







【实验3.3】使用Python的Skleamn库进行数据预处理实验。
目录
【实验3.3】使用Python的Skleamn库进行数据预处理实验。
任务二:从https://archive.ics.uci.cdu/ml/index.php 下载iris数据集(鸢尾花数据集),并对所有的属性列(不包括类别标签列)进行Z-Score标准化处理。
3).找到我们下载到的数据集存放位置在哪里啦~(到这一步就完成啦!)
4)有关pandas的DataFrame可以自行百度学习一下如何使用。
2.也可不下载,直接调用sklearn中的数据集,进行加载鸢尾花数据集即可
任务一:从https://archive.ics.uci.edu/ml/index.php 下载labor数据集,并对所有的属性列(不包
括类别标签列)进行缺失值填充:对数值型属性采用平均值进行填充:对非数值型属
性采用众数进行填充。
任务二:从https://archive.ics.uci.cdu/ml/index.php 下载iris数据集(鸢尾花数据集),并对所有
的属性列(不包括类别标签列)进行Z-Score标准化处理。
任务一:从https://archive.ics.uci.edu/ml/index.php 下载labor数据集,并对所有的属性列(不包
括类别标签列)进行缺失值填充:对数值型属性采用平均值进行填充:对非数值型属性采用众数进行填充。
1.下载数据集
2.编写代码

import pandas as pd
from sklearn.impute import SimpleImputer
# 读取 CSV 文件
data = pd.read_csv('labor.csv')
# 获取除类别标签列之外的所有属性列
numeric_cols = data.select_dtypes(include=['number']).columns
non_numeric_cols = data.select_dtypes(exclude=['number']).columns
# 数值型属性采用平均值填充缺失值
for col in numeric_cols:
if data[col].isnull().any(): # 检查是否有缺失值
imp_mean = SimpleImputer(strategy='mean')
data[col] = imp_mean.fit_transform(data[[col]])
# 非数值型属性采用众数填充缺失值
for col in non_numeric_cols:
if data[col].isnull().any(): # 检查是否有缺失值
imp_mode = SimpleImputer(strategy='most_frequent')
data[col] = imp_mode.fit_transform(data[[col]])
# 打印填充后的数据
print(data)
# 将填充后的数据保存到新的 CSV 文件
data.to_csv('filled_labor.csv', index=False)
3.运行结果:


任务二:从https://archive.ics.uci.cdu/ml/index.php 下载iris数据集(鸢尾花数据集),并对所有
的属性列(不包括类别标签列)进行Z-Score标准化处理。
1.下载数据集
鸢尾花(iris)数据集保存到本地以及sklearn其他数据集下载保存
具体步骤可如下图所示:
1).运行下述代码:
#从sklearn数据集导入我们要的iris数据集,iris数据集调用在下方
from sklearn.datasets import load_iris
iris = load_iris()
print(iris)
#数据集并不能直接用,通过pandas的DataFrame来转化
import pandas as pd
#col是列名
col = list(iris["feature_names"])
#在iris数据集中,标签在"data"数组里,标记在"target"数组里
m1 = pd.DataFrame(iris.data,index=range(150),columns=col)
m2 = pd.DataFrame(iris.target,index=range(150),columns=["outocme"])
#将上述两张DataFrame表连接起来,how是DataFrame参数,可以不写,这里用外连接。不清楚外连接的可以看下SQL语句
m3 = m1.join(m2,how='outer')
#to_excel语句转化成excel格式,后缀名为.xls
m3.to_excel("./test.xls")

2).点击换行,使得结果方便显示出来
3).找到我们下载到的数据集存放位置在哪里啦~(到这一步就完成啦!)

