







**注:在2.x中,上述命令可以直接运行,在3.x中,reduce函数已经被移除了全局命名空间,置于fuctools库中,可通过from fuctools import reduce引入reduce。**
上述代码也可用循环语句写成:
s=1
for i in range(1,n+1):
s=s*i
d、filter()函数:它是一个过滤器,用于筛选列表中符合条件的元素。例如:
b=filter(lambda x : x>5 and x<8,range(10))
b=list(b)
print(b) #结果为[6, 7]
上述语句也可以用列表解析写出:
b=[i for i in range(10) if i>5 and i<8]
我们使用map()、reduce()、filter()最终的目的是兼顾简洁和效率,因为map()、reduce()、filter()的循环速度比Python内置的while和for循环快的多。
#### (4)库的导入和添加
##### 1.库的导入:例如:导入math库
import math
math.sin(1) #计算正弦
math.exp(1) #计算指数
math.pi #内置的圆周率常数
重命名库:
import math as m
m.sin(1)
指定导入某个函数:
from math import exp as e
e(1) help(‘modules’) #获得已安装的所有模块名
##### 2.导入futurn特征
使用2.x的用户可以通过引入futurn特征的方式兼容代码,如:
#将print变成函数形式,即用print(a)的方式输出:
from futurn import print_function
#3.x的3/2=1.5,3//2=1;2.x的3/2=1
from futurn import division
##### 3.添加第三方库
以安装pandas为例:
打开cmd,输入 pip install pandas,点击回车即可
### 2.3 Python数据分析工具
###### Python数据挖掘相关扩展库
* numpy:提供数组支持,以及相应的高效的处理函数
* sicpy:提供矩阵支持,以及矩阵相关的数值计算模块
* matplotlib:强大的数据可视化工具、作图库
* pandas:强大、灵活的数据分析和探索工具
* statsmodels:统计建模和计量经济学,包括描述统计、统计模型估计和推断
* scikit-learn:支持回归、分类、聚类等的强大的机器学习库
* keras:深度学习库,用于建立神经网络以及深度学习模型
* gensim:用来做文本主题模型的库,文本挖掘可以用到
#### 2.3.1 numpy
Python并没有提供真正的数组功能,而numpy则提供了真正的数组功能,它还是很多更高级库的依赖库,,例如scipy、matplotlib、pandas等。numpy内置函数的处理速度是C语言级别的,因此在编写函数的时候应当尽量的使用它们内置的函数,避免出现效率瓶颈的问题(尤其是涉及循环问题)。
安装numpy:
pip install numpy #在Windows中可以像安装其他第三方库一样用pip完成 python setup.py install #Windows还可自行下载源代码,然后用此代码安装 sudo apt-get install python-numpy #在Linux的Ubuntu下安装
numpy的基本操作:
#-*- coding :utf-8 -*
import numpy as np #一般用np作为numpy的别名
a = np.array([2,0,1,5]) #创建数组
print(a) #打印结果
print(a[:3]) #引用前3个数字(切片)
print(a.min()) #输出a的最小值
a.sort() #将a的元素从小到大排列,此操作直接修改a,print(a)为[0,1,2,5]
print(a)
b = np.array([[1,2,3],[4,5,6]]) #创建二维数组
