







mainWindow = auto.DocumentControl(ClassName=‘Chrome_RenderWidgetHostHWND’)
print(‘mainWindow Name:’,mainWindow.Name)
show_index_window()
3、获取评价数据截图文件
在此之后,我们打开控件识别工具 Inspect.exe工具(可从网上下载)来查看元素情况,我使用的是另一个工具,各个元素的分层情况就显而易见了:


可以看出,多少条评价也是隐藏的。从元素层级上来看,可以从文档元素->列表元素->列表项目元素的大体思路找到目标元素。也就是"XXXX条评论<链接>"这个元素,定位这个元素之后,就获取这个元素的大小,然后截图保存。具体的代码如下:
import time
import uiautomation as auto
获取每一个商户根元素
def get_root_control():
documentControl = auto.DocumentControl(ClassName=‘Chrome_RenderWidgetHostHWND’)
层层搜索找到目标元素
documentControl_f_son_control = documentControl.GetChildren()[0]
子元素列表
f_son_control = documentControl_f_son_control.GetChildren()
target_list_control = None
for each_control in f_son_control:
son_control = each_control.GetChildren()
if len(son_control) == 1:
元素属性ControlTypeName为ListControl
if son_control[0].ControlTypeName == ‘ListControl’:
target_list_control = son_control[0]
break
return target_list_control
获取数据截图
def get_comment_pic():
mainWindow = auto.PaneControl(ClassName=‘Chrome_WidgetWin_1’)
print(‘mainWindow Name:’, mainWindow.Name)
窗口存在,切换窗口
if mainWindow.Exists(3, 1):
handle = mainWindow.NativeWindowHandle
auto.SwitchToThisWindow(handle)
target_list_control = get_root_control()
当前页面展示的商户的数量
business_num = len(target_list_control.GetChildren()) - 1
print(‘business_num:’, business_num)
当前数据所在页数
PageNum = 0
获取xxxx评价元素的大小并截图
for i in range(business_num):
第一层,第二层,第三层数据
layer_1_ele = target_list_control.GetChildren()[i]
layer_2_ele = layer_1_ele.GetChildren()[1]
layer_2_son_ele = layer_2_ele.GetChildren()
layer_3_ele = None
for each in layer_2_son_ele:
if “条评价” in each.Name:
layer_3_ele = each
if layer_3_ele is None:
raise Exception(‘获取元素失败’)
print(layer_3_ele)
获取目标元素的底部坐标,如果底部坐标等于0,说明元素在当前窗口未显示出来,需要pagedown操作
layer_3_ele_bottom = layer_3_ele.BoundingRectangle.bottom
print(‘layer_3_ele_bottom:’, layer_3_ele_bottom)
if layer_3_ele_bottom > 0:
time.sleep(1)
获取截图
layer_3_ele.CaptureToImage(‘./pic/%d%d.png’ % (PageNum, i))
if layer_3_ele_bottom <= 0:
print(‘目标元素未显示’)
auto.WheelDown()
auto.mouse_event(auto.MouseEventFlag.Wheel, 0, 0, -435, 0)
auto.SendKeys(“{PAGEDOWN}”)
time.sleep(1)
pagedown后重新获取元素
target_list_control = get_root_control()
layer_1_ele = target_list_control.GetChildren()[i]
layer_2_ele = layer_1_ele.GetChildren()[1]
layer_2_son_ele = layer_2_ele.GetChildren()
layer_3_ele = None
for each in layer_2_son_ele:
if “条评价” in each.Name:
layer_3_ele = each
if layer_3_ele is None:
raise Exception(‘获取元素失败’)
print(layer_3_ele)
获取截图
layer_3_ele.CaptureToImage(‘./pic/%d%d.png’ % (PageNum, i))
get_comment_pic()
上述代码中PageNum的作用是给采集的图片进行命名。当我们采集第一页商户评价数据的时候,可以更新PageNum的值为1,当我们将页面点击到第二页的时候就更新PageNum为2。
当然了为了偷懒,我们这没有编写点击下一页按钮和更新PageNum值的脚本,这个作业就交给大家实现了。
采集几页数据之后,我们就可以得到下列数据图:
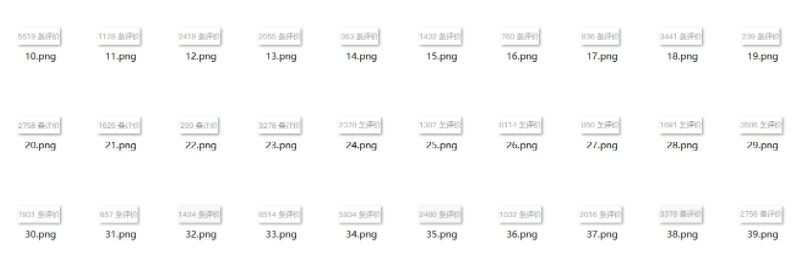

获取截图文件之后,我们要做的就是识别其中的字符就可以了。
对于获取到的截图文件的说明:
(1)不同分辨率电脑获取的截图文件大小存在差异;
(2)评价数值是几位数也会直接影响截图的大小;
(3)同一电脑获取的截图文件高度是一致的。
4、识别评价数据截图文件
评价数据截图文件的识别可以借助OCR工具来进行提取,如果感兴趣的小伙伴,可以点击蓝字查看:
所以本文其实到这里就可以结束了,那么为什么进度条才到一半呢?


