







目录
一、没有重复项数字的全排列
1.1 题目
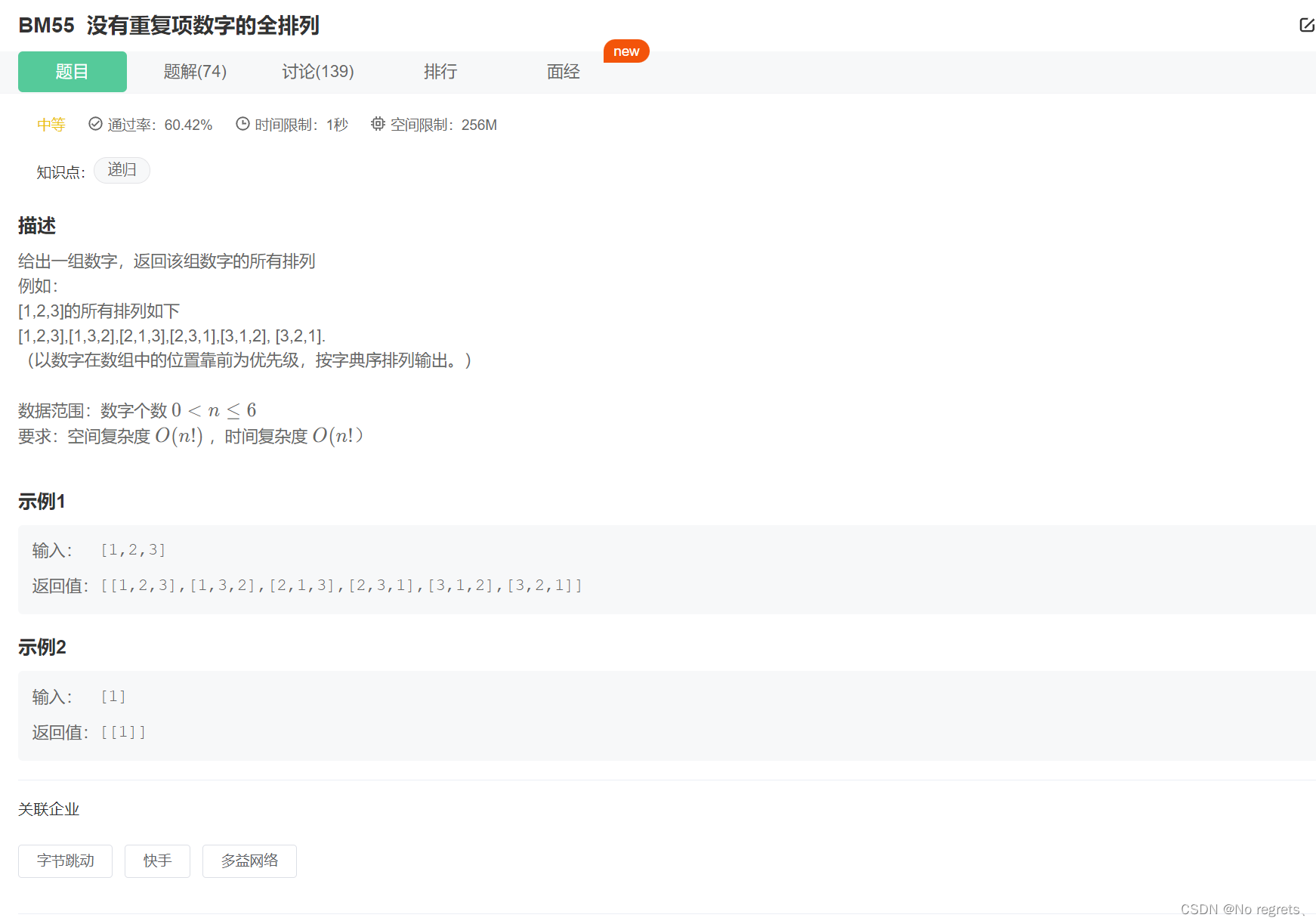
1.2 题解
思路:将n个数的全排列想象成有n个空格,将这n个数填到这n个空格中的所有填法,那么我们如何填这n个空格呢?