print(b*b) #输出数组的平方阵[[1,4,9],[16,25,36]]
numpy官网:[http://www.numpy.org/]( )或者[http://reverland.org/python/2012/08/12/numpy/]( )
#### 2.3.2 SciPy
SciPy包含的功能有最优化、线性代数、几份、插值、拟合、特殊函数、快速傅里叶变换、信号处理和图像处理、常微分方程求解和其他科学与工程中常用的计算。SciPy依赖于numpy,因此安装它之前需要先安装numpy,安装scipy和安装numpy在Windows平台上是一样的,直接用pip进行安装即可,sudo apt-get install python-scipy 在Linux的Ubuntu下安装。
SciPy求解非线性方程组和数值积分:
#-*-coding:utf-8 -*
#求解非线性方程组2x1-x22=1,x12-x2=2
from scipy.optimize import fsolve #导入求解方程组的函数
def f(x): #定义要求解的方程组
x1=x[0]
x2=x[1]
return [2*x1-x2**2-1,x1**2-x2-2]
result = fsolve(f,[1,1]) #输出初值[1,1]并求解
print(result) #数值积分
from scipy import integrate #导入积分函数
def g(x): #定义被积函数
return (1-x**2)**0.5
pi_2,err = integrate.quad(g,-1,1) #积分结果和误差
print(pi_2*2) #有微积分知识知道积分结果为圆周率pi的一半
#### 2.3.3 Matplotlib
主要用于绘制二维图,也可以进行简单的三维绘图。安装方法也和上述两个库的安装方法一致。
**注:matplotlib对上级库的依赖较多,手动安装的时候需要吧这些库也逐一安装完成**
matplotlib绘图的基本代码:
#-*-coding:utf-8 -*
import numpy as np
import matplotlib.pyplot as plt #导入matplotlib
x = np.linspace(0,10,1000) #作图的变量自变量
y = np.sin(x)+1 #因变量y
z = np.cos(x**2)+1 #因变量z
plt.figure(figsize=(8,4)) #设置图像大小
plt.plot(x,y,label= ‘
sin
x
+
1
\sin x+1
sinx+1’,color=‘red’,linewidth=2) #作图,设置标签,线条颜色,线条大小
plt.plot(x,z,‘b–’,label=‘
cos
x
2
+
1
\cos x^2+1
cosx2+1’) #作图,设置标签,线条类型
plt.xlabel(‘Time(s)’) #X轴名称
plt.ylabel(‘Volt’) #Y轴名称
plt.title(‘A Simple Example’) #标题
plt.ylim(0,2.2) #显示Y轴范围
plt.legend() #显示图例
plt.show()
做出来的图如下:

以上代码做出来的图
如果使用的是中文标签,会发现中文标签无法正常显示。这是由于matplotlib的默认字体是英文导致的,解决办法是在作图之前手动将默认字体设置为中文字体,如黑体(SimHei):
plt.rcParams[‘font.sans-serif’]=[‘SimHei’] #这句用来正常显示中文字体
如果保存图像负号不显示则可以用以下代码解决:
plt.rcParams[‘axes.unicode_minus’]=False #解决保存图像是负号“-”显示为方块的问题
建议:有空多去matplotlib提供的“画廊”欣赏他做出来的漂亮效果,链接如下:[https://matplotlib.org/gallery.html]( )
