






目录
1.项目要求

2.爬虫过程
2.1 Nodejs爬虫
首先,先明确需要使用的几个工具
- request发起请求,获取页面数据;
- cheerio将获取的页面数据(String)转换为可像jQuery一样操作;
- iconv-lite处理一些返回的页面数据乱码;
- mysql将爬取的内容存储到数据库中;
安装MySQL、Nodejs后,利用npm install将需要利用的工具下载下来,方便后续操作。(我还另外下载了Navicat,这是一个可视化工具,可以直观创建、访问到数据库中存储的信息)

Navicat页面展示
2.2 分析网站链接格式和网页信息格式
本次项目一共爬取了三个网站:新浪娱乐、凤凰娱乐、网易娱乐。下面是对每个网站的url分析。对于每一个网站,我们都会分析他们的网页链接格式以及网页信息格式。
2.2.1 凤凰娱乐

凤凰娱乐的网址是https://ent.ifeng.com/。接下来观察一下凤凰网的新闻网页信息格式。
https://ent.ifeng.com/c/8RBOfvAWaLL
https://ent.ifeng.com/c/8RAdw1HyHIX
https://ent.ifeng.com/c/8QpTzWyrmAx可以看出基本的格式为“/c/11位数字(字母)”,所以在js爬虫代码中我们构造的正则表达式为
const url_reg = /c\/([a-zA-Z0-9]{11})/我们主要想提取的内容是标题、关键词、来源、时间、作者、简介、原文。不同的网站可以爬取的内容也不同,针对凤凰娱乐,我们只提取了部分内容,但为了方便存储,有些内容以其他内容进行替代(并不会展示在前端中)。
我们对某一文章进行查看他的源代码可以看到以下的内容:
![]()
![]()
![]()
![]()
![]()
将以上需要的内容爬取下来,代码如下所示:
const url_reg = /c\/([a-zA-Z0-9]{11})/
const seedURL_format = "$('a')";
const keywords_format = " $('meta[name=\"keywords\"]').eq(0).attr(\"content\")";
const source_format = " $('meta[name=\"og:category\"]').eq(0).attr(\"content\")";
const title_format = "$('title').text()";
const date_format = "$('meta[name=\"og:time \"]').eq(0).attr(\"content\")";
const author_format = " $('meta[name=\"og:category \"]').eq(0).attr(\"content\")";
const desc_format = " $('meta[name=\"description\"]').eq(0).attr(\"content\")";
const content_format = " $('meta[name=\"description\"]').eq(0).attr(\"content\")";
const source_name = "凤凰娱乐";
const domain = 'https://ent.ifeng.com/';
const myEncoding = "utf-8";
const seedURL = 'https://ent.ifeng.com/';2.2.2 网易娱乐

网易娱乐的网址是https://ent.163.com/,接下来观察一下网易娱乐的新闻网页信息格式。
https://www.163.com/ent/article/I8VU1NKB00038FO9.html
https://www.163.com/ent/article/I90BMADD00038FO9.html
https://www.163.com/ent/article/I8VKGTU900038FO9.html
可以看出基本的格式为“/ent/article/16位数字(字母).html”,所以在js爬虫代码中我们构造的正则表达式为
const url_reg = /ent\/article\/([a-zA-Z0-9]{16}).html/;我们对网易娱乐某一文章进行查看他的源代码可以看到以下的内容:

将以上需要的内容爬取下来,代码如下所示:
const url_reg = /ent\/article\/([a-zA-Z0-9]{16}).html/;
const seedURL_format = "$('a')";
const keywords_format = " $('meta[name=\"keywords\"]').eq(0).attr(\"content\")";
const source_format = " $('meta[name=\"Copyright\"]').eq(0).attr(\"content\")";
const title_format = " $('meta[name=\"description\"]').eq(0).attr(\"content\")";
const date_format = "$('.post_info').text().match(/(\\d{4})-(\\d{2})-(\\d{2})/)[0]\n";
const author_format = "$('meta[property=\"article:author\"]').eq(0).attr(\"content\")";
