







目录
了解:
参考图
(1) html解析器:
(2) 解析方式:

介绍
### 前言:
网页解析即抓取我们想要数据(舍弃其他数据)。
在python中我们可以通过以下方式去解析抓取:正则表达式、BeautifulSoup、XPath。
### 解析方式对比:
参考上图表
(1) 正则表达式
抓取效率:正则表达式的抓取效率最高,但是需要编写正确的正则表达式,且在处理复杂的HTML文档时容易出错。
使用难度:正则表达式的使用难度较高,需要掌握正则表达式的语法和规则,以及HTML文档的结构和特点,需要较强的技术功底。
可靠性:正则表达式的可靠性不如其他两种方式,特别是在处理复杂的HTML文档时容易出错。
(2) BeautifulSoup
抓取效率:BeautifulSoup的抓取效率相对较低,但可以处理复杂的HTML文档,查找元素的速度较快,对于一些动态加载的网页也能够很好的支持。
使用难度:BeautifulSoup的使用难度较低,语法简单,易于上手,适合初学者和快速开发。
可靠性:BeautifulSoup的可靠性较高,可以处理复杂的HTML文档,也可以容错处理,避免了正则表达式的不稳定性。
(3) XPath
抓取效率:XPath的抓取效率较高,可以处理复杂的HTML文档,查找元素的速度较快。
使用难度:XPath的使用难度较高,需要掌握XPath的语法和规则,适合有一定技术功底的开发者。
可靠性:XPath的可靠性较高,可以处理复杂的HTML文档,语法规则相对稳定,也可以容错处理。
(4) 总结:
综合来看,对于初学者和一些简单的网页抓取任务,建议使用BeautifulSoup作为解析库,它易于上手,语法简单,也比较稳定和可靠。对于复杂的网页抓取任务,可以考虑使用XPath或正则表达式,在效率和可靠性之间进行权衡。
注意,Xpath只是一种解析方式概念(并不是具体的库或模块),实现Xpath方式的是使用lxml库。
bs4:
解析器:

### 解析器:
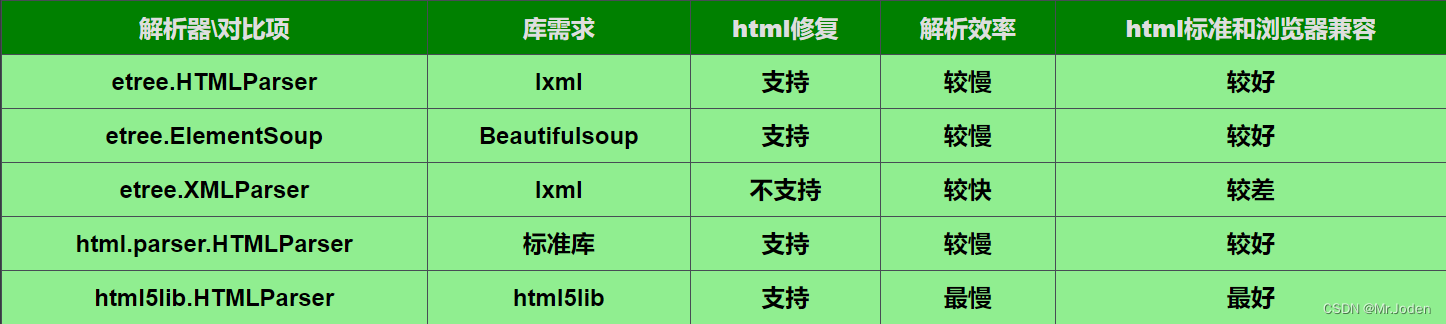
BeautifulSoup支持以下几种解析器(参考图表):
(1) Python标准库中的解析器可选值:'html.parser'和'xml'
具体:html.parser.HTMLParser和xml.etree.ElementTree
优点:不需要安装任何第三方库,适用于简单的HTML或XML文档解析
缺点:解析速度较慢,不支持Xpath语法
