







DESIGNER: Design-Logic-Guided Multidisciplinary Data Synthesis for LLM Reasoning
Authors: Weize Liu, Yongchi Zhao, Yijia Luo, Mingyu Xu, Jiaheng Liu, Yanan Li, Xiguo Hu, Yuchi Xu, Wenbo Su, Bo Zheng
Deep-Dive Summary:
DESIGNER:设计逻辑引导的多学科数据合成用于LLM推理
摘要
大型语言模型(LLMs)在许多自然语言任务中取得了显著的成功,但在复杂、多步骤推理方面仍面临挑战,尤其是在跨学科领域。现有的推理数据集往往缺乏学科广度或结构深度,无法引发强大的推理行为。我们提出了DESIGNER:一个设计逻辑引导的推理数据合成管道,利用自然可获得的、广泛的原始文档(书籍语料库和网络语料库)生成多学科挑战性问题。我们方法的核心创新是引入了**设计逻辑(Design Logic)**概念,模拟人类教育者创建问题的过程。我们使用LLMs对来自不同学科的超过12万个现有问题进行逆向工程和抽象,提取出设计逻辑。通过将这些设计逻辑与学科源材料匹配,我们能够创建出远远超过现有数据集难度和多样性的推理问题。基于这一管道,我们合成了两个大规模推理数据集,涵盖75个学科:Design-Logic-Reasoning-Book (DLR-Book),包含从书籍语料库合成的304万个挑战性问题;Design-Logic-Reasoning-Web (DLR-Web),包含从网络语料库合成的166万个挑战性问题。我们的数据分析表明,通过我们的方法合成的题目比基准数据集中的题目具有更高的难度和多样性。我们通过对Qwen3-8B-Base和Qwen3-4B-Base模型进行SFT实验,验证了这些数据集的有效性。结果显示,我们的数据集显著优于同等规模的现有多学科数据集。使用完整数据集进行训练进一步使模型超越了官方Qwen3-8B和Qwen3-4B模型的多学科推理性能。
1 引言
大型语言模型(LLMs)在多种自然推理任务中展示了卓越的能力(Brown 等人,2020;Kaplan 等人,2020;Hoffmann 等人,2022;Chowdhery 等人,2023;OpenAI,2023),例如数学和编程,尤其是在使用长链式思维(CoT)技术时(Guo 等人,2025;Moshkov 等人,2025;Cai 等人,2025)。然而,它们在广泛的大学级别学科特定推理问题上的表现仍然不及人类专家。一个主要的瓶颈是缺乏大规模、高质量且多样化的多学科推理数据。现有的数据集主要集中在数学和编程上,通过从数学和编程竞赛平台收集问题来训练模型(Moshkov 等人,2025;Cai 等人,2025)。这种方法严重依赖于这些特定领域的大量开放问题资源,但许多其他学术学科缺乏如此丰富的资源,这限制了大型语言模型多学科推理能力的发展。
目前从现有大型语言模型生成的问题合成方法(Wang 等人,2023;Xu 等人,2023;Jung 等人,2025;Havrilla 等人,2025)可以大致分为以查询为中心和以文档为中心两种方法。以查询为中心的方法以初始“种子”问题池为核心,迭代演化现有问题,通过改写现有问题、增加约束(例如 Evol-Instruct)或引入思维链(Wang 等人,2023;Xu 等人,2023;Yu 等人,2025)生成更复杂和多样化的新问题。然而,生成问题的广度和深度受到初始种子池质量和覆盖范围的严重限制,同时也容易受到生成模型自身偏见的影响,难以超越领域限制并在广泛学科中创建高质量问题。相比之下,以文档为中心的方法从大量非结构化(例如网页、书籍)或结构化(例如知识图谱)文档开始(Yue 等人,2024;Yuan 等人,2025;Huang 等人,2025)。通过直接从这些文档中提取或推理出问题-答案对,这种方法确保合成数据与特定领域知识和事实紧密相关,理论上能够覆盖更广泛的学科。这些方法的主要挑战是如何有效控制生成问题的难度和多样性,防止其退化为简单的表面事实回忆任务。
为了解决这些问题,如图 1 所示,我们提出了 DESIGNER:一种由设计逻辑引导的推理数据合成方法,利用大规模文本语料(书籍语料和网络语料)合成大量多学科挑战性问题。我们方法的核心创新在于引入了一个新颖的概念:“设计逻辑”。我们观察到,当人类教育专家设计具有挑战性和深刻见解的问题时,他们并不仅仅是陈述事实,而是遵循一个结构化的设计过程,例如:识别关键知识点 → 构建场景 → 设计推理路径 → 预设干扰项。我们认为这一过程体现了一种“设计逻辑”:一系列有意的步骤,将基础知识点转化为复杂、情境丰富的问题,要求深入推理。因此,我们的流程不仅限于直接从文档中提取问题,而是首先使用强大的大型语言模型从各种学科的现有高质量问题库中逆向工程并抽象出数万种“元设计逻辑”。在合成阶段,我们精确匹配最合适的设计逻辑,以构建全新的问题。
具体而言,我们的方法遵循一个精细的流程。首先,我们通过多维度标注和过滤(例如按学科、可读性和知识价值)对大规模书籍语料和网络语料进行全面处理,构建覆盖广泛学科的高质量源材料库。接下来,从包含数亿问题的一个私人问题库中,我们使用聚类和采样选择一个既困难又多样化的子集问题。然后,我们指导一个强大的大型语言模型从这个子集中总结和抽象出超过 120,000 种结构化的“设计逻辑”。在问题合成阶段,我们开创了一种两阶段的“检索与生成”匹配机制。首先,我们使用向量相似性从设计逻辑库中为每个源文档检索一组粗粒度的最相关候选逻辑。然后,大型语言模型进行细粒度评估,选择最佳逻辑,并严格按照该设计逻辑的步骤应用于源文档内容,生成一个新的具有挑战性的推理问题。
本文的主要贡献可以总结如下:
- 我们提出了一个从原始文本语料合成挑战性问题的数据工程流程。基于此流程,我们构建了两个大规模推理数据集:Design-Logic-Reasoning-Book (DLR-Book),包含从书籍语料合成的 304 万个挑战性问题,以及 Design-Logic-Reasoning-Web (DLR-Web),包含从网络语料合成的 166 万个挑战性问题。这些数据集扩展了数学等常见学科,覆盖了 75 个学科(包括 STEM、人文、社会科学、艺术以及应用和专业领域),以更好地训练大型语言模型的多学科推理能力。
- 我们引入了一种基于“设计逻辑”的新颖、可扩展的数据合成范式,模仿人类专家在问题创建中的智慧,显著提升了以文档为中心合成问题的推理深度和多样性。我们的数据分析表明,通过我们方法合成的问题在难度和多样性上明显优于基线数据集中的问题。
- 我们在 Qwen3-8B-Base 和 Qwen3-4B-Base 模型(Yang 等人,2025a)上进行的全面比较和消融实验表明,使用我们的数据进行训练不仅显著提高了模型的多学科推理能力,而且在相同数据量下优于现有的多学科数据集。使用我们的完整数据集进行训练后,所得模型的性能超过了同等规模的官方 Qwen3 模型。