const desc_format = " $('meta[name=\"description\"]').eq(0).attr(\"content\")";
const content_format = "$('.post_body').text()";
const source_name = "网易娱乐";
const domain = 'https://ent.163.com/';
const myEncoding = "utf-8";
const seedURL = 'https://ent.163.com/';2.2.3 新浪娱乐
新浪娱乐的网址是https://ent.sina.com.cn/,接下来观察一下新浪娱乐的新闻网页信息格式。
https://ent.sina.com.cn/y/ygangtai/2023-07-06/doc-imyztiir2242077.shtml
https://ent.sina.com.cn/m/c/2023-07-05/doc-imyzrvhi2937794.shtml
https://ent.sina.com.cn/y/yrihan/2023-07-07/doc-imyzvfyz8545807.shtml
https://ent.sina.com.cn/s/m/2023-07-07/doc-imyzvwwt8306832.shtml新浪娱乐的格式因为分区的不同,没办法做出唯一的正则表达式,最后构造的正则表达式有:
const url_reg = /m\/c\/(\d{4})-(\d{2})-(\d{2})\/doc-(\w{8})(\d{7}).shtml/;
const url_reg = /y\/yrihan\/(\d{4})-(\d{2})-(\d{2})\/doc-(\w{8})(\d{7}).shtml/;
const url_reg = /y\/yneidi\/(\d{4})-(\d{2})-(\d{2})\/doc-(\w{8})(\d{7}).shtml/;
const url_reg = /tv\/zy\/(\d{4})-(\d{2})-(\d{2})\/doc-(\w{8})(\d{7}).shtml/;
const url_reg = /y\/ygangtai\/(\d{4})-(\d{2})-(\d{2})\/doc-(\w{8})(\d{7}).shtml/;我们对新浪娱乐某一文章进行查看他的源代码可以看到以下的内容:
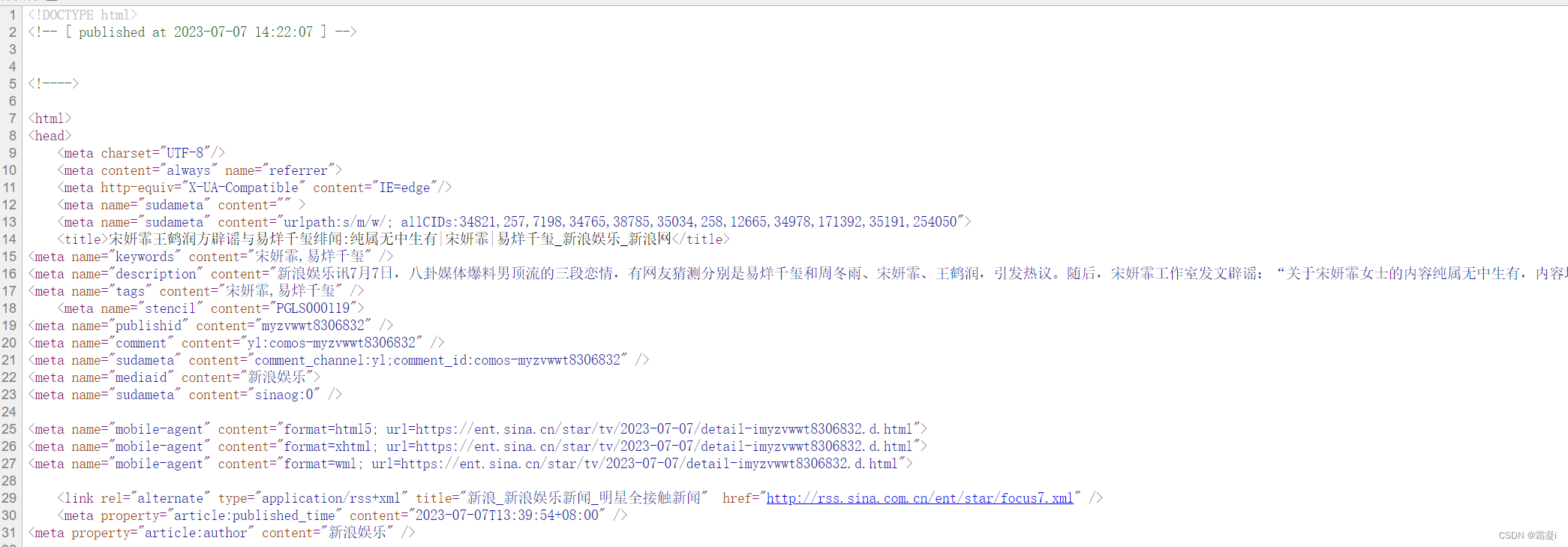
将以上需要的内容爬取下来,代码如下所示:
// const url_reg = /m\/c\/(\d{4})-(\d{2})-(\d{2})\/doc-(\w{8})(\d{7}).shtml/;
// const url_reg = /y\/yrihan\/(\d{4})-(\d{2})-(\d{2})\/doc-(\w{8})(\d{7}).shtml/;
// const url_reg = /y\/yneidi\/(\d{4})-(\d{2})-(\d{2})\/doc-(\w{8})(\d{7}).shtml/;
// const url_reg = /tv\/zy\/(\d{4})-(\d{2})-(\d{2})\/doc-(\w{8})(\d{7}).shtml/;
const url_reg = /y\/ygangtai\/(\d{4})-(\d{2})-(\d{2})\/doc-(\w{8})(\d{7}).shtml/;
const regExp = /((\d{4}|\d{2})(\-|\/|\.)\d{1,2}\3\d{1,2})|(\d{4}年\d{1,2}月\d{1,2}日)/;
const seedURL_format = "$('a')";
const keywords_format = " $('meta[name=\"keywords\"]').eq(0).attr(\"content\")";
const source_format = " $('meta[name=\"mediaid\"]').eq(0).attr(\"content\")";
const title_format = "$('title').text()";
const date_format = "$('meta[property=\"article:published_time\"]').eq(0).attr(\"content\")";
const author_format = "$('meta[property=\"article:author\"]').eq(0).attr(\"content\")";
const desc_format = " $('meta[name=\"description\"]').eq(0).attr(\"content\")";
const content_format = "$('.article').text()";
const source_name = "新浪新闻";
const domain = 'https://ent.sina.com.cn/';
const myEncoding = "utf-8";
const seedURL = 'https://ent.sina.com.cn/';2.3 数据库存储
创建数据库web和表格fetches
CREATE TABLE `fetches` (
`id_fetches` int(11) NOT NULL AUTO_INCREMENT,
`url` varchar(200) DEFAULT NULL,