(2) lxml解析器可选值:'lxml'
具体:lxml.etree.XMLParser
优点:速度非常快,支持Xpath语法,基于C语言编写
缺点:需要安装lxml库,
(3) html5lib解析器可选值:'html5lib'
具体:html5lib.html5parser.HTMLParser
优点:能够解析所有的HTML和XML文档,能够正确处理文档中的嵌套标签
缺点:解析速度最慢,需要安装html5lib库
综上所述,如果需要解析速度较快且支持Xpath语法,则使用lxml解析器是最好的选择;如果需要解析的文档比较复杂,则使用html5lib解析器;如果解析的文档比较简单,则使用Python标准库中的html.parser或xml解析器即可。### 使用解析器:
BeautifulSoup(html,features)
features即可以接受描述解析器的"字符串参数",然后内部自动调用对应的解析器(前面解析器中已经介绍)
可选值:'html.parser'、'xml'、'lxml'、'html5lib'
返回:bs4.BeautifulSoup对象### bs4.BeautifulSoup对象的相关方法:
因为其继承了bs4.element.Tag,所以可以参考下面的bs4.element.Tag对象常用方法,这里仅对新方法进行补充。
new_tag(name, attrs=None):创建一个新的标签对象,返回bs4.element.Tag对象。
new_string(text, parent=None):创建一个新的文本节点对象,返回bs4.element.NavigableString对象
prettify():将BeautifulSoup对象的标签树重新格式化,以便于查看和验证。
replace_with(replacement):用指定的标签或字符串替换当前标签,返回被替换的标签。
insert_before(new_tag):在当前标签之前插入一个新的标签,返回被插入的标签。
insert_after(new_tag):在当前标签之后插入一个新的标签,返回被插入的标签。
encode(encoding=None, formatter=None):将BeautifulSoup对象转换为字节流
decode(encoding=None, formatter=None):将字节流转换为BeautifulSoup对象。
解析方法
参考图:
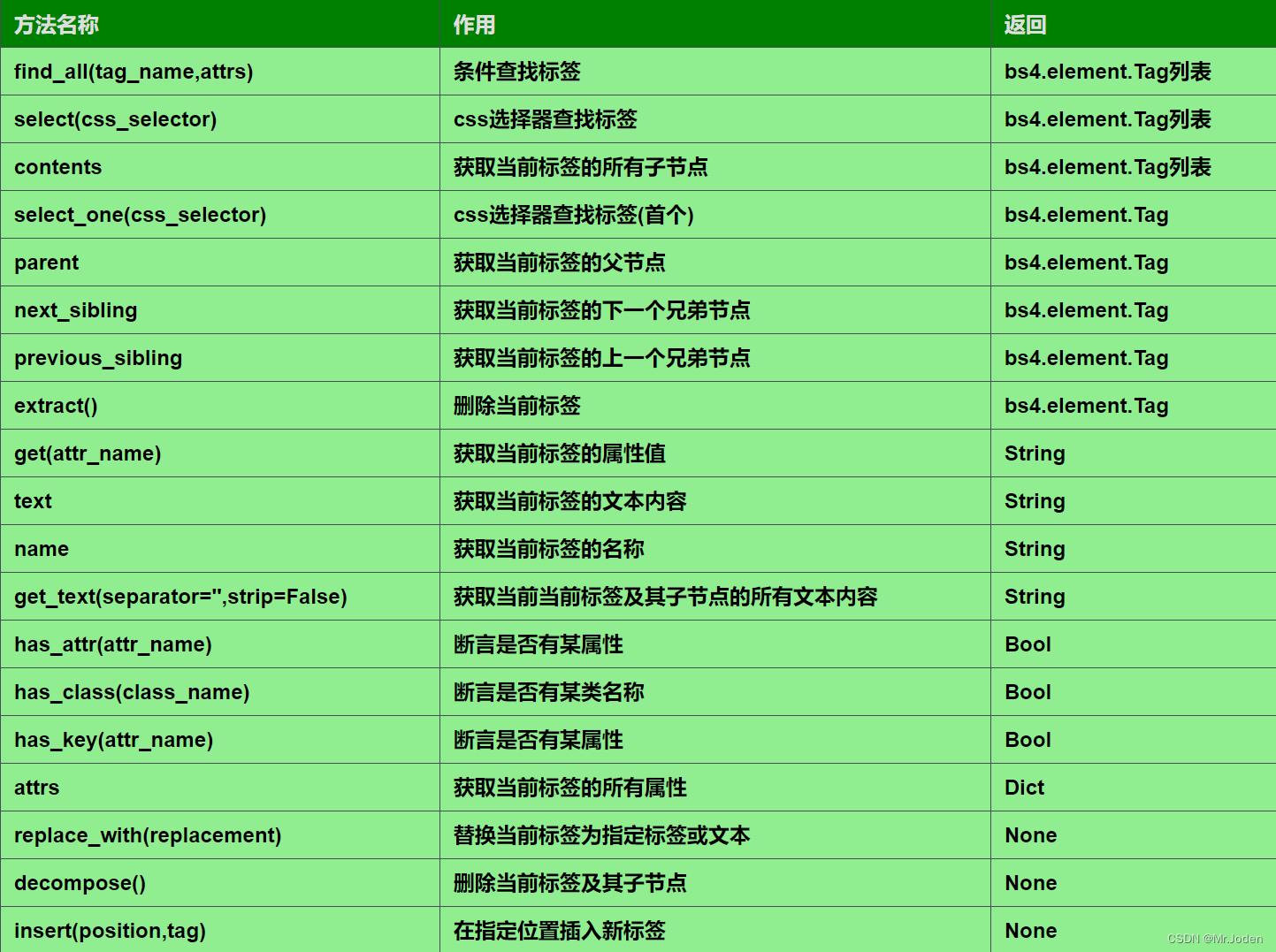