从左往后对每个空格尝试填入一个数,数字不能重复使用
下面我们通过代码的思路模拟这个过程,
变量i表示当前我们已经填到了第i个格子
- 如果i==n,说明n个格子都已经填满,作为一种可能的排序加入到结果集中
- 如果i<n,说明填到了第i个格子,需要选择一个数填入该格子中,同时选择的数不能是被使用过的,因此使用vis数组来保存当前数字是否被使用过,将i号格子填好之后,就可以填后面的格子了,通过调用递归函数填后面的格子,在回溯的时候撤销该位置填入的数,尝试在该格子中填入其他数
代码:
public ArrayList<ArrayList<Integer>> permute(int[] num) {
ArrayList<ArrayList<Integer>> ret=new ArrayList<>();
Deque<Integer> list=new ArrayDeque<>();
int n=num.length;
boolean[] vis=new boolean[n];
dfs(num,n,0,ret,list,vis);
return ret;
}
public void dfs(int[] num,int n,int i, ArrayList<ArrayList<Integer>> ret,Deque<Integer> list,boolean[] vis){
if(i==n){
ret.add(new ArrayList<>(list));
}
for(int j=0;j<n;j++){
if(vis[j]) continue;
list.add(num[j]);
vis[j]=true;
dfs(num,n,i+1,ret,list,vis);
list.removeLast();
vis[j]=false;
}
}
二、有重复项数字的全排列
2.1 题目
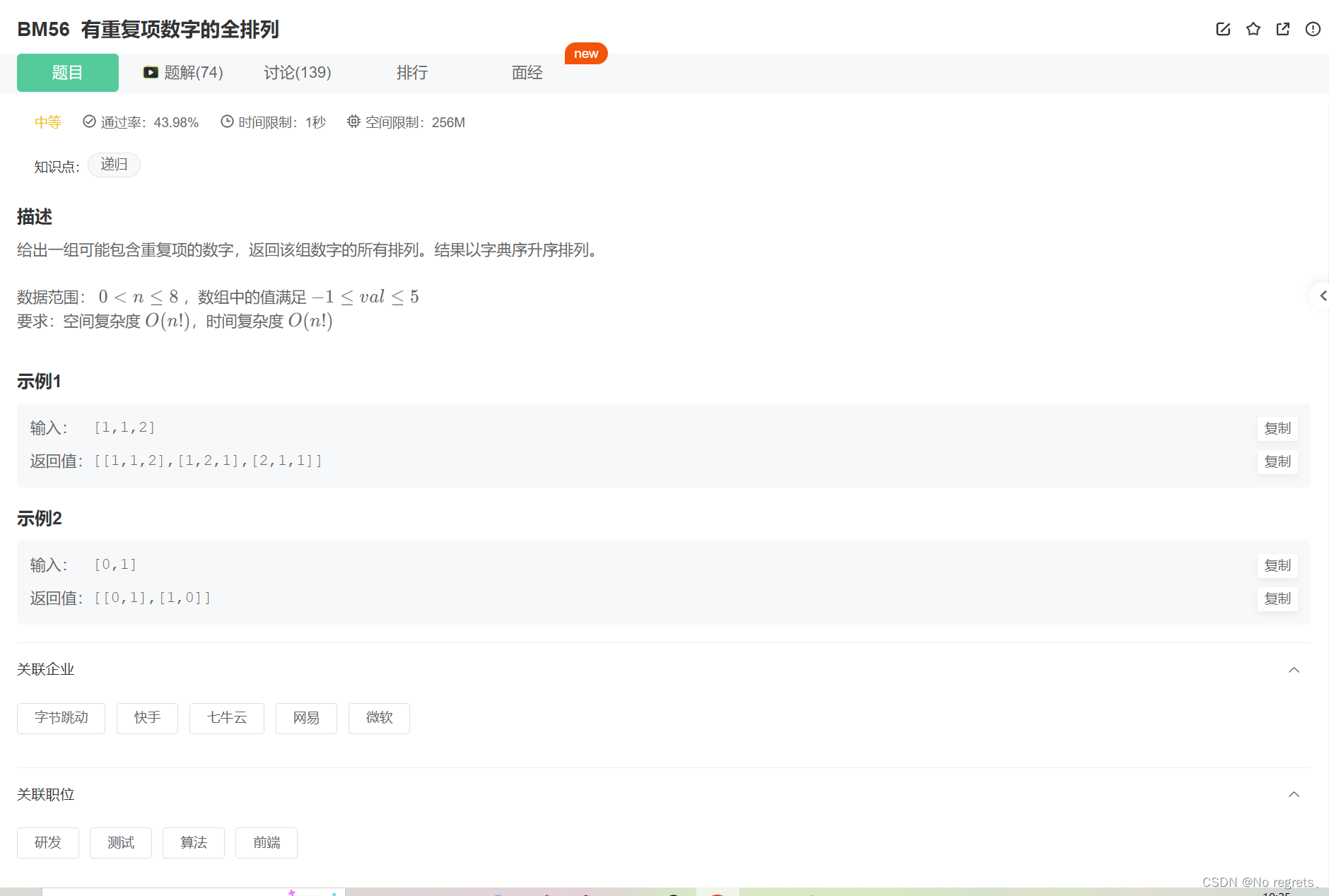
2.2 题解
与第四题字符串的排列几乎一样,只是把数字换成了字符
代码:
public ArrayList<ArrayList<Integer>> permuteUnique(int[] num) {
ArrayList<ArrayList<Integer>> ret=new ArrayList<>();