`source` varchar(200) DEFAULT NULL,
`source_encoding` varchar(45) DEFAULT NULL,
`source_name` varchar(200) DEFAULT NULL,
`title` varchar(200) DEFAULT NULL,
`keywords` varchar(200) DEFAULT NULL,
`author` varchar(200) DEFAULT NULL,
`publish_date` date DEFAULT NULL,
`crawler_time` datetime DEFAULT NULL,
`content` longtext,
`description` longtext,
PRIMARY KEY (`id_fetches`),
UNIQUE KEY `id_fetches_UNIQUE` (`id_fetches`),
UNIQUE KEY `url_UNIQUE` (`url`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
2.4 爬虫代码具体实现
此处以网易新闻的爬取为例进行讲解。
首先是上文中已经提到过的引用request,cheerio,mysql等工具,并解析链接和正则表达式
const fs = require('fs');
const mysql = require('mysql');
const requestLib = require('request');
const cheerio = require('cheerio');
const iconv = require('iconv-lite');
const moment = require('moment');
require('date-utils');
const url_reg = /ent\/article\/([a-zA-Z0-9]{16}).html/;
const seedURL_format = "$('a')";
const keywords_format = " $('meta[name=\"keywords\"]').eq(0).attr(\"content\")";
const source_format = " $('meta[name=\"Copyright\"]').eq(0).attr(\"content\")";
const title_format = " $('meta[name=\"description\"]').eq(0).attr(\"content\")";
const date_format = "$('.post_info').text().match(/(\\d{4})-(\\d{2})-(\\d{2})/)[0]\n";
const author_format = "$('meta[property=\"article:author\"]').eq(0).attr(\"content\")";
const desc_format = " $('meta[name=\"description\"]').eq(0).attr(\"content\")";
const content_format = "$('.post_body').text()";
const source_name = "网易娱乐";
const domain = 'https://ent.163.com/';
const myEncoding = "utf-8";
const seedURL = 'https://ent.163.com/';为了防止爬虫被封,我们添加以下的头部,假装是客户端进行访问
const headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36',
};接下来,在爬虫代码中添加以下的内容,与数据库进行连接。
// Database configuration
// 此处信息隐去,可以根据自己的数据库更改这段内容
const dbConfig = {
host: 'localhost',
user: 'root',
password: '',
database: 'web'
};
// Create a database connection
const connection = mysql.createConnection(dbConfig);
// Connect to the database
connection.connect();在爬虫代码中,一共有四个重要的函数:
function makeRequest(url, callback):调用该函数能够访问指定的url并且能够设置回调函数来处理得到的html页面。
function checkURLExistence(url, callback):检查现在爬取的url是否已经在数据库中存储过,如果已经存储过则跳过本次爬取,进行下一条新闻的爬取。
function seedget():从种子页面抓取二级页面的url。
function newsGet(myURL):传入的参数为二级页面URL,解析得到新闻的具体信息,包括title, publish_date, source_name, keywords, content等,并存储到数据库web的fetches表中。
这四个函数的代码如下
function makeRequest(url, callback) {
const options = {
url: url,
encoding: null,
headers: headers,
timeout: 10000,