(1) bs4.element.Tag常用方法:
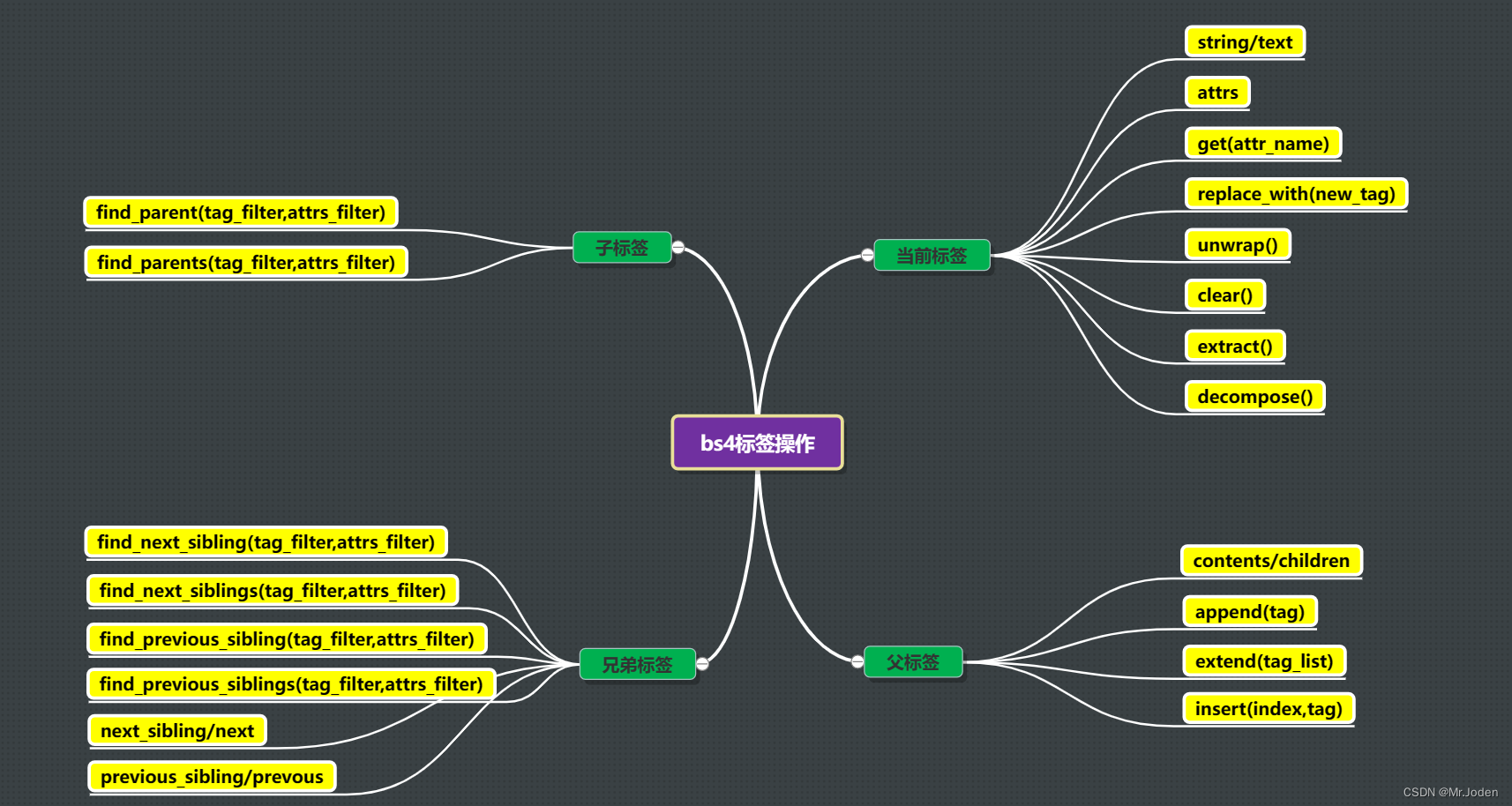
(2) 标签操作:
详细介绍:
### 以下为相关的bs4.element.Tag对象常用方法(参考图表):
注意,以下方法中有的返回依然是bs4.element.Tag对象或者bs4.element.Tag对象列表,所以我们可以链式使用。
find_all(name, attrs): 在当前标签的后代节点中查找符合条件的所有标签,返回bs4.element.Tag对象列表。
select(css_selector): 使用CSS选择器语法查找符合条件的所有标签,返回bs4.element.Tag对象列表。
contents: 获取当前标签的所有子节点(包括自身的文本节点),返回bs4.element.Tag对象列表。
select_one(css_selector): 使用CSS选择器语法查找符合条件的第一个标签,并返回bs4.element.Tag对象。
parent: 获取当前标签的父节点,返回bs4.element.Tag对象。
next_sibling: 获取当前标签的下一个兄弟节点,返回bs4.element.Tag对象。
previous_sibling: 获取当前标签的上一个兄弟节点,返回bs4.element.Tag对象。
extract(): 将当前标签从文档中移除,返回bs4.element.Tag对象。
get(name): 获取当前标签的指定属性值,返回字符串。
text: 获取当前标签的文本内容,返回字符串。
name: 获取当前标签的名称,返回字符串。
get_text(separator, strip): 获取当前标签及其后代节点的所有文本内容,返回字符串。
has_attr(name): 判断当前标签是否包含指定的属性,返回布尔值。
has_class(name): 判断当前标签是否包含指定的CSS类,返回布尔值。
has_key(key): 判断当前标签是否包含指定的属性,返回布尔值。
attrs: 获取当前标签的所有属性,返回字典。
replace_with(replacement): 将当前标签替换为指定的标签或字符串。
decompose(): 删除当前标签及其所有后代节点。
insert(position, tag): 在当前标签的指定位置插入一个新的标签。
### 以下为常用标签操作(这里单独整理出来,参考脑图):
name:获取或设置标签的名称。
