







C语言基础
1、运算符
1、算术运算符
-
-
-
- /
- %
2、比较运算符
两个结果 0 1
- > >=
- < <=
- !=
- ==
3、逻辑运算符
两个结果 0 1
-
&&:左右两边都不是0,结果就是 1,否则结果是 0
-
||:左右两端都是 0,结果才是 0,否则结果是 1
-
!:取反
&&和&区别
&&左边出错不会计算右边
&左边出错仍会计算右边
4、位运算符
- $
- |
- ^:相同取0,不同取1
- ~
- <<:左移
- >>:右移
5、++,–
2、逻辑语言
1、if…else
2、if语句的并列
3、if…else if …
4、if语句的嵌套
5、switch…case…break
#include<stdio.h>
int main(){
int h = 0;
int a = 1;//变量
scanf("%d",&h);
switch(h){ //1. switch必须是整型
case 1: //2. 必须是整型常量
printf("星期一");
break;
case 2: //3. case分支的值不能相同
printf("星期二");
break; //4. break不可忽视
case 3: //5. 如果想在case分支中定义一个变量,用{}实现
{
int a = 10;
printf("星期三");
break;
}
default: //6. 所有case都不满足,则执行defalut分支
printf("输入有误");
break;
}
return 0;
}
break和continue区别
break:语句则是结束整个循环过程,不再判断执行循环的条件是否成立。
continue:语句只结束本次循环,而不是终止整个循环的执行;
6、while
7、循环嵌套
8、循环并列
指针
1、指针基础
1、房子理论
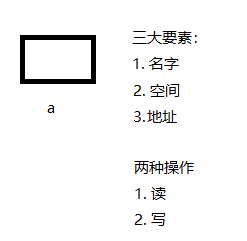
2、指针变量
作用:用来存储地址
口诀:指针变量中放的是谁的地址,*地址变量就是谁

