







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前在阿里
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

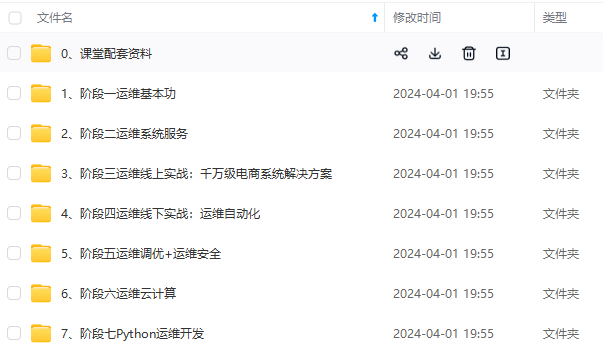
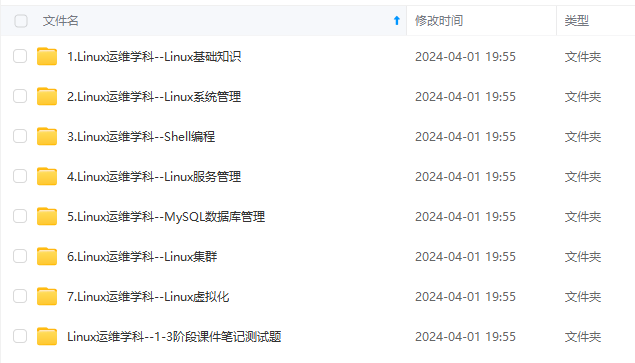
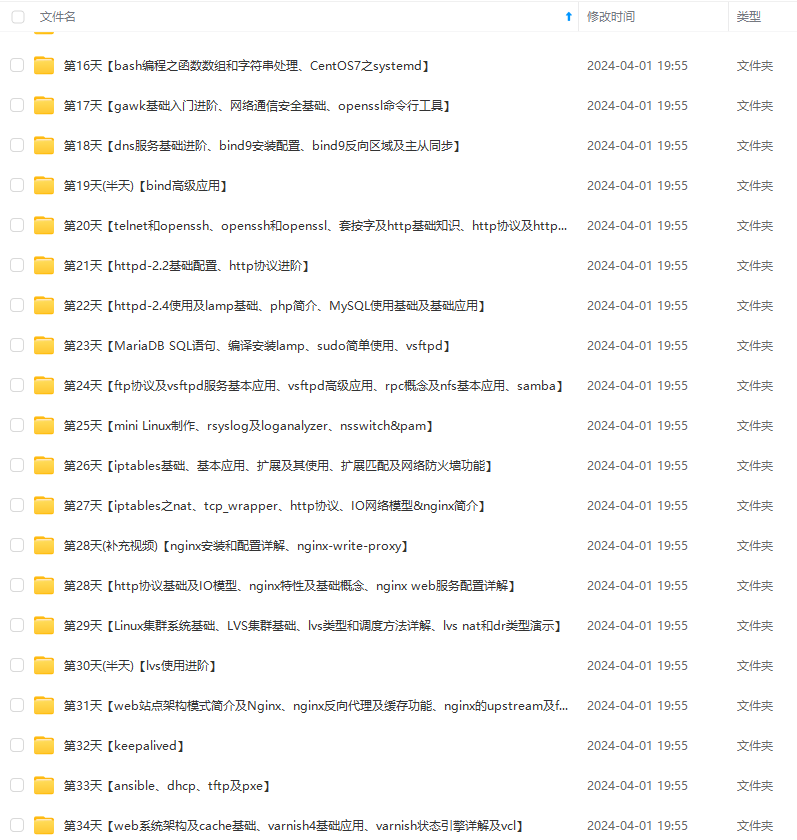
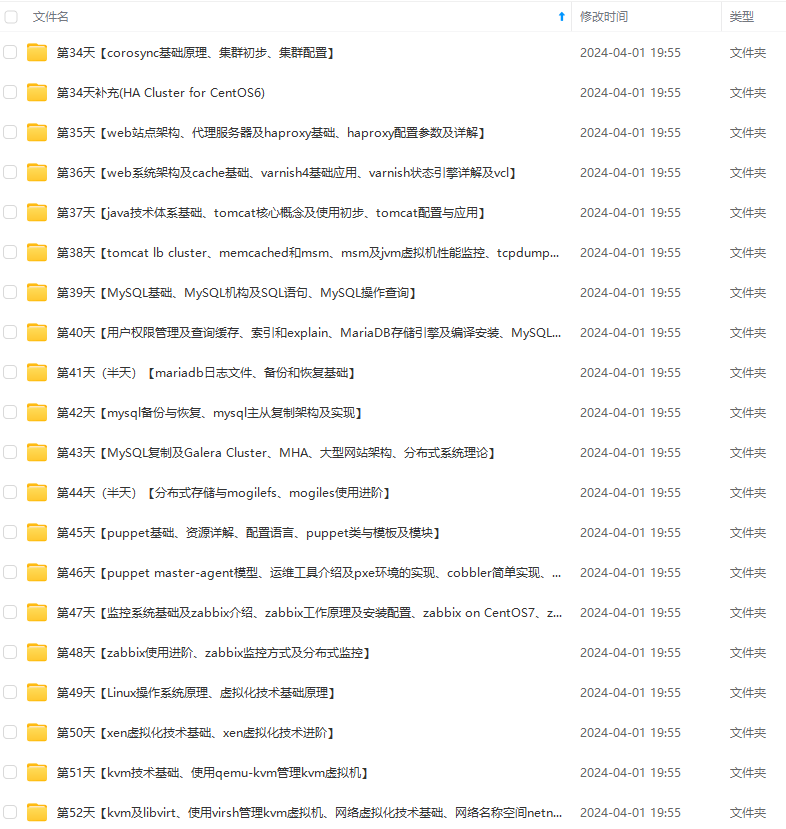
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上运维知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
dec9ae2c2d21 prom/node-exporter “/bin/node_exporter …” 9 minutes ago Up 9 minutes ceph-55e5485a-b292-11ea-8087-000c2993d00b-node-exporter.node1
78f3e297aa77 prom/prometheus:latest “/bin/prometheus --c…” 9 minutes ago Up 9 minutes ceph-55e5485a-b292-11ea-8087-000c2993d00b-prometheus.node1
此时已经运行了以下组件
* ceph-mgr ceph管理程序
* ceph-monitor ceph监视器
* ceph-crash 崩溃数据收集模块
* prometheus prometheus监控组件
* grafana 监控数据展示dashboard
* alertmanager prometheus告警组件
* node\_exporter prometheus节点数据收集组件
请参阅下面的一些对某些用户可能有用的选项,或者运行cephadm bootstrap -h命令查看所有可用选项:
* 为了方便起见,Bootstrap会将访问新集群所需的文件写入/etc/ceph,以便主机上安装的任何Ceph软件包(例如,访问命令行界面)都可以轻松找到它们。
* 但是使用cephadm部署的daemon容器根本不需要/etc/ceph。避免与同一主机上的现有Ceph配置(cephadm或其他方式)存在潜在冲突,可以使用–output-dir 选项将它们放置在不同的目录中。
* 可以使用–config选项将任何初始Ceph配置选项传递到新集群,方法是将它们放在标准ini样式的配置文件中。
查看所有组件运行状态
[root@node1 ~]# ceph orch ps
查看某个组件运行状态
[root@node1 ~]# ceph orch ps --daemon-type mds