#### 2.3.4 pandas
pandas是Python下最强大的数据分析和探索工具,pandas构建在numpy之上,使得以numpy为中心的应用很容易使用。pandas的功能非常强大,支持类似于SQL的增删改查,并带有丰富的数据处理函数。支持时间序列分析功能;支持灵活处理缺失数据等。
##### (1)安装
安装方法和以上的库均一样,但是在使用pandas之前需要先安装numpy才能使用。pandas本身是不支持Excel文件的读写的,需要安装xlrd(读)和xlwt(写)库才能支持Excel的读写。
##### (2)使用
pandas基本的数据结构是Series和DataFrame,Series是序列类似一堆数组;DataFrame则是相当于一张二维的表格,类似于二维数组,它的每一列就是一个Series。为了定位Series中的元素,pandas提供了Index对象,每个Series都会带有一个对应的Index,用来标记不同的元素。Index类似于SQL中的主键DataFrame相当于对个带有Index的Series的组合(本质是Series的容器),每一个Series都带有唯一的表头,用来标识不同的Series。
###### pandas的简单例子:
#-*-coding:utf-8 -*
import pandas as pd #通常用pd作为pandas的别名
s = pd.Series([1,2,3],index = [‘a’,‘b’,‘c’]) #创建一个序列s
d = pd.DataFrame([[1,2,3],[4,5,6]],columns=[‘a’,‘b’,‘c’]) #创建一个表
d2 = pd.DataFrame(s) # 也可以用已有的序列来创建表格
print(d.head()) #预览前5行数据,3.x版本需要加上print
print(d.describe()) #数据的基本统计量,3.x版本需要加上print
#读取文件,注意文件的路径不能有中文,否则读取可能出错
pd.read_excel(‘data.xls’) #读取Excel文件,创建DataFrame
pd.read_csv(‘data.csv’,encoding=‘utf-8’) #读取文本格式的数据,一般用encoding指定编码
#### 2.3.5 StatsModels
相比于pandas而言,StatsModels更加注重数据的统计建模分析,使得Python有了一丝R语言的味道。StatsModels支持与pandas进行数据交互,与pandas进行组合,成为了Python下强大的数据挖掘组合。StatsModels依赖于pandas,也依赖于pandas所依赖的,同时还依赖于pasty(一个描述统计的库)。
使用StatsModels来进行ADF平稳性检验的例子:
#-*-coding:utf-8 -*
from statsmodels.tsa.stattools import adfuller as ADF #导入ADF检验
import numpy as np
print(ADF(np.random.rand(100))) #返回的结果是ADF值、p值等
#### 2.3.6 Scikit-Learn
Scikit-Learn是Python下的一个强大的机器学习包,提供了完善的机器学习工具箱,包括数据预处理、分类、回归、聚类、预测、和模型分析等。Scikit-Learn依赖于numpy、SciPy、matplotlib,因此只要提前安装好这几个库然后按照Scikit-Learn基本上没有什么问题,安装方法和之前一样。
使用Scikit-Learn创建一个机器学习的模型:
#-*-coding:utf-8 -*
from sklearn.linear_model import LinearRegression #导入线性回归模型
model=LinearRegression() #建立线性回归模型
print(model)
##### (1)所有模型提供的接口有:
* model.fit():训练模型,对于监督模型来说是fit(X,y),对于非监督模型是fit(X)。
##### (2)监督模型提供的接口有:
* model.predict(X\_new):预测新样本