3、指针变量的大小
32为编译环境下是4个字节
64为编译环境是8个字节
数组传参 int nums[]会退化成指针 int *nums
//*(nums + i) <===> nums[i]
#include <stdio.h>
void printArray(int* nums, int n) {//数组传参 int nums[]会退化成指针 int *nums
for (int i = 0; i < n; i++) {
printf("%d", *(nums + i)); //*(nums + i) <===> nums[i]
}
}
int main() {
int nums[10] = { 1,2,3,4,5,6,7,8,9,10 };
printArray(nums, sizeof(nums) / sizeof(int));
return 0;
}
2、指针运算
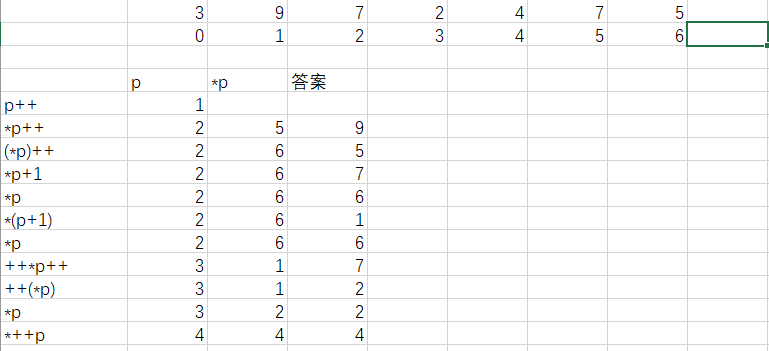
注意:++ 操作一定有数的变化,变化来源有p指针指向的下标变化或者是p指针指向的内容变化
#include <stdio.h>
int main() {
int nums[10] = { 3,9,5,1,4,7,5 };
int* p = nums;
p++;
printf("%d\n",*p++ );
printf("%d\n",(*p)++);
printf("%d\n", *p+1);
printf("%d\n", *p);
printf("%d\n", *(p+1));
printf("%d\n", *p);
printf("%d\n", ++*p++);
printf("%d\n", ++(*p));
printf("%d\n", *p);
printf("%d\n", *++p);
printf("\n");
for (int i = 0; i < 10; i++) {
printf("%d ", nums[i]);
}
return 0;
}
一般来说p是很大的随机值,这里为了方便学习故假设p初值为0
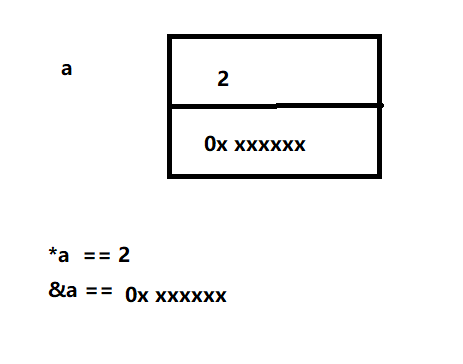
1、 * 和 &
- 和 & 可理解为一对相反操作,*是指针a指向的内容,&是指针a的地址
函数
1、功能
实现某一个功能的代码
2、函数的定义
无参无返回值
void add(){
int a = 10;
int b = 20;
printf("%d",a+b);
}
有参无返回值
void add(int a,int b){
printf("%d",a+b);
}
int main(){
add(1,2); //调用函数
return 0;
}
有参有返回值
#include<stdio.h>
int add(int a,int b){
return (a+b);
}
int main(){
int s = add(6,2);
printf("%d",s)
return 0;
}
3、函数指针
#incldue<stdio.h>
int* f2(char c,int i){
printf("f2");
}
typedef int*(*pFun)(char,int);
int main(){
pFun p = &f2; //pFun函数指针类型
int*(*pFun)(char,int) = &f2; // pfun 函数指针变量
return 0;
}
数组
1、数组的定义
//100代表的是数组的长度
//[] 中放的是常量
int nums[100];
2、数组的初始化
int nums[]={0,1,2,3,4,5};
int nums[10]={1,3,5,7,9}; //后面的值会被填充成0
3、数组的访问
int nums[10] = {0,1,2,3,4,5};
printf("%d",nums[0]); //以数组下标的方式访问数组(下标的范围0~n-1)
printf("%d",nums[1]);
printf("%d",nums[9]);
注意:访问数组时千万不要超过数组的临界值
4、数组的特点
- 地址空间是连续的
- 支持随机访问
- 删除和插入效率低
5、数组的名字
int a[5];
数组的名字代表的是数组第一个元素的地址(首地址)
a:数组首元素的地址
&a:数组的地址
a和&a的地址值虽然相同,但是二者意义不同
#include<iostream>
using namespace std;
int main() {
int a[3] = { 0,1,2 };
cout << a << endl;
cout << &a << endl;
cout << a+1 << endl;
cout << &a+1 << endl;
return 0;
}
/*
00D8F9B0 //a
00D8F9B0 //&a
00D8F9B4 //a+1
00D8F9BC //&a+1
*/
由以上例子可见 a作为数组首元素的地址,它的单位大小是首元素的类型,所以 a+1 时得到的答案是 +4;而&a作为数组的地址,它的单位大小是数组的大小,所以 &a+1 时得到的答案是 +12。
字符串
1、字符
- 0,‘0’ ,‘\0’
#include<stdio.h>
int main() {
char c = '0';
printf("%c\n", c); //0
printf("%d\n", c); //48
c = 0;
printf("%c\n", c); //
printf("%d\n", c); //0
c = '\0';
printf("%c\n", c); //
printf("%d\n", c); //0
return 0;
}
/*
0
48
0
0
*/
2、转义字符

3、计算字符串长度
#include<stdio.h>
#include<string.h>
int main() {
const char* p = "a\0\n\012ab0";
printf("%d\n", sizeof(p)); //4
printf("%d\n", sizeof("a\0\n\012ab0")); //8
//a \0 \n \012 a b 0 \0
int n = strlen(p);
printf("%d\n", n); //1
p++;
p++;
n = strlen(p);
printf("%d\n", n); //5
return 0;
}
4、字符数组和字符串常量的区别
#include<iostream>
#include<string>
using namespace std;
int main(){
const char *str1 = "abcde";//字符串常量
char str2[] = "abcde";//字符数组
cout << sizeof(str1) << endl;
cout << sizeof(str2) << endl;
cout << strlen(str1) << endl;
cout << strlen(str2) << endl;
return 0;
}
/*
4 //str1指针大小
6 //加上 '\0'
5 //不加 '\0'
5 //不加 '\0'
*/
字符串常量:字符串常量不能修改,因为是共用的,*str1因为是指针类型的字符串常量,所以只占4个字节。
字符数组:如果想将一个字符串存放到变量中,必须使用字符数组,就是用一个字符型数组存放一个字符串

