to larger scales.
3.3 Benchmark tracks: Filtering and mixing
(i) In the filtering track, participants propose algorithms to select training data from a candidate pool.
(ii) In the mixing track, a submission combines documents from potentially many sources.
3.4 Training
训练过程统一
we adopt a decoder-only Transformer (e.g., GPT-2, Llama) [127, 161, 165], implemented in OpenLM [70]. We also provide unified data processing utilities.
3.5 Evaluation
contains 53 downstream tasks suitable for base model evaluation
focus on three main performance metrics.
- First, we consider MMLU 5-shot accuracy
- we propose CORE centered accuracy, computed over a subset of 22 tasks
- Finally, we report EXTENDED centered accuracy, which averages the centered performance for all of our 53 tasks.
4 Building high-quality training datasets with DCLM
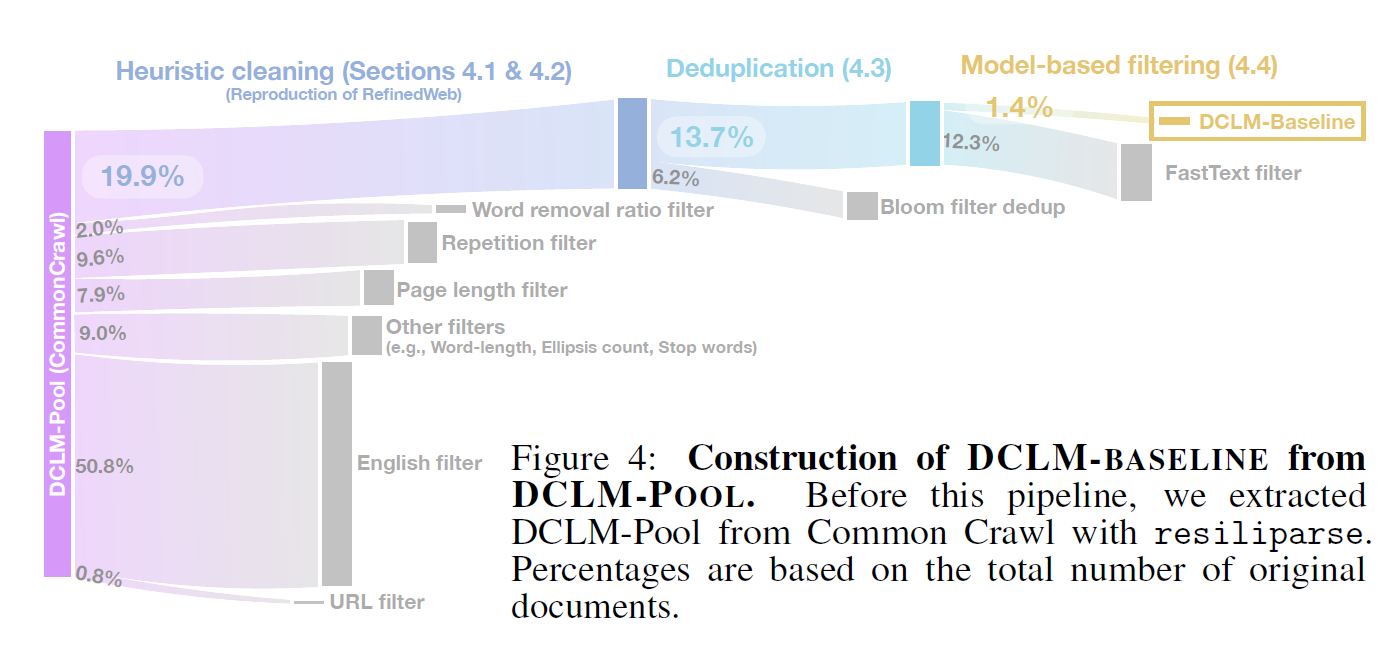
4.1 Evaluating existing training datasets
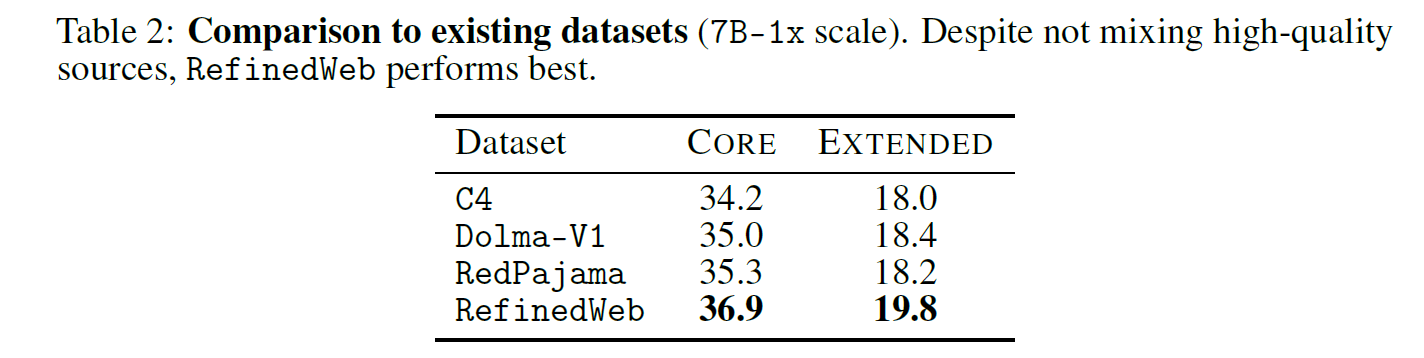
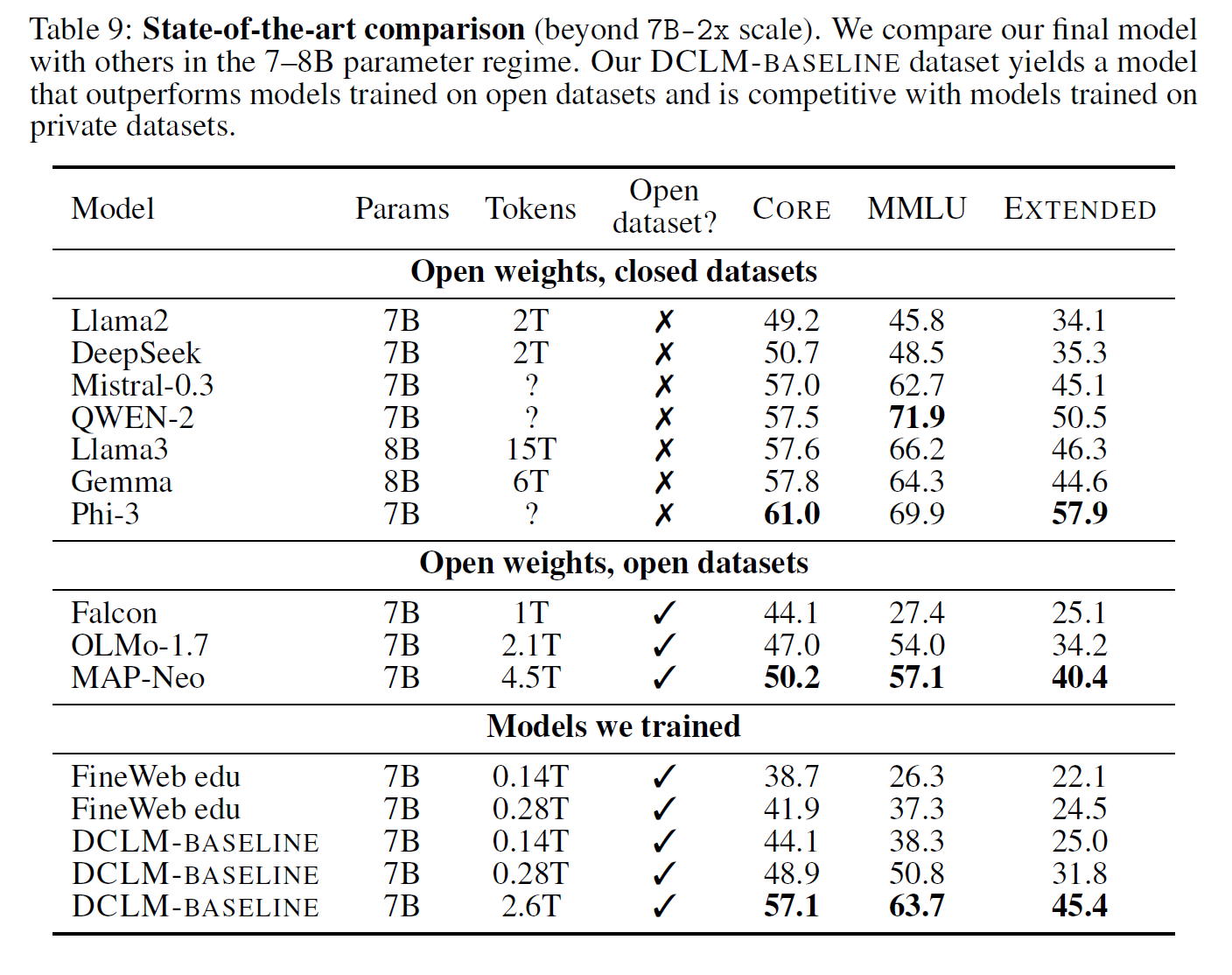
we find that RefinedWeb performs the best on our CORE and EXTENDED metrics at the 7B-1x scale

pipeline: Common Crawl text extraction, heuristic selection rules (e.g., to remove spam), and deduplication of repeated content.
