







| 3 | 1,0,4 |
| 4 | 4,1,2 |
| 5 | 2,3,0 |
| 6 | 3,0,1 |
| 7 | 0,1,4 |
| 8 | 1,4,2 |
| 9 | 4,2,3 |
- BrokerList 是上面的集合{0,1,2,3,4} ; 但是并不是说顺序就是这样的,只是表示有这个几个Broker参与了分配
我们把每个分区的第一个副本取出来{2,3,0,1,4,2,3,0,1,4}; 从里面获取连续5个(尾部跟头部也是相连)包含所有Broker就可以把它当成BrokerLIst顺序, 这里我们可以取 {2,3,0,1,4}也可以取{0,1,4,2,3} 都可以; 这里我们最终选BrokerList={2,3,0,1,4}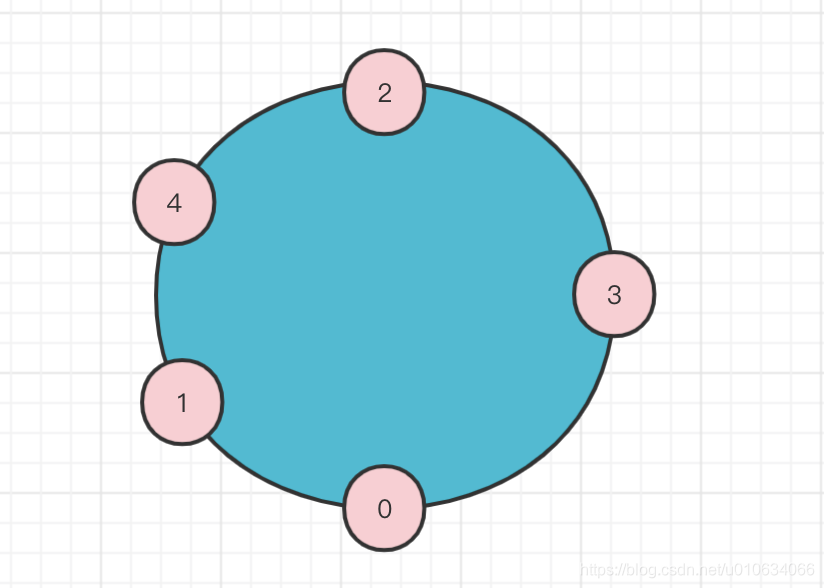
-
分区数可以指定是10个; 副本数是3个 -
起始随机数
startIndex这个值,的获取跟上面的BrokerList有关系; 比如我们选择了BrokerList={2,3,0,1,4}; 先看看第一个分区的第一个副本是 2;再看2在BrokerList中的第几个位置; 看到是第一个位置,那么索引值就=0;startIndex=0 -
起始随机
nextReplicaShift就看看前面几个分区的第一个副本和第二个副本的差值; 我们把上面的转换一下成索引位置
| 分区号 | brokerlist中索引值 | 副本1和副本2的差值 |
| — | — | — |
| 0 | 0,4,1 | 3 |
| 1 | 1,0,2 | 3(1->2->3->4->0 中间差值是2,3,4) |
| 2 | 2,1,3 | 3 |
| 3 | 3,2,4 | 3 |
| 4 | 4,3,0 | 3 |
所以起始随机nextReplicaShift=3
到这里我们已经把所有变量算出来了
BrokerList={2,3,0,1,4}
- 分区数=10
- 副本数=3
- 起始随机数
startIndex=0
- 起始随机
nextReplicaShift=3
按照这些参数,重新调用接口AdminUtils.assignReplicasToBrokersRackUnaware 就肯定能够得到一模一样的分配数据
然后这个时候只调整副本数这个参数的话,就可以满足我们上面最小变动副本的要求了;
当然: AdminUtils.assignReplicasToBrokersRackUnaware 并不能完全满足我们需求,因为nextReplicaShift=3不是参入传入的,是在里面随机产生的,所以我们自己按照这个方法写一个新方法微一下就行了;
如果副本的分配原本是自己手动指定的,并不是kafka自动计算的,则上面方法不可用; 那么只能直接用kafka接口重新计算,完全重新分配了


