







 本文探讨了在金融科技场景下模型可解释性的重要性,介绍了模型解释的分类方法,如局部和全局解释,以及依赖和不依赖模型的解释。文章通过案例详细解释了部分依赖图(PDP)、个体期望条件图(ICE)和累积局部效应法(ALE),并提到了LIME和SHAP等可解释性工具的应用。在反欺诈和设备分类场景中,模型解释有助于理解模型决策,验证模型效果,确保模型在线上环境的合理性和有效性。
本文探讨了在金融科技场景下模型可解释性的重要性,介绍了模型解释的分类方法,如局部和全局解释,以及依赖和不依赖模型的解释。文章通过案例详细解释了部分依赖图(PDP)、个体期望条件图(ICE)和累积局部效应法(ALE),并提到了LIME和SHAP等可解释性工具的应用。在反欺诈和设备分类场景中,模型解释有助于理解模型决策,验证模型效果,确保模型在线上环境的合理性和有效性。
1.背景介绍
书籍推荐
首先,想向各位读者推荐一本电子书籍《Interpretable Machine Learning》,其原因有两个:
1.该书作者从2017年首次在网络发布本书之后至今一直在持续更新,在github上可以看到其最新的更新时间是今年的6月30日。作者这样的科研精神,值得每一个相关从业者尊敬;
2.该书对机器学习模型可解释性进行了系统且有条理的总结,省去了读者查询文献的时间。通过阅读该书能够很快地对这一领域建立起一个基础的知识体系,同时也能给有应用需求的读者提供理论基础,本文内容在很大程度上也受益于这本电子书,非常适合对这一领域有进一步了解兴趣的读者阅读。

模型为什么需要解释?
我们为什么需要对模型进行解释?此处想引用书中的一句话:
“If the user do not trust a model or a prediction,they will not use it.
当我们在建立相关的模型过程中,我们需要验证模型的正确性与合理性。相比于客观的模型衡量标准如AUC、召回、准确率等,实际模型的使用人员更关心的是一些实际与业务相关的问题,如“模型做出这个决定依据是什么?”,“这个用户为什么会被拒绝?这个理由合理么?”。当建模人员得到在模型衡量标准上表现良好的模型,是否意味着在实际问题中表现良好呢?

书中作者给出了一个这样的例子,利用邮件文本内容判断是“无神论者”还是“基督徒”。在利用随机森林模型建立模型之后,模型在测试集上的准确率达到了92.4%。但是当利用模型解释器去探究模型分类的依据时发现,将邮件判断为“无神论者”的关键词汇是“Posting”,“Host”,“edu”一系列不被常识认可的词汇。这样的模型虽然在准确率上表现很好,但是其在之后的实际中能否满足模型需求,存在较大偏差。
在上述的案例中我们可以发现,对模型进行解释,能够帮助建模人员校验模型的有效性,从而保证模型的“线下”效果能够顺利迁移到“线上”。利用工具对模型进行解释,可以辅助建模人员或业务人员对模型结果有更加深入的理解,因此成为当下一个兼具应用价值与研究意义的课题。
2.模型解释常用分类方法
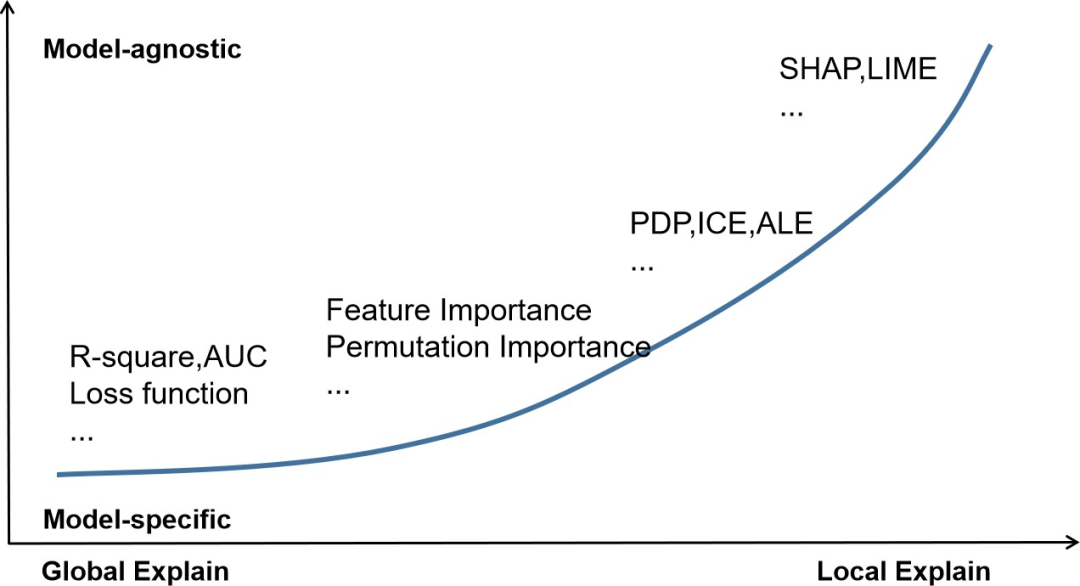
模型可解释性的常用方法,可以大致根据是否依赖被解释模型,以及模型解释的全局性进行分类。
-
依赖模型或不依赖模型?(Model-specific or model-agnostic)
根据解释方法对需要解释模型的依赖关系可以将模型解释方法分为:依赖模型的解释方法与不依赖模型的解释方法。
依赖模型的解释方法,是指依据被解释模型自生的原理与结构,提取其结果或者中间过程作为对某一特征或者整个模型预测结果的解释。例如,线性模型中的p-value,R-square都是建立在被解释模型的假设条件下所建立的模型解释;XGBoost模型,可以使用在模型生成过程中特征的作为分裂依据的次数(freq),影响观测结果的数量(cover)以及特征贡献的增益(gain),作为对变量重要性的解释。
但是上述方法存在一些缺点:1.基于不同模型的解释结果,之间往往不存在可比性。2.解释结果需要使用者具备一定的模型理解与专业知识。
-
局部的或全局的?(Local or global)
模型解释方法,根据模型的解释结果是针对整体模型的解释还是局部样本表现的可以分为:全局与局部的解释方法。
常见的全局解释通常是对整个模型的结果的解释,如特征重要性,模型结构(如树模型)。而局部的模型解释则是针对某一个实例的模型预测结果的解释,比如卡模型,单个实例各个变量取值得分。
-
不依赖模型的局部可读的模型解释方法(Local Interpretable Model-Agnostic Explanations)
在融慧金科的实际应用场景中,需要对不同模型中各个中间产品结果进行解释(如人群画像,风险评价),并且希望这些解释的结果能够对实际的业务人员在生产过程中产生帮助(如风险审核人员)。因此,不依赖于模型本身的局部模型解释方法是我们的首要选择。
3. 基于边际效应的模型可解释性
-
部分依赖图(Partial Dependence Plot)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