* model.predict\_proda(X\_new):预测概率,仅对某些模型有用(比如LR)
* model.score():得分越高,fit越好
##### (3)非监督模型提供的接口有:
* model.transfrom():从数据中学习新的“基空间”
* model.fit\_transfrom():从数据中学习到新的基并将这个数据按照这组“基”进行转换。
Scikit-Learn本身提供了一些实例数据,比如常见的有安德森鸢尾花卉数据集、手写图像数据集等。
#-*-coding:utf-8 -*
from sklearn import datasets #导入数据集
iris=datasets.load_iris() #加载数据集
print(iris.data.shape) #查看数据集大小
from sklearn import svm #导入SVM模型
clf = svm.LinearSVC() #建立线性SVM分类器
clf.fit(iris.data,iris.target) #用数据训练模型
clf.predict([[5.0,3.6,1.3,0.25]]) #训练好模型后,输入新的数据进行预测
print(clf.coef_) #查看训练好的模型的参数
#### 2.3.7 Keras
本书用Keras来搭建神经网络,但是Keras并不只是神经网络库,而是一个基于Theano的强大的深度学习库,还可以利用它搭建自编码器、循环神经网络、递归神经网络、卷积神经网络等,由于基于Theano,因此速度也很快。Keras大大的简化了搭建神经网络的难度,允许普通用户轻松地搭建并求解具有几百个输入节点的深层神经网络,而且定制的自由度非常大。
##### (1)安装
安装Keras之前需要安装numpy、SciPy和Theano,安装Theano需要先准备一个C++编译器,这在Linux下是自带的,所以在Linux上安装是相对简单一些的,而在Windows上则需要先安装MinGW(Windows下的GCC和C++),然后再安装Theano,最后安装Keras。如果需要实现GPU加速则需要安装和配置CUDA。值得一提的是在windows下Keras会大打折扣,因此想要在神经网络和深度学习方面进行深入研究,请在Linux下搭建相应的环境。
##### (2)使用
简单搭建一个MLP(多层感知器),如下:
#-*-coding:utf-8 -*
from keras.models import Sequential
from keras.layers.core import Dense,Dropout,Activation
from keras.optimizers import SGD
model = Sequential() #模型初始化
model.add(Dense(20,64)) #添加输入层20个节点,第一隐藏层64个节点的连接
model.add(Activation(‘tanh’)) #第一隐藏层用tanh作为激活函数
model.add(Dropout(0.5)) #使用Dropout防止过拟合
model.add(Dense(64,64)) #添加第一隐藏层64节点,第二隐藏层64节点连接
model.add(Activation(‘tanh’)) #第二隐藏层用tanh作为激活工具
model.add(Dropout(0.5)) #使用Dropout防止过拟合
model.add(Dense(64,1)) #添加第二隐藏层64节点,输出层1节点连接
model.add(Activation(‘sigmoid’)) #输出层用sigmoid作为激活函数
sgd = SGD(lr=0.1,decay=le-6,momentum=0.9,nesterov=True) #定义求解算法
model.compile(loss=‘mean_squared_error’,optimizer=sgd) #编译生成模型,损失函数为平均误差平方和
model.fit(x_train,x_train,nb_epoch=20,batch_size=16) #训练模型