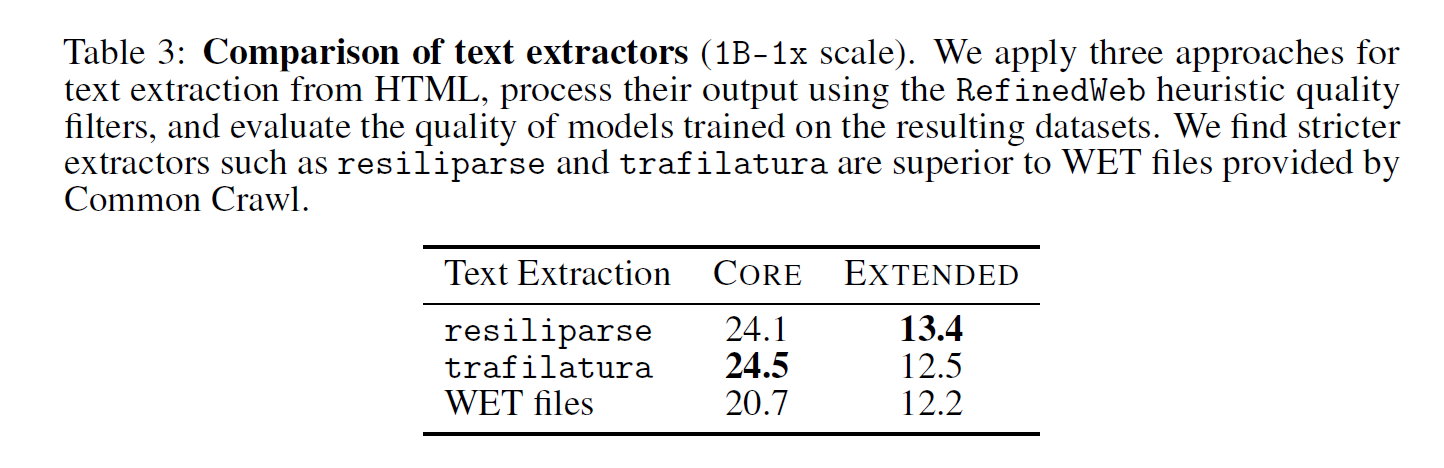
4.2 Text extraction
compare three text extraction approaches: resiliparse, trafilatura (used by RefinedWeb), and the Common Crawl-provided WET files that contain pre-extracted text.
4.3 Deduplication
we explore MinHash [28], as part of a suffix array pipeline [88, 121], and near-duplicate Bloom filtering, which modifies an exact document and paragraph deduplication scheme
modified Bloom filter approach scales more easily to datasets surpassing 10TB.

4.4 Model-based quality filtering
- PageRank score filtering
- Semantic Deduplication (SemDedup)
- linear classifiers fit on pre-trained BGE text embeddings
- AskLLM
- Perplexity filtering where we retain low perplexity sequences following CCNet [170]
- Top-k average logits
- fastText [81] binary classifiers to distinguish data quality.
