







最后
🍅 硬核资料:关注即可领取PPT模板、简历模板、行业经典书籍PDF。
🍅 技术互助:技术群大佬指点迷津,你的问题可能不是问题,求资源在群里喊一声。
🍅 面试题库:由技术群里的小伙伴们共同投稿,热乎的大厂面试真题,持续更新中。
🍅 知识体系:含编程语言、算法、大数据生态圈组件(Mysql、Hive、Spark、Flink)、数据仓库、Python、前端等等。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
Traceback (most recent call last):
File “”, line 1, in
AttributeError: ‘NoneType’ object has no attribute ‘group’
**示例3**:`\d`用法
import re
普通的匹配方式
ret = re.match(“嫦娥1号”,“嫦娥1号发射成功”)
print(ret.group())
嫦娥1号
ret = re.match(“嫦娥2号”,“嫦娥2号发射成功”)
print(ret.group())
嫦娥2号
ret = re.match(“嫦娥3号”,“嫦娥3号发射成功”)
print(ret.group())
嫦娥3号
使用\d进行匹配
ret = re.match(“嫦娥\d号”,“嫦娥1号发射成功”)
print(ret.group())
嫦娥1号
ret = re.match(“嫦娥\d号”,“嫦娥2号发射成功”)
print(ret.group())
嫦娥2号
ret = re.match(“嫦娥\d号”,“嫦娥3号发射成功”)
print(ret.group())
嫦娥3号
**其他的匹配符参见后面章节的讲解**
### 3、匹配多个字符
匹配多个字符的相关格式
| 字符 | 功能 |
| --- | --- |
| `*` | 匹配前一个字符出现0次或者无限次,即可有可无 |
| `+` | 匹配前一个字符出现1次或者无限次,即至少有1次 |
| `?` | 匹配前一个字符出现1次或者0次,即要么有1次,要么没有 |
| `{m}` | 匹配前一个字符出现m次 |
| `{m,n}` | 匹配前一个字符出现从m到n次 |
**示例1**:`*`用法
需求:匹配出,一个字符串第一个字母为大小字符,后面都是小写字母并且这些小写字母可有可无
import re
ret = re.match(“[A-Z][a-z]*”,“M”)
print(ret.group())
M
ret = re.match(“[A-Z][a-z]*”,“MnnM”)
print(ret.group())
Mnn
ret = re.match(“[A-Z][a-z]*”,“Aabcdef”)
print(ret.group())
Aabcdef
**示例2**:`+`用法
需求:匹配出,变量名是否有效
import re
names = [“name1”, “_name”, “2_name”, “__name__”]
for name in names:
ret = re.match(“[a-zA-Z_]+[\w]*”,name)
if ret:
print(“变量名 %s 符合要求” % ret.group())
else:
print(“变量名 %s 非法” % name)
输出结果:
变量名 name1 符合要求
变量名 _name 符合要求
变量名 2_name 非法
变量名 name 符合要求
示例3:`?`用法
需求:匹配出,0到99之间的数字
import re
ret = re.match(“[1-9]?[0-9]”,“7”)
print(ret.group())
7
ret = re.match(“[1-9]?\d”,“33”)
print(ret.group())
33
ret = re.match(“[1-9]?\d”,“09”)
print(ret.group())
0 # 这个结果并不是想要的,利用$才能解决
**示例4**:`{m}`用法
需求:匹配出,8到20位的密码,可以是大小写英文字母、数字、下划线
import re
ret = re.match(“[a-zA-Z0-9_]{6}”,“12a3g45678”)
print(ret.group())
12a3g4
ret = re.match(“[a-zA-Z0-9_]{8,20}”,“1ad12f23s34455ff66”)
print(ret.group())
1ad12f23s34455ff66
### 4、匹配开头结尾
| 字符 | 功能 |
| --- | --- |
| `^` | 匹配字符串开头 |
| `$` | 匹配字符串结尾 |
**示例1**: `^`用法
需要:匹配以135开头的电话号码
import re
ret = re.match(“^135[0-9]{8}”,“13588888888”)
print(ret.group())
13588888888
ret = re.match(“^135[0-9]{8}”,“13512345678”)
print(ret.group())
13512345678
136开头的没法匹配就会报错
ret = re.match(“^135[0-9]{8}”,“13688888888”)
print(ret.group())