2 概述
我们提出了一种数据工程流水线,用于从原始文本语料(网络语料和书籍语料)中合成具有挑战性的问题。完整的流水线如图1所示。
第一阶段涉及数据整理,这是一个针对我们三个主要数据源量身定制的细致过程,并在一个包含75个学科的综合分类体系下统一:
- 网络语料:我们对一个大型网络数据集应用面向推理的过滤和重新标注,仅保留对研究推理过程最有用的文本。
- 书籍语料:该语料经过预处理、学科标注和以质量为优先的采样方法,以确保选择高可读性和高帮助性的文本片段。
- 问题库:我们为问题库标注多维度标签(学科、难度、类型),并使用基于聚类的方法选择多样化且高质量的子集。
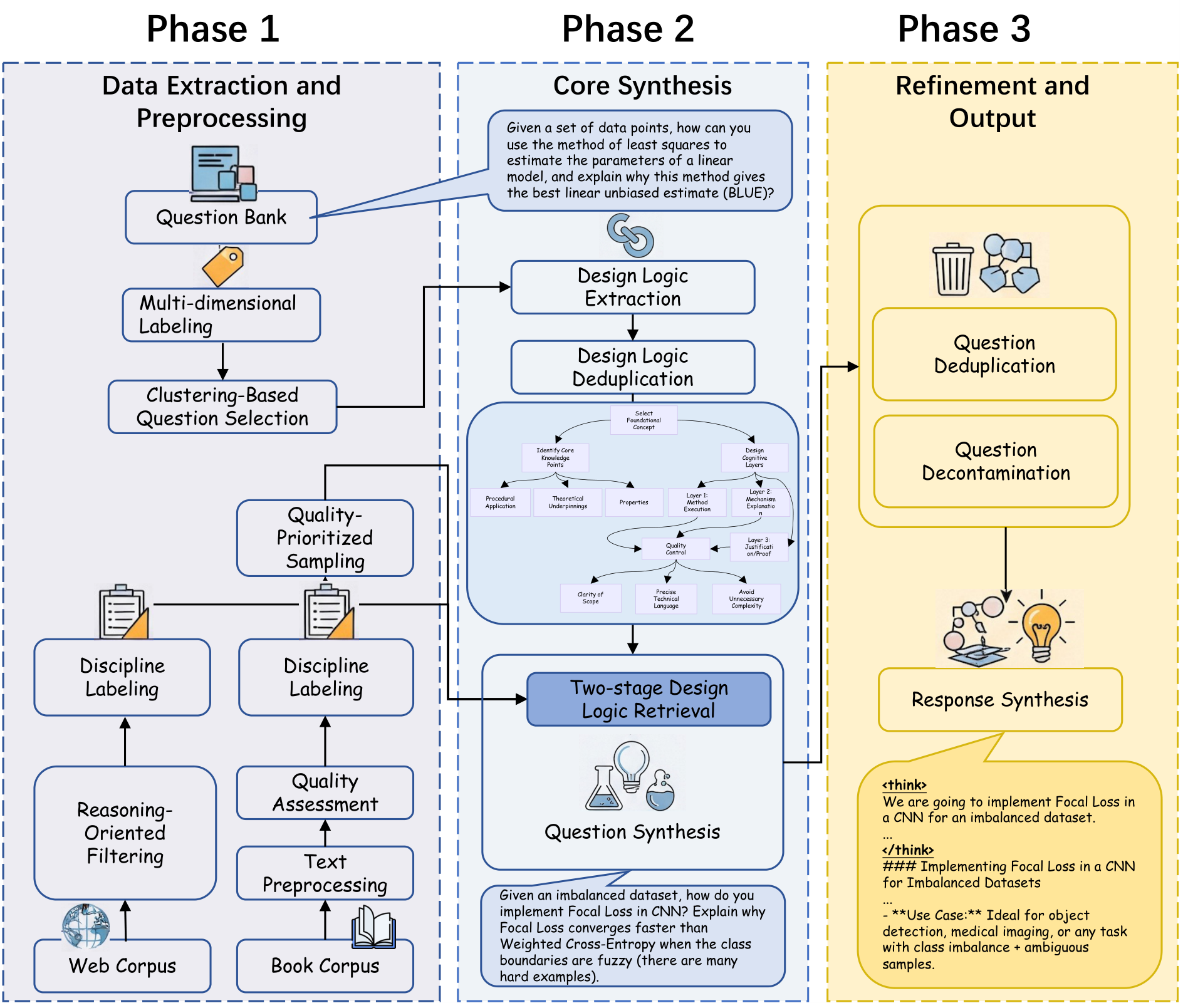
第二阶段专注于问题合成。我们首先从采样的问题子集中提取底层设计逻辑。然后,我们利用两阶段的“检索与生成”机制,将这些可重复使用的设计逻辑应用于我们整理的文本语料。这个过程使我们能够严格遵循每个逻辑的步骤,构建数百万个新的推理问题,确保它们既具有挑战性又多样化,同时反映了人类设计问题的复杂性。最后,我们为每个问题合成相应的长链式思考(CoT)答案,创建了一个有价值的监督微调数据集。
基于这一流水线,我们构建了两个大规模推理数据集:Design-Logic-Reasoning-Book (DLR-Book),包含从书籍语料中合成的304万个具有挑战性的问题;以及 Design-Logic-Reasoning-Web (DLR-Web),包含从网络语料中合成的166万个问题。这些数据集超越了数学等常见学科,覆盖了75个学科(包括STEM、人文和社会科学),从而更好地支持跨学科推理的大型语言模型(LLM)训练。此外,我们在数据集中还包含了从文本语料中与问题同时生成的简洁参考答案,以及由 Qwen3-235B-A22B-Thinking-2507-FP8 生成的长CoT响应。
3 数据整理
3.1 数据收集
我们整理了三个主要数据源,并定义了一个全面的学科分类体系:
- 网络语料:对于网络语料,我们使用了 FineFine Web?,这是 Common Crawl 数据集的一个过滤子集。
- 书籍语料:我们使用了一个专有的书籍库。
- 问题库:一个专有的考试和练习项目库。
学科分类体系:我们建立了一个包含75个不同学科的分类系统,如第13节所示。该分类体系在几个主要领域提供了全面覆盖:
- STEM:科学、技术、工程和数学。
- 人文和社会科学:包括法律、哲学和社会学等领域。
- 应用和专业领域:涵盖临床医学、教育和工商管理等领域。
- 艺术。
3.2 数据处理和过滤
论文摘要(中文)
3.2.1 题库处理
多维度标注
使用 Qwen3-30B-A3B(非思考模式),我们对自有题库中超过1.5亿道题目进行了学科、难度和类型标签的标注。具体的分类提示分别详见图3、图4和图5。



基于聚类的题目选择
为了便于提取设计逻辑,我们计划从题库中筛选出一个高质量且多样化的子集。该子集经过特别策划,以确保覆盖多个学科和不同难度级别。我们使用 Qwen3-Embedding-4B 计算嵌入向量,并在每个学科内应用 K-means 聚类(Ahmed 等人,2020)。随后,在每个学科的每个聚类中均匀抽样,通过轮廓系数搜索确定聚类数量,并根据题库的学科分布设置每个学科的样本量。此过程最终筛选出132,409道题目用于设计逻辑提取。
3.2.2 书籍语料处理
文本预处理
我们按章节级别处理每本书籍。超过5000字的章节进一步拆分为最多5000字的块。然后,我们执行 MinHash 去重,以获得最终的书籍片段。
学科标注与质量评估
我们使用经过微调的 ModernBERT-large 模型为书籍片段分配学科标签(Warner 等人,2024)。随后,我们引入了两个关键质量评估指标:可读性和帮助性。可读性由基于 BERT 的分类器预测(Turc 等人,2019),旨在过滤掉不连贯或杂乱的文本。帮助性则由 fineweb-edu-classifier 评分(Lozhkov 等人,2024),评分范围为0到5,使我们能够定量评估每个文档的教育价值。
质量优先抽样
我们从语料库中抽样了超过300万书籍片段。对于每个学科,我们根据其在书籍语料库和题库中的频率比例分配配额。为确保获取高质量数据,我们设计了质量优先的抽样策略。首先移除所有可读性被分类为负面的样本。基于帮助性评分,在每个学科内对剩余候选片段按降序排序,然后从列表顶部开始选择样本,直到达到预定配额。此过程确保所选文本是可用的最高质量,最终选定的大多数片段帮助性评分≥2。
3.2.3 网络语料处理
面向推理的过滤
由于并非所有 FineFine Web 文本都包含足够的推理内容,我们设计了一个五级评分标准(评分从0开始;提示见图6)来评估文本在研究推理过程中的潜在有用性。我们使用 Qwen3-30B-A3B(非思考模式)模型对 FineFine Web 数据集中的65亿文本进行评分,仅保留评分≥3的文本。

学科重新标注
最后,我们使用 Qwen3-30B-A3B(非思考模式)模型和图3中指定的提示对保留的文本进行重新标注,使网络语料与我们的75个学科分类体系保持一致。
4 使用设计逻辑合成问题
(此部分未提供具体内容,保留标题以保持结构完整性)
4.1 设计逻辑提取
人类教育者通常通过一系列结构化的设计决策来构建考试问题,将简单的知识概念转化为复杂且具有挑战性的问题,而不仅仅是罗列事实。一个典型的设计过程可能包括:确定目标和待测试的知识点 → 构建情境场景 → 设计逻辑推理过程 → 制定正确答案。这一过程要求解题者通过多步推理来解构问题,远远超出简单的记忆(例如,解释一个知识点)。
受此实践的启发,我们提出了一种基于“设计逻辑”的问题合成方法。利用图7中展示的提示,我们指导一个大型语言模型(DeepSeek-R1-0528)分析从我们的题库中抽样的真实问题。对于每个问题,LLM 被赋予三个关键步骤:(i) 推断问题设计者的思维过程,(ii) 分析问题是如何从相关知识点构建的,(iii) 抽象并总结底层的设计逻辑和原则。我们特别要求模型将提取的抽象设计逻辑组织成 Mermaid 格式。这一过程产生了一个可重用的资源池。
这种方法消除了手动制作大量不同提示的需要,显著提高了自动化程度。它还大幅提升了 LLM 生成问题的难度和多样性,同时使问题的结构更接近人类教师设计的问题。
4.2 设计逻辑去重
为了增强提供给 LLM 的设计原则的多样性,我们进一步对提取的设计逻辑进行去重。这确保了一组多样的原则,从而有助于生成多样化的问题。对于每个学科,我们计算所有设计逻辑之间的成对语义相似度,得到一个相似度矩阵 S ′ ∈ R n × n S' \in \mathbb{R}^{n \times n} S′∈Rn×n,其中 S i j S_{ij} Sij 表示第 i i i 个和第 j j j 个设计逻辑之间的语义相似度。
算法 1 基于图的去重通过中心点选择
1: 输入:一组项目
D
=
{
d
1
,
.