string 或 text:获取或设置标签的文本内容。
attrs:获取或设置标签的属性。
get(attr_name):获取标签属性值。
has_attr(attr_name):判断标签中是否存在指定属性。
find(tag_filter, attrs_filter):查找文档中第一个与指定标签名和属性匹配的标签。
find_all(tag_filter, attrs_filter):查找文档中所有与指定标签名和属性匹配的标签。
find_parent(tag_filter, attrs_filter):获取单个祖先标签。
find_parents(tag_filter, attrs_filter):查找标签的所有祖先标签。
find_next_sibling(tag_filter, attrs_filter):查找标签的下一个兄弟标签。
find_previous_sibling(tag_filter, attrs_filter):查找标签的上一个兄弟标签。
find_next_siblings(tag_filter, attrs_filter):查找标签后面的所有兄弟标签。
find_previous_siblings(tag_filter, attrs_filter):查找标签前面的所有兄弟标签。
contents 或 children:获取标签的所有子节点,返回一个列表类型。
next_sibling 或 next:获取后面的兄弟标签。
previous_sibling 或 previous:获取上前面的兄弟标签。
append(tag):追加子节点
extend(tag_list):追加多个子节点
insert(index, tag_or_text):插入子节点。
replace_with(new_tag):将当前标签替换为一个新的标签,并返回当前标签,结合soup.prettify()。
unwrap():将当前标签的所有子标签移动到当前标签的父标签中,并删除当前标签。
clear(): 清空标签。
extract():将当前标签从文档中删除,并返回当前标签。
decompose():将当前标签从文档中删除,并销毁当前标签及其子标签的所有内容。
代码示例
(1) 'html.parser'+ find_all:
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