C语言内存管理
常量区(军事管理区,不可以修改)
特点
- 整型常量 10 20 -10
- 浮点常量 1.2 1.001
- 字符常量 ‘a’ ‘0’ ‘\0’
- 字符串常量 “asdf” “123”
- 地址常量 int a; &a 数组名 函数名
栈区
特点
- 租的房子,房子到期自动回收
- 访问速度快
- 空间少
- 作用域和生命周期从定义的位置开始 ‘}’
- 局部变量
- 函数变量
全局区(全局变量)
特点
- 局部大于全局
- 初始化默认为0
- 生命周期 程序开始到程序结束
- 作用域:整个项目
引用其他文件中的全局变量
/*main.c*/
#include<stdio.h>
int g_value;
int main(){
printf("%d",g_value);
return 0;
}
/*a.c*/
extern int g_value; //extern 引用其他文件的全局变量
void print(){
g_value = 200;
}
静态区
静态局部变量
- 生命周期:从程序开始到程序结束
- 作用域:到 '}'结束
- 只被初始化一次
#include<stdio.h>
void fun(){
int a = 10;
static int s = 10;
printf("%d",a++);
printf("%d",s++);
}
int main(){
fun(); //10 10
fun(); //10 11
return 0;
}
静态全局变量
- 生命周期:程序开始到程序结束
- 作用域 :当前文件
- 特点:不怕重名
堆区
特点
- 不会自动释放
- 容量大
- 访问速度慢
- 堆区空间没名字
注意
- 不要访问越界
- 不要忘记释放空间
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
int main(){
char* p =malloc(400);//在堆区申请空间
strcpy(p,"12345");
//房子不用的时候记得释放
free(p);
return 0;
}
GetMemory的几个面试题
Test1
void GetMemory1(char *p){
p = (char *)malloc(100);
}
void Test1(void){
char *str = NULL;
GetMemory1(str);
strcpy(str,"hello world");
printf(str);
}
//输出结果:访问空指针,异常退出
solution1
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
char* GetMemory1(char *p)
{
p = (char *)malloc(100);
return p;
}
void Test1()
{
char *str = NULL;
str = GetMemory1(str);
strcpy(str,"hello world");
printf(str);
free(str);
}
int main()
{
Test1();
return 0;
}
solution2
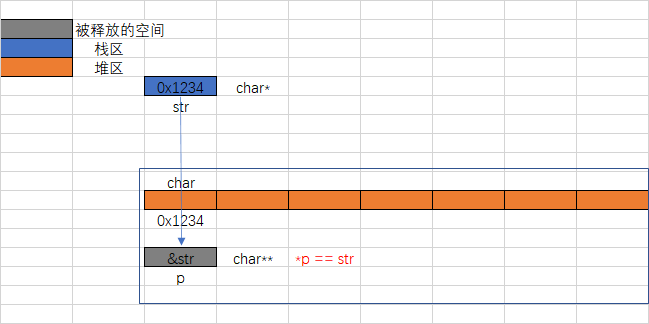
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
char* GetMemory1(char **p)
{
*p = (char *)malloc(100);
}
void Test1()
{
char *str = NULL;
str = GetMemory1(&str);
strcpy(str,"hello world");
printf(str);
free(str);
}
int main()
{
Test1();
return 0;
}
Test2
char *GetMemory2(void){
char p[] = "hello world";
return p;
}
void Test2(void){
char *str = NULL;
str = GetMemory2();
printf(str);
}
//输出结果:字符串数组在栈区分配,函数结束被释放,输出乱码
Test3
char *GetMemory3(void){
char *p = "hello world";
return p;
}
void Test3(void){
char *str = NULL;
str = GetMemory3();
printf(str);
}
//输出结果:hello world
Test4
char *GetMemory4(void){
static char p[] = "hello world";
return p;
}
void Test4(void){
char *str = NULL;
str = GetMemory4();
printf(str);
}
//输出结果:hello world 静态局部变量不会被释放空间,生命周期是全局的
Test5
void Test5(void){
char *str = (char *)malloc(100);
strcpy(str,"hello");