.
.
,
d
n
}
D = \{d_1, ..., d_n\}
D={d1,...,dn},一个相似度矩阵
S
∈
R
n
×
n
S \in \mathbb{R}^{n \times n}
S∈Rn×n,一个相似度阈值
T
T
T。
2: 输出:一组去重后的代表性项目
R
R
R。
3:
4: 初始化一个无向图
G
=
(
V
,
E
)
G = (V, E)
G=(V,E),其中
V
=
{
1
,
.
.
.
,
n
}
V = \{1, ..., n\}
V={1,...,n} 且
E
=
∅
E = \emptyset
E=∅。
5: 初始化代表性项目集合
R
=
∅
R = \emptyset
R=∅。
6:
7: // 构建相似度图,节点为项目,边连接相似项目。
8: 对于
i
=
1
i = 1
i=1 到
n
n
n 做
9: 对于
j
=
i
+
1
j = i + 1
j=i+1 到
n
n
n 做
10: 如果
S
i
j
>
T
S_{ij} > T
Sij>T 则
11: 向
E
E
E 添加边
(
i
,
j
)
(i, j)
(i,j)。
12: 结束如果
13: 结束循环
14: 结束循环
15:
16: // 通过寻找连通分量识别重复项目的集群。
17: 令
C
←
F
i
n
d
C
o
n
n
e
c
t
e
d
C
o
m
p
o
n
e
n
t
s
(
G
)
C \leftarrow FindConnectedComponents(G)
C←FindConnectedComponents(G)。
18:
19: // 从每个集群中选择最具代表性的项目(中心点)。
20: 对于每个连通分量
C
′
∈
C
C' \in C
C′∈C 做
21: 找到
i
∗
=
arg
max
i
∈
C
′
∑
j
∈
C
′
S
i
j
i^* = \arg\max_{i \in C'} \sum_{j \in C'} S_{ij}
i∗=argmaxi∈C′∑j∈C′Sij
22: 将项目
d
i
∗
d_{i^*}
di∗ 添加到
R
R
R。
23: 结束循环
24:
25: 返回
R
R
R。
我们采用基于图的连通分量去重方法。将某个学科内的 n n n 个设计逻辑建模为一个图 G = ( V , E ) G = (V, E) G=(V,E),其中 ∣ V ∣ = n |V| = n ∣V∣=n。如果节点 i i i 和 j j j 的语义相似度 S i j ≥ T S_{ij} \geq T Sij≥T,则在它们之间添加一条无向边。这种构建形成了连通分量,每个分量代表一组相互冗余的项目。从每个连通分量 C C C 中,我们选择一个唯一的代表——与该分量内所有其他项目相似度总和最大的项目,并丢弃其余项目。完整流程详见算法 1,相似度阈值设置为 T = 0.85 T = 0.85 T=0.85。
去重后,我们共保留了 125,328 个独特的设计逻辑。各学科的具体数量见表 13。
4.3 问题合成
为了解决直接将每个设计逻辑与每个文本片段匹配所带来的计算复杂度问题(这会导致组合爆炸),我们提出了一种类似于检索增强生成(RAG)的方法。我们使用Qwen3-Embedding-4B模型,针对每个学科特定的语料库(书籍或网页),计算每个文本片段与每个设计逻辑的嵌入之间的余弦相似度,并结合任务特定的指令(见图8)。具体来说,对于文本片段 t t t和设计逻辑 d d d,我们计算 s ( t , d ) = cos ( e ( t ) , e ( d ) ) s(t, d) = \cos(e(t), e(d)) s(t,d)=cos(e(t),e(d))。然后,我们保留相似度得分最高的top-5设计逻辑作为每个文本片段的问题合成候选。
具体流程如图9所示。特别是,我们指示大型语言模型(LLM)执行以下操作:(i) 从top-5候选设计逻辑中选择最适合给定源文本的问题设计逻辑;(ii) 严格遵循相应的逻辑和步骤构建一个具有挑战性的问题。这一两阶段过程起到了一种从粗到精的排名机制。初始通过语义相似性检索top-5设计逻辑作为粗粒度的召回阶段,随后LLM选择最合适的逻辑作为细粒度的排名阶段。这一策略确保了设计逻辑与文本之间的精确匹配,显著提高了合成问题的质量。
对于每个合成的问题,我们还指示LLM基于源文本提供一个简洁的参考答案。为了便于自动化评估,特别是对于具有明确答案的问题(例如数学问题或多项选择题),我们要求LLM以特定标签格式化其最终输出。具体来说,如果问题有单一的、结论性的结果(例如数字、公式或短语),LLM必须在最后使用格式清晰地表述:“The final answer is: \boxed{answer}”。
问题去重与去污染
我们实现了一个两阶段过滤流程来管理冗余并避免评估泄露。首先,我们使用基于MinHash的检测方法去除高度相似的问题。其次,为了解决潜在的数据污染问题,我们通过将合成问题与本研究中使用的所有评估基准进行比较,对合成问题进行去污染处理。这通过标准的13-gram去污染方法实现,期间忽略非语义标点。任何被标记为相似的问题将被丢弃。
使用第3.2节中过滤后的书籍和网页语料库,我们通过DeepSeek-R1-0528为每个文本片段生成一个相应的推理问题。经过去重和去污染处理后,我们最终的推理数据集包含从书籍语料库合成的3,040,620个具有挑战性的问题,以及从网页语料库合成的1,658,541个具有挑战性的问题。
4.4 响应合成
为了证明我们合成的问题能够有效激发和转移推理模型的长链式思维(CoT)能力,并提高在这些数据上训练的模型性能,我们使用Qwen3-235B-A22B-Thinking-2507-FP8为每个合成问题生成一个相应的长CoT响应。
5 数据分析
为了开始我们的质量评估,我们进行了定量分析,比较了我们合成数据集(DLR-Book和DLR-Web)与基线数据集的复杂性和难度。分析重点包括问题类型的分布、问题和响应的长度、问题的整体难度及其多样性。
5.1 问题类型分析
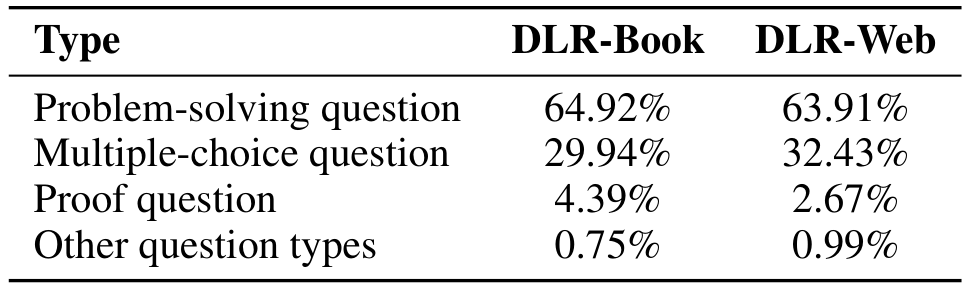
