







实例要求
使用PySimpleGUI做一个把单位考勤系统导出的pdf文件合并输出Excel的应用,故事出自:
https://hannyang.blog.csdn.net/article/details/135395946
当时时间紧,没有好好做界面且输出csv文件了事。今天趁周六休息,把代码做一下升级处理,使用库PySimpleGUI做了一个稍微漂亮一点的界面;又用pdfplumber直接遍历多个pdf文件,得到数据后输出Excel文件,比我原本先做合并pdf文件再去取数要快,原先的pdf文件合并操作纯粹有点多余。最后,又尝试对pdf文件读取函数的改造,使用了asyncio异步编程效果非常不错。
下面请听我慢慢道来:
原始pdf文件格式

输出xls文件格式

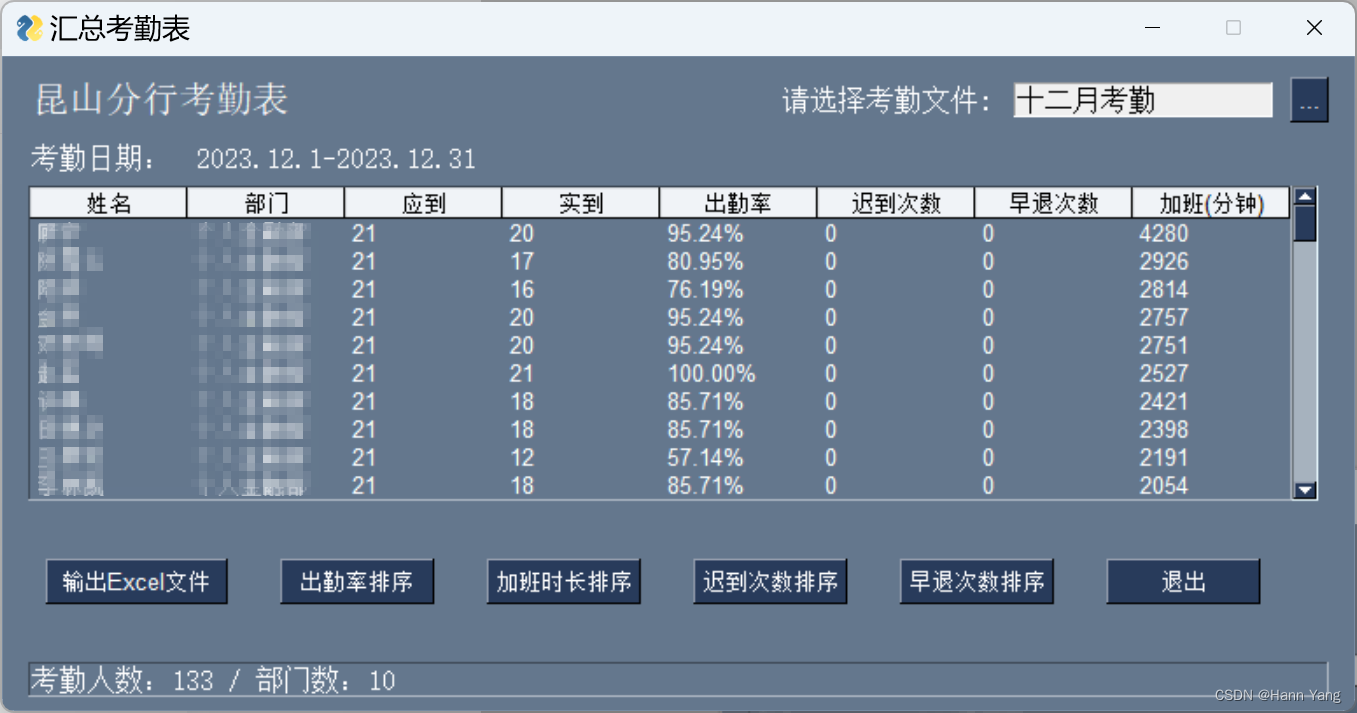
运行界面
完整代码
import xlwt, pyperclip, asyncio, pdfplumber
import os, time, datetime as dt
import PySimpleGUI as sg
# 全局变量
table_head = '姓名,部门,应到,实到,出勤率,迟到次数,早退次数,加班(分钟)'
path, font = '', ('宋体',12)
date, data = [], []
DateFormat = ' . . - . . '
ErrMessage = '错误'
SortedType = ["出勤率排序","加班时长排序","迟到次数排序","早退次数排序"]
# 定义布局
layout = [
[sg.Text("昆山分行考勤表",font=('',16)),
sg.Text(pad=(132,10)),
sg.Text("请选择考勤文件:",font=font),
sg.Input(key="-FOLDER-", enable_events=True, readonly=True,font=font,size=18),
sg.FolderBrowse(button_text='...', enable_events=True, initial_folder='./')
],
[sg.Text("考勤日期:",font=font),
sg.Text(DateFormat,key='-DATE-',font=font)
],
[sg.Table(values='',
headings=table_head.split(','),
key='-TABLE-',
auto_size_columns=False,
justification='left',
num_rows=10)],
[sg.Button("输出Excel文件",size=(12,1),pad=(15,30)),
sg.Button(SortedType[0], enable_events=True,size=(10,1),pad=(15,30)),
sg.Button(SortedType[1], enable_events=True,size=(10,1),pad=(15,30)),
sg.Button(SortedType[2], enable_events=True,size=(10,1),pad=(15,30)),
sg.Button(SortedType[3], enable_events=True,size=(10,1),pad=(15,30)),
sg.Button("退出",size=(10,1),pad=(15,30))],
[sg.StatusBar('',key="-BAR-",font=font,size=92)]
]
# 读取pdf表格
async def read_table(file):
dct = dict()
with pdfplumber.open(file) as pdf:
for page in pdf.pages:
tables = page.extract_tables(table_settings = {})
for table in tables:
for lst in table:
tmp = lst[1:]
if not any(tmp): continue
tmp = [tmp[0]]+tmp[3:8]+[tmp[-1]]
tmp[0] = tmp[0].replace('\n','')
tmp[0] = tmp[0].split('/')
tmp[0] = tmp[0][-1]
if lst[0]=='时间':
dct[lst[0]] = tmp[0]
else:
dct[','.join([lst[0],tmp[0]])] = ','.join(tmp[1:])
return dct
# 写入xls文件
def write_sheet():
global data, date, table_head, ErrMessage
if ErrMessage[:2] in ('错误','文件'): return