p_tags = soup.find_all('p', {'class':'content'})
for p in p_tags:
print(p.text)
(2) 'html.parser' + select
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
p_tags = soup.select('p.content')
for p in p_tags:
print(p.text)
(3) 'lxml' + select(推荐):
soup = BeautifulSoup(html, 'lxml')
注意,该方式只能是在下载了lxml第三方库的前提下使用,否则会出现异常。通过该方式能够加快解析速度,因为BeautifulSoup支持python标准的"html.parser"和html5lib库的"html5lib"解析方式都比较慢
(4) 总结:
推荐使用方式:BeutifulSoup + lxml + selectlxml:
解析器
### lxml解析器
(1) 以下为介绍内容:
在lxml中用于解析网页的解析器主要在lxml.etree模块中。
当然lxml在除了lxml.etree模块外还有其他的解析器,但暂不在学习范围内。
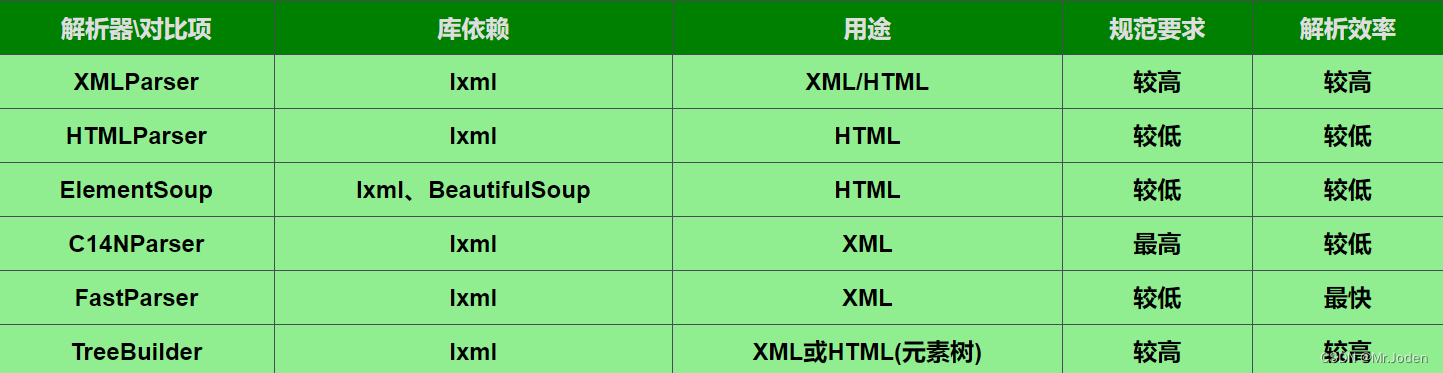
(2) 如下为etree模块的解析器(参考图表):
etree.XMLParser:使用 lxml 库的 XML 解析器。
etree.HTMLParser:使用 lxml 库的 HTML 解析器。
etree.ElementSoup:使用 BeautifulSoup 库的 HTML 解析器。
etree.C14NParser:使用 lxml 库的 Canonical XML 解析器。
etree.FastParser:使用 lxml 库的快速解析器。
etree.TreeBuilder:使用 lxml 库的树构建器。
### 使用解析器
etree.HTML(html,parser=None)
返回: lxml.etree._Element
parser参数即可以传入具体的解析器对象,如果没有传入则默认使用html.parser.HTMLParser(python标准库)。
注意:etree.HTML方法只能使用etree模块中实现的解析器对象,不能再使用其他库的解析器。
解析方法
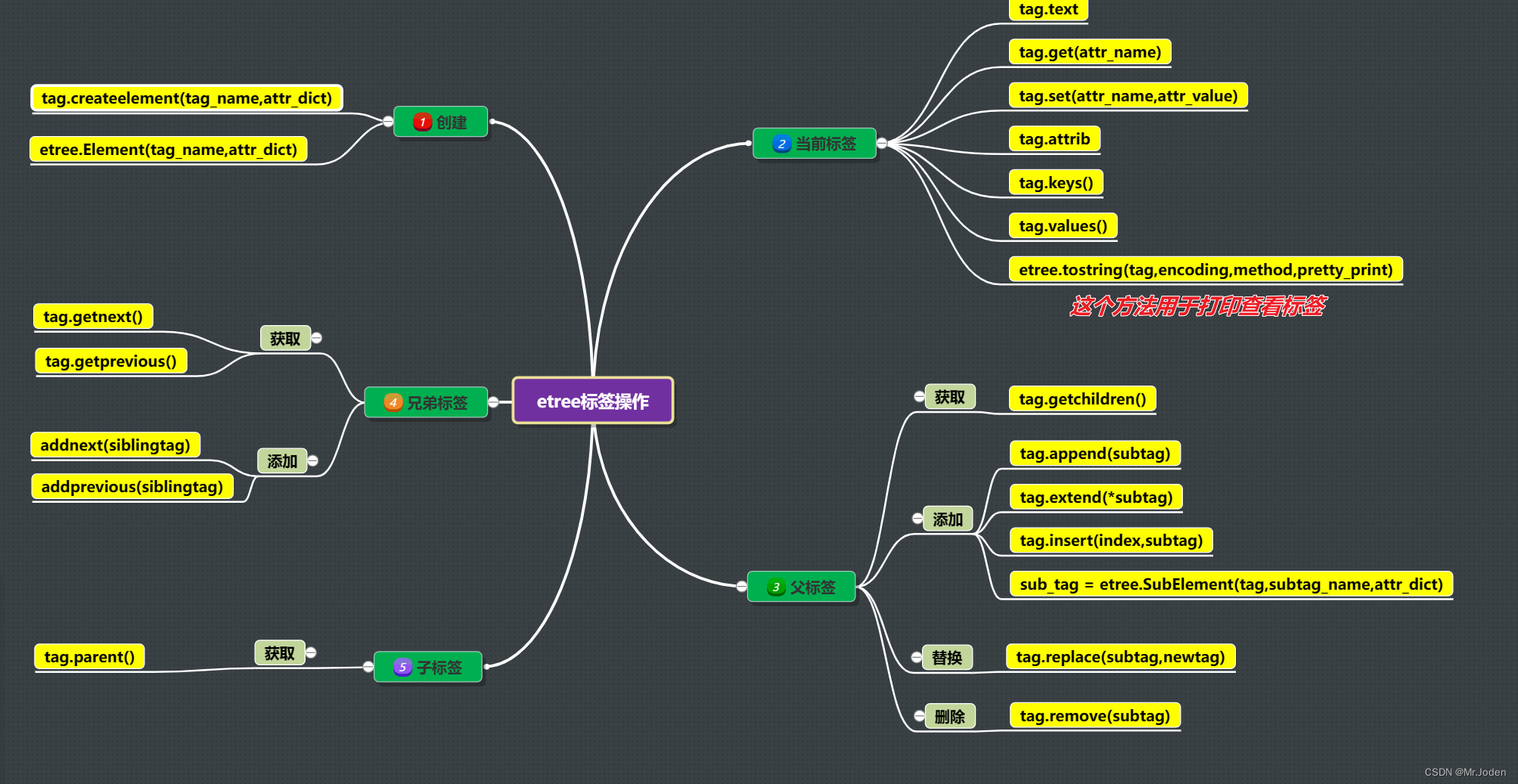