如表1所示,解决问题类问题在我们的合成数据集中占主导地位,构成了书籍语料库的64.92%和网页语料库的63.91%。多项选择题是第二常见的类型,分别占29.94%和32.43%。这一分布分析表明,我们合成问题的构成偏向于推理型问题,而非简单的回忆型问题。
5.2 数据复杂性
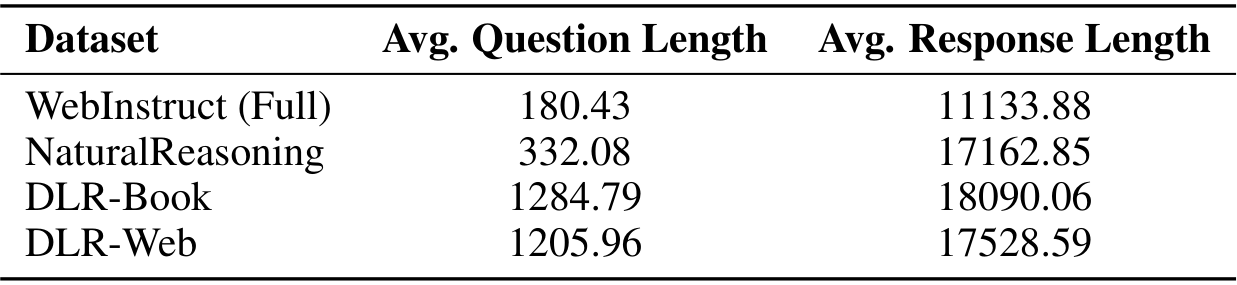
在表2中,我们比较了我们的两个合成数据集与WebInstruct (Full) 和 NaturalReasoning 的问题平均长度及其相应回答的长度。我们的数据集中的问题及其所需回答的长度明显长于WebInstruct (Full)(Yue 等人,2024)和NaturalReasoning(Yuan 等人,2025)。这一观察结果间接证明了我们合成问题的高难度和复杂性。问题长度的显著增加表明我们的合成方法生成了具有更详细背景和更复杂前提的问题,需要对输入内容有更深入的理解。我们同样观察到我们的数据集中回答长度较长,这是问题复杂性增加的直接结果。这一观察表明,解决我们合成的问题需要比基准数据集更深入的推理链。
5.3 难度分析
为了更直接地衡量难度,我们使用Qwen3-30B-A3B-Instruct-2507模型对来自我们的书籍和网络语料库以及WebInstruct (Full) 和 NaturalReasoning 的问题分配难度标签。根据所需推理的复杂性和长度,我们将问题分为四个难度级别:简单、中等、困难和非常困难。
如表3所示,我们的数据集明显更具难度。“困难”和“非常困难”问题的总百分比非常高:DLR-Book 为89.84%,DLR-Web 为83.15%。这与基准数据集形成鲜明对比。DLR-Book 包含54.66%的“非常困难”问题,远高于NaturalReasoning 的31.11%和WebInstruct (Full) 的3.59%。相反,我们数据集中“简单”问题的比例微不足道(分别为0.27%和0.72%),特别是与WebInstruct (Full) 的39.02%相比。
总体而言,这些关于问题长度和难度分布的定量分析一致表明,我们的数据合成方法生成的问题比基准数据集具有显著更高的复杂性和难度。
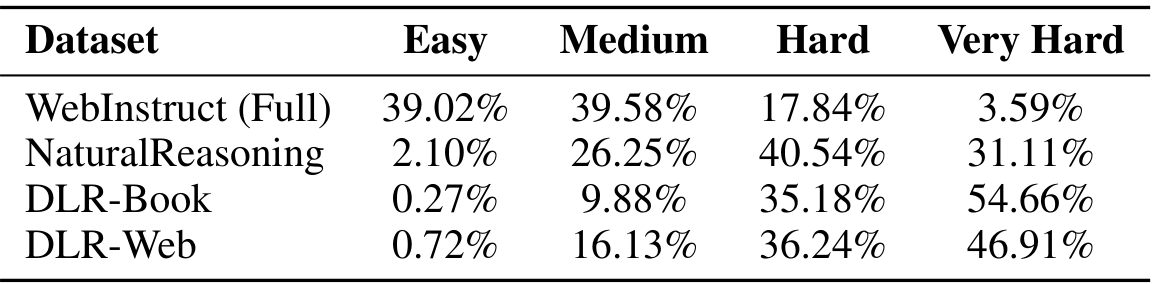
表4:我们合成数据集和基准数据集的语义多样性指标,基于每个数据集的30万个问题的统一样本计算。所有指标越高越好。

5.4 多样性分析
为了评估合成问题的语义多样性,我们使用基于距离的度量方法进行了定量分析。这种方法通过检查问题嵌入在高维语义空间中的分布来评估多样性。
多样性度量和实验设置
我们首先使用 Qwen3-Embedding-4B 模型为每个问题生成高维向量表示。对于给定的问题集
X
=
{
1
,
2
,
…
,
N
}
X = \{1, 2, \dots, N\}
X={1,2,…,N},此过程生成对应的嵌入向量集
E
=
{
e
1
,
e
2
,
…
,
e
N
}
E = \{e_1, e_2, \dots, e_N\}
E={e1,e2,…,eN},其中
e
i
∈
R
d
e_i \in \mathbb{R}^d
ei∈Rd 是问题
i
i
i 的
d
d
d 维嵌入向量。我们从每个数据集中均匀采样
N
=
300
,
000
N = 300,000
N=300,000 个问题,并在嵌入空间中计算以下五种基于距离的度量指标:
- 平均余弦距离 (DistMean Cosine) (Yang 等人,2025b):所有问题对之间的平均余弦距离,计算公式为 DistMean Cosine = 1 N ( N − 1 ) / 2 ∑ i < j ( 1 − cos ( e i , e j ) ) \text{DistMean Cosine} = \frac{1}{N(N-1)/2} \sum_{i<j} (1 - \cos(e_i, e_j)) DistMean Cosine=N(N−1)/21∑i<j(1−cos(ei,ej))。较高的值表示更大的语义差异性。
- 平均 L2 距离 (DistMean L2) (Yang 等人,2025b):所有问题对之间的平均欧几里得距离,反映问题在嵌入空间中的平均分离度。
- 1-最近邻距离 (1-NN Distance) (Stasaski & Hearst, 2022):每个问题嵌入到其最近邻的平均余弦距离。此指标突出显示是否存在紧密聚类、几乎相同的问题。
- 聚类惯性 (Cluster Inertia) (Du & Black, 2019):应用 K-means 聚类算法后,样本到其最近聚类中心的总平方距离,计算公式为 M inertia = ∑ i = 1 N min c s ∥ e i − c s ∥ 2 2 M_{\text{inertia}} = \sum_{i=1}^N \min_{c_s} \|e_i - c_s\|_2^2 Minertia=i=1∑Ncsmin∥ei−cs∥22,其中 c s c_s cs 是聚类中心。此指标衡量数据聚类的整体扩散和密度。
- 半径 (Radius) (Lai 等人,2020):嵌入维度的标准差的几何平均值,计算公式为 Radius = ( ∏ j = 1 d σ j ) 1 / d \text{Radius} = \left( \prod_{j=1}^d \sigma_j \right)^{1/d} Radius=(∏j=1dσj)1/d,其中 σ j \sigma_j σj 是第 j j j 维的标准差。此指标直接量化数据在语义空间中的扩散程度。
如表 4 所示,我们的数据集 DLR-Book 和 DLR-Web 在所有五种语义多样性指标上均表现出比基准数据集更高的多样性。较高的平均余弦距离和平均 L2 距离值证实了我们合成的问平均而言在语义上比 WebInstruct (Full) 和 NaturalReasoning 中的问题更为不同,表明其概念范围更广。最显著的差异体现在 1-NN 距离上,我们的数据集得分约为基准数据集的两倍,这表明我们的方法生成的语义冗余问题要少得多。此外,我们数据集的聚类惯性和半径得分表明,生成的问题在语义嵌入空间中占据了更大且更多样的体积。这一量化证据证实了我们的合成流程不仅生成了更复杂和困难的问题,而且还生成了明显更多样的问题集。
6 实验