Arrays.sort(num);
boolean[] vis=new boolean[num.length];
ArrayList<Integer> tmp=new ArrayList<>();
recursion(ret,num,tmp,vis);
return ret;
}
public void recursion( ArrayList<ArrayList<Integer>> ret,int[] num,ArrayList<Integer> tmp,boolean[] vis){
if(tmp.size()==num.length){
ret.add(new ArrayList<Integer>(tmp));
return;
}
for(int i=0;i<num.length;i++){
if(vis[i])continue;
//注意:这里的判断条件是!vis[i-1]而不是vis[i-1],
//举个例子,[1,1,2],在第一个分支会选择0号下标的1作为排列的第一个数字(此时i为0),
//并将vis[0]=true,但在回溯的时候会将vis[0]改为false,然后进入下一次循环i变为1,此时num[i]==num[i-1],由于在第一个分支中已经选择将0号下标的1作为排序的第一个数字了,此处就不能在选择将下标为1的1作为排序的第一个数字了,因此使用判断条件!vis[i-1],就可以跳过这种情况,起到去重的效果
if(i>0 && num[i]==num[i-1] && !vis[i-1]){
continue;
}
vis[i]=true;
tmp.add(num[i]);
recursion(ret,num,tmp,vis);
vis[i]=false;
tmp.remove(tmp.size()-1);
}
}
三、岛屿数量
3.1 题目
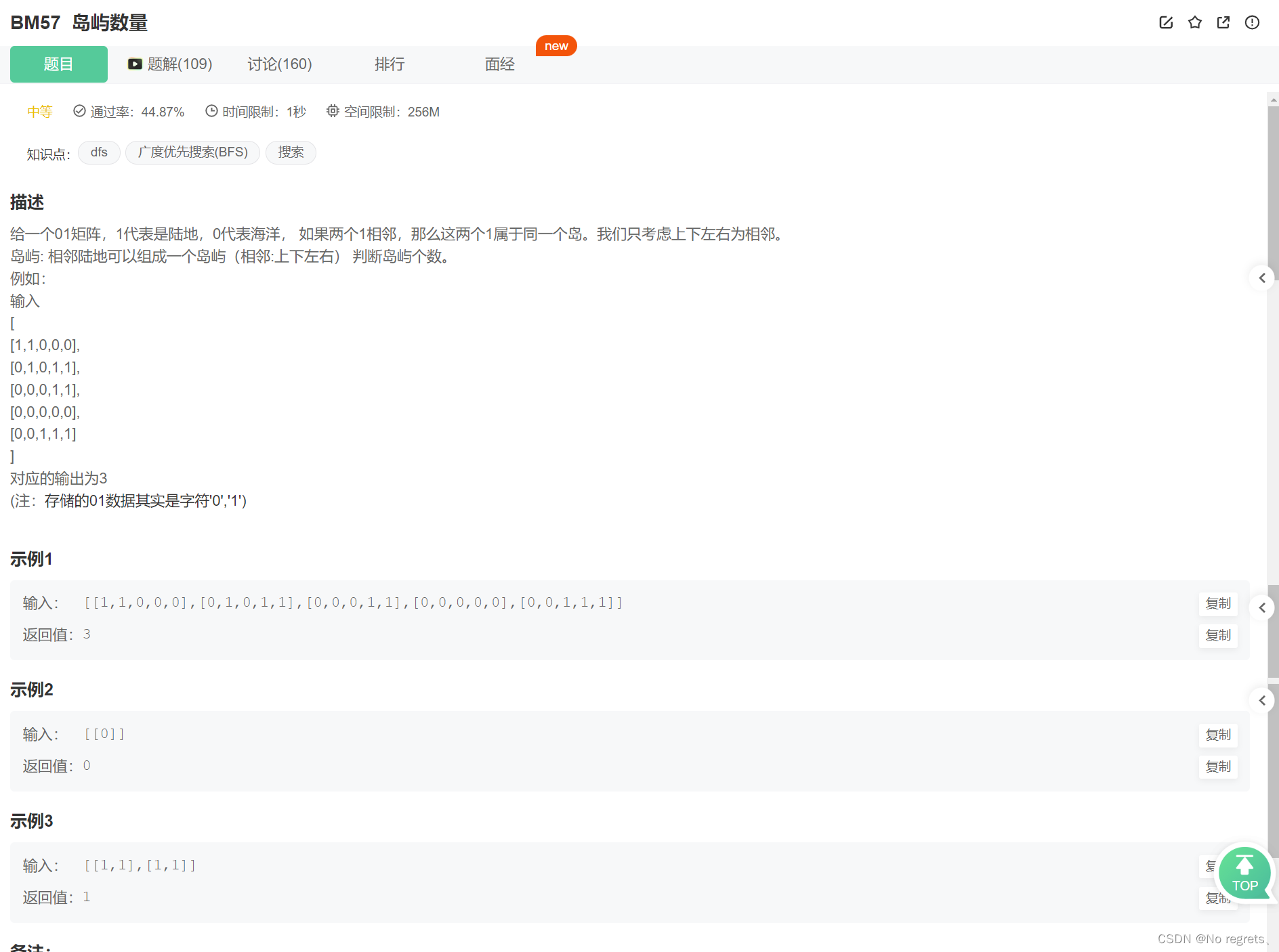
3.2 题解
深度优先遍历:深度优先搜索一般用于树或者图的遍历,其他有分支的(如二维矩阵)也适用。它的原理是从初始点开始,一直沿着同一个分支遍历,直到该分支结束,然后回溯到上一级继续沿着一个分支走到底,如此往复,直到所有的节点都有被访问到。