如果已经进行过分区扩容
我们先回忆一下,如果进行过分区扩容,那么分区计算的并不是按照一个原则来进行分配的; 请看【kafka源码】kafka分区副本的分配规则 ; 如果还按照上面的方式来进行,那肯定达不到最小粒度的副本扩容了; 因为后面进行过扩分区的分区肯定会进行数据移动;
把之前的例子搬过来再看看;
例如我有个topic 2分区 3副本; 分配情况
起始随机startIndex:0currentPartitionId:0;起始随机nextReplicaShift:2;brokerArray:ArrayBuffer(0, 1, 4, 2, 3)
(p-0,ArrayBuffer(0, 2, 3))
(p-1,ArrayBuffer(1, 3, 0))
我们来计算一下,第3个分区如果同样条件的话应该分配到哪里
- 先确定一下分配当时的BrokerList 按照顺序的关系0->2->3 1->3->0 至少 我们可以画出下面的图
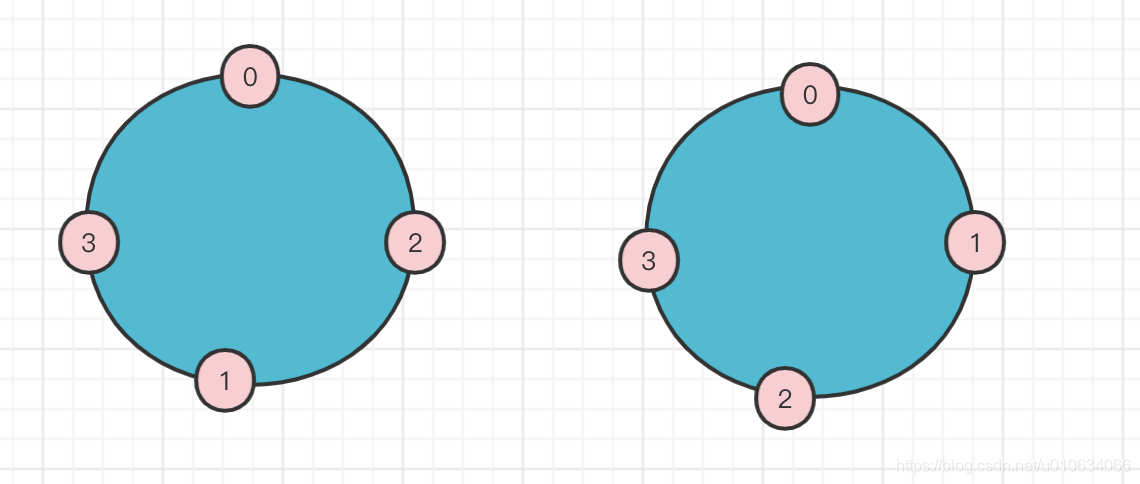
-
又根据2->3(2下一个是3) 3->0(3下一个是0)这样的关系可以知道
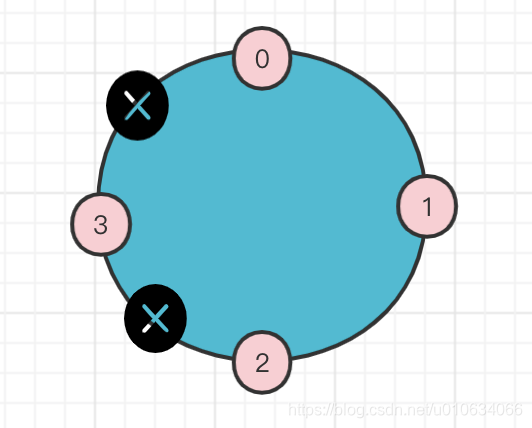
-
又要满足 0->2 和 1->3的跨度要满足一致(当然说的是在同一个遍历范围内
currentPartitionId / brokerArray.length 相等) -
又要满足0->1是连续的那么Broker4只能放在1-2之间了;(正常分配的时候,每个分区的第一个副本都是按照brokerList顺序下去的,比如P1(0,2,3),P2(1,3,0), 那么0->1之间肯定是连续的; )
结果算出来是BrokerList={0,1,4,2,3} 跟我们打印出来的相符合;
那么同样可以计算出来, startIndex=0;(P1的第一个副本id在BrokerList中的索引位置,刚好是索引0,起始随机 nextReplicaShift = 2(P1 0->2 中间隔了1->4>2 ))
指定这些我们就可以算出来新增一个分区P3的位置了吧?
P3(4,0,1)
然后执行新增一个分区脚本之后,并不是按照上面分配之后的 {4,0,1} ; 而是如下
起始随机startIndex:0 currentPartitionId:2;起始随机nextReplicaShift:0;brokerArray:ArrayBuffer(0, 1, 2, 3, 4)
(p-2,ArrayBuffer(2, 3, 4))
如果我又进行扩分区操作的话,还是一样的逻辑; 假如我这再次新增一个分区
BrokerList={0,1,2,3,4} 扩分区的BrokerList都是经过排序的;
currentPartitionId=3 起始随机nextReplicaShift=startIndex=第一个分区第一个副本BrokerId在BrokerList中的索引值=0
那么P3是{3,4,0}
来,执行一下看看结果
起始随机startIndex:0currentPartitionId:3;起始随机nextReplicaShift:0;brokerArray:ArrayBuffer(0, 1, 2, 3, 4)
(p-3,ArrayBuffer(3, 4, 0))
那么这种情况下怎么进行分配?
如果还是想要实现我们的目标,最小成本的去扩缩副本,那么我们就需要找到是从哪个分区开始进行了 扩分区的操作
假如现在的分区
0,2,3
1,3,0
2,3,4
3,4,0
先去验证是否有冲突的地方; 比如上面3>4(3下一个是4) 3>0(3下一个是0) 就冲突了;
就可以直接去掉后面两个,再验证
0,2,3
1,3,0
是否冲突
然后根据不同情况来进行重新分配;
同时又有其他问题 比如 存在手动分配过的分区 这种不是按照固定的规则来分配的,也不能按照上面的处理, 这种就需要重新完全分配了
所以总结起来,这种思路可行, 但没有必要; 我也是写到了这里,才觉得没有必要
相比第一种想法, 需要考虑过多的情况,这个想法就简单霸道多了
直接再每一个分区的最后一个副本上顺推就行了(如果是缩副本就减小)
比如5个Broker 4分区 3副本, 前面两个是创建的时候分配的,后面两个是分区扩容分配的
“0”:[0,1,4]
“1”:[1,4,2]
“2”:[4,2,3]
再扩容3个分区
“3”:[3,4,0]
“4”:[4,0,1]
“5”:[0,2,3]
副本扩容
就直接假定BrokerList[0,1,2,3,4], 然后将最后一个副本往后顺推一个可用Broker;
“0”:[0,1,4] ==》 [0,1,4,2]
“1”:[1,4,2] ==》 [1,4,2,3]
“2”:[4,2,3] ==》 [4,2,3,1]
再扩容3个分区
“3”:[3,4,0] ==》 [3,4,0,1]
“4”:[4,0,1] ==》 [4,0,1,2]
“5”:[0,2,3] ==》 [0,2,3,4]
如果都只有一个副本,那么按照分区号简单做一个排序(一般情况是按照分区号大小顺序排的), 然后得到一个BrokerList; 接着按照之前的算法重新计算就行,为啥不直接顺推出第二个位置,因为原来第一和第二副本之间会根据遍历的次数nextReplicaShift+1
副本缩小
直接从最后删除,多出来的副本
“0”:[0,1,4] ==》 [0,1]
小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数初中级Java工程师,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Java开发全套学习资料》送给大家,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。