myxl = xlwt.Workbook()
style = xlwt.easyxf('align: wrap yes; align: horiz center; font: bold yes;')
sheet = myxl.add_sheet('考勤表')
wcol = [20,40,60,30,30,40,40,40,60]
for i,w in enumerate(wcol):
sheet.col(i).width = w * 80
sheet.write_merge(0,0,0,8,'出勤统计报表',style)
style = xlwt.easyxf('borders:top thin; borders:bottom thin; borders:left thin; borders:right thin;')
sheet.write_merge(1,1,0,2,'考勤日期:'+date[0])
for i,head in enumerate(['序号']+table_head.split(',')):
sheet.write(2,i,head,style)
for i,row in enumerate(data):
for j,col in enumerate([str(i+1)]+row):
sheet.write(3+i,j,col,style)
for i,t in enumerate(SortedType):
if t in ErrMessage:
tmp = SortedType[i]
break
else: tmp = ""
excel_file = f'昆山分行考勤表{date[0]}({tmp}{strDateTime()}).xls'
ErrMessage = f'文件输出为:{excel_file}'
try:
myxl.save(excel_file)
except:
ErrMessage = '写入excel文件失败!'
finally:
pyperclip.copy('\\'.join((os.getcwd(),excel_file)))
window['-BAR-'].update(ErrMessage)
# 获取当前时间
def strDateTime(diff=0):
now = dt.datetime.now()
time = now + dt.timedelta(days=diff)
return f'{time.year}{time.month:02}{time.day:02}{time.hour:02}{time.minute:02}{time.second:02}'
# 选择并处理文件
async def on_text_changed(event, values):
global date, data, path, ErrMessage
new_path = values["-FOLDER-"]
window["-FOLDER-"].update(new_path.split('/')[-1])
if path==new_path: return
else: path = new_path
pdfs = [f for f in os.listdir(path) if f.endswith('.pdf') and not f.startswith('PDFmerged')]
nums = len(pdfs)
if nums==0:
ErrMessage = '错误:所选文件夹中没有PDF文件!'
window['-BAR-'].update(ErrMessage)
window['-DATE-'].update(DateFormat)
window['-TABLE-'].update(values=[])
return
date, data, sheet = [], [], dict()
tasks = []
for pdf in pdfs:
tasks.append(read_table('/'.join([path,pdf])))
ErrMessage = f'文件读取中(共{nums}个PDF文件)......'
window['-BAR-'].update(ErrMessage)
window.refresh()
results = await asyncio.gather(*tasks)
for r in results:
dt = r.get('时间',None)
if dt: date.append(dt)
sheet.update(r)
if date:
window['-DATE-'].update(date[-1])
for k,v in sheet.items():
if k in ('时间','姓名,所属组织','普通班个人出勤统计报表,'): continue
data.append(','.join([k,v]).split(','))
window['-TABLE-'].update(values=data)