};
requestLib(options, callback);
}
function checkURLExistence(url, callback) {
const sql = 'SELECT COUNT(*) AS count FROM fetches WHERE url = ?';
connection.query(sql, [url], function (error, results, fields) {
if (error) throw error;
const count = results[0].count;
callback(count > 0);
});
}
function seedget() {
makeRequest(seedURL, function (err, res, body) {
if (body === undefined) return;
const html = iconv.decode(body, myEncoding);
const $ = cheerio.load(html, { decodeEntities: true });
const seedurl_news = eval(seedURL_format);
seedurl_news.each(function (i, e) {
let myURL = "";
try {
const href = $(e).attr("href");
if (href === undefined) return;
if (href.toLowerCase().startsWith('http://') || href.toLowerCase().startsWith('https://')) myURL = href;
else if (href.startsWith('//')) myURL = 'https:' + href;
//else myURL = domain + href;
else myURL = seedURL.substr(0, seedURL.lastIndexOf('/') + 1) + href;
} catch (e) {
console.log('识别种子页面中的新闻链接出错:' + e);
}
if (!url_reg.test(myURL)) return;
newsGet(myURL);
});
});
}
function newsGet(myURL) {
checkURLExistence(myURL, function (urlExists) {
if (urlExists) {
console.log('URL already exists, skipping: ' + myURL);
return;
}
makeRequest(myURL, function (err, res, body) {
if (body === undefined) {
console.error('Response body is empty');
return;
}
const html_news = iconv.decode(body, myEncoding);
const $ = cheerio.load(html_news, { decodeEntities: true });
console.log("转码读取成功: " + myURL);
const fetch = {};
fetch.title = "";
fetch.content = "";
fetch.publish_date = ""
fetch.url = myURL;
fetch.source_name = source_name;
fetch.source_encoding = myEncoding;
fetch.crawltime = new Date();
if (keywords_format == "") fetch.keywords = source_name;
else fetch.keywords = eval(keywords_format);
if (title_format == "") fetch.title = "";
else fetch.title = eval(title_format);
if (date_format == "") fetch.publish_date = date_format
else fetch.publish_date = eval(date_format)
if (author_format == "") fetch.author = source_name;
else fetch.author = eval(author_format);
if (content_format == "") fetch.content = "";
else fetch.content = eval(content_format).replace("\r\n" + fetch.author, "");
if (source_format == "") fetch.source = fetch.source_name;
else fetch.source = eval(source_format).replace("\r\n", "");
if (desc_format == "") fetch.desc = fetch.title;
else {
if (eval(desc_format) != null) fetch.desc = eval(desc_format).replace("\r\n", "");
}
// Insert the fetched data into the database
