







1.产品定位:
数据克隆是高效,安全的从通过从线上指定数据库/表克隆数据,从而快速构建虚拟环境,提供更高效的数据交付服务。从效率上可以支持业务自助提取数据,分钟级快速构建环境,可以通过workbench等工具访问数据,整个过程基本不需要DBA手工操作介入。从安全上,支持数据操作日志审计,提供库/表访问过滤,随机虚拟环境和临时密码交付,此外会对虚拟环境使用时长进行限制,尽可能保证数据的使用安全。
2.适用场景:
目前数据克隆功能支持如下的场景:
1)线上配置数据的快速查看
2)提取线上表结构
3)日志数据查询,线上大表
4)线上SQL异常,快速构建虚拟环境进行SQL优化,压测等
5)指定大表的变更和数据操作影响评估
6)数据补丁合并,基于业务逻辑的数据操作和数据补丁整理
整个实现的过程有很多考虑的细节,不过还是在设计和实现中由同事和我一并解决了。
到了交付的时机了,我们想到还有一个关键的地方需要补充,那就是数据库和用户的权限关联,也就意味着每个人可以看到和使用的数据库应该是不大一样的,因为做一些权限隔离,所以接下来我会说说数据克隆方向的用户权限设计。
数据克隆的用户权限设计是面向业务使用的基础功能,目前对于用户权限的设计可以基于数据库级别。
权限的实现可以分两个阶段来完成:
1)数据初始化阶段,可以使用用户组批量初始化的方式,部分数据可以从工单历史中获取
2)定制化配置阶段,根据业务需求变更和组织架构调整进行数据库和用户映射关系的微调

其中,
实例信息和库信息可以基于数据库基线表 mysql_db_baseline
用户组信息和用户信息可以基于用户表 user_info
数据库-用户关系表需要新建,表名为:mysql_db_user_rel(id,ip_addr,db_port,db_name,user_id)
需要实现四个子功能:
1)数据库-用户关系映射,实现单一数据库和单一用户的关系,在关系表中为一条记录
言尽于此,完结
无论是一个初级的 coder,高级的程序员,还是顶级的系统架构师,应该都有深刻的领会到设计模式的重要性。
- 第一,设计模式能让专业人之间交流方便,如下:
程序员A:这里我用了XXX设计模式
程序员B:那我大致了解你程序的设计思路了
- 第二,易维护
项目经理:今天客户有这样一个需求…
程序员:明白了,这里我使用了XXX设计模式,所以改起来很快
- 第三,设计模式是编程经验的总结
程序员A:B,你怎么想到要这样去构建你的代码
程序员B:在我学习了XXX设计模式之后,好像自然而然就感觉这样写能避免一些问题
- 第四,学习设计模式并不是必须的
程序员A:B,你这段代码使用的是XXX设计模式对吗?
程序员B:不好意思,我没有学习过设计模式,但是我的经验告诉我是这样写的
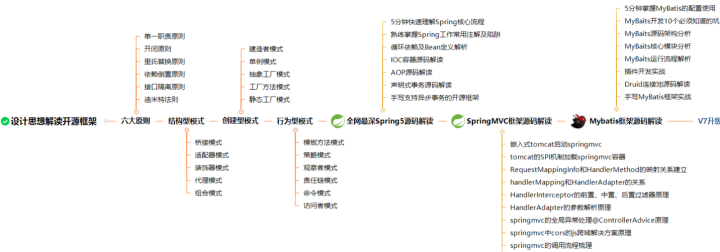
从设计思想解读开源框架,一步一步到Spring、Spring5、SpringMVC、MyBatis等源码解读,我都已收集整理全套,篇幅有限,这块只是详细的解说了23种设计模式,整理的文件如下图一览无余!
CodeChina开源项目:【一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频】
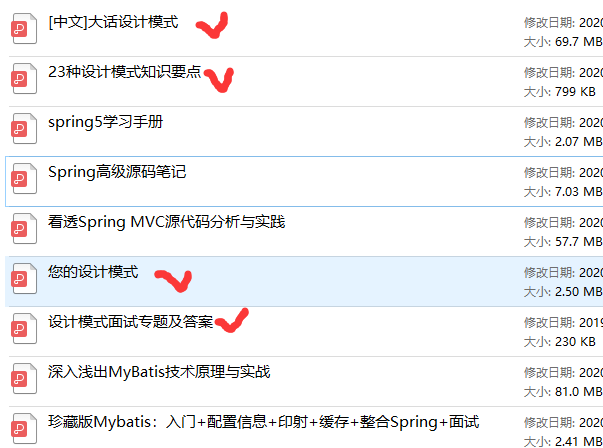
最新讲解视频】](https://codechina.csdn.net/m0_60958482/java-p7)**
[外链图片转存中…(img-ENHl3qv6-1631066791442)]
搜集费时费力,能看到此处的都是真爱!















 186
186











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