Traceback (most recent call last):
File “”, line 1, in
AttributeError: ‘NoneType’ object has no attribute ‘group’
**示例2**:$
需求:匹配出163的邮箱地址,且@符号之前有4到20位,例如hello@163.com
import re
email_list = [“xiaoWang@163.com”, “xiaoWang@163.comheihei”, “.com.xiaowang@qq.com”]
for email in email_list:
ret = re.match(“[\w]{4,20}@163.com$”, email)
if ret:
print(“%s 是符合规定的邮件地址,匹配后的结果是:%s” % (email, ret.group()))
else:
print(“%s 不符合要求” % email)
输出结果:
xiaoWang@163.com 是符合规定的邮件地址,匹配后的结果是:xiaoWang@163.com
xiaoWang@163.comheihei 不符合要求
.com.xiaowang@qq.com 不符合要求
### 5、匹配分组
| 字符 | 功能 |
| --- | --- |
| ` | ` |
| `(ab)` | 将括号中字符作为一个分组 |
| `\num` | 引用分组num匹配到的字符串 |
| `(?P<name>)` | 分组起别名 |
| `(?P=name)` | 引用别名为name分组匹配到的字符串 |
**示例1**:`|`用法
需求:匹配出0-100之间的数字
import re
ret = re.match(“[1-9]?\d”,“8”)
print(ret.group())
8
ret = re.match(“[1-9]?\d”,“78”)
print(ret.group())
78
不正确的情况
ret = re.match(“[1-9]?\d”,“08”)
print(ret.group())
0
修正之后的
ret = re.match(“[1-9]?\d$”,“08”)
if ret:
… print(ret.group())
… else:
… print(“不在0-100之间”)
…
不在0-100之间
添加|
ret = re.match(“[1-9]?\d$|100”,“8”)
print(ret.group()) # 8
8
ret = re.match(“[1-9]?\d$|100”,“78”)
print(ret.group()) # 78
78
ret = re.match(“[1-9]?\d$|100”,“08”)
print(ret.group()) # 不是0-100之间
ret = re.match(“[1-9]?\d$|100”,“100”)
print(ret.group()) # 100
100
**示例2**:`()`用法
需求:匹配出163、126、qq邮箱
import re
ret = re.match(“\w{4,20}@163.com”, “test@163.com”)
print(ret.group())
test@163.com
ret = re.match(“\w{4,20}@(163|126|qq).com”, “test@126.com”)
print(ret.group())
test@126.com
ret = re.match(“\w{4,20}@(163|126|qq).com”, “test@qq.com”)
print(ret.group())
test@qq.com
ret = re.match(“\w{4,20}@(163|126|qq).com”, “test@gmail.com”)
if ret:
… print(ret.group())
… else:
… print(“不是163、126、qq邮箱”)
…
不是163、126、qq邮箱
需求:不是以4、7结尾的手机号码(11位)
import re
tels = [“13100001234”, “18912344321”, “10086”, “18800007777”]
for tel in tels:
ret = re.match(“1\d{9}[0-35-68-9]”, tel)
if ret:
print(ret.group())
else:
print(“%s 不是想要的手机号” % tel)
输出结果:
18912344321
10086 不是想要的手机号
18800007777 不是想要的手机号
需求:提取区号和电话号码
import re
ret = re.match(“([^-]*)-(\d+)”,“010-12345678”)
print(ret.group())
010-12345678
print(ret.group(1))
010
print(ret.group(2))
12345678
**示例3**:`\`用法
需求:匹配出`<html>hh</html>`
import re
hh能够完成对正确的字符串的匹配
ret = re.match(“<[a-zA-Z]*>\w*</[a-zA-Z]*>”, “hh”)
print(ret.group())
hh如果遇到非正常的html格式字符串,匹配出错
ret = re.match(“<[a-zA-Z]*>\w*</[a-zA-Z]*>”, “hh”)