思路:遍历二维数组,遇到 ’ 1 ',count++,代表岛屿数量增加1,然后通过深度优先遍历将属于该岛屿中的 ’ 1 ',全部改为 ’ 0 ’
深度优先遍历的过程:首先将i,j位置的’ 1 ‘,置为’ 0 ‘,然后判断上下左右四个位置,如果有’ 1 ',就进入该相邻元素继续修改,该过程可以使用递归实现
终止条件:i,j位置周围没有’ 1 ‘,或遇到边界
本级任务:将i,j位置置为’ 0 ',然后判断能够继续修改相邻位置的元素,如果能,就进入相邻位置继续修改
代码:
public void dfs(char[][] grid,int i,int j){
grid[i][j]='0';
if(i-1>=0 && grid[i-1][j]=='1'){
dfs(grid,i-1,j);
}
if(i+1<grid.length && grid[i+1][j]=='1'){
dfs(grid,i+1,j);
}
if(j-1>=0 && grid[i][j-1]=='1'){
dfs(grid,i,j-1);
}
if(j+1<grid[0].length && grid[i][j+1]=='1'){
dfs(grid,i,j+1);
}
}
public int solve (char[][] grid) {
int n=grid.length;
int m=grid[0].length;
int count=0;
for(int i=0;i<n;i++){
for(int j=0;j<m;j++){
if(grid[i][j]=='1'){
count++;
dfs(grid,i,j);
}
}
}
return count;
}
四、字符串的排列
4.1 题目
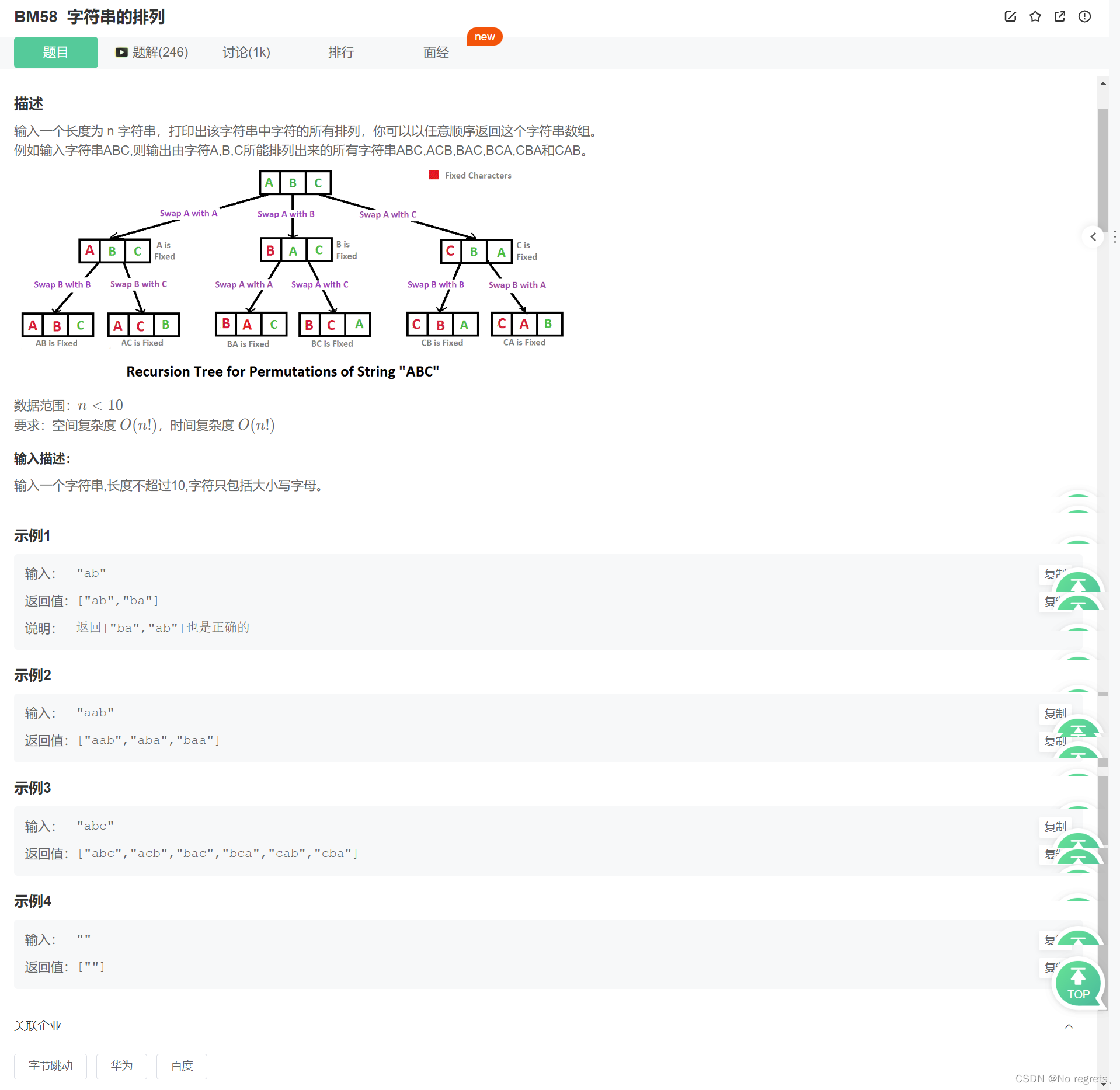
4.2 题解
树型递归:该题目属于是树型递归,父问题有很多的分支,我们需要从子问题回到父问题,在进入到另一个子问题,因为有时候进入第一个子问题的时候修改过一些变量,因此回溯的时候会要求改回父问题时的样子才能进入第二子问题
分支
思路:为了便于后序去重,先对字符串根据字典序排序,因为排序后重复的字符就会相邻,后续递归找起来也很方便。
使用临时变量保存一个排列的情况,当选取了一个字符后,问题就转化成将后序字符的进行全排列后追加到第一个字符后,对后序问题进行全排列就是一个递归的子问题