NAME HOST STATUS REFRESHED AGE VERSION IMAGE NAME IMAGE ID CONTAINER ID
mds.cephfs.node1.qahxbq node1 running (27m) 42s ago 27m 15.2.3 docker.io/ceph/ceph:v15 d72755c420bc 5aa9e4f2f3f7
mds.cephfs.node2.djktgx node2 running (27m) 40s ago 27m 15.2.3 docker.io/ceph/ceph:v15 d72755c420bc 064fc7ff6873
mds.cephfs.node3.vmcgpb node3 running (27m) 39s ago 27m 15.2.3 docker.io/ceph/ceph:v15 d72755c420bc ef24629708c0
[root@node1 ~]# ceph orch ps --daemon-type mgr
NAME HOST STATUS REFRESHED AGE VERSION IMAGE NAME IMAGE ID CONTAINER ID
mgr.node1.dzrkgj node1 running (54m) 50s ago 89m 15.2.3 docker.io/ceph/ceph:v15 d72755c420bc 551cd88bb48a
mgr.node2.dygsih node2 running (54m) 48s ago 59m 15.2.3 docker.io/ceph/ceph:v15 d72755c420bc 1f146b9e8b33
根据初始化完成的提示使用浏览器访问dashboard
…
INFO:cephadm:Creating initial admin user…
INFO:cephadm:Fetching dashboard port number…
INFO:cephadm:Ceph Dashboard is now available at:
URL: https://node1:8443/
User: admin
Password: nfyee637l9
INFO:cephadm:You can access the Ceph CLI with:
sudo /usr/sbin/cephadm shell --fsid 55e5485a-b292-11ea-8087-000c2993d00b -c /etc/ceph/ceph.conf -k /etc/ceph/ceph.client.admin.keyring
INFO:cephadm:Please consider enabling telemetry to help improve Ceph:
ceph telemetry on
For more information see:
