







- 其他数据库的同步操作
1.点击 Tapdata Cloud 操作后台左侧菜单栏的【连接管理】,然后点击右侧区域【连接列表】右上角的【创建连接】按钮,打开连接类型选择页面,然后选择MySQL
2.在打开的连接信息配置页面依次输入需要的配置信息
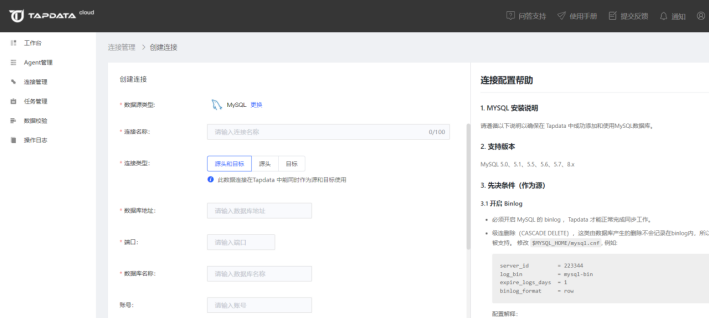
【连 接 名 称】:设置连接的名称,多个连接的名称不能重复
【数据库地址】:数据库 IP / Host
【端 口】:数据库端口
【数据库名称】:tapdata 数据库连接是以一个 db 为一个数据源。这里的 db 是指一个数据库实例中的 database,而不是一个 mysql 实例。
【账 号】:可以访问数据库的账号
【密 码】:数据库账号对应的密码
【时 间 时 区】:默认使用该数据库的时区;若指定时区,则使用指定后的时区设置
3.测试连接,提示测试通过
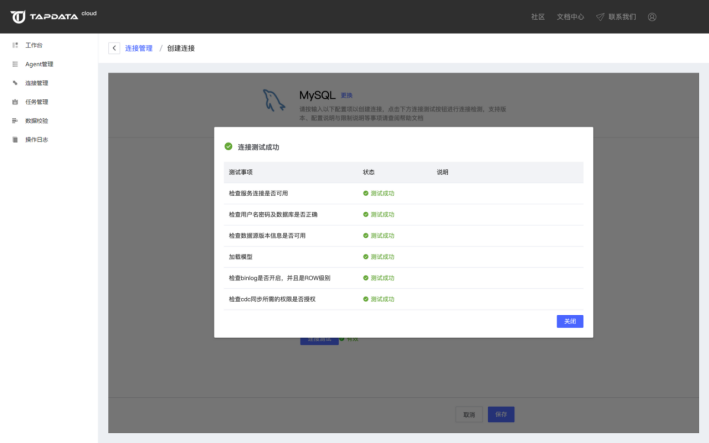
4.测试通过后保存连接即可。
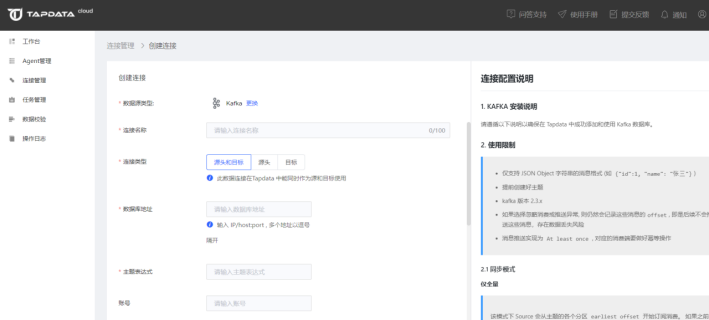
1.同第一步操作,点击左侧菜单栏的【连接管理】,然后点击右侧区域【连接列表】右上角的【创建连接】按钮,打开连接类型选择页面,然后选择 Kafka
2.在打开的连接信息配置页面依次输入需要的配置信息,配置完成后测试连接保存即可。
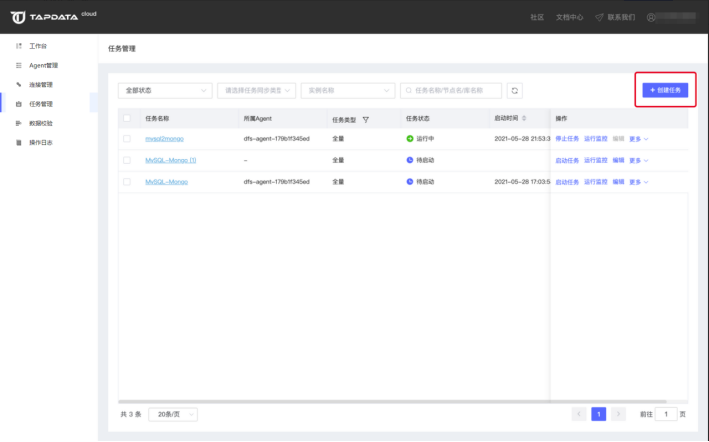
进入Tapdata Cloud 操作后台任务管理页面,点击添加任务按钮进入任务设置流程
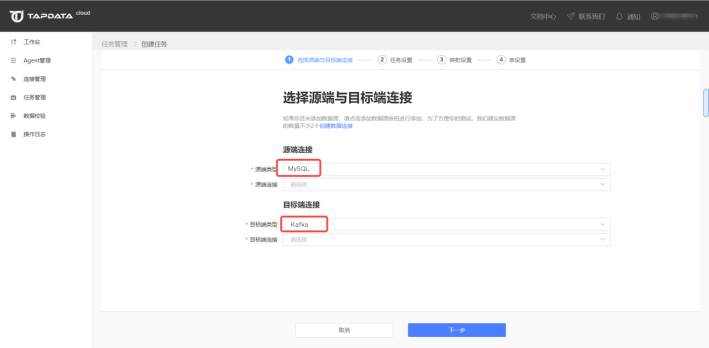