print(ret.group())
正确的理解思路:如果在第一对<>中是什么,按理说在后面的那对<>中就应该是什么
通过引用分组中匹配到的数据即可,但是要注意是元字符串,即类似 r""这种格式
hhret = re.match(r"<([a-zA-Z]*)>\w*</\1>", “hh”)
print(ret.group())
因为2对<>中的数据不一致,所以没有匹配出来
hh 这是一对不正确的标签test_label = “hh”
ret = re.match(r"<([a-zA-Z]*)>\w*</\1>“, test_label)
if ret:
… print(ret.group())
… else:
… print(”%s 这是一对不正确的标签" % test_label)
…
**示例4:**`\number`用法
需求:匹配出`<html><h1>www.itcast.cn</h1></html>`
import re
labels = [“
www.itcast.cn
”, “www.itcast.cn
”]for label in labels:
ret = re.match(r"<(\w*)><(\w*)>.*</\2></\1>“, label)
if ret:
print(”%s 是符合要求的标签" % ret.group())
else:
print(“%s 不符合要求” % label)
输出结果:
www.itcast.cn
是符合要求的标签www.itcast.cn
不符合要求
**示例5**:`(?P<name>) (?P=name)`用法
需求:匹配出`<html><h1>www.itcast.cn</h1></html>`
import re
ret = re.match(r"<(?P\w*)><(?P\w*)>.*</(?P=name2)></(?P=name1)>", “
www.itcast.cn
”)
print(ret.group())
www.itcast.cn
ret = re.match(r"<(?P\w*)><(?P\w*)>.*</(?P=name2)></(?P=name1)>", “
www.itcast.cn
”)
print(ret.group())
Traceback (most recent call last):
File “”, line 1, in
AttributeError: ‘NoneType’ object has no attribute ‘group’
**注意**:`(?P<name>)和(?P=name)`中的字母p大写

### 6、高级用法
#### re.search
>
> re.search 扫描整个字符串并返回第一个成功的匹配;匹配成功re.search方法返回一个匹配的对象,否则返回None。
>
>
>
**函数语法**:`re.search(pattern, string, flags=0)`
**参数说明**:
* `pattern`: 匹配的正则表达式
* `string`: 要匹配的字符串。
* `flags`: 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
案例:
import re
line = “Cats are smarter than dogs”
searchObj = re.search( r’(.*) are (.*?) .*', line, re.M|re.I)
if searchObj:
print ("searchObj.group() : ", searchObj.group())
print ("searchObj.group(1) : ", searchObj.group(1))
print ("searchObj.group(2) : ", searchObj.group(2))
else:
print (“Nothing found!!”)
输出结果:
searchObj.group() : Cats are smarter than dogs
searchObj.group(1) : Cats
searchObj.group(2) : smarter
**re.match与re.search的区别**
>
> re.match 只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回 None,而 re.search 匹配整个字符串,直到找到一个匹配。
>
>
>
import re
line = “Cats are smarter than dogs”
matchObj = re.match( r’dogs’, line, re.M|re.I)
if matchObj:
print ("match --> matchObj.group() : ", matchObj.group())
else:
print (“No match!!”)
matchObj = re.search( r’dogs’, line, re.M|re.I)
if matchObj:
print ("search --> matchObj.group() : ", matchObj.group())
else:
print (“No match!!”)
输出结果:
No match!!