### 以下为lxml.etree._Elemen对象的常用方法(其他结合下面标签操作补充):
注意对于返回类型依然为lxml.etree._Element类型时,我们可以进行链式操作。
findall(tag):查找元素的所有子元素,返回lxml.etree._Elemen列表。
xpath(xpath_express):使用XPath语法查找元素,返回lxml.etree._Element列表或字符串列表。
getchildren():获取元素的所有子元素,返回lxml.etree._Element列表。
find(tag):查找元素的第一个子元素,返回lxml.etree._Element。
getparent():获取元素的父元素,返回一个lxml.etree._Element。
getnext():获取元素的下一个兄弟元素,返回一个lxml.etree._Element。
getprevious():获取元素的前一个兄弟元素,返回一个lxml.etree._Element。
makeelement(tag, attrib=None, nsmap=None):创建标签,返回lxml.etree._Element。
getroottree():获取元素所在文档的根元素,返回一个lxml.etree._ElementTree。
text:获取元素的文本内容,返回一个字符串。
tag:获取元素的标签名,返回一个字符串。
get(tag):获取元素的指定属性值,返回字符串或None。
attrib:获取元素的所有属性,返回字典。
append(tag):追加子标签,返回None。
remove(tag):删除子标签,返回None。### xpath和findall对比:
无论是xpath方法还是findall方法都能使用Xpath表达式。
xpath更加灵活实用,区别于findall方法(只能查找到元素标签级别),xpath方法可以获取元素标签的属性值、文本、子元素等等。
xpath更加高效,xpath内部使用了编译后的XPath表达式来查找元素;而findall内部使用的是正则表达式来匹配元素,效率较低。
xpath一定可以替代findall,但findall不一定能替代xpath,所以建议使用xpath即可。
### 标签(lxml.etree._Element对象)操作(参考脑图):
创建标签:etree.createelement(tag_name,attr_dict)