free(str);
//str = NULL;
if(str!=NULL){
strcpy(str,"world");
printf(str);
}
}
//输出结果:world 内存已经被释放,访问野指针造成内存泄漏
Test6
void Test6(){
char *str = (char *)malloc(100);
strcpy(str,"hello");
str+=6;
free(str);
//str = NULL;
if(str!=NULL){
strcpy(str,"world");
printf(str);
}
}
//输出结果:出现异常,释放空间不对
结构体
1、结构体的定义初始化
1、不使用typedef的结构体
以下例子中,不加typedef时,struct STUDENT 是结构体类型名
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
struct STUDENT {
int num;
char name[20];
int age;
int weight;
};
int main() {
struct STUDENT stu;
stu.num = 101;
//数组直接输入字符串需用 strcpy函数,不能直接赋值
strcpy(stu.name, "hello");
stu.age = 18;
stu.weight = 100;
/*
student stu = { 101,"hello",18,100 };
*/
printf("学号: %d 姓名: %s 年龄: %d 体重:%d", stu.num, stu.name, stu.age, stu.weight);
return 0;
}
2、使用typedef的结构体
定义一个新的类型
以下例子中,加了typedef,struct STUDENT是结构体类型名,student也是结构体类型名
student s中的s是结构体变量
#include<stdio.h>
#include<stdlib.h>
typedef struct STUDENT{
int number;
int age;
int weight;
int score;
char s;
}student;
typedef int INT32;
int main(){
INT32 a;
student s;
return 0;
}
3、结构体数组
#include<stdio.h>
#include<stdlib.h>
typedef struct STUDENT{
int number;
int score;
}student;
int main(){
int array[10];
char buffer[10];
student s[10] = {{1,10},{2,30}};
s[0].number;
s[0].score;
s[1];
student* p = s;
printf("%d",s[0].score);
printf("%d",(*p).score);
printf("%d",p->score);
return 0;
}
2、结构体中字节对齐原则
- 按照最长的成员对齐
- 保证整数倍地址对齐
按照最长的成员对齐:结构体中默认以所占字节最长的成员划分。例如,一个结构体中 int 占4个字节最长,则按 4字节作为排列长度
保证整数倍地址对齐:一个类型对齐的地址应是该类型所占字节的倍数。例如 char 类型占一个字节,它能占的地址是1 的倍数,short 占2个字节,它能站得地址是2的倍数
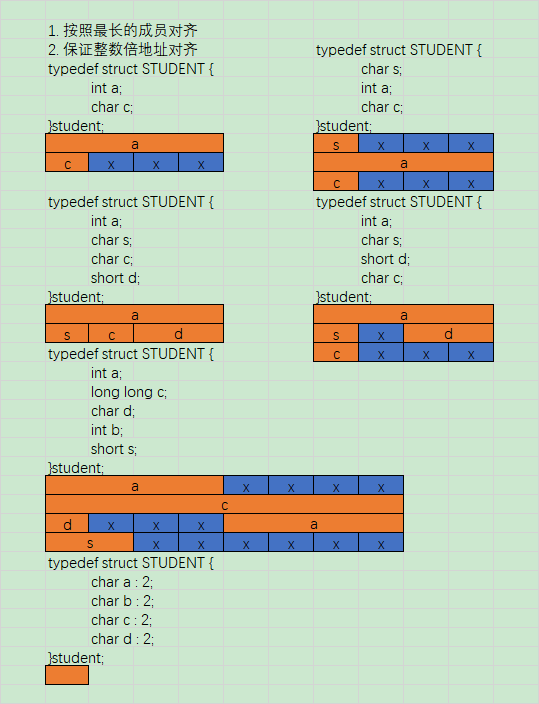
结构体默认按最长字节对齐,也可认为规定对齐的最长长度
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
// #pragma pack(2) 规定在这个范围里的结构体按长度 2 对齐
#pragma pack(2)
typedef struct STUDENT {
int a;
char c;
char res[3];
} student;
#pragma pack(2)
int main() {
printf("%d", sizeof(student));
return 0;
}
结构体定义的原则:保证结构体字节对齐
#include<stdio.h>
#include<stdlib.h>
#pragma pack(2) /*指定按2字节对齐*/
typedef struct A {
int a;
char c;
char res[1];
}a;
#pragma pack() /*取消指定对齐,恢复缺省对齐*/
typedef struct B {
int a;
char c;
char res[1];
}b;
int main() {
printf("%d\n", sizeof(a));
printf("%d\n", sizeof(b));
return 0;
}
/*
6
8
*/
链表
1.特点
空间不连续,不可以支持随机访问,插入删除的效率高
2.链表定义
typedef struct NODE{
int num;
struct NODE* next; //指向下一地址的指针
}Node;
3.链表的创建