persons = len(data)
departments = len(set([d[1] for d in data]))
if 0:#len(set(date))!=1:
data = []
ErrMessage = f'错误:请检查所选文件存在多个时间段:{",".join(set(date))}'
else:
ErrMessage = f'考勤人数:{persons} / 部门数:{departments}'
window['-BAR-'].update(ErrMessage)
# 表格排序
def on_table_sorted(event, data):
global ErrMessage
if not data: return
slist = ['x[-4][:-1]', 'x[-1]', 'x[-3]', 'x[-2]']
style = slist[SortedType.index(event)]
data = sorted(data, key=lambda x: float(eval(style)), reverse=True)
window['-TABLE-'].update(values=data)
ErrMessage = f'已按{event}更新!'
window['-BAR-'].update(ErrMessage)
# 创建窗口
window = sg.Window("考勤表汇总", layout, finalize=True)
# 事件循环
while True:
event, values = window.read()
if event == sg.WINDOW_CLOSED or event == "退出":
break
elif event == "-FOLDER-":
asyncio.run(on_text_changed(event, values))
elif event in SortedType:
on_table_sorted(event, data)
elif event == "输出Excel文件":
write_sheet()
# 关闭窗口
window.close()
代码分析
重点代码都用彩色字体加粗标注了:
遍历表格
读取代码如下:
import pdfplumber
…
with pdfplumber.open(file) as pdf:
for page in pdf.pages:
tables = page.extract_tables(table_settings = {})
for table in tables:
for lst in table:
# 根据表格实际情况来清洗数据
return dct
布局界面
import PySimpleGUI as pg
layout = [
[sg.Text(“昆山分行考勤表”,font=(‘’,16)),
sg.Text(pad=(132,10)),
sg.Text(“请选择考勤文件:”,font=font),
sg.Input(key=“-FOLDER-”, enable_events=True, readonly=True,font=font,size=18),
sg.FolderBrowse(button_text=‘…’, enable_events=True, initial_folder=‘./’)
],
[sg.Text(“考勤日期:”,font=font),
sg.Text(DateFormat,key=‘-DATE-’,font=font)
],
[sg.Table(values=‘’,
headings=table_head.split(‘,’),
如果你也是看准了Python,想自学Python,在这里为大家准备了丰厚的免费学习大礼包,带大家一起学习,给大家剖析Python兼职、就业行情前景的这些事儿。
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。

四、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。


四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

五、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

成为一个Python程序员专家或许需要花费数年时间,但是打下坚实的基础只要几周就可以,如果你按照我提供的学习路线以及资料有意识地去实践,你就有很大可能成功!
最后祝你好运!!!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!














 3864
3864











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









