








感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的:
① 2000多本Python电子书(主流和经典的书籍应该都有了)
② Python标准库资料(最全中文版)
③ 项目源码(四五十个有趣且经典的练手项目及源码)
④ Python基础入门、爬虫、web开发、大数据分析方面的视频(适合小白学习)
⑤ Python学习路线图(告别不入流的学习)
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
(2)访问:
元组和字符串以及列表类似,索引都是从0开始,并且可以进行截取和组合等操作。
如下:
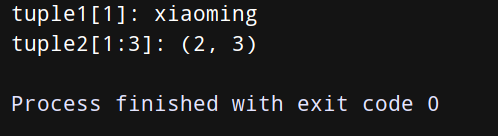
tuple1 = (‘xiaoming’, ‘xiaohong’, 18, 21)
tuple2 = (1, 2, 3, 4, 5)
显示元组中索引为1的元素的值
print(“tuple1[1]:”, tuple1[0])
显示元组中索引从1到3的元素的值
print(“tuple2[1:3]:”, tuple2[1:3])
(1)元组的修改:
虽然在开头就说元组不可变,但是它还是有个被支持的骚操作——元组之间进行连接组合:
tuple1 = (‘xiaoming’, ‘xiaohong’, 18, 21)
tuple2 = (1, 2, 3, 4, 5)
tuple_new = tuple1 + tuple2
print(tuple_new)

(1)元组的删除:
虽然元组不可变,但是却可以通过del语句删除整个元组。
如下:
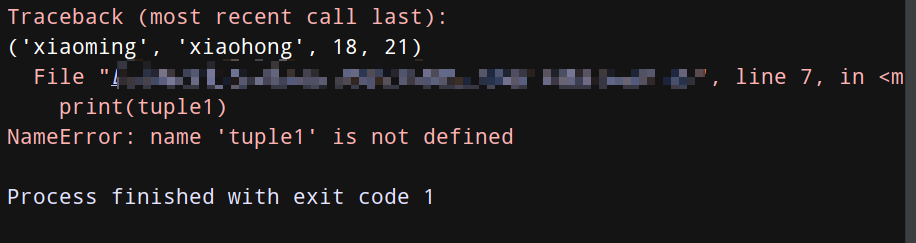
tuple1 = (‘xiaoming’, ‘xiaohong’, 18, 21)
print(tuple1) # 正常打印tuple1
del tuple1
print(tuple1) # 因为上面删除了tuple1,所以再打印会报错哦!
元组是不可变,但是我们可以通过使用内置方法来操作元组。常用的内置方法如下:
-
len(tuple):计算元组元素个数;
-
max(tuple):返回元组中元素的最大值;
-
min(tuple):返回元组中元素的最小值;
-
tuple(seq):将列表转换为元组。
其实更多时候,我们是将元组先转换为列表,操作之后再转换为元组(因为列表具有很多方法~)。
(1)
Python允许将一个包含N个元素的元组或序列分别为N个单独的变量。这是因为Python语法允许任何序列/可迭代对象通过简单的赋值操作分解为单独的变量,唯一的要求是变量的总数和结构要与序列相吻合。
如下:
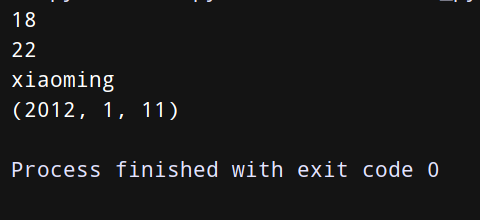
tuple1 = (18, 22)
x, y = tuple1
print(x)
print(y)
tuple2 = [‘xiaoming’, 33, 19.8, (2012, 1, 11)]
name, age, level, date = tuple2
print(name)
print(date)
如果要分解未知或任意长度的可迭代对象,上述分解操作岂不直接很nice!通常在这类可迭代对象中会有一些已知的组件或模式(例如:元素1之后的所有内容都是电话号码),利用“*”星号表达式分解可迭代对象后,使得开发者能轻松利用这些模式,而无须在可迭代对象中做复杂操作就能得到相关的元素。
在Python中,星号表达式在迭代一个变长的元组序列时十分有用。如下演示分解一个待标记元组序列的过程。
records = [
(‘AAA’, 1, 2),
(‘BBB’, ‘hello’),
(‘CCC’, 5, 3)
]
def do_foo(x, y):
print(‘AAA’, x, y)
def do_bar(s):
print(‘BBB’, s)
for tag, *args in records:
if tag == ‘AAA’:
do_foo(*args)
elif tag == ‘BBB’:
do_bar(*args)
line = ‘guan:ijing234://wef:678d:guan’
uname, *fields, homedir, sh = line.split(‘:’)
print(uname)
print(*fields)
print(homedir)
print(sh)

(2)
在Python中迭代处理列表或元组等序列时,有时需要统计最后几项记录以实现历史记录统计功能。
使用内置的deque实现:
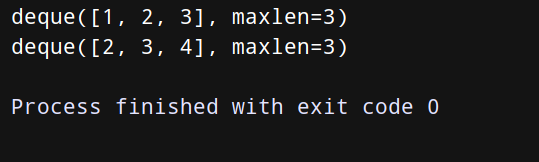
from _collections import deque
q = deque(maxlen=3)
q.append(1)
q.append(2)
q.append(3)
print(q)
q.append(4)
print(q)
如下——演示了将序列中的最后几项作为历史记录的过程。
from _collections import deque
def search(lines, pattern, history=5):
previous_lines = deque(maxlen=history)
for line in lines:
if pattern in line:
yield line, previous_lines
previous_lines.append(line)
Example use on a file
if name == ‘main’:
with open(‘123.txt’) as f:
for line, prevlines in search(f, ‘python’, 5):
for pline in prevlines: # 包含python的行
print(pline) # print (pline, end=‘’)
打印最后检查过的N行文本
print(line) # print (pline, end=‘’)
123.txt:
pythonpythonpythonpythonpythonpythonpython
python
python
在上述代码中,对一系列文本行实现了简单的文本匹配操作,当发现有合适的匹配时,就输出当前的匹配行以及最后检查过的N行文本。使用deque(maxlen=N)创建了一个固定长度的队列。当有新记录加入而使得队列变成已满状态时,会自动移除最老的那条记录。当编写搜索某项记录的代码时,通常会用到含有yield关键字的生成器函数,它能够将处理搜索过程的代码和使用搜索结果的代码成功解耦开来。
使用内置模块heapq可以实现一个简单的优先级队列。
如下——演示了实现一个简单的优先级队列的过程。
import heapq
class PriorityQueue:
def init(self):
self._queue = []
self._index = 0
def push(self, item, priority):
heapq.heappush(self._queue, (-priority, self._index, item))
self._index += 1
def pop(self):
return heapq.heappop(self._queue)[-1]
class Item:
def init(self, name):
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。

四、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