创建标签:etree.Element(tag_name,attr_dict)
获取/修改标签文本内容:tag.text
获取标签属性:tag.get(attr_name)
设置/修改标签属性:tag.set(attr_name,attr_value)
获取/修改标签属性:tag.attrib
获取标签属性:tag.keys()
获取标签属性值:tag.values()
获取子标签:tag.getchildren()
获取后面的兄弟标签:tag.getnext()
获取前面的兄弟标签:tag.getprevious()
获取父标签:tag.getparent()
查看标签:etree.tostring(tag,encoding=None,method='html',pretty_print=False)
追加子标签:tag.append(subtag)
追加多个子标签:tag.entend(*subtag)
追加子标签:sub_tag = etree.SubElement(tag,subtag_name,attr_dict)
指定位置插入标签:tag.insert(index,tag)
后面添加兄弟标签:addnext(tag)
前面添加兄弟标签:addprevious(tag)
替换子标签:tag.replace(subtag,new_tag)
删除子标签:tag.remove(subtag)
清空标签:tag.clear()
代码示例
(1) etree.HTMLParser + findall:
from lxml import etree
root = etree.HTML(html,parser=etree.HTMLParser())
p_tags = root.findall('//p[@class="content"]')
for p in p_tags:
print(p.text)
(2) etree.XMLParser + xpath:
from lxml import etree
root = etree.HTML(html,parser=etree.XMLParser())
p_tags = root.xpath('//p[@class="content"]')
for p in p_tags:
print(p.text)















 4983
4983











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