//有头指针的头插法
#include<stdio.h>
#include<stdlib.h>
typedef struct NODE {
int num;
struct NODE* next;
}Node;
void printList(Node* p) { //链表打印
while (p) {
printf("%d ", p->num);
p = p->next;
}
}
void freeList(Node* p) { //链表的释放
Node* t = NULL;
while (p) {
t = p->next;
free(p);
p = t;
}
}
Node* findNode(Node* p, int num) { //链表查找
while (p) {
if (p->num == num) {
return p;
}
p = p->next;
}
return NULL;
}
void deleteNode(Node* p, int num) { //链表删除
if (p == NULL) {
return;
}
Node* q = p;
p = p->next;//p比q多走一步
while (p) {
if (p->num == num) {//删除节点
q->next = p->next;
free(p);
break;
}
q = p;
p = p->next;
}
}
void insertNode(Node* p, int findNum, int newNum) { //链表添加
Node* q = p;
p = p->next;//p比q多走一步
while (p) {
if (p->num == findNum) {//插入节点
Node* t = malloc(sizeof(Node));
t->num = newNum;
t->next = p;
q->next = t;
break;
}
q = p;
p = p->next;
}
//找不到findNum不处理
}
int main() {
Node* head = malloc(sizeof(Node));
head->next = NULL;
int number = 0;
while (1) {
scanf("%d", &number);
if (number <= 0) {
break;
}
Node* p = malloc(sizeof(Node));
p->num = number;
p->next = head->next;
head->next = p;
}
//修改节点
Node* t = findNode(head->next, 10);
if (t != NULL) {
t->num = 20;
}
//删除节点
deleteNode(head, 10);
//增加节点
insertNode(head, 10, 50);
//查找节点
Node* t = findNode(head->next, 10);
//修改节点
if (t != NULL) {
t->num = 20;
}
//打印链表
printList(head->next);
//释放链表
freeList(head);
return 0;
}
4.链表的打印