- 终止条件:临时变量中选取了n个元素,构成了一种排列,加入到结果集中
- 返回值:每一层给上一层返回的就是本层级在临时字符串中添加的元素,递归到末尾的时候就能添加全部元素
- 本级任务:每一级都需要选择一个元素加入到临时字符串末尾
具体步骤:
step1:对数组进行排序,准备一个临时空间tmp,保存一组排列情况,vis数组记录被使用过的字符
step2:每次递归从头遍历字符串,获取字符加入:首先根据vis数组,已经加入的元素不能再次加入了;同时,如果当前的元素str[i]与同一层的前一个元素str[i-1]相同且str[i-1]已经用,也不需要将其纳入。
step3:进入下一层递归前将vis数组当前位置标记为使用过。
step4:回溯的时候需要修改vis数组当前位置标记,同时去掉刚刚加入字符串的元素
step 5:临时字符串长度到达原串长度就是一种排列情况。
五、N皇后问题
5.1 题目
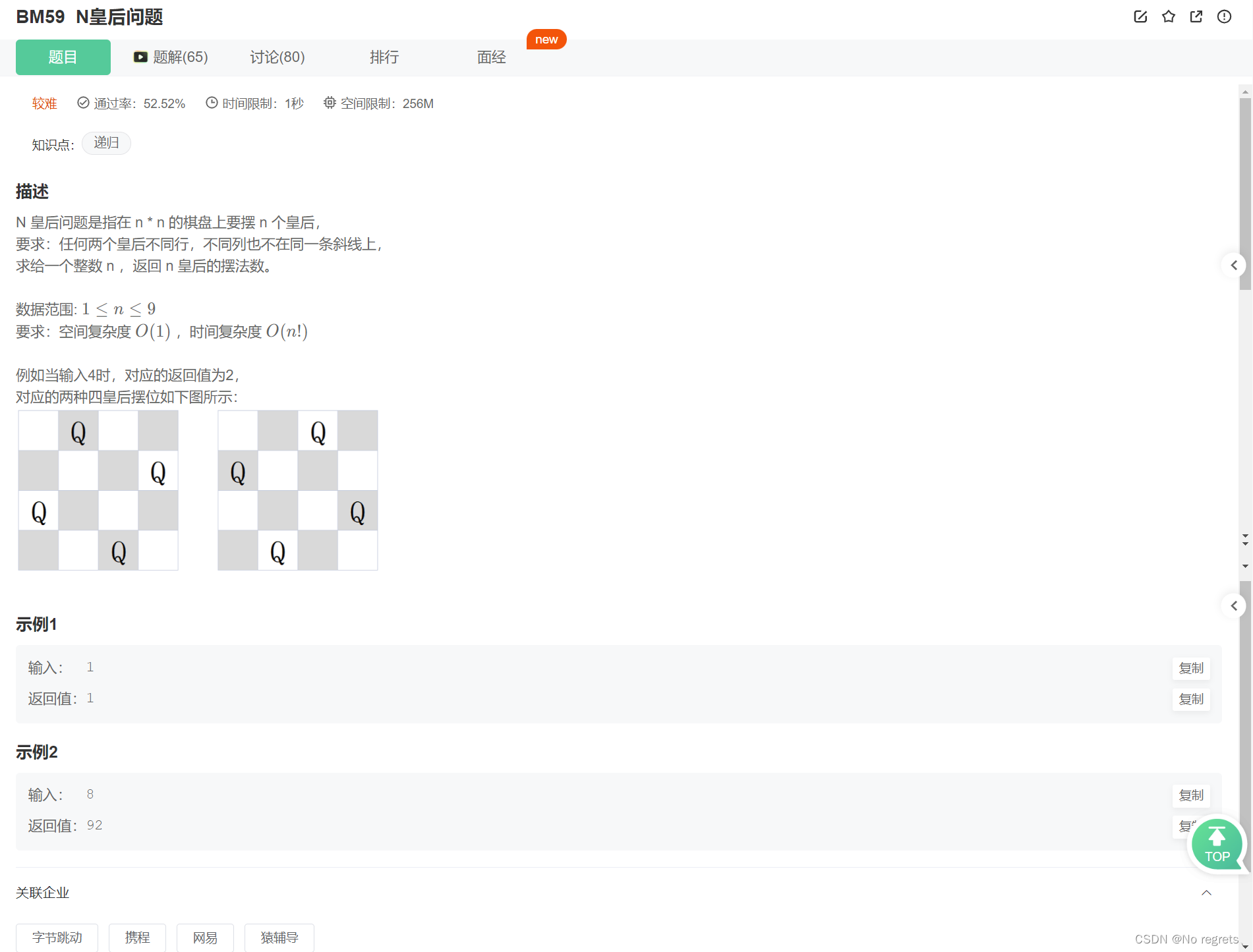
5.2 题解
思路:递归+回溯
树型递归:父问题有很多分支,我需要从子问题回到父问题,进入另一个子问题。因此回溯是指在递归过程中,从某一分支的子问题回到父问题进入父问题的另一子问题分支,因为有时候进入第一个子问题的时候修改过一些变量,因此回溯的时候会要求改回父问题时的样子才能进入第二子问题分支。
该题目属于树型递归,符合条件的分支可能有多个,因此需要回溯
具体做法:
- 使用三个集合分别记录不能再被选中的的列col,正斜线pos,反斜线neg
- 递归的进入每一行,遍历该行的每个位置,如果能找到合适的位置,在进入下一行之间,将该位置的位置信息添加到三个集合中,然后递归进入下一行
- 如果在所有行中都能找到一个合适的皇后位置,也就是递归到了i==n的情况,结果res加1
- 但由于在某一行合适的位置(可以放皇后的位置)分支可能不止一个,因此我们需要进行回溯,并将之前选择的位置,在三个集合中移除
【注意】:
之所以我们没有创建集合用来保存不能放置的行,是因为我们递归进入到某一行中,只要在该行中遇到一个合适的位置就会进入到下一行,这就避免了在某一行中放置多个皇后的问题
代码:
import java.util.*;