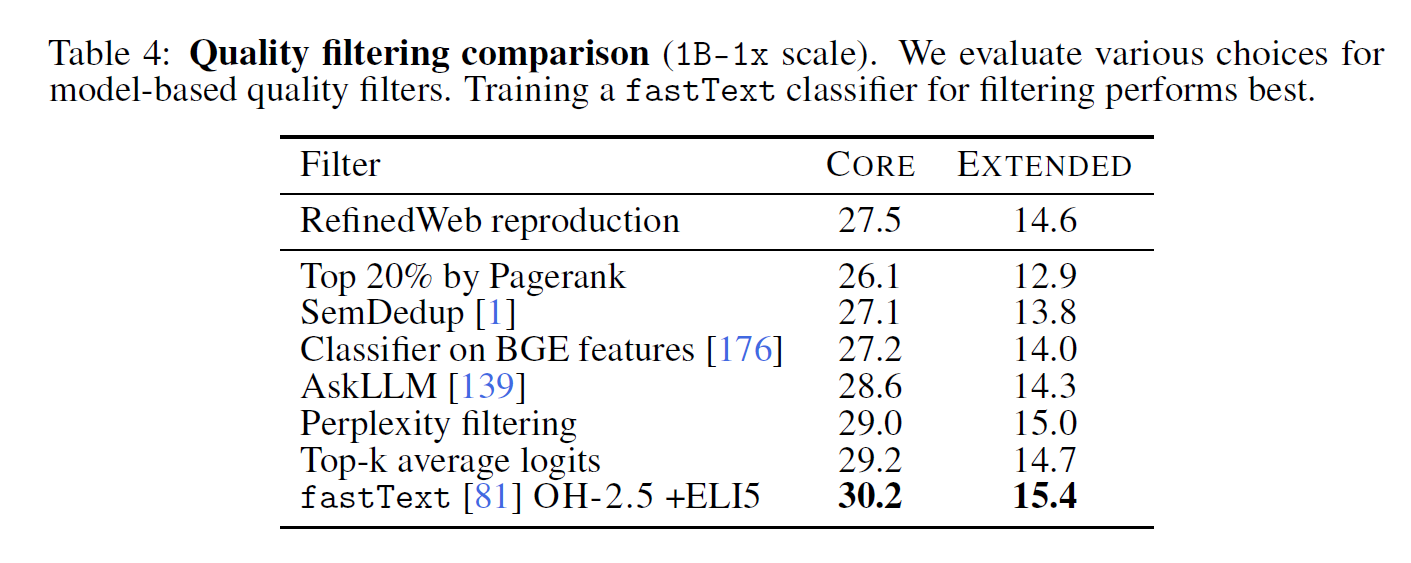
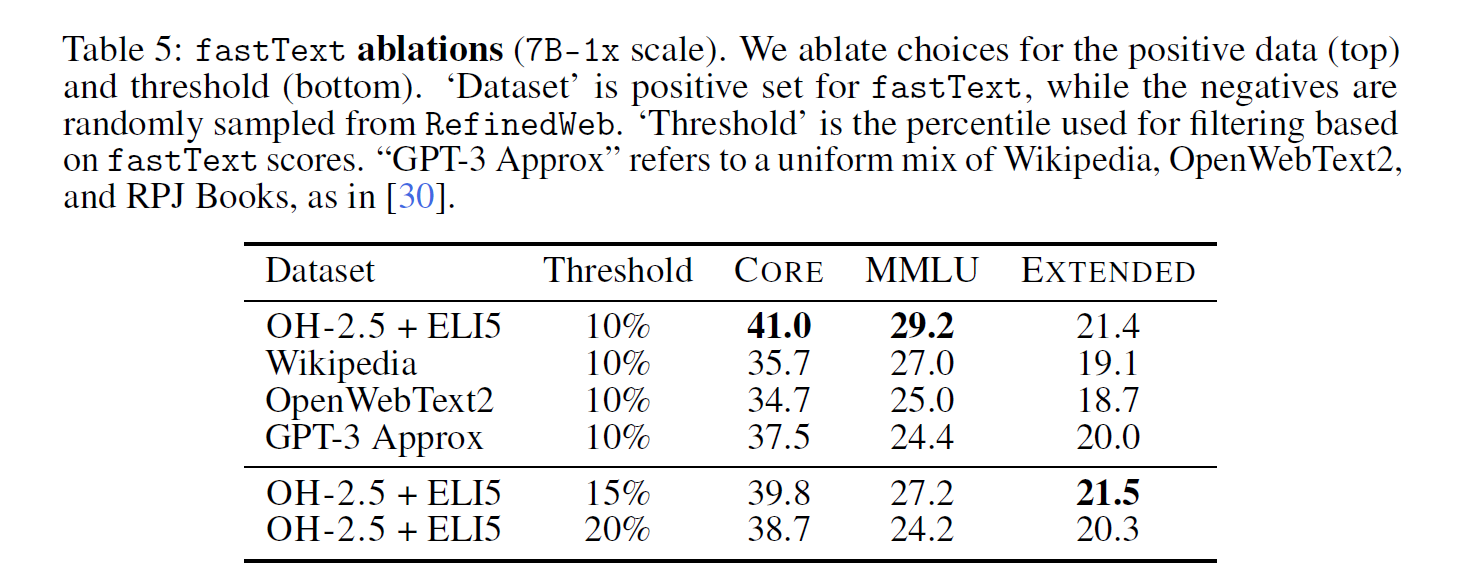
We also try a novel approach, using instruction-formatted data, drawing examples from OpenHermes
2.5 [157] (OH-2.5) and high-scoring posts from the r/ExplainLikeImFive (ELI5) subreddit.