https://docs.ceph.com/docs/master/mgr/telemetry/
INFO:cephadm:Bootstrap complete.
修改密码后登录到ceph dashboard

### 启用CEPH命令
无特殊说明,以下所有操作在node1节点执行。
cephadm shell命令在安装了所有Ceph包的容器中启动bash shell。默认情况下,如果在主机上的/etc/ceph中找到配置和keyring文件,则会将它们传递到容器环境中,以便shell完全正常工作。注意,在MON主机上执行时,cephadm shell将从MON容器推断配置,而不是使用默认配置。如果给定–mount
,则主机
(文件或目录)将显示在容器中的/mnt下:
[root@node1 ceph]# cephadm shell
INFO:cephadm:Inferring fsid 55e5485a-b292-11ea-8087-000c2993d00b
INFO:cephadm:Using recent ceph image ceph/ceph:v15
[ceph: root@node1 /]# ceph status
cluster:
id: 55e5485a-b292-11ea-8087-000c2993d00b
health: HEALTH_WARN
Reduced data availability: 1 pg inactive
OSD count 0 < osd_pool_default_size 3
services:
mon: 1 daemons, quorum node1 (age 2m)
mgr: node1.dzrkgj(active, since 2m)
osd: 0 osds: 0 up, 0 in
data:
pools: 1 pools, 1 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs: 100.000% pgs unknown
1 unknown
创建别名可能会有所帮助(省略):
alias ceph=‘cephadm shell – ceph’
可以安装ceph-common包,里面包含了所有的ceph命令,其中包括ceph,rbd,mount.ceph(用于安装CephFS文件系统)等:
cephadm add-repo --release octopus
cephadm install ceph-common
如果安装较慢,可以尝试使用阿里云ceph源
cp /etc/yum.repos.d/ceph.repo{,.bak}
cat > ceph.repo << ‘EOF’
[Ceph]
name=Ceph
b
a
s
e
a
r
c
h
b
a
s
e
u
r
l
=
h
t
t
p
:
/
/
m
i
r
r
o
r
s
.
a
l
i
y
u
n
.