void printList(Node* p){
while(p){
printf("%d ",p->num);
p = p->next;
}
}
5.链表的释放

void freeList(Node* p){
Node* t = NULL;
while(p){
t = p->next;
free(p);
p = t;
}
}
6.查找节点
Node* findNode(Node* p,int num){
while(p){
if(p->num == num){
return p;
}
p = p->next;
}
return NULL;
}
7.修改节点
Node* t = findNode(head->next,10);
if(t!=NULL){
t->num = 20;
}
8.删除节点
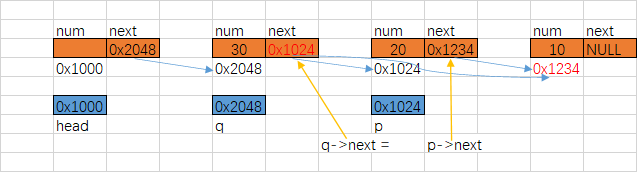
void deleteNode(Node* p,int num){
if(p == NULL){
return;
}
Node* q = p;
p = p->next;//p比q多走一步
while(p){
if(p->num ==num){//删除节点
q->next = p->next;
free(p);
break;
}
q = p;
p = p->next;
}
}
9.插入节点

void insertNode(Node* p,int findNum,int newNum){
Node* q = p;
p = p->next;//p比q多走一步
while(p){
if(p->num == findNum){//插入节点
Node* t = malloc(sizeof(Node));
t->num = newNum;
t->next = p;
q->next = t;
break;
}
q = p;
p = p->next;
}
//找不到findNum不处理
}
联合
联合
所有成员共享一块空间
- 联合的空间大小取决于联合体内部定义的最大变量类型,如下面代码中 int 有4个字节,最大,则UN 的空间大小为4个字节,
- 向联合体内存数据,取的值都是一样的,因为共享一块空间,如下面 u.c 赋值为 10,u.a u.b 也赋值为10
#include<stdio.h>
union UN {
int a;
char b;
int c;
};
int main() {
printf("%d", sizeof(union UN)); //4
union UN u;
u.c = 10;
printf("%d %d %d", u.a, u.b, u.c); //10 10 10
return 0;
}
注意:虽然不同类型的变量共享一块地址,但是对其中变量赋值时只能总用于相同的类型。
大小端
1.出现原因
计算机系统中内存是以字节为单位进行编址的,每个地址单元都唯一的对应着1个字节(8 bit)。这可以应对char类型数据的存储要求,因为char类型长度刚好是1个字节,但是有些类型的长度是超过1个字节的(字符串虽然是多字节的,但它本质是由一个个char类型组成的类似数组的结构而已),比如C/C++中,short类型一般是2个字节,int类型一般4个字节等。因此这里就存在着一个如何安排多个字节数据中各字节存放顺序的问题。正是因为不同的安排顺序导致了大端存储模式和小端存储模式的存在。
2.存放方式
- 小端存储:高地址放高位,低地址放低位(高高低低)
- 大端存储:高地址放低位,低地址放高位(高低低高)
以下图为例存十进制100000,小端存储按高地址放高位,低地址放低位,大端存储按低地址放高位,高地址放低位

//用来判断环境是大端还是小端,以下用intel为例(intel)一般为小端存储
#include<stdio.h>
int checkSystem(){
union UN{
int a;
char c;
}u;
//将a赋值为1
//如果环境是大端存储,1应在最右边字节的最后一位
//若环境是小端存储,1应在最左边字节的最后一位
u.a=1;
//u.c的位置一直是最左边的字节。
//若环境为大端存储,则u.c == 1 返回为0
//若环境为小端存储,则u.c == 1 返回为1
return u.c == 1;
}
int main(){
printf("%d",checkSystem());
//打印 1 说明该环境为小端存储
return 0;
}
宏定义
1、宏定义
#include<stdio.h>
#define NUM 5+2
int main() {
printf("%d", NUM * 3);
return 0;
}
/*
11 //5+2*3=11
*/
2、宏函数
#include<stdio.h>
#define MAX(a,b) if(a>b){printf("%d",a);}else{printf("%d",b);}
int main(){
MAX(20,30)
return 0;
}
文件读写
#include<stdio.h>
int main() {
//1. 打开文件
FILE* fr = fopen("C:\\Users\\hp\\Desktop\\hi.txt", "r");
FILE* fw = fopen("C:\\Users\\hp\\Desktop\\hello.txt", "w");
if (fr == NULL || fw == NULL) {
printf("文件打开失败");
return 0;
}
//2.读写文件
char buffer[128];
while (fgets(buffer, 128, fr)) {//获取fr(hi.txt)中的字符串存入buffer
fputs(buffer, fw); //将buffer中的字符串存入fw(hello.txt)
}
//3.关闭文件
fclose(fr);
fclose(fw);
return 0;
}















 8126
8126











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