4)有关pandas的DataFrame可以自行百度学习一下如何使用。

eg:下载下载保存波士顿房价。
from sklearn.datasets import load_boston
load_boston = load_boston()
import pandas as pd
# print(load_boston)
col = load_boston["feature_names"]
m1 = pd.DataFrame(load_boston.data,index=range(506),columns=col)
m2 = pd.DataFrame(load_boston.target,index=range(506),columns=["price"])
m3 = m1.join(m2,how="outer")
m3.to_excel("./load_boston.xls")2.也可不下载,直接调用sklearn中的数据集,进行加载鸢尾花数据集即可
import pandas as pd
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import StandardScaler
# 加载鸢尾花数据集
iris = load_iris()
iris_df = pd.DataFrame(data=iris.data, columns=iris.feature_names) # 将数据转换为 DataFrame
# 选择需要标准化的属性列(不包括类别标签列)
attributes = iris_df.columns
# 初始化 StandardScaler
scaler = StandardScaler()
# 对属性列进行 Z-Score 标准化
iris_df[attributes] = scaler.fit_transform(iris_df[attributes])
# 创建可视化
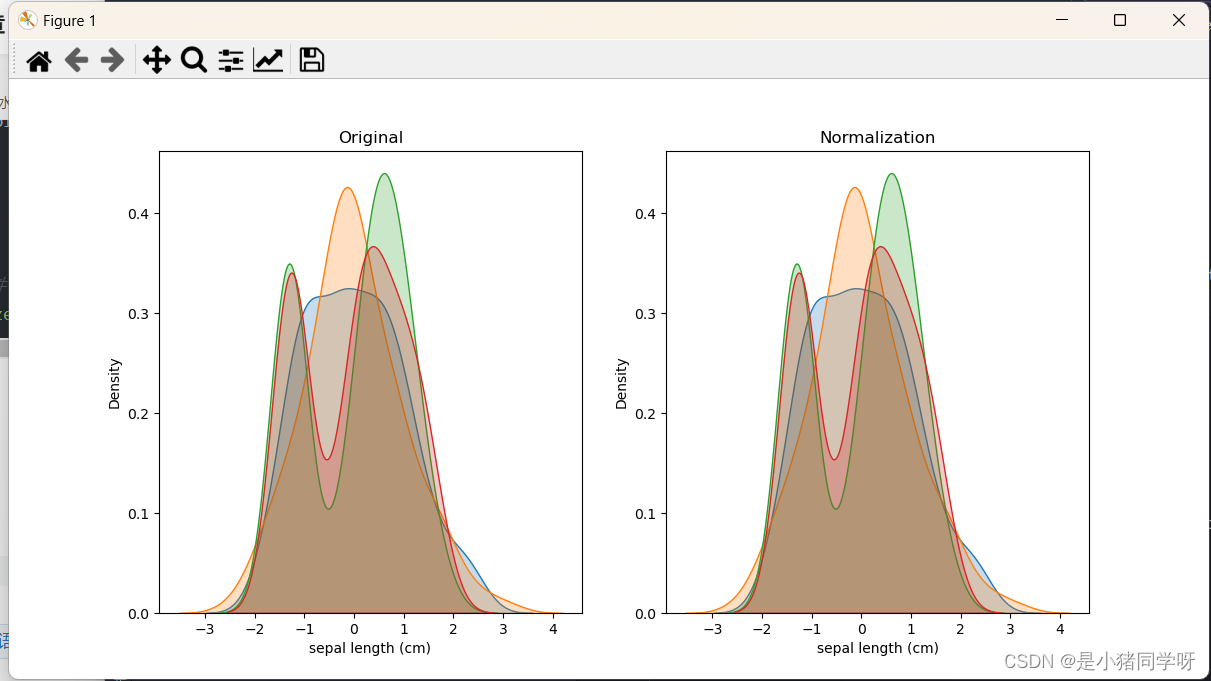
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.title('Original')
for column in iris_df.columns:
sns.kdeplot(iris_df[column], shade=True, label=column)
# 标准化后的可视化
plt.subplot(1, 2, 2)
plt.title('Normalization')
for column in iris_df.columns:
sns.kdeplot(iris_df[column], shade=True, label=column)
plt.show()
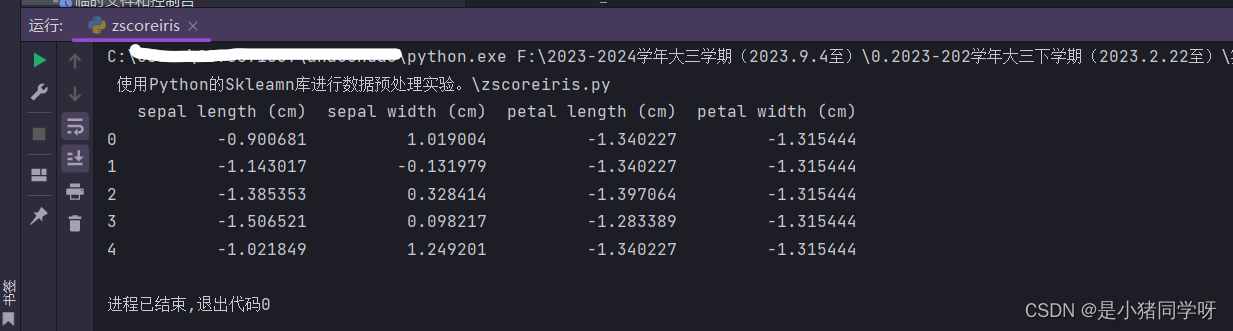
# 打印标准化后的数据集
print(iris_df.head())
# 将标准化后的数据保存到文件
iris_df.to_csv('standardized_iris.csv', index=False)
3.运行结果:
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