在本研究中,我们通过对基础模型进行监督微调 (SFT) 来评估合成数据的有效性。生成的模型随后在一系列广泛使用的基准测试中进行评估。我们的大量实验表明,通过我们的方法合成的数据能够有效激发 LLM 在复杂、多学科问题上的长链式推理能力。此外,在相同训练数据量的情况下,我们的方法相较于 NaturalReasoning 和 WebInstruct (Full) 等现有数据集,展现出更优的模型性能。
6.1 实验设置
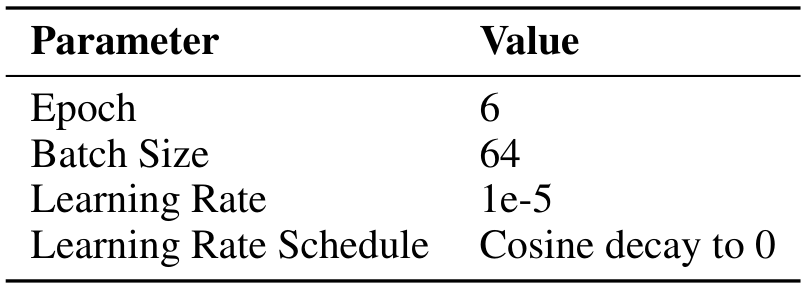
SFT设置:在大部分实验中,我们对 Qwen3-8B-Base 模型进行监督微调(SFT)。随后,我们还验证了合成数据在其他模型规模上的有效性。所有 SFT 实验均遵循表 5 中详细列出的超参数设置。
评估设置:为了确保公平比较,我们对所有训练模型采用零样本评估设置,并使用表 6 中指定的统一生成配置。对每个基准测试,我们为每个测试实例进行 N 次独立的采样滚动。评估涉及以下三个指标:
- Pass@1:N 次滚动中的平均准确率(%)。我们报告 Pass@1 分数及其标准差,以展示方法的性能和稳定性。
- CoT-sC:通过对 N 个生成样本的多数投票确定的准确率(%)。此指标等同于带思维链的自我一致性(CoT-SC)方法,并在 N > 1 的情况下报告。
- Pass@N:在 N 次滚动中至少找到一个正确解决方案的问题比例(%)。

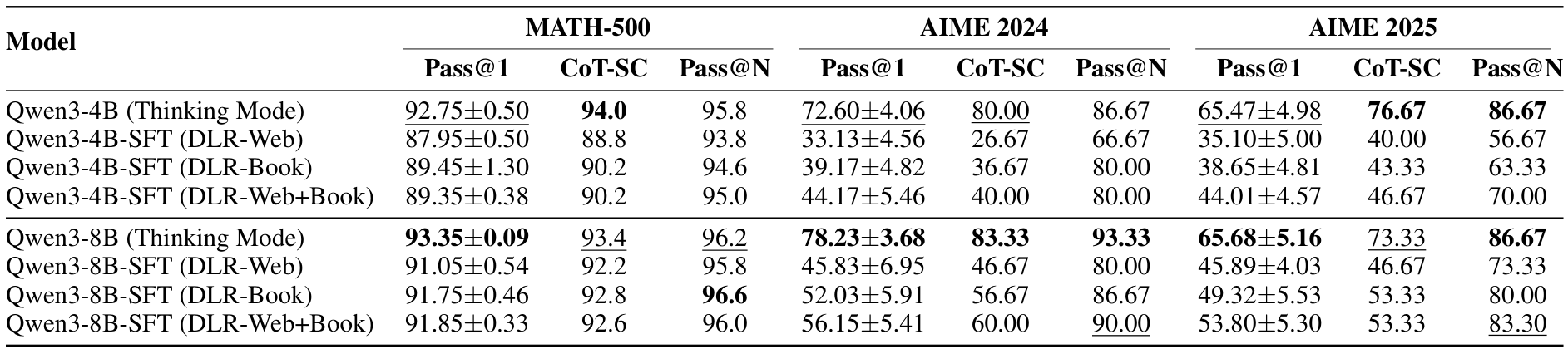
基准测试:我们评估中使用的基准测试及其各自的学科和滚动次数(M)在表 7 中详细列出。
6.2 监督微调实验
我们使用合成数据集 DLR-Book 和 DLR-Web 对 Qwen3-4B-Base 和 Qwen3-8B-Base 模型进行了监督微调(SFT)。随后,将得到的 SFT 模型与官方的 Qwen3-4B 和 Qwen3-8B 模型(思维模式)在我们的评估设置下进行比较。
如表 8 所示,使用我们的合成数据集进行监督微调显著提升了模型性能。Qwen3-8B(思维模式)在所有推理基准测试中均表现优于基准线。值得注意的是,使用组合数据集训练的模型取得了第二好的成绩。这种改进在高度复杂的推理任务(如 GPQA-Diamond)上尤为显著。这些结果证实了我们的数据合成策略在增强语言模型推理能力方面的有效性。
6.3 高级数学推理性能
在针对具有挑战性的数学竞赛问题(如 AIME 的问题)的研究中,我们额外报告了 Pass@N 的结果。研究表明,类似带有可验证奖励的强化学习(RLVR)的方法主要通过更好地选择已有的推理路径来提升 Pass@1 的准确率,而对 Pass@N 的提升并不显著(Yue 等人,2025)。由于我们仅使用监督微调(SFT)而未进行后续的强化学习(RL)阶段,因此我们的模型在 Pass@1 上的得分相对较低是预料之中的。然而,我们微调模型在 Pass@N 上的显著提升值得关注。这一结果表明,我们的数据成功引入了新的推理模式,从而扩展了模型的解题空间并增强了其解决问题的潜力。这种扩展的能力为未来通过强化学习将这些推理技能转化为更高的 Pass@1 性能奠定了坚实的基础。
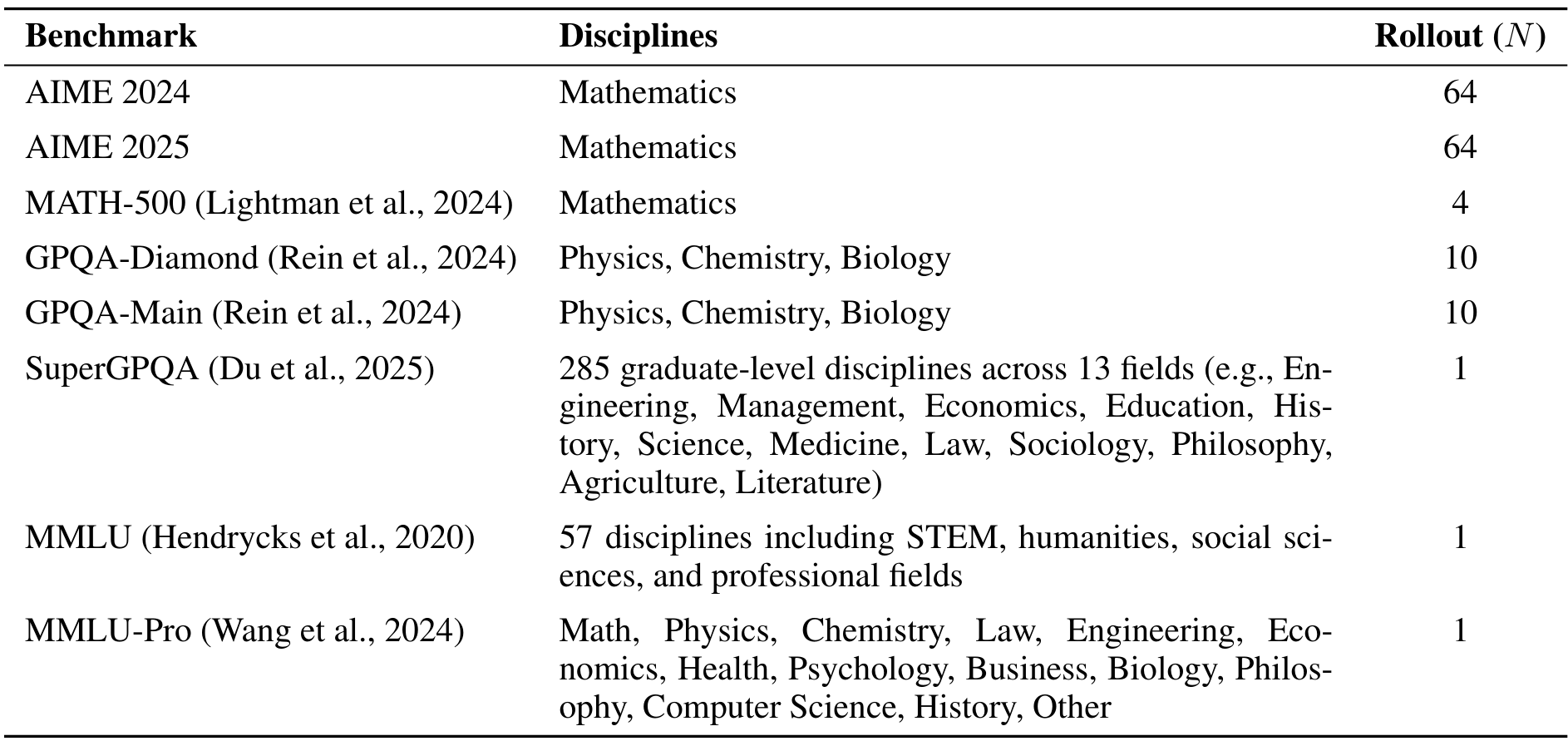
表 8:在我们数据集上微调的模型性能。模型在 DLR-Web、DLR-Book 或组合数据集 DLR-Web+Book 上进行训练。基线模型包括官方的 Qwen3-4B 和 Qwen3-8B 模型(思考模式),并在我们的设置下进行评估。每一列中的最佳和次佳成绩分别以粗体和下划线显示。
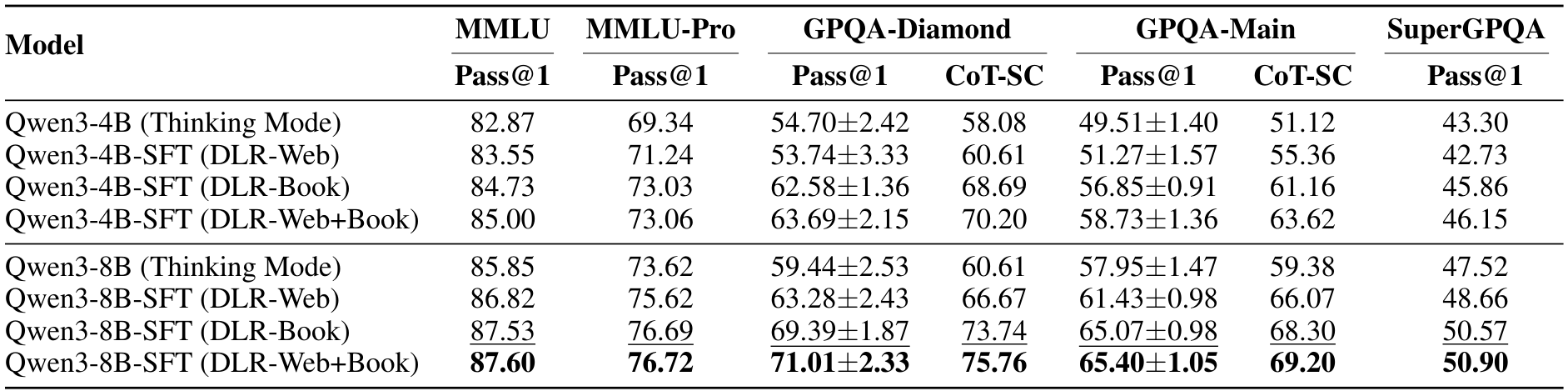
表 9:数学推理基准测试的性能,包括 Pass@N 结果。每一列中的最佳结果以粗体显示,次佳结果以下划线标注。在 DLR-Web+Book 上训练的模型在 Pass@N 上表现出显著改进,表明其推理能力得到了扩展。
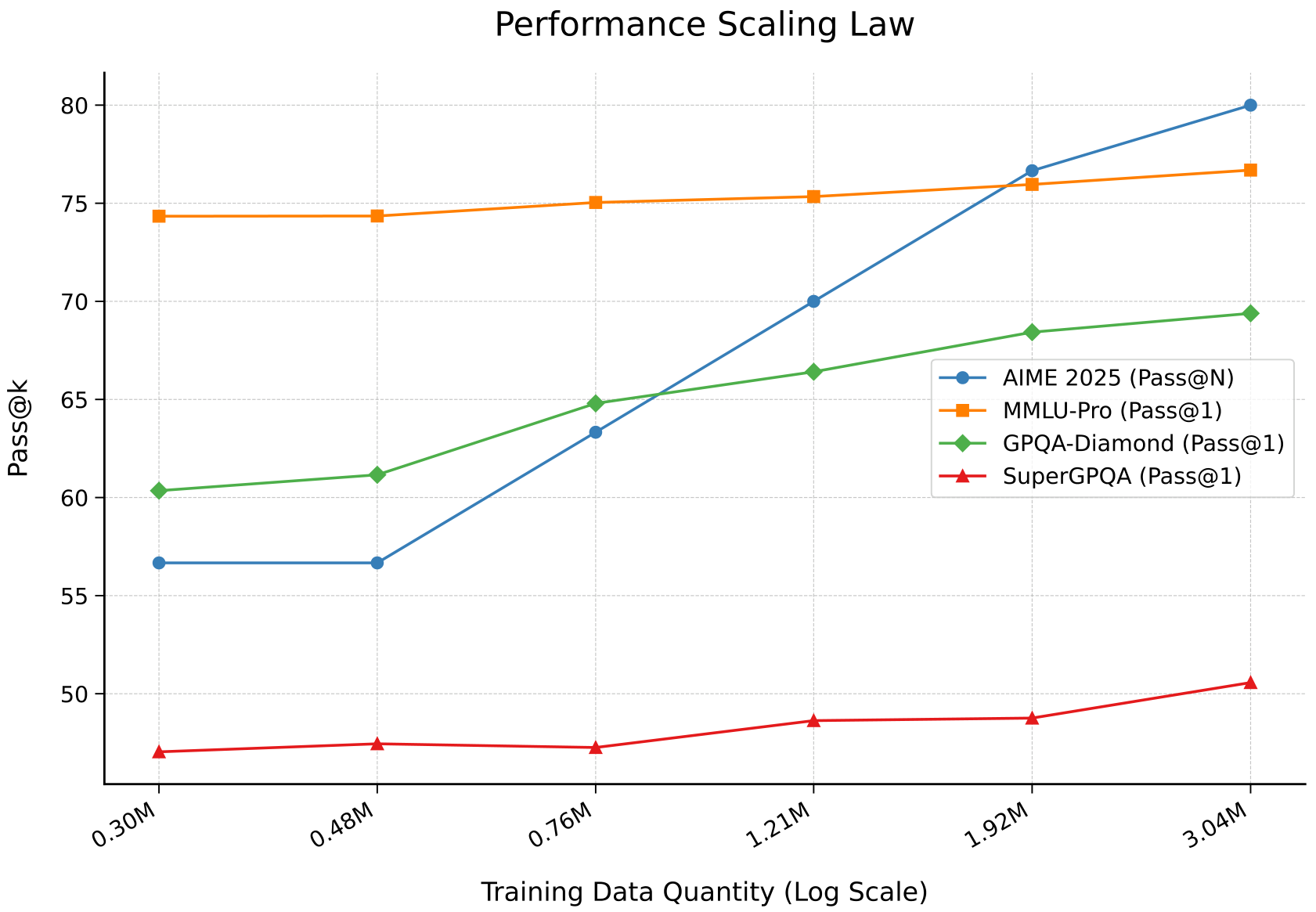
6.4 数据规模效应
为了验证我们数据合成方法的可扩展性,我们进行了一系列实验,评估在逐渐增大的合成数据集上训练的模型的推理能力。结果如图 2 所示,合成数据量与模型在多个具有挑战性的推理基准测试中的性能之间呈现出明显的正相关。
在这一多样化的基准测试集上的一致改进表明,我们的合成过程并未过拟合到特定领域或基准测试,而是增强了通用的、稳健的推理能力。这些强大的规模法则证实了我们的方法通过持续改进数据提供了一条可靠的途径,以实现卓越的模型性能。
6.5 与基线数据集的比较
我们对我们的合成数据与其他知名的开源合成数据集进行了比较分析。为了确保公平比较,考虑到原始数据集的大小不同,我们从每个数据集中随机抽取了相同数量的 304,181 个实例用于微调实验。为了公平比较的目的,我们使用相同的 Qwen3-235B-A22B-Thinking-2507-FP8 模型为所有基线方法(包括 WebInstruct(Full)和 NaturalReasoning)重新生成了长链式推理(CoT)响应。
如表 10 所示,我们的 Design-Logic-Reasoning 数据集在所有基准测试中始终优于 WebInstruct(Full)和 NaturalReasoning。具体而言,DLR-Book 在 MMLU、MMLU-Pro 和 GPQA-Diamond 上取得了最佳结果,而 DLR-Web 在 SuperGPQA 上表现最佳,并在其他基准测试中位居第二。这些结果验证了我们的数据生成方法相较于现有方法的卓越质量和有效性。
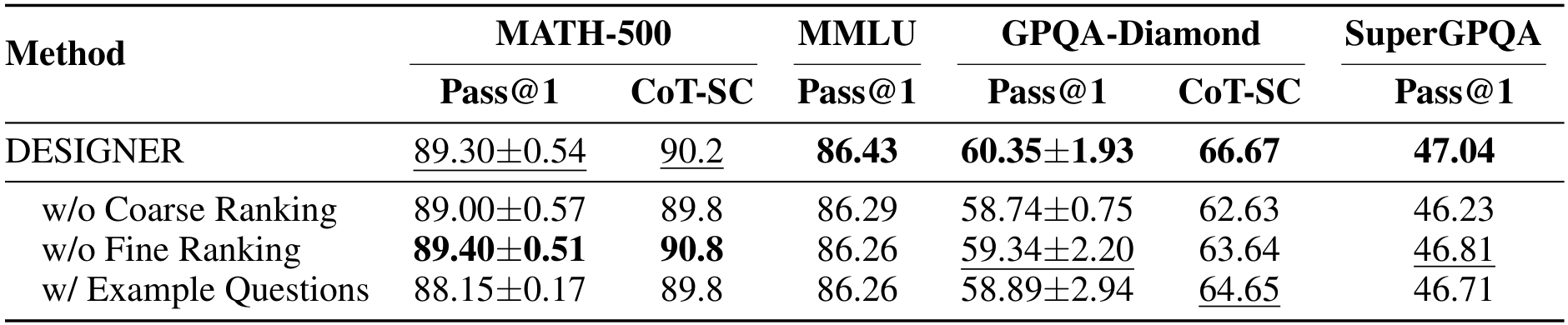
6.6 消融研究
我们在问题合成流程上进行了消融研究,以量化两个关键组成部分的贡献:设计逻辑与语料片段之间的粗到细匹配,以及明确设计逻辑的使用。为了确保公平比较,所有消融实验都从相同的书籍语料库中合成问题,通过均匀采样304,181个文本片段进行。在适用的情况下,我们使用了相同的检索模型Qwen3-Embedding-4B,并使用相同的生成模型Qwen3-235B-A22B-Thinking-2507-FP8生成模型响应。