search --> matchObj.group() : dogs
#### re.findall
>
> 在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果有多个匹配模式,则返回元组列表,如果没有找到匹配的,则返回空列表。
>
>
>
**注意**: match 和 search 是匹配一次 findall 匹配所有。
**函数语法**:`re.findall(pattern, string, flags=0)`
**参数说明**:
* `pattern`: 匹配的正则表达式
* `string`: 要匹配的字符串。
* `flags`: 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
**案例**:统计出python、c、c++相应文章阅读的次数
import re
ret = re.findall(r"\d+", “python = 9999, c = 7890, c++ = 12345”)
print(ret)
[‘9999’, ‘7890’, ‘12345’]
**案例**:多个匹配模式,返回元组列表
import re
result = re.findall(r’(\w+)=(\d+)', ‘set width=20 and height=10’)
print(result)
[(‘width’, ‘20’), (‘height’, ‘10’)]
#### re.sub
>
> 将匹配到的数据进行替换
>
>
>
**函数语法**:`re.sub(pattern, repl, string, count=0, flags=0)`
**参数说明**(前三个为必选参数,后两个为可选参数。):
* `pattern` : 正则中的模式字符串。
* `repl` : 替换的字符串,也可为一个函数。
* `string` : 要被查找替换的原始字符串。
* `count` : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
* `flags` : 编译时用的匹配模式,数字形式。
案例:
import re
phone = “2004-959-559 # 这是一个电话号码”
删除注释
num = re.sub(r’#.*$', “”, phone)
print ("电话号码 : ", num)
电话号码 : 2004-959-559移除非数字的内容
num = re.sub(r’\D’, “”, phone)
print ("电话号码 : ", num)
电话号码 : 2004959559
**repl 参数是一个函数**
**案例**:将字符串中的匹配的数字乘于 2
import re
将匹配的数字乘于 2
def double(matched):
value = int(matched.group(‘value’))
return str(value * 2)
s = ‘A23G4HFD567’
print(re.sub(‘(?P\d+)’, double, s))
输出结果:
A46G8HFD1134
#### re.split
>
> 根据匹配进行切割字符串,并返回一个列表
>
>
>
**函数语法**:`re.split(pattern, string[, maxsplit=0, flags=0])`
**参数说明**:
* `pattern`: 匹配的正则表达式
* `string`: 要匹配的字符串。
* `maxsplit`:分割次数,maxsplit=1 分割一次,默认为 0,不限制次数。
* `flags`: 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
**案例**:以`:`或者`空格`切割字符串“info:xiaoZhang 33 shandong”
import re
ret = re.split(r"😐 ",“info:xiaoZhang 33 shandong”)
print(ret)
[‘info’, ‘xiaoZhang’, ‘33’, ‘shandong’]
**案例**:对于一个找不到匹配的字符串而言,split 不会对其作出分割
import re
re.split(‘a’, ‘hello world’)
[‘hello world’]
### 7、特殊语法讲解
#### (?:pattern)
>
> `()`表示捕获分组,`()`会把每个分组里的匹配的值保存起来,从左向右,以分组的左括号为标志,第一个出现的分组的组号为1,第二个为2,以此类推。而`(?:)`表示非捕获分组,和捕获分组唯一的区别在于,非捕获分组匹配的值不会保存起来。
>
>
>
import re
a = “123abc456”
捕获所有分组
ret = re.search(“([0-9]*)([a-z]*)([0-9]*)”,a)
print(ret.group(1))
123
print(ret.group(2))
abc
print(ret.group(3))
456
仅捕获后两个分组
ret = re.search(“(?:[0-9]*)([a-z]*)([0-9]*)”,a)
print(ret.group(1))
abc
print(ret.group(2))
456
print(ret.group(3)) # 因为第一个括号中的分组并未捕获所有只有两个分组数据
Traceback (most recent call last):
File “”, line 1, in
IndexError: no such group
**说明**:`(?:pattern)`匹配 pattern 但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。
#### (?=pattern)
>
> 正向肯定预查(look ahead positive assert),匹配pattern前面的位置。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。
>
>
>
import re
ret = re.search(“Windows(?=95|98|NT|2000)”,“Windows2000”)
print(ret.group())