c
o
m
/
c
e
p
h
/
r
p
m
−
o
c
t
o
p
u
s
/
e
l
8
/
basearch baseurl=http://mirrors.aliyun.com/ceph/rpm-octopus/el8/
basearchbaseurl=http://mirrors.aliyun.com/ceph/rpm−octopus/el8/basearch
enabled=1
gpgcheck=1
gpgkey=http://mirrors.aliyun.com/ceph/keys/release.asc
[Ceph-noarch]
name=Ceph noarch
baseurl=http://mirrors.aliyun.com/ceph/rpm-octopus/el8/noarch
enabled=1
gpgcheck=1
gpgkey=http://mirrors.aliyun.com/ceph/keys/release.asc
[Ceph-source]
name=Ceph SRPMS
baseurl=http://mirrors.aliyun.com/ceph/rpm-octopus/el8/SRPMS
enabled=1
gpgcheck=1
gpgkey=http://mirrors.aliyun.com/ceph/keys/release.asc
EOF
使用以下`ceph`命令确认该命令是否可访问:
[root@node1 ~]# ceph -v
ceph version 15.2.3 (d289bbdec69ed7c1f516e0a093594580a76b78d0) octopus (stable)
通过以下`ceph`命令确认命令可以连接到集群及显示状态:
[root@node1 ~]# ceph status
cluster:
id: 55e5485a-b292-11ea-8087-000c2993d00b
health: HEALTH_WARN
Reduced data availability: 1 pg inactive
OSD count 0 < osd_pool_default_size 3
services:
mon: 1 daemons, quorum node1 (age 3m)
mgr: node1.dzrkgj(active, since 2m)
osd: 0 osds: 0 up, 0 in
data:
pools: 1 pools, 1 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs: 100.000% pgs unknown
1 unknown
### 将主机添加到集群中
要将新主机添加到群集,请执行两个步骤:
在新主机的根用户`authorized_keys`文件中安装集群的公共SSH密钥:
ssh-copy-id -f -i /etc/ceph/ceph.pub root@node2
ssh-copy-id -f -i /etc/ceph/ceph.pub root@node3
告诉Ceph,新节点是集群的一部分:
[root@node1 ~]# ceph orch host add node2
Added host ‘node2’
[root@node1 ~]# ceph orch host add node3
Added host ‘node3’
查看ceph纳管的所有节点
[root@node1 ~]# ceph orch host ls
HOST ADDR LABELS STATUS
node1 node1
node2 node2
node3 node3
添加完成后ceph会自动扩展monitor和manager到另外2个节点,在另外2个节点查看,自动运行了以下容器
[root@node2 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
41b9e0ab5595 prom/node-exporter “/bin/node_exporter …” About a minute ago Up About a minute ceph-55e5485a-b292-11ea-8087-000c2993d00b-node-exporter.node2
ecca97ca8f93 ceph/ceph:v15 “/usr/bin/ceph-mon -…” About a minute ago Up About a minute ceph-55e5485a-b292-11ea-8087-000c2993d00b-mon.node2
d3ae9d560599 ceph/ceph:v15 “/usr/bin/ceph-mgr -…” About a minute ago Up About a minute ceph-55e5485a-b292-11ea-8087-000c2993d00b-mgr.node2.dygsih
e24c7ea4157a ceph/ceph:v15 “/usr/bin/ceph-crash…” 2 minutes ago Up 2 minutes ceph-55e5485a-b292-11ea-8087-000c2993d00b-crash.node2
查看ceph集群状态
[root@node1 ~]# ceph -s
cluster:
id: 55e5485a-b292-11ea-8087-000c2993d00b
health: HEALTH_WARN
Reduced data availability: 1 pg inactive
OSD count 0 < osd_pool_default_size 3
services:
mon: 3 daemons, quorum node1,node2,node3 (age 2m)
mgr: node1.dzrkgj(active, since 16m), standbys: node2.dygsih
osd: 0 osds: 0 up, 0 in
data:
pools: 1 pools, 1 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs: 100.000% pgs unknown
1 unknown
### 部署其他Monitors(可选)
本节以下操作可全部忽略,ceph已自动扩展mon和mgr,下面是定制扩容的操作。