score = model.evaluate(x_test,y_test,batch_size=16) #测试模型
**注:Keras的预测函数和Scikit-Learn有所差别,Keras用model.predict()方法给出概率,model.predict\_classes()方法给出分类结果。**
### 关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
**朋友们如果需要这份完整的资料可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】**

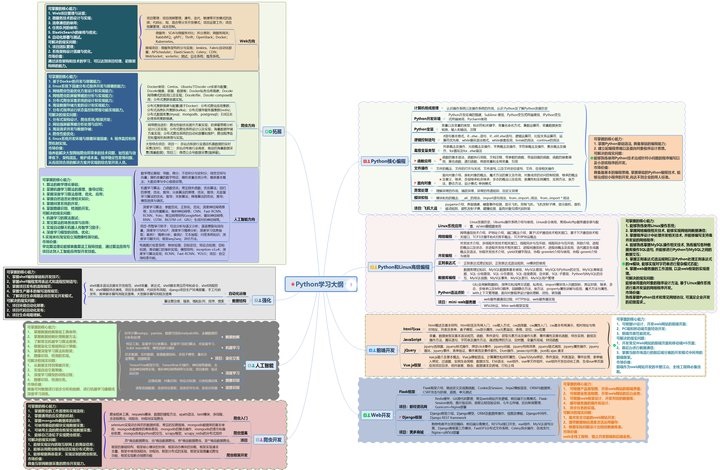
#### 一、Python学习大纲
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
#### 二、Python必备开发工具

#### 三、入门学习视频
#### 四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
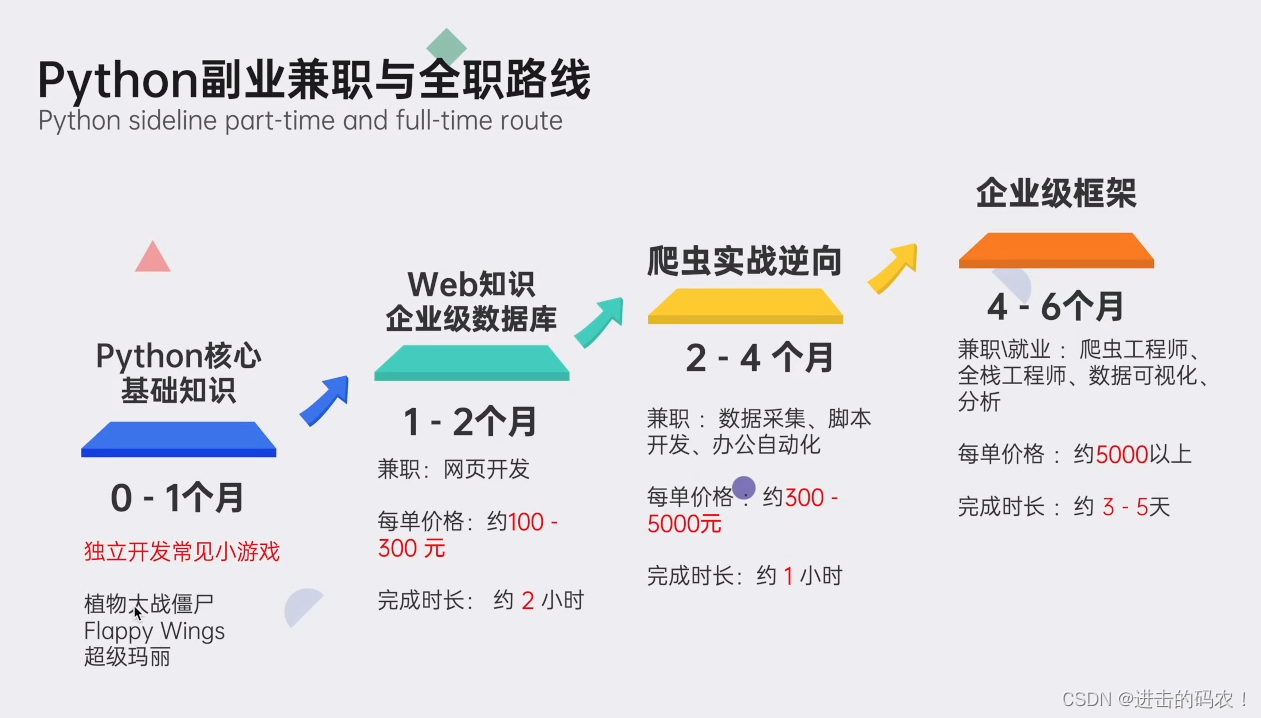
#### 五、python副业兼职与全职路线

>
> 👉[[[CSDN大礼包:《python兼职资源&全套学习资料》免费分享]]]( )(**安全链接,放心点击**)
>
>
>
**自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。**
**深知大多数Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!**
**因此收集整理了一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。**






**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Python开发知识点,真正体系化!**
**由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新**
**如果你觉得这些内容对你有帮助,可以添加V获取:vip1024c (备注Python)**

### 最后
> **🍅 硬核资料**:关注即可领取PPT模板、简历模板、行业经典书籍PDF。
> **🍅 技术互助**:技术群大佬指点迷津,你的问题可能不是问题,求资源在群里喊一声。
> **🍅 面试题库**:由技术群里的小伙伴们共同投稿,热乎的大厂面试真题,持续更新中。
> **🍅 知识体系**:含编程语言、算法、大数据生态圈组件(Mysql、Hive、Spark、Flink)、数据仓库、Python、前端等等。
**一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**

**
**如果你觉得这些内容对你有帮助,可以添加V获取:vip1024c (备注Python)**
[外链图片转存中...(img-vGAM8tpL-1712950110677)]
### 最后
> **🍅 硬核资料**:关注即可领取PPT模板、简历模板、行业经典书籍PDF。
> **🍅 技术互助**:技术群大佬指点迷津,你的问题可能不是问题,求资源在群里喊一声。
> **🍅 面试题库**:由技术群里的小伙伴们共同投稿,热乎的大厂面试真题,持续更新中。
> **🍅 知识体系**:含编程语言、算法、大数据生态圈组件(Mysql、Hive、Spark、Flink)、数据仓库、Python、前端等等。
**一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
[外链图片转存中...(img-hseI1j0N-1712950110677)]
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