由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频
如果你觉得这些内容对你有帮助,可以添加下面V无偿领取!(备注Java)

总结
总体来说,如果你想转行从事程序员的工作,Java开发一定可以作为你的第一选择。但是不管你选择什么编程语言,提升自己的硬件实力才是拿高薪的唯一手段。
如果你以这份学习路线来学习,你会有一个比较系统化的知识网络,也不至于把知识学习得很零散。我个人是完全不建议刚开始就看《Java编程思想》、《Java核心技术》这些书籍,看完你肯定会放弃学习。建议可以看一些视频来学习,当自己能上手再买这些书看又是非常有收获的事了。

**
如果你觉得这些内容对你有帮助,可以添加下面V无偿领取!(备注Java)
[外链图片转存中…(img-NfEazCj8-1711090706612)]
总结
总体来说,如果你想转行从事程序员的工作,Java开发一定可以作为你的第一选择。但是不管你选择什么编程语言,提升自己的硬件实力才是拿高薪的唯一手段。
如果你以这份学习路线来学习,你会有一个比较系统化的知识网络,也不至于把知识学习得很零散。我个人是完全不建议刚开始就看《Java编程思想》、《Java核心技术》这些书籍,看完你肯定会放弃学习。建议可以看一些视频来学习,当自己能上手再买这些书看又是非常有收获的事了。
[外链图片转存中…(img-djGdEaGc-1711090706613)]














 2385
2385











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