public class Solution {
/**
*
* @param n int整型 the n
* @return int整型
*/
int result = 0;
Set<Integer> column = new HashSet<Integer>();//保存不能放置皇后的列
Set<Integer> posSlant = new HashSet<>();//保存不能防止皇后的正对角线
Set<Integer> conSlant = new HashSet<>();//保存不能防止的斜对角角线
public int Nqueen (int n) {
compute(0,n);
return result;
}
public void compute(int i,int n){
if(i==n){
result++;
}
for(int j=0;j<n;j++){
if(column.contains(j) || conSlant.contains(i+j) || posSlant.contains(i-j)){
continue;
}
column.add(j);
posSlant.add(i-j);
conSlant.add(i+j);
compute(i+1,n);
column.remove(j);
posSlant.remove(i-j);
conSlant.remove(i+j);
}
}
}
六、括号生成
6.1 题目
6.2 题解
递归是一个过程或函数在其定义或说明中有直接或间接调用自身的一种方法,它通常把一个大型复杂的问题层层转化为一个与原问题相似的规模较小的问题来求解。因此递归过程,最重要的就是查看能不能讲原本的问题分解为更小的子问题,这是使用递归的关键。
线型递归:子问题直接回到父问题不需要回溯
树型递归:父问题有很多分支,我需要从子问题回到父问题,进入另一个子问题。因此回溯是指在递归过程中,从某一分支的子问题回到父问题进入父问题的另一子问题分支,因为有时候进入第一个子问题的时候修改过一些变量,因此回溯的时候会要求改回父问题时的样子才能进入第二子问题分支。
思路:题目给定n对括号,将n对括号组合在一起,相当于先使用一个左括号,再将剩余的n-1个左括号和n个右括号组合在一起拼接到使用了的左括号后面