那是为了与众不同,我决定使用机器学习算法来识别截图文件。


我们先将截图文件转换为下列样式,即去掉干扰部分并清晰化数据截图文件:


具体实现的代码可以这样:
import os
from PIL import Image
裁剪后观察样本数据可以发现,含有不同数目的字符图片的长度是不一样的,即:
1个–>9
2个–>16
3个–>23
4个–>30
5个–>37
大家可以自己像一个很好的办法来区分,这里我就简单的人工罗列。
注意不同分辨率的电脑这个数据也会改变的,大家可以做一个映射表即可。
def get_each_pic_num(imgPath, savePath):
global rct
files = os.listdir(imgPath)
files.sort()
for file in files:
fileType = os.path.splitext(file)
if fileType[1] == ‘.png’:
img = Image.open(imgPath + ‘/’ + file)
img = img.convert(“L”)
pixdata = img.load()
w, h = img.size
cut_times = 0
if w == 9:
rct = ((0, 0, 7, h),)
cut_times = 1
if w == 16:
rct = ((0, 0, 7, h),
(7, 0, 14, h))
cut_times = 2
if w == 23:
rct = ((0, 0, 7, h),
(7, 0, 14, h),
(14, 0, 21, h),)
cut_times = 3
if w == 30:
rct = ((0, 0, 7, h),
(7, 0, 14, h),
(14, 0, 21, h),
(21, 0, 28, h),)
cut_times = 4
if w == 37:
rct = ((0, 0, 7, h),
(7, 0, 14, h),
(14, 0, 21, h),
(21, 0, 28, h),
(28, 0, 35, h),)
cut_times = 5
cut_img = []
for part in range(cut_times):
cut_img.append(img.crop(rct[part]))
return img
d = 0
for im in cut_img:
d += 1
im.save(savePath + str(d) + str(file))
get_each_pic_num(‘./cutpic/’, ‘./each_character/’)
之后我们对图片进行切割,这里使用固定坐标切割,得到如下所示单个字符数据:


实现代码如下:
import os
from PIL import Image
灰度和二值化处理
def binarizing(imgPath, savePath):
files = os.listdir(imgPath)
files.sort()
img=Image.open(img).convert(“L”)
for file in files:
fileType = os.path.splitext(file)
if fileType[1] == ‘.png’:
img = Image.open(imgPath + ‘/’ + file)
img = img.convert(“L”)
pixdata = img.load()
w, h = img.size
for y in range(h):
for x in range(w):
if pixdata[x, y] < 220:
pixdata[x, y] = 0
else:
pixdata[x, y] = 255
removeFrame(img,1)
img.save(savePath + ‘/’ + file) # 保存图片
return img
def get_cut(file_name):
img = Image.open(file_name)
不同分辨率减去的值可能不同
可以做一个字典映射
right = img.size[0] - 39
right = img.size[0] - 47
cut_img = []
rct = (
(0, 0, right, 28), # 左边距 上边距 右边距 下边距
)
for part in range(1):
cut_img.append(img.crop(rct[part]))
return cut_img
二值化
binarizing(‘./pic/’, ‘./binpic/’)
切割保存
imgPath = ‘./binpic/’
files = os.listdir(imgPath)
files.sort()
for file in files:
fileType = os.path.splitext(file)
if fileType[1] == ‘.png’:
img = Image.open(imgPath + ‘/’ + file)
img = get_cut(imgPath + ‘/’ + file)
d = 0
for im in img:
d += 1
im.save(‘./cutpic/’ + str(file))
注意,切割后的单个图片要保证h和w是一致的。当然了大家可以尝试使用连通区域分割算法进行切割。
5、人工标注数据集
建立0-9一共10个文件夹,人工判断字符属于哪个文件夹,并将拆分的字符文件移动到对应的文件夹中。由于字符不是很复杂每一个文件夹只需大概20个文件即可:


6、机器学习
得到数据集之后,我们就可以构建机器学习模型。机器学习算法采用的是SVM算法,具体就不详解了,先图片数据转文本数据,
代码如下:
# 获取图像二值化数值
import numpy as np
from PIL import Image
import os, sys
def getBinaryPix(im):
im = Image.open(im)
im = im.convert(“L”)
img = np.array(im)
rows, cols = img.shape
print(img.shape)
for i in range(rows):
for j in range(cols):
if (img[i, j] <= 220):
img[i, j] = 0
else:
img[i, j] = 1
binpix = np.ravel(img)
binpix=img.reshape(1,rows*cols)
return binpix
def getfiles(path):
files = []
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Python开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024c (备注Python)

整理了一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。**
[外链图片转存中…(img-Cz8FTc7d-1712955740524)]
[外链图片转存中…(img-1VRr4pMW-1712955740524)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Python开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024c (备注Python)
[外链图片转存中…(img-CCi2CFkV-1712955740524)]















 732
732











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