- 无粗糙排名(w/o Coarse Ranking):此设置绕过了基于语义相似度的检索前5个相关设计逻辑的步骤。取而代之的是,提示大型语言模型(LLM)从一组随机选择的5个逻辑中挑选最合适的逻辑。
- 无精细排名(w/o Fine Ranking):此设置去除了基于LLM的重新排名阶段。直接使用粗糙检索结果中最相似的一个设计逻辑(即前1结果)来生成问题。
- 使用示例问题(w/ Example Questions):此设置替代了我们对抽象设计逻辑的使用。LLM不再受逻辑指导,而是通过模仿最合适的示例问题的风格和结构来生成新问题。该示例是从从问题库中检索的5个相关示例问题中选择的。
- DESIGNER:这是我们的完整方法,包括通过相似度进行粗糙检索前5个设计逻辑,随后基于LLM的精细选择并基于“设计逻辑”进行合成。
表11总结了我们的消融研究结果。我们的完整“DESIGNER”方法在大多数基准测试中始终优于消融配置。去掉粗糙检索(w/o Coarse Ranking)或精细排名(w/o Fine Ranking)都会导致性能下降,证实了我们两步匹配过程中每个阶段的价值。特别是在MATH基准测试中,“无精细排名”配置表现良好,表明初始检索在识别相关逻辑方面非常有效。然而,其他基准测试的一致改进验证了完整粗到细流程在处理复杂、多学科推理方面的益处。最后,设计逻辑相较于具体的“示例问题”的优越性能证实了我们的假设,即明确的逻辑结构是高质量问题合成的更准确和稳健的指导。
表11:我们数据合成流程的消融研究。所有实验都在Qwen3-8B-Base模型上进行,使用从相同书籍语料库合成的数据。每列的最佳结果以粗体表示,次佳结果以下划线表示。
6.7 源语料质量对合成数据的影响
普遍认为书籍语料库的质量高于网络语料库。为了测试源语料质量如何影响我们的数据合成方法,我们进行了一项受控的SFT实验。我们比较了从书籍语料库和网络语料库(FineFine Web)合成的数据,两者数据分布完全相同。对于FineFine Web语料库中数据有限的学科,我们使用了所有可用实例。对于其他学科,我们采用随机采样。这一过程最终生成了两个大小相等(各282,857个实例)且按学科分布相同的最终数据集。
如表12所示,结果验证了我们的假设。基于书籍语料库微调的模型在几乎所有基准测试中始终优于基于网络语料库训练的模型。这表明我们的合成方法受益于更高质量的源材料。然而,我们的方法也证明了对初始语料质量的鲁棒性,表明我们的方法能够有效合成高质量问题以提升模型性能,无论初始语料质量如何。

7 相关工作
查询中心的数据合成
查询中心的数据合成的核心思想是通过迭代扩展或演化现有的查询池来生成新的训练数据。Self-Instruct(Wang 等人,2023)从现有查询池中抽样问题,并利用大型语言模型(LLM)生成新的问答对,随后用于微调模型。Wizard LM(Xu 等人,2023;Luo 等人,2025;Luo 等人,2024)和Auto Evol-Instruct(Zeng 等人,2024)采用指令进化方法,生成更复杂和多样化的数据。CoT-Self-Instruct(Yu 等人,2025)将CoT推理机制整合到指令生成过程中,通过“先思考后生成”的方式提升合成数据的质量。Prismatic Synthesis(Jung 等人,2025)将数据多样性的定义从表面的文本特征推向更基础的模型行为层面,旨在最大化模型诱导梯度的多样性。SPARQ方法(Havrilla 等人,2025)引入了一个评估数据合成中多样性和难度的框架,认为高难度数据能提升分布内性能,而多样性则增强分布外泛化能力。尽管这些查询中心的方法试图优化合成数据的难度和多样性,但它们仍然受限于初始查询池和用于合成的模型的分布偏差,难以覆盖跨学科的问题。
文档中心的数据合成
文档中心的数据合成方法从大量的非结构化(例如,CC、书籍)或结构化(例如,知识图谱)文本数据入手,通过直接从文档中提取或推断生成问答对,从而确保合成数据与特定领域知识和事实密切相关。UltraChat(Ding 等人,2023)从Wikidata等知识来源和人类专家预定义的元主题(例如,技术、健康)中生成关于世界知识的问题。Humpback(Li 等人,2024)同样使用大型网络语料作为数据源,训练一个“反向模型”来推断可能导致给定文档的指令。KPDDS方法(Huang 等人,2025)基于提取的主题和知识点构建主题级共现概率矩阵(TCPM),通过从该矩阵中采样指导数据合成。MAmmoTH2(Yue 等人,2024)通过三步“回忆-提取-精炼”流程直接从现有网络内容中挖掘高质量问题,但其提取问题的难度较低。NaturalReasoning(Yuan 等人,2025)也从大规模预训练语料中合成数据,但其过程更专注于生成高难度的推理问题,尽管其合成问题的多样性受到单一提示的限制。我们的工作独特地引入了设计逻辑的概念,将文档中心的数据合成过程类比为人类教师创建问题的过程,通过将文档与合适的设计逻辑匹配,显著提升了合成问题的难度和多样性。
推理数据合成
使用合成的长链式推理(CoT)数据进行数据蒸馏是提升小型模型推理能力的有效方式。DeepSeek(Guo 等人,2025)通过DeepSeek-R1生成的高质量数据样本蒸馏出一系列较小的开源模型,显著增强了这些小型模型的推理能力。OpenMathReasoning(Moshkov 等人,2025)从在线数学论坛(AoPS)中提取高质量数学问题,并利用现有的强大模型为这些问题生成长CoT响应,显著提升了模型的数学能力。OmniThought(Cai 等人,2025)从数学、代码和科学领域收集问题,并基于多个教师模型生成长CoT数据集。然而,这些方法主要集中在为现有问题生成高质量的推理过程,而开源社区仍然缺乏高质量、跨学科的原创问题。相比之下,我们的方法专注于利用自然可用的跨学科文档,通过引入设计逻辑合成难度高且多样化的跨学科问题。
8 结论