const sql = `INSERT INTO fetches (url, source, source_encoding, source_name, title, keywords, author, publish_date, crawler_time, content, description)
SELECT ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ? FROM DUAL
WHERE NOT EXISTS (SELECT * FROM fetches WHERE url = ?)`;
const values = [
fetch.url,
fetch.source,
fetch.source_encoding,
fetch.source_name,
fetch.title,
fetch.keywords,
fetch.author,
fetch.publish_date,
fetch.crawltime,
fetch.content,
fetch.desc,
fetch.url,
];
connection.query(sql, values, function (error, results, fields) {
if (error) throw error;
if (results.affectedRows > 0) {
console.log('Data inserted successfully');
} else {
console.log('URL already exists, skipping: ' + myURL);
}
});
});
});
}最终,我们可以通过Navicat看到存储的数据

3.网站搭建过程
3.1使用Express框架搭建
Express框架:基于Node运行环境的轻量级Web框架,封装了Node的http模块并对该模块的功能进行了扩展使开发者可以轻松完成页面路由、请求处理、响应处理。
在本次的代码中,一共有一下六个板块:
1.导入所需要的模块:
express:用于创建和配置Express应用。mysql:用于连接和操作MySQL数据库。path:用于处理文件路径。moment:用于格式化日期。
const express = require('express');
const mysql = require('mysql');
const path = require('path');
const moment = require('moment');2.创建Express应用实例
const app = express();
3.配置静态文件目录:这行代码指定了将来访问的静态文件(如CSS、JavaScript和图片)所在的目录为public目录。
app.use(express.static('public'));
4.配置数据库连接池:这段代码定义了数据库的连接配置,并使用mysql模块创建了一个数据库连接池。
// 部分信息隐去,后期代码可以根据个人需求更改
const dbConfig = {
host: 'localhost',
user: 'root',
password: '',
database: 'web'
};
const pool = mysql.createPool(dbConfig);
5.定义路由
- index路由:当用户访问根路径时,将会发送index.html作为响应
app.get('/', (req, res) => {
res.sendFile(path.join(__dirname, 'index.html'));
});
- Search路由:当用户发送搜索请求时,将执行相应的数据库查询逻辑,并将结果作为JSON响应返回。
app.get('/search', (req, res) => {
const keyword = req.query.keyword;
// Query the database for news matching the keyword
const sql = `
SELECT title, publish_date, author, keywords, url, source_name
FROM fetches
WHERE keywords LIKE '%${keyword}%'
`;
pool.query(sql, (error, results) => {
if (error) {
console.error('Error executing database query:', error);
res.status(500).json({ error: 'An error occurred' });
return;
}
const formattedResults = results.map(news => ({
...news,
publish_date: moment(news.publish_date).format('YYYY-MM-DD'),
}));
// Send the search results as JSON response
res.json(formattedResults);
});
});- Keyword Frequency路由:当用户发送关键词频率请求时,将执行相应的数据库查询逻辑,并将结果作为JSON响应返回。
app.get('/keyword-frequency', (req, res) => {
const keyword = req.query.keyword;
// Query the database for keyword frequency over time