Windows
ret = re.search(“Windows(?=95|98|NT|2000)”,“Windows3.1”)
print(ret.group())
Traceback (most recent call last):
File “”, line 1, in
AttributeError: ‘NoneType’ object has no attribute ‘group’
**说明**:`"Windows(?=95|98|NT|2000)"`能匹配`"Windows2000"`中的 Windows,但不能匹配`"Windows3.1"`中的 Windows。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。
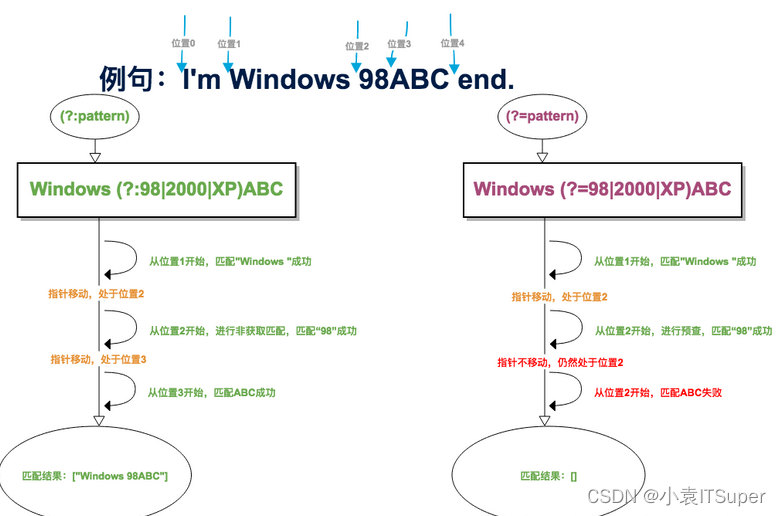
`(?:pattern)`和`(?=pattern)`的区别:
* (?:pattern) 匹配得到的结果包含pattern,(?=pattern) 则不包含。如:
import re
(?:pattern)
ret = re.search(“industr(?:y|ies)”,“industry abc”)
print(ret.group())
industry
(?=pattern)
ret = re.search(“industr(?=y|ies)”,“industry abc”)
print(ret.group())
industr
* (?:pattern) 消耗字符,下一字符匹配会从已匹配后的位置开始。(?=pattern) 不消耗字符,下一字符匹配会从预查之前的位置开始,如:
#### (?!pattern)
>
> 正向否定预查(negative assert),在任何不匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。
>
>
>
import re
ret = re.search(“Windows(?!95|98|NT|2000)”,“Windows2000”)
print(ret.group())
Traceback (most recent call last):
File “”, line 1, in
AttributeError: ‘NoneType’ object has no attribute ‘group’
ret = re.search(“Windows(?!95|98|NT|2000)”,“Windows3.1”)
print(ret.group())
Windows
**说明**:`"Windows(?=95|98|NT|2000)"`不能匹配`"Windows2000"`中的 Windows,但能匹配`"Windows3.1"`中的 Windows。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。与(?=pattern)相反
### 8、python贪婪和非贪婪
>
> 正则表达式模式中使用到通配字,那它在从左到右的顺序求值时,会尽量“抓取”满足匹配最长字符串。Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪则相反,总是尝试匹配尽可能少的字符。在`"*","?","+","{m,n}"`后面加上`?`,使贪婪变成非贪婪。
>
>
>
import re
str = ‘www.baidu.com/path’
‘+’贪婪模式,匹配1个或多个
ret = re.match(r’\w+', str)
print(ret.group())
www
‘+?’非贪婪模式,匹配1个
ret = re.match(r’\w+?', str)
print(ret.group())
w
{2,5}贪婪模式最少匹配2个,最多匹配5个
ret = re.match(r’\w{2,5}', str)
print(ret.group())
www
{2,5}?非贪婪模式,匹配两个
ret = re.match(r’\w{2,5}?', str)
print(ret.group())
ww
### 9、r的作用
>
> 与大多数编程语言相同,正则表达式里使用`"\"`作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符`"\"`,那么使用编程语言表示的正则表达式里将需要`4个反斜杠"\\"`:前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。
>
>
>
>
> Python里的原生字符串`r'`很好地解决了这个问题,有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
>
>
>
import re
mm = “c:\a\b\c”
mm
‘c:\a\b\c’
print(mm)
c:\a\b\c
re.match(“c:\\”,mm).group()
‘c:\’
ret = re.match(“c:\\”,mm).group()
print(ret)
c:\
ret = re.match(“c:\\a”,mm).group()
print(ret)
c:\a
ret = re.match(r"c:\a",mm).group()
print(ret)
c:\a
ret = re.match(r"c:\a",mm).group()
Traceback (most recent call last):
File “”, line 1, in
AttributeError: ‘NoneType’ object has no attribute ‘group’

感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的:
① 2000多本Python电子书(主流和经典的书籍应该都有了)
② Python标准库资料(最全中文版)
③ 项目源码(四五十个有趣且经典的练手项目及源码)
④ Python基础入门、爬虫、web开发、大数据分析方面的视频(适合小白学习)
⑤ Python学习路线图(告别不入流的学习)
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