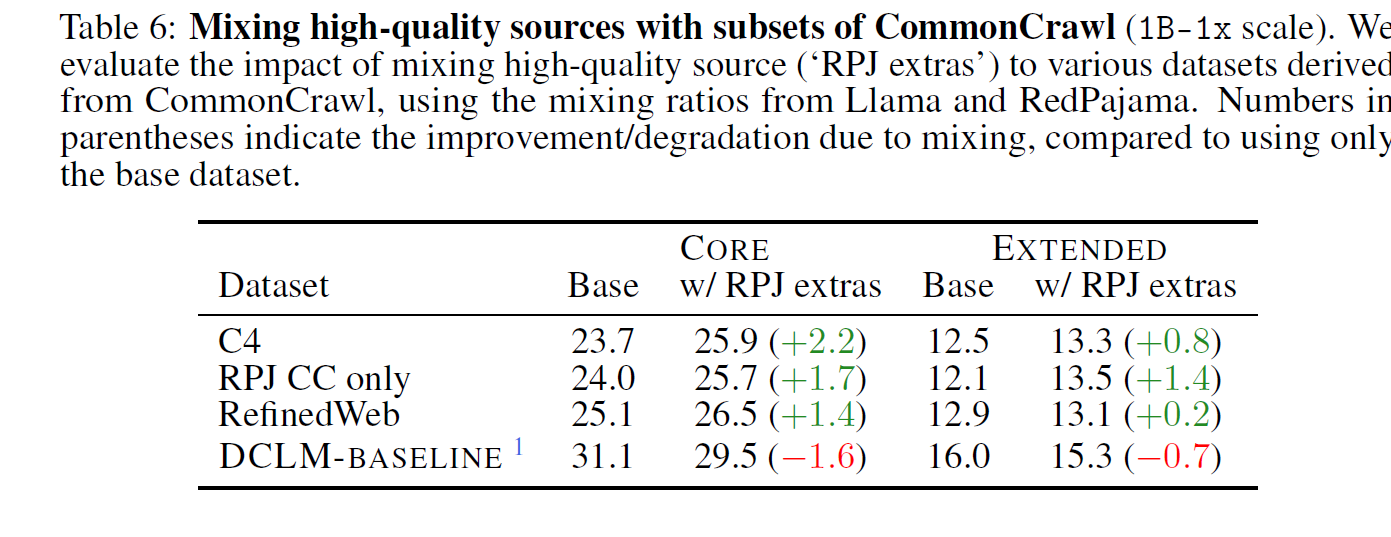
4.5 Dataset mixing
4.6 Decontamination

5 Scaling up DCLM-BASELINE to the trillion token scale



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