const sql = `
SELECT DATE(publish_date) AS date, COUNT(*) AS frequency
FROM fetches
WHERE keywords LIKE '%${keyword}%'
GROUP BY DATE(publish_date)
ORDER BY DATE(publish_date) ASC
`;
pool.query(sql, (error, results) => {
if (error) {
console.error('Error executing database query:', error);
res.status(500).json({ error: 'An error occurred' });
return;
}
const keywordFrequency = results.map(result => ({
date: moment(result.date).format('YYYY-MM-DD'),
frequency: result.frequency
}));
// Send the keyword frequency data as JSON response
res.json(keywordFrequency);
});
});6.启动服务器:这行代码将在本地的3000端口上启动服务器,并打印一条消息来指示服务器已成功启动。(运行main.js并访问http://localhost:3000/)
app.listen(3000, () => {
console.log('Server started on port 3000');
});
3.2 后端实现
后端主要实现一些功能。本次实现的功能主要有:翻页与排序、根据关键词搜索新闻、对于关键词分析热度并绘画折线图。
1.翻页:规定每页只显示十条新闻,定义初始页码为1,如果新闻数多于十条则需要进行翻页。定义的变量如下:
currentPage:当前页码,初始值为1。resultsPerPage:每页显示的新闻条数。newsData:用于存储从服务器获取的新闻数据。
let currentPage = 1;
const resultsPerPage = 10;
let newsData = []; goToPrevPage() 和 goToNextPage() 函数:用于切换到上一页和下一页的搜索结果。它们会更新 currentPage 变量的值,并调用 showResults() 函数重新展示结果。
function goToPrevPage() {
if (currentPage > 1) {
currentPage--;
showResults();
}
}
function goToNextPage() {
const totalPages = Math.ceil(newsData.length / resultsPerPage);
if (currentPage < totalPages) {
currentPage++;
showResults();
}
}排序:用于将新闻以日期的正序或倒序排序。
function sortByDateAsc() {
newsData.sort((a, b) => new Date(a.publish_date) - new Date(b.publish_date));
showResults();
}
function sortByDateDesc() {
newsData.sort((a, b) => new Date(b.publish_date) - new Date(a.publish_date));
showResults();
} 2.获取关键词:当用户点击搜索按钮时调用该函数。从输入框中获取关键字,并使用 fetch() 方法发送一个异步请求到服务器的 /search 路由,携带关键字作为查询参数。然后,将服务器返回的新闻数据存储在 newsData 变量中,并调用 showResults() 函数展示搜索结果。
function searchNews() {
const keyword = document.getElementById('keyword-input').value;
fetch(`/search?keyword=${encodeURIComponent(keyword)}`)
.then(response => response.json())
.then(data => {
newsData = data;
showResults();
})
.catch(error => {
console.error('An error occurred during the search:', error);
alert('搜索过程中发生了错误');
});
}3.展示搜索结果:根据当前页码和每页显示的结果数量计算出需要显示的新闻数据范围,并将相应的数据渲染成表格形式。如果没有找到匹配的新闻,会显示一个提示信息。同时,还会根据当前页码和总页数来控制上一页和下一页按钮的可用状态。
function showResults() {
const resultContainer = document.getElementById('result-container');
const resultBody = document.getElementById('result-body');
const prevButton = document.getElementById('prev-btn');