本文介绍了 DESIGNER,一种新颖的基于设计逻辑的数据合成流程,旨在解决大型语言模型(LLMs)在多学科推理数据方面的稀缺问题。我们的核心创新在于“设计逻辑”的概念,通过这些逻辑,我们生成了两个大规模数据集 DLR-Book 和 DLR-Web,包含了来自不同原始文本来源的75个学科的数百万复杂问题。我们的合成问题被证明比现有方法的问题显著更困难且多样化,超越了简单的 factual recall(事实回忆),需要深入的多步骤推理。我们通过广泛的实验验证了我们方法的有效性,证明使用我们的数据进行微调的模型在多学科推理方面取得了显著的性能提升。具体来说,使用我们数据集训练的模型不仅优于使用同等规模现有多学科数据集微调的模型,而且在多学科推理性能上还能超越同等规模的官方 Qwen3 模型,验证了我们方法的有效性。这项工作为创建多样化和具有挑战性的推理数据提供了一个可扩展的范式,为推动 LLMs 的推理能力超越特定领域任务开辟了新路径。
B 提示
学科分类提示
您是一名专业的多学科数据标注专家,专门从事多学科学术问题的分类。对于您无法确定的问题数据,请使用“Unknown Discipline”(未知学科)标签。请直接输出“labels”: “(您选择的标签)”。
学科标签列表:
[‘Mathematics’, ‘Biology’, ‘Chemistry’, ‘Physics’, ‘Computer Science and Technology’, ‘Philosophy’, ‘Psychology’, ‘Business Administration’, ‘Clinical Medicine’, ‘Economics’, ‘Law’, ‘Political Science’, ‘Statistics’, ‘Electrical Engineering’, ‘Geography’, ‘Mechanical Engineering’, ‘Basic Medicine’, ‘Information and Communication Engineering’, ‘Sociology’, ‘Materials Science and Engineering’, ‘Pharmacy’, ‘Bioengineering’, ‘English and Foreign Languages’, ‘Chemical Engineering and Technology’, ‘Electronic Science and Technology’, ‘Education’, ‘Geophysics’, ‘Art and Design’, ‘Agricultural Engineering’, ‘Aerospace Science and Technology’, ‘Atmospheric Sciences’, ‘Chinese Language and Literature’, ‘Civil Engineering’, ‘Ecology’, ‘Geology’, ‘Nursing’, ‘Optical Engineering’, ‘Public Administration’, ‘Journalism and Communication’, ‘Physical Education’, ‘Marine Sciences’, ‘Safety Science and Engineering’, ‘Architecture’, ‘Transportation Engineering’, ‘Power Engineering and Engineering Thermophysics’, ‘Food Science and Engineering’, ‘Archaeology’, ‘Biomedical Engineering’, ‘Chinese History’, ‘Veterinary Medicine’, ‘Instrument Science and Technology’, ‘Hydraulic Engineering’, ‘Stomatology’, ‘Urban and Rural Planning’, ‘Petroleum and Natural Gas Engineering’, ‘Naval Architecture and Ocean Engineering’, ‘Surveying and Mapping Science and Technology’, ‘History of Science and Technology’, ‘Agricultural Resources and Environment’, ‘Remote Sensing Science and Technology’, ‘Information Resources Management’, ‘Mining Engineering’, ‘Forensic Medicine’, ‘Ethnology’, ‘Textile Science and Engineering’, ‘Geological Resources and Geological Engineering’, ‘Animal Husbandry’, ‘Other’, ‘Non-disciplinary’, ‘Unknown Discipline’]
示例 1
论文摘要(中文)
以下是对所提供学术论文片段的中文总结,保留了原文中的图片部分及其格式,并按照原文结构组织内容。
示例问题与分类
示例 1
输入问题:考虑一个以光速行进的光子。光子如何体验空间?相对论束效应对其空间维度的感知有何影响?请提供详细解释,包括相关的数学推导和物理原理。
总结:这个问题涉及光子在光速下的空间感知以及相对论束效应的影响,要求深入理解相对论物理学,并进行数学推导,难度较高。
示例 2
输入问题:一根重杆,质量为
M
M
M,长度为
L
L
L,一端自由铰接在墙上的点
O
O
O 处。另一端通过绳子连接到墙上点
O
O
O 上方的固定点
A
A
A。系统处于平衡状态,杆与水平面夹角为
θ
\theta
θ,绳子与水平面夹角为
α
\alpha
α。探讨系统参数 (
M
M
M,
L
L
L,
θ
\theta
θ,
α
\alpha
α) 如何影响其平衡和稳定性。
总结:这个问题要求分析一个力学系统的平衡和稳定性,涉及多个参数的相互作用,需要运用力学原理和数学分析,难度较高。
示例 3
输入问题:如果约翰租了一辆车,租金为 150 美元,并需要购买 8 加仑汽油,每加仑 3.50 美元来加满油箱,且每英里费用为 0.50 美元,那么他驾驶 320 英里总共花费了多少钱?