- 终止条件:左右括号都用了n个后,将该字符串加入结果集
- 返回值:返回用当前剩余的左右括号组装好的括号序列
- 本级任务:每一级就是保证左括号还有剩余的情况下,使用一次左括号进入子问题,或者右括号还有剩余且右括号使用次数少于左括号的情况下使用一次右括号进入子问题
代码:
public void process(ArrayList<String> ret, String tmp, int left, int right, int n){
if(left==n && right==n) {
ret.add(tmp);
}
if(left<n){
process(ret,tmp+"(",left+1,right,n);
}
if(right<n && right<left){
process(ret,tmp+")",left,right+1,n);
}
}
public ArrayList<String> generateParenthesis (int n) {
ArrayList<String> ret=new ArrayList<>();
String tmp="";
process(ret,tmp,0,0,n);
return ret;
}
七、矩阵最长递增路径
7.1 题目
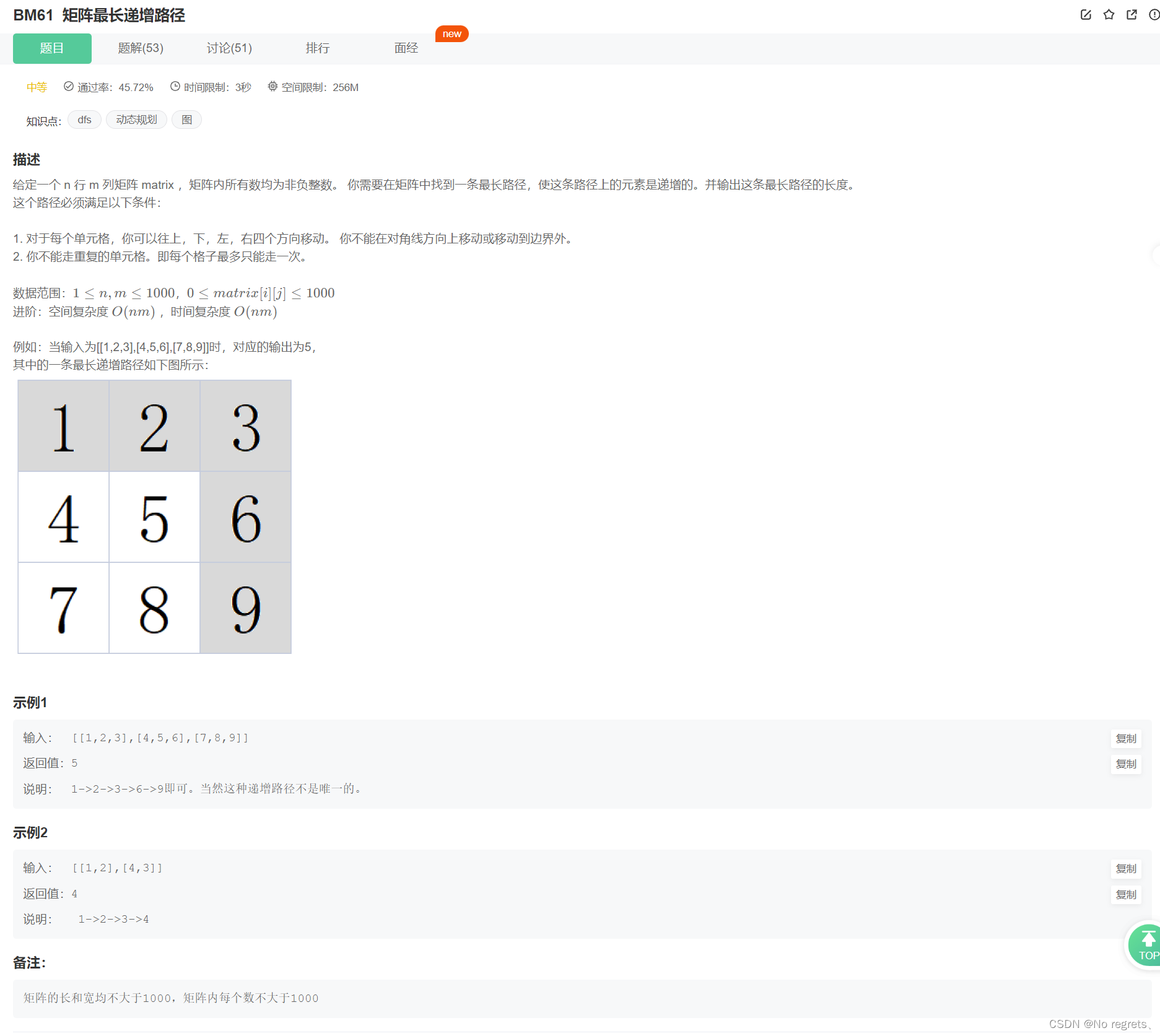
7.2 题解
【解法一】:深度优先遍历
思路:题目要求找出最长的递增路径,因此首先我们要确定这条路径的起点位置,但我们又无法直接确定起点位置,因此我们决定依次遍历每个位置,找出所有位置作为起点得到的最长递增路径中的最大值即可
创建二维数组dp,dp[i][j]的含义是,以i,j位置作为起点所得到的最长递增路径
那么又该如何求以i,j位置为起点的最长递增路径呢?
深度优先遍历,以i,j位置为起点的最长递增路径,等价于从i,j位置能到达的下一个相邻位置作为起点的最长递增路径长度+1,因此就将一个问题转化成了一个递归的子问题。
- 终止条件:位置越界或无法继续增长路径的长度即i,j位置四周的数都比自己大
- 返回值:以i,j位置作为起点的最长递增路径
- 本级任务:遍历i,j位置的四个方向,进入符合不越过边界且递增的下一个临近位置,继续递归,因为对于i,j位置最多有四个可以进入的邻居位置,比较后取其中的最大值
代码:
import java.util.*;
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
* 递增路径的最大长度
* @param matrix int整型二维数组 描述矩阵的每个数
* @return int整型
*/
private int[][] dirs={{-1,0},{1,0},{0,-1},{0,1}};
public int solve (int[][] matrix) {
if(matrix==null || matrix.length==0 || matrix[0].length==0) return 0;
int n=matrix.length;
int m=matrix[0].length;
int ret=0;
int[][] dp=new int[n][m];
for(int i=0;i<n;i++){
for(int j=0;j<m;j++){
ret=Math.max(ret,dfs(matrix,i,j,dp));
}
}
return ret;
}
public int dfs(int[][] matrix,int i,int j,int[][]dp){
if(dp[i][j]!=0){
return dp[i][j];
}
dp[i][j]++;
for(int k=0;k<4;k++){
int nexti=i+dirs[k][0];
int nextj=j+dirs[k][1];
if(nexti>=0 && nexti<matrix.length && nextj>=0 && nextj<matrix[0].length && matrix[nexti][nextj]>matrix[i][j]){
dp[i][j]=Math.max(dp[i][j],dfs(matrix,nexti,nextj,dp)+1);
}
}
return dp[i][j];
}
}















 2283
2283











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