const nextButton = document.getElementById('next-btn');
const totalPages = Math.ceil(newsData.length / resultsPerPage);
resultBody.innerHTML = '';
if (newsData.length === 0) {
resultContainer.style.display = 'none';
alert('没有找到匹配的新闻');
} else {
resultContainer.style.display = 'block';
document.querySelector('.bg').style.display = 'none'; // 隐藏图片
const startIndex = (currentPage - 1) * resultsPerPage;
const endIndex = startIndex + resultsPerPage;
for (let i = startIndex; i < endIndex && i < newsData.length; i++) {
const news = newsData[i];
const row = document.createElement('tr');
row.innerHTML = `
<td>${news.title}</td>
<td>${news.publish_date}</td>
<td>${news.author}</td>
<td>${news.keywords}</td>
<td><a href="${news.url}" target="_blank">查看详情</a></td>
<td>${news.source_name}</td>
`;
resultBody.appendChild(row);
}
prevButton.disabled = currentPage === 1;
nextButton.disabled = currentPage === totalPages;
document.querySelector('.bg').style.display = 'none'; // 显示图片
}
} 4.展示热度图:当用户点击频率图标按钮时,从输入框中获取关键字,并使用 fetch() 方法发送一个异步请求到服务器的 /keyword-frequency 路由,携带关键字作为查询参数。然后,它会将服务器返回的关键词频率数据使用 Highcharts 库创建成折线图,并展示在页面上。用户可以通过点击关闭按钮关闭图表弹窗。
function showKeywordFrequencyChart() {
const keyword = document.getElementById('keyword-input').value;
fetch(`/keyword-frequency?keyword=${encodeURIComponent(keyword)}`)
.then(response => response.json())
.then(data => {
// Create the chart
const chart = Highcharts.chart('chart-container', {
chart: { type: 'column' }, // Use 'column' as the base chart type
title: { text: '词条热度' },
xAxis: { categories: data.map(item => item.date) },
yAxis: { title: { text: '频数' } },
series: [
{ name: '频数', data: data.map(item => item.frequency), type: 'column' }, // Column series
{ name: '频数', data: data.map(item => item.frequency), type: 'line' } // Line series
]
});
// Show the popup with the chart
const popup = document.getElementById('chart-popup');
popup.style.display = 'block';
// Close the popup when the close button is clicked
const closeButton = document.getElementById('close-button');
closeButton.addEventListener('click', () => {
popup.style.display = 'none';
chart.destroy(); // Destroy the chart to release resources
});
})
.catch(error => {
console.error('An error occurred while retrieving keyword frequency:', error);
alert('获取关键词频率时发生错误');
});Highcharts是一个用纯Javascript编写的一个图表库,能够很简单便捷的在web网站或是web应用程序添加有交互性的图表,并且免费提供给个人学习、个人网站和非商业用途使用。HighCharts支持的图表类型有曲线图、区域图、柱状图、饼状图、散状点图和综合图表。
3.3 前端代码
前端代码的主要部分有输入框、按钮、表格以及弹窗。