总结:这是一个简单的计算问题,涉及基本的算术运算,难度较低。
学科分类提示
图表 3:用于学科分类的少样本提示。模型会看到一系列学科和三个示例,然后被要求对给定的问题进行分类,问题将替换 {text} 占位符。

难度分类提示
难度分类说明:你是一名教育和考试专家,专门从事多学科问题的难度分类。对于给定的问题,请根据回答所需的推理复杂性和长度评估其难度,并将其标记为:简单、中等、困难 或 非常困难。直接输出“Difficulty: (你选择的标签)”。
以下为难度分类示例:
- 示例 1:光子空间感知问题,输出为“Difficulty: Very Hard”(非常困难)。
- 示例 2:重杆平衡问题,输出为“Difficulty: Hard”(困难)。
- 示例 3:租车费用问题,输出为“Difficulty: Easy”(简单)。
图表 4:用于难度分类的少样本提示。模型会看到三个示例,然后被要求对给定的问题进行难度分类,问题将替换 {text} 占位符。

问题类型分类提示
问题类型分类说明:你是一名教育和考试专家,专门从事问题类型分类。对于给定的问题,请评估其类型并将其标记为:解决问题型问题、选择题、证明题 或 其他问题类型。对于无法确定的问题,使用“其他问题类型”。
以下为问题类型分类示例:
- 示例 1:确定由字母 A 和 B 组成的 k 字母序列中至少包含两个连续 A 的序列数量,输出为“Question type: Problem-solving question”(解决问题型问题)。
- 示例 2:考虑函数 f ( x ) f(x) f(x) 的积分值问题,输出为“Question type: Other question types”(其他问题类型)。
论文摘要(中文)
以下是对论文中指定部分的中文总结,保留了原文中的 Markdown 图像部分及其原始格式和位置。
Example 3 总结
这一部分展示了一个多选题的示例,涉及函数的性质和实数参数的可能值。题目描述了一个奇函数 f ( c ) = x a f(c) = x^a f(c)=xa,并要求该函数在 ( 0 , + ∞ ) (0, +\infty) (0,+∞) 上单调递增,求实数 a a a 的可能值。选项包括 A: -1, 3;B: 1, 3;C: -1, 3;D: 1, 3。模型的任务是识别问题类型为“多选题”。

Figure 5: The few-shot prompt used for question type classification. The model is presented with three examples and is then asked to classify the type of a given question, which replaces the {text} placeholder.
推理导向过滤任务的提示
本部分介绍了一个用于评估互联网文本在研究推理过程中的潜在有用性的提示。评估采用5分制评分系统,从0开始,根据以下标准累加分数:
- 如果文本包含推理或思考过程,加1分。
- 如果文本包含明确的目标分解(将问题拆分为中间目标),加1分。例如:“为了解决…,我们先…,然后…”。
- 如果文本包含验证步骤(作者明确检查自己的工作),加1分。例如:“让我们检查…”。
- 如果文本包含回溯行为(作者意识到某条路径无效并尝试其他方法),加1分。例如:“让我再试一次”。
- 如果文本包含逆向推理行为(从目标开始逆向推导),加1分。例如:“为了找到…,让我们从期望的结果开始逆向推导。”
响应的格式要求使用 Markdown 结构,包括对行为的描述、最终评分和待评估文本。

Figure 6: The prompt used for the reasoning-oriented filtering task. It defines a five-level scoring rubric to assess the usefulness of a text (which replaces the {text} placeholder) for studying reasoning.
论文摘要(中文)
以下是对所提供学术论文片段的总结,内容涉及考试问题设计逻辑的提取、检索和合成过程。总结以中文撰写,并保留了原文中的Markdown图片部分,放置在适当位置。
设计逻辑提取的提示
本部分描述了一个用于提取考试问题设计逻辑的提示。作者要求模型作为教育专家和考试问题设计专家,分析给定考试问题的设计思路,超越具体内容和知识点,提炼出问题背后的设计逻辑和原则。目标是利用这些抽象的逻辑,针对不同的知识点和源材料,创建其他高质量、具有复杂逻辑推理要求的挑战性问题。此外,提取的设计逻辑需以Mermaid格式组织。

图7:用于设计逻辑提取的提示。模型被指示逆向工程给定的问题(替换{text}占位符)的思维过程,并以Mermaid格式结构化抽象逻辑。
设计逻辑检索的指令
本部分提供了一个基于书籍片段检索最适合问题设计逻辑的指令。任务是根据给定的书籍片段,找到以Mermaid格式表示的最适合创建挑战性考试问题的设计逻辑。文本片段和设计逻辑的嵌入向量在该指令下使用Qwen3-Embedding-4B模型计算,以实现基于相似性的检索。

图8:用于检索给定文本片段最适合设计逻辑的任务特定指令。文本片段和设计逻辑的嵌入向量在此指令下使用Qwen3-Embedding-4B模型计算,支持基于相似性的检索。
问题合成的提示
本部分详细说明了一个用于考试问题合成的提示。模型被要求作为教育和考试设计领域的专家,根据提供的源文本,编写研究生水平或以上的挑战性考试问题。问题需基于源文本,并严格遵循相应的设计逻辑,要求具备批判性思维,测试深入理解和解决问题的能力,而非简单的知识回忆。问题必须是自包含的,无需依赖源文本即可回答;如需源文本内容,则需将相关信息包含在问题中。问题需清晰、无缺失信息或歧义,并确保有正确答案。对于选择题,需先分析确定答案,再设计选项,确保至少有一个正确答案,且选项数量不限于四个(A, B, C, D)。如有最终单一结果或结论(如数字、公式或短语),需明确声明“最终答案是:\boxed{answer}”。

图9:用于问题合成的提示。LLM被提供源文本和五个通过语义相似性检索的候选设计逻辑,指示其选择最适合的逻辑并严格遵循,生成研究生水平的问题及相应的参考答案,以JSON格式结构化。
Original Abstract: Large language models (LLMs) have achieved remarkable success in many natural
language tasks but still struggle with complex, multi-step reasoning,
particularly across diverse disciplines. Existing reasoning datasets often
either lack disciplinary breadth or the structural depth necessary to elicit
robust reasoning behaviors. We propose DESIGNER: a DESIGN-logic-guidEd
Reasoning data synthesis pipeline that leverages naturally available, extensive
raw documents (book corpus and web corpus) to generate multidisciplinary
challenging questions. A core innovation of our approach is the introduction of
a Design Logic concept, which mimics the question-creation process of human
educators. We use LLMs to reverse-engineer and abstract over 120,000 design
logics from existing questions across various disciplines. By matching these
design logics with disciplinary source materials, we are able to create
reasoning questions that far surpass the difficulty and diversity of existing
datasets. Based on this pipeline, we synthesized two large-scale reasoning
datasets that span 75 disciplines: Design-Logic-Reasoning-Book (DLR-Book),
containing 3.04 million challenging questions synthesized from the book corpus,
and Design-Logic-Reasoning-Web (DLR-Web), with 1.66 million challenging
questions from the web corpus. Our data analysis demonstrates that the
questions synthesized by our method exhibit substantially greater difficulty
and diversity than those in the baseline datasets. We validate the
effectiveness of these datasets by conducting SFT experiments on the
Qwen3-8B-Base and Qwen3-4B-Base models. The results show that our dataset
significantly outperforms existing multidisciplinary datasets of the same
volume. Training with the full datasets further enables the models to surpass
the multidisciplinary reasoning performance of the official Qwen3-8B and
Qwen3-4B models.
PDF Link: 2508.12726v1
部分平台可能图片显示异常,请以我的博客内容为准




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