根据刚才建好的连接,选定源端与目标端。
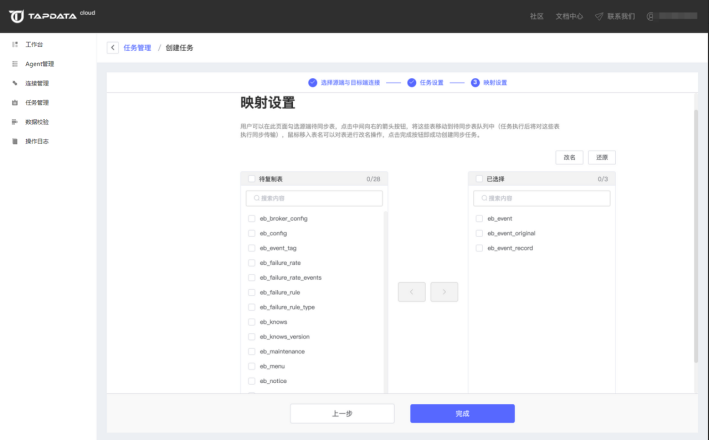
根据数据需求,选择需要同步的库、表,如果你对表名有修改需要,可以通过页面中的表名批量修改功能对目标端的表名进行批量设置
在以上选项设置完毕后,下一步选择同步类型,平台提供全量同步、增量同步、全量+增量同步,设定写入模式和读取数量。
如果选择的是全量+增量同步,在全量任务执行完毕后,Tapdata Agent 会自动进入增量同步状态。在该状态中,Tapdata Agent 会持续监听源端的数据变化(包括:写入、更新、删除),并实时的将这些数据变化写入目标端。
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数初中级Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Python爬虫全套学习资料》送给大家,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频
如果你觉得这些内容对你有帮助,可以添加下面V无偿领取!(备注:python)

时减轻大家的负担。**
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频
如果你觉得这些内容对你有帮助,可以添加下面V无偿领取!(备注:python)
[外链图片转存中…(img-SW5zjMM7-1710868943099)]














 1004
1004











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