1.输入框和两个功能按钮:
<div class="search-bar">
<input id="keyword-input" type="search" class="form-control fa-magnifying-glass" placeholder="开启吃瓜之旅"><br>
<button class="btn" onclick="searchNews()">搜索</button><br>
<button class="btn" onclick="showKeywordFrequencyChart()">查看热度</button>
</div>2.表格以及翻页按钮:
<div class="table-container" style="display: flex; align-items: center;">
<button class="btn2" id="prev-btn" style="margin-left: 10%;" onclick="goToPrevPage()"> < </button>
<table class="table">
<thead>
<tr>
<th class="table-header">题目</th>
<th class="table-header">时间
<button class="sort-btn" onclick="sortByDateAsc()">▲</button>
<button class="sort-btn" onclick="sortByDateDesc()">▼</button>
</th>
<th class="table-header">作者</th>
<th class="table-header">关键词</th>
<th class="table-header">URL</th>
<th class="table-header">来源</th>
</tr>
</thead>
<tbody id="result-body"></tbody>
</table>
<button class="btn2" id="next-btn" style="margin-right: 8%;" onclick="goToNextPage()"> > </button>
</div>3.弹窗:
<div id="chart-popup" style="display: none;">
<button id="close-button">关闭</button>
<div id="chart-container"></div>
</div> 最开始实现的效果如下: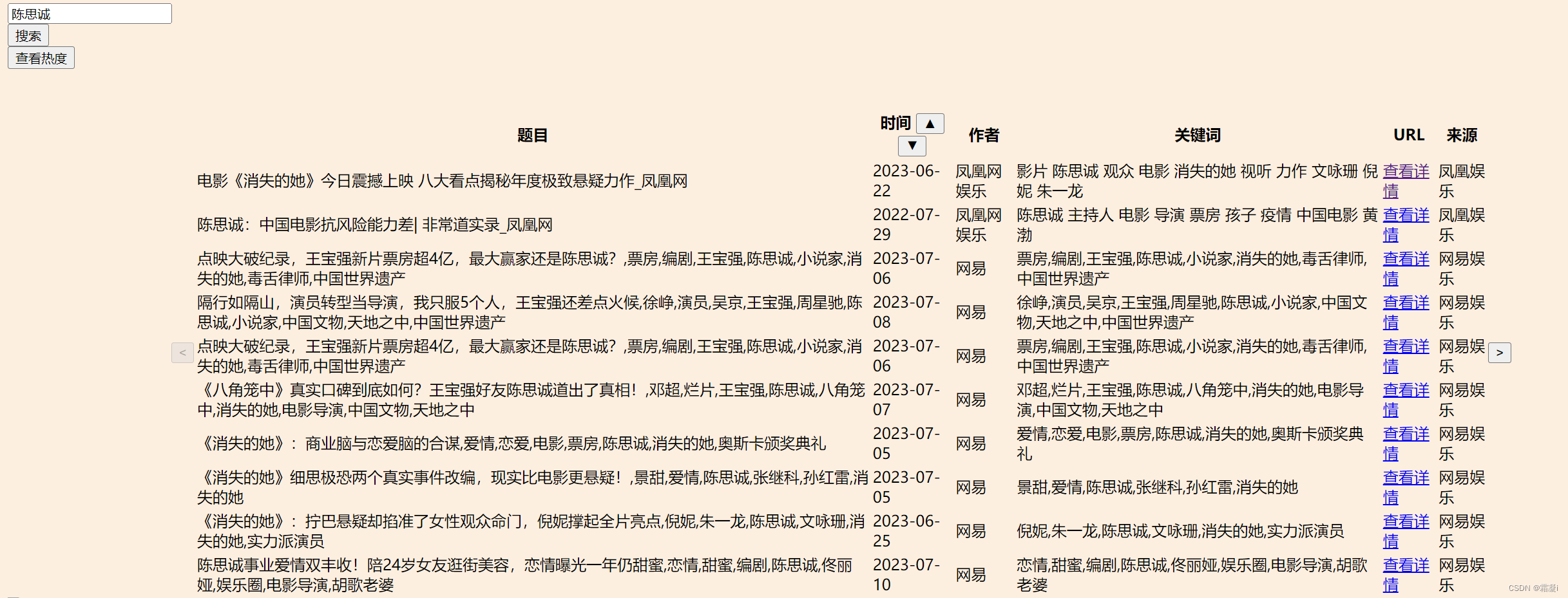
可以看出,目前的前端还比较丑陋,于是我又进行了一些美化和修饰。加了一些动画效果以及按钮触发后的效果响应。最终,静态前端如图所示

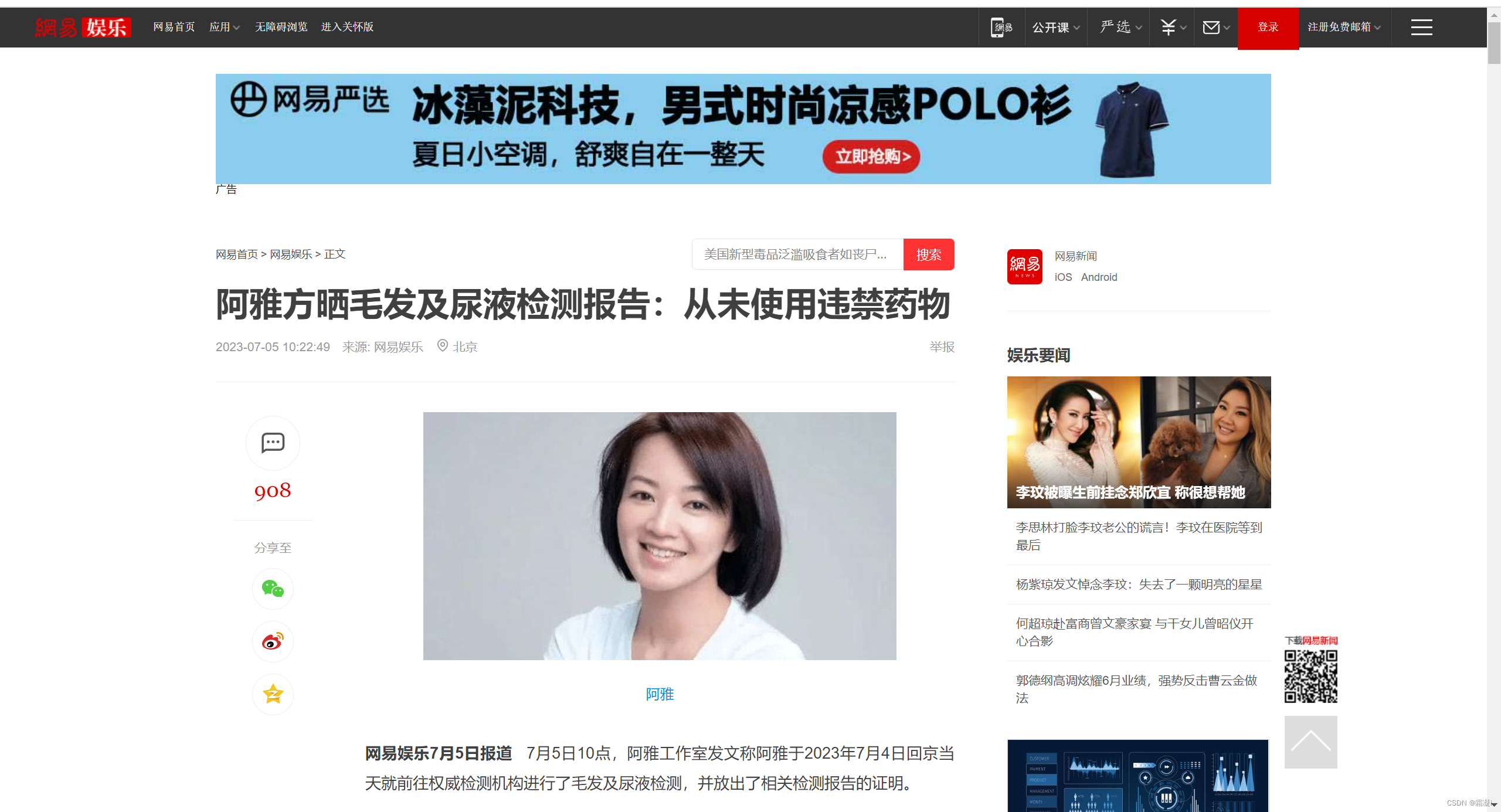
当点击搜索按钮后,背景图“吃瓜群众”的display值设为none,被隐藏掉,同时出现查找内容。
点击查看热度,会出现关键词近些天出现的次数折线与柱状图

点击“查看详情”按钮,会跳转到新闻的原界面。

最后,用一条视频展示项目的成果。
Web编程项目展示
4. 遇到的困难
-
爬取凤凰网新闻的时候下面这段代码出现了问题,没能爬取到时间。
const date_format = "$('meta[name=\"og:time\"]').eq(0).attr(\"content\")";可以看到,网页的源代码是这样的

乍一看og:time是没问题的,但其实,在time的后面有一个空格,只需要把"og:time"变成"og:time ",就可以了
const date_format = "$('meta[name=\"og:time \"]').eq(0).attr(\"content\")";2. 凤凰网的格式非常不利于观察,所有代码都在同一行,造成了巨大的困扰,不建议我的学弟学妹爬取这个网站的内容。
3. 我是使用Webstorm进行编程设计的,但是如果我直接在Webstorm中运行,呈现的效果是这样的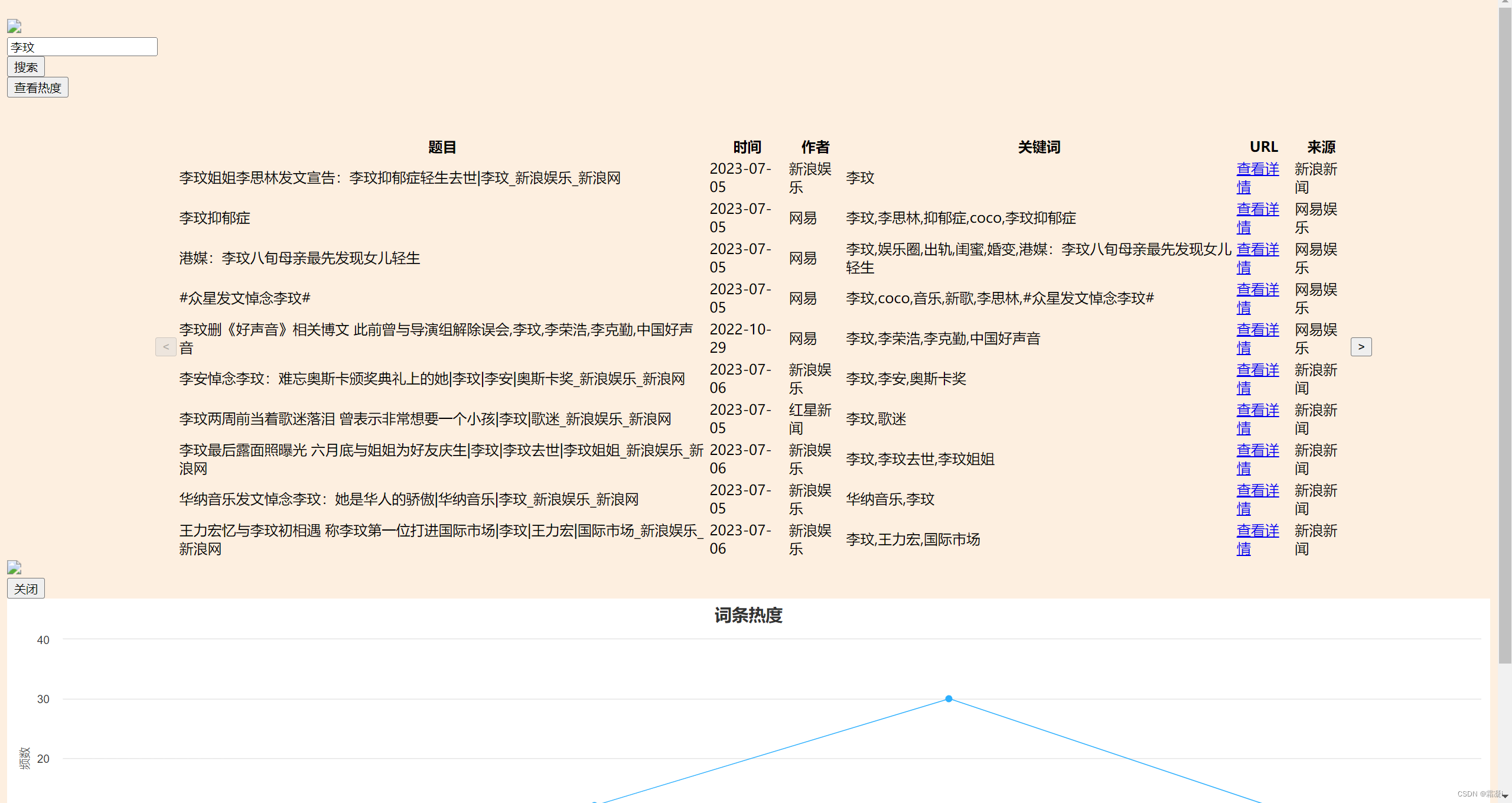
可以理解为,我的静态文件访问失败,所以只能显示出html中的内容,无法链接到css和js中的内容和功能。这个问题无法确定真实的原因是什么,猜测可能是Webstorm有自己的搭建方式,导致出现了路径问题,无法找到我的静态文件。如果有大佬愿意解答欢迎在评论区留下你的解答,不胜感激~。
最后的解决方法是:在terminal中运行。很呆,但有效。

4. 爬虫不免会被封......最开始我想爬取中娱网 - 领先的娱乐资讯网站,结果刚爬了一条新闻就被封了(如果非爬不可可以换IP)。第一次爬虫能力毕竟有限,不如选其他的网站进行爬取。
5.感想
本次项目完成了用Nodejs实现爬虫爬取新闻,存入mysql数据库并使用express框架搭建网站并进行时间热度分析。我学到了正则表达式以及如何从要爬取网站的源代码分析要爬取的内容应该如何获取,怎么将前后端功能链接起来,将数据从数据库中取出并加以利用,前端的美化等等。总体来说,本次项目的制作还算顺利,感谢老师和助教的帮助。也希望这篇文章能够帮助到初次搭建网站的朋友们。
源码已上传至Github:GitHub - TheadoraTang/Web: 华东师范大学数据科学与工程学院Web编程项目















 321
321











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