一个典型的Ceph集群具有三个或五个分布在不同主机上的Monitors守护程序。如果群集中有五个或更多节点,我们建议部署五个Monitors。
当Ceph知道Monitors应该使用哪个IP子网时,它可以随着群集的增长(或收缩)自动部署和扩展Monitors。默认情况下,Ceph假定其他Monitor应使用与第一台Monitor IP相同的子网。
如果Ceph Monitor(或整个群集)位于单个子网中,则默认情况下,当向群集中添加新主机时,cephadm会自动最多添加5个监视器。无需其他步骤。
如果存在Monitors应使用的特定IP子网,则可以使用以下命令以[CIDR]( )格式(例如`10.1.2.0/24`)配置该IP子网:
ceph config set mon public_network **
例如:
ceph config set mon public_network 10.1.2.0/24
Cephadm仅在已在配置的子网中配置了IP的主机上部署新的monitor守护程序。
如果要调整5个monitor的默认值:
ceph orch apply mon **
要将monitor部署在一组特定的主机上:
ceph orch apply mon *<host1,host2,host3,…>*
确保在此列表中包括第一台(引导)主机。
可以通过使用主机标签来控制运行monitor的主机。要将`mon`标签设置为适当的主机,执行以下命令:
ceph orch host label add ** mon
要查看当前的主机和标签:
ceph orch host ls
例如:
ceph orch host label add host1 mon
ceph orch host label add host2 mon
ceph orch host label add host3 mon
ceph orch host ls
HOST ADDR LABELS STATUS
host1 mon
host2 mon
host3 mon
host4
host5
告诉cephadm根据标签部署monitor:
ceph orch apply mon label:mon
可以为每个monitor显式指定IP地址或CIDR网络,并控制其放置位置。要禁用自动monitor部署:
ceph orch apply mon --unmanaged
要部署每个其他monitor:
ceph orch daemon add mon *host1:ip-or-network1 [host1:ip-or-network-2…]*
例如,要在`newhost1`IP地址`10.1.2.123`上部署第二台监视器,并`newhost2`在网络`10.1.2.0/24`中部署第三台monitor:
ceph orch apply mon --unmanaged
ceph orch daemon add mon newhost1:10.1.2.123
ceph orch daemon add mon newhost2:10.1.2.0/24
### 部署OSD
所有群集主机上的存储设备清单可以显示为:
ceph orch device ls
如果满足以下所有条件,则认为存储设备*可用*:
* 设备必须没有分区。
* 设备不得具有任何LVM状态。
* 不得安装设备。
* 该设备不得包含文件系统。
* 该设备不得包含Ceph BlueStore OSD。
* 设备必须大于5 GB。
Ceph拒绝在不可用的设备上配置OSD。
有几种创建新OSD的方法:
告诉Ceph使用任何可用和未使用的存储设备(可能是bug没有显示任何信息,选择手动添加osd):
ceph orch apply osd --all-available-devices
从特定主机上的特定设备创建OSD:
[root@node1 ~]# ceph orch daemon add osd node1:/dev/sdb
Created osd(s) 0 on host ‘node1’
[root@node1 ~]# ceph orch daemon add osd node2:/dev/sdb
Created osd(s) 1 on host ‘node2’
[root@node1 ~]# ceph orch daemon add osd node3:/dev/sdb
Created osd(s) 2 on host ‘node3’
[root@node1 ~]# ceph orch device ls
HOST PATH TYPE SIZE DEVICE AVAIL REJECT REASONS
node1 /dev/sda hdd 60.0G False LVM detected, locked, Insufficient space (<5GB) on vgs
node1 /dev/sdb hdd 20.0G False LVM detected, locked, Insufficient space (<5GB) on vgs
node2 /dev/sda hdd 60.0G False LVM detected, locked, Insufficient space (<5GB) on vgs
node2 /dev/sdb hdd 20.0G False LVM detected, locked, Insufficient space (<5GB) on vgs
node3 /dev/sda hdd 60.0G False LVM detected, locked, Insufficient space (<5GB) on vgs
node3 /dev/sdb hdd 20.0G False LVM detected, locked, Insufficient space (<5GB) on vgs
查看集群状态
[root@node1 ~]# ceph -s
cluster:
id: 55e5485a-b292-11ea-8087-000c2993d00b
health: HEALTH_OK
services:
mon: 3 daemons, quorum node1,node2,node3 (age 4m)
mgr: node1.dzrkgj(active, since 4m), standbys: node2.dygsih
osd: 3 osds: 3 up (since 85s), 3 in (since 85s)
data:
pools: 1 pools, 1 pgs
objects: 0 objects, 0 B
usage: 3.0 GiB used, 57 GiB / 60 GiB avail
pgs: 1 active+clean
也可以使用[OSD服务规范]( )基于设备的属性来描述要使用的设备,例如设备类型(SSD或HDD),设备型号名称,大小或设备所在的主机:
ceph orch apply osd -i spec.yml
### 部署的MDS
要使用CephFS文件系统,需要一个或多个MDS守护程序。如果使用较新的界面来创建新的文件系统,则会自动创建这些文件。有关更多信息,请参见[FS卷和子卷]( )。`cephfsvolume`
部署元数据服务器
[root@node1 ~]# ceph osd pool create cephfs_data 64 64
pool ‘cephfs_data’ created
[root@node1 ~]# ceph osd pool create cephfs_metadata 64 64
pool ‘cephfs_metadata’ created
[root@node1 ~]# ceph fs new cephfs cephfs_metadata cephfs_data
new fs with metadata pool 3 and data pool 2
[root@node1 ~]# ceph fs ls
name: cephfs, metadata pool: cephfs_metadata, data pools: [cephfs_data ]
[root@node1 ~]# ceph orch apply mds cephfs --placement=“3 node1 node2 node3”
查看节点各启动了一个mds容器
[root@node1 ~]# docker ps | grep mds
5aa9e4f2f3f7 ceph/ceph:v15 “/usr/bin/ceph-mds -…” 58 seconds ago Up 57 seconds ceph-55e5485a-b292-11ea-8087-000c2993d00b-mds.cephfs.node1.qahxbq
查看集群状态
[root@node1 ~]# ceph -s
cluster:
id: 55e5485a-b292-11ea-8087-000c2993d00b
health: HEALTH_OK
services:
mon: 3 daemons, quorum node1,node2,node3 (age 30m)
mgr: node1.dzrkgj(active, since 30m), standbys: node2.dygsih
mds: cephfs:1 {0=cephfs.node2.djktgx=up:active} 2 up:standby
osd: 3 osds: 3 up (since 27m), 3 in (since 27m)
task status:
scrub status:
mds.cephfs.node2.djktgx: idle
data:
pools: 3 pools, 81 pgs
objects: 22 objects, 2.2 KiB
usage: 3.1 GiB used, 57 GiB / 60 GiB avail
pgs: 81 active+clean
### 部署RGWS
Cephadm将radosgw部署为管理特定*领域*和*区域*的守护程序的集合。(有关领域和区域的更多信息,请参见[Multi-Site]( )。)
请注意,使用cephadm时,radosgw守护程序是通过监视器配置数据库而不是通过ceph.conf或命令行来配置的。如果该配置尚未就绪(通常在本`client.rgw.<realmname>.<zonename>`节中),那么radosgw守护程序将使用默认设置(例如,绑定到端口80)启动。
例如,要在node1、node2和node3上部署3个服务于*myorg*领域和*us-east-1*区域的rgw守护程序:
#如果尚未创建领域,请首先创建一个领域:
radosgw-admin realm create --rgw-realm=myorg --default
#接下来创建一个新的区域组:
radosgw-admin zonegroup create --rgw-zonegroup=default --master --default
#接下来创建一个区域:
radosgw-admin zone create --rgw-zonegroup=default --rgw-zone=cn-east-1 --master --default
#为特定领域和区域部署一组radosgw守护程序:
ceph orch apply rgw myorg cn-east-1 --placement=“3 node1 node2 node3”
查看服务状态
[root@node1 ~]# docker ps | grep rgw
78f9a9dfc46c ceph/ceph:v15 “/usr/bin/radosgw -n…” 2 hours ago Up 2 hours ceph-55e5485a-b292-11ea-8087-000c2993d00b-rgw.myorg.cn-east-1.node1.yjurkc
[root@node1 ~]# ceph orch ls | grep rgw
rgw.myorg.cn-east-1 3/3 6m ago 2h count:3 node1,node2,node3 docker.io/ceph/ceph:v15 d72755c420bc
### 部署NFS Ganesha
Cephadm使用预定义的RADOS*池*和可选的namespace部署NFS Ganesha
要部署NFS Ganesha网关,请执行以下操作:
例如,同一个服务ID部署NFS*FOO*,将使用RADOS池*NFS的象头*和命名空间*NFS-NS*,:
ceph osd pool create nfs-ganesha 64 64
ceph orch apply nfs foo nfs-ganesha nfs-ns --placement=“3 node1 node2 node3”
ceph osd pool application enable nfs-ganesha cephfs
查看容器和服务
[root@node1 ~]# docker ps | grep nfs
b89fe9bb981d ceph/ceph:v15 “/usr/bin/ganesha.nf…” About a minute ago Up About a minute ceph-55e5485a-b292-11ea-8087-000c2993d00b-nfs.foo.node1
[root@node1 ~]# ceph orch ls | grep nfs
nfs.foo 3/3 2m ago 2m count:3 node1,node2,node3 docker.io/ceph/ceph:v15 d72755c420bc
### 部署自定义容器
不清楚要表达什么。
也可以选择与默认容器不同的容器来部署Ceph。有关这方面选项的信息,请参阅[Ceph容器映像]( )。
最后查看所有服务
[root@node1 ~]# ceph orch ls
NAME RUNNING REFRESHED AGE PLACEMENT IMAGE NAME IMAGE ID
alertmanager 1/1 7m ago 3h count:1 prom/alertmanager c876f5897d7b
crash 3/3 7m ago 3h * docker.io/ceph/ceph:v15 d72755c420bc
grafana 1/1 7m ago 3h count:1 ceph/ceph-grafana:latest 87a51ecf0b1c
mds.cephfs 3/3 7m ago 2h count:3 node1,node2,node3 docker.io/ceph/ceph:v15 d72755c420bc
mgr 2/2 7m ago 3h count:2 docker.io/ceph/ceph:v15 d72755c420bc
mon 3/5 7m ago 3h count:5 docker.io/ceph/ceph:v15 d72755c420bc
nfs.foo 3/3 7m ago 38m count:3 node1,node2,node3 docker.io/ceph/ceph:v15 d72755c420bc
node-exporter 3/3 7m ago 3h * prom/node-exporter 0e0218889c33
osd.all-available-devices 0/3 - - *
prometheus 1/1 7m ago 3h count:1 prom/prometheus:latest 396dc3b4e717
rgw.myorg.cn-east-1 3/3 7m ago 2h count:3 node1,node2,node3 docker.io/ceph/ceph:v15 d72755c420bc
[root@node1 ~]#
查看集群健康状态
[root@node1 ~]# ceph -s
cluster:
id: 55e5485a-b292-11ea-8087-000c2993d00b
health: HEALTH_OK
services:
mon: 3 daemons, quorum node1,node2,node3 (age 44m)
mgr: node1.dzrkgj(active, since 44m), standbys: node2.dygsih
mds: cephfs:1 {0=cephfs.node2.djktgx=up:active} 2 up:standby
osd: 3 osds: 3 up (since 2h), 3 in (since 2h)
rgw: 3 daemons active (myorg.cn-east-1.node1.yjurkc, myorg.cn-east-1.node2.yiahpt, myorg.cn-east-1.node3.delvkm)
task status:
scrub status:
mds.cephfs.node2.djktgx: idle
data:
pools: 8 pools, 249 pgs
objects: 258 objects, 8.4 KiB
usage: 3.2 GiB used, 57 GiB / 60 GiB avail
pgs: 249 active+clean
io:
client: 76 KiB/s rd, 0 B/s wr, 75 op/s rd, 50 op/s wr
查看osd状态
[root@node1 ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.05846 root default
-3 0.01949 host node1
0 hdd 0.01949 osd.0 up 1.00000 1.00000
-5 0.01949 host node2
1 hdd 0.01949 osd.1 up 1.00000 1.00000
-7 0.01949 host node3
2 hdd 0.01949 osd.2 up 1.00000 1.00000
查看ceph dashboard

### 查看prometheus监控信息
ceph grafana登录
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化的资料的朋友,可以点击这里获取!](https://bbs.csdn.net/topics/618635766)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
0.01949 osd.0 up 1.00000 1.00000
-5 0.01949 host node2
1 hdd 0.01949 osd.1 up 1.00000 1.00000
-7 0.01949 host node3
2 hdd 0.01949 osd.2 up 1.00000 1.00000
查看ceph dashboard

查看prometheus监控信息
ceph grafana登录
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 810
810











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









